









目录
1. Map基本操作
Go语言的map是一种哈希表实现,用于存储键值对。它的主要特点是通过键进行快速查找。
1.1 初始化
在Go中,可以通过以下几种方式初始化一个map:
1.1.1 使用make函数
- 不指定容量
m := make(map[string]int)
这种方式创建一个空的map,其中键为string类型,值为int类型。
- 指定容量
m := make(map[string]int, 10)
这种方式可以预先指定map的容量,有助于优化性能,减少在后续插入数据时的内存分配次数。
1.1.2 使用字面值
m := map[string]int{"one": 1, "two": 2, "three": 3}
这种方式可以在初始化时为map赋值。
1.2 增删改查
添加或更新
m["key"] = value
如果键已存在,则更新其值;如果键不存在,则插入新的键值对。
查找
value, ok := m["key"]
如果键存在,ok为true,value为对应的值;如果键不存在,ok为false,value为值类型的零值。
删除
delete(m, "key")
删除指定键的键值对。如果键不存在,不会发生任何错误。
1.3 危险操作
1.3.1 并发读写
map操作不是原子的,多个goroutine同时读写map是可能产生读写冲突,会引起panic进而导致程序退出。应使用sync.Map或其他同步机制(如sync.RWMutex)来保护并发访问。
package main
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
m := make(map[int]int)
var mu sync.Mutex
for i := 0; i < 10; i++ {
wg.Add(1)
go func(i int) {
defer wg.Done()
mu.Lock()
m[i] = i * i
mu.Unlock()
}(i)
}
wg.Wait()
fmt.Println(m) // 输出: 各种结果,取决于锁的使用情况
}
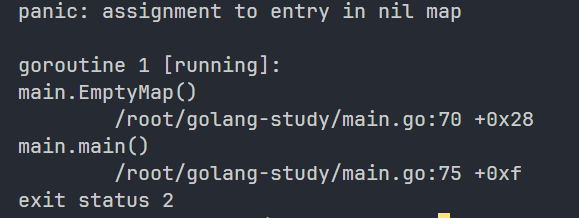
1.3.2 nil map
声明但未初始化的map值为nil,在向值为nil的map添加元素时会触发panic,使用时需要避免
func EmptyMap() {
var m map[string]int
m["a"] = 1
fmt.Println(m)
}
引发panic如下:
2. Map底层实现
2.1 数据结构
2.1.1 Map的数据结构
在Go语言中,map的底层数据结构包含一个哈希表。每个map类型都有一个hmap结构体,存储了指向实际数据的指针、哈希函数、桶(bucket)数组等。
type hmap struct {
count int // 元素数量
flags uint8
B uint8 // 桶的数量是2^B
noverflow uint16 // 溢出桶的数量
hash0 uint32 // 哈希种子
buckets unsafe.Pointer // 指向桶数组的指针
oldbuckets unsafe.Pointer // 扩容时的旧桶数组
nevacuate uintptr // 记录扩容的进度
extra *mapextra // 可选字段,用于溢出桶和键值迭代器
}
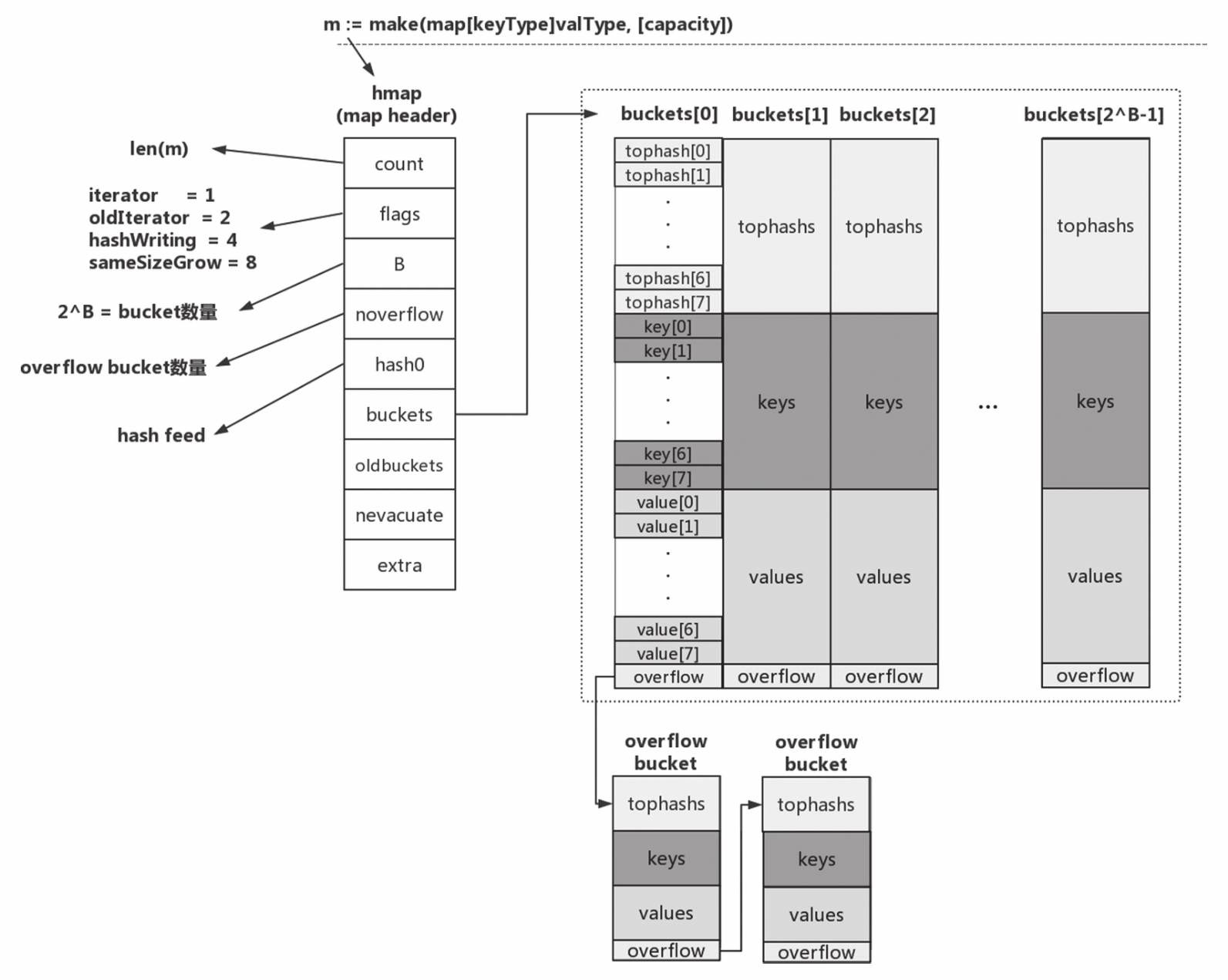
2.1.2 bucket的数据结构
每个桶(bucket)也是一个结构体,包含若干个键值对和溢出指针。当一个桶装满时,新的键值对会存储在溢出桶中。
type bmap struct {
tophash [bucketCnt]uint8
keys [bucketCnt]keyType
values [bucketCnt]valueType
overflow *bmap
}
- tophash区域
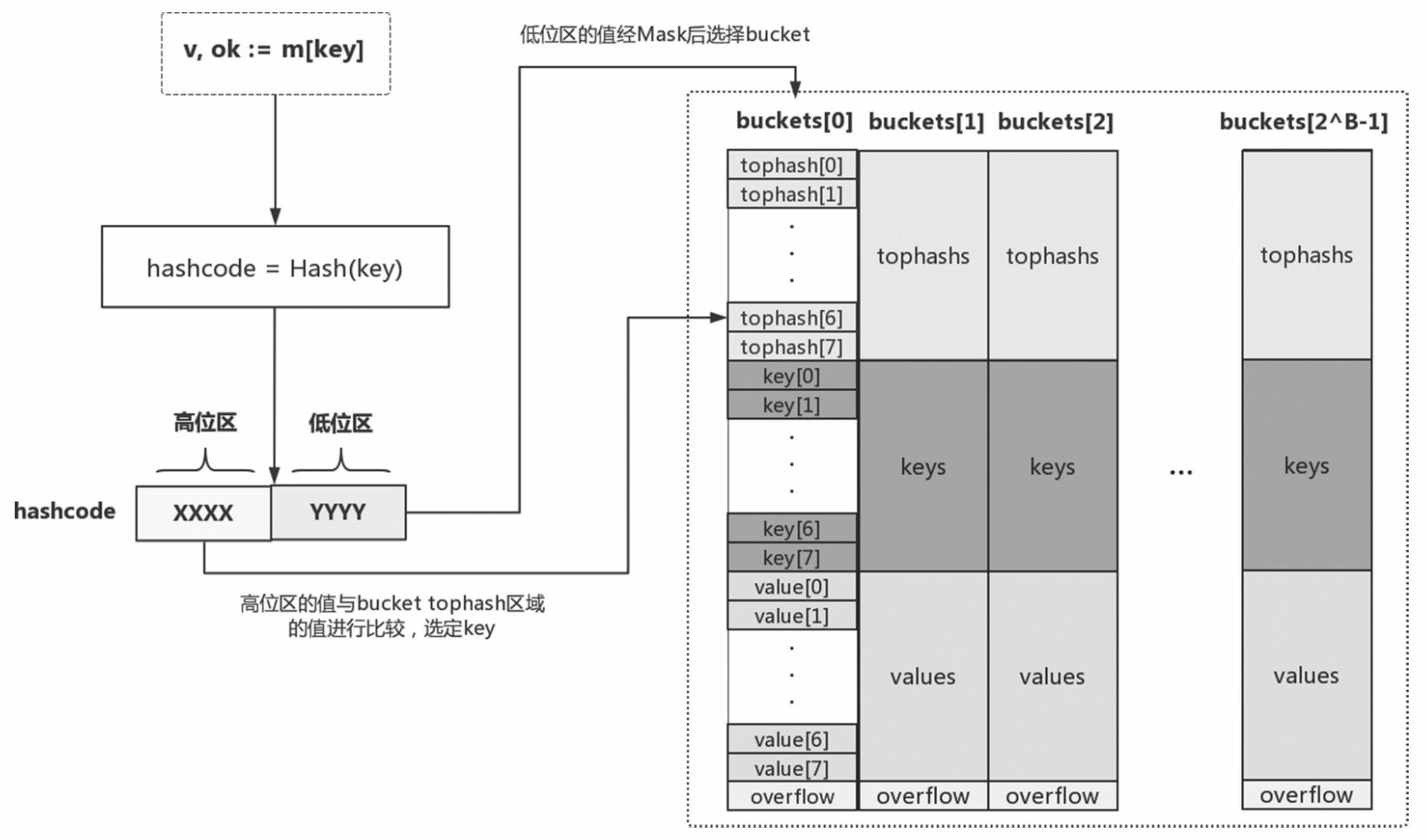
当向map插入一条数据或从map按key查询数据的时候,运行时会使用哈希函数对key做哈希运算并获得一个哈希值hashcode。这个hashcode非常关键,运行时将hashcode“一分为二”地看待,其中低位区的值用于选定bucket,高位区的值用于在某个bucket中确定key的位置。如下图
- keys
tophash区域下面是一块连续的内存区域,存储的是该bucket承载的所有key数据。运行时在分配bucket时需要知道key的大小。那么运行时是如何知道key的大小的呢?当我们声明一个map类型变量时,比如var m map[string]int,Go运行时就会为该变量对应的特定map类型生成一个runtime.maptype实例(如存在,则复用):
// $GOROOT/src/runtime/type.go
type maptype struct {
typ _type
key *_type
elem *_type
bucket *_type // 表示hash bucket的内部类型
keysize uint8 // key的大小
elemsize uint8 // elem的大小
bucketsize uint16 // bucket的大小
flags uint32
}
该实例包含了我们所需的map类型的所有元信息。前面提到过编译器会将语法层面的map操作重写成运行时对应的函数调用,这些运行时函数有一个共同的特点:第一个参数都是maptype指针类型的参数。Go运行时就是利用maptype参数中的信息确定key的类型和大小的,map所用的hash函数也存放在maptype.key.alg.hash(key, hmap.hash0)中。同时maptype的存在也让Go中所有map类型共享一套运行时map操作函数,而无须像C++那样为每种map类型创建一套map操作函数,从而减少了对最终二进制文件空间的占用。
- values
key存储区域下方是另一块连续的内存区域,该区域存储的是key对应的value。和key一样,该区域的创建也得到了maptype中信息的帮助。Go运行时采用了将key和value分开存储而不是采用一个kv接着一个kv的kv紧邻方式存储,这带来的是算法上的复杂性,但却减少了因内存对齐带来的内存浪费。以map[int8]int64为例,下图是存储空间利用率对比:
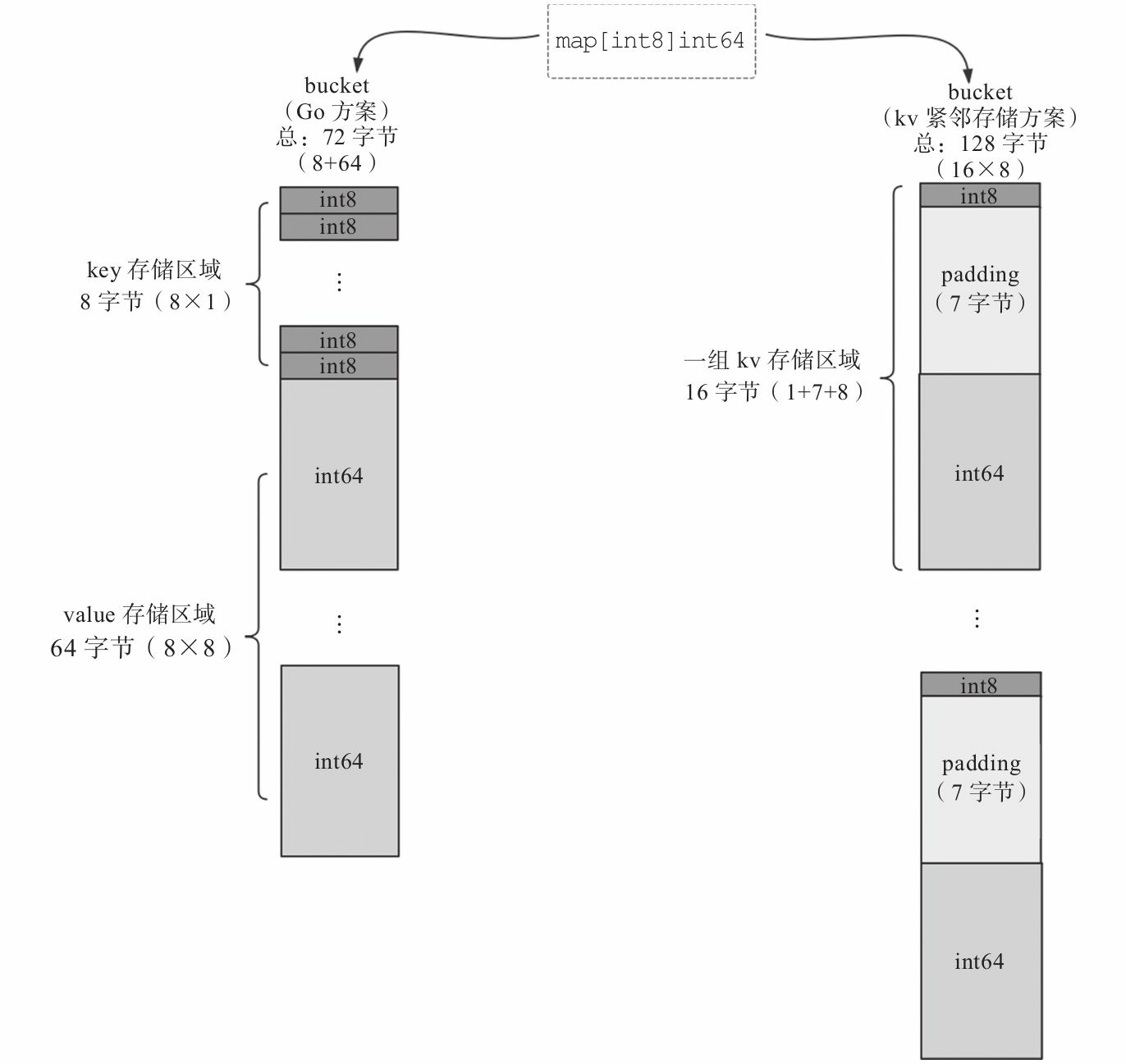
我们看到当前Go运行时使用的方案内存利用效率很高。而kv紧邻存储的方案在map[int8]int64这样的例子中内存浪费十分严重,其内存利用率=72/128=56.25%,有近一半的空间都浪费掉了。
2.2 Hash冲突
当两个或更多的键被哈希到同一个桶时,就会发生哈希冲突。Go语言的map通过链地址法(即使用溢出桶)解决冲突。
2.3 负载因子
负载因子是map中元素数量与桶数量的比值。当负载因子超过某个阈值时,map会进行扩容。Go语言的map设计目标是保持较低的负载因子,以保证高效的查找和插入操作。
每个Hash表的实现对负载因子的容忍程度不同。Redis的map实现中负载因子大于1时就会触发rehash,而Go语言的map在负载因子达到6.5时才会触发rehash,因为Redis的每个bucket只能存储一个键值对,而Go的bucket可以存储8个键值对
2.4 扩容
map会对底层使用的内存进行自动管理。因此,在使用过程中,在插入元素个数超出一定数值后,map势必存在自动扩容的问题(扩充bucket的数量),并重新在bucket间均衡分配数据。
2.4.1 扩容条件
为了保证效率,当新元素将要添加到map时,都会检查是否需要进行扩容,这实际上是一种空间换时间的手段,触发扩容需要满足以下任一条件:
- 负载因子大于6.5时,即平均每个bucket存储的键值对达到6.5个以上
- overflow的数量大于2^15,即overflow数量超过32768
2.4.2 增量扩容
如果是因为当前数据数量超出LoadFactor指定的水位的情况,那么运行时会建立一个两倍于现有规模的bucket数组,但真正的排空和迁移工作也是在进行assign和delete操作时逐步进行的。原bucket数组会挂在hmap的oldbuckets指针下面,直到原buckets数组中所有数据都迁移到新数组,原buckets数组才会被释放。如下图:
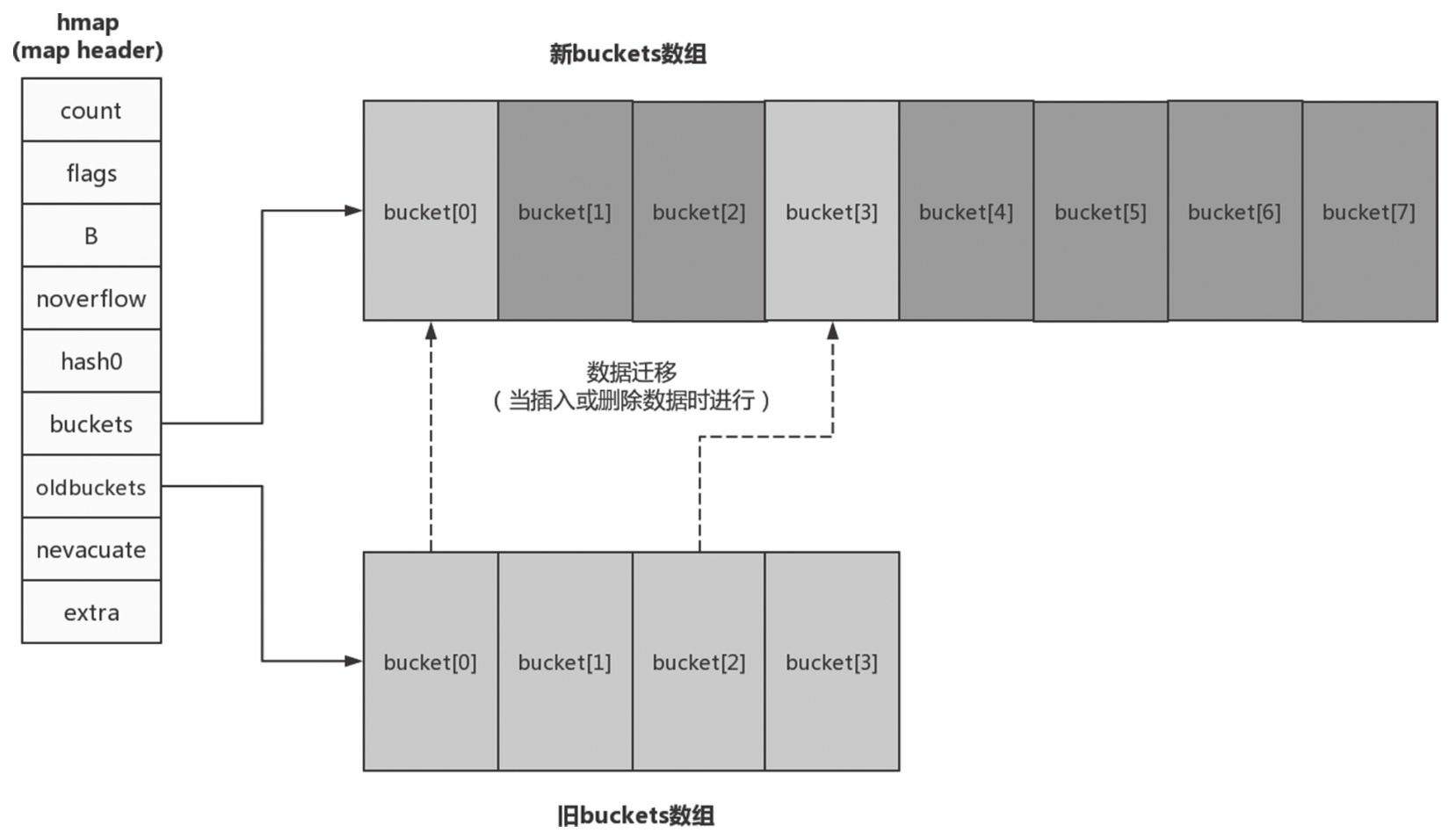
2.4.3 等量扩容
如果是因为overflow bucket过多导致的“扩容”,实际上运行时会新建一个和现有规模一样的bucket数组,然后在进行assign和delete操作时进行排空和迁移
2.5 增删改查
2.5.1 查找过程
查找操作通过计算哈希值并遍历桶中的键值对来实现。
- 计算哈希值:使用哈希函数计算键的哈希值。
- 确定桶位置:根据哈希值计算桶的索引。
- 遍历桶:遍历桶中的键,如果找到匹配的键,则返回对应的值。
- 溢出桶处理:如果桶中没有找到匹配的键,则检查溢出桶。
m := make(map[string]int)
m["key1"] = 100
m["key2"] = 200
fmt.Println(m)
2.5.2 添加过程
添加操作的核心步骤包括计算哈希值、确定哈希桶位置、插入键值对等。
- 计算哈希值:使用哈希函数计算键的哈希值。
- 确定桶位置:根据哈希值计算桶的索引,桶的数量为 2^B,索引为 hash % (2^B)。
- 插入键值对:
- 如果桶未满,将键值对插入桶中合适的位置。
- 如果桶已满,创建溢出桶,将键值对插入溢出桶。
- 如果负载因子超过阈值,触发扩容(将 B 加 1,重新分配桶并迁移键值对)。
m := map[string]int{"key1": 100, "key2": 200}
value, exists := m["key1"]
if exists {
fmt.Println("Found:", value)
} else {
fmt.Println("Not Found")
}
2.5.3 删除过程
删除操作通过计算哈希值并遍历桶中的键值对来找到并移除目标键值对。
- 计算哈希值:使用哈希函数计算键的哈希值。
- 确定桶位置:根据哈希值计算桶的索引。
- 遍历桶:遍历桶中的键,如果找到匹配的键,则将其标记为删除(具体实现中可能是将键值对置为零值)。
- 溢出桶处理:如果桶中没有找到匹配的键,则检查溢出桶。
m := map[string]int{"key1": 100, "key2": 200}
delete(m, "key1")
fmt.Println(m)
2.5.4 更新过程
更新操作与插入操作类似,通过计算哈希值找到目标键并更新其值。如果键不存在,则插入新的键值对。
m := make(map[string]int)
m["key1"] = 100
m["key1"] = 300 // 更新 key1 的值
fmt.Println(m)















 628
628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









