







1.1 运行时数据区域

1.1.1 程序计数器
概念:字节码解释器工作时就是通过改变这个计数器的值来进行选取下一条需要执行的字节码指令、分支、循环、跳转、异常处理、线程恢复等基础功能。
因为Java虚拟机的多线程是通过线程轮流切换分支并分配处理器执行时间的方式来实现的,因此需要让此区域线程私有。
区别:Java内存空间中唯一一个没有规定OutMemoryError情乱的区域。
1.1.2 Java虚拟机栈
线程私有的。他的生命周期与线程相同。
设置虚拟机栈的指令:-Xss256k(K)或者-Xss12m(M),单位不区分大小写
两种异常
- 当线程请求栈的深度大于虚拟机规定的最大深度的情况下会抛出StackOverflowError异常
- 如果虚拟机栈允许扩展的情况下,如果扩展时无法申请到足够的时候会抛出outofOverflowError异常
概念:虚拟机栈描述的是Java方法执行的内存模型。每个方法在执行的同时都会创建一个栈帧。
栈帧中存放的数据:
- 局部变量表
- 操作数栈
- 动态链接
- 方法出口等信息(方法返回地址)
局部变量表
-
定义为一个数字数组,主要用于存储方法参数和定义在方法体内的局部变量,数据类型包括:基本数据类型,引用类型和returnAddress类型
-
局部变量表建立在线程栈上,是线程的私有数据,不存在数据安全问题
-
局部变量表所需的容量大小是在编译期确定下来的,并保存在方法的code属性的maximum local variables数据项,在方法运行期间是不会改变局部变量表的大小。
-
参数值的存放总是在局部变量数组的index0开始,到数组长度-1的索引结束
-
最基本的存储单元是slot(变量槽)
-
4字节以内的类型只占用一个slot(包括returnAddress类型),64位的类型(long和double)占用两个slot
byte、short、char在存储前被转换为int,boolean也被转换为int,0为false,非0为true。
-
byte:1个字节 8位 -128~127
-
short :2个字节 16位
-
int :4个字节 32位
-
long:8个字节 64位
-
float:4个字节 32 位
-
double :8个字节 64位
-
char:2个字节。
-
boolean: (true or false)(并未指明是多少字节 1字节 1位 4字节)
-
-
jvm会为局部变量表中的每一个slot都分配一个访问索引,通过这个索引即可成功访问到局部变量表中指定的局部变量值。
-
当一个实例方法被调用的时候,它的方法参数和方法体内部定义的局部变量将会按照顺序被复制到局部变量表中的每一个slot上。
-
如果要访问局部变量表中的一个64位的局部变量值时,只需要使用前一个索引,比如下图中中要访问double类型,即访问索引4即可。

-
如果当前帧是由构造方法或者实例方法创建,那么该对象引用this将会存放在index为0的slot处,其余的参数按照参数表顺序继续排列。
-
栈帧中的局部变量表中槽位是可以重用的,如果一个局部变量过了其作用域,那么在其作用域之后申明的新的局部变量有可能复用过期的局部变量的槽位,从而到达节省资源。

-
方法嵌套调用次数由栈的大小决定。
-
局部变量表中的变量只有在当前方法调用中有效,在方法执行时,虚拟机通过使用局部变量表完成参数值到参数变量列表的传递过程。当方法调用结束后,随着方法栈帧的销毁,局部变量表也会随之销毁。
-
类变量在“准备阶段”执行系统初始化,在“初始化”阶段使用程序的显示赋值操作。
-
但是局部变量不存在系统初始化,即一旦定义了局部变量必须要先人为初始化,否则无法使用。
-
局部变量表中的变量也是重要的垃圾回收根节点,只要被局部变量表中直接或者间接引用的对象都不会被回收。
操作数栈
概念:每一个独立的栈帧中除了包含局部变量表之外,还包含一个操作数栈。操作数栈在方法执行过程中,根据字节码指令,往栈中写入数据或者提取数据,即入栈/出栈。
动态链接
每一个栈帧内部都包含一个指向运行时常量池中该栈帧所属方法的引用,目的为了支持当前方法的代码能够实现动态链接
在java源文件被编译到字节码文件中时,所有的变量和方法引用都作为符号引用保存在class文件的常量池里。
比如:描述一个方法调用了另一个其他的方法时,就是通过常量池中指向方法的符号引用来表示的,那么动态链接的作用就是为了这些符号引用转换为调用方法的直接引用。
方法返回地址
(1)存放调用该方法的pc寄存器的值
(2)一个方法的结束,有两种方式
i)正常执行结束
执行引擎遇到一个方法返回的字节码指令(return)会有返回值传递给上层的方法调用者,简称正常完成出口。
一个方法在正常调用完成后,需要哪一种返回指令还需要根据方法返回值的实际数据类型而定。
遇到ireturn(返回值是boolean,byte,char,short,int)
lreturn、freturn、dreturn、areturn(引用类型)和return(void,实例初始化,类和接口的初始化方法的返回)
ii)出现未处理的异常,非正常退出
方法执行过程中遇到了异常,并且这个异常没有在方法内进行处理,也就是只要在本方法的异常表中没有搜索到匹配的异常处理器,就会导致方法的退出。
方法执行过程中抛出异常时的异常处理,存储在一个异常处理表中,方便再发生异常的时候找到处理异常的代码。
1.1.3 本地方法栈
类似于Java虚拟机栈主要是保存执行本地放的的数据。
1.1.4 Java 堆
线程共享的,在虚拟机创建的时候创建。
-Xmx 和 -Xms进行设置堆内存大小。
- Java堆(Java Heap)是java虚拟机所管理的内存中最大的一块
- java堆被所有线程共享的一块内存区域
- 虚拟机启动时创建java堆
- java堆的唯一目的就是存放对象实例。
- java堆是垃圾收集器管理的主要区域。
- 从内存回收的角度来看, 由于现在收集器基本都采用分代收集算法, 所以Java堆可以细分为:新生代(Young)和老年代(Old)。 新生代又被划分为三个区域Eden、From Survivor, To Survivor等。无论怎么划分,最终存储的都是实例对象, 进一步划分的目的是为了更好的回收内存, 或者更快的分配内存。
- java堆的大小是可扩展的, 通过-Xmx和-Xms控制。
- 如果堆内存不够分配实例对象, 并且对也无法在扩展时, 将会抛出outOfMemoryError异常
堆内存划分
- 堆大小 = 新生代 + 老年代。堆的大小可通过参数–Xms(堆的初始容量)、-Xmx(堆的最大容量) 来指定。
- 其中,新生代 ( Young ) 被细分为 Eden 和 两个 Survivor 区域,这两个 Survivor 区域分别被命名为 from 和 to,以示区分。默认的,Edem : from : to = 8 : 1 : 1 。(可以通过参数 –XX:SurvivorRatio 来设定 。
- 即: Eden = 8/10 的新生代空间大小,from = to = 1/10 的新生代空间大小。
- JVM 每次只会使用 Eden 和其中的一块 Survivor 区域来为对象服务,所以无论什么时候,总是有一块 Survivor 区域是空闲着的。
- 新生代实际可用的内存空间为 9/10 ( 即90% )的新生代空间。
1.1.5 方法区
概念:它用于存储已被虚拟机加载的类信息、常量、静态常量、即时编译器编译后的代码等数据。
老版本的方法区类似于堆内存,也有人叫做永久代,但是jdk1.8之后已经取消了方法去,换成了元空间,他是在本地内存上分配的。
当内存不够分配的时候会抛出OutOfMemoryError异常
1.1.6 运行时常量池
概念:运行时常量池是方法区的一部分(现在来说就是元空间的一部分)
Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池,用于存放编译器生成的各种字面量和符号引用,这部分内容将在类加载后进入方法去的运行时常量池中存放。
异常:OutOfMemoryError异常
1.1.7 直接内存
1.2 HotSpot虚拟机对象
1.2.1 对象的创建
- 当虚拟机遇到一条new指令的时候,首先会检查这个参数是否在常量池中定位到一个类ide符号引用,并检查这个符号引用类是否已经被加载、解析和初始化过。如果没有,执行相应的初始化流程。
- 类加载通过之后,接下来需要为新生对象分配内存。(所需内存的大小在类加载完成之后就会确定)
- 分配内存空间有两种方式
- 指针碰撞(前提是内存空间需要时规整的):就是一段内存中有一个指针表示临界指针,左边的是已经分配过的内存,右边的是空闲内存。使用这种方式的虚拟机有:Serial、ParNew等带Compact过程的收集器时使用指针碰撞。
- 空闲列表(内存并不规整):虚拟机需要维护一个列表,记录那块内存能用,再分配的时候从列表中找到一块符合大小的内存空间就行了,并更新列表上的记录。使用这种方式的虚拟机一般来说是使用CMS这种基于Mark-Sweep算法的收集器的时候。
- 分配内存的线程安全。
- 虚拟机采用CAS配上失败重试的方式保证更新操作的原子性。
- 把内存分配的动作按照线程划分在不同的空间中进行。即每个线程在Java堆中预先分配一小块内存,曾为本地线程分配缓存(TLAB)。哪个线程需要分配内存,就在那个线程的TLAb上分配,只有TLAB用完并分配新的TLAB时,才需要同步锁定。虚拟机是否使TLAB,可以通过-XX:+/-UseTLAB参数设定。
- 内存分配完成之后虚拟机需要将分配到的内存空间都初始化为零值。
- 接下来虚拟机需要对对象进行一些必要的设置。
- 以上的操作执行完成之后,从虚拟机的视角来说,一个新的对象已经产生了,但是从Java成需要来看的话,对象创建才开始——方法还没有进行执行。所有字段还为零。执行new指令还需要执行方法。
源码解读:
CASE(_new): {
u2 index = Bytes::get_Java_u2(pc+1);
// 解释器状态能拿到常量池
ConstantPool* constants = istate->method()->constants();
// 可以看出这段代码是为了判断常量池中存放的是已解释的类。
if (!constants->tag_at(index).is_unresolved_klass()) {
// Make sure klass is initialized and doesn't have a finalizer
// 确保klass被初始化,并且没有终结器
// klass在Java中就是描述类的对象
Klass* entry = constants->slot_at(index).get_klass();
// 判断从栈帧中拿出来的这个对象是klass
assert(entry->is_klass(), "Should be resolved klass");
Klass* k_entry = (Klass*) entry;
// 应该是实例Klass
assert(k_entry->oop_is_instance(), "Should be InstanceKlass");
InstanceKlass* ik = (InstanceKlass*) k_entry;
// 确保对象所属类型已经经过初始化阶段
if ( ik->is_initialized() && ik->can_be_fastpath_allocated() ) {
// 取对象长度。
size_t obj_size = ik->size_helper();
oop result = NULL;
// If the TLAB isn't pre-zeroed then we'll have to do it
// 如果TLAB没有提前归零,我们就得这么做
// 记录是否需要将对象所有字段置为零
bool need_zero = !ZeroTLAB;
// 确认是否在TLAB中分配对象
if (UseTLAB) {
result = (oop) THREAD->tlab().allocate(obj_size);
}
// Disable non-TLAB-based fast-path, because profiling requires that all
// allocations go through InterpreterRuntime::_new() if THREAD->tlab().allocate
// returns NULL.
#ifndef CC_INTERP_PROFILE
if (result == NULL) {
need_zero = true;
// 直接在eden中分配对象
// Try allocate in shared eden
retry:
HeapWord* compare_to = *Universe::heap()->top_addr();
HeapWord* new_top = compare_to + obj_size;
if (new_top <= *Universe::heap()->end_addr()) {
// 这里是通过CAS指令分配空间
if (Atomic::cmpxchg_ptr(new_top, Universe::heap()->top_addr(), compare_to) != compare_to) {
goto retry;
}
result = (oop) compare_to;
}
}
#endif
if (result != NULL) {
// Initialize object (if nonzero size and need) and then the header
// 如果需要,则为对象初始化零值。
if (need_zero ) {
HeapWord* to_zero = (HeapWord*) result + sizeof(oopDesc) / oopSize;
obj_size -= sizeof(oopDesc) / oopSize;
if (obj_size > 0 ) {
memset(to_zero, 0, obj_size * HeapWordSize);
}
}
// 根据是否启用偏向锁来设置对象头信息
if (UseBiasedLocking) {
result->set_mark(ik->prototype_header());
} else {
result->set_mark(markOopDesc::prototype());
}
result->set_klass_gap(0);
result->set_klass(k_entry);
// Must prevent reordering of stores for object initialization
// with stores that publish the new object.
OrderAccess::storestore();
// 对象入栈,继续执行下一条指令
SET_STACK_OBJECT(result, 0);
UPDATE_PC_AND_TOS_AND_CONTINUE(3, 1);
}
}
}
1.2.2 对象的内存布局
在 JVM 中,Java对象保存在堆中时,由以下三部分组成:
- 对象头(object header):包括了关于堆对象的布局、类型、GC状态、同步状态和标识哈希码的基本信息。Java对象和vm内部对象都有一个共同的对象头格式。
- 实例数据(Instance Data):主要是存放类的数据信息,父类的信息,对象字段属性信息。
- 对齐填充(Padding):为了字节对齐,填充的数据,不是必须的。
对象头

在每个gc管理的堆对象开始处的公共结构。(每个oop都指向一个对象头。)包括关于堆对象的布局、类型、GC状态、同步状态和标识哈希码的基本信息。由两个词组成。在数组中,紧随其后的是长度字段。注意,Java对象和vm内部对象都有一个通用的对象头格式。虚拟机可以通过普通Java对象的元数据信息确定Java对象的大小,但是从数组的元数据中无法确定数组的大小。
它里面提到了对象头由两个字组成,这两个字是什么呢?我们还是在上面的那个Hotspot官方文档中往上看,可以发现还有另外两个名词的定义解释,分别是 mark word 和 klass pointer。
klass pointer
The second word of every object header. Points to another object (a metaobject) which describes the layout and behavior of the original object. For Java objects, the “klass” contains a C++ style “vtable”.
mark word
The first word of every object header. Usually a set of bitfields including synchronization state and identity hash code. May also be a pointer (with characteristic low bit encoding) to synchronization related information. During GC, may contain GC state bits.
Mark Word
用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等。
Mark Word在32位JVM中的长度是32bit,在64位JVM中长度是64bit。我们打开/openjdk/hotspot/src/share/vm/oops,Mark Word对应到C++的代码markOop.hpp,可以从注释中看到它们的组成。

Mark Word在不同的锁状态下存储的内容不同,在32位JVM中是这么存的
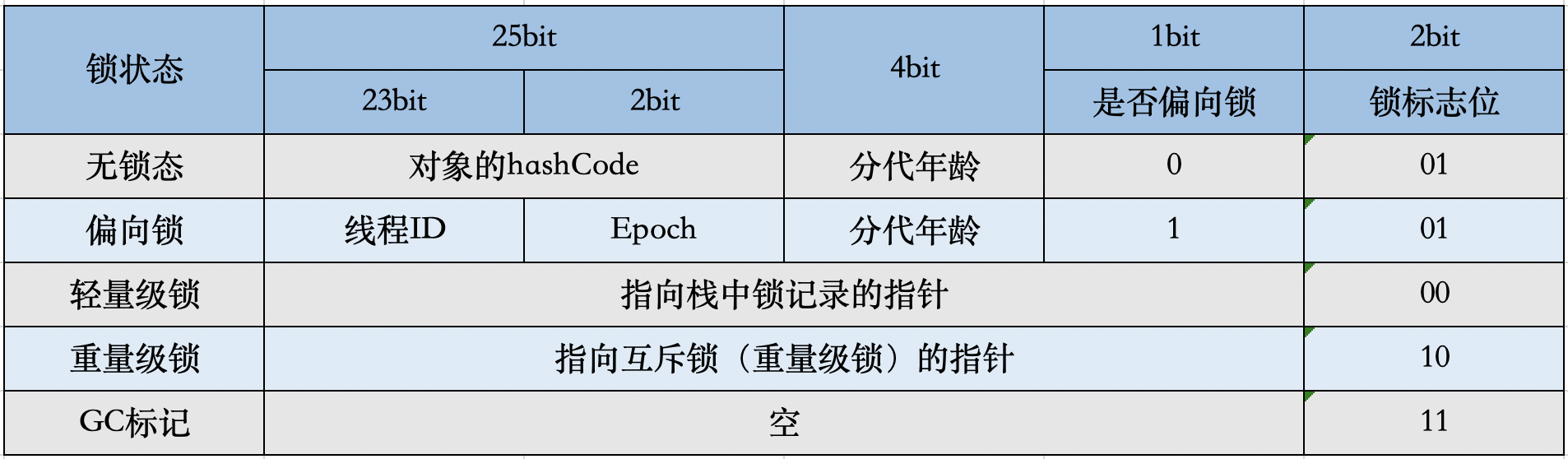
在64位JVM中是这么存的
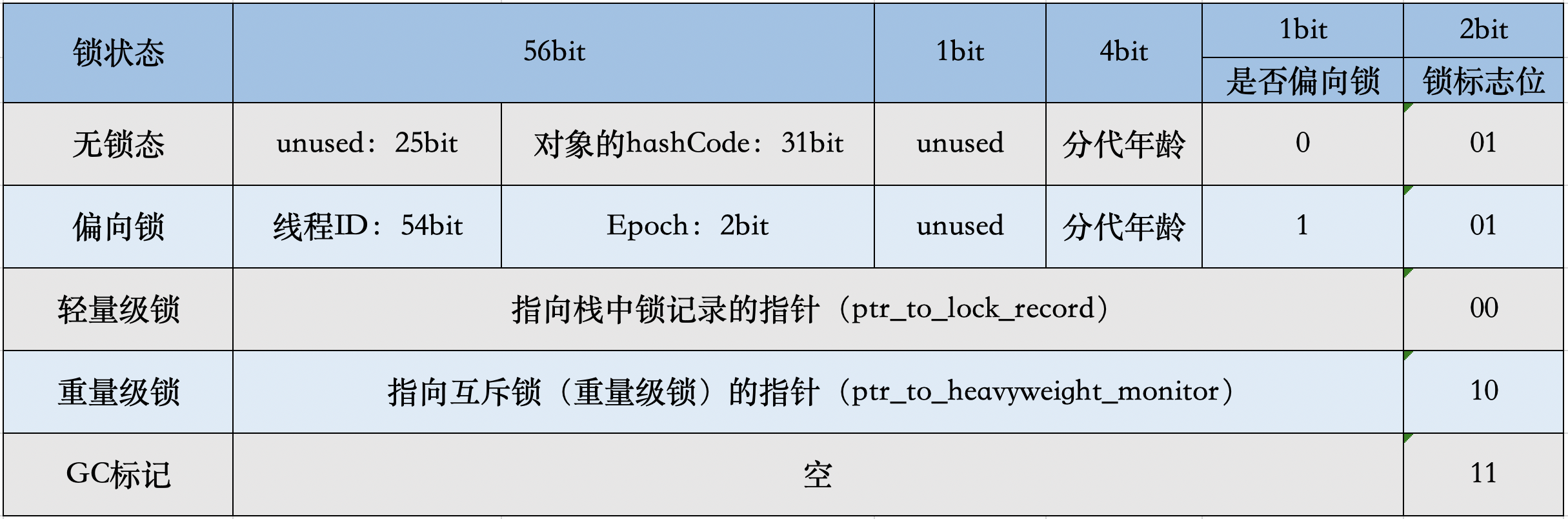
虽然它们在不同位数的JVM中长度不一样,但是基本组成内容是一致的。
- 锁标志位(lock):区分锁状态,11时表示对象待GC回收状态, 只有最后2位锁标识(11)有效。
- biased_lock:是否偏向锁,由于正常锁和偏向锁的锁标识都是 01,没办法区分,这里引入一位的偏向锁标识位。
- 分代年龄(age):表示对象被GC的次数,当该次数到达阈值的时候,对象就会转移到老年代。
- 对象的hashcode(hash):运行期间调用System.identityHashCode()来计算,延迟计算,并把结果赋值到这里。当对象加锁后,计算的结果31位不够表示,在偏向锁,轻量锁,重量锁,hashcode会被转移到Monitor中。
- 偏向锁的线程ID(JavaThread):偏向模式的时候,当某个线程持有对象的时候,对象这里就会被置为该线程的ID。 在后面的操作中,就无需再进行尝试获取锁的动作。
- epoch:偏向锁在CAS锁操作过程中,偏向性标识,表示对象更偏向哪个锁。
- ptr_to_lock_record:轻量级锁状态下,指向栈中锁记录的指针。当锁获取是无竞争的时,JVM使用原子操作而不是OS互斥。这种技术称为轻量级锁定。在轻量级锁定的情况下,JVM通过CAS操作在对象的标题字中设置指向锁记录的指针。
- ptr_to_heavyweight_monitor:重量级锁状态下,指向对象监视器Monitor的指针。如果两个不同的线程同时在同一个对象上竞争,则必须将轻量级锁定升级到Monitor以管理等待的线程。在重量级锁定的情况下,JVM在对象的ptr_to_heavyweight_monitor设置指向Monitor的指针。
Klass Pointer
即类型指针,是对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
实例数据
属性的分配策略:longs/doubles、ints、shorts/chars、bytes/booleans、opps。
如果对象有属性字段,则这里会有数据信息。如果对象无属性字段,则这里就不会有数据。根据字段类型的不同占不同的字节,例如boolean类型占1个字节,int类型占4个字节等等;
对齐数据
对象可以有对齐数据也可以没有。默认情况下,Java虚拟机堆中对象的起始地址需要对齐至8的倍数。如果一个对象用不到8N个字节则需要对其填充,以此来补齐对象头和实例数据占用内存之后剩余的空间大小。如果对象头和实例数据已经占满了JVM所分配的内存空间,那么就不用再进行对齐填充了。
所有的对象分配的字节总SIZE需要是8的倍数,如果前面的对象头和实例数据占用的总SIZE不满足要求,则通过对齐数据来填满。
为什么要对齐数据?字段内存对齐的其中一个原因,是让字段只出现在同一CPU的缓存行中。如果字段不是对齐的,那么就有可能出现跨缓存行的字段。也就是说,该字段的读取可能需要替换两个缓存行,而该字段的存储也会同时污染两个缓存行。这两种情况对程序的执行效率而言都是不利的。其实对其填充的最终目的是为了计算机高效寻址。
如果想要自己验证做的对不对需要引入openjdk提供的jol包进行打印对象信息。
1.2.3 对象的访问定位
- 句柄: 如果使用句柄的话,那么 Java 堆中将会划分出一块内存来作为句柄池,reference 中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自的具体地址信息。
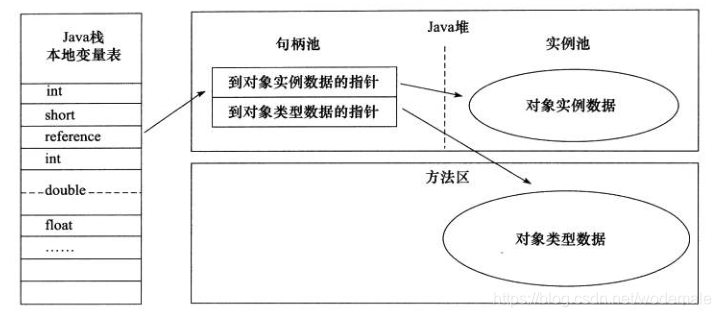
通过句柄访问对象 - 直接指针: 如果使用直接指针访问,那么 Java 堆对象的布局中就必须考虑如何放置访问类型数据的相关信息,而 reference 中存储的直接就是对象的地址。
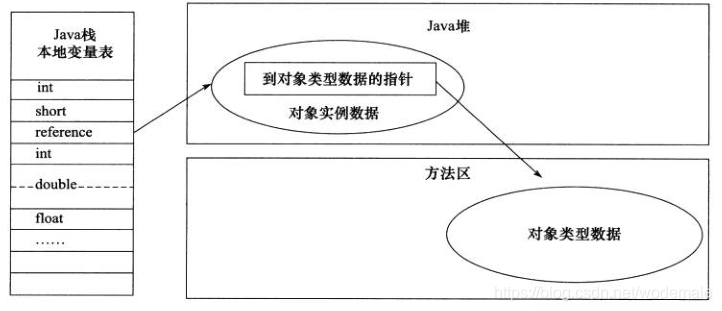
通过直接指针访问对象
这两种对象访问方式各有优势。使用句柄来访问的最大好处是 reference 中存储的是稳定的句柄地址,在对象被移动时只会改变句柄中的实例数据指针,而 reference 本身不需要修改。使用直接指针访问方式最大的好处就是速度快,它节省了一次指针定位的时间开销。














 725
725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









