






 本文档描述了如何处理ClickHouse内存不足的问题,通过查询日志文件大小,删除占用空间的日志分区,调整配置文件以定期清理日志,并重启服务以确保设置生效。操作包括检查日志文件、删除特定分区、创建force_drop_table标志文件以及修改query_log配置。
本文档描述了如何处理ClickHouse内存不足的问题,通过查询日志文件大小,删除占用空间的日志分区,调整配置文件以定期清理日志,并重启服务以确保设置生效。操作包括检查日志文件、删除特定分区、创建force_drop_table标志文件以及修改query_log配置。
今天早上想看看clickhouse里面跑了多少数据了,一查询刺激了。。。。。
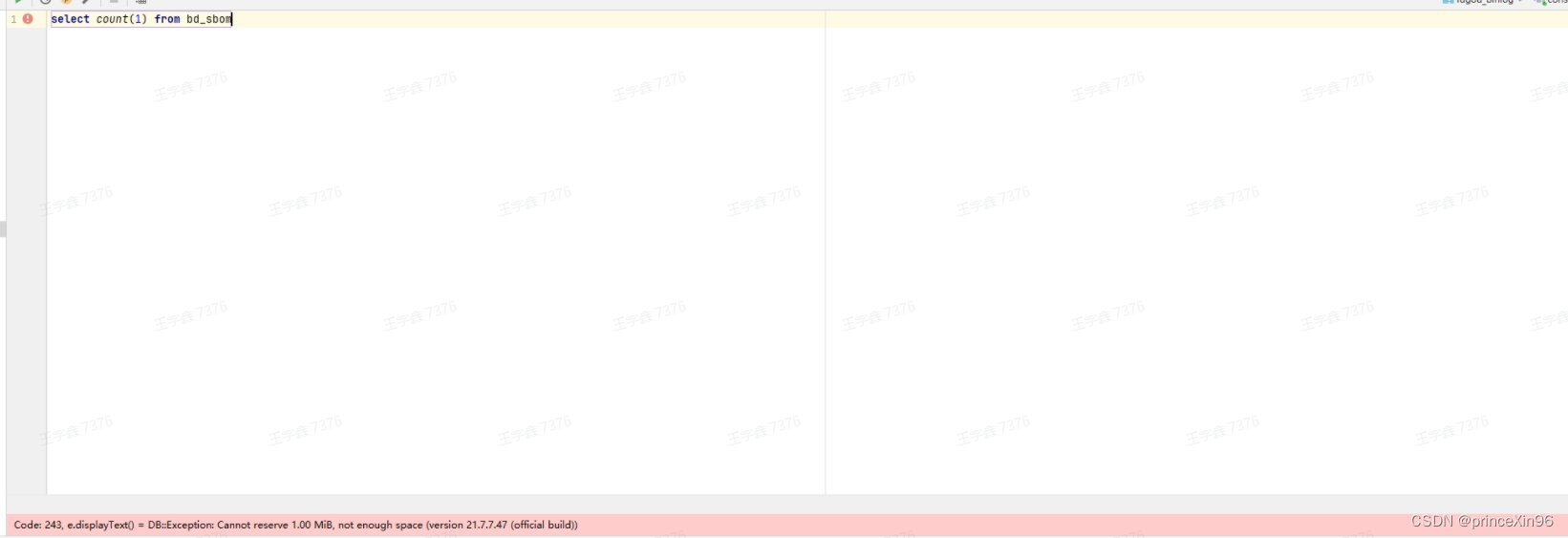
抱着遇到问题解决问题的态度,根据报错那不就是内存空间不足了吗?
来到服务器df -h一跑果然use%达到100%
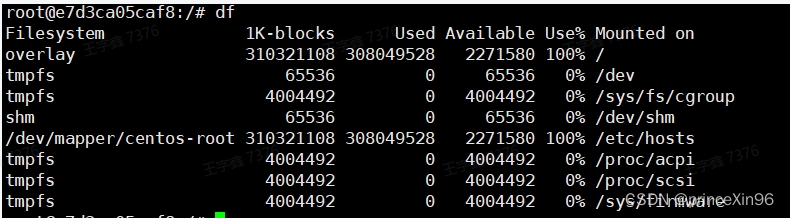
没得说清内存吧,可是要怎么清呢,问了度娘一大圈,总结还是clickhouse一些XX_log日志文件太大了,那就删呗
重点来了。。。
1、先看是哪个日志文件把我的内存打满了
SELECT
sum(rows) AS `总行数`,
formatReadableSize(sum(data_uncompressed_bytes)) AS `原始大小`,
formatReadableSize(sum(data_compressed_bytes)) AS `压缩大小`,
round((sum(data_compressed_bytes) / sum(data_uncompressed_bytes)) * 100, 0) AS `压缩率`,
`table` AS `表名`
FROM system.parts where database = 'system' group by `table`2、找到后执行删除命令,注意clickhouse里面的日志文件都是按照日期分区存储的,query_thread_log或者query_log,看具体哪个日志文件占的内存大
alter table system.query_thread_log drop partition '202201';3.如果日志文件的大小超过50G,删除会报错,此时需要添加一个文件/var/lib/clickhouse/flags/force_drop_table,文件内容如下;添加完即可成功删除
<max_table_size_to_drop>0</max_table_size_to_drop>删干净之后再用df看,发现内存空闲多了
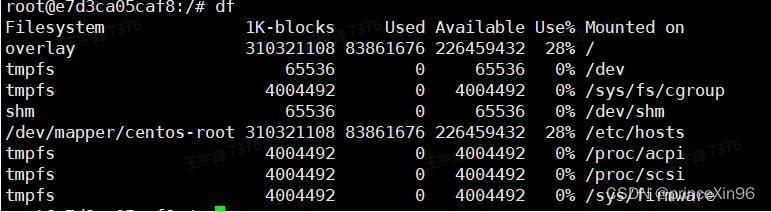
4、删除完之后并没有完全解决问题,要想完全解决问题,需要修改服务端的config.xml(配置文件位置 /etc/clickhouse-server/config.xml)配置文件(设置每15天清一次日志文件)
<query_log>
<database>system</database>
<table>query_thread_log</table>
<engine>Engine = MergeTree PARTITION BY event_date ORDER BY event_time TTL event_date + INTERVAL 15 day</engine>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_log>
5、最最重要的是要重启一下clickhouse,如果你是docker部署的直接,不重启还是会报错
docker restart 容器id
















 707
707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









