







论文Learning Deep Features for One-Class Classification
1.概述
作者在深度学校多分类的基础上提出了新的特征提取方法。并且提出了两个概念:描述性损失(descriptiveness loss)、紧凑性损失(compactness loss)。跟着作者的论文路线,一步一步解析。
2.分类方法
分类方法有机器学习的支持向量机、神经网络、线性判别分析等,这些都是在原始数据上面进行直接分类。还有更强大的深度学习,使用卷积神经网络提取特征之后再使用分类网络分类。但是深度学习的训练都是建立在大量数据上面的。作者提出了四种数据情况:
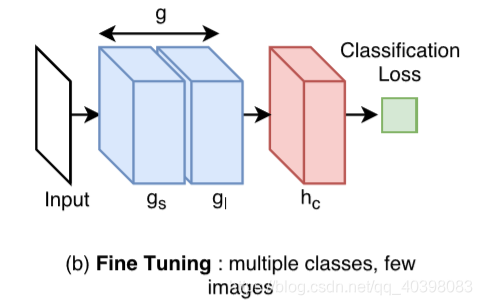
- 多类多样本:在训练时权重使用随机数据初始化,训练的结果可以作为预训练模型。
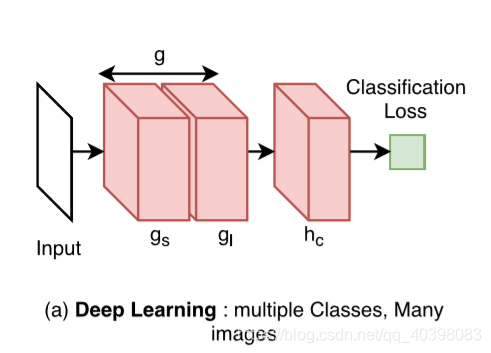
- 多类中等样本:把卷积网络分成两个子网络,gs共享网络,gl学习网络。使用预训练模型初始化权重。训练时冻结共享网络,训练学习网络和分类网络。
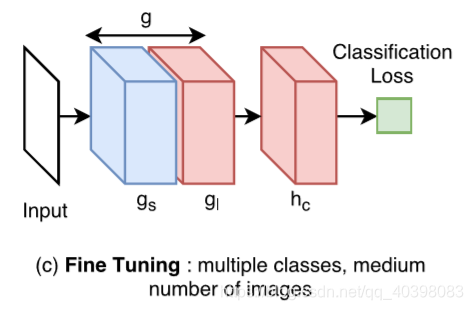
- 多类少样本:冻结卷积网络,使用预训练模型初始化权重,训练时只训练分类网络。
- 一类或者没有训练数据:只有一种类数据可用时,使用预训练模型的卷积网络提取特征,使用机器学习的方法训练分类器。
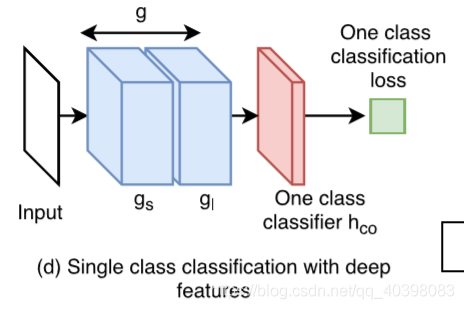
对于单分类的机器学习方法在https://blog.csdn.net/qq_40398083/article/details/97375286
作者研究的主要就是最后一种情况。
3.单分类提取特征的三中策略
-
直接在训练好的模型中提取特征,然后使用SVM或者k-近邻分类。这种情况,可以正确的分类,特征具有很强的描述性,但是没有紧凑性。红色是正常椅子,蓝色是异常椅子。可以看到分类效果不是很好。
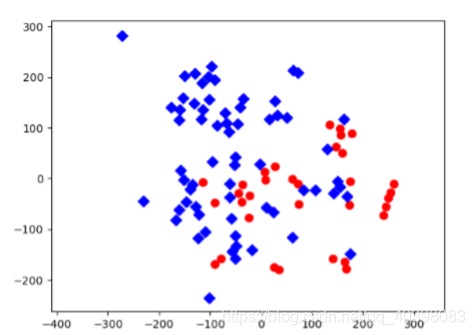
-
微调二分类,使用一个外部数据集作为负样本,给定的类的数据作为正样本进行训练。结果也不是很好,因为网络学到了很多相似的特征,不能完全的分开正常椅子和异常椅子。除非负样本数据集与正样本有很强的的关联。
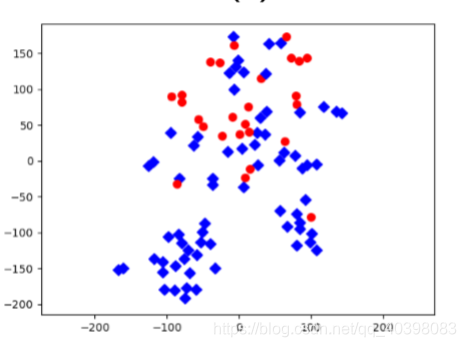
-
只使用给定类微调。可以使用传统的交叉熵损失函数或者其他的损失函数,理论上正常椅子在特征空间是紧凑地。这种情况所有的标签相同,学习的是没有的结果。比如标签是0,那么把所有的权重变成0,损失也就是0。因为缺少一个正则项。
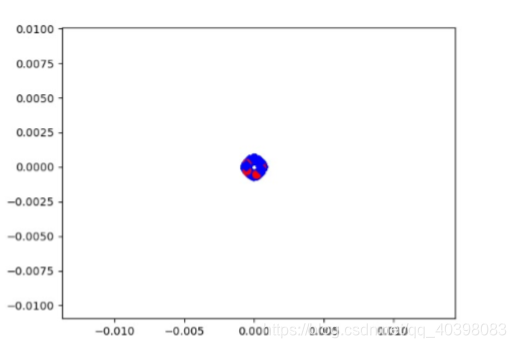
只有第一种策略最合理,但是没有考虑紧凑性。作者提出了新的网络框架,效果比较好
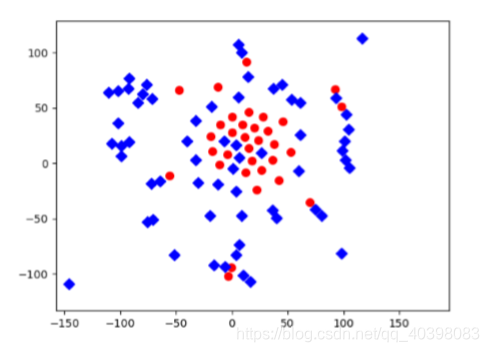
4.DOC
优化目标:
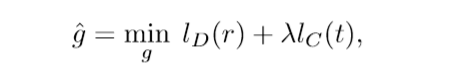
其中ld是描述性损失,lc是紧凑性损失,r是数据集。λ是正常数,它的存在决定了训练网络对描述性和紧凑地重要程度,如果大于1,那么紧凑性更重要,如果小于1,描述性更重要。
网络结构:
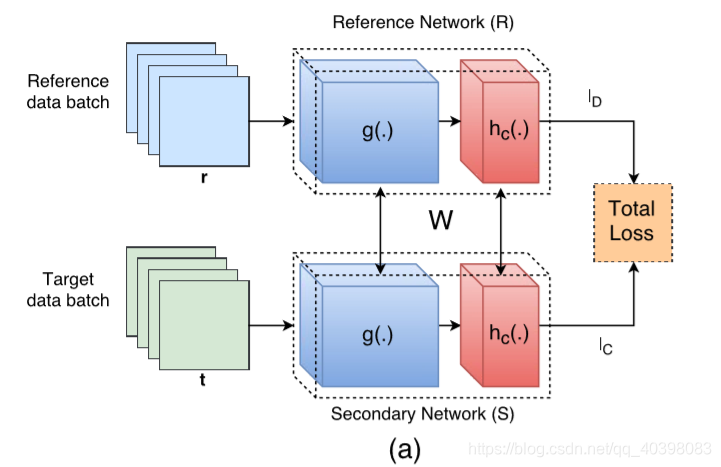
参考网络(R):就是普通的卷积网络,可以使用VGG16或者ImgNet等。产生描述性损失。
辅助网络(S):跟参考网络结构一样的卷积网络,紧凑性损失。
参考数据集:给定类之外的数据,训练参考网络。
目标数据集:给定类数据集,训练辅助网络。
权重:参考网络和辅助网络使用相同的权重初始化。
描述性损失:使用交叉熵损失函数。
紧凑性损失:使用均方误差
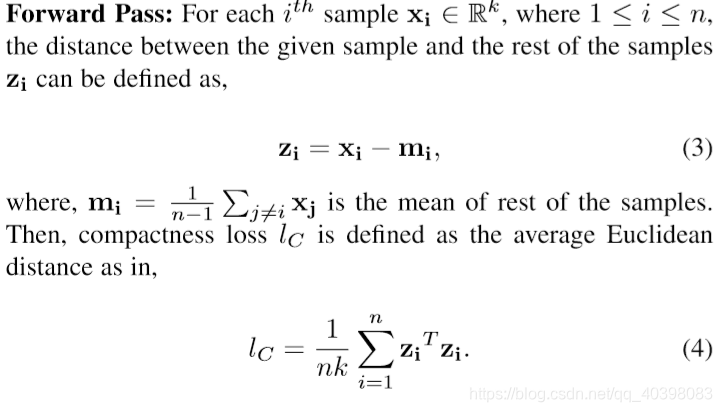
5.训练
冻结前面一部分卷积网络,学习率用一个相对小的值。参考网络和目标数据同时送入输入。复合损失:
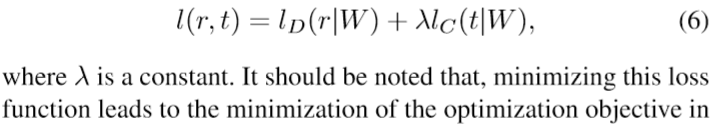
6.测试
使用训练好的网络(参考网络、辅助网络)提取特征,生成模版,然后使用机器学习方法分类。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









