









1、相关概念
数理统计:以概率论为基础,研究大量随机现象的统计规律性。
- 描述统计
- 推断统计
描述性统计:从总体数据中提取变量的主要信息(总和,均值等),从总体层面上,对数据进行统计性描述
2、统计量
2.1、频数与频率
- 导入相关模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris
import warnings
sns.set(style='darkgrid')
plt.rcParams['font.family'] = 'SimHei'## 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False ## 用来正常显示负号
warnings.filterwarnings('ignore')
- 获取鸢尾花数据
#鸢尾花
iris = load_iris()
#data代表每朵花的长度共150条,target代表花的类别,共三种每种50个
#sepal花萼petal花瓣
display(iris)


- 处理数据,随机获取10行,并将type拼接到数组数据中
#取前十行
display(iris.data[:10],iris.target[:10])
#将花的长度信息与花类别拼接到一个数组
iris_data=np.concatenate((iris.data,iris.target.reshape(-1,1)),axis=1)
#display(iris_data)
#转换为DataFrame
df=pd.DataFrame(iris_data,columns=['sepal length','sepal width','petal length','petal width','type'])
display(df.sample(10))

- 获取频数,计算频率
#获取频数,先取出该列,然后.value_counts()
frequency=df['type'].value_counts()
display(frequency)
#获取df的行数即有多少个鸢尾花数据,也可用print(df['type'].size)
print(len(df))
#获取频率
percentage=frequency*100/len(df)
display(percentage)
frequency.plot(kind='bar')

2.2、集中趋势
2.2.1、均值、中位数、众数
左偏分布:尾巴在左(极端值异常值在左)
右偏分布:尾巴在右(极端值异常值在右)


- 分别计算平均数,中位数,众数
#分别求平均数,中位数,众数
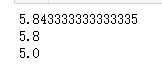
mean=df['sepal length'].mean()
print(mean)
median=df['sepal length'].median()
print(median)
#借用value_counts(),默认降序
value=df['sepal length'].value_counts()
mode=value.index[0]
print(value.index[0])
- 计算众数的简单方法,调用scipy中的stats模块
from scipy import stats
#结果放在一个数组中,众数可能有多个
stats.mode(df['sepal length']).mode
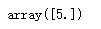
- 根据三个结果,接近正态。画图验证,使用seaborn的distplot函数
#分布图,接近正态
sns.distplot(df['sepal length'])
#plt.axvline() # 用于画出图形中的竖线
plt.axvline(mean,ls='-',color='r',label='均值')
plt.axvline(median,ls='-',color='g',label='中值')
plt.axvline(mode,ls='-',color='indigo',label='众数')
plt.legend()

2.2.2、四分位点
四分位值未必是元素的某个值
若不正好是元素值,那么需要使用加权的方式计算,以索引到分位点索引(该情况下为小数)距离的倒数作为权重比例,再乘以索引对应的元素值,即为计算后的四分位值
numpy和pandas都提供了分位点的计算方法
- numpy计算四分位点,使用.quantile
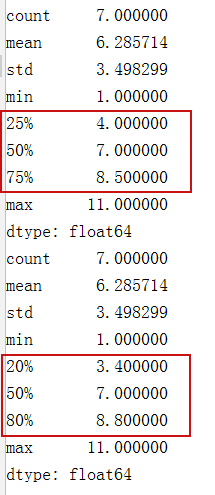
x=[1,3,5,7,8,9,11]
print(np.quantile(x,[0.25,0.5,0.75]))
#计算2/8分位点
print(np.quantile(x,[0.2,0.8]))

- pandas计算四分位点,使用.describe,其中参数percentiles=[0.2,0.8]可修改分位点
s=pd.Series(x)
print(s.describe())
#计算2/8分位点
print(s.describe(percentiles=[0.2,0.8]))
2.3、离散程度(极差,方差,标准差)
- 极差
一组数据中,最大值与最小值之差 - 方差
一组数据中,每个元素与均值偏离的大小
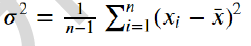
- 标准差
方差的开方


#计算花萼长度的极值,方差,标准差
sub=max(df['sepal length'])-min(df['sepal length'])
#sub=df['sepal length'].max()-df['sepal length'].max()
print(sub)
#方差
var=df['sepal length'].var()
print(var)
#标准差
std=df['sepal length'].std()
print(std)
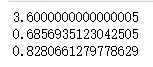
2.4、分布形状(偏度、峰度)
-
偏度 df.skew()
数据分布偏斜方向的程度的度量,描述了数据的非对称程度- 对称分布 - 左偏,偏度<0 - 又偏,偏度>0
#验证左偏分布的数据是否左偏
c1=np.random.randint(1,11,size=100)
c2=np.random.randint(11,21,size=500)
c3=np.concatenate([c1,c2])
left=pd.Series(c3)
print(left.skew())
##验证右偏分布的数据是否右偏
r1=np.random.randint(11,21,size=100)
r2=np.random.randint(1,11,size=500)
r3=np.concatenate([r1,r2])
right=pd.Series(r3)
print(left.skew())
#绘图,sns.kdeplotshade代表是否有阴影
sns.kdeplot(left,shade=True,label='左偏')
sns.kdeplot(right,shade=True,label='右偏')
#图例的位置,可修改local参数
plt.legend()

- 峰度
描述总体中所有取值分布形态陡缓程度的统计量,可理解为高矮程度,比较是相对于标准正态分布的
- 峰度>0,比正态分布密集,方差小,更高更瘦
- 峰度<0,比正态分布分散,方差大,更矮更胖
ps:numpy.random.normal(loc=0.0, scale=1.0, size=None)正态分布
loc:float概率分布的均值,对应着整个分布的中心center
scale:float概率分布的标准差,对应于分布的宽度,scale越大越矮胖,scale越小,越瘦高
size:int or tuple of ints输出的shape,默认为None,只输出一个值
#numpy.random.normal(loc=0.0, scale=1.0, size=None)正态分布
standard=pd.Series(np.random.normal(0,1,size=10000))
print(standard.kurt(),standard.std())
print(df['sepal width'].kurt(),df['sepal width'].std())
print(df['petal length'].kurt(),df['petal length'].std())
sns.kdeplot(standard,shade=True,label='标准正态')
sns.kdeplot(df['sepal width'],shade=True,label='标准正态')
sns.kdeplot(df['petal length'],shade=True,label='标准正态')
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









