







SparkStreaming学习笔记

Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。 Spark 和Hadoop 的根本差异是多个作业之间的数据通信问题 : Spark 多个作业之间数据通信是基于内存,而 Hadoop 是基于磁盘。
Spark核心模块

数据处理的分类
数据处理的方式角度
流式(Streaming)数据处理
批量(brtch)数据处理
数据处理的延迟长短
实时数据处理:毫秒级
离线数据处理:小时or天数级别
流式(Streaming)数据处理
准实时,微批次(时间)的数据处理框架,而且支持的数据输入源很多。数据输入后可以用 Spark 的高度抽象原语,如:map、reduce、join、window 等进行运算。而结果也能保存在很多地方,如 HDFS,数据库等。

架构图:
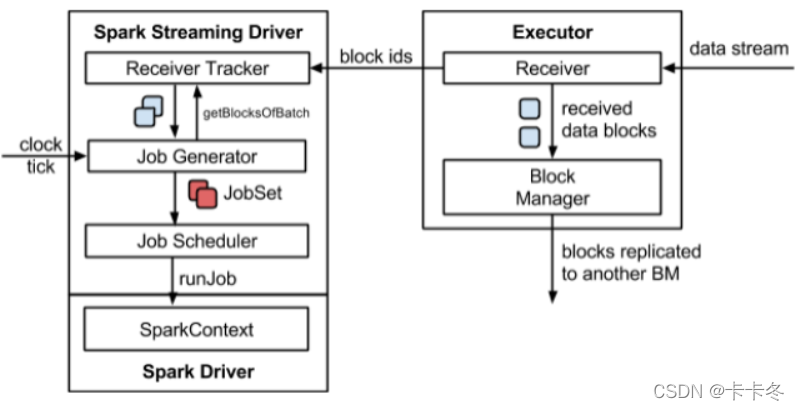
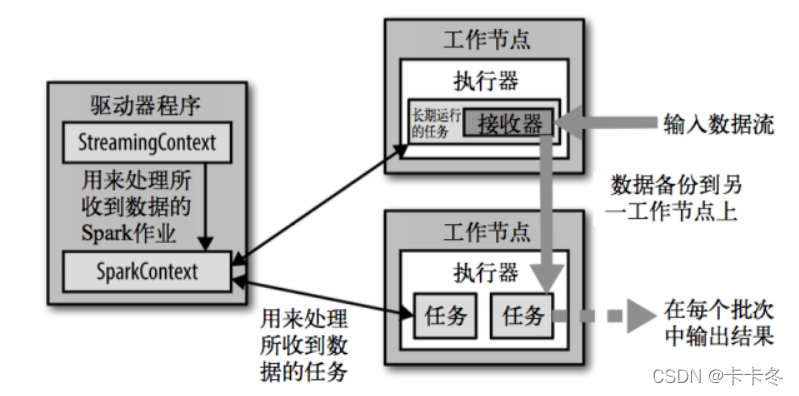
使用Dstream进行wordCount操作:
添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.0.0</version>
</dependency>
代码如下:
package com.cjy.bigdata.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming01_WordCount {
def main(args: Array[String]): Unit = {
//TODO 创建环境对象
//StreamingContext创建时,需要传递两个参数
//第一个表示环境配置
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
//第二个参数表示批量处理的周期(采集周期)
val ssc = new StreamingContext(sparkConf,Seconds(3))
//TODO 逻辑处理
//获取端口数据
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val wordToOne = words.map((_, 1))
val wordToCount: DStream[(String,Int)] = wordToOne.reduceByKey(_ + _)
wordToCount.print()
//TODO 关闭环境
//由于采集器是长期执行的任务,所以不能直接关闭,而且不能让main方法执行完毕
//ssc.stop()
//1、启动采集器
ssc.start()
//2、等待采集器的关闭
ssc.awaitTermination()
}
}
1、得到StreamingContext对象,参数中是环境配置和采集周期
2、调用socketTextStream方法,采集数据为一行行的
3、使用flatMap将数据切分,形成单词形式
4、words.map((_, 1))将单词映射为元组
5、使用reduceByKey方法将相同单词数做统计
结果如下:

DStream的创建
DStream是Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark算子操作后的结果数据流。
在内部实现上,每一批次的数据封装成一个RDD,一系列连续的RDD组成了DStream。对这些RDD的转换是由Spark引擎来计算。
说明:DStream中批次与批次之间计算相互独立。如果批次设置时间小于计算时间会出现计算任务叠加情况,需要多分配资源。通常情况,批次设置时间要大于计算时间。
自定义数据采集器
需要继承 Receiver,并实现 onStart、onStop 方法来自定义数据源采集。
一个简单的案例实现:onStart方法中使用一个新线程对发送的数据进行保存store(),
package com.cjy.bigdata.spark.streaming
import java.util.Random
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming03_DIY {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf,Seconds(3))
val messageDS: ReceiverInputDStream[String] = ssc.receiverStream(new MyReceiver)
messageDS.print()
//1、启动采集器
ssc.start()
//2、等待采集器的关闭,将主线程阻塞,主线程不退出
ssc.awaitTermination()
}
/*自定义数据采集器
* 1、继承Receiver,定义泛型,传递参数
* 2、重写方法
* */
class MyReceiver extends Receiver[String](StorageLevel.MEMORY_ONLY){
private var flag = true
override def onStart(): Unit = {
//模拟一个新线程去发送数据
new Thread(new Runnable {
override def run(): Unit = {
while (flag){
val message: String = "采集的数据为:" + new Random().nextInt(10).toString
store(message)
Thread.sleep(500)
}
}
}).start()
}
override def onStop(): Unit = {
flag=false
}
}
}
一个经典的案例,自定义数据采集器:实现监控某个端口号,获取端口内容,有些类似socketTextStream这个方法了,代码如下:主要内容就是对onStart的重写
package com.cjy.bigdata.spark.streaming
import java.io.{BufferedReader, InputStreamReader}
import java.net.Socket
import java.nio.charset.StandardCharsets
import java.util.Random
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming04_DIY {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf,Seconds(3))
val lineStream: ReceiverInputDStream[String] = ssc.receiverStream(new CustomerReceiver("localhost",9998))
val wordStream: DStream[String] = lineStream.flatMap(_.split("\t"))
val wordCount: DStream[(String, Int)] = wordStream.map((_, 1)).reduceByKey(_ + _)
wordCount.print()
//1、启动采集器
ssc.start()
//2、等待采集器的关闭,将主线程阻塞,主线程不退出
ssc.awaitTermination()
}
/*自定义数据采集器
* 实现监控某个端口号,获取端口内容
* */
class CustomerReceiver(host: String,port: Int) extends Receiver[String](StorageLevel.MEMORY_ONLY){
//启动后,调用该方法,读数据并且将数据发送给spark
override def onStart(): Unit = {
new Thread("Socket Receiver"){
override def run(): Unit ={
receive
}
}.start()
}
//读数据并将数据发送给spark
def receive: Unit = {
//创建一个socket
val socket = new Socket(host, port)
//定义一个变量,用来接收端口传来的数据
var input: String = null
//创建一个BufferedReader用于读取端口传来的数据,字节流转字符流在放入缓冲区
val reader = new BufferedReader(new InputStreamReader(socket.getInputStream, StandardCharsets.UTF_8))
//读取数据
input = reader.readLine()
//当receiver没有关闭并且输入数据不为空,则循环发送数据给spark
while(!isStopped() && input != null){
store(input)
input = reader.readLine()
}
//跳出则关闭资源
reader.close()
socket.close()
//重启任务
restart("restart")
}
override def onStop(): Unit = {
}
}
}
-------------------------------------------
Time: 1639470255000 ms
-------------------------------------------
-------------------------------------------
Time: 1639470258000 ms
-------------------------------------------
-------------------------------------------
Time: 1639470261000 ms
-------------------------------------------
(aa,1)
-------------------------------------------
Time: 1639470264000 ms
-------------------------------------------
(aa,2)
(,1)
(a,3)
spark对kafka数据源的操作
通过 SparkStreaming 从 Kafka 读取数据,并将读取过来的数据做简单计算,最终打印到控制台
pom中导入依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.10.1</version>
</dependency>
代码如下:主要是创建了kafkaDStream之后对kv的操作
package com.cjy.bigdata.spark.streaming
import java.util.Random
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{DStream, InputDStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming05_Kafka {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf,Seconds(3))
//3.定义 Kafka 参数
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> //配置端口
"linux1:9092,linux2:9092,linux3:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "cjyYq", //配置集群
"key.deserializer" ->
"org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" ->
"org.apache.kafka.common.serialization.StringDeserializer"
)
//4.读取 Kafka 数据创建 DStream
val kafkaDStream: InputDStream[ConsumerRecord[String, String]] =
KafkaUtils.createDirectStream[String, String](ssc,
LocationStrategies.PreferConsistent,
//读取主题topic
ConsumerStrategies.Subscribe[String, String](Set("cjyYq"), kafkaPara))
//5.将每条消息的 KV 取出
val valueDStream: DStream[String] = kafkaDStream.map(record => record.value())
//6.计算 WordCount
valueDStream.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.print()
ssc.start()
ssc.awaitTermination()
}
}














 207
207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









