







鉴于有很多人来询问我数据集(我翻箱倒柜找了一下= =放在这里了,有需要自取)
链接:https://pan.baidu.com/s/1Fjgs_MMiIDO9-wFKs6QJSg
提取码:1efk
复制这段内容后打开百度网盘手机App,操作更方便哦
一、实验目的
考核各位同学使用较小的模型和小规模的训练数据下的模型设计和训练的能力。需要同学充分利用迁移学习等方法,以解决训练数据少的问题,同时需要思考和解决深度学习中过拟合的问题。所提供的场景定义为比较单一的车辆场景,一定程度上平衡了难度系数。
二、实验内容
使用提供的2000张标注了的车辆场景分类信息的高分辨率图片,建立并训练模型,并将此模型运用于测试数据集的图像分类标注。
标签信息:
0,巴士,bus
1,出租车,taxi
2,货车,truck
3,家用轿车,family sedan
4,面包车,minibus
5,吉普车,jeep
6,运动型多功能车,SUV
7,重型货车,heavy truck
8,赛车,racing car
9,消防车,fire engine
三、实验内容
1、实验平台:
WIN10+annaconda+tensorflow
安装教程:https://blog.csdn.net/qq_30611601/article/details/79067982
2、实验流程:
代码利用卷积网络完成一个图像分类的功能。训练完成后,模型保存在model文件中,可直接使用模型进行线上分类。同一个代码包括了训练和测试阶段,通过修改train参数为True和False控制训练和测试。显示实验结果,再根据结果做微小调整。
数据处理->导入相关库->配置信息->数据读取->定义placeholder(容器)->定义卷积网络(卷积和Pooling部分)->定义全连接部分->定义损失函数和优化器(这里有一个技巧,没有必要给Optimizer传递平均的损失,直接将未平均的损失函数传给Optimizer即可)->定义模型保存器/载入器->进入训练/测试执行阶段
3、实验代码
整体代码参考的如下网址:
https://blog.csdn.net/wills798/article/details/80890990
需要修改的两点:
1、由于参考代码训练的是32X32图片,而且图片名字也是标签名+序号,所以我们想要直接用的话,就必须做修改工作
分为:rename、resize两个步骤
2、参考代码训练和测试的数据集是同一个,而我们这里有区分,所以要把源代码分为train.py,test.py
修改图片:
在项目根目录新建以下空文件夹
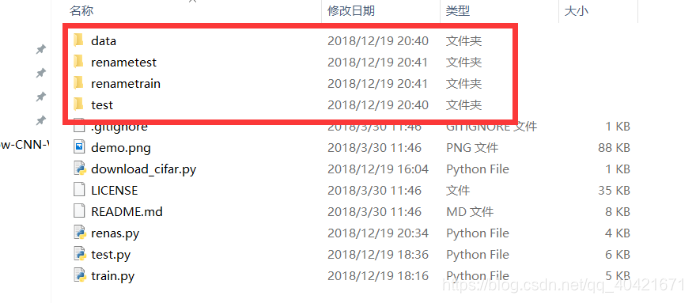
移入源数据(这里的测试集用的是val,用test还要修改代码懒得弄)
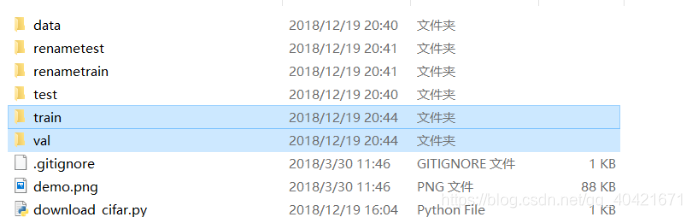
运行renas.py(注意,这里运行一次就可以了,因为运行完,默认将train内源数据删除)

运行结果:
代码:
#coding=utf-8
from PIL import Image
import os
import os.path
import glob
def rename(rename_path,outer_path,folderlist):
#列举文件夹
for folder in folderlist:
if os.path.basename(folder)=='bus':
foldnum = 0
elif os.path.basename(folder)=='taxi':
foldnum = 1
elif os.path.basename(folder)=='truck':
foldnum = 2
elif os.path.basename(folder)=='family sedan':
foldnum = 3
elif os.path.basename(folder)=='minibus':
foldnum = 4
elif os.path.basename(folder)=='jeep':
foldnum = 5
elif os.path.basename(folder)=='SUV':
foldnum = 6
elif os.path.basename(folder)=='heavy truck':
foldnum = 7
elif os.path.basename(folder)=='racing car':
foldnum = 8
elif os.path.basename(folder)=='fire engine':
foldnum = 9
inner_path = os.path.join(outer_path, folder)
total_num_folder = len(folderlist) #文件夹的总数
# print 'total have %d folders' % (total_num_folder) #打印文件夹的总数
filelist = os.listdir(inner_path) #列举图片
i = 0
for item in filelist:
total_num_file = len(filelist) #单个文件夹内图片的总数
if item.endswith('.jpg'):
src = os.path.join(os.path.abspath(inner_path), item) #原图的地址
dst = os.path.join(os.path.abspath(rename_path), str(foldnum) + '_' + str(i) + '.jpg') #新图的地址(这里可以把str(folder) + '_' + str(i) + '.jpg'改成你想改的名称)
try:
os.rename(src, dst)
# print 'converting %s to %s ...' % (src, dst)
i += 1
except:
continue
#训练集
rename_path1 = 'E:/Tensorflow-CNN-VehicleIdentification/renametrain'
outer_path1 = 'E:/Tensorflow-CNN-VehicleIdentification/train'
folderlist1 = os.listdir(r"E:/Tensorflow-CNN-VehicleIdentification/train")
rename(rename_path1,outer_path1,folderlist1)
print("train totally rename ! ! !")
#测试集
rename_path2 = 'E:/Tensorflow-CNN-VehicleIdentification/renametest'
outer_path2 = 'E:/Tensorflow-CNN-VehicleIdentification/val'
folderlist2 = os.listdir(r"E:/Tensorflow-CNN-VehicleIdentification/val")
rename(rename_path2,outer_path2,folderlist2)
print("test totally rename ! ! !")
#修改图片尺寸
def convertjpg(jpgfile,outdir,width=32,height=32):
img=Image.open(jpgfile)
img=img.convert('RGB')
img.save(os.path.join(outdir,os.path.basename(jpgfile)))
new_img=img.resize((width,height),Image.BILINEAR)
new_img.save(os.path.join(outdir,os.path.basename(jpgfile)))
#训练集
for jpgfile in glob.glob("E:/Tensorflow-CNN-VehicleIdentification/renametrain/*.jpg"):
convertjpg(jpgfile,"E:/Tensorflow-CNN-VehicleIdentification/data")
print("train totally resize ! ! !")
#测试集
for jpgfile in glob.glob("E:/Tensorflow-CNN-VehicleIdentification/renametest/*.jpg"):
convertjpg(jpgfile,"E:/Tensorflow-CNN-VehicleIdentification/test")
print("test totally resize ! ! !")
修改源代码:
train.py
#coding=utf-8
import os
#图像读取库
from PIL import Image
#矩阵运算库
import numpy as np
import tensorflow as tf
# 数据文件夹
data_dir = "E:/Tensorflow-CNN-VehicleIdentification/data"
# 训练还是测试True False
train = True
# 模型文件路径
model_path = "model/image_model"
# 从文件夹读取图片和标签到numpy数组中
# 标签信息在文件名中,例如1_40.jpg表示该图片的标签为1
def read_data(data_dir):
datas = []
labels = []
fpaths = []
for fname in os.listdir(data_dir):
fpath = os.path.join(data_dir, fname)
fpaths.append(fpath)
image = Image.open(fpath)
data = np.array(image) / 255.0
label = int(fname.split("_")[0])
datas.append(data)
labels.append(label)
datas = np.array(datas)
labels = np.array(labels)
print("shape of datas: {}\tshape of labels: {}".format(datas.shape, labels.shape))
return fpaths, datas, labels
fpaths, datas, labels = read_data(data_dir)
# 计算有多少类图片
num_classes = len(set(labels))
# 定义Placeholder,存放输入和标签
datas_placeholder = tf.placeholder(tf.float32, [None, 32, 32, 3])
labels_placeholder = tf.placeholder(tf.int32, [None])
# 存放DropOut参数的容器,训练时为0.25,测试时为0
dropout_placeholdr = tf.placeholder(tf.float32)
# 定义卷积层, 20个卷积核, 卷积核大小为5,用Relu激活
conv0 = tf.layers.conv2d(datas_placeholder, 20, 5, activation=tf.nn.relu)
# 定义max-pooling层,pooling窗口为2x2,步长为2x2
pool0 = tf.layers.max_pooling2d(conv0, [2, 2], [2, 2])
# 定义卷积层, 40个卷积核, 卷积核大小为4,用Relu激活
conv1 = tf.layers.conv2d(pool0, 40, 4, activation=tf.nn.relu)
# 定义max-pooling层,pooling窗口为2x2,步长为2x2
pool1 = tf.layers.max_pooling2d(conv1, [2, 2], [2, 2])
# 定义卷积层, 60个卷积核, 卷积核大小为3,用Relu激活
conv2 = tf.layers.conv2d(pool0, 60, 3, activation=tf.nn.relu)
# 定义max-pooling层,pooling窗口为2x2,步长为2x2
pool2 = tf.layers.max_pooling2d(conv2, [2, 2], [2, 2])
# 将3维特征转换为1维向量
flatten = tf.layers.flatten(pool2)
# 全连接层,转换为长度为100的特征向量
fc = tf.layers.dense(flatten, 400, activation=tf.nn.relu)
# 加上DropOut,防止过拟合
dropout_fc = tf.layers.dropout(fc, dropout_placeholdr)
# 未激活的输出层
logits = tf.layers.dense(dropout_fc, num_classes)
predicted_labels = tf.arg_max(logits, 1)
# 利用交叉熵定义损失
losses = tf.nn.softmax_cross_entropy_with_logits(
labels=tf.one_hot(labels_placeholder, num_classes),
logits=logits
)
# 平均损失
mean_loss = tf.reduce_mean(losses)
# 定义优化器,指定要优化的损失函数
optimizer = tf.train.AdamOptimizer(learning_rate=1e-2).minimize(losses)
n=0
# 用于保存和载入模型
saver = tf.train.Saver()
with tf.Session() as sess:
if train:
print("训练模式")
# 如果是训练,初始化参数
sess.run(tf.global_variables_initializer())
# 定义输入和Label以填充容器,训练时dropout为0.25
train_feed_dict = {
datas_placeholder: datas,
labels_placeholder: labels,
dropout_placeholdr: 0.5
}
for step in range(150):
_, mean_loss_val = sess.run([optimizer, mean_loss], feed_dict=train_feed_dict)
if step % 10 == 0:
print("step = {}\tmean loss = {}".format(step, mean_loss_val))
saver.save(sess, model_path)
print("训练结束,保存模型到{}".format(model_path))
else:
print("测试模式")
# 如果是测试,载入参数
saver.restore(sess, model_path)
print("从{}载入模型".format(model_path))
# label和名称的对照关系
label_name_dict = {
0: "巴士",
1: "出租车",
2: "货车",
3: "家用轿车",
4: "面包车",
5: "吉普车",
6: "运动型多功能车",
7: "重型货车",
8: "赛车",
9: "消防车"
}
# 定义输入和Label以填充容器,测试时dropout为0
test_feed_dict = {
datas_placeholder: datas,
labels_placeholder: labels,
dropout_placeholdr: 0
}
predicted_labels_val = sess.run(predicted_labels, feed_dict=test_feed_dict)
# 真实label与模型预测label
for fpath, real_label, predicted_label in zip(fpaths, labels, predicted_labels_val):
# 将label id转换为label名
real_label_name = label_name_dict[real_label]
predicted_label_name = label_name_dict[predicted_label]
print("{}\t{} => {}".format(fpath, real_label_name, predicted_label_name))
test.py
#coding=utf-8
import os
#图像读取库
from PIL import Image
#矩阵运算库
import numpy as np
import tensorflow as tf
# 数据文件夹
data_dir = "E:/Tensorflow-CNN-VehicleIdentification/test"
# 训练还是测试True False
train = False
# 模型文件路径
model_path = "model/image_model"
# 从文件夹读取图片和标签到numpy数组中
# 标签信息在文件名中,例如1_40.jpg表示该图片的标签为1
def read_data(data_dir):
datas = []
labels = []
fpaths = []
for fname in os.listdir(data_dir):
fpath = os.path.join(data_dir, fname)
fpaths.append(fpath)
image = Image.open(fpath)
data = np.array(image) / 255.0
label = int(fname.split("_")[0])
datas.append(data)
labels.append(label)
datas = np.array(datas)
labels = np.array(labels)
print("shape of datas: {}\tshape of labels: {}".format(datas.shape, labels.shape))
return fpaths, datas, labels
fpaths, datas, labels = read_data(data_dir)
# 计算有多少类图片
num_classes = len(set(labels))
# 定义Placeholder,存放输入和标签
datas_placeholder = tf.placeholder(tf.float32, [None, 32, 32, 3])
labels_placeholder = tf.placeholder(tf.int32, [None])
# 存放DropOut参数的容器,训练时为0.25,测试时为0
dropout_placeholdr = tf.placeholder(tf.float32)
# 定义卷积层, 20个卷积核, 卷积核大小为5,用Relu激活
conv0 = tf.layers.conv2d(datas_placeholder, 20, 5, activation=tf.nn.relu)
# 定义max-pooling层,pooling窗口为2x2,步长为2x2
pool0 = tf.layers.max_pooling2d(conv0, [2, 2], [2, 2])
# 定义卷积层, 40个卷积核, 卷积核大小为4,用Relu激活
conv1 = tf.layers.conv2d(pool0, 40, 4, activation=tf.nn.relu)
# 定义max-pooling层,pooling窗口为2x2,步长为2x2
pool1 = tf.layers.max_pooling2d(conv1, [2, 2], [2, 2])
# 定义卷积层, 60个卷积核, 卷积核大小为3,用Relu激活
conv2 = tf.layers.conv2d(pool0, 60, 3, activation=tf.nn.relu)
# 定义max-pooling层,pooling窗口为2x2,步长为2x2
pool2 = tf.layers.max_pooling2d(conv2, [2, 2], [2, 2])
# 将3维特征转换为1维向量
flatten = tf.layers.flatten(pool2)
# 全连接层,转换为长度为100的特征向量
fc = tf.layers.dense(flatten, 400, activation=tf.nn.relu)
# 加上DropOut,防止过拟合
dropout_fc = tf.layers.dropout(fc, dropout_placeholdr)
# 未激活的输出层
logits = tf.layers.dense(dropout_fc, num_classes)
predicted_labels = tf.arg_max(logits, 1)
# 利用交叉熵定义损失
losses = tf.nn.softmax_cross_entropy_with_logits(
labels=tf.one_hot(labels_placeholder, num_classes),
logits=logits
)
# 平均损失
mean_loss = tf.reduce_mean(losses)
# 定义优化器,指定要优化的损失函数
optimizer = tf.train.AdamOptimizer(learning_rate=1e-2).minimize(losses)
# 用于保存和载入模型
saver = tf.train.Saver()
with tf.Session() as sess:
if train:
print("训练模式")
# 如果是训练,初始化参数
sess.run(tf.global_variables_initializer())
# 定义输入和Label以填充容器,训练时dropout为0.25
train_feed_dict = {
datas_placeholder: datas,
labels_placeholder: labels,
dropout_placeholdr: 0.5
}
for step in range(150):
_, mean_loss_val = sess.run([optimizer, mean_loss], feed_dict=train_feed_dict)
if step % 10 == 0:
print("step = {}\tmean loss = {}".format(step, mean_loss_val))
saver.save(sess, model_path)
print("训练结束,保存模型到{}".format(model_path))
else:
print("测试模式")
# 如果是测试,载入参数
saver.restore(sess, model_path)
print("从{}载入模型".format(model_path))
# label和名称的对照关系
label_name_dict = {
0: "巴士",
1: "出租车",
2: "货车",
3: "家用轿车",
4: "面包车",
5: "吉普车",
6: "运动型多功能车",
7: "重型货车",
8: "赛车",
9: "消防车"
}
# 定义输入和Label以填充容器,测试时dropout为0
test_feed_dict = {
datas_placeholder: datas,
labels_placeholder: labels,
dropout_placeholdr: 0
}
predicted_labels_val = sess.run(predicted_labels, feed_dict=test_feed_dict)
# 真实label与模型预测label
for fpath, real_label, predicted_label in zip(fpaths, labels, predicted_labels_val):
# 将label id转换为label名
real_label_name = label_name_dict[real_label]
predicted_label_name = label_name_dict[predicted_label]
print("{}\t{} => {}".format(fpath, real_label_name, predicted_label_name))
# 正确次数
correct_number=0
# 计算正确率
for fpath, real_label, predicted_label in zip(fpaths, labels, predicted_labels_val):
if real_label==predicted_label:
correct_number+=1
correct_rate=correct_number/200
print('正确率: {:.2%}'.format(correct_rate))
四、实验结果
dropout=0.25
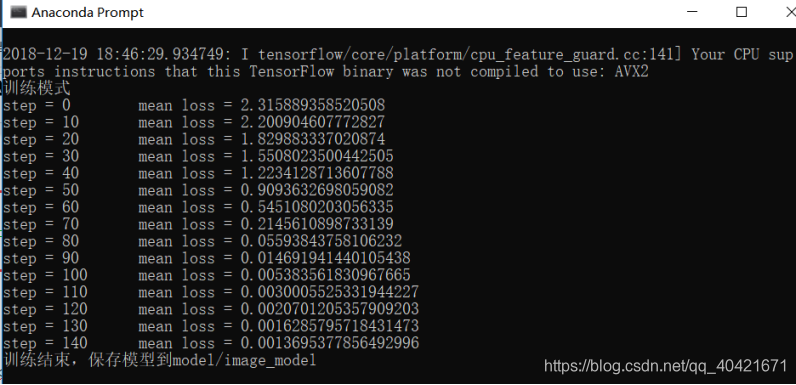
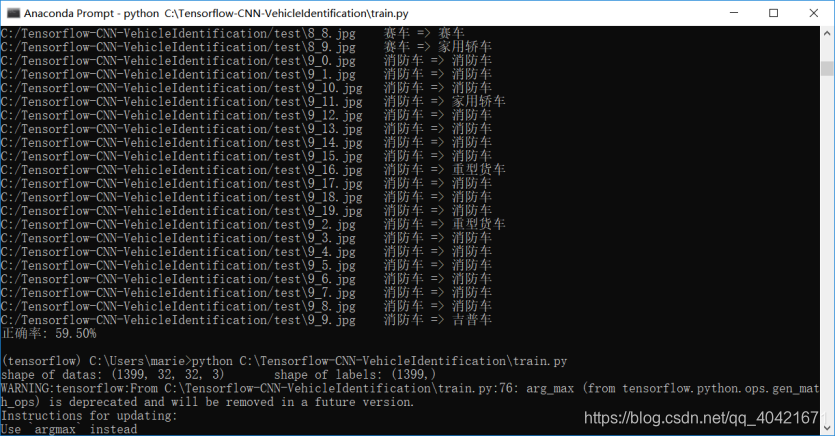
drop=0.5
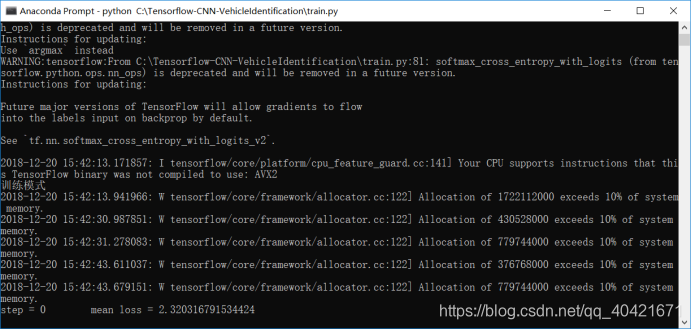
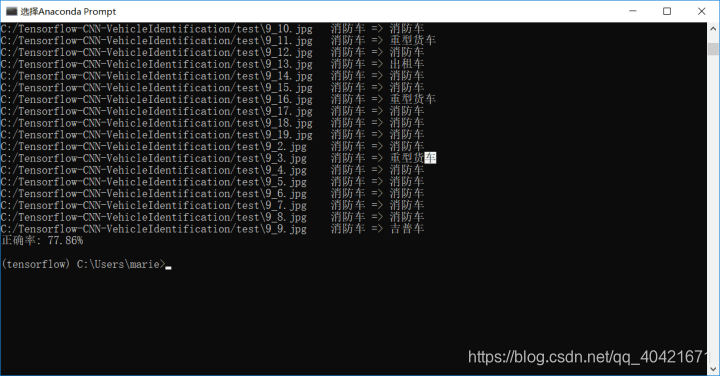
正确率不高,因为用的模型就是基础的神经网络,想要准确度更好,可以试试RESNET,DENSENET等迁移模型。
或者直接进pytorch官网https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html有现成的模型可以套

















 945
945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









