









本节用于简单介绍pm4py的相关示例,给读者提供一个简单直观的认识。
目录
2.4.1 将pandas DataFrame存储为 csv 文件
2.4.2 将pandas DataFrame存储为 .xes 文件

1.理解流程挖掘
1.1 现代世界中的流程
绝大多数活跃在几乎任何领域的公司都会执行一个流程。 无论公司的核心业务是交付产品,例如制造汽车,烹饪美味的比萨饼等,还是提供服务,例如为您提供抵押贷款以购买梦想中的房屋,偿还保险索赔等,为了有效地交付您的产品/服务,流程都会被执行。 因此,一个自然的问题是:“什么是过程? 一般来说,流程概念有几个概念。 但是,在流程挖掘中,我们通常假设以下概念定义:
“流程代表我们为实现某个目标而执行的一系列活动。”
例如,考虑一下拐角处的汉堡餐厅,它也提供汉堡。 当你打电话给餐厅点你心爱的汉堡时,员工采取的第一个动作,让我们叫她露西,接你的电话,就是接你的订单。 假设你去吃一个美味的芝士汉堡和一罐苏打水。 露西在收银机中输入您的订单后,她会询问您的地址,并将其添加到订单中。 最后,她询问您喜欢的付款方式,然后为您提供交货前的粗略估计时间。 当露西打完电话后,她打印了你的订单并将其交给厨师,让我们叫他路易吉。 由于您打电话相对较早,Luigi 可以立即开始准备您的汉堡。 与此同时,露西从冰箱里拿出一罐苏打水,放在柜台上。 另一个客户打来一个新电话,她的处理方式与你的大致相同。 当路易吉吃完你的汉堡时,他把它滑进一个纸箱里,然后把盒子交给露西。 露西把订单装在一个袋子里。 然后她把装有汉堡和苏打水的袋子交给迈克,迈克用一辆花哨的电动自行车把你的订单送到你家。
在这个小示例中,假设我们对流程感兴趣,即为您的订单执行的活动集合。 根据我们刚才介绍的方案,步骤如下所示:
1.露西接受您的订单
2. 露西记下你的地址
3.露西记下您的首选付款方式
4. 路易吉准备你的汉堡
5.露西拿起你的汽水罐
6.路易吉把你的汉堡放在一个盒子里
7.露西包装您的订单
8.迈克交付您的订单
2.导入第一个事件日志
在本节中,我们将介绍如何在PM4Py中导入(和导出)事件数据。
2.1 文件类型:CSV 和 XES
为了支持不同流程挖掘工具和库之间的互操作性,使用两种标准数据格式来捕获事件日志,即逗号分隔值 (CSV) 文件和可扩展事件流 (XES) 文件。CSV 文件中的每一行都描述了发生的事件。这些列表示相同类型的数据,如示例中所示,例如,事件发生的情况、活动、时间戳、执行活动的资源等。XES 文件格式是一种基于 XML 的格式,允许我们描述流程行为。我们不会详细介绍XES文件的格式,想要了解的可以参考 https://www.xes-standard.org 。
本教程的其余部分中,我们将使用常用的虚拟示例事件日志来解释基本的流程挖掘操作。我们正在考虑的流程是与客户投诉处理相关的简化流程。该过程以及我们将要使用的事件数据如下所示。
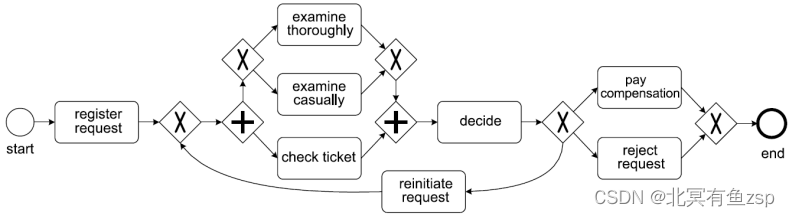
让我们开始吧!我们准备了一个小型示例事件日志,其中包含与图 1中的流程模型类似的行为。可以在此处找到示例事件日志。请下载文件并将其存储在计算机上的某个位置,例如,您的下载文件夹(在Windows上:这是“C:/Users/user_name/Dowloads”)。考虑图 2,其中我们描述了示例文件的前 25 行。
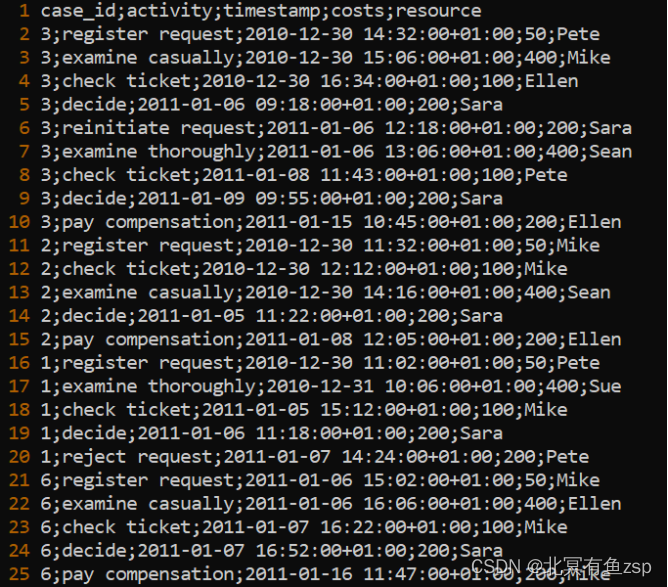
请注意,图 2 中描述的数据以文本格式描述了一个表。文件中的每一行对应于表中的一行。每当我们在一行上遇到“;”符号时,这意味着我们正在“输入”下一列。第一行(即行)指定每列的名称。观察到,在文件描述的数据表中,我们有 5 列,分别是:case_id、活动、时间戳、成本和资源。请注意,与我们之前的示例类似,第一列表示案例标识符,即允许我们识别在流程的哪个实例的上下文中记录了哪些活动。第二列显示已执行的活动。第三列显示记录活动的时间点。在此示例数据中,还存在其他信息。在这种情况下,第四列轨迹活动的成本,而第五行轨迹执行活动的资源。
在将示例文件加载到 PM4Py 之前,让我们简要看一下数据。请注意,第 2-10 行显示为案例标识符 3 标识的流程记录的事件。我们观察到,首先执行注册请求活动,然后是随意检查,检查票证,决定,重新发起请求,彻底检查票证,决定,最后是支付赔偿活动。请注意,实际上,在这种情况下,记录的流程实例的行为与图 1中描述的模型所述。
2.2 加载 CSV 文件
鉴于我们已经熟悉了事件日志和在 CSV 文件中表示事件日志的方法,是时候开始进行一些进程挖掘了!我们将加载事件数据,并且我们将计算事件日志中存在多少个案例,以及事件数。请注意,对于所有这些,我们有效地使用了一个名为 pandas 的第三方库。我们这样做是因为熊猫是加载/操作基于 csv 的数据的事实标准。因此,在PM4Py中实现的任何流程挖掘算法,使用事件日志作为输入,都可以直接与pandas文件一起使用!
示例 1:加载存储在 CSV 文件中的事件日志并计算文件中的事例数和事件数。在这个例子中,还没有使用PM4Py,它都是用pandas处理的。如果您自己运行代码,请确保将路径“C:/Users/demo/Downloads/running-example.csv”替换为计算机上包含正在运行的示例文件的相应路径。
import pandas
def import_csv(file_path):
event_log = pandas.read_csv(file_path, sep=';')
num_events = len(event_log)
num_cases = len(event_log.case_id.unique())
print("Number of events: {}\nNumber of cases: {}".format(num_events, num_cases))
if __name__ == "__main__":
import_csv("C:/Users/demo/Downloads/running-example.csv")快速浏览上面的示例代码。在第一行中,我们导入pandas。最后几行(包含 if 语句)确保代码在粘贴时自行运行(我们将在以后的示例中省略这些行)。脚本的核心是函数import_csv。作为输入参数,它需要 csv 文件的路径。该脚本使用 pandas read_csv函数来加载事件数据。为了计算事件的数量,我们只需查询数据框的长度,即通过调用 len(event_log)。为了计算事例数,我们使用内置的 pandas 函数返回case_id列的唯一值数,即 event_log.case_id.unique()。由于该函数返回一个包含列所有值的 pandas 内置数组对象,因此我们再次查询其长度。请注意,与编程时经常出现的情况一样,有多种方法可以根据给定的 CSV 文件计算上述示例统计信息。
现在我们已经加载了第一个事件日志,是时候将一些 PM4Py 放入混合物中了。假设我们不仅对事件和事例的数量感兴趣,而且还想弄清楚事件日志描述的跟踪中哪些活动首先发生,哪些活动最后发生。PM4Py为此具有特定的内置函数,即分别为get_start_activities()和get_end_activities()。考虑示例 2,其中我们提供了相应的代码。
示例 2:加载存储在 CSV 文件中的事件日志,并计算事件日志中跟踪的开始和结束活动。如果自己运行代码,请确保将文件路径指向计算机上包含正在运行的示例文件的相应路径。
import pandas
import pm4py
def import_csv(file_path):
event_log = pandas.read_csv(file_path, sep=';')
event_log = pm4py.format_dataframe(event_log, case_id='case_id', activity_key='activity', timestamp_key='timestamp')
start_activities = pm4py.get_start_activities(event_log)
end_activities = pm4py.get_end_activities(event_log)
print("Start activities: {}\nEnd activities: {}".format(start_activities, end_activities))
if __name__ == "__main__":
import_csv("csv_file.csv")请注意,我们现在导入pandas和pm4py。脚本的第一行再次将以 CSV 格式存储的事件日志加载为数据帧。第二行将事件数据表转换为 pm4py 中任何流程挖掘算法都可以使用的格式。也就是说,format_dataframe()-函数创建输入事件日志的副本,并将分配的列重命名为 pm4py 中使用的标准化列名。在我们的示例中,列case_id重命名为 case:concept:name,活动列重命名为 concept:name,时间戳列重命名为 time:timestamp。使用上述标准名称的根本原因主要与基于 XES(我们稍后将介绍的另一种文件格式)遗留有关。因此,建议始终导入基于 csv 的日志,如下所示。
请注意,在此示例中,参数的值(即 sep、case_id、activity_key 和 timestamp_key)取决于输入数据。若要获取事件日志中任何轨迹中首先和最后发生的活动,我们调用 pm4py.get_start_activities(event_log) 和 pm4py.get_end_activities(event_log) 函数。这些函数返回一个字典,其中包含作为键的活动,以及事件日志中的观察次数(即,它们首先出现、分别是最后出现的轨迹数)。
PM4Py利用内置的pandas函数自动检测输入数据中时间戳的格式。但是,pandas会孤立地查看每行中的时间戳值。在某些情况下,这可能会导致问题。例如,如果提供的值是 2020-01-18,即首先是年份,然后是月份,然后是日期的日期,在某些情况下,值 2020-02-01 可能会被错误地解释为 2 月 1 日,即而不是 <> 月 <> 日。为了缓解这个问题,可以为 format_dataframe() 方法提供一个额外的参数,即 timest_format 参数。默认的 Python 时间戳格式代码可用于提供时间戳格式。在此示例中,时间戳格式为 %Y-%m-%d %H:%M:%S%z。一般来说,我们建议指定时间戳格式!
2.3 加载 XES 文件
除了CSV文件之外,事件数据也可以以基于XML的格式存储,即XES文件。在 XES 文件中,我们可以描述包含关系,即日志包含许多轨迹,而这些轨迹又包含多个事件。此外,允许对象(即日志、轨迹或事件)具有属性。优点是,对于日志或轨迹而言,某些常量的数据属性可以存储在该级别。例如,假设我们只知道案例的总成本,而不是单个事件的成本。如果我们想将这些信息存储在 CSV 文件中,我们要么需要复制这些信息(即我们只能将数据存储在直接引用事件的行中),要么,我们需要明确定义某些列只获取一次值,即引用案例级属性。XES标准更自然地支持此类信息的存储。
考虑图 3,其中我们描述了以 .xes 文件格式存储的运行示例数据的快照。完整的文件可以在这里下载。
请注意,编号为 1 的轨迹(由第 9 行上的 [string key=“concept:name”]-标记反映)是此事件日志中记录的第一个轨迹。轨迹的第一个事件表示 Pete 执行的“注册请求”活动。第二个事件是“彻底检查”活动,由苏等执行。我们不会在这里详细阐述XES标准,即我们参考XES主页,以及我们关于导入XES的视频教程以获取更多信息。
导入 XES 文件相当简单。PM4Py有一个特殊的read_xes()函数,可以解析给定的xes文件并将其加载到PM4Py中,即作为事件日志对象。请考虑以下代码片段,其中演示如何导入 XES 事件日志。与前面的示例一样,该脚本输出可以开始和结束轨迹的活动。
def import_xes(file_path):
event_log = pm4py.read_xes(file_path)
start_activities = pm4py.get_start_activities(event_log)
end_activities = pm4py.get_end_activities(event_log)
print("Start activities: {}\nEnd activities: {}".format(start_activities, end_activities))
if __name__ == "__main__":
import_xes("C:/Users/demo/Downloads/running-example.xes")2.4 导出事件数据
现在我们可以将事件数据导入 PM4Py,让我们看一下相反的情况,即导出事件数据。导出事件日志可能非常有用,例如,我们可能希望将.csv文件转换为 .xes 文件,或者我们可能希望过滤掉某些(嘈杂)情况并保存筛选的事件日志。与导入一样,可以通过两种方式导出事件数据,即导出为 csv(使用 pandas)和导出为 xes。在接下来的部分中,我们将展示如何将存储为 pandas 数据帧的事件日志导出为 csv 文件,将 pandas 数据帧导出为 xes 文件,将 PM4Py 事件日志对象导出为 csv 文件,最后将 PM4Py 事件日志对象导出为 xes 文件。
2.4.1 将pandas DataFrame存储为 csv 文件
存储表示为 pandas 数据帧的事件日志非常简单,即我们可以直接使用 pandas DataFrame 对象的 to_csv 函数。请考虑以下示例代码片段,其中我们展示了此功能。
请注意,示例代码将正在运行的示例 csv 文件导入为 pandas 数据框,并将其导出到位置为“C:/Users/demo/Desktop/running-example-exported.csv”的 csv 文件。请注意,默认情况下,熊猫使用“,”符号而不是“;”-符号作为列分隔符。
import pandas as pd
if __name__ == "__main__":
event_log = pm4py.format_dataframe(pd.read_csv('C:/Users/demo/Downloads/running-example.csv', sep=';'), case_id='case_id',
activity_key='activity', timestamp_key='timestamp')
event_log.to_csv('C:/Users/demo/Desktop/running-example-exported.csv')2.4.2 将pandas DataFrame存储为 .xes 文件
也可以将pandas DataFrame存储到 xes 文件中。这只需通过调用 pm4py.write_xes() 函数来完成。您可以将数据帧作为输入参数传递给函数,即 pm4py 在将数据帧写入磁盘之前处理数据帧到事件日志对象的内部转换。请注意,此构造仅在格式化DataFrame时才有效,即如前面导入 CSV 部分中突出显示的那样。
import pandas
import pm4py
if __name__ == "__main__":
event_log = pm4py.format_dataframe(pandas.read_csv('C:/Users/demo/Downloads/running-example.csv', sep=';'), case_id='case_id',
activity_key='activity', timestamp_key='timestamp')
pm4py.write_xes(event_log, 'C:/Users/demo/Desktop/running-example-exported.xes')2.4.3 将事件日志对象存储为 .csv 文件
在某些情况下,我们可能希望将事件日志对象(例如,通过导入 .xes 文件获得的对象)存储为 csv 文件。例如,某些(商业)流程挖掘工具仅支持 csv 导入。为此,pm4py提供了转换功能,允许您将事件日志对象转换为数据帧,随后可以使用pandas导出数据帧。
import pm4py
if __name__ == "__main__":
event_log = pm4py.read_xes('C:/Users/demo/Downloads/running-example.xes')
df = pm4py.convert_to_dataframe(event_log)
df.to_csv('C:/Users/demo/Desktop/running-example-exported.csv')2.4.4 将事件日志对象存储为 .xes 文件
将事件日志对象存储为 .xes 文件非常简单。在 pm4py 中,write_xes() 方法允许我们这样做。请考虑下面的简单示例脚本,其中我们展示了此功能的示例。
import pm4py
if __name__ == "__main__":
event_log = pm4py.read_xes(C:/Users/demo/Downloads/running-example.xes)
pm4py.write_xes(event_log, 'C:/Users/demo/Desktop/running-example-exported.xes')2.5 预构建的事件日志筛选器
PM4Py中有各种预构建的过滤器,这使得通常需要的过程挖掘过滤功能变得更加容易。在即将发布的列表中,我们将简要概述这些功能。我们描述了如何调用它们,它们的主要输入参数和它们的返回对象。
-
filter_start_activities(log, activities, retain=True);此函数根据需要在轨迹起点出现的一组给定输入活动名称筛选给定的事件日志对象(数据帧或 PM4Py 事件日志对象)。如果将 retain 设置为 False,则会删除包含任何指定活动的所有轨迹作为其第一个事件。
-
filter_end_activities(log, activities, retain=True);与启动活动筛选器类似的功能。但是,在这种情况下,筛选器将应用于轨迹末尾发生的活动。
-
filter_event_attribute_values(log, attribute_key, values, level=“case”, retain=True);根据事件属性筛选事件日志(数据框或 PM4Py 事件日志对象)。attribute_key是一个字符串,表示要过滤的属性键,values 参数允许您指定一组允许的值。如果 level 参数设置为“case”,则保留至少包含一个与属性-值组合匹配的事件的任何跟踪。如果级别参数值设置为“event”,则仅保留描述指定值的事件。将“保留”设置为“False”将反转筛选器。
-
filter_trace_attribute_values(log, attribute_key, values, retain=True);仅保留(如果保留设置为 False,则删除)具有所提供attribute_key的属性值并在相应值集合中列出的跟踪。
-
filter_variants(log, variants, retain=True);保留与特定活动执行序列(即称为变体)相对应的跟踪。例如,在大型日志中,我们希望保留描述执行序列“a”、“b”、“c”的所有跟踪。变量参数是活动名称列表的集合。
-
filter_directly_follows_relation(log, relations, retain=True);此函数筛选包含指定“直接跟随关系”的所有轨迹。这样的关系只是一对活动,例如,('a','b') s.t.,'a'后面紧跟着'b'。例如,轨迹<'a','b','c','d'>包含直接跟随对('a','b')、('b','c')和('c','d')。relations 参数是一组元组,包含活动名称。retain 参数允许我们表达是否要保留或删除数学跟踪。
-
filter_eventually_follows_relation(log, relations, retain=True)这个函数允许我们在直接跟随关系的泛化上匹配轨迹,即允许在输入关系之间发生任意数量的活动。例如,当我们用关系('a','b')调用函数时,我们在某个点观察到活动'a'的任何轨迹,后面跟着活动'b',在某个点再次跟随,都遵循这个过滤器。例如,跟踪<'a','b','c','d'>包含最终跟随对('a','b')、('a','c')('a','d')、('b','c')、('b','d')和('c','d')。同样,relations 参数是一组元组,包含活动名称,保留参数允许我们表达是否要保留或删除匹配的跟踪。
-
filter_time_range(log, dt1, dt2, mode='events');根据给定的时间范围(由时间戳 dt1 和 dt2 定义)筛选事件日志。时间戳的格式应为 datetime.datetime。过滤器有三种模式(默认为:“事件”):
-
“events”;保留在提供的时间范围内的所有事件。删除筛选的事件日志中的任何空轨迹;
-
“traces_contained”;保留在给定时间范围内完全“包含”的任何轨迹。例如,如果有兴趣保留特定日/月/年的所有完整轨迹,则此筛选器非常有用。
-
“traces_intersecting”;保留至少有一个事件落入给定时间范围的任何轨迹。
-
请考虑下面的示例代码,其中我们使用正在运行的示例事件日志提供了上述筛选函数的各种示例应用程序。尝试复制粘贴您自己的环境中的每一行,并使用生成的筛选事件日志,以更好地了解每个筛选器的功能。请注意,下面显示的所有函数在提供数据帧作为输入时也有效!
import pm4py
import datetime as dt
if __name__ == "__main__":
log = pm4py.read_xes('C:/Users/demo/Downloads/running-example.xes')
filtered = pm4py.filter_start_activities(log, {'register request'})
filtered = pm4py.filter_start_activities(log, {'register request TYPO!'})
filtered = pm4py.filter_end_activities(log, {'pay compensation'})
filtered = pm4py.filter_event_attribute_values(log, 'org:resource', {'Pete', 'Mike'})
filtered = pm4py.filter_event_attribute_values(log, 'org:resource', {'Pete', 'Mike'}, level='event')
filtered = pm4py.filter_trace_attribute_values(log, 'concept:name', {'3', '4'})
filtered = pm4py.filter_trace_attribute_values(log, 'concept:name', {'3', '4'}, retain=False)
filtered = pm4py.filter_variants(log, [
['register request', 'check ticket', 'examine casually', 'decide', 'pay compensation']])
filtered = pm4py.filter_variants(log, [
['register request', 'check ticket', 'examine casually', 'decide', 'reject request']])
filtered = pm4py.filter_directly_follows_relation(log, [('check ticket', 'examine casually')])
filtered = pm4py.filter_eventually_follows_relation(log, [('examine casually', 'reject request')])
filtered = pm4py.filter_time_range(log, dt.datetime(2010, 12, 30), dt.datetime(2010, 12, 31), mode='events')
filtered = pm4py.filter_time_range(log, dt.datetime(2010, 12, 30), dt.datetime(2010, 12, 31),
mode='traces_contained')
filtered = pm4py.filter_time_range(log, dt.datetime(2010, 12, 30), dt.datetime(2010, 12, 31),
mode='traces_intersecting')3. 发现您的第一个流程模型
由于我们已经研究了流程挖掘和事件数据处理和处理的基本概念知识,因此我们专注于流程发现。如前所述,目标是发现,即主要是完全自动化和算法化的,一个准确描述流程的流程模型,即在事件数据中观察到的流程模型。例如,给定运行示例事件数据,我们的目标是发现用于解释运行示例进程行为的流程模型,即图 3。本节简要说明在应用不同过程发现算法时PM4Py中存在哪些建模形式。其次,我们概述了实现的进程发现算法、它们的输出类型以及如何调用它们。最后,我们讨论了在实践中应用过程发现的挑战。
3.1 获取流程模型
PM4Py 目前支持三种不同的流程建模符号。这些符号是:BPMN,流程树和Petri网。与BPMN相比,Petri网是一种更数学的建模表示。通常,与BPMN模型相比,Petri网的行为更难理解。然而,由于它们的数学性质,Petri网通常不那么模糊(即,不可能混淆其描述的行为)。过程树表示Petri网的严格子集,并以分层方式描述流程行为。在本教程中,我们将主要关注 BPMN 模型和流程树。有关Petri网及其在(业务)流程建模中的应用(从“工作流”角度)的更多信息,请参阅本文。
有趣的是,PM4Py中实现的算法都没有直接发现BPMN模型。但是,任何流程树都可以很容易地转换为BPMN模型。由于我们已经讨论了 BPMN 模型的基本运算符,我们将从发现流程树开始,并将其转换为 BPMN 模型。稍后,我们将研究“底层”进程树。我们将要使用的算法是“inductive Miner”;有关算法(内部工作原理)的更多详细信息,请参阅本演示文稿和本文。请考虑以下代码片段。我们基于运行的示例事件数据集,使用Inductive Miner发现了一个 BPMN 模型(使用从流程树到 BPMN 的转换)。
import pm4py
if __name__ == "__main__":
log = pm4py.read_xes('C:/Users/demo/Downloads/running-example.xes')
process_tree = pm4py.discover_process_tree_inductive(log)
bpmn_model = pm4py.convert_to_bpmn(process_tree)
pm4py.view_bpmn(bpmn_model)请注意,生成的流程模型如下图所示:

观察一下,我们发现的流程模型确实和我们之前使用的模型是同一个模型,即如图3所示。
如前所述,此示例中使用的算法实际上发现了一个流程树。从数学上讲,这样的流程树是用“控制流”信息注释的根树。我们将首先使用以下代码片段根据运行示例发现流程树,然后简要分析模型。
import pm4py
if __name__ == "__main__":
log = pm4py.read_xes('C:/Users/demo/Downloads/running-example.xes')
process_tree = pm4py.discover_process_tree_inductive(log)
pm4py.view_process_tree(process_tree)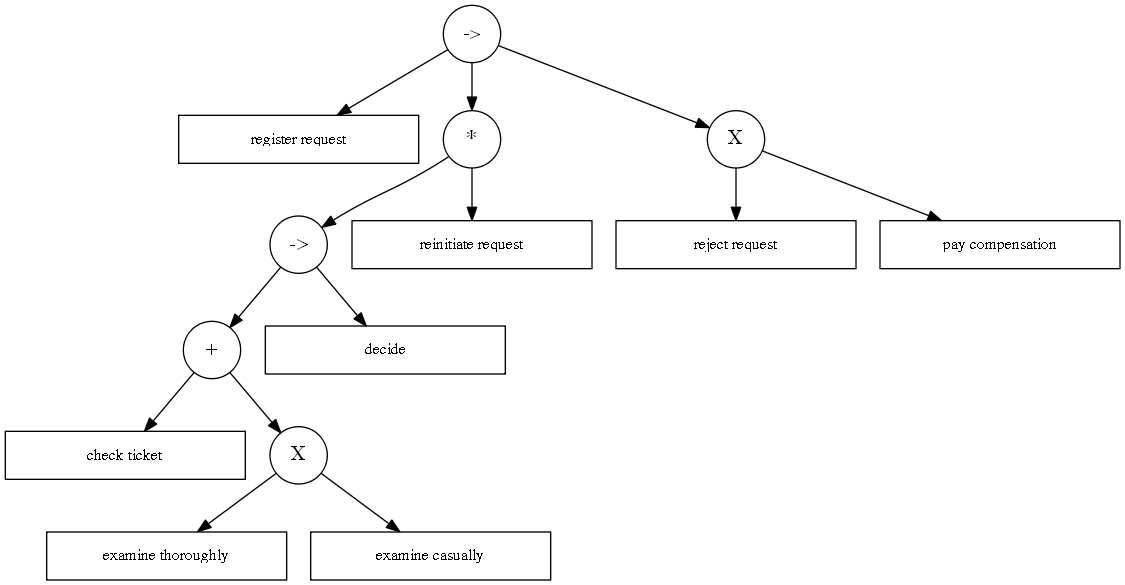
我们从上到下对流程树进行建模。第一个圆圈,即进程树的“根”,描述一个“->”符号。这意味着,当进一步向下滚动时,模型描述的过程从左到右执行根的“子项”。因此,首先执行“注册请求”,然后执行带有“*”符号的圆形节点,最后执行带有“X”符号的节点。带有“*”的节点表示“重复行为”,即重复行为的可能性。当进一步向下滚动时,始终执行“*”运算符最左侧的“子树”,最右侧的子级(在本例中为“重新发起请求”)触发最左侧子级的重复执行。请注意,这与我们之前看到的流程模型一致,即“重新发起请求”活动允许我们重复有关检查和检查工单的行为。当我们在 '*' 运算符的子树中进一步向下移动时,我们再次观察到一个 '->' 节点。因此,首先执行最左边的子项,然后执行最右边的子项(“决定”)。“->”节点最左侧的子节点有一个“+”符号。这表示并发行为;因此,它的子级可以同时执行或按任何顺序执行。它最左边的子项是“检查票证”活动。它最右边的子节点是带有“X”符号的节点(就像树根的最右边的子节点一样)。这代表了一种排他性的选择,即其中一个孩子被处决(“随意检查”或“彻底检查”)。请注意,流程树描述的行为与前面显示的 BPMN 模型完全相同。
3.2 获取流程图
许多商业流程挖掘解决方案不提供对发现流程模型的扩展支持。通常,作为流程的主要可视化,使用流程图。流程图包含活动以及它们之间的连接(通过弧形)。两个活动之间的联系通常意味着存在某种形式的优先关系。在最简单的形式中,它意味着“源”活动直接在“目标”活动之前。让我们快速看一个具体的例子!考虑以下代码片段,其中我们学习了基于“直接跟随图”(DFG)的流程图:
import pm4py
if __name__ == "__main__":
log = pm4py.read_xes('C:/Users/demo/Downloads/running-example.xes')
dfg, start_activities, end_activities = pm4py.discover_dfg(log)
pm4py.view_dfg(dfg, start_activities, end_activities)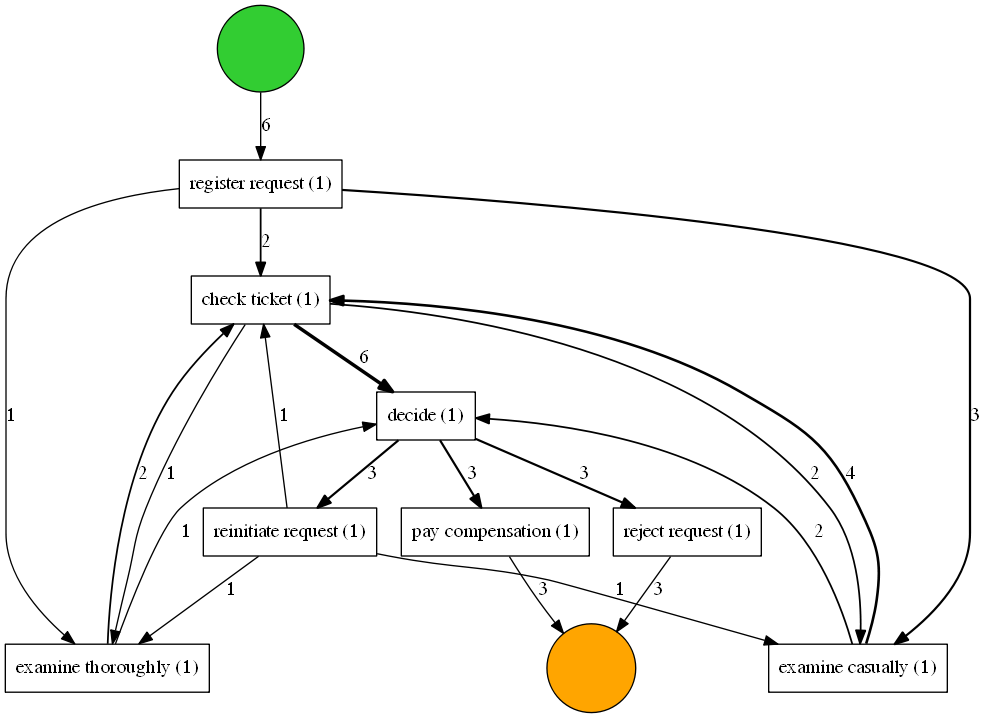
pm4py.discover_dfg(log) 函数返回三元组。第一个结果,即在本例中称为dfg,是一个字典,将直接跟随彼此的活动对映射到相应观测值的数量。第二个和第三个参数是在事件日志中观察到的开始和结束活动(再次是计数器)。在可视化中,绿色圆圈表示任何观察到的流程实例的开始。橙色圆圈表示观察到的流程实例的结束。在 6 种情况下,注册请求是观察到的第一个活动(由标有值 6 的弧表示)。在事件日志中,检查票证活动直接在注册请求活动之后执行。彻底检查活动是注册后一次,随意检查后3次。请注意,实际上,注册活动之后总共有 6 个不同的事件,即运行的示例事件日志中有 6 个跟踪。但是,请注意,与事件日志中的事例数相比,可观察到的关系通常要多得多。即使使用这种简单的事件数据,基于 DFG 的流程图也比之前学习的流程模型复杂得多。此外,根据流程图推断流程的实际执行要困难得多。因此,在使用流程图时,在尝试理解实际流程时应该非常小心。
在PM4Py中,我们还实现了启发式矿工,这是一种更先进的流程图发现算法,与其基于DFG的替代方案相比。我们不会在这里详细介绍算法,但是,在基于 HM 的流程图中,活动之间的弧表示观察到的并发性。例如,该算法能够检测到票证检查和检查是并发的。因此,这些活动将不会在流程图中连接。因此,与基于 DFG 的流程图相比,基于 HM 的流程图通常更简单。
import pm4py
if __name__ == "__main__":
log = pm4py.read_xes('C:/Users/demo/Downloads/running-example.xes')
map = pm4py.discover_heuristics_net(log)
pm4py.view_heuristics_net(map)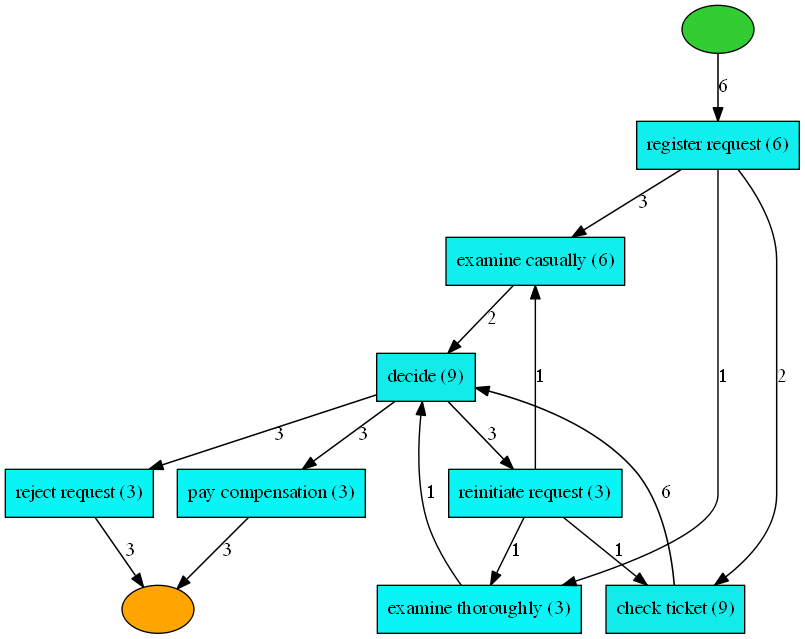
如需了解更多,欢迎加入流程挖掘交流群QQ:671290481.


















 507
507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











