






[AutoML] HyperGBM:九章云极的全Pipeline自动机器学习工具

HyperGBM是九章云极公司的开源全Pipeline自动机器学习工具。九章云极(DataCanvas)于2013年成立,是自主研发的中国公司,专注自动化数据科学平台的持续开发与建设,已为政府、金融、通信、航空、制造、交通、教育、地产和互联网等多行业客户提供实时敏捷的AI能力建设。2020年,凭借其独创的DeepTables开源项目,九章云极在包括了知名电商公司和搜索引擎公司的全球1100多支队伍中胜出,荣获Kaggle竞赛全球第一名。
HyperGBM端到端地完整覆盖从数据预处理、特征衍生、特征筛选、模型选择、超参数优化、模型融合的全过程。大部分现有的自动机器学习工具主要解决超参数优化问题,但HyperGBM能解决从数据清洗到算法优化的整个过程。
先直观地感受一下HyperGBM的使用:
from hypergbm import make_experiment
train_data = '/path/to/mydata.csv'
experiment = make_experiment(train_data, target='my_target', reward_metric='auc')
estimator = experiment.run()
print(estimator)
'''
Pipeline(steps=[('data_clean',
DataCleanStep(...),
('estimator',
GreedyEnsemble(...)])
'''
HyperGBM的使用较为简单,只需要几行代码即可训练模型。
下面对HpyerGBM的功能进行简单介绍:
HyperGBM功能合集
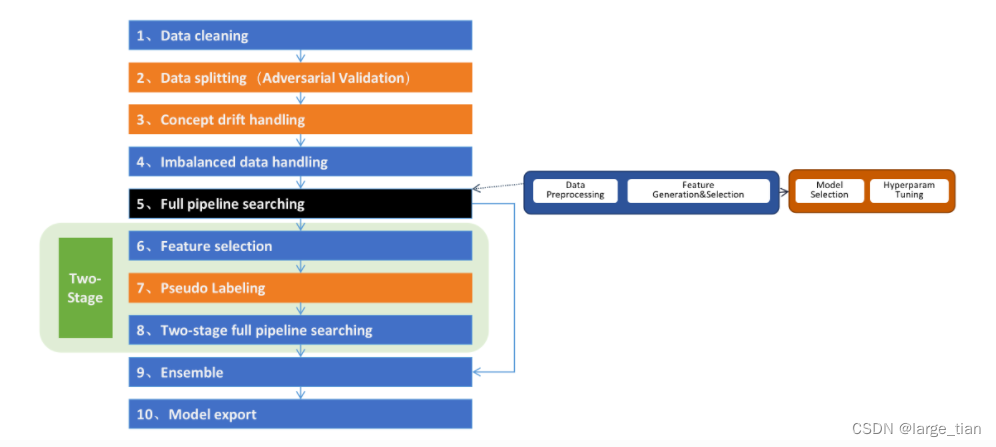
支持的操作
数据清洗
- 特殊空值字符处理 (e.g. None替换为np.nan)
- 删除标签为空的样本
- 自动识别列类别
- 列类别校正(e.g. 对每列数据尝试进行
X[col] = X[col].astype('float')) - inf值处理(e.g. 可将np.inf, -np.inf替换为指定内容(默认为np.nan))
- 重复列清理
- 去除指定列数据
- id列清理
- 常量列清理
- 共线性检测
- 漂移检测
数据预处理
SimpleImputer;SafeOrdinalEncoder;TargetEncoder;SafeOneHotEncoder;TruncatedSVD;StandardScaler;MinMaxScaler;MaxAbsScaler;RobustScaler
数据集划分:
- 按比例划分
- 基于对抗验证的数据集划分
特征加工和筛选
-
特征衍生:
依赖featuretools库实现,通过设定参与特征衍生的- 初始连续型特征,如果为None则依据训练数据的特征类型自行推断。
- 初始类别型特征,需要明确指定。
- 初始日期型特征,如果为None则依据训练数据的特征类型自行推断。
- 经纬度特征,如果为None则依据训练数据自行推断。
- 初始文本性特征,如果为None则依据训练数据自行推断。
- 用于特征衍生的算子
注意:若未指定特征衍生算子,则会依据参与特征衍生的初始特征自行推断所采用的算子,针对不同类型的特征采取不同算子。
from hypergbm import make_experiment
train_data = ...
experiment = make_experiment(train_data,
feature_generation=True,
...)
-
特征筛选:
通过训练一个常规模型对训练数据的特征重要性进行评估,进而筛选出最重要的特征参与到后续模型训练中。
筛选策略:- threshold——重要性高于该阈值的特征会被选择
- quantile—— 重要性分位高于该阈值的特征会被选择
- number ——筛选的特征数量
from hypergbm import make_experiment train_data=... experiment = make_experiment(train_data, feature_selection=True, feature_selection_strategy='quantile', feature_selection_quantile=0.3, ...)
模型选择 & 超参数优化
-
模型选择:支持流行的几种GBM
- XGBoost
- LightGBM
- CatBoost
- HistGradientBoosting
- 支持自定义建模算法——需要封装为HyperEstimator的子类,提供对应的搜索空间
详见:https://hypergbm.readthedocs.io/zh_CN/latest/example_customize.html
-
搜索空间:
HpyerGBM中提供默认搜索空间,但也可自定义。搜索空间共包含三部分:- Parameter Space (算法里的参数)
- Module Space(都有哪些算法)
- Connection Space (不同连接方式)
详见:https://hypergbm.readthedocs.io/zh_CN/latest/example_customize.html
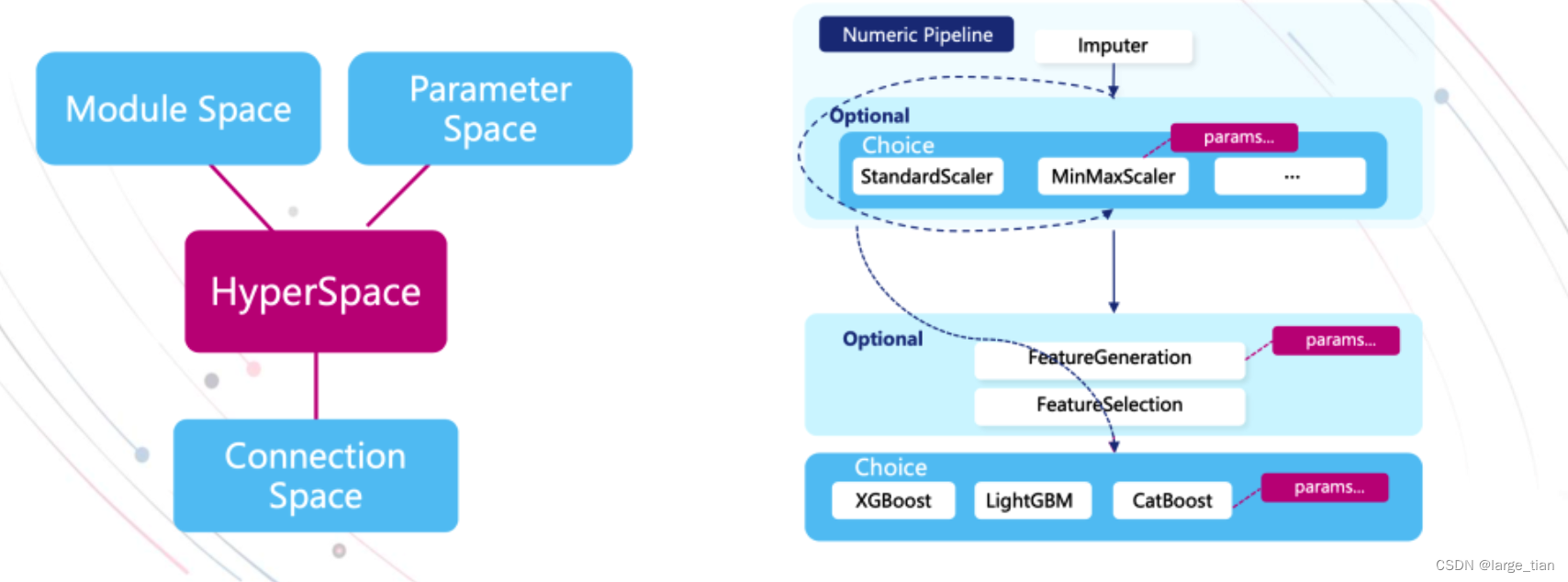
-
搜索算法:
随机搜索,蒙特卡罗树搜索,进化搜索 -
评估策略:
评估的时候在不是太不精确的情况下尽可能减少计算量-
使用meta-learner指导搜索方向:
-
将以往经验用在新的未知的任务上,加速在新任务上的执行效率
——通过fit不同的搜索子例数据集,大体确定数据预处理方法,算法的学习率大小,树的深度,迭代次数等参数的一个较好组合方向,进而提升搜索算法的性能参考:https://zhuanlan.zhihu.com/p/433566931
-
-
通过缓存节省处理时间——记录很多中间结果,反复使用
-
early stopping防止过拟合:
- 指定最大等待尝试次数(在搜索时若最高指标在接下来n次尝试都不提升便终止)
- 限定搜索时间
- 指定评估指标的目标值
from hypergbm import make_experiment experiment = make_experiment(train, target=target, early_stopping_rouds=10, early_stopping_time_limit=3600, early_stopping_reward=None)
参考:https://blog.csdn.net/weixin_42137700/article/details/119108848
-
-
模型的导出——官方推荐导出为pkl
import pickle with open('model.pkl','wb') as f: pickle.dump(estimator, f)
涉及的高级功能
HyperGBM中引入了多个高级特性来解决样本不均衡、数据漂移、泛化能力不足等问题
针对样本不均衡问题
HyperGBM中提供三种方式应对样本不均衡问题:
- 类别权重:ClassWeight
- 让样本少的类在训练时有更高的权重
- 重采样:RandomOversampling, SMOTE, ADASYN
from imblearn.over_sampling import RandomOverSampler, SMOTE, ADASYN- 对少数分类的样本重复采样来达到类别平衡的方法
- 降采样:RandomUndersampling, NearMiss, TomekLinks
from imblearn.under_sampling import RandomUnderSampler, NearMiss, TomekLinks, EditedNearestNeighbours- 抛弃多数类中的一部分样本来实现类别平衡
不同方法的介绍详见:https://zhuanlan.zhihu.com/p/350052055
自动内存适配
此步骤仅当输入数据是pandas或cudf的数据类型时生效;
检测是否有足够的系统内存容纳输入数据进行建模,如果发现内存不足则尝试对输入数据进行缩减。
可通过如下参数对数据适配的细节进行调整:
- data_adaption:(default True),是否开启数据适配
- data_adaption_memory_limit:(default 0.05),将输入数据缩减到系统可用内存的多大比例
- data_adaption_min_cols:(default 0.3),如果需要缩减数据的话,至少保留多少列
- data_adaption_target:(default None),此选项仅当输入数据是pandas DataFrame时生效,将此选项设置为’cuml’或’cuda’则会利用主机的CPU和MEM对数据进行缩减,然后转换为cudf.DataFrame,使得后续实验步骤在GPU中运行
共线性特征检测
去除相关度很高的特征
数据漂移检测
数据漂移:需要预测的数据和用于训练的数据分布表现出明显的偏移
HyperGBM引入了对抗验证的方法专门处理数据漂移问题。这个方法会自动的检测是否发生漂移,并且找出发生漂移的特征并删除他们,以保证模型在真实数据上保持良好的状态
特征筛选(二阶段)
传统的特征筛选方法:
-
训练前通过相关性指标评估或基于模型的特征评估排序,根据阈值或排序选择n个特征用于训练;
缺陷:特征的评估标准和实际用于训练的模型无关,不会考虑特征之间的交互关系。
-
先训练模型然后根据模型本身提供的特征重要性来选择一部分特征重新训练
缺陷:模型提供的是在训练数据上的重要性,并不能体现在评估数据或测试数据上特征的重要性。
HyperGBM的二阶特征筛选方法:
首先执行一阶段AutoML过程,选择其中表现最好的n个模型,使用permutation模式评估特征重要性,删除低于某一阈值的特征后,重新执行AutoML过程。
(permutation特征筛选:首先,基于已训练好的模型在评估集上得到一个baseline评分,然后分别将每一列特征变成噪音数据后重新评估,评分等于或高于baseline评分说明该特征对模型没有增益甚至于是有损的,如果评分下降说明该特征是对模型有益的,用这个和baseline评分的差值做为特征筛选的参考值选择特征)
from hypergbm import make_experiment
experiment = make_experiment(train, target, feature_reselection=True, \
feature_reselection_estimator_size=10, feature_reselection_threshold=1e-5)
'''
feature_reselection : bool, (default=True)
feature_reselection_estimator_size : int, (default=10)
The number of estimator to evaluate feature importance. Only valid when *feature_reselection* is True.
feature_reselection_threshold : float, (default=1e-5)
The threshold for feature selection. Features with importance below the threshold will be dropped. Only valid when *feature_reselection* is True.
'''
- 参考资料:https://zhuanlan.zhihu.com/p/349824150
伪标签(Pseudo-labeling)
主要应用在分类任务上,通过半监督学习的方法来增加更多的训练数据
from hypergbm import make_experiment
experiment = make_experiment(train, target=target, pseudo_labeling=True, pseudo_labeling_proba_threshold=0.8, pseudo_labeling_resplit=False)
'''
pseudo_labeling : bool, (default=False)
pseudo_labeling_proba_threshold : float, (default=0.8)
Confidence threshold of pseudo-label samples. Only valid when *pseudo_labeling* is True.
pseudo_labeling_resplit : bool, (default=False)
Whether to re-split the training set and evaluation set after adding pseudo-labeled data. If False, the
pseudo-labeled data is only appended to the training set. Only valid when *pseudo_labeling* is True.
'''
通过降采样进行预搜索
在进行模型参数优化搜索时
通常:使用全部训练数据进行模型训练 —— 数据量较大时训练耗时较长
hyperGBM:通过降采样减少参与模型训练的数据量,进行预搜索,以便在相同的时间内尝试更多的模型参数;然后从预搜索结果中 挑选表现较好的参数再利用全量数据进行训练和评估
from hypergbm import make_experiment
train_data=...
experiment = make_experiment(train_data,
down_sample_search=True,
down_sample_search_size=0.2,
...)
'''
down_sample_search_size:int 参与预搜索的样本数量
down_sample_search_time_limit:int, (default early_stopping_time_limit*0.33), 预搜索的时间限制。
down_sample_search_max_trials:int, (default max_trials*3), 预搜索的最大尝试次数。
'''
模型融合:GreedyEnsemble:
from hypergbm import make_experiment
experiment = make_experiment(train, target, ensemble_size=20)
'''
ensemble_size : int, (default=20, set 0 to disable ensemble)
'''
四种运行模式
- 单机模式:在一台服务器上运行,使用Pandas和Numpy数据结构
- 单机GPU模式:在一台服务器上运行,使用cuDF和cupy数据结构
- 单机分布式:在一台服务器上运行,使用Dask数据结构,在运行HyperGBM之前需要创建运行在单机上的Dask集群
- 多机分布式:在多台服务器上运行,使用Dask数据结构,在运行HyperGBM之前需要创建能管理多台服务器资源的Dask集群
P.S.:
-
支持命令行方式运行
-
”HyperGBM支持使用Dask进行分布式训练,在运行实验之前您需要部署Dask集群并初始化Dask客户端Client对象;如果您的训练数据是csv或parquet格式,而且数据文件的扩展名是“.csv”或“.parquet”的话,可以直接使用文件路径创建实验,make_experiment在检测到Dask环境是会自动将数据加载为Dask的DataFrame对象并进行搜索和训练。“
详见:https://hypergbm.readthedocs.io/zh_CN/latest/example_by_experiment.html -
“支持全Pipeline的GPU加速 包括所有的数据处理和模型训练环节,在我们的实验环境中可得到最多超过50倍的性能提升”
——HyperGBM利用NVIDIA RAPIDS中的 cuML 和 cuDF对数据处理进行加速,所以如果要利用GPU对HyperGBM进行加速的话,需要在运行HyperGBM之前安装cuML and cuDF这两个软件 -
对于hyperGBM的不同运行模式,功能特性支持稍有差异,
详见:https://hypergbm.readthedocs.io/zh_CN/latest/overview_features.html
参考资料
- https://hypergbm.readthedocs.io/zh_CN/latest/overview_about.html
- https://github.com/DataCanvasIO/HyperGBM















 397
397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









