







Kernal
引入
在实际数据中常常遇到不可线性分割的情况,此时通常需要将其映射到高维空间中,使其变得线性可分。例如二维数据:
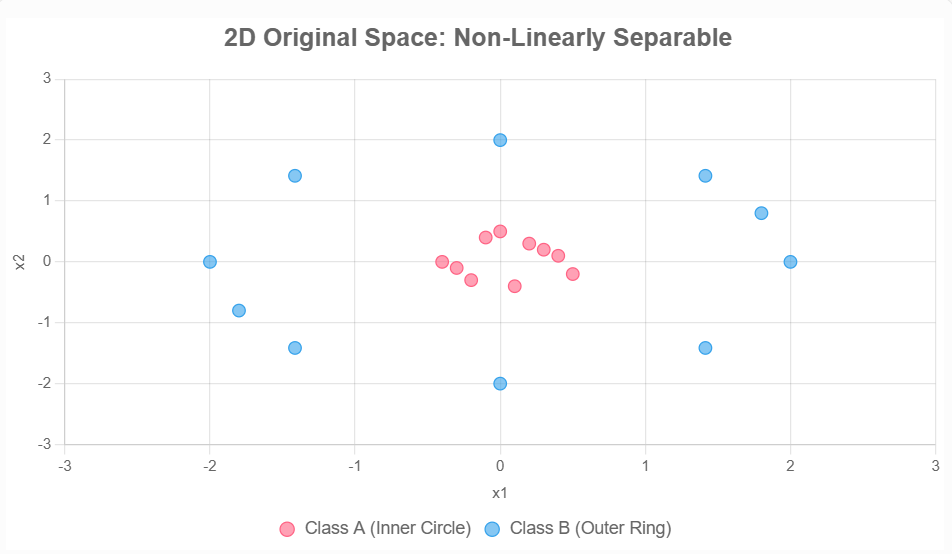
通过映射
ϕ
(
x
1
,
x
2
)
=
(
x
1
2
,
2
x
1
x
2
,
x
2
2
)
\phi(x_1, x_2) = (x_1^2, \sqrt{2}x_1x_2, x_2^2)
ϕ(x1,x2)=(x12,2x1x2,x22),将数据投影到三维空间,下面展示的是一个二维投影(三维画不出来):
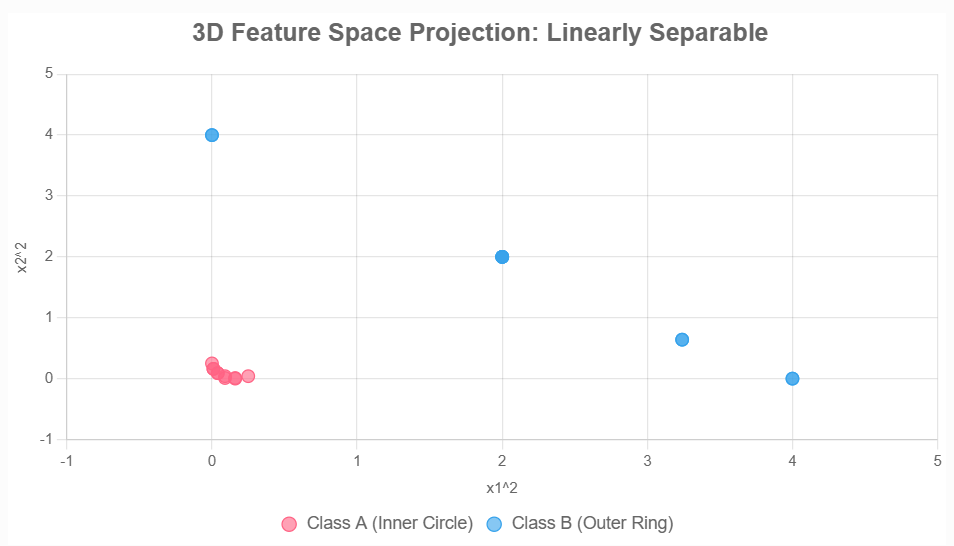
于是我们可以找到一个超平面(如
x
1
2
+
x
2
2
=
c
x_1^2 + x_2^2 = c
x12+x22=c)来把两类数据分开。这种投影方法被称为显式投影法,即构造出一个函数
ϕ
(
x
)
\phi(x)
ϕ(x)将数据从原始空间投影到高维空间。
在一些模型中(如SVM),需要计算高维空间下数据点之间的内积 x 1 ⊤ x 2 x_1^\top x_2 x1⊤x2,反映数据点之间的相似度。然而将数据点投影后再计算会产生许多时间花费和空间花费。那有没有什么方法能直接计算出内积,跳过投影的过程呢?~~有的兄弟,有的。~~于是核方法诞生了。
定义
核方法(Kernel Methods)是一类机器学习算法,旨在通过将数据从原始空间隐式映射到高维特征空间来解决非线性问题,同时利用核函数高效计算特征空间中的内积,而无需显式计算高维特征向量。
设输入空间为
X
\mathcal{X}
X,如下形式的函数称为核函数:
K
:
X
×
X
→
R
\mathcal{K}: \mathcal{X} \times \mathcal{X} \to \mathbb{R}
K:X×X→R
满足其对应的Gram矩阵是正定的或半正定的,这保证了核函数在数学上定义了一个有效的内积空间。
则这个核函数一定能写成某个高维空间的内积
K
(
x
,
x
′
)
=
ϕ
(
x
)
⊤
ϕ
(
x
′
)
\mathcal{K}(x,x') = \phi(x)^\top\phi(x')
K(x,x′)=ϕ(x)⊤ϕ(x′),这由Mercer定理支持。
Mercer定理
描述
如果核函数
K
:
X
×
X
→
R
\mathcal{K}: \mathcal{X} \times \mathcal{X} \to \mathbb{R}
K:X×X→R满足Mercer条件,即正定性,则存在一个映射
ϕ
:
X
→
H
\phi: \mathcal{X} \to \mathcal{H}
ϕ:X→H,将
x
x
x映射到某个希尔伯特空间,使得:
K
(
x
,
x
′
)
=
ϕ
(
x
)
T
ϕ
(
x
′
)
\mathcal{K}(x, x') = \phi(x)^T\phi(x')
K(x,x′)=ϕ(x)Tϕ(x′)
有限情形证明
先在有限数据集
{
x
1
,
.
.
.
,
x
N
}
⊂
X
\set{x_1, ..., x_N} \subset \mathcal{X}
{x1,...,xN}⊂X上证明:由于
K
\mathcal{K}
K是对称正定矩阵,则可以分解为
K
=
U
⊤
Λ
U
Λ
=
diag
(
λ
1
,
.
.
.
,
λ
N
)
,
λ
i
≥
0
\mathcal{K} = U^\top\Lambda U \\ \Lambda = \text{diag }(\lambda_1, ..., \lambda_N), \lambda_i \ge 0 \\
K=U⊤ΛUΛ=diag (λ1,...,λN),λi≥0
U
U
U是正交矩阵,
U
⊤
U
=
I
U^\top U=I
U⊤U=I,列向量
u
1
,
.
.
.
,
u
N
u_1, ..., u_N
u1,...,uN是特征向量。
定义特征映射为
ϕ
:
X
→
R
N
\phi:\mathcal{X} \to \mathbb{R}^N
ϕ:X→RN为:
ϕ
(
x
i
)
=
Λ
1
/
2
u
i
\phi(x_i) = \Lambda^{1/2}u_i
ϕ(xi)=Λ1/2ui
其中
Λ
1
/
2
=
diag
(
λ
1
,
.
.
.
,
λ
N
)
\Lambda^{1/2} = \text{diag }\left(\sqrt{\lambda_1}, ..., \sqrt{\lambda_N}\right)
Λ1/2=diag (λ1,...,λN)
验证内积:
ϕ
(
x
i
)
⊤
ϕ
(
x
j
)
=
u
i
⊤
Λ
u
j
=
K
(
x
i
,
x
j
)
\phi(x_i)^\top\phi(x_j) = u_i^\top \Lambda u_j = \mathcal{K}(x_i, x_j)
ϕ(xi)⊤ϕ(xj)=ui⊤Λuj=K(xi,xj)
补充:若
K
\mathcal{K}
K的秩
r
<
N
r < N
r<N,(可能有零特征值),特征空间的维度可以降为
r
r
r,即只保留非零特征值对应的分量。
这证明了对于有限数据集,核函数可以通过特征分解构造一个有限维特征空间的内积。
一般情形证明
为了严谨性,对于一般核函数
K
(
x
,
x
′
)
\mathcal{K}(x, x')
K(x,x′),输入空间
X
\mathcal{X}
X可能是连续的(如
X
=
R
d
\mathcal{X} = \mathbb{R}^d
X=Rd或紧致域),且核函数可能定义在无穷多点上。Mercer定理的完整形式需要函数空间的理论,特别是再生核希尔伯特空间(RKHS)。
假设:
(1)
X
\mathcal{X}
X是紧致集
(2)
K
(
x
,
x
′
)
\mathcal{K}(x, x')
K(x,x′)是对称的、连续的,且满足Mercer条件(正定性)。
(3)正定性在连续情形下定义为:对于任意平方可积函数
f
∈
L
2
(
X
)
f \in \mathcal{L}^2(\mathcal{X})
f∈L2(X),有:
∬
X
×
X
f
(
x
)
K
(
x
,
x
′
)
f
(
x
′
)
d
x
d
x
′
≥
0
\iint_{\mathcal{X} \times \mathcal{X}} f(x)\mathcal{K}(x, x')f(x')dxdx' \ge 0
∬X×Xf(x)K(x,x′)f(x′)dxdx′≥0
然后对
K
\mathcal{K}
K进行特征展开,核函数
K
(
x
,
x
′
)
\mathcal{K}(x, x')
K(x,x′)作为一个对称正定算子,可以通过特征值分解表示。定义积分算子:
(
T
K
f
)
(
x
)
=
∫
X
K
(
x
,
x
′
)
f
(
x
′
)
d
x
′
(T_Kf)(x) = \int_\mathcal{X}\mathcal{K}(x, x')f(x')dx'
(TKf)(x)=∫XK(x,x′)f(x′)dx′
T
K
T_K
TK是一个紧致、自我伴随的算子(因为
K
\mathcal{K}
K对称且连续)。根据希尔伯特-施密特理论,
T
K
T_K
TK有可数个特征值
λ
i
≥
0
\lambda_i \ge 0
λi≥0和对应的特征函数
ψ
i
(
x
)
\psi_i(x)
ψi(x),满足:
T
K
ψ
i
=
λ
i
ψ
i
,
∫
X
K
(
x
,
x
′
)
ψ
i
(
x
′
)
d
x
′
=
λ
i
ψ
i
T_K \psi_i = \lambda_i\psi_i, \int_\mathcal{X}\mathcal{K}(x, x')\psi_i(x')dx' = \lambda_i\psi_i
TKψi=λiψi,∫XK(x,x′)ψi(x′)dx′=λiψi
特征函数
{
ψ
i
}
\left\{\psi_i\right \}
{ψi}构成了
L
2
(
X
)
\mathcal{L}^2(\mathcal{X})
L2(X)的正交基,满足:
∫
X
ψ
i
(
x
)
ψ
j
(
x
)
d
x
=
δ
i
j
\int_\mathcal{X}\psi_i(x)\psi_j(x)dx = \delta_{ij}
∫Xψi(x)ψj(x)dx=δij
核函数可以表示为特征展开:
K
(
x
,
x
′
)
=
∑
∞
i
=
1
λ
i
ψ
i
(
x
)
ψ
i
(
x
′
)
\mathcal{K}(x,x') = \underset{i=1}{\overset{\infty}{\sum}}\lambda_i\psi_i(x)\psi_i(x')
K(x,x′)=i=1∑∞λiψi(x)ψi(x′)
这一级数在
X
×
X
\mathcal{X} \times \mathcal{X}
X×X上均匀收敛(因为
K
\mathcal{K}
K连续且
X
\mathcal{X}
X紧致)
然后我们构造特征映射
ϕ
:
X
→
H
\phi: \mathcal{X} \to \mathcal{H}
ϕ:X→H,其中
H
\mathcal{H}
H是希尔伯特空间(通常是
l
2
l^2
l2,无穷维序列空间),可以理解为无限维的欧几里得空间。
ϕ
(
x
)
=
(
λ
1
ψ
1
(
x
)
,
λ
1
ψ
2
(
x
)
,
.
.
.
)
\phi(x) = \left(\sqrt{\lambda_1}\psi_1(x), \sqrt{\lambda_1}\psi_2(x), ... \right)
ϕ(x)=(λ1ψ1(x),λ1ψ2(x),...)
每个
ϕ
(
x
)
\phi(x)
ϕ(x)是一个无穷序列,其分量为
λ
i
ψ
i
(
x
)
\sqrt{\lambda_i}\psi_i(x)
λiψi(x)
在
H
\mathcal{H}
H中的内积定义为:
ϕ
(
x
)
⊤
ϕ
(
x
′
)
=
∑
∞
i
=
1
(
λ
i
ψ
i
(
x
)
)
(
λ
i
ψ
i
(
x
′
)
)
=
∑
∞
i
=
1
λ
i
ψ
i
(
x
)
ψ
i
(
x
′
)
=
K
(
x
,
x
′
)
\phi(x)^\top\phi(x') = \underset{i=1}{\overset{\infty}{\sum}}\left(\sqrt{\lambda_i}\psi_i(x)\right)\left(\sqrt{\lambda_i}\psi_i(x')\right)=\underset{i=1}{\overset{\infty}{\sum}}\lambda_i\psi_i(x)\psi_i(x') = \mathcal{K}(x,x')
ϕ(x)⊤ϕ(x′)=i=1∑∞(λiψi(x))(λiψi(x′))=i=1∑∞λiψi(x)ψi(x′)=K(x,x′)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









