







基于足迹矩阵的拟合度评估方法是一种便于理解的评估方法,下面我们将详细地介绍这一方法。
1.相关知识
我们在前面介绍Alpha Miner及其系列算法的时候层定义了四种关系:紧邻,因果,并行,无关,详细地介绍如下:
紧邻:x>y当且仅当存在一条轨迹使得活动x后面紧跟着y;
因果:x->y当且仅当x>y且非y>x;
并行:x||y当且仅当x>y且y>x;
无关:x#y当且仅当非x>y且非y>x.
在这四种关系的基础上我们介绍足迹矩阵。
2. 相关案例介绍
2.1 示例事件日志
给定一个事件日志L,包含的信息如下表所示,L中共有1391条轨迹,21条轨迹变体(不重复的轨迹数)。例如,在轨迹1=<a,c,d,e,h>中有455个案例,在轨迹2=<a,b,d,e,g>中有191个案例等。

2.2 示例流程模型
给定四个对应的流程模型,如下图所示,各Petri网模型的具体情况如下所示:

Petri网N1是对上述示例日志L应用基础α算法发现的流程模型;
Petri网N2相对于N1是一个顺序模型,需要在活动d前进行活动b或者活动c,有些示例日志L中的轨迹不能被表示;
Petri网N3中没有选择结构,即要求总是被拒绝,在示例日志L中的大部分轨迹不能被表示出来;
Petri网N4是一个“花型模型”的变体:只要求轨迹以a开始,以g或h结束,很明显,示例日志L中的所有轨迹都能够被N4表示。
3.基于足迹矩阵的拟合度评估方法
下表中展示了事件日志Lfull的足迹矩阵,该矩阵是由“直接跟随关系” >Lfull产生。显然,流程模型也有一个足迹:简单地产生一个完备的事件日志,即Play-out这个模型并记录执行序列。从足迹矩阵的角度来看,一个事件日志是完备的,当且仅当所有能够跟随在另一个活动之后的活动至少出现在日志中一次。将这个应用到第2节中的Petri网N1,产生相同的足迹矩阵(即下表),这说明事件日志Lfull和流程模型N1是“一致的”。
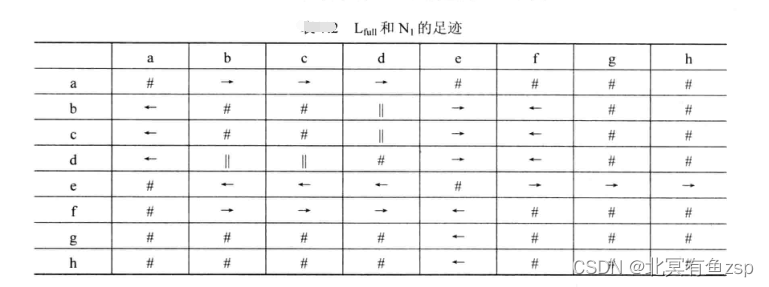
下表中现实了由工作流网N2产生的足迹矩阵,即Play-Out模型N2来记录一个完整的日志并且生成它的足迹。对比N1和N2两个足迹矩阵,可以发现两者存在如下差异如下表。
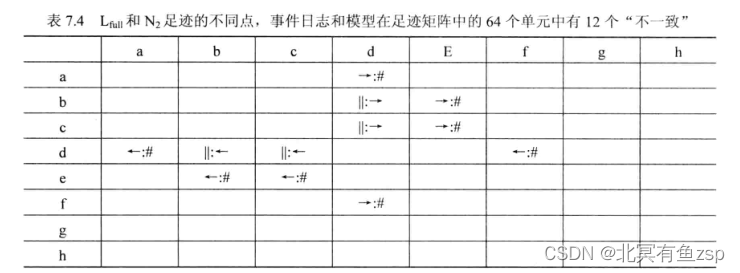
例如,a和d之间的关系从->变化到#。b和d之间的关系从||变为->。
可以从上表中量化事件日志和流程模型之间的合规性。比如,从上表中,对比事件日志Lfull和流程模型N2的不同之处,发现总共有64个单元中有12个是不同的,所以可以计算得到:
Lfull和N2基于足迹矩阵的合规性是:
Lfull和N1基于足迹矩阵的合规性是1.(因为两者的单元都相同)。
4.工具支持
(2)使用pm4py调用基于足迹矩阵算法的链接地址:
PM4Py - Process Mining for Python (fraunhofer.de)
from pm4py.algo.discovery.footprints import algorithm as footprints_discovery
fp_log = footprints_discovery.apply(log, variant=footprints_discovery.Variants.ENTIRE_EVENT_LOG)from pm4py.algo.discovery.footprints import algorithm as footprints_discovery
fp_trace_by_trace = footprints_discovery.apply(log, variant=footprints_discovery.Variants.TRACE_BY_TRACE)5.总结
基于足迹矩阵的优缺点如下:
(1)基于足迹的合规性分析仅仅在日志关于“直接跟随”关系>L是完备的时候才有意义;
(2)模型和事件日志都有足迹,所以我们除了对日志和模型之间的比较,还可以将其用于“日志与日志”、“模型与模型”的对比上;
(3)足迹仅仅是事件日志和模型的多个可能的特征中的一个。原则上任何时序属性都可以使用。除了“直接跟随”关系之外,“最终跟随”关系>>L也可以被使用。
参考文献:
《流程挖掘:业务过程的发现、合规和改进》,Wil van der Aalst著,王建民、闻立杰等译;
如需进行相关的了解或者交流,欢迎私信或者加入QQ群:




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











