






java实现InfluxDB的插入和查询
1.InfluxDB2.0涉及的部分名词
1)bucket:数据库
2)measurement:数据库中的表
3)points:表里面的一行数据
point由时间戳【time:每个数据记录时间,是数据库中的主索引(会自动生成)】、数据【field:(各种记录值(没有索引的属性)也就是记录的值)】、标签【tags:(各种有索引的属性】组成
2.InfluxDB2.0部分语法说明
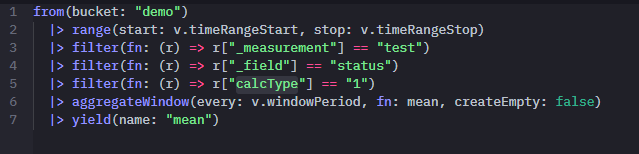
1)from 指定数据源bucket
2)|> 管道连接符
3)range 指定起始时间段
4)filter 过滤
5)yield作为查询结果输出过滤的tables
6)aggregateWindow函数,可结合参数every输出持续时间,比如每5s,createEmpty: true没有数据返回一行空数据,可结合fill(usePrevious: true)将此空数据赋值为前一条非空的数据值
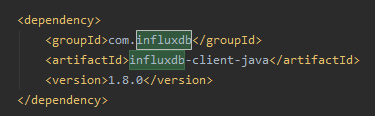
3.maven依赖
4.InfluxDataUtil工具类
public class InfluxDataUtil {
/** 连接的url*/
private String url;
/** 连接的token*/
private String token;
/** 连接的org*/
private String org;
private InfluxDBClient client;
public InfluxDataUtil(String url, String token, String org) {
this.url = url;
this.token = token;
this.org = org;
influxDbBuild();
}
/**
* 连接时序数据库 ,若不存在则创建
* @return
*/
public InfluxDBClient influxDbBuild() {
if (null == client) {
//client = InfluxDBClientFactory.create(url, token.toCharArray());
//获取client调整为单例模式,模式中主要代码就是InfluxDBClientFactory.create(url, token.toCharArray())
client = InfluxData.getInfluxData();
}
return client;
}
/**
* 关闭数据库
*/
public void close() {
client.close();
}
/**
* 往时序数据库插入数据
* @return
*/
public void insert(String measurement, String bucket,Map<String, String> tags, Map<String, Object> fields, Instant createTime){
if(null == measurement || null == createTime || null == tags || null == fields){
throw new XxlJobException("插入influxDB的重要参数不能为空,请检查");
}
Point point = Point.measurement(measurement)
.addTags(tags)
.addFields(fields)
.time(createTime, WritePrecision.S);
try (WriteApi writeApi = client.getWriteApi()) {
writeApi.writePoint(bucket, org, point);
}
}
/**
* 查询
* @param command 查询语句
* @return
*/
public List<FluxTable> query(String command){
if(StringUtils.isEmpty(command)){
throw new XxlJobException("查询influxDB的重要参数不能为空,请检查");
}
return client.getQueryApi().query(command, org);
}
public InfluxDBClient getClient() {
return client;
}
public void setClient(InfluxDBClient client) {
this.client = client;
}
}
5.新增数据
/**
* 往influxDB中插入值数据
*/
private void insertInfluxDB(String bucket,String comprehensiveAlarmId, Long status,InfluxDataUtil influxDataUtil) {
Date date = new Date();
Instant createTime = null;
try {
createTime = DateUtils.StringToDateToInstant(DateUtils.dateToStr(date, "yyyy-MM-dd HH:mm"), "yyyy-MM-dd HH:mm");
} catch (ParseException e) {
e.printStackTrace();
}
Map<String, String> tags = new HashMap<>();
tags.put(Constants.JobRelevantInfo.COMPREHENSIVE_ALARM_ID, comprehensiveAlarmId);
Map<String, Object> fields = new HashMap<>();
fields.put(Constants.JobRelevantInfo.STATUS, status);
influxDataUtil.insert(measurement, bucket, tags, fields, createTime);
}
说明:插入时需要根据自己的业务需求存储tags和fields,
6.查询数据
在类似mapper类中开发具体的查询语句:
private String queryValueFlux="from(bucket: \"%s\") " +
"|> range(start: %s) " +
"|> filter(fn: (r) => r._measurement == \"%s\" and r.name== \"%s\" and r._field == \"%s\") |> %s";
public String formateQueryValueFlux(User user){
return String.format(queryTagValueFlux, user.getDataBucket(),user.getStart(),user.getMeasurement(),user.getTagNumber(),"value",user.getSortType());
}
在类似service类中开发一个方法供调用,将查询的数据封装在map中返回:
public Map<String, Object> qryVal(User user, InfluxDataUtil influxDataUtil) {
List<FluxTable> tables = influxDataUtil.query(tagValueInfoMapper.formateQueryValueFlux(user);
Double value = null;
Map<String, Object> map = new HashMap<>();
if(CollectionUtil.isNotEmpty(tables)){
for(FluxTable table : tables){
List<FluxRecord> records = table.getRecords();
for(FluxRecord fluxRecord : records){
if(fluxRecord.getField().equals("value")){
value = (Double)fluxRecord.getValue();
map.put("value",value);
map.put("valueTime", DateUtils.InstantToDate(fluxRecord.getTime()));
}
}
}
}
return map;
}
注:其中关于sortType可根据业务需要传last、first取第一条还是最后一条数据,语句可根据业务需要自己编辑
文章中的代码仅供参考,希望可以给你带来帮助,如有不足之处,自行优化。















 1177
1177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









