






文章目录
八股文
本文章是一篇内容较为全面的java秋招八股文,内容包含数据结构、计算机网络、数据库、Redis、消息队列、JavaSE、JVM、JUC、海量数据题目、高并发场景、项目的亮点难点、ssm框架、dubbo框架等等。这是我整个秋招不停面试的总结和反思,最后也是靠它拿到了菜鸟的offer,希望可以帮助到马上进行秋招的朋友。
数据结构
Java的排序Arrays.sort()是怎么做的
先说总结:
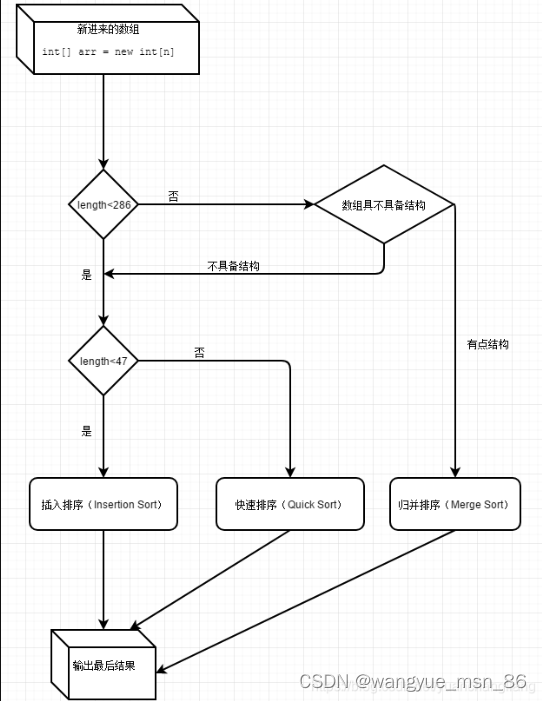
数组长度为n,则1 <= n < 47 使用插入排序
数组长度为n,则47 <= n < 286 使用使用快速排序
数组长度为n,则286 < n 使用归并排序或快速排序(有一定顺序使用归并排序,毫无顺序使用快排)
n的数量小的话,可能插入排序比快排更快。当n的数量47到286之间时,用快速排序就行了。当大于286时,先判断数组结构是不是基本有序的(官方称之为有结构的),如果是的话就用归并排序,如果不是的话就用快速排序。因为数组数量太少不值得去判断数组结构是不是基本有序。
判断是不是有结构的代码: 时间复杂度大概O(n)
// Check if the array is nearly sorted
for (int k = left; k < right; run[count] = k) {
if (a[k] < a[k + 1]) { // ascending
while (++k <= right && a[k - 1] <= a[k]);
} else if (a[k] > a[k + 1]) { // descending
while (++k <= right && a[k - 1] >= a[k]);
for (int lo = run[count] - 1, hi = k; ++lo < --hi; ) {
int t = a[lo]; a[lo] = a[hi]; a[hi] = t;
}
} else { // equal
for (int m = MAX_RUN_LENGTH; ++k <= right && a[k - 1] == a[k]; ) {
if (--m == 0) {
sort(a, left, right, true);
return;
}
}
}
/*
* The array is not highly structured,
* use Quicksort instead of merge sort.
*/
if (++count == MAX_RUN_COUNT) {
sort(a, left, right, true);
return;
}
}
这里主要作用是看他数组具不具备结构:实际逻辑是分组排序,每降序为一个组,像1,9,8,7,6,8。9到6是降序,为一个组,然后把降序的一组排成升序:1,6,7,8,9,8。然后最后的8后面继续往后面找。
每遇到这样一个降序组,++count,当count大于MAX_RUN_COUNT(67),被判断为这个数组不具备结构(也就是这数据时而升时而降),然后送给之前的sort(里面的快速排序)的方法(The array is not highly structured,use Quicksort instead of merge sort.)
如果count少于MAX_RUN_COUNT(67)的,说明这个数组还有点结构,就继续往下走下面的归并排序。
快速排序
为什么基准元素(第一个)和处理完的元素互换的时候,能保证处理完的元素是比基准元素小的呢?
因为是让right指针先走的,且看这几种情况:
- left right交换完中间就剩一个元素了,right先走,如果中间的数大于基准数,那么right还要走,走到和left相等,left这时候是比基准小的
- 如果是递增的,那么right一路左移动,最后基准元素等于left等于right,也满足
class Solution {
public void quickSort(int[] nums,int start,int end) {
// 遵守循环不变量,start和end为左闭右闭结构
// 如果传过来的数组只有一个,或者end比start还小,就没必要继续了
if(start >= end){
return;
}
// 基准选本数组的第一个
int pivot = nums[start];
// 两个指针开始 左从基准元素开始 右从最右边开始
int left = start;
int right = end;
while(left<right){
// right指针先走,找到第一个小于基准的数
while(nums[right] >= pivot && left<right){
right--;
}
while(nums[left] <= pivot && left<right){
left++;
}
if(left<right){
int temp = nums[left];
nums[left] = nums[right];
nums[right] = temp;
}
}
// 将基准元素和left交换顺序
nums[start] = nums[left];
nums[left] = pivot;
// 遍历基准左边的数组
if(start<left){
quickSort(nums,start,left-1);
}
// 遍历基准右边的数组
if(left<end){
quickSort(nums,left+1,end);
}
}
}
// 测试:
class test{
public static void main(String[] args) {
Solution solution =new Solution();
int[] nums = new int[]{6 ,1 ,2 ,5 ,9 ,3 ,4 ,7 ,10 ,8};
solution.quickSort(nums,0,nums.length-1);
for (int a:nums){
System.out.print(a);
}
}
}

递归是n方,而快排使用二分思想,n✖️logn 因为递归深度是logn。
选第一个元素为基准,然后分成两拨。
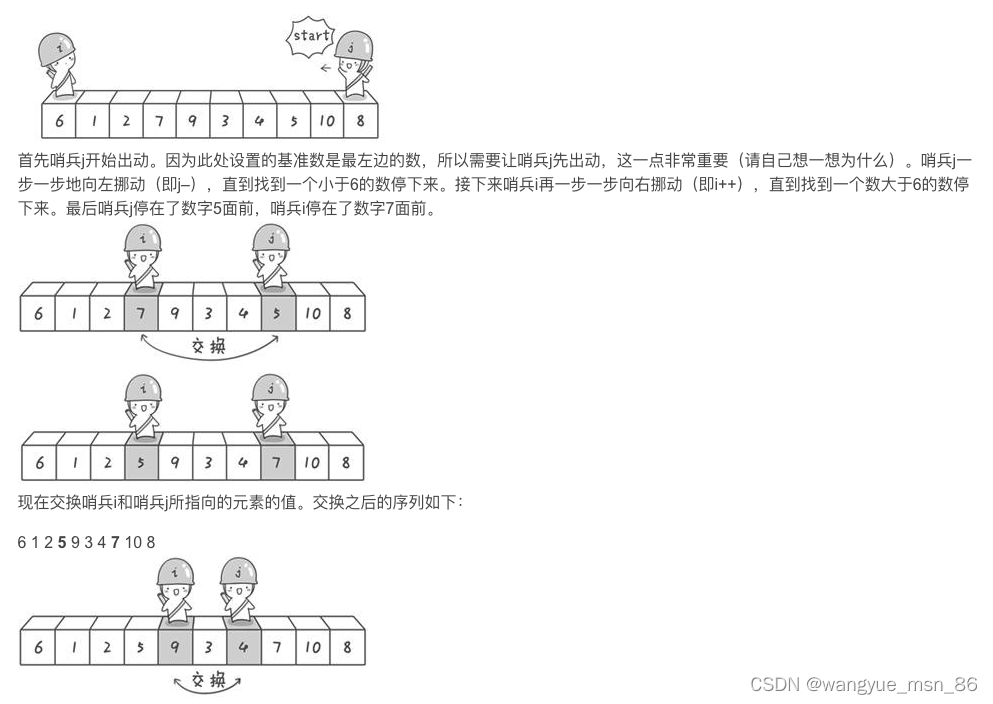
假设我们现在对“6 1 2 7 9 3 4 5 10 8”这个10个数进行排序。首先在这个序列中随便找一个数作为基准数(不要被这个名词吓到了,就是一个用来参照的数,待会你就知道它用来做啥的了)。为了方便,就让第一个数6作为基准数吧。接下来,需要将这个序列中所有比基准数大的数放在6的右边,比基准数小的数放在6的左边,类似下面这种排列:
3 1 2 5 4 6 9 7 10 8
在初始状态下,数字6在序列的第1位。我们的目标是将6挪到序列中间的某个位置,假设这个位置是k。现在就需要寻找这个k,并且以第k位为分界点,左边的数都小于等于6,右边的数都大于等于6。想一想,你有办法可以做到这点吗?
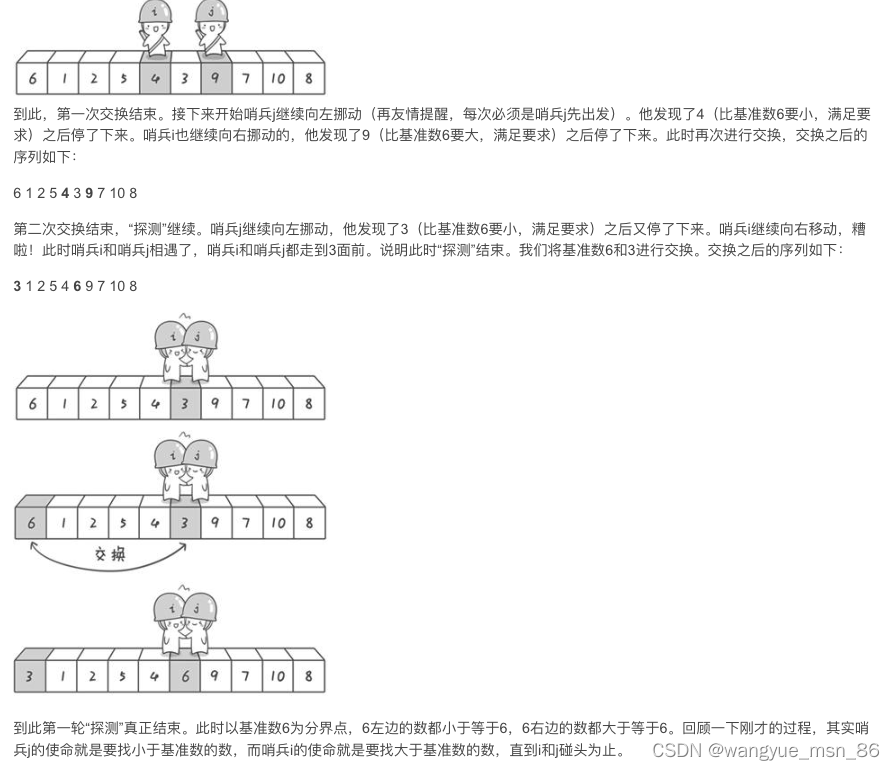
方法其实很简单:分别从初始序列“6 1 2 7 9 3 4 5 10 8”两端开始“探测”。先从右往左找一个小于6的数,再从左往右找一个大于6的数,然后交换他们。这里可以用两个变量i和j,分别指向序列最左边和最右边。我们为这两个变量起个好听的名字“哨兵i”和“哨兵j”。刚开始的时候让哨兵i指向序列的最左边(即i=1),指向数字6。让哨兵j指向序列的最右边(即=10),指向数字。
快速排序如何优化?
如果选第一个,数组基本有序的话,不就退化为冒泡了吗,空间复杂度还高,怎么优化呢
随机基准
在待排数组有序或基本有序的情况下,选择使用固定基准影响快排的效率。为了解决数组基本有序的问题,可以采用随机基准的方式来化解这一问题。算法如下:
int Random(int a[], int low, int high)//在low和high间随机选择一元素作为划分的基准
{
srand(time(0));
int pivot = rand()%(high - low) + low;
Swap(a[pivot],a[low]); //把随机基准位置的元素和low位置元素互换
return a[low];
}
此时,原来Partition()函数里的T x = a[low];相应的改为T x = Random(a, low, high);
虽然使用随机基准能解决待排数组基本有序的情况,但是由于这种随机性的存在,对其他情况的数组也会有影响(若数组元素是随机的,使用固定基准常常优于随机基准)。随机数算法(Sherwood算法)能有效的减少升序数组排序所用的时间,数组元素越多,随机数算法的效果越好。可以试想,上述升序数组中有10万个元素而且各不相同,那么在第一次划分时,基准选的最差的概率就是十万分之一。当然,选择最优基准的概率也是十万分之一,随机数算法随机选择一个元素作为划分基准,算法的平均性能较好,从而避免了最坏情况的多次发生。许多算法书中都有介绍随机数算法,因为算法对程序的优化程度和下面所讲的三数取中方法很接近,所以我只记录了一种方法的运行时间。
三数取中
由于随机基准选取的随机性,使得它并不能很好的适用于所有情况(即使是同一个数组,多次运行的时间也大有不同)。目前,比较好的方法是使用三数取中选取基准。它的思想是:选取数组开头,中间和结尾的元素,通过比较,选择中间的值作为快排的基准。其实可以将这个数字扩展到更大(例如5数取中,7数取中等)。这种方式能很好的解决待排数组基本有序的情况,而且选取的基准没有随机性。
例如:序列[1][1][6][5][4][7][7],三个元素分别是[1]、[5]、[7],此时选择[5]作为基准。
第一趟:[1][1][4][5][6][7][7]
三数取中算法如下:
int NumberOfThree(int arr[],int low,int high)
{
int mid = low + ((high - low) >> 1);//右移相当于除以2
if (arr[mid] > arr[high])
{
Swap(arr[mid],arr[high]);
}
if (arr[low] > arr[high])
{
Swap(arr[low],arr[high]);
}
if (arr[mid] > arr[low])
{
Swap(arr[mid],arr[low]);
}
//此时,arr[mid] <= arr[low] <= arr[high]
return arr[low];
}
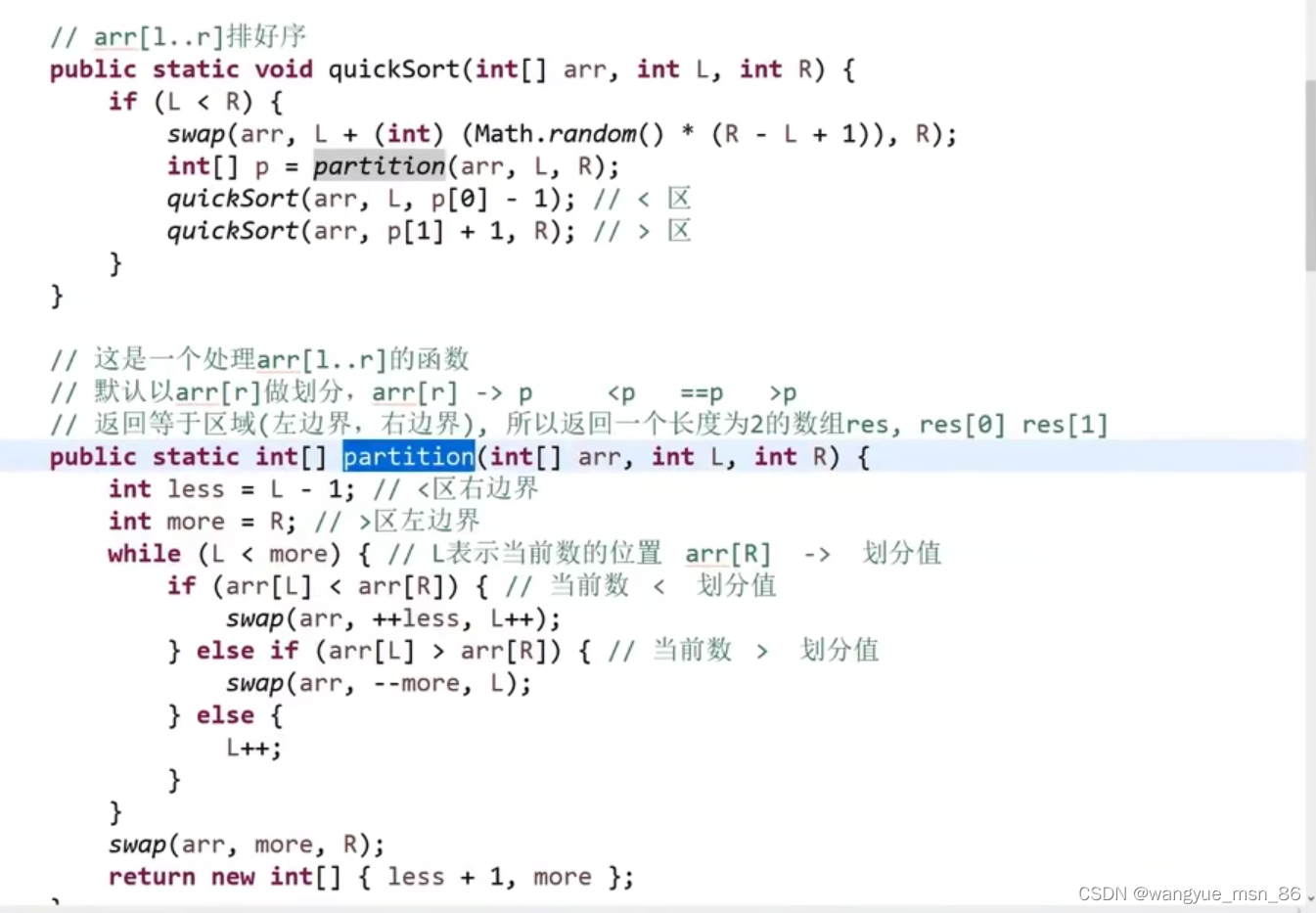
快排3.0随机版本,partition是划分成三部分 小于部分 等于部分 大于部分 等于部分不止一个 荷兰国旗问题
归并排序

归并排序过程 需要额外用一个数组空间,比如最后那两个,两个指针,在两个有序的数组中按照顺序放到一个新数组中
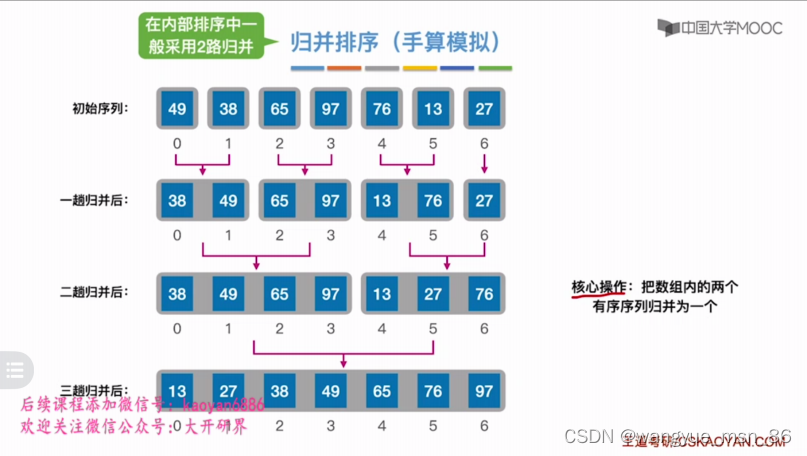
从小的,各自有序的子数组,慢慢归并到大数组
public class MergeSort {
public static void main(String[] args) {
int[] nums = new int[]{1,3,2,1,7,5,4,6};
mergeSort(nums,0,nums.length-1);
for (int a:nums){
System.out.println(a);
}
}
// 归并排序
public static void mergeSort(int[] nums,int left,int right){
// base case 两指针指向一个了
if (left == right){
return;
}
int mid = (left+right)/2;
mergeSort(nums,left,mid);
mergeSort(nums,mid+1,right);
merge(nums,left,mid,right);
}
// 归并
public static void merge(int[] nums,int left,int mid,int right){
int[] help = new int[right-left+1];
int i=0;
int cur1=left;
int cur2=mid+1;
while (cur1 <=mid && cur2 <=right){ // 左右两个数组,两个指针,放更大的数
help[i++] = nums[cur1]<nums[cur2]?nums[cur1++]:nums[cur2++];
}
// 如果用右面的用尽了,把左面剩余的加入
while (cur1<=mid){
help[i++] = nums[cur1++];
}
// 如果左面的用尽了,把右面剩余的加入
while (cur2<=right){
help[i++] = nums[cur2++];
}
// 把归并的数组复制到原数组中
for (int j = 0; j < help.length; j++) {
nums[left+j] = help[j];
}
}
}
堆排序
堆排序的地位远远没有堆结构重要
堆排序是稳定在O N*logN 复杂度,空间复杂度稳定在O(1)的,性能不错
大根堆、小根堆,以大根堆举例,大根堆就是一个完全二叉树,其结点的值比子树的结点值都大,就是爸爸大于儿子
不是维护一个真的树结构,只是一个数组结构,使用数组下标就可以模拟树的父子关系,使用heapSize控制堆结点数量
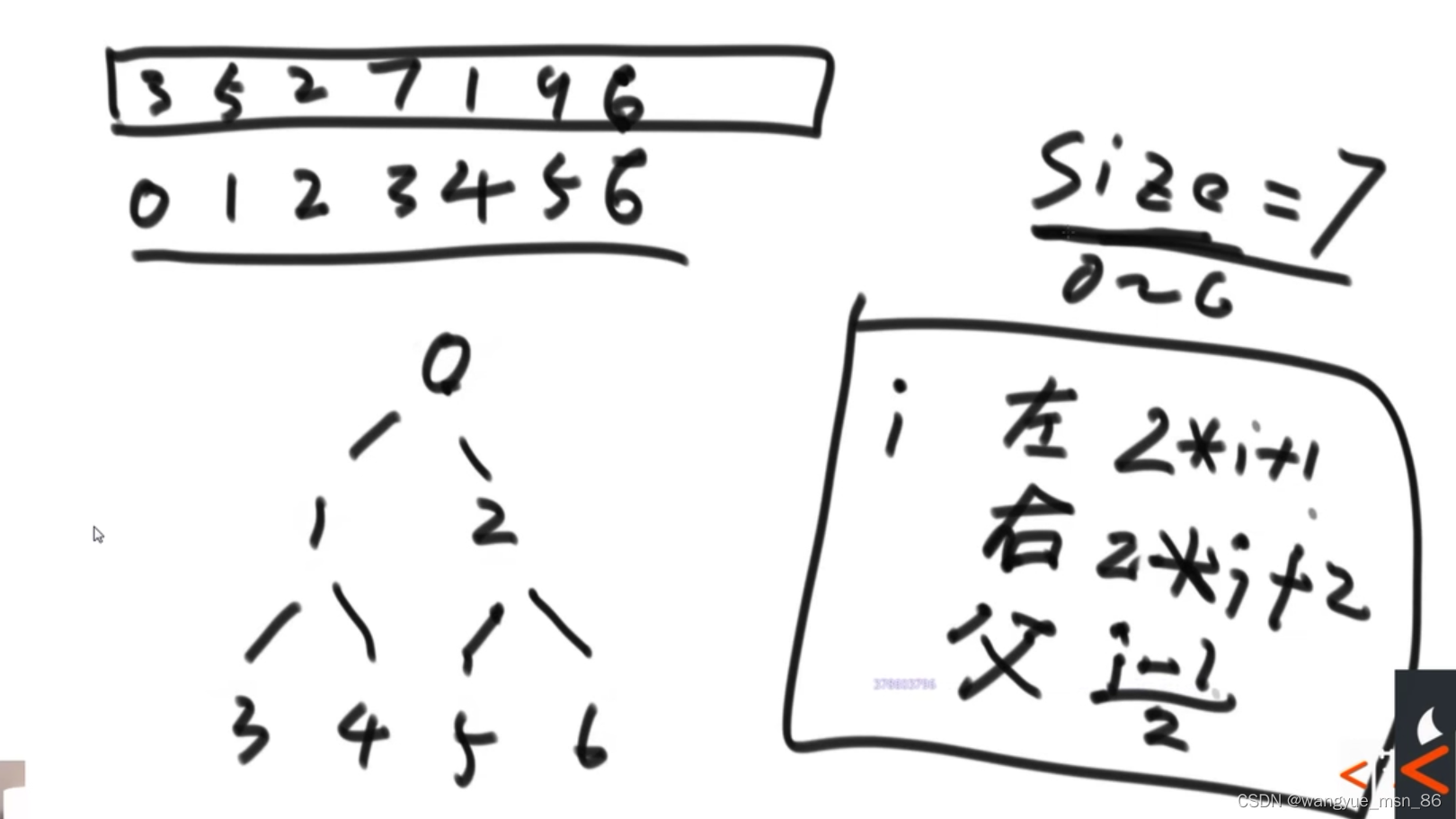
1.往大根堆插入结点:插入后比较父结点和自己的大小,如果自己大就交换,该while到达根结点后,自己就是父 index-1除2也是0,所以也退出循环

2.还有一个重要操作,heapify,如果把最大值拿掉,把堆最后一个元素放到第一位,就要重新调整回大根堆,heapify就是把当前元素下沉到合适的位置
两个孩子中最大的那个跟当前比较,如果比当前的大,当前的和最大孩子交换位置
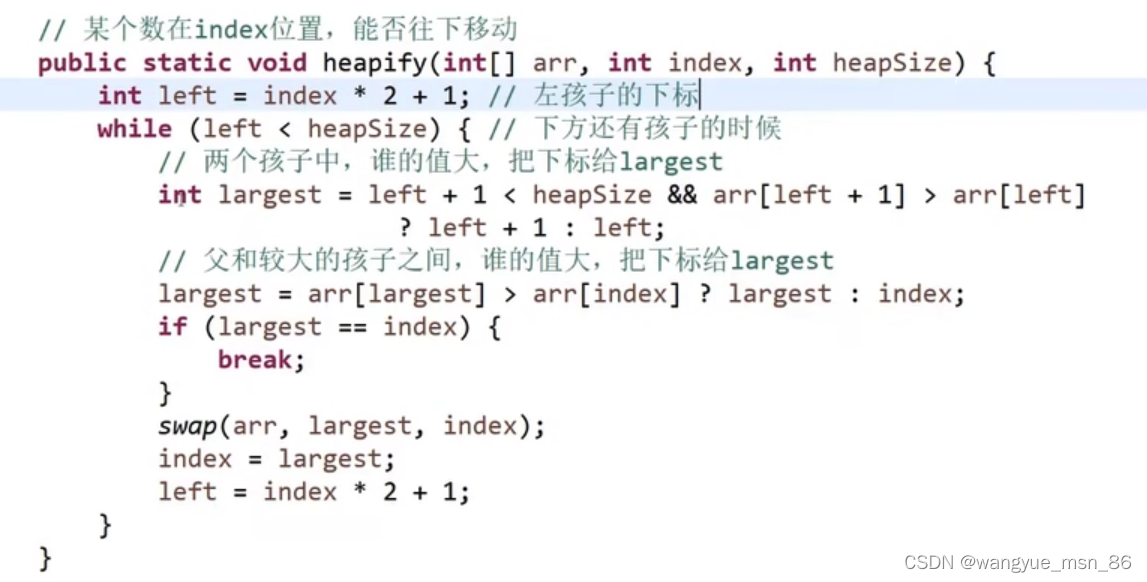
代码:
取大根堆第一个,就是最大的,和最后一个数,交换,把排序好的剔除出大根堆,新的根调整成大根堆,就行了。
package Sort;
public class HeapSort {
public static void main(String[] args) {
int[] nums = new int[]{1,3,2,-1,8,4};
heapSort(nums);
for (int a:nums){
System.out.println(a);
}
}
public static void heapSort(int[] nums){
if (nums == null || nums.length < 2){
return;
}
// 建立大根堆策略1:从左到右插入,O(N*logN),但是性能不太好,因为整个数组已经给出了,没必要一个个插入
// for (int i = 0; i < nums.length; i++) { // O(N)
// heapInsert(nums,i); // O(logn)
// }
// 建立大根堆策略2:类似与王道的策略,完全二叉树从后往前,先保证小树是大根堆,然后调整当前结点,让大树慢慢也变成大根堆,不需要一个个插入,只需要把数组调整成大根堆就行了
for (int i = nums.length-1; i >= 0 ; i--) { // 复杂度 O(N)比上面的从左往右插入 N* logN 快点
heapify(nums,i,nums.length);
}
int heapSize = nums.length;
swap(nums,0,--heapSize); // 已经排序好的部分,剔除大根堆
while(heapSize>0){ // o(N )
heapify(nums,0,heapSize); // O(logn)
swap(nums,0,--heapSize);
}
}
// 往堆里插入数据
public static void heapInsert(int[] nums,int index){
while(nums[index] > nums[(index-1)/2]){ // 如果比父亲的值大,也包含了边界判断,不能比根还小,等于0就不满足了
swap(nums,index,(index-1)/2);
index = (index-1)/2; // 交换完后索引指向父结点,接着比较
}
}
// 下沉调整
public static void heapify(int[] nums,int index,int heapSize){
// heapSize控制了堆的界限,而不是看数组下标
int left = index*2+1; // 左孩子的下标
while (left < heapSize){ // 下方还有孩子的时候
int largest = left+1 < heapSize && nums[left+1] > nums[left]?left+1:left; // 取左右孩子最大值下标,如果右孩子不在堆里,只能用左孩子
largest = nums[largest] > nums[index]?largest:index; // 最大孩子和当前比较
if (largest == index){ // 当前最大,下沉可以结束了
break;
}
// 孩子大,交换
swap(nums,largest,index);
index = largest;
left = index*2+1;
}
}
public static void swap(int[] nums,int i,int j){
int temp = nums[i];
nums[i] = nums[j];
nums[j] =temp;
}
}
LRU缓存(lfu哈希表加小根堆即可)
明显需要实现一个带访问顺序的Hash表的数据结构,Java中已经有了就是LinkedHashMap
分析上面的操作过程,要让 put 和 get 方法的时间复杂度为 O(1),我们可以总结出 cache 这个数据结构必要的条件:
1、显然 cache 中的元素必须有时序,以区分最近使用的和久未使用的数据,当容量满了之后要删除最久未使用的那个元素腾位置。
2、我们要在 cache 中快速找某个 key 是否已存在并得到对应的 val;
3、每次访问 cache 中的某个 key,需要将这个元素变为最近使用的,也就是说 cache 要支持在任意位置快速插入和删除元素。
那么,什么数据结构同时符合上述条件呢?哈希表查找快,但是数据无固定顺序;链表有顺序之分,插入删除快,但是查找慢。所以结合一下,形成一种新的数据结构:哈希链表 LinkedHashMap。
LRU 缓存算法的核心数据结构就是哈希链表,双向链表和哈希表的结合体。这个数据结构长这样:
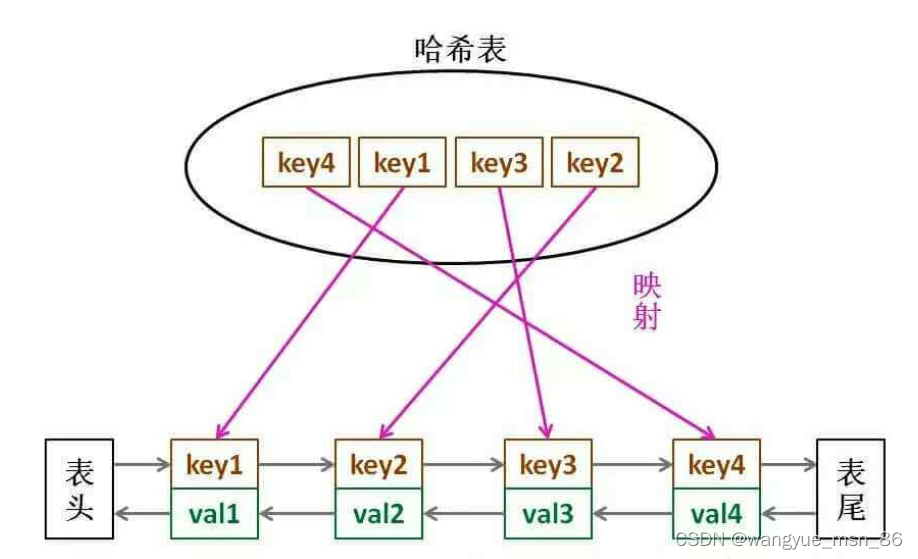
我们把entry维护为一个双向链表就行了,维护一个头结点和尾结点,HashMap中的entry只指向了后继,但是这里是双向的,就是为了方便删除来维护访问顺序,我们把最右边的理解为最近访问的,最左边的理解为最久未访问的就行了。
class Node {
public int key, val;
public Node next, prev;
public Node(int k, int v) {
this.key = k;
this.val = v;
}
}
然后依靠我们的 Node 类型构建一个双链表,实现几个 LRU 算法必须的 API:
class DoubleList {
// 头尾虚节点
private Node head, tail;
// 链表元素数
private int size;
public DoubleList() {
// 初始化双向链表的数据
head = new Node(0, 0);
tail = new Node(0, 0);
head.next = tail;
tail.prev = head;
size = 0;
}
// 在链表尾部添加节点 x,时间 O(1)
public void addLast(Node x) {
x.prev = tail.prev;
x.next = tail;
tail.prev.next = x;
tail.prev = x;
size++;
}
// 删除链表中的 x 节点(x 一定存在)
// 由于是双链表且给的是目标 Node 节点,时间 O(1)
public void remove(Node x) {
x.prev.next = x.next;
x.next.prev = x.prev;
size--;
}
// 删除链表中第一个节点,并返回该节点,时间 O(1)
public Node removeFirst() {
if (head.next == tail)
return null;
Node first = head.next;
remove(first);
return first;
}
// 返回链表长度,时间 O(1)
public int size() { return size; }
}
注意我们实现的双链表 API 只能从尾部插入,也就是说靠尾部的数据是最近使用的,靠头部的数据是最久为使用的。
有了双向链表的实现,我们只需要在 LRU 算法中把它和哈希表结合起来即可,先搭出代码框架:
class LRUCache {
// key -> Node(key, val)
private HashMap<Integer, Node> map;
// Node(k1, v1) <-> Node(k2, v2)...
private DoubleList cache;
// 最大容量
private int cap;
public LRUCache(int capacity) {
this.cap = capacity;
map = new HashMap<>();
cache = new DoubleList();
}
先不慌去实现 LRU 算法的 get 和 put 方法。由于我们要同时维护一个双链表 cache 和一个哈希表 map,很容易漏掉一些操作,比如说删除某个 key 时,在 cache 中删除了对应的 Node,但是却忘记在 map 中删除 key。
解决这种问题的有效方法是:在这两种数据结构之上提供一层抽象 API。
说的有点玄幻,实际上很简单,就是尽量让 LRU 的主方法 get 和 put 避免直接操作 map 和 cache 的细节。我们可以先实现下面几个函数:
/* 将某个 key 提升为最近使用的 */
private void makeRecently(int key) {
Node x = map.get(key);
// 先从链表中删除这个节点
cache.remove(x);
// 重新插到队尾
cache.addLast(x);
}
/* 添加最近使用的元素 */
private void addRecently(int key, int val) {
Node x = new Node(key, val);
// 链表尾部就是最近使用的元素
cache.addLast(x);
// 别忘了在 map 中添加 key 的映射
map.put(key, x);
}
/* 删除某一个 key */
private void deleteKey(int key) {
Node x = map.get(key);
// 从链表中删除
cache.remove(x);
// 从 map 中删除
map.remove(key);
}
/* 删除最久未使用的元素 */
private void removeLeastRecently() {
// 链表头部的第一个元素就是最久未使用的
Node deletedNode = cache.removeFirst();
// 同时别忘了从 map 中删除它的 key
int deletedKey = deletedNode.key;
map.remove(deletedKey);
}
这里就能回答之前的问答题「为什么要在链表中同时存储 key 和 val,而不是只存储 val」,注意 removeLeastRecently 函数中,我们需要用 deletedNode 得到 deletedKey。
也就是说,当缓存容量已满,我们不仅仅要删除最后一个 Node 节点,还要把 map 中映射到该节点的 key 同时删除,而这个 key 只能由 Node 得到。如果 Node 结构中只存储 val,那么我们就无法得知 key 是什么,就无法删除 map 中的键,造成错误。
上述方法就是简单的操作封装,调用这些函数可以避免直接操作 cache 链表和 map 哈希表,下面我先来实现 LRU 算法的 get 方法:
public int get(int key) {
if (!map.containsKey(key)) {
return -1;
}
// 将该数据提升为最近使用的
makeRecently(key);
return map.get(key).val;
}
总结:get的时候,就把原来的结点删了,插入到链表尾部。put的时候,也是到尾部
这样我们可以轻松写出 put 方法的代码:
public void put(int key, int val) {
if (map.containsKey(key)) {
// 删除旧的数据
deleteKey(key);
// 新插入的数据为最近使用的数据
addRecently(key, val);
return;
}
if (cap == cache.size()) {
// 删除最久未使用的元素
removeLeastRecently();
}
// 添加为最近使用的元素
addRecently(key, val);
}
至此,你应该已经完全掌握 LRU 算法的原理和实现了,我们最后用 Java 的内置类型 LinkedHashMap 来实现 LRU 算法,逻辑和之前完全一致,我就不过多解释了:
class LRUCache {
int cap;
LinkedHashMap<Integer, Integer> cache = new LinkedHashMap<>();
public LRUCache(int capacity) {
this.cap = capacity;
}
public int get(int key) {
if (!cache.containsKey(key)) {
return -1;
}
// 将 key 变为最近使用
makeRecently(key);
return cache.get(key);
}
public void put(int key, int val) {
if (cache.containsKey(key)) {
// 修改 key 的值
cache.put(key, val);
// 将 key 变为最近使用
makeRecently(key);
return;
}
if (cache.size() >= this.cap) {
// 链表头部就是最久未使用的 key
int oldestKey = cache.keySet().iterator().next();
cache.remove(oldestKey);
}
// 将新的 key 添加链表尾部
cache.put(key, val);
}
private void makeRecently(int key) {
int val = cache.get(key);
// 删除 key,重新插入到队尾
cache.remove(key);
cache.put(key, val);
}}
红黑树
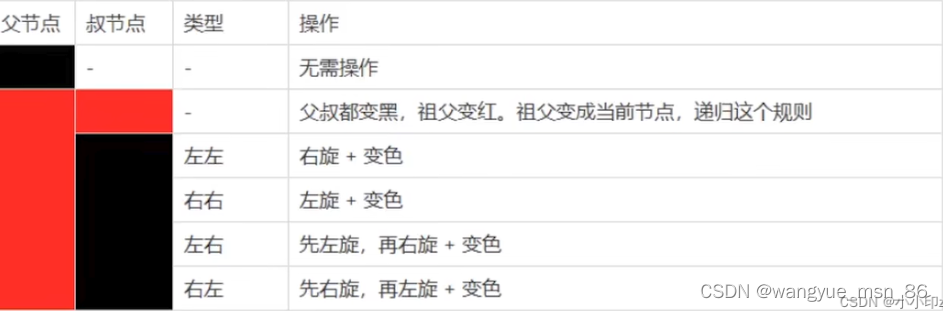
红黑树的特点:
- 结点不是红色就是黑色
- 根结点和叶子结点是黑色的,这里的叶子结点不是通常意义上的叶子结点,是指的null值
- 红色结点不能相邻
- 任一结点到叶子结点(null)值的黑色一样多
本质上来看,红黑树没有严格的约束平衡,而是保证最大情况是最小情况的二倍,比如最大是红黑交替的,最小是全黑的,最多差二倍
查找的效率也是log n级别的,虽然查找比avl稍微差了一些,但是插入和删除的效率比avl高,由于hashmap常有插入和删除,并且concurrentHashMap加锁时,插入时间更是影响性能,所以使用红黑树。
红黑树的插入过程的调整:可以看到,最多涉及三层的改动(旋转和变色),要看叔叔结点的状态,所以整个性能比avl要好,avl旋转可能涉及到整个树的旋转
海量数据场景题目
海量数据场景中的题目,面试官的问题往往给出的是模糊的,这个时候也考验你问清楚问题的能力。

1.统计不同号码的个数(位图的各种思考)
题目描述
已知某个文件内包含大量电话号码,每个号码为8位数字,如何统计不同号码的个数?
这类题目其实是求解数据重复的问题。对于这类问题,可以使用位图法处理
8位电话号码可以表示的范围为00000000~99999999。如果用 bit表示一个号码,那么总共需要1亿个
bit,总共需要大约10MB的内存。
申请一个位图并初始化为0,然后遍历所有电话号码,把遍历到的电话号码对应的位图中的bit设置为1。
当遍历完成后,如果bit值为1,则表示这个电话号码在文件中存在,否则这个bit对应的电话号码在文件
中不存在。
最后这个位图中bit值为1的数量就是不同电话号码的个数了。
首先位图可以使用一个int数组来实现(在Java中int占用4byte)。
假设电话号码为 P,而通过电话号码获取位图中对应位置的方法为:
第一步,因为int整数占用4*8=32bit,通过 P/32 就可以计算出该电话号码在 bitmap 数组中的下标,从
而可以确定它对应的 bit 在数组中的位置。
第二步,通过 P%32 就可以计算出这个电话号码在这个int数字中具体的bit的位置。只要把1向左移
P%32 位,然后把得到的值与这个数组中的值做或运算,就可以把这个电话号码在位图中对应的位设置
为1。
这样极大的减少了内存,但是我感觉映射关系的设计不能直接设计对应的位,如果号码是以1300000000为最小值的话,那么需要进行一个映射,把位图的第一位映射为1300000000。
如果有移动,联通,电信三家的号码,分别是13,15,18打头的话,那么就三家各用各的位图,各用各的映射规则,先判断是哪家的,然后存到对应的位图中。
但是想解决位图稀疏数据存储问题怎么办,比如1,50001,98,45600222,我们至少需要初始化45600222位的bit数组,
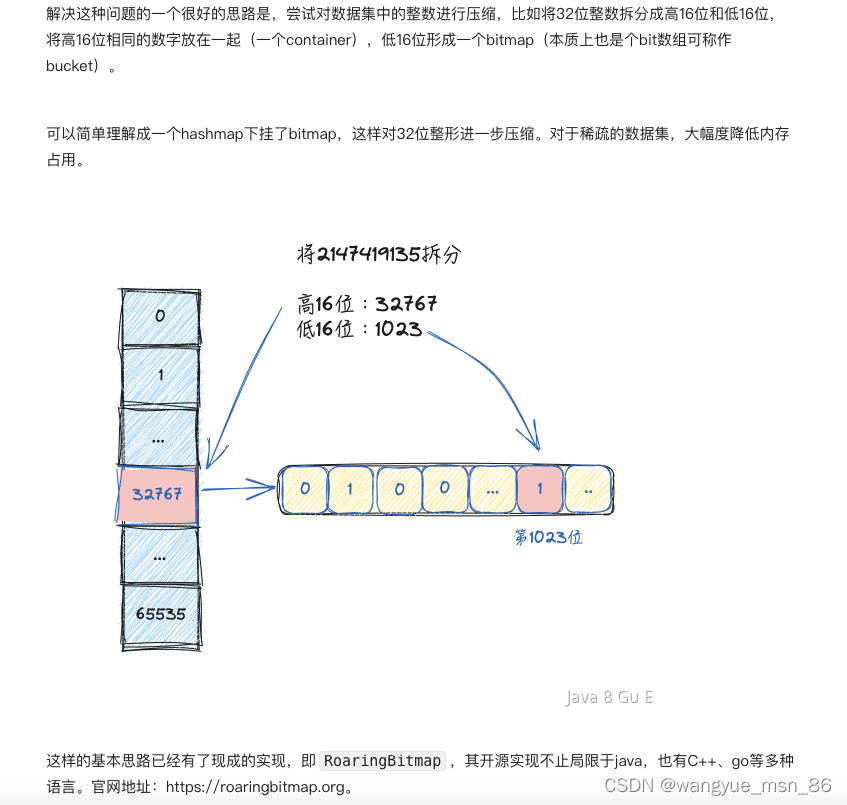
在es,hive等知名开源组件中都应用过这种算法。
2.查找两个大文件共同的url个数
题目
给定 a、b 两个文件,各存放 50 亿个 URL,每个 URL 各占 64B,找出 a、b 两个文件共同的 URL。内
存限制是 4G。
分析
每个 URL 占 64B,那么 50 亿个 URL占用的空间大小约为 320GB。
5,000,000,000 * 64B ≈ 320GB
由于内存大小只有 4G,因此,不可能一次性把所有 URL 加载到内存中处理。
可以采用分治策略,也就是把一个文件中的 URL 按照某个特征划分为多个小文件,使得每个小文件大小
不超过 4G,这样就可以把这个小文件读到内存中进行处理了。首先遍历文件a,对遍历到的 URL 进行哈希取余 hash(URL) % 1000 ,根据计算结果把遍历到的 URL
存储到 a0, a1,a2, …, a999,这样每个大小约为 300MB。使用同样的方法遍历文件 b,把文件 b 中的
URL 分别存储到文件 b0, b1, b2, …, b999 中。这样处理过后,所有可能相同的 URL 都在对应的小文件
中,即 a0 对应 b0, …, a999 对应 b999,不对应的小文件不可能有相同的 URL。那么接下来,我们只需
要求出这 1000 对小文件中相同的 URL 就好了。
接着遍历 ai( i∈[0,999] ),把 URL 存储到一个 HashSet 集合中。然后遍历 bi 中每个 URL,看在
HashSet 集合中是否存在,若存在,说明这就是共同的 URL, 把共同的url记录到保存最终结果的大文件中。
总结
最后总结一下:
-
分而治之,进行哈希取余;
-
对每个子文件进行 HashSet 统计。
因为小文件是一个个处理的,HashSet也是记录小文件的内容,所以内存可以承担的下。
本题也可以使用布隆过滤器来处理,就可以直接在内存中操作了,布隆过滤器比较节省空间,但是有一定的误判率。把出现过的元素都存一下就行了。如果此元素之前还出现过就是重复的元素。
3. 出现频率最高的100个词
题目描述
假如有一个1G大小的文件,文件里每一行是一个词,每个词的大小不超过16byte,要求返回出现频率
最高的100个词。内存大小限制是10M
解法1
由于内存限制,我们无法直接将大文件的所有词一次性读到内存中。
可以采用分治策略,把一个大文件分解成多个小文件,保证每个文件的大小小于10M,进而直接将单个
小文件读取到内存中进行处理。
第一步,首先遍历大文件,对遍历到的每个词x,执行 hash(x) % 500 ,将结果为i的词存放到文件f(i)
中,遍历结束后,可以得到500个小文件,每个小文件的大小为2M左右;
第二步,接着统计每个小文件中出现频数最高的100个词。可以使用HashMap来实现,其中key为词,
value为该词出现的频率。
对于遍历到的词x,如果在map中不存在,则执行 map.put(x, 1)。
若存在,则执行 map.put(x, map.get(x)+1) ,将该词出现的次数加1。
第三步,在第二步中找出了每个文件出现频率最高的100个词之后,通过维护一个小顶堆来找出所有小
文件中出现频率最高的100个词。
具体方法是,遍历第一个文件,把第一个文件中出现频率最高的100个词构建成一个小顶堆。
如果第一个文件中词的个数小于100,可以继续遍历第二个文件,直到构建好有100个结点的小顶堆为
止。
继续遍历其他小文件,如果遍历到的词的出现次数大于堆顶上词的出现次数,可以用新遍历到的词替换
堆顶的词,然后重新调整这个堆为小顶堆。
当遍历完所有小文件后,这个小顶堆中的词就是出现频率最高的100个词。总结一下,这种解法的主要思路如下:
\1. 采用分治的思想,进行哈希取余
\2. 使用HashMap统计每个小文件单词出现的次数
\3. 使用小顶堆,遍历步骤2中的小文件,找出词频top100的单词
但是很容易可以发现问题,在第二步中,如果这个1G的大文件中有某个词词频过高,可能导致小文件大
小超过10m。这种情况下该怎么处理呢?
接下来看另外一种解法。
解法2
第一步:使用多路归并排序对大文件进行排序,这样相同的单词肯定是紧挨着的
多路归并排序对大文件进行排序的步骤如下:
① 将文件按照顺序切分成大小不超过2m的小文件,总共500个小文件
② 使用10MB内存分别对 500 个小文件中的单词进行排序
③ 使用一个大小为500大小的堆,对500个小文件进行多路排序,结果写到一个大文件中
其中第三步,对500个小文件进行多路排序的思路如下:
初始化一个最小堆,大小就是有序小文件的个数500。堆中的每个节点存放每个有序小文件对应的
输入流。
按照每个有序文件中的下一行数据对所有文件输入流进行排序,单词小的输入文件流放在堆顶。
拿出堆顶的输入流,并其下一行数据写入到最终排序的文件中,如果拿出来的输入流中还有数据的
话,那么将这个输入流再一次添加到栈中。否则说明该文件输入流中没有数据了,那么可以关闭这
个流。
循环这个过程,直到所有文件输入流都没有数据为止。
第二步:
① 初始化一个100个节点的小顶堆,用于保存100个出现频率最多的单词
② 遍历整个文件,一个单词一个单词的从文件中取出来,并计数
③ 等到遍历的单词和上一个单词不同的话,那么上一个单词及其频率如果大于堆顶的词的频率,那么放
在堆中,否则不放
最终,小顶堆中就是出现频率前100的单词了。
解法2相对解法1,更加严谨,如果某个词词频过高或者整个文件都是同一个词的话,解法1不适用。
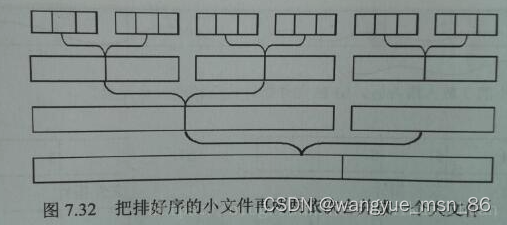
4.海量数据排序问题
当所要排序的的数据量太多或者文件太大,无法直接在内存里排序,而需要依赖外部设备时,就会使用到外部排序(外部归并)。
1、算法描述
假设有一堆小文件要进行排序,即使是一个大文件,也要拆分成小文件,通过hash映射等方式,然后内存才可以处理小文件
-
依次读入每个文件块,在内存中对当前文件块进行排序(应用恰当的内排序算法,如快排),此时,每块文件相当于一个由小到大排列的有序队列;
-
在内存中建立一个小根堆,读入每块文件的队列头(如果是10路归并,堆的大小比10大就行);
-
弹出堆顶元素,如果元素来自第i块,则从第i块文件中补充一个元素到最小值堆。弹出的元素暂存至临时数组;
-
当临时数组存满时,将数组写至磁盘,并清空数组内容;
-
重复过程3、4,直至所有文件块读取完毕。
就这样,m路归并,从小的有序一步步变成最终大文件的有序。
计算机网络
三次握手和四次挥手
三次握手:
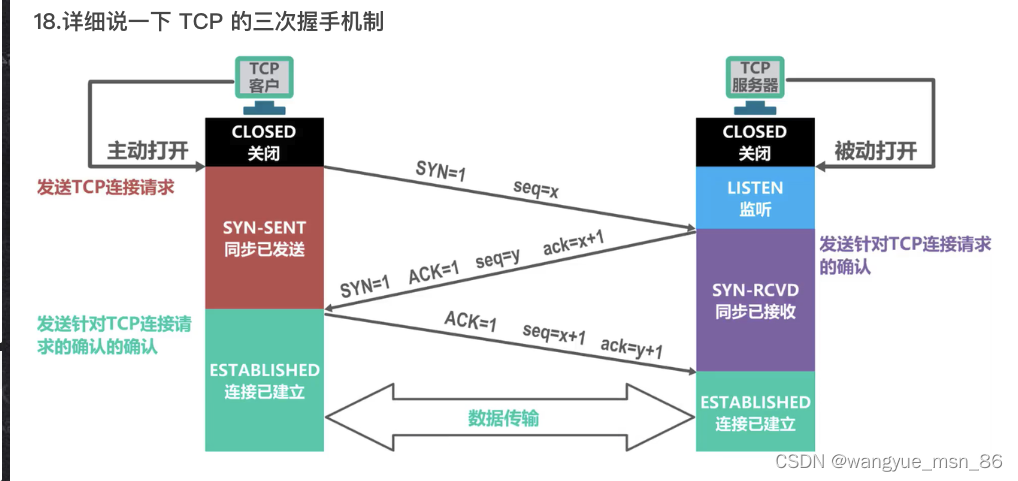
最开始,客户端和服务端都处于 CLOSE(关闭)状态,服务端监听客户端的请求,进入 LISTEN(监听) 状态。
客户端发送连接请求,进行第一次握手(同步位 SYN=1,序号字段 seq=x),发送完毕后,客户端就进入 SYN_SENT(同步已发送) 状态。
服务端确认连接,进行第二次握手(同步位 SYN=1,确认位 ACK=1,序号字段 seq=y,确认号字段 ack=x+1), 发送完毕后,服务端就进入 SYN_RCV(同步已接收) 状态。
客户端收到服务端的确认后,再次向服务端确认,进行第三次握手(确认位 ACK=1,确认号字段 ack=y+1),发送完毕后,客户端就进入 ESTABLISHED(连接已建立) 状态,当服务端接收到这个包时,也进入 ESTABLISHED(连接已建立) 状态。
为什么是三次握手?不是两次、四次? 第三次握手证明了客户端收信息的能力没问题
- 三次握手才可以阻止重复历史连接的初始化(主要原因)
- 三次握手才可以同步双方的初始序列号
- 三次握手才可以避免资源浪费
四次挥手:

为什么 TIME_WAIT 等待的时间是 2MSL?
MSL 是 Maximum Segment Lifetime,报文最大生存时间,它是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。因为 TCP 报文基于是 IP 协议的,而 IP 头中有一个 TTL 字段,是 IP 数据报可以经过的最大路由数,每经过一个处理他的路由器此值就减 1,当此值为 0 则数据报将被丢弃,同时发送 ICMP 报文通知源主机。
MSL 与 TTL 的区别: MSL 的单位是时间,而 TTL 是经过路由跳数。所以 MSL 应该要大于等于 TTL 消耗为 0 的时间,以确保报文已被自然消亡。
TTL 的值一般是 64,Linux 将 MSL 设置为 30 秒,意味着 Linux 认为数据报文经过 64 个路由器的时间不会超过 30 秒,如果超过了,就认为报文已经消失在网络中了。
TIME_WAIT 等待 2 倍的 MSL,比较合理的解释是: 网络中可能存在来自发送方的数据包,当这些发送方的数据包被接收方处理后又会向对方发送响应,所以一来一回需要等待 2 倍的时间。
比如,如果被动关闭方没有收到断开连接的最后的 ACK 报文,就会触发超时重发 FIN 报文,另一方接收到 FIN 后,会重发 ACK 给被动关闭方, 一来一去正好 2 个 MSL。
为什么是4次挥手,三次挥手行吗?
四次挥手是因为服务器可能还有数据发送给客户端,所以收到客户端的Fin报文只能一个ACK,然后发送完剩下的数据后,再发送fin给客户端,「**没有数据要发送」并且「开启了 TCP 延迟确认机制」,那么第二和第三次挥手就会合并传输,这样就出现了三次挥手。**当没有数据发送时,默认就是三次挥手,所以实际上抓包的话,3次挥手比四次挥手的情况还要多。
TCP相关面试题
TCP面向字节流/粘包拆包问题
TCP是面向字节流的,udp是面向报文的,怎么理解?
当用户消息用udp发送时,操作系统不会对消息拆分,发送出的udp报文的数据就是完整的用户数据。
但是TCP由于有发送窗口、拥塞窗口以及当前发送缓冲区的大小等条件,所以消息可能被拆分到不同的TCP包中(拆包)。
比如两个消息:hello和world,被不幸分成了两个报文,he和lloworld,那么就属于粘包了,需要自己找到边界。
如何解决粘包?
粘包的问题出现是因为不知道一个用户消息的边界在哪,如果知道了边界在哪,接收方就可以通过边界来划分出有效的用户消息。
一般有三种方式分包的方式:
- 固定长度的消息,例如规定每个消息都是64字节,这种方式效率不高,不太常用;
- 特殊字符作为边界:http的做法,HTTP 通过设置回车符、换行符作为 HTTP 报文协议的边界,消息中出现这俩字符需要转义;
- 自定义消息结构。
我们可以自定义一个消息结构,由包头和数据组成,其中包头包是固定大小的,而且包头里有一个字段来说明紧随其后的数据有多大。
比如这个消息结构体,首先 4 个字节大小的变量来表示数据长度,真正的数据则在后面。
struct {
u_int32_t message_length;
char message_data[];
} message;
当接收方接收到包头的大小(比如 4 个字节)后,就解析包头的内容,于是就可以知道数据的长度,然后接下来就继续读取数据,直到读满数据的长度,就可以组装成一个完整到用户消息来处理了。
自己的rpc项目如何解决粘包:
自定义的报文头部中,有头部长度和总长度两个字段,不定长的body长度就是总长度-头部长度
Http协议
http状态码

200:成功状态码,表示一切正常
301:表示永久重定向,说明请求的资源已经不存在了,需改用新的 URL 再次访问。
302:表示临时重定向,说明请求的资源还在,但暂时需要用另一个 URL 来访问
304:不具有跳转的含义,表示资源未修改,重定向已存在的缓冲文件,也称缓存重定向,也就是告诉客户端可以继续使用缓存资源,用于缓存控制。
400:表示客户端请求的报文有错误,但只是个笼统的错误
403:表示服务器禁止访问资源,并不是客户端的请求出错,可能是权限认证未通过
404:表示请求的资源在服务器上不存在或未找到,所以无法提供给客户端
500:与 400 类型,是个笼统通用的错误码,服务器发生了什么错误,我们并不知道。
502:通常是服务器作为网关或代理时返回的错误码,表示服务器自身工作正常,访问后端服务器发生了错误。
503:表示服务器当前很忙,暂时无法响应客户端,类似“网络服务正忙,请稍后重试”的意思。
http1.1/2/3的改进
本小结引用一下小林coding的文章片段:
HTTP/1.1 相比 HTTP/1.0 提高了什么性能?
HTTP/1.1 相比 HTTP/1.0 性能上的改进:
使用长连接的方式改善了 HTTP/1.0 短连接造成的性能开销。
支持管道(pipeline)网络传输,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出去,可以减少整体的响应时间。
但 HTTP/1.1 还是有性能瓶颈:
请求 / 响应头部(Header)未经压缩就发送,首部信息越多延迟越大。只能压缩 Body 的部分;
发送冗长的首部。每次互相发送相同的首部造成的浪费较多;
服务器是按请求的顺序响应的,如果服务器响应慢,会招致客户端一直请求不到数据,也就是队头阻塞;
没有请求优先级控制;
请求只能从客户端开始,服务器只能被动响应。
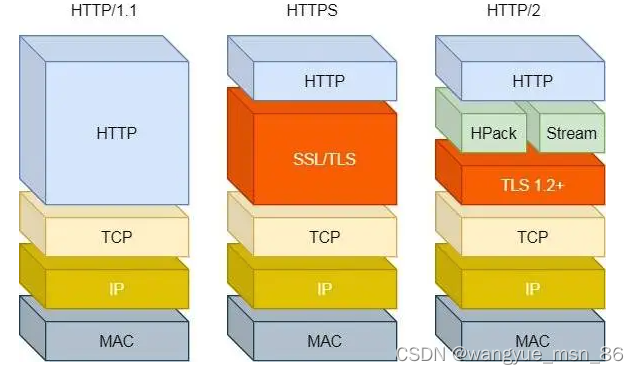
#HTTP/2 做了什么优化?
HTTP/2 协议是基于 HTTPS 的,所以 HTTP/2 的安全性也是有保障的。
那 HTTP/2 相比 HTTP/1.1 性能上的改进:
头部压缩
二进制格式
并发传输
服务器主动推送资源
- 头部压缩
HTTP/2 会压缩头(Header)如果你同时发出多个请求,他们的头是一样的或是相似的,那么,协议会帮你消除重复的部分。
这就是所谓的 HPACK 算法:在客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就提高速度了。
- 二进制格式
HTTP/2 不再像 HTTP/1.1 里的纯文本形式的报文,而是全面采用了二进制格式,头信息和数据体都是二进制,并且统称为帧(frame):头信息帧(Headers Frame)和数据帧(Data Frame)。
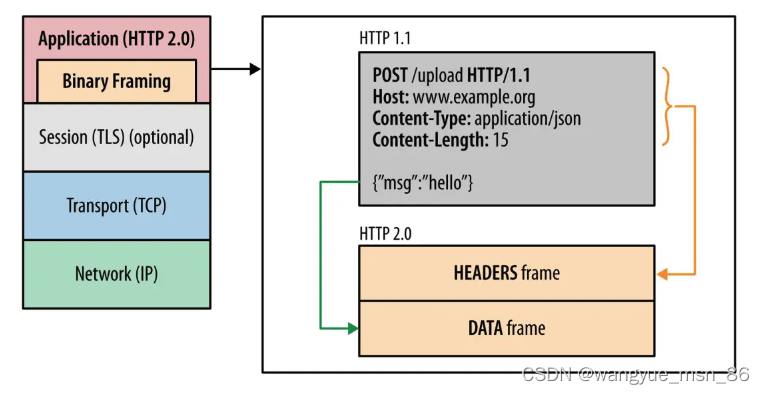
HTTP/1 与 HTTP/2
这样虽然对人不友好,但是对计算机非常友好,因为计算机只懂二进制,那么收到报文后,无需再将明文的报文转成二进制,而是直接解析二进制报文,这增加了数据传输的效率。
比如状态码 200 ,在 HTTP/1.1 是用 ‘2’‘0’‘0’ 三个字符来表示(二进制:00110010 00110000 00110000),共用了 3 个字节,如下图
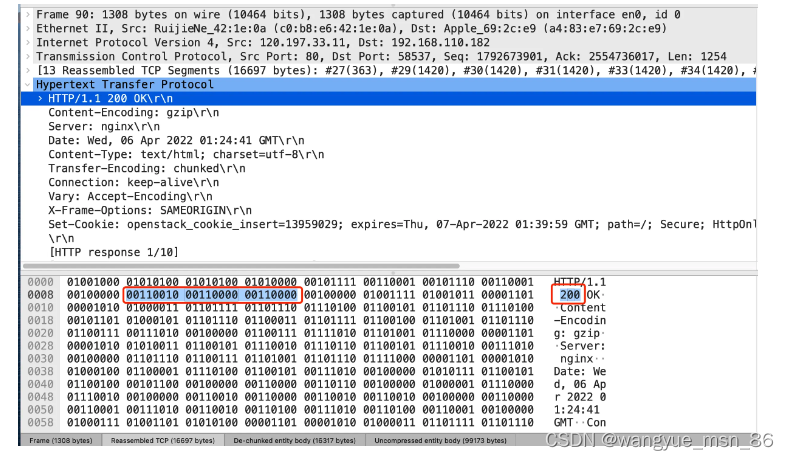
在 HTTP/2 对于状态码 200 的二进制编码是 10001000,只用了 1 字节就能表示,相比于 HTTP/1.1 节省了 2 个字节,如下图:
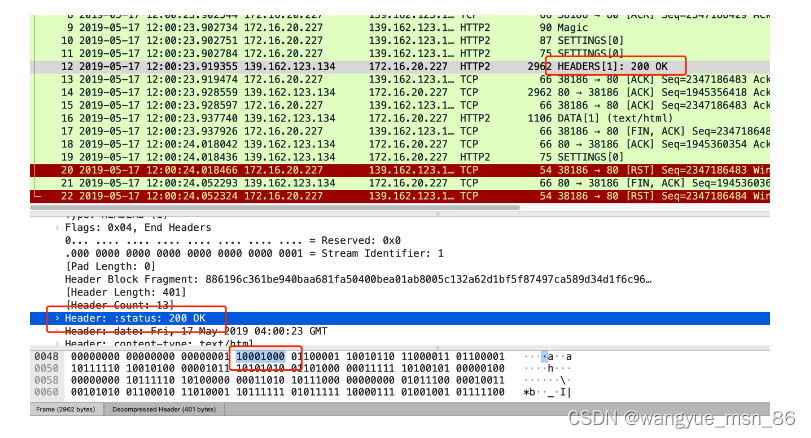
Header: :status: 200 OK 的编码内容为:1000 1000,那么表达的含义是什么呢?

最前面的 1 标识该 Header 是静态表中已经存在的 KV。(至于什么是静态表,可以看这篇:HTTP/2 牛逼在哪? (opens new window))
在静态表里,“:status: 200 ok” 静态表编码是 8,二进制即是 1000。
因此,整体加起来就是 1000 1000。
- 并发传输
我们都知道 HTTP/1.1 的实现是基于请求-响应模型的。同一个连接中,HTTP 完成一个事务(请求与响应),才能处理下一个事务,也就是说在发出请求等待响应的过程中,是没办法做其他事情的,如果响应迟迟不来,那么后续的请求是无法发送的,也造成了队头阻塞的问题。
而 HTTP/2 就很牛逼了,引出了 Stream 概念,多个 Stream 复用在一条 TCP 连接。
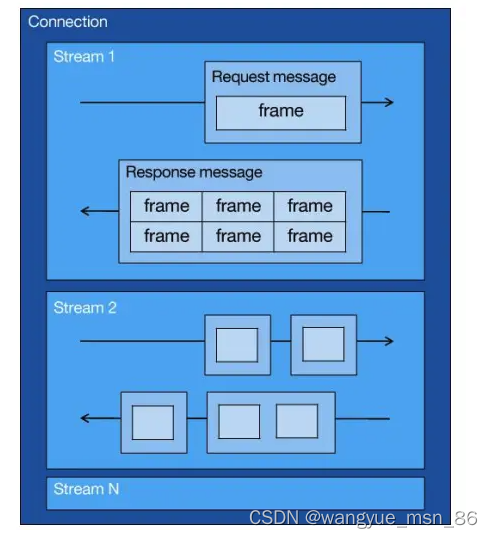
从上图可以看到,1 个 TCP 连接包含多个 Stream,Stream 里可以包含 1 个或多个 Message,Message 对应 HTTP/1 中的请求或响应,由 HTTP 头部和包体构成。Message 里包含一条或者多个 Frame,Frame 是 HTTP/2 最小单位,以二进制压缩格式存放 HTTP/1 中的内容(头部和包体)。
针对不同的 HTTP 请求用独一无二的 Stream ID 来区分,接收端可以通过 Stream ID 有序组装成 HTTP 消息,不同 Stream 的帧是可以乱序发送的,因此可以并发不同的 Stream ,也就是 HTTP/2 可以并行交错地发送请求和响应。
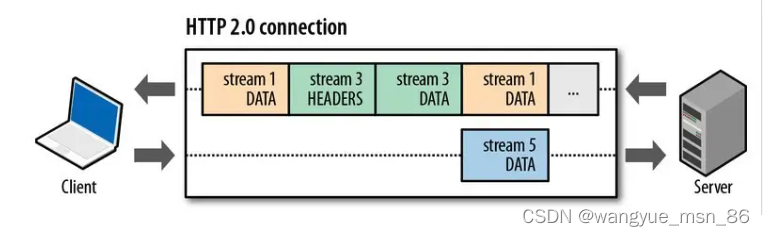
比如下图,服务端并行交错地发送了两个响应: Stream 1 和 Stream 3,这两个 Stream 都是跑在一个 TCP 连接上,客户端收到后,会根据相同的 Stream ID 有序组装成 HTTP 消息。
4、服务器推送
HTTP/2 还在一定程度上改善了传统的「请求 - 应答」工作模式,服务端不再是被动地响应,可以主动向客户端发送消息。
客户端和服务器双方都可以建立 Stream, Stream ID 也是有区别的,客户端建立的 Stream 必须是奇数号,而服务器建立的 Stream 必须是偶数号。
比如下图,Stream 1 是客户端向服务端请求的资源,属于客户端建立的 Stream,所以该 Stream 的 ID 是奇数(数字 1);Stream 2 和 4 都是服务端主动向客户端推送的资源,属于服务端建立的 Stream,所以这两个 Stream 的 ID 是偶数(数字 2 和 4)。
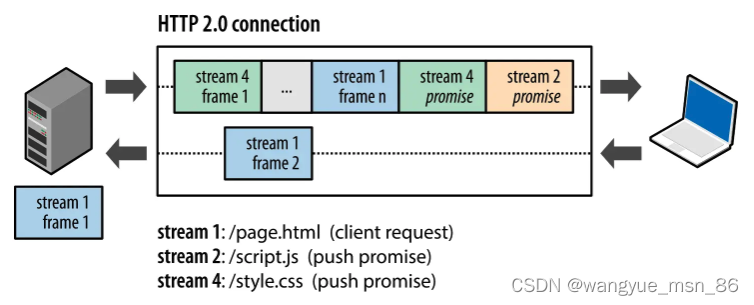
再比如,客户端通过 HTTP/1.1 请求从服务器那获取到了 HTML 文件,而 HTML 可能还需要依赖 CSS 来渲染页面,这时客户端还要再发起获取 CSS 文件的请求,需要两次消息往返,如下图左边部分:
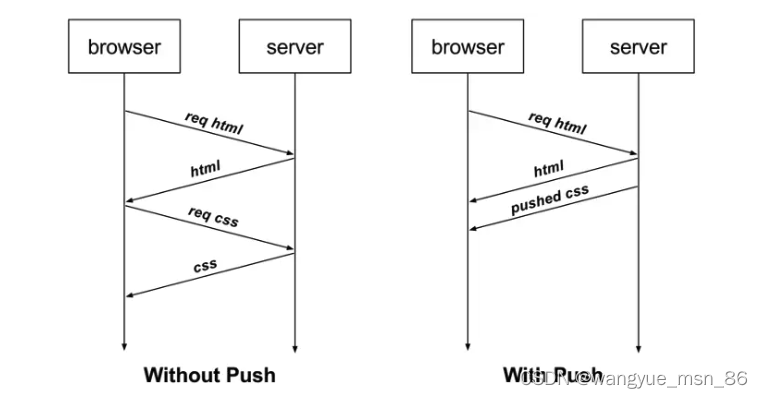
如上图右边部分,在 HTTP/2 中,客户端在访问 HTML 时,服务器可以直接主动推送 CSS 文件,减少了消息传递的次数。
HTTP/2 有什么缺陷?
HTTP/2 通过 Stream 的并发能力,解决了 HTTP/1 队头阻塞的问题,看似很完美了,但是 HTTP/2 还是存在“队头阻塞”的问题,只不过问题不是在 HTTP 这一层面,而是在 TCP 这一层。
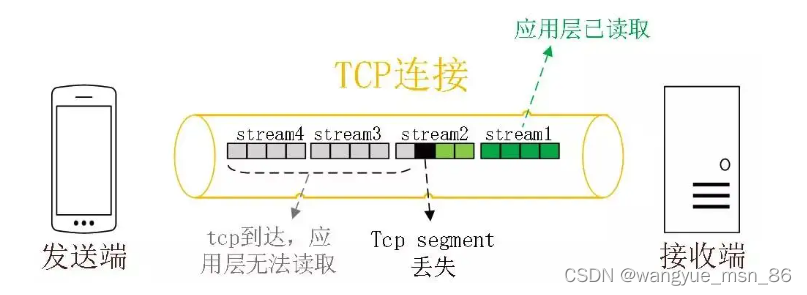
HTTP/2 是基于 TCP 协议来传输数据的,TCP 是字节流协议,TCP 层必须保证收到的字节数据是完整且连续的,这样内核才会将缓冲区里的数据返回给 HTTP 应用,那么当「前 1 个字节数据」没有到达时,后收到的字节数据只能存放在内核缓冲区里,只有等到这 1 个字节数据到达时,HTTP/2 应用层才能从内核中拿到数据,这就是 HTTP/2 队头阻塞问题。
举个例子,如下图:
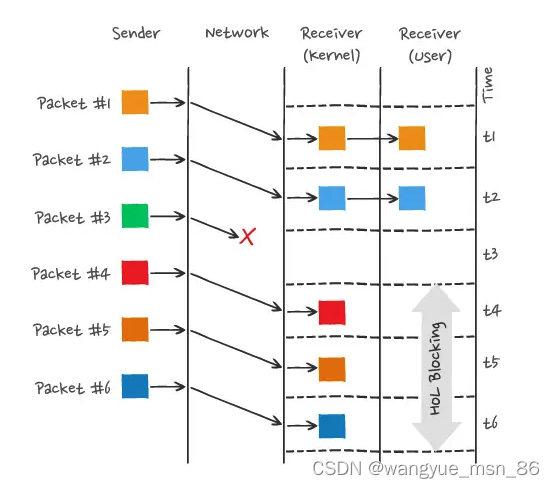
图中发送方发送了很多个 packet,每个 packet 都有自己的序号,你可以认为是 TCP 的序列号,其中 packet 3 在网络中丢失了,即使 packet 4-6 被接收方收到后,由于内核中的 TCP 数据不是连续的,于是接收方的应用层就无法从内核中读取到,只有等到 packet 3 重传后,接收方的应用层才可以从内核中读取到数据,这就是 HTTP/2 的队头阻塞问题,是在 TCP 层面发生的。
所以,一旦发生了丢包现象,就会触发 TCP 的重传机制,这样在一个 TCP 连接中的所有的 HTTP 请求都必须等待这个丢了的包被重传回来。
HTTP/3 做了哪些优化?
前面我们知道了 HTTP/1.1 和 HTTP/2 都有队头阻塞的问题:
HTTP/1.1 中的管道( pipeline)虽然解决了请求的队头阻塞,但是没有解决响应的队头阻塞,因为服务端需要按顺序响应收到的请求,如果服务端处理某个请求消耗的时间比较长,那么只能等响应完这个请求后, 才能处理下一个请求,这属于 HTTP 层队头阻塞。
HTTP/2 虽然通过多个请求复用一个 TCP 连接解决了 HTTP 的队头阻塞 ,但是一旦发生丢包,就会阻塞住所有的 HTTP 请求,这属于 TCP 层队头阻塞。
HTTP/2 队头阻塞的问题是因为 TCP,所以 HTTP/3 把 HTTP 下层的 TCP 协议改成了 UDP!
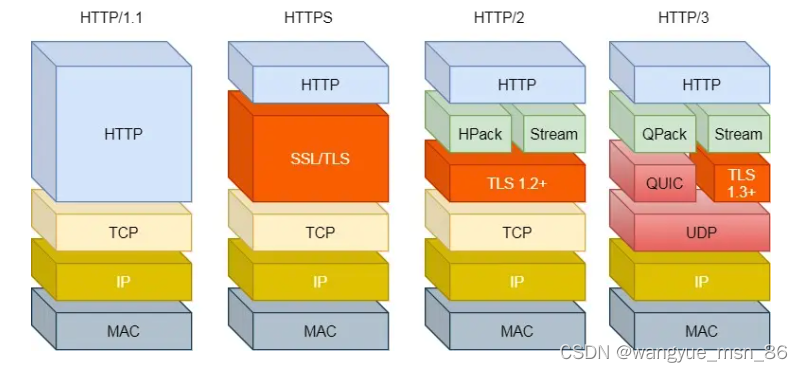
UDP 发送是不管顺序,也不管丢包的,所以不会出现像 HTTP/2 队头阻塞的问题。大家都知道 UDP 是不可靠传输的,但基于 UDP 的 QUIC 协议 可以实现类似 TCP 的可靠性传输。
QUIC 有以下 3 个特点。
无队头阻塞
更快的连接建立
连接迁移
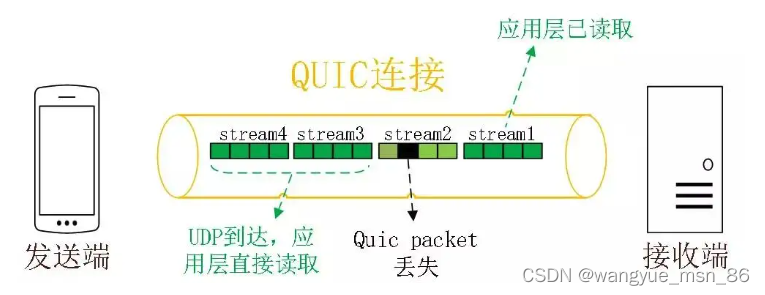
1、无队头阻塞
QUIC 协议也有类似 HTTP/2 Stream 与多路复用的概念,也是可以在同一条连接上并发传输多个 Stream,Stream 可以认为就是一条 HTTP 请求。
QUIC 有自己的一套机制可以保证传输的可靠性的。当某个流发生丢包时,只会阻塞这个流,其他流不会受到影响,因此不存在队头阻塞问题。这与 HTTP/2 不同,HTTP/2 只要某个流中的数据包丢失了,其他流也会因此受影响。
所以,QUIC 连接上的多个 Stream 之间并没有依赖,都是独立的,某个流发生丢包了,只会影响该流,其他流不受影响。
2、更快的连接建立
对于 HTTP/1 和 HTTP/2 协议,TCP 和 TLS 是分层的,分别属于内核实现的传输层、openssl 库实现的表示层,因此它们难以合并在一起,需要分批次来握手,先 TCP 握手,再 TLS 握手。
HTTP/3 在传输数据前虽然需要 QUIC 协议握手,但是这个握手过程只需要 1 RTT,握手的目的是为确认双方的「连接 ID」,连接迁移就是基于连接 ID 实现的。
但是 HTTP/3 的 QUIC 协议并不是与 TLS 分层,而是 QUIC 内部包含了 TLS,它在自己的帧会携带 TLS 里的“记录”,再加上 QUIC 使用的是 TLS/1.3,因此仅需 1 个 RTT 就可以「同时」完成建立连接与密钥协商,如下图:
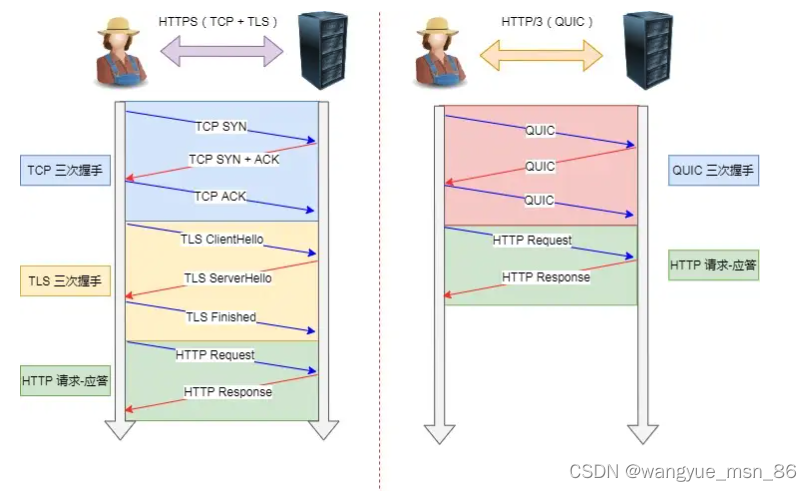
甚至,在第二次连接的时候,应用数据包可以和 QUIC 握手信息(连接信息 + TLS 信息)一起发送,达到 0-RTT 的效果。
如下图右边部分,HTTP/3 当会话恢复时,有效负载数据与第一个数据包一起发送,可以做到 0-RTT(下图的右下角):

3、连接迁移
基于 TCP 传输协议的 HTTP 协议,由于是通过四元组(源 IP、源端口、目的 IP、目的端口)确定一条 TCP 连接。
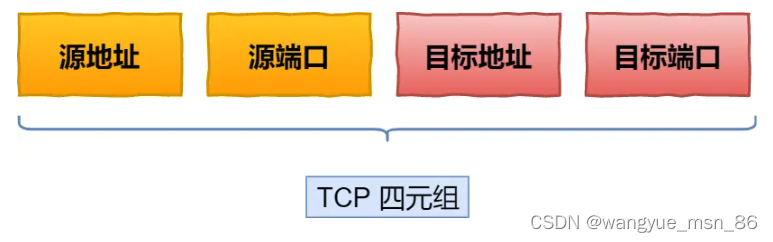
那么当移动设备的网络从 4G 切换到 WIFI 时,意味着 IP 地址变化了,那么就必须要断开连接,然后重新建立连接。而建立连接的过程包含 TCP 三次握手和 TLS 四次握手的时延,以及 TCP 慢启动的减速过程,给用户的感觉就是网络突然卡顿了一下,因此连接的迁移成本是很高的。
而 QUIC 协议没有用四元组的方式来“绑定”连接,而是通过连接 ID 来标记通信的两个端点,客户端和服务器可以各自选择一组 ID 来标记自己,因此即使移动设备的网络变化后,导致 IP 地址变化了,只要仍保有上下文信息(比如连接 ID、TLS 密钥等),就可以“无缝”地复用原连接,消除重连的成本,没有丝毫卡顿感,达到了连接迁移的功能。
所以, QUIC 是一个在 UDP 之上的伪 TCP + TLS + HTTP/2 的多路复用的协议。
QUIC 是新协议,对于很多网络设备,根本不知道什么是 QUIC,只会当做 UDP,这样会出现新的问题,因为有的网络设备是会丢掉 UDP 包的,而 QUIC 是基于 UDP 实现的,那么如果网络设备无法识别这个是 QUIC 包,那么就会当作 UDP包,然后被丢弃。
操作系统
零拷贝
DMA 的全称叫直接内存存取(Direct Memory Access),是一种允许外围设备(硬件子系统)直接访问系统主内存的机制。
DMA下读取磁盘数据流程如下:·
- 用户进程向 CPU 发起 read 系统调用读取数据,由用户态切换为内核态,然后一直阻塞等待数据的返回。
- CPU 在接收到指令以后对 DMA 磁盘控制器发起调度指令。
- DMA 磁盘控制器对磁盘发起 I/O 请求,将磁盘数据先放入磁盘控制器缓冲区,CPU 全程不参与此过程。
- 数据读取完成后,DMA 磁盘控制器会接受到磁盘的通知,将数据从磁盘控制器缓冲区拷贝到内核缓冲区。
- DMA 磁盘控制器向 CPU 发出数据读完的信号,由 CPU 负责将数据从内核缓冲区拷贝到用户缓冲区。
- 用户进程由内核态切换回用户态,解除阻塞状态。
整个数据传输操作是在一个 DMA 控制器的控制下进行的。CPU 除了在数据传输开始和结束时做一点处理外(开始和结束时候要做中断处理),在传输过程中 CPU 可以继续进行其他的工作。这样在大部分时间里,CPU 计算和 I/O 操作都处于并行操作,使整个计算机系统的效率大大提高(主要cpu速度比IO快很多,用来等IO操作不值当,所以引入DMA来处理IO)。
- 传统方式:四次用户态和内核态的切换,四次拷贝(两次cpu拷贝,两次DMA拷贝)
程序传统IO实际上是调用系统的read()和write()实现,通过read()把数据从硬盘读取到内核缓冲区,再复制到用户缓冲区;然后再通过write()写入到socket缓冲区,最后写入网卡设备:(网卡和磁盘差不多,都是需要进行IO的)
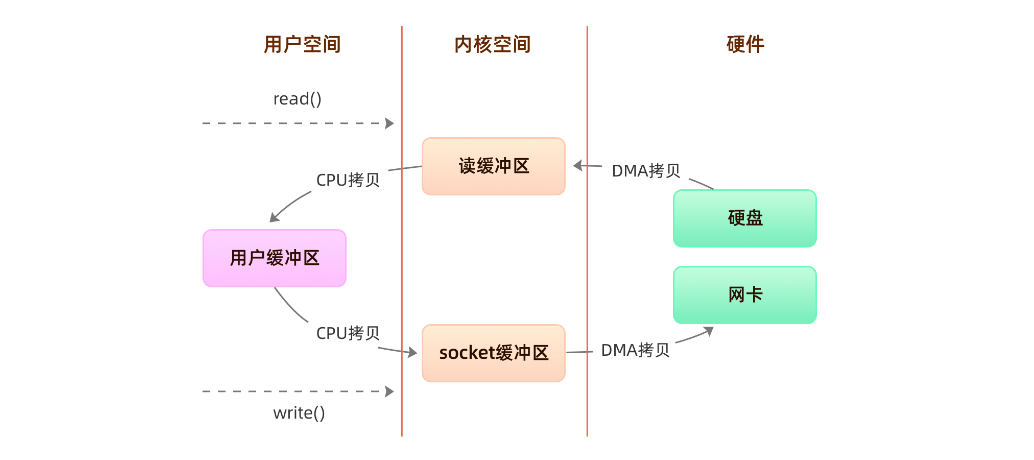
整个过程发生了四次用户态和内核态的切换还有四次IO拷贝, 具体流程是:
- 用户进程通过
read()方法向操作系统发起调用,此时上下文从用户态转向内核态 - DMA控制器把数据从硬盘中拷贝到读缓冲区
- CPU把读缓冲区数据拷贝到应用缓冲区,上下文从内核态转为用户态,
read()返回 - 用户进程通过
write()方法发起调用,上下文从用户态转为内核态 - CPU将应用缓冲区中数据拷贝到socket缓冲区
- DMA控制器把数据从socket缓冲区拷贝到网卡,上下文从内核态切换回用户态,
write()返回
图中的read方法,就是一个系统调用,让程序从用户态到内核态,比如java FileInputStream的read方法,里面调用了本地方法read0,这个read0相当于图中的read,是个系统调用
零拷贝实现方式
方案一、内存映射(mmap+write)
mmap 是 Linux 提供的一种内存映射文件方法,即将一个进程的地址空间中的一段虚拟地址映射到磁盘文件地址。
mmap 主要实现方式是将**读缓冲区的地址和用户缓冲区的地址进行映射,内核缓冲区和应用缓冲区共享,**从而减少了从读缓冲区到用户缓冲区的一次CPU拷贝,然而内核读缓冲区(read buffer)仍需将数据拷贝到内核写缓冲区(socket buffer)。
你可以想象,就相当于一个hashmap记录了用户缓冲区和读缓冲区的映射,用空间换时间,减少了用户缓冲区往socket缓冲区的一次cpu拷贝
所以有4次用户态和内核态的上下文切换和3次拷贝
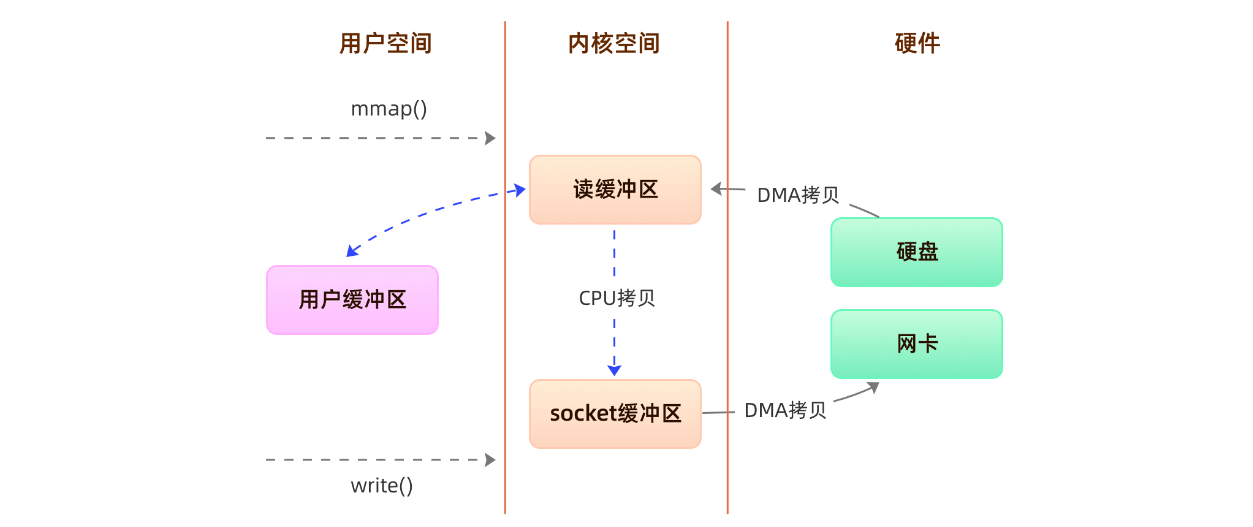
基于 mmap + write 系统调用的零拷贝方式,整个过程发生了4次用户态和内核态的上下文切换和3次拷贝,具体流程如下:
- 用户进程通过mmap()方法向操作系统发起调用,上下文从用户态转向内核态
- DMA控制器把数据从硬盘中拷贝到读缓冲区
- 上下文从内核态转为用户态,mmap调用返回
- 用户进程通过write()方法发起调用,上下文从用户态转为内核态
- CPU将读缓冲区中数据拷贝到socket缓冲区
- DMA控制器把数据从socket缓冲区拷贝到网卡,上下文从内核态切换回用户态,write()返回
mmap 主要的用处是提高 I/O 性能,特别是针对大文件。对于小文件,内存映射文件反而会导致碎片空间的浪费,因为内存映射总是要对齐页边界,最小单位是 4 KB,一个 5 KB 的文件将会映射占用 8 KB 内存,也就会浪费 3 KB 内存。
方案二、sendfile
就是把读和写变成一个整体了,不进行中间状态的转换了。读缓冲区直接在内核中拷贝到socket缓冲区,总共两次状态切换和三次拷贝。一次cpu拷贝
但是如果中间用户需要处理中间的数据,就不适用了
通过使用sendfile函数,数据可以直接在内核空间进行传输,因此避免了用户空间和内核空间的拷贝,同时由于使用sendfile替代了read+write从而节省了一次系统调用,也就是2次上下文切换。
 image-20230328162114261
image-20230328162114261
整个过程发生了2次用户态和内核态的上下文切换和3次拷贝,具体流程如下:
- 用户进程通过sendfile()方法向操作系统发起调用,上下文从用户态转向内核态
- DMA控制器把数据从硬盘中拷贝到读缓冲区
- CPU将读缓冲区中数据拷贝到socket缓冲区
- DMA控制器把数据从socket缓冲区拷贝到网卡,上下文从内核态切换回用户态,sendfile调用返回
sendfile方法IO数据对用户空间完全不可见,所以只能适用于完全不需要用户空间处理的情况,比如静态文件服务器。
sendfile 只适用于把数据从磁盘中读出来往 socket buffer 发送的场景
方案三、sendfile+DMA scatter/gather
没有cpu拷贝,只有两次DMA拷贝,这个DMA拷贝是避免不了的。
Linux2.4内核版本之后对sendfile做了进一步优化,通过引入新的硬件支持,这个方式叫做DMA Scatter/Gather 分散/收集功能。
它将读缓冲区中的数据描述信息–内存地址和偏移量记录到socket缓冲区,由 DMA 根据这些将数据从读缓冲区拷贝到网卡,相比之前版本减少了一次CPU拷贝的过程。
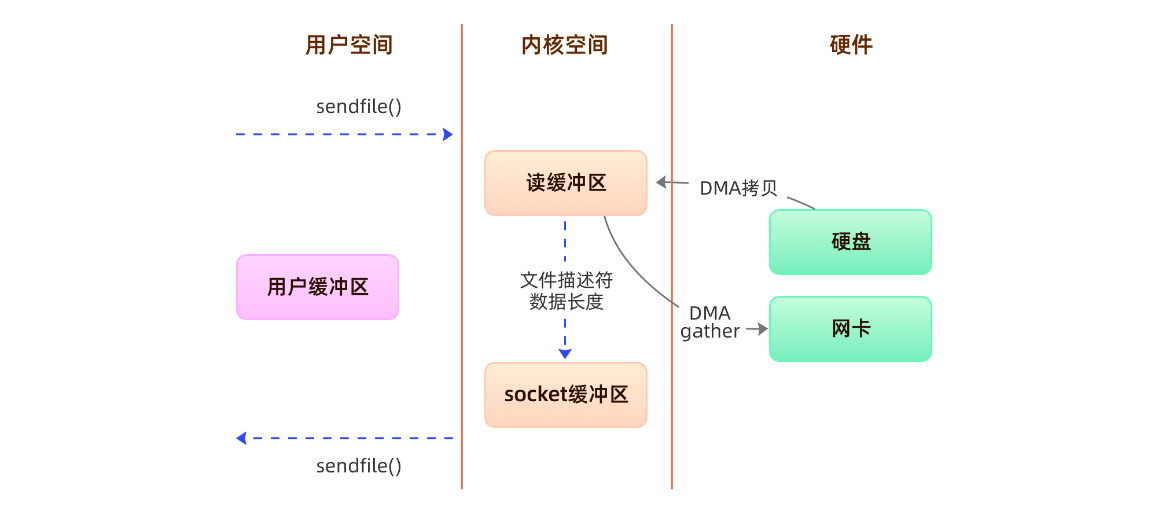
整个过程发生了2次用户态和内核态的上下文切换和2次拷贝,其中更重要的是完全没有CPU拷贝,具体流程如下:
- 用户进程通过sendfile()方法向操作系统发起调用,上下文从用户态转向内核态
- DMA控制器利用scatter把数据从硬盘中拷贝到读缓冲区离散存储
- CPU把读缓冲区中的文件描述符和数据长度发送到socket缓冲区
- DMA控制器根据文件描述符和数据长度,使用scatter/gather把数据从内核缓冲区拷贝到网卡
- sendfile()调用返回,上下文从内核态切换回用户态
DMA gather和sendfile一样数据对用户空间不可见,而且需要硬件支持,同时输入文件描述符只能是文件,但是过程中完全没有CPU拷贝过程,极大提升了性能。
总结:
- 由于CPU和IO速度的差异问题,产生了DMA技术,通过DMA搬运来减少CPU的等待时间。
- 传统的
IO read/write方式会产生2次DMA拷贝+2次CPU拷贝,同时有4次上下文切换。 - 而通过
mmap+write方式则产生2次DMA拷贝+1次CPU拷贝,4次上下文切换,通过内存映射减少了一次CPU拷贝,可以减少内存使用,适合大文件的传输。 sendfile方式是新增的一个系统调用函数,产生2次DMA拷贝+1次CPU拷贝,但是只有2次上下文切换。因为只有一次调用,减少了上下文的切换,但是用户空间对IO数据不可见,适用于静态文件服务器。sendfile+DMA gather方式产生2次DMA拷贝,没有CPU拷贝,而且也只有2次上下文切换。虽然极大地提升了性能,但是需要依赖新的硬件设备支持。
netty的零拷贝:主要是内存角度,拷贝数组的次数少了

CompositeByteBuf 零拷贝
Composite buffer实现了透明的零拷贝,将物理上的多个 Buffer 组合成了一个逻辑上完整的 CompositeByteBuf.
比如在网络编程中, 一个完整的 http 请求常常会被分散到多个 Buffer 中。用 CompositeByteBuf 很容易将多个分散的Buffer组装到一起,而无需额外的复制:
ByteBuf header = Unpooled.buffer();// 模拟http请求头
ByteBuf body = Unpooled.buffer();// 模拟http请求主体
CompositeByteBuf httpBuf = Unpooled.compositeBuffer();
// 这一步,不需要进行header和body的额外复制,httpBuf只是持有了header和body的引用
// 接下来就可以正常操作完整httpBuf了
httpBuf.addComponents(header, body);
复制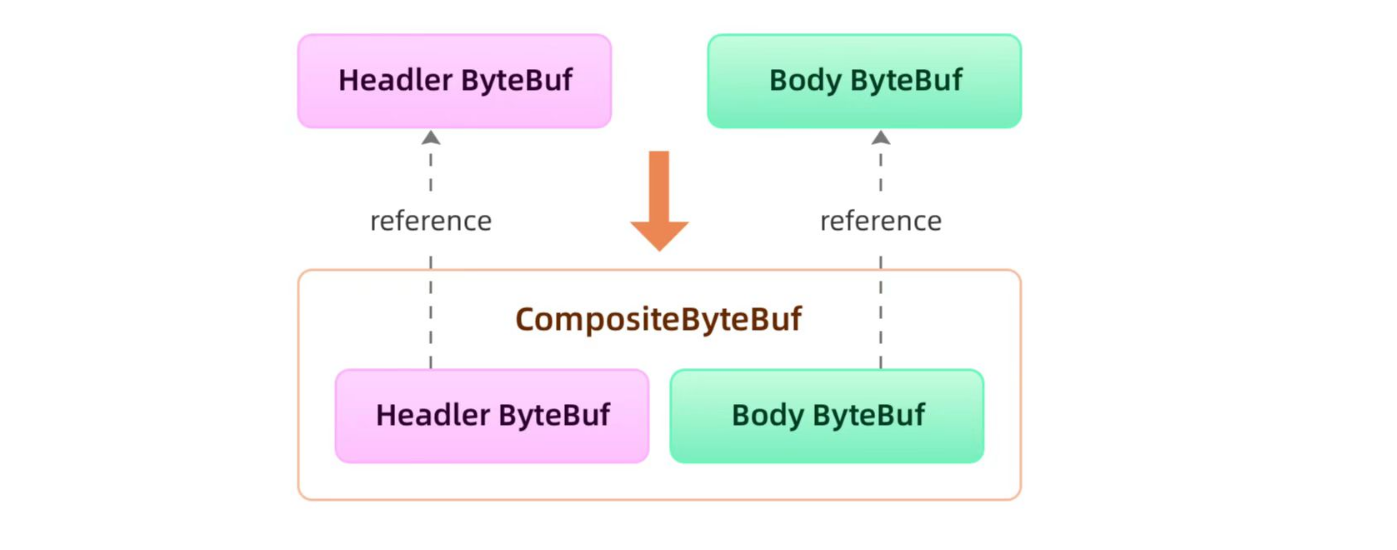
而 JDK ByteBuffer 完成这一需求:
ByteBuffer header = ByteBuffer.allocate(1024);// 模拟http请求头
ByteBuffer body = ByteBuffer.allocate(1024);// 模拟http请求主体
// 需要创建一个新的ByteBuffer来存放合并后的buffer信息,这涉及到复制操作
ByteBuffer httpBuffer = ByteBuffer.allocate(header.remaining() + body.remaining());
// 将header和body放入新创建的Buffer中
httpBuffer.put(header);
httpBuffer.put(body);
httpBuffer.flip();
相比于JDK,Netty的实现更合理,省去了不必要的内存复制,可以称得上是JVM层面的零拷贝。
(3)wrap 操作实现零拷贝
例如我们有一个 byte 数组, 我们希望将它转换为一个 ByteBuf 对象, 以便于后续的操作, 那么传统的做法是将此 byte 数组拷贝到 ByteBuf 中, 即:
byte[] bytes = ...
ByteBuf byteBuf = Unpooled.buffer();
byteBuf.writeBytes(bytes);
这样的操作是有一次额外的拷贝,如果使用Unpooled相关的方法,包装这个byte数组生成一个新的的ByteBuf,而不需要进行拷贝,如:
byte[] bytes = ...
ByteBuf byteBuf = Unpooled.wrappedBuffer(bytes);
Unpooled.wrappedBuffer 方法来将 bytes 包装成为一个 UnpooledHeapByteBuf 对象, 而在包装的过程中, 是不会有拷贝操作的. 即最后我们生成的生成的 ByteBuf 对象是和 bytes 数组共用了同一个存储空间, 对 bytes 的修改也会反映到 ByteBuf 对象中
Unpooled 提供的方法可以将一个或多个 buffer 包装为一个 ByteBuf 对象, 从而避免了拷贝操作.
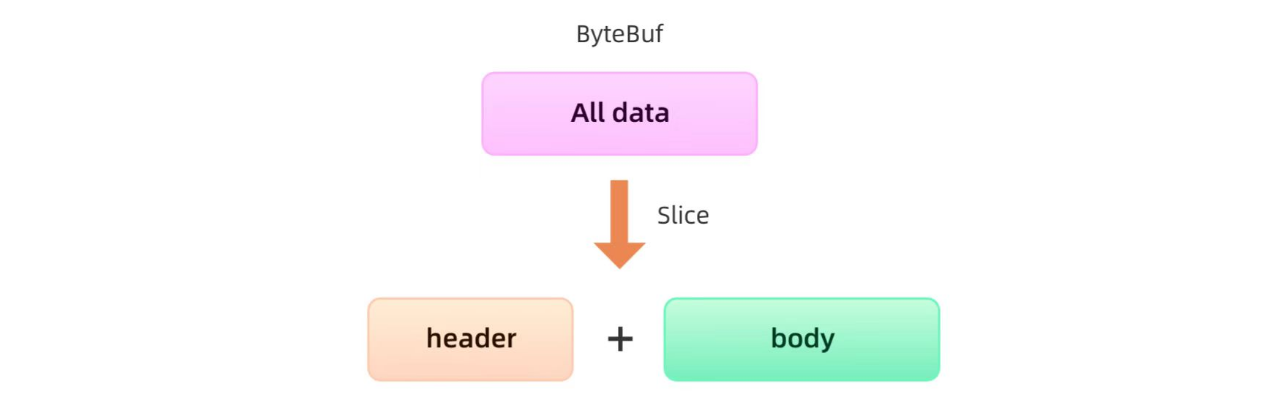
(4)通过 slice 操作实现零拷贝
slice 操作和 wrap 操作刚好相反, Unpooled.wrappedBuffer 可以将多个 ByteBuf 合并为一个 而 slice 操作将一个 ByteBuf 切片为多个共享一个存储区域的 ByteBuf 对象,如:
ByteBuf byteBuf = ...
ByteBuf header = byteBuf.slice(0, 5);
ByteBuf body = byteBuf.slice(5, 10);
用 slice 方法产生 byteBuf 的过程是没有拷贝操作的, header 和 body 对象在内部其实是共享了 byteBuf 存储空间的不同部分而已。
设计模式
你用过哪些设计模式?
单例模式
单例模式(Singleton Pattern)是 Java 中最简单的设计模式之一。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。这个类提供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。
单例模式的主要有以下角色:
- 单例类。只能创建一个实例的类
- 访问类。使用单例类
面试要用双检查:
/**
* 双重检查方式
*/
public class Singleton {
//私有构造方法
private Singleton() {}
private static volatile Singleton instance;
//对外提供静态方法获取该对象
public static Singleton getInstance() {
//第一次判断,如果instance不为null,不进入抢锁阶段,直接返回实际
if(instance == null) {
synchronized (Singleton.class) {
//抢到锁之后再次判断是否为空
if(instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
单例设计模式分类两种:
饿汉式:类加载就会导致该单实例对象被创建
懒汉式:类加载不会导致该单实例对象被创建,而是首次使用该对象时才会创建
-
饿汉式-方式1(静态变量方式)
/** * 饿汉式 * 静态变量创建类的对象 */ public class Singleton { //私有构造方法 private Singleton() {} //在成员位置创建该类的对象 private static Singleton instance = new Singleton(); //对外提供静态方法获取该对象 public static Singleton getInstance() { return instance; } }说明:
该方式在成员位置声明Singleton类型的静态变量,并创建Singleton类的对象instance。instance对象是随着类的加载而创建的。如果该对象足够大的话,而一直没有使用就会造成内存的浪费。
-
饿汉式-方式2(静态代码块方式)
/** * 恶汉式 * 在静态代码块中创建该类对象 */ public class Singleton { //私有构造方法 private Singleton() {} //在成员位置创建该类的对象 private static Singleton instance; static { instance = new Singleton(); } //对外提供静态方法获取该对象 public static Singleton getInstance() { return instance; } }说明:
该方式在成员位置声明Singleton类型的静态变量,而对象的创建是在静态代码块中,也是对着类的加载而创建。所以和饿汉式的方式1基本上一样,当然该方式也存在内存浪费问题。
-
懒汉式-方式1(线程不安全)
/** * 懒汉式 * 线程不安全 */ public class Singleton { //私有构造方法 private Singleton() {} //在成员位置创建该类的对象 private static Singleton instance; //对外提供静态方法获取该对象 public static Singleton getInstance() { if(instance == null) { instance = new Singleton(); } return instance; } }说明:
从上面代码我们可以看出该方式在成员位置声明Singleton类型的静态变量,并没有进行对象的赋值操作,那么什么时候赋值的呢?当调用getInstance()方法获取Singleton类的对象的时候才创建Singleton类的对象,这样就实现了懒加载的效果。但是,如果是多线程环境,会出现线程安全问题。
-
懒汉式-方式2(线程安全)
/** * 懒汉式 * 线程安全 */ public class Singleton { //私有构造方法 private Singleton() {} //在成员位置创建该类的对象 private static Singleton instance; //对外提供静态方法获取该对象 public static synchronized Singleton getInstance() { if(instance == null) { instance = new Singleton(); } return instance; } }说明:
该方式也实现了懒加载效果,同时又解决了线程安全问题。但是在getInstance()方法上添加了synchronized关键字,导致该方法的执行效果特别低。从上面代码我们可以看出,其实就是在初始化instance的时候才会出现线程安全问题,一旦初始化完成就不存在了。
-
懒汉式-方式3(双重检查锁)
再来讨论一下懒汉模式中加锁的问题,对于
getInstance()方法来说,绝大部分的操作都是读操作,读操作是线程安全的,所以我们没必让每个线程必须持有锁才能调用该方法,我们需要调整加锁的时机。由此也产生了一种新的实现模式:双重检查锁模式/** * 双重检查方式 */ public class Singleton { //私有构造方法 private Singleton() {} private static Singleton instance; //对外提供静态方法获取该对象 public static Singleton getInstance() { //第一次判断,如果instance不为null,不进入抢锁阶段,直接返回实例 if(instance == null) { synchronized (Singleton.class) { //抢到锁之后再次判断是否为null if(instance == null) { instance = new Singleton(); } } } return instance; } }双重检查锁模式是一种非常好的单例实现模式,解决了单例、性能、线程安全问题,上面的双重检测锁模式看上去完美无缺,其实是存在问题,在多线程的情况下,可能会出现空指针问题,出现问题的原因是JVM在实例化对象的时候会进行优化和指令重排序操作。
要解决双重检查锁模式带来空指针异常的问题,只需要使用
volatile关键字,volatile关键字可以保证可见性和有序性。/** * 双重检查方式 */ public class Singleton { //私有构造方法 private Singleton() {} private static volatile Singleton instance; //对外提供静态方法获取该对象 public static Singleton getInstance() { //第一次判断,如果instance不为null,不进入抢锁阶段,直接返回实际 if(instance == null) { synchronized (Singleton.class) { //抢到锁之后再次判断是否为空 if(instance == null) { instance = new Singleton(); } } } return instance; } }小结:
添加
volatile关键字之后的双重检查锁模式是一种比较好的单例实现模式,能够保证在多线程的情况下线程安全也不会有性能问题。 -
懒汉式-方式4(静态内部类方式)
静态内部类单例模式中实例由内部类创建,由于 JVM 在加载外部类的过程中, 是不会加载静态内部类的, 只有内部类的属性/方法被调用时才会被加载, 并初始化其静态属性。静态属性由于被
static修饰,保证只被实例化一次,并且严格保证实例化顺序。/** * 静态内部类方式 */ public class Singleton { //私有构造方法 private Singleton() {} private static class SingletonHolder { private static final Singleton INSTANCE = new Singleton(); } //对外提供静态方法获取该对象 public static Singleton getInstance() { return SingletonHolder.INSTANCE; } }说明:
第一次加载Singleton类时不会去初始化INSTANCE,只有第一次调用getInstance,虚拟机加载SingletonHolder
并初始化INSTANCE,这样不仅能确保线程安全,也能保证 Singleton 类的唯一性。
小结:
静态内部类单例模式是一种优秀的单例模式,是开源项目中比较常用的一种单例模式。在没有加任何锁的情况下,保证了多线程下的安全,并且没有任何性能影响和空间的浪费。
-
枚举方式
枚举类实现单例模式是极力推荐的单例实现模式,因为枚举类型是线程安全的,并且只会装载一次,设计者充分的利用了枚举的这个特性来实现单例模式,枚举的写法非常简单,而且枚举类型是所用单例实现中唯一一种不会被破坏的单例实现模式。
/** * 枚举方式 */ public enum Singleton { INSTANCE; }说明:
枚举方式属于饿汉式方式。
工厂模式
简单工厂,抽象工厂
策略模式
策略模式的主要角色如下:
- 抽象策略(Strategy)类:这是一个抽象角色,通常由一个接口或抽象类实现。此角色给出所有的具体策略类所需的接口。
- 具体策略(Concrete Strategy)类:实现了抽象策略定义的接口,提供具体的算法实现或行为。
- 环境(Context)类:持有一个策略类的引用,最终给客户端调用。
【例】促销活动
一家百货公司在定年度的促销活动。针对不同的节日(春节、中秋节、圣诞节)推出不同的促销活动,由促销员将促销活动展示给客户。类图如下: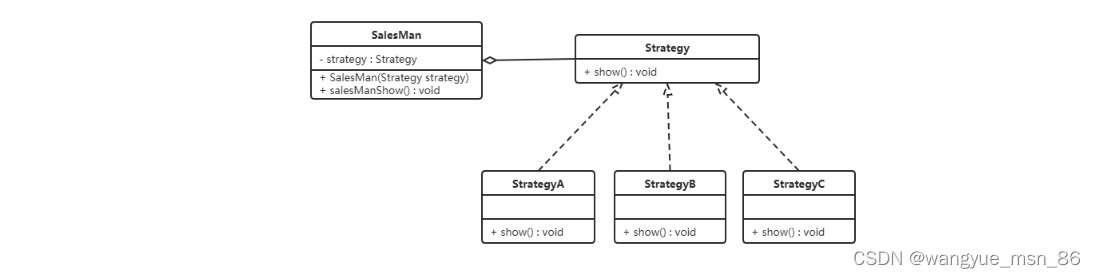
代码如下:
定义百货公司所有促销活动的共同接口
public interface Strategy {
void show();
}
定义具体策略角色(Concrete Strategy):每个节日具体的促销活动
//为春节准备的促销活动A
public class StrategyA implements Strategy {
public void show() {
System.out.println("买一送一");
}
}
//为中秋准备的促销活动B
public class StrategyB implements Strategy {
public void show() {
System.out.println("满200元减50元");
}
}
//为圣诞准备的促销活动C
public class StrategyC implements Strategy {
public void show() {
System.out.println("满1000元加一元换购任意200元以下商品");
}
}
定义环境角色(Context):用于连接上下文,即把促销活动推销给客户,这里可以理解为销售员
public class SalesMan {
//持有抽象策略角色的引用
private Strategy strategy;
public SalesMan(Strategy strategy) {
this.strategy = strategy;
}
//向客户展示促销活动
public void salesManShow(){
strategy.show();
}
}
1,优点:
-
策略类之间可以自由切换
由于策略类都实现同一个接口,所以使它们之间可以自由切换。
-
易于扩展
增加一个新的策略只需要添加一个具体的策略类即可,基本不需要改变原有的代码,符合“开闭原则“
-
避免使用多重条件选择语句(if else),充分体现面向对象设计思想。
2,缺点:
- 客户端必须知道所有的策略类,并自行决定使用哪一个策略类。
- 策略模式将造成产生很多策略类,可以通过使用享元模式在一定程度上减少对象的数量。
使用场景
- 一个系统需要动态地在几种算法中选择一种时,可将每个算法封装到策略类中。
- 一个类定义了多种行为,并且这些行为在这个类的操作中以多个条件语句的形式出现,可将每个条件分支移入它们各自的策略类中以代替这些条件语句。
- 系统中各算法彼此完全独立,且要求对客户隐藏具体算法的实现细节时。
- 系统要求使用算法的客户不应该知道其操作的数据时,可使用策略模式来隐藏与算法相关的数据结构。
- 多个类只区别在表现行为不同,可以使用策略模式,在运行时动态选择具体要执行的行为。
JavaSE
对象头信息
Java对象信息:
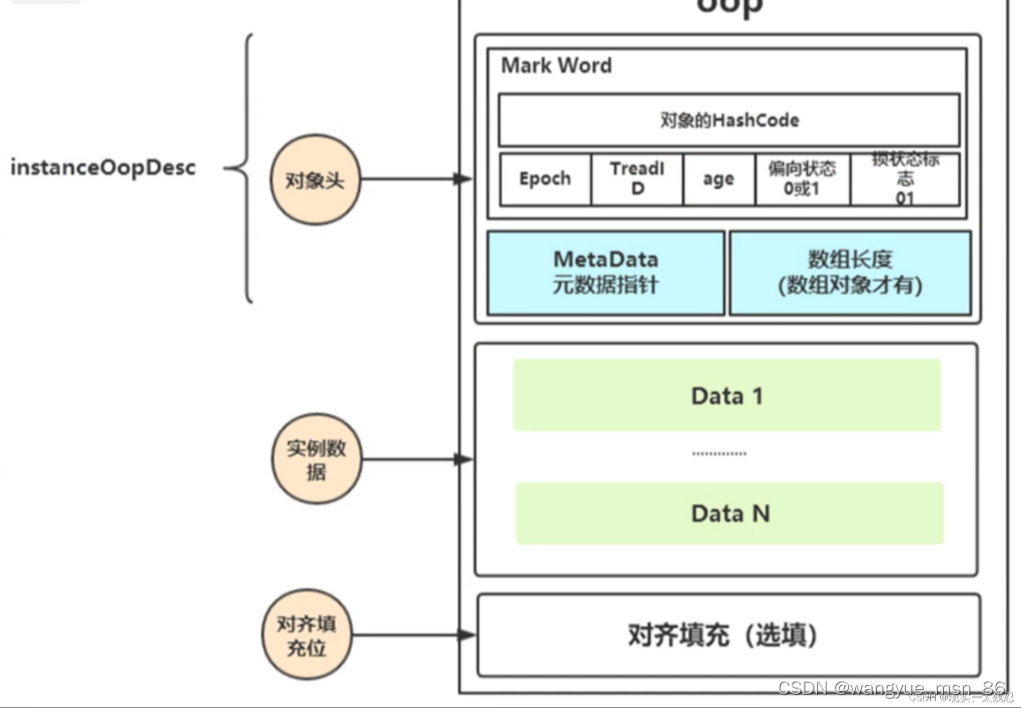
对象头、实例数据,填充位:
对象头里还有Mark word ,元数据指针指向方法区的类型信,数组长度(数组才有)
64位虚拟机Markword情况

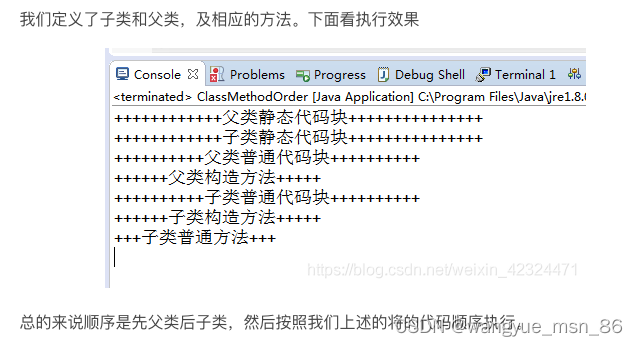
代码执行顺序:
下面我们来讨论下如果类存在父类的情况下,代码执行顺序。其实执行顺序还是按照上述给出类代码的执行顺序
public class ClassMethodOrder {
public static void main(String[] args) {
Apple apple = new Apple();
apple.getName("hello");
}
}
class Fruit {
static{
System.out.println("++++++++++++父类静态代码块+++++++++++++++");
}
{
System.out.println("++++++++++父类普通代码块++++++++++");
}
public Fruit() {
System.out.println("++++++父类构造方法+++++");
}
public void getName(String name) {
System.out.println("+++父类普通方法+++");
}
}
class Apple extends Fruit{
static{
System.out.println("++++++++++++子类静态代码块+++++++++++++++");
}
{
System.out.println("++++++++++子类普通代码块++++++++++");
}
public Apple() {
System.out.println("++++++子类构造方法+++++");
}
public void getName(String name) {
System.out.println("+++子类普通方法+++");
}
父类的总是要先执行的:
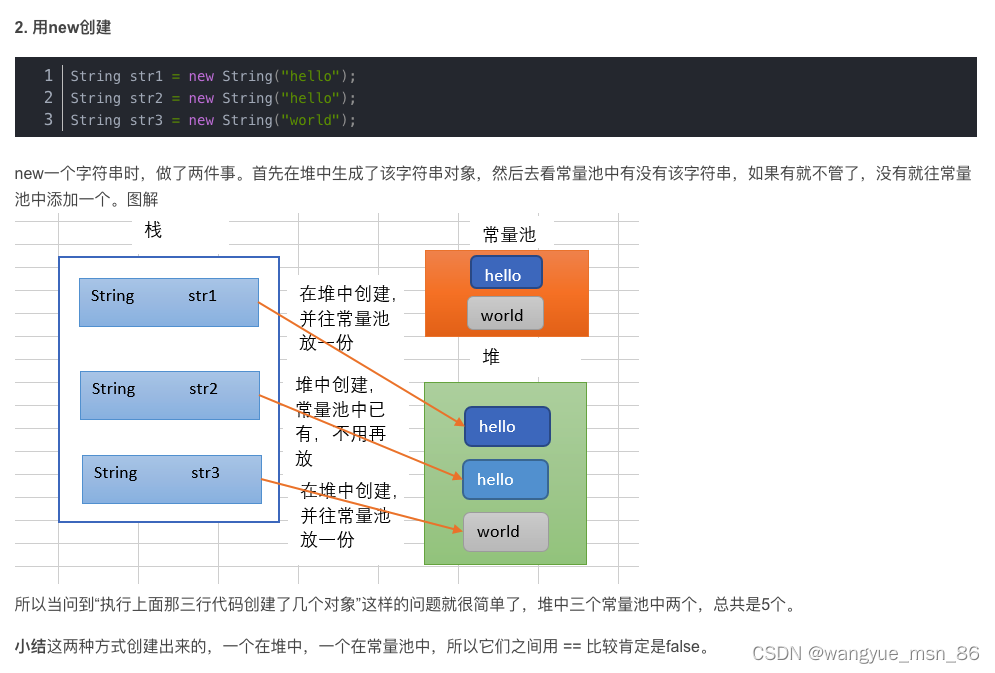
String
创建了几次字符串?
String类型为什么设计为不可变的?
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
1、字符串常量池
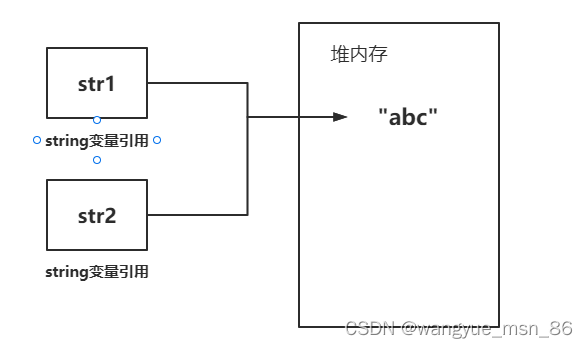
在Java中,由于会大量的使用String常量,如果每一次声明一个String都创建一个String对象,那将会造成极大的空间资源的浪费。Java提出了String pool的概念,在堆内存中开辟一块存储空间String pool,当初始化一个String变量时,如果该字符串已经存在了,就不会去创建一个新的字符串变量,而是会返回已经存在了的字符串的引用。
如果字符串是可变的,某一个字符串变量改变了其值,那么其他string引用它的就会发生错误,String pool将不能够实现!
2.设计成不可变是线程安全的
因为读的时候并发是不会造成线程安全问题的,并且也没法写,所以string可以在多线程的情况下放心使用,如果写的话,是创建了新的线程,这一点有点写时复制的思想。
3、避免安全问题
在网络连接和数据库连接中字符串常常作为参数,例如,网络连接地址URL,文件路径path,反射机制所需要的String参数。其不可变性可以保证连接的安全性。如果字符串是可变的,黑客就有可能改变字符串指向对象的值,那么会引起很严重的安全问题。
因为String是不可变的,所以它的值是不可改变的。但由于String不可变,也就没有任何方式能修改字符串的值,每一次修改都将产生新的字符串,如果使用char[]来保存密码,仍然能够将其中所有的元素设置为空和清零,也不会被放入字符串缓存池中,用字符串数组来保存密码会更好。
4、加快字符串处理速度
由于String是不可变的,保证了hashcode的唯一性,于是在创建对象时其hashcode就可以放心的缓存了,不需要重新计算。这也就是Map喜欢将String作为Key的原因,处理速度要快过其它的键对象。所以HashMap中的键往往都使用String。
字符串是重写了hashcode方法的,那么是如何把字符串类型的值变成int类型的hashcode的呢?
public int hashCode() {
int h = hash;
if (h == 0 && !hashIsZero) {
h = isLatin1() ? StringLatin1.hashCode(value)
: StringUTF16.hashCode(value);
if (h == 0) {
hashIsZero = true;
} else {
hash = h;
}
}
return h;
}
可以看到hash是一个缓存,曾经如果计算过hash就可以直接拿缓存了,因为string不可变,所以计算一次之后就不用重复计算了。
那么string到底是怎么把byte数组变成hashcode的呢,看StringLatin1的hashCode方法
public static int hashCode(byte[] value) {
int h = 0;
for (byte v : value) {
h = 31 * h + (v & 0xff);
//更新哈希值。这里使用了一个经典的哈希算法,通过不断乘以 31 并加上当前字节的值。(v & 0xff) 用于确保将字节视为无符号整数,因为 Java 的字节是有符号的,取与 0xff 的按位与操作可以将其转换为无符号整数。
}
return h;
}
很简单,把byte的值,string每一个字节是一个ascii码,比如ABC,是65 66 67,按照上面的规则进行计算,但是这样算出来的不是完全不发生冲突的。
异常
异常执行顺序:try发生异常后的代码没有执行
public static void main(String[] args) {
System.out.println("try之前的代码");
try{
System.out.println("try中发生异常前部分");
int i = 1/0;
System.out.println("try中发生异常后部分");
}catch(Exception e){
System.out.println("catch异常啦");
}finally {
System.out.println("finally部分");
}
System.out.println("try之后的代码");
}
try之前的代码
try中发生异常前部分
catch异常啦
finally部分
try之后的代码
有return的情况:
public int test() {
int i = 0;
try {
i++;
//i = i / 0; 有没有异常
return i++;
} catch (Exception e) {
i++;
return i++;
} finally {
return ++i;
}
}
// 如果没有异常 走的顺序: try > try的return > finally的return i最终结果是3
// 如果没有异常 走的顺序: try > catch > catch的return > finally的return i最终结果是4
集合
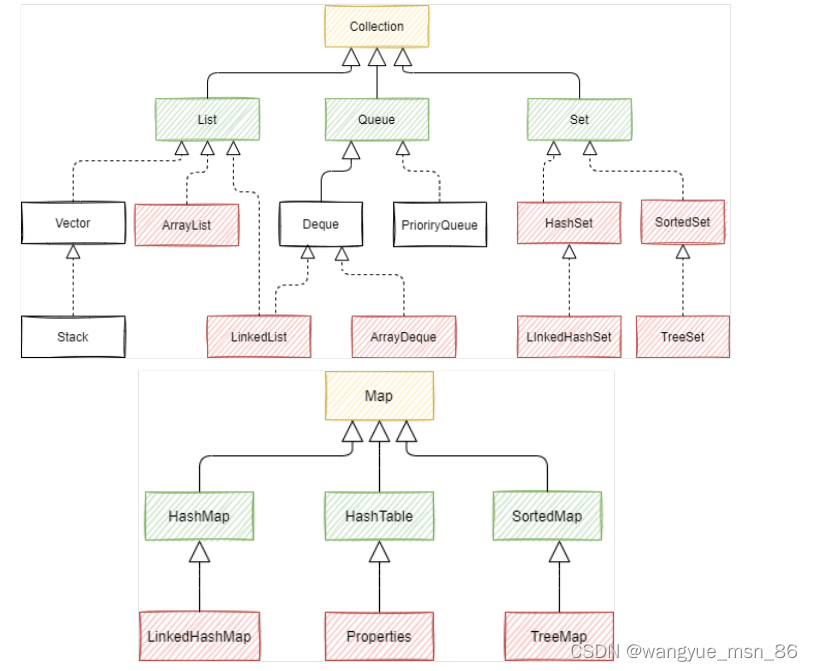
Java集合图:
ArrayList
ArrayList 的底层是动态数组,它的容量能动态增长。在添加大量元素前,应用可以使用ensureCapacity 操作增加 ArrayList 实例的容量。ArrayList 继承了 AbstractList ,并实现了 List 接口。

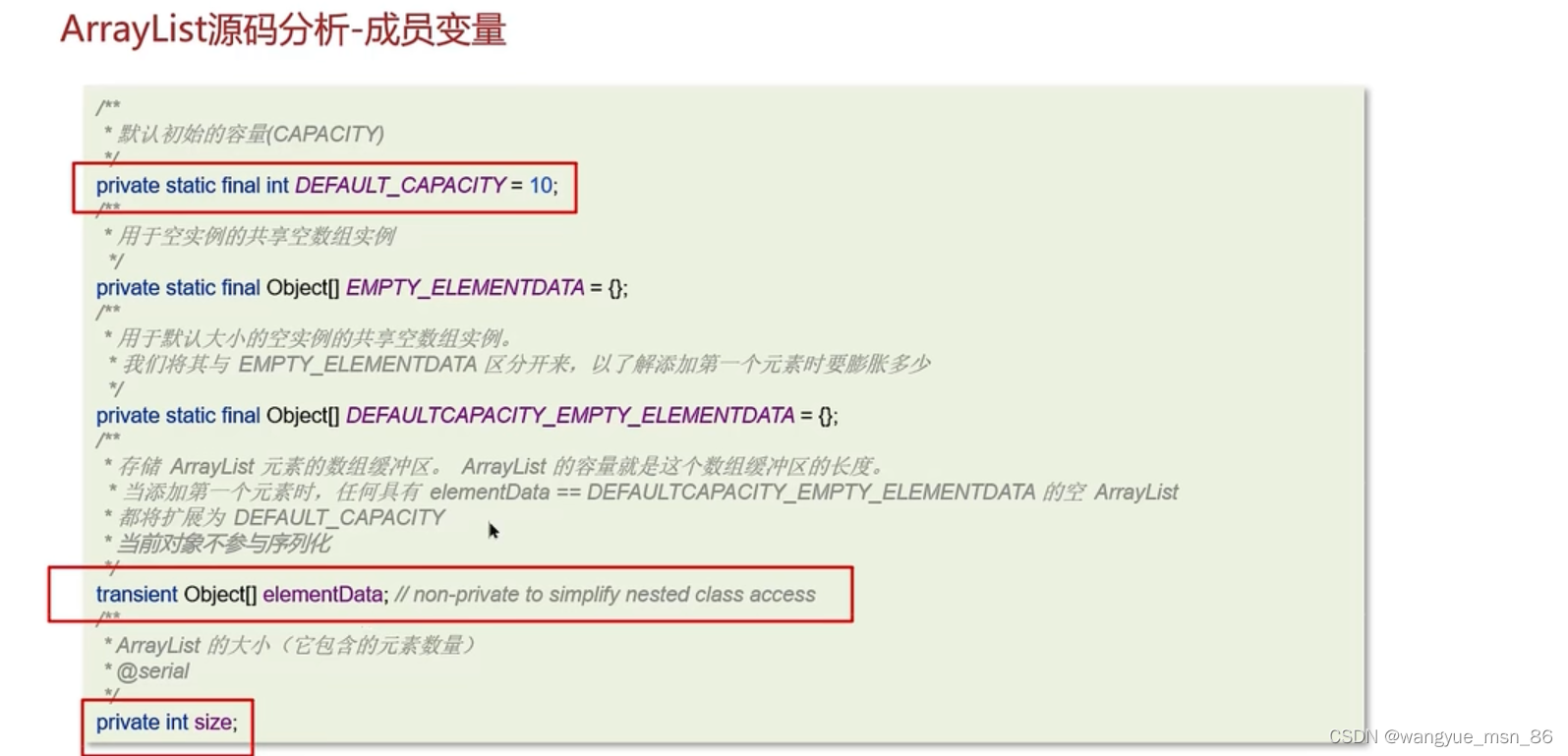
ArrayList成员变量:
elementData是真实存放数据的数组
size是ArrayList的大小
defaultcapacity指定了第一次初始化的容量 就是10
三个构造函数:无参的,指定初始化容量的 根据别的集合构造的

无参构造执行分析:
第一次,确认容量,calculateCapacity返回的是defalutcapacity,是10,然后扩容,到grow方法扩容,老容量是0,所以执行第一次初始化为10的操作,刚new的时候arraylist是没有容量的,第一个add会扩容到10
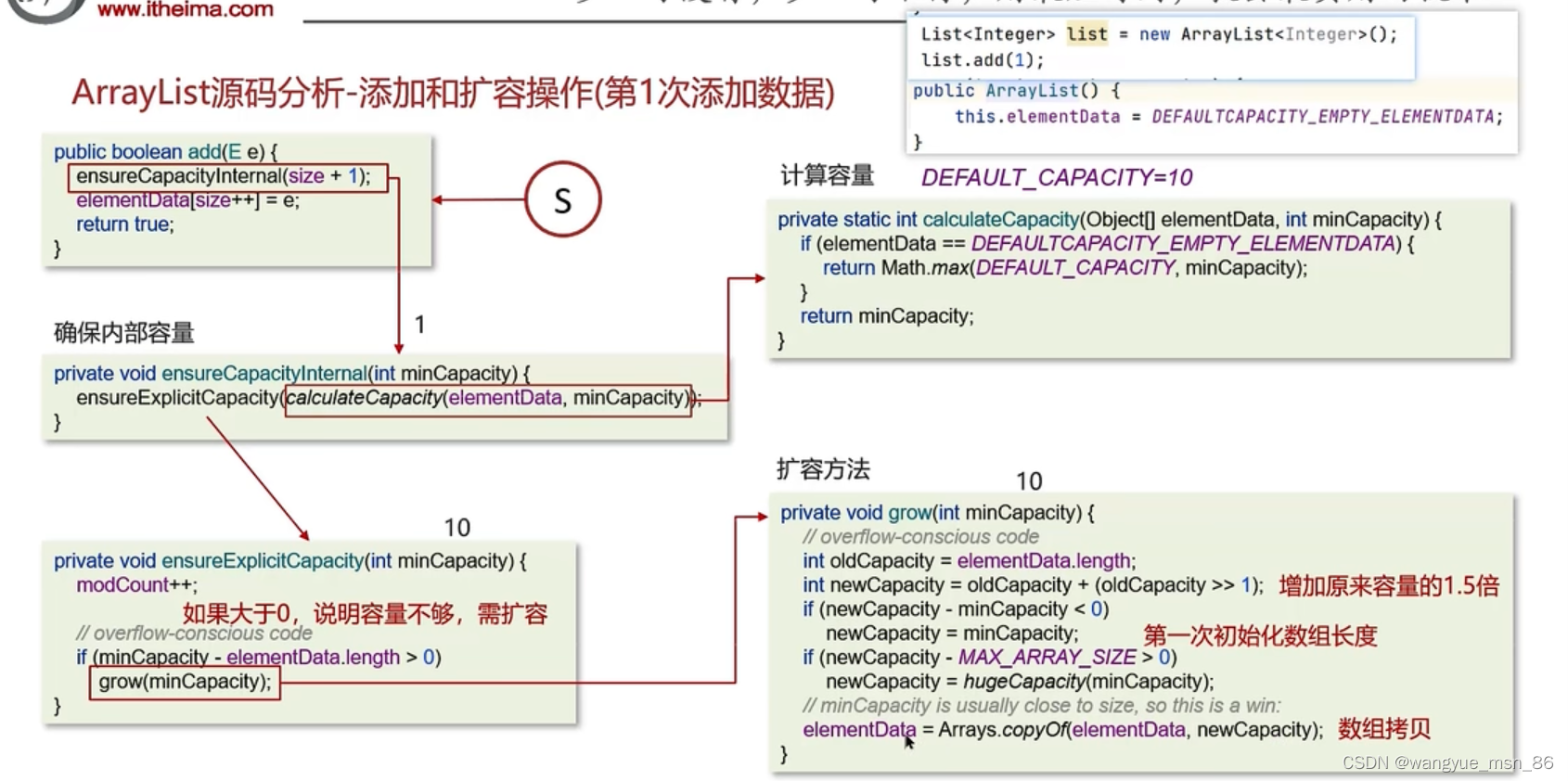
第二次到第10次,都没有超过容量,直接添加就行了
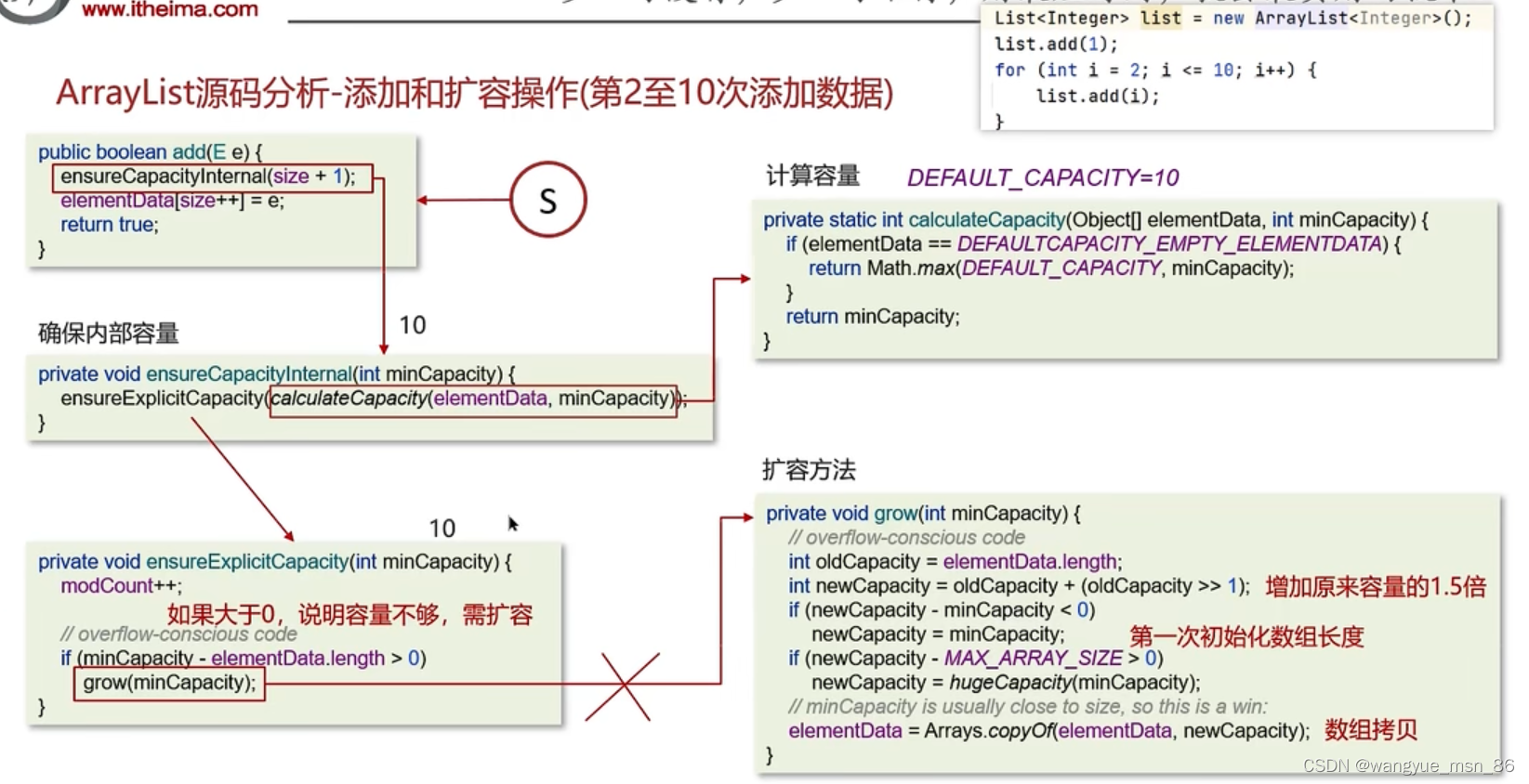
第11次添加,超过容量,扩容1.5倍,右移1是除2,加本身,就是1.5倍
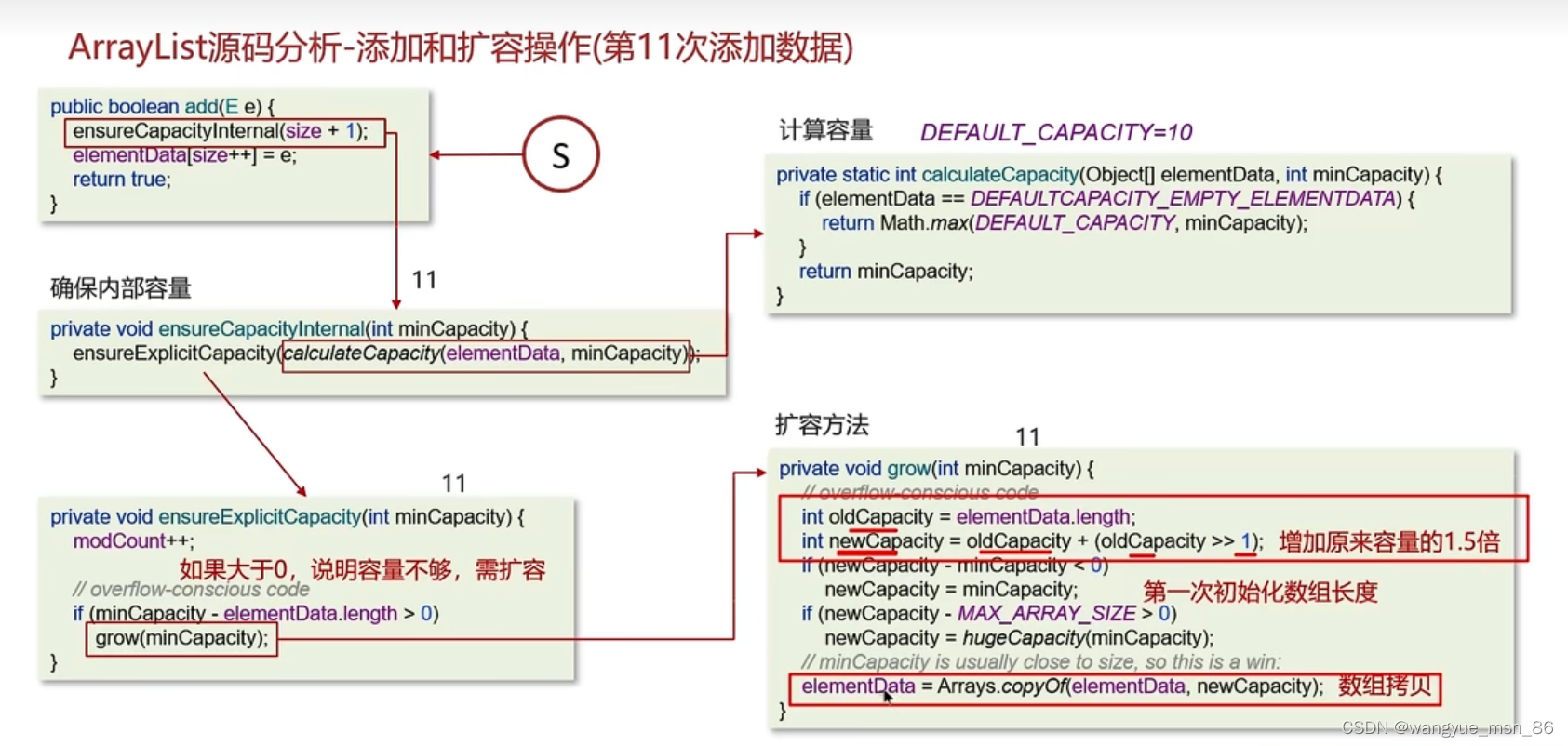
没有扩容:使用有参构造,直接初始化数组,不需要扩容

HashMap
红黑树结构:
为什么java用红黑树不用AVL?
最主要的一点是:
在CurrentHashMap中是加锁了的,实际上是读写锁,如果写冲突就会等待,
如果插入时间过长必然等待时间更长,而红黑树相对AVL树他的插入更快!
AVL树和红黑树有几点比较和区别:
(1)AVL树是更加严格的平衡,因此可以提供更快的查找速度,一般读取查找密集型任务,适用AVL树。
(2)红黑树更适合于插入修改密集型任务。
(3)通常,AVL树的旋转比红黑树的旋转更加难以平衡和调试
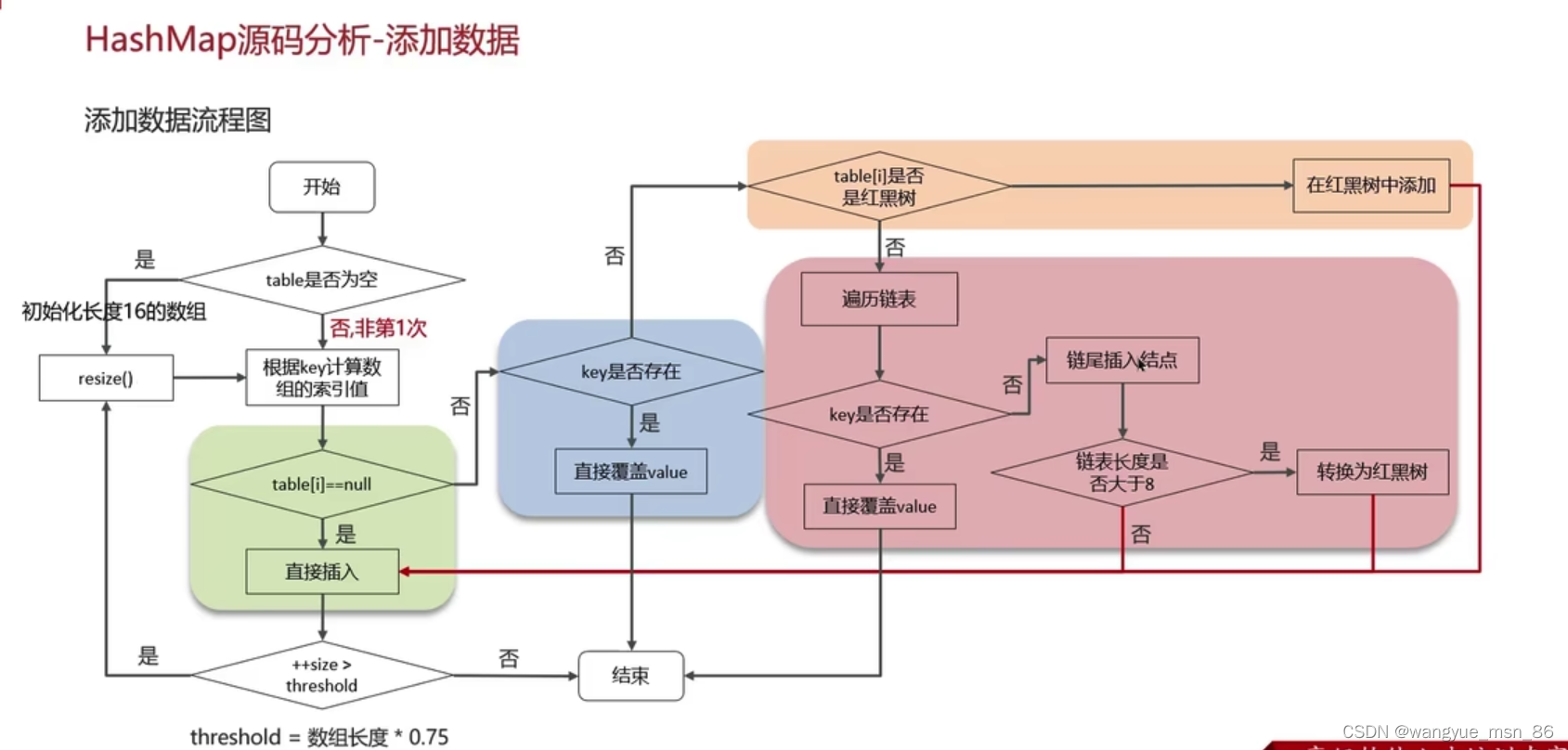
HashMap实现原理: 7和8的区别

HashMap源码分析
默认容量:16
默认加载因子:0.75
table:装数据的数组 Node是HashMap的内部类: hash值(计算完的),key,value,以及下一个Node (为了冲突时 链表)
size:集合中存储元素的个数

构造方法:懒惰加载,没有初始化table数组,只设置了加载因子为默认的 0.75

put方法的流程?

图解HashMap put方法:第一次put,会给map初始化长度为16的数组,根据key计算数组中的索引,如果该索引没有值,直接插入,然后看看长度需不需要扩容。阈值的数组长度✖️加载因子 16*0.75=12 没达到12不扩容,结束
当数组对应位置有值的时候,如果key存在了,那就覆盖value,不存在就去看看是不是红黑树,如果是链表在链表中查key,插入新的节点的话,考虑链表是不是需要转化为红黑树
源码:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
static final int hash(Object key) {
int h;
//高16低16异或运算,减少hash碰撞
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
/**
* hash就是经过扰动的hashcode
* key 就是存入的key
* value 就是存入的value
* onlyIfAbsent if true,相同的key不会插值了,这里默认为false,
* @Override 这个方法是true
* public V putIfAbsent(K key, V value) {
* return putVal(hash(key), key, value, true, true);
* }
* evict为false,则hashmap的table处于创建模式
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
// tab指代是hashmap的散列表再,在下方初始化,hashmap不是在创建的时候初始化,而是在put的时候初始化,属于懒初始化
// p表示当前散列表元素
// n表示散列表数组长度
// i表示路由寻址的结果
Node<K,V>[] tab; Node<K,V> p; int n, i;
//判断是否为空,为空的话初始化,不为空对tab和n进行赋值
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;//正的创建散列表,初始化入口,同时对n赋值
//这个i就是(n-1)和hash做与运算得到的位置,p就是这个位置的Node元素
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);//当这个位置为空,直接封装key和value,放入tab中
else {
//e 临时的node元素
//k 表示临时的一个key
Node<K,V> e; K k;
//表示这个桶的位置的元素的key和将要插入的key是一个,会进行替换
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//当前节点是红黑树的节点,加入树中,instanceof 判断对象是不是谁的实例,返回boolean类型的值
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//链表的情况,而且链表的头元素与我们要插入的key不一致
else {
for (int binCount = 0; ; ++binCount) {
//判断到最后也没有key是一样的,就在最末尾插入一个新的节点
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//在插入完第九个节点,会进行树化
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);//树化函数
break;
}
//条件成立就是在遍历链表中有相同的key,直接跳出
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//这种属于覆盖操作,当e中有值进入操作
if (e != null) { // existing mapping for key
//oldValue保存老的值,方便return
V oldValue = e.value;
//onlyIfAbsent传入的是false,指定能进入判断
if (!onlyIfAbsent || oldValue == null)
e.value = value;//值的替换
afterNodeAccess(e);
return oldValue;
}
}
++modCount;//增加修改次数
if (++size > threshold)//插入新元素,size自增,大于扩容阈值会触发扩容
resize();//扩容
afterNodeInsertion(evict);
return null;
}
Hash算法?
Hash算法:取key的hashCode值、高位运算、取模运算。
在JDK1.8的实现中,优化了高位运算的算法,通过 hashCode() 的高16位异或低16位实现的:这么做可
以在数组比较小的时候,也能保证考虑到高低位都参与到Hash的计算中,可以减少冲突,同时不会有太
大的开销。
static final int hash(Object key) {
int h;
//高16低16异或运算,减少hash碰撞
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
h = key.hashCode()获取hashcode的值
h >>> 16 无符号右移 16位 然后按位异或,扰动算法,填充到数组中就比较均匀。
put的时候,寻找插入位置,使用按位与运算代替取模,性能更好 hash % 数组len 等价于 hash& (n-1)
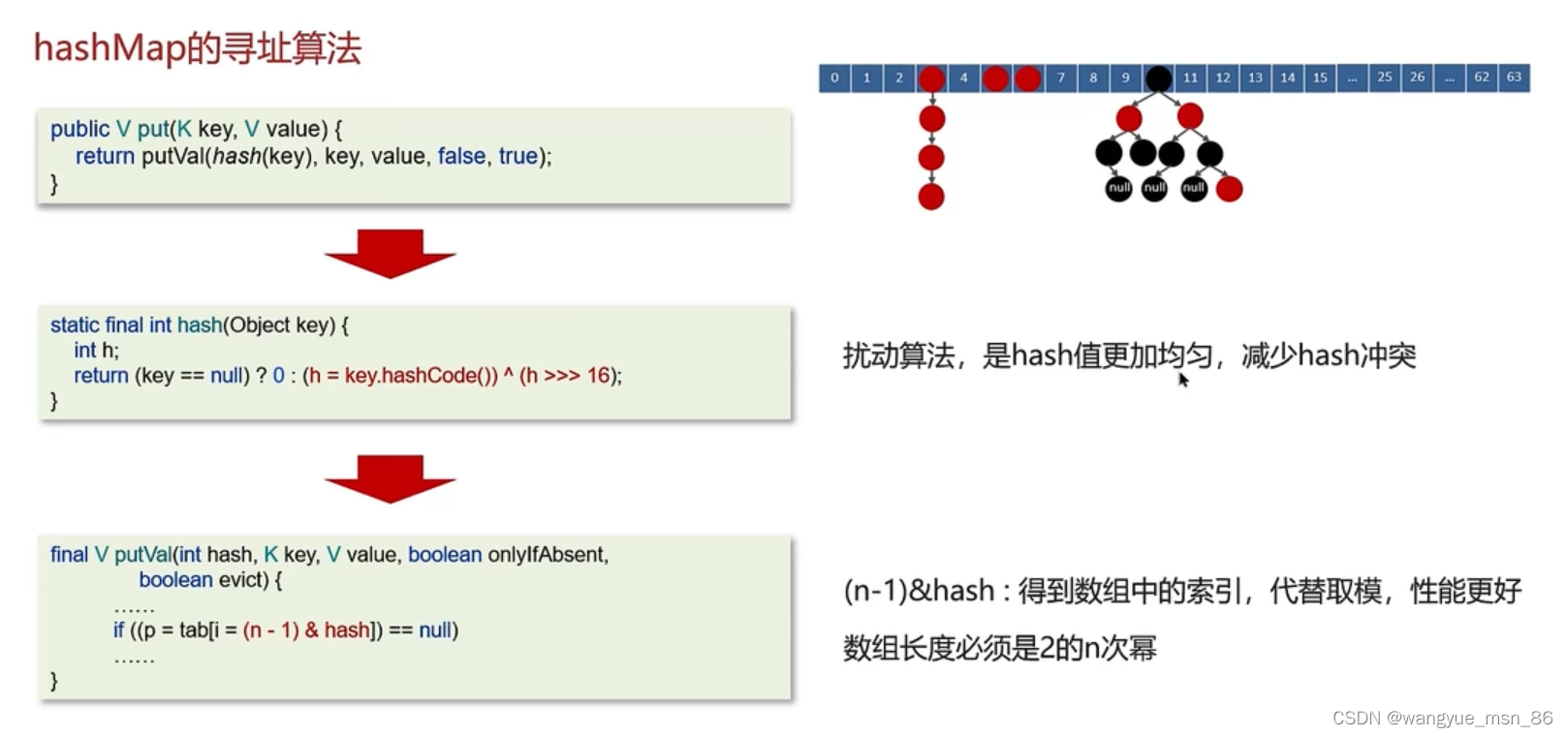
HashMap 的长度为什么是 2 的幂次方?
Hash 值的范围值比较大,使用之前需要先对数组的长度取模运算,得到的余数才是元素存放的位置也
就是对应的数组下标。这个数组下标的计算方法是 (n - 1) & hash 。将HashMap的长度定为2 的幂次
方,这样就可以使用 (n - 1)&hash 位运算代替%取余的操作,提高性能。
HashMap扩容方式?
1.8扩容机制:当元素个数大于 threshold 时,会进行扩容,使用2倍容量的数组代替原有数组。采用尾插入的方式将原数组元素拷贝到新数组。1.8扩容之后链表元素相对位置没有变化,而1.7扩容之后链表元素会倒置。
1.7链表新节点采用的是头插法,这样在线程一扩容迁移元素时,会将元素顺序改变,导致两个线程中出现元素的相互指向而形成循环链表,1.8采用了尾插法,避免了这种情况的发生。
原数组的元素在重新计算hash之后,因为数组容量n变为2倍,那么n-1的mask范围在高位多1bit。在元
素拷贝过程不需要重新计算元素在数组中的位置,只需要看看原来的hash值新增的那个bit是1还是0,
是0的话索引没变,是1的话索引变成“原索引+oldCap”(根据 e.hash & oldCap == 0 判断) 。这样可
以省去重新计算hash值的时间,而且由于新增的1bit是0还是1可以认为是随机的,因此resize的过程会
均匀的把之前的冲突的节点分散到新的bucket
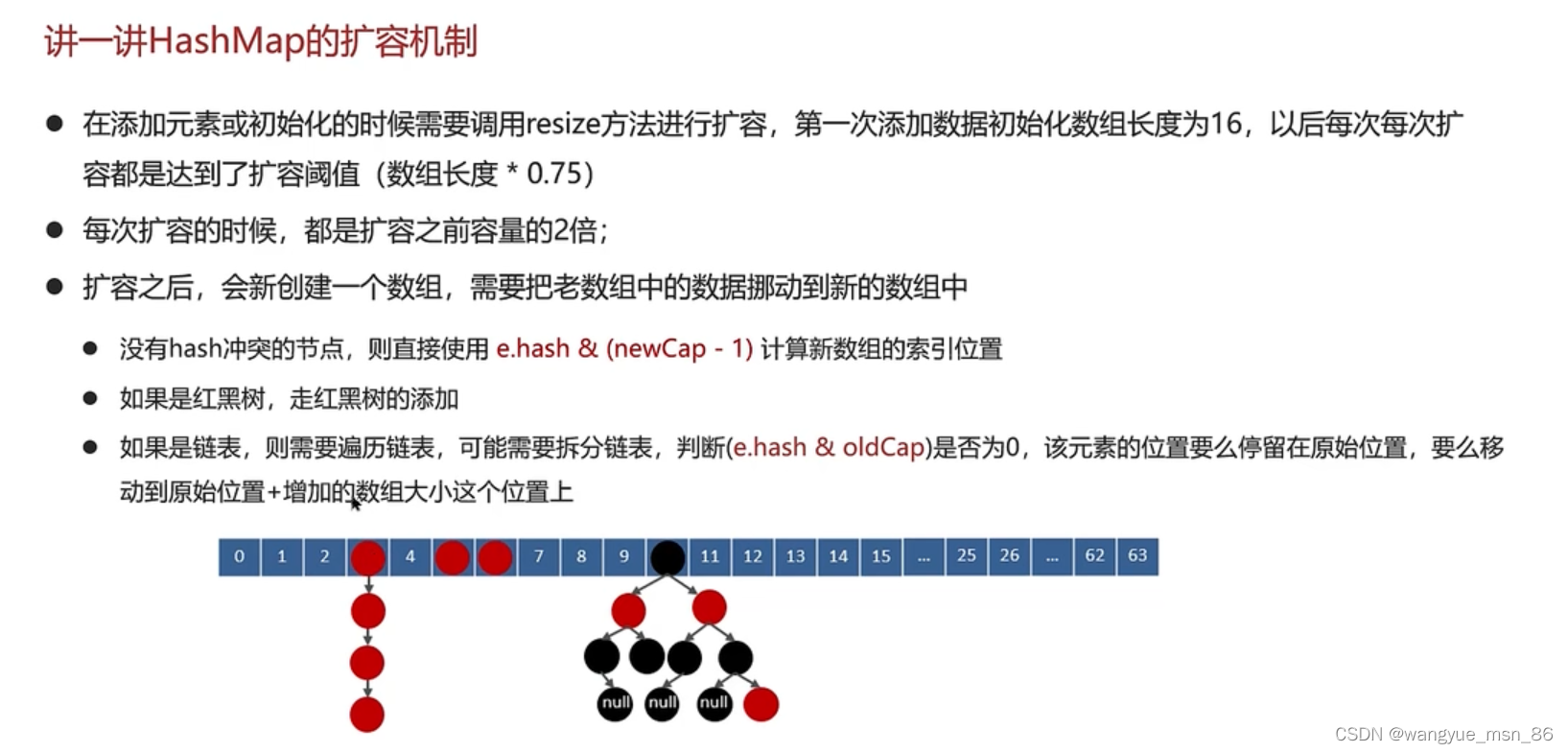
Jdk1.7在多线程环境下造成的循环问题:

详细请看文章:
https://blog.csdn.net/u014571143/article/details/128599879?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522169165159416800182113734%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=169165159416800182113734&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_click~default-1-128599879-null-null.142v92insert_down28v1&utm_term=hashmap1.7%E5%A4%B4%E6%8F%92%E6%B3%95%E6%AD%BB%E5%BE%AA%E7%8E%AF&spm=1018.2226.3001.4187
NIO
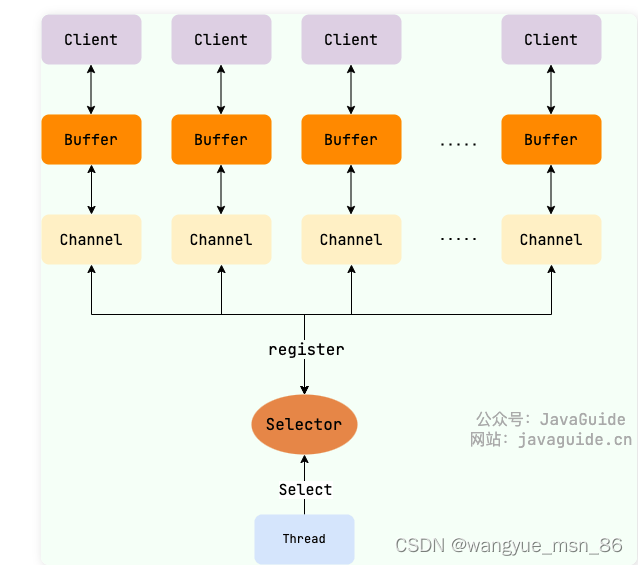
来自 java guide:NIO 主要包括以下三个核心组件:
- Buffer(缓冲区):NIO 读写数据都是通过缓冲区进行操作的。读操作的时候将 Channel 中的数据填充到 Buffer 中,而写操作时将 Buffer 中的数据写入到 Channel 中。
- Channel(通道):Channel 是一个双向的、可读可写的数据传输通道,NIO 通过 Channel 来实现数据的输入输出。通道是一个抽象的概念,它可以代表文件、套接字或者其他数据源之间的连接。(channel是一个抽象的模型,不是tcp的连接,而是要基于tcp的连接)
- Selector(选择器):允许一个线程处理多个 Channel,基于事件驱动的 I/O 多路复用模型。所有的 Channel 都可以注册到 Selector 上,由 Selector 来分配线程来处理事件。
三者的关系如下图所示
Buffer(缓冲区)
在传统的 BIO 中,数据的读写是面向流的, 分为字节流和字符流。netty中用的是更合理的bytebuf
在 Java 1.4 的 NIO 库中,所有数据都是用缓冲区处理的,这是新库和之前的 BIO 的一个重要区别,有点类似于 BIO 中的缓冲流。NIO 在读取数据时,它是直接读到缓冲区中的。在写入数据时,写入到缓冲区中。 使用 NIO 在读写数据时,都是通过缓冲区进行操作。
Buffer 的子类如下图所示。其中,最常用的是 ByteBuffer,它可以用来存储和操作字节数据。
Channel(通道)
Channel 是一个通道,它建立了与数据源(如文件、网络套接字等)之间的连接。我们可以利用它来读取和写入数据,就像打开了一条自来水管,让数据在 Channel 中自由流动。
BIO 中的流是单向的,分为各种 InputStream(输入流)和 OutputStream(输出流),数据只是在一个方向上传输。通道与流的不同之处在于通道是双向的,它可以用于读、写或者同时用于读写。
Channel 与前面介绍的 Buffer 打交道,读操作的时候将 Channel 中的数据填充到 Buffer 中,而写操作时将 Buffer 中的数据写入到 Channel 中。
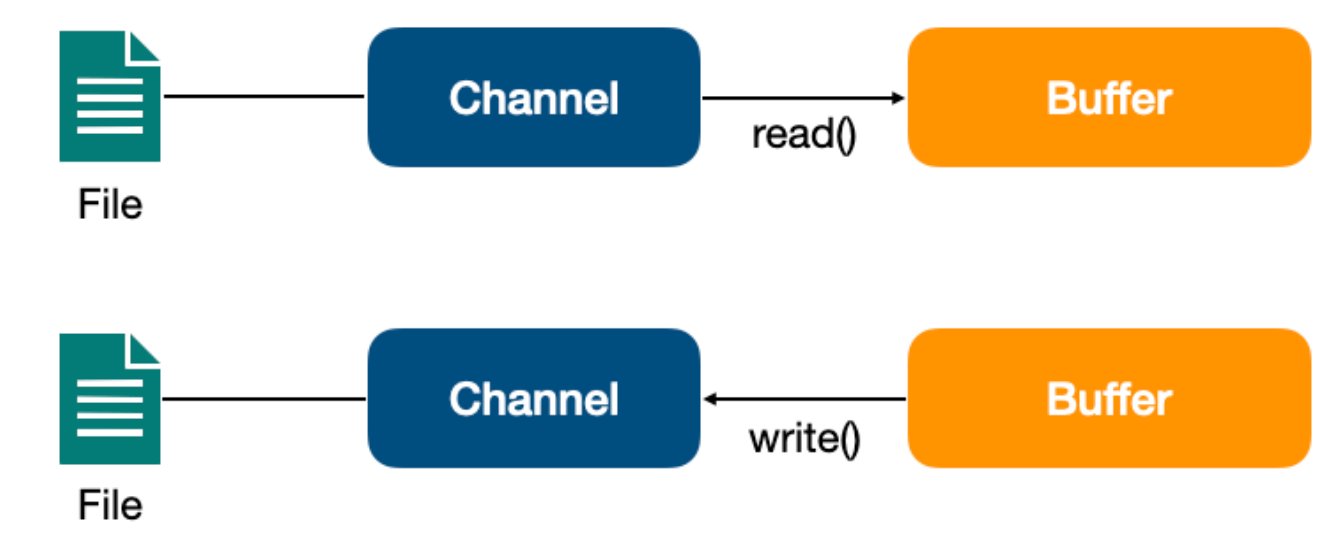
另外,因为 Channel 是全双工的,所以它可以比流更好地映射底层操作系统的 API。特别是在 UNIX 网络编程模型中,底层操作系统的通道都是全双工的,同时支持读写操作。
Selector(选择器)
Selector(选择器) 是 NIO 中的一个关键组件,它允许一个线程处理多个 Channel。Selector 是基于事件驱动的 I/O 多路复用模型,主要运作原理是:通过 Selector 注册通道的事件,Selector 会不断地轮询注册在其上的 Channel。当事件发生时,比如:某个 Channel 上面有新的 TCP 连接接入、读和写事件,这个 Channel 就处于就绪状态,会被 Selector 轮询出来。Selector 会将相关的 Channel 加入到就绪集合中。通过 SelectionKey 可以获取就绪 Channel 的集合,然后对这些就绪的 Channel 进行响应的 I/O 操作。
selector就是IO多路复用的关键,就是selector线程一直循环的读取注册的channel的状态,当有读写事件的时候,就可以进行具体操作。相当于这个selector依着在发送select或者epoll这种系统调用在监控fd文件的状态,linux系统一切都是文件。
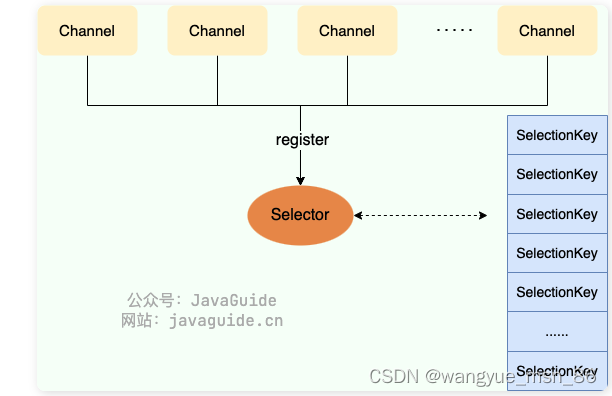
一个多路复用器 Selector 可以同时轮询多个 Channel,由于 JDK 使用了 epoll() 代替传统的 select 实现,所以它并没有最大连接句柄 1024/2048 的限制。这也就意味着只需要一个线程负责 Selector 的轮询,就可以接入成千上万的客户端。
Selector 可以监听以下四种事件类型:
SelectionKey.OP_ACCEPT:表示通道接受连接的事件,这通常用于ServerSocketChannel。SelectionKey.OP_CONNECT:表示通道完成连接的事件,这通常用于SocketChannel。SelectionKey.OP_READ:表示通道准备好进行读取的事件,即有数据可读。SelectionKey.OP_WRITE:表示通道准备好进行写入的事件,即可以写入数据。
Selector是抽象类,可以通过调用此类的 open() 静态方法来创建 Selector 实例。Selector 可以同时监控多个 SelectableChannel 的 IO 状况,是非阻塞 IO 的核心。
一个 Selector 实例有三个 SelectionKey 集合:
- 所有的
SelectionKey集合:代表了注册在该 Selector 上的Channel,这个集合可以通过keys()方法返回。 - 被选择的
SelectionKey集合:代表了所有可通过select()方法获取的、需要进行IO处理的 Channel,这个集合可以通过selectedKeys()返回。 - 被取消的
SelectionKey集合:代表了所有被取消注册关系的Channel,在下一次执行select()方法时,这些Channel对应的SelectionKey会被彻底删除,程序通常无须直接访问该集合,也没有暴露访问的方法。
简单演示一下如何遍历被选择的 SelectionKey 集合并进行处理:
Set<SelectionKey> selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = selectedKeys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key != null) {
if (key.isAcceptable()) {
// ServerSocketChannel 接收了一个新连接
} else if (key.isConnectable()) {
// 表示一个新连接建立
} else if (key.isReadable()) {
// Channel 有准备好的数据,可以读取
} else if (key.isWritable()) {
// Channel 有空闲的 Buffer,可以写入数据
}
}
keyIterator.remove();
}
Selector 还提供了一系列和 select() 相关的方法:
int select():监控所有注册的Channel,当它们中间有需要处理的IO操作时,该方法返回,并将对应的SelectionKey加入被选择的SelectionKey集合中,该方法返回这些Channel的数量。依赖底层的系统调用,linux是epoll,windows是selectint select(long timeout):可以设置超时时长的select()操作。int selectNow():执行一个立即返回的select()操作,相对于无参数的select()方法而言,该方法不会阻塞线程。Selector wakeup():使一个还未返回的select()方法立刻返回。- ……
使用 Selector 实现网络读写的简单示例:
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
import java.util.Set;
public class NioSelectorExample {
public static void main(String[] args) {
try {
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.configureBlocking(false);
serverSocketChannel.socket().bind(new InetSocketAddress(8080));
Selector selector = Selector.open();
// 将 ServerSocketChannel 注册到 Selector 并监听 OP_ACCEPT 事件
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
int readyChannels = selector.select();
if (readyChannels == 0) {
continue;
}
Set<SelectionKey> selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = selectedKeys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
// 处理连接事件
ServerSocketChannel server = (ServerSocketChannel) key.channel();
SocketChannel client = server.accept();
client.configureBlocking(false);
// 将客户端通道注册到 Selector 并监听 OP_READ 事件
client.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) {
// 处理读事件
SocketChannel client = (SocketChannel) key.channel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
int bytesRead = client.read(buffer);
if (bytesRead > 0) {
buffer.flip();
System.out.println("收到数据:" +new String(buffer.array(), 0, bytesRead));
// 将客户端通道注册到 Selector 并监听 OP_WRITE 事件
client.register(selector, SelectionKey.OP_WRITE);
} else if (bytesRead < 0) {
// 客户端断开连接
client.close();
}
} else if (key.isWritable()) {
// 处理写事件
SocketChannel client = (SocketChannel) key.channel();
ByteBuffer buffer = ByteBuffer.wrap("Hello, Client!".getBytes());
client.write(buffer);
// 将客户端通道注册到 Selector 并监听 OP_READ 事件
client.register(selector, SelectionKey.OP_READ);
}
keyIterator.remove();
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
在示例中,我们创建了一个简单的服务器,监听 8080 端口,使用 Selector 处理连接、读取和写入事件。当接收到客户端的数据时,服务器将读取数据并将其打印到控制台,然后向客户端回复 “Hello, Client!”。
Mysql
存储引擎
MySQL中常见的存储引擎?
- innodb 5.1之后默认的
- myisam 5.1之前默认的
- memory 适用于读写效率高,能容忍数据丢失的
Innodb和myisam引擎的区别?
- 最大的区别是 innodb支持事务,myisam不支持事务
- Innodb支持到行级锁,Myisam不支持行级锁,只支持到表锁
- innodb支持外键,myisam不支持外键
- myisam性能比innodb高
- innodb支持崩溃后安全恢复,myisam不支持
- innodb主键查询性能高于myisam
- myisam支持fulltext类型的全文索引,innodb不支持,但是innodb可以使用sphinx插件来支持全文索引,且性能更好
索引
了解过索引吗,索引有什么用?
- 索引是帮助mysql高效查找数据的数据结构
- 提高数据检索效率,降低IO成本(B+树矮胖IO次数少)
- 通过索引对数据进行排序,降低了数据库排序的成本,降低了cpu的消耗
有哪些数据结构可以做索引?
B+树索引、Hash索引、FullText索引
Hash索引的缺点?
- Hash索引只能用于对等比较(=,in),不支持范围查询(between,>,< ,…)
- 无法利用索引完成排序操作
为什么不用二叉树?红黑树?
插入的数据多了二叉树会退化成链表,查找性能变低,即使红黑树可以保证平衡,但是数据多了树很高,说白了就是二叉不够用,需要多叉树,让索引尽可能的矮胖,查询性能较好。
请描述一下B树和B+树:
B树/B+树是多路平衡查找树,专门为提升数据库查询性能而产生的数据结构,是绝对平衡的m叉查找树,一个m叉树 最多 m-1个key,m个指针,在B-Tree中,非叶子节点和叶子节点都会存放数据,B+树中,非叶子结点只存放索引,数据全存放在叶子结点处,而且叶子结点用指针相连成了一个链表
为什么不用B树而用B+树:
1.B+树非叶子结点放的全是索引,而操作系统一个磁盘块的空间的有限的,那么一个磁盘块就能放下更多的索引,树也会更加的矮胖,查询IO次数更少,性能更高
2.B+树存放数据的叶子结点用指针相连成了链表,可以按照关键码排序的次序来有序遍历全部记录,由于数据顺序排列并且相连,所以便于区间查找和搜索(根据空间局部性原理),
B+树高度为3就能记录2000万条数据,就是因为足够矮胖:
这里我们先假设B+树高为2,即存在一个根节点和若干个叶子节点,那么这棵B+树的存放总记录数为:根节点指针数*单个叶子节点记录行数。
上文我们已经说明单个叶子节点(页)中的记录数=16K/1K=16。(这里假设一行记录的数据大小为1k,实际上现在很多互联网业务数据记录大小通常就是1K左右)。
那么现在我们需要计算出非叶子节点能存放多少指针,其实这也很好算,我们假设主键ID为bigint类型,长度为8字节,而指针大小在InnoDB源码中设置为6字节,这样一共14字节,我们一个页中能存放多少这样的单元,其实就代表有多少指针,即16384/14=1170。那么可以算出一棵高度为2的B+树,能存放1170*16=18720条这样的数据记录。
根据同样的原理我们可以算出一个高度为3的B+树可以存放:1170*1170*16=21902400条这样的记录。所以在InnoDB中B+树高度一般为1-3层,它就能满足千万级的数据存储。在查找数据时 一次页的查找代表一次IO, 所以通过主键索引查询通常 只需要1-3次IO操作 即可查找到数据。
从物理存储(innodb引擎)的角度来看,索引分为聚簇索引(主键索引)、二级索引(辅助索引/非聚簇索引),二者的区别?
- 主键索引的 B+Tree 的叶子节点存放的是实际数据(行数据),所有完整的用户记录都存放在主键索引的 B+Tree 的叶子节点里;
- 二级索引的 B+Tree 的叶子节点存放的是主键值,而不是实际数据。
在查询时如果走的是二级索引,并且查询的数据在二级索引里查询不到,那么要根据二级索引查到的主键值去主键索引回表查询,如果可以查询的到,(比如只查询二级索引的那个字段和主键字段),就不需要回表查询,这个过程叫覆盖索引。
聚簇索引选取原则?
- 如果存在主键,主键索引就是聚簇索引
- 如果没有主键,将使用第一个唯一索引来作为聚簇索引
- 如果没有主键,也没有合适的唯一索引,Innodb会自动生成一个rowid作为隐藏的聚簇索引
什么是覆盖索引?
上面写的就是,因为不用回表查询了,性能稍微好点,IO次数少点,所以可以建立联合索引。也要避免使用Select *(非必要),会回表查询降低效率
MySQl超大分页如何处理(因为数据量比较大时,limit分页查询,需要对数据进行排序,效率低)?
解决方案:覆盖索引+子查询

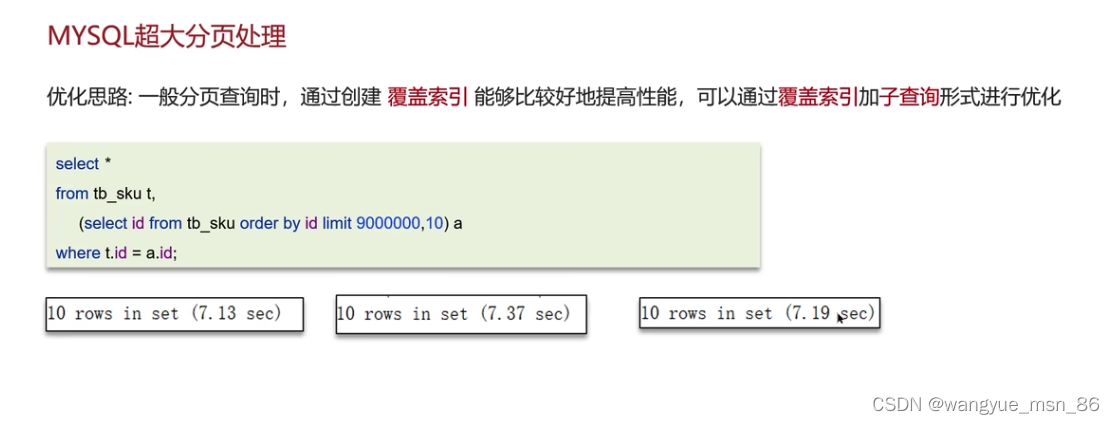
这样优化在了哪里呢,先走子查询查询9000000到90000010的id,虽然也要进行排序,并且丢弃9000000以前的数据,但是走的都是覆盖索引,都没回表,然后再关联到表中进行查询,性能较高。
创建索引的原则?
1、2、5、6点比较重要:超过10万再建立索引,经常作为查询条件的建立索引、尽量使用联合索引,可以覆盖索引,索引不是越多越好

如何判断SQL走没走索引?
使用explain查看sql执行计划
什么情况下索引会失效?(适当思考一下假装自己遇到过)
- (联合索引)违反最左前缀原则
- 范围查询右边的列,不能使用索引 >号可以改为>=
- 在索引列上进行运算操作,索引列将失效 … where substring(name,3,2)= ‘科技‘
- 字符串不加单引号,导致索引失效 (mysql查询优化器会进行自动类型转化,导致索引失效)
- 以%开头的Like模糊查询,索引失效(模糊查询不能头部模糊) where name like '%黑马程序员’会失效
最左前缀原则:走联合索引的情况下,如果字段不按索引顺序来作为条件查询,那么不按照顺序的部分将失效 如下是三个字段的联合索引
使用name和address作为条件只有name索引会生效(看key_len,索引长度只走了name一个索引)
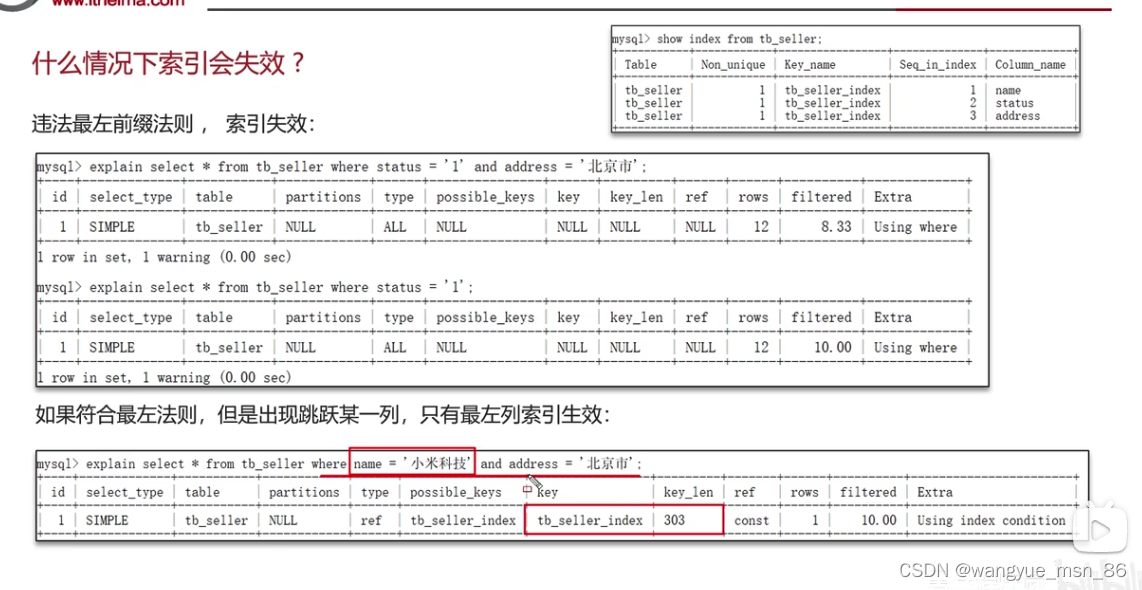
sql优化
MySQL 的常见的优化手段有以下五种:
查询优化:
1、避免 SELECT *,只查询需要的字段。
2、小表驱动大表,即小的数据集驱动大的数据集,比如,当 B 表的数据集小于 A 表时,用 in 优化
exist,两表执行顺序是先查 B 表,再查 A 表,查询语句:select * from A where id in (select id from
B) 。
3、一些情况下,可以使用连接代替子查询,因为使用 join 时,MySQL 不会在内存中创建临时表。
优化索引的使用:
1、尽量使用主键查询,而非其他索引,因为主键查询不会触发回表查询。
2、不做列运算,把计算都放入各个业务系统实现
3、查询语句尽可能简单,大语句拆小语句,减少锁时间
4、不使用 select * 查询
5、or 查询改写成 in 查询
6、不用函数和触发器
7、避免 %xx 查询
8、少用 join 查询
9、使用同类型比较,比如 ‘123’ 和 ‘123’、123 和 123
10、尽量避免在 where 子句中使用 != 或者 <> 操作符,查询引用会放弃索引而进行全表扫描
11、列表数据使用分页查询,每页数据量不要太大
12、用 exists 替代 in 查询
13、避免在索引列上使用 is null 和 is not null
14、尽量使用主键查询
15、避免在 where 子句中对字段进行表达式操作
16、尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型
表结构设计优化:
1、使用可以存下数据最小的数据类型。
2、使用简单的数据类型,int 要比 varchar 类型在 MySQL 处理简单。
3、尽量使用 tinyint、smallint、mediumint 作为整数类型而非 int。
4、尽可能使用 not null 定义字段,因为 null 占用 4 字节空间。
5、尽量少用 text 类型,非用不可时最好考虑分表。
6、尽量使用 timestamp,而非 datetime。
7、单表不要有太多字段,建议在 20 个字段以内。
表拆分当数据库中的数据非常大时,查询优化方案也不能解决查询速度慢的问题时,我们可以考虑拆分表,让
每张表的数据量变小,从而提高查询效率。
1、垂直拆分:是指数据表列的拆分,把一张列比较多的表拆分为多张表,比如,用户表中一些字段经
常被访问,将这些字段放在一张表中,另外一些不常用的字段放在另一张表中,插入数据时,使用事务
确保两张表的数据一致性。
垂直拆分的原则:
1、把不常用的字段单独放在一张表;
2、把 text,blob 等大字段拆分出来放在附表中;
4、经常组合查询的列放在一张表中。
2、水平拆分:指数据表行的拆分,表的行数超过200万行时,就会变慢,这时可以把一张的表的数据拆
成多张表来存放。
通常情况下,我们使用取模的方式来进行表的拆分,比如,一张有 400W 的用户表 users,为提高其查
询效率我们把其分成 4 张表 users1,users2,users3,users4,然后通过用户 ID 取模的方法,同时
查询、更新、删除也是通过取模的方法来操作。
读写分离:
一般情况下对数据库而言都是“读多写少”,换言之,数据库的压力多数是因为大量的读取数据的操作造
成的,我们可以采用数据库集群的方案,使用一个库作为主库,负责写入数据;其他库为从库,负责读
取数据。这样可以缓解对数据库的访问压力。
事务
你在开发中什么时候使用事务(Transactional注解)
Transactional是通过AOP实现的,环绕通知,执行方法前启动事务,执行方法后关闭事务
单条sql语句mysql是默认加事务的。如果一个方法里有多条sql语句,就要考虑是不是需要加事务了
1、原子性保障——多个insert,update,delete操作
这个应该是大家最熟悉的一种场景,保证多个insert,update,delete操作要么全都执行成功(Committed),要么全都不执行(Rollback)。
原子性的特点:
1、针对单事务的控制
2、针对多个insert,update,delete操作ååå
示例:
执行方法,添加多个商品。添加事务控制,保障所有商品要么全部添加成功,要么全部添加失败。
@Transactional(rollbackFor = Exception.class)
public void addList(List list){
list.forEach(e->{
goodsStockMapper.add(e);
});
}
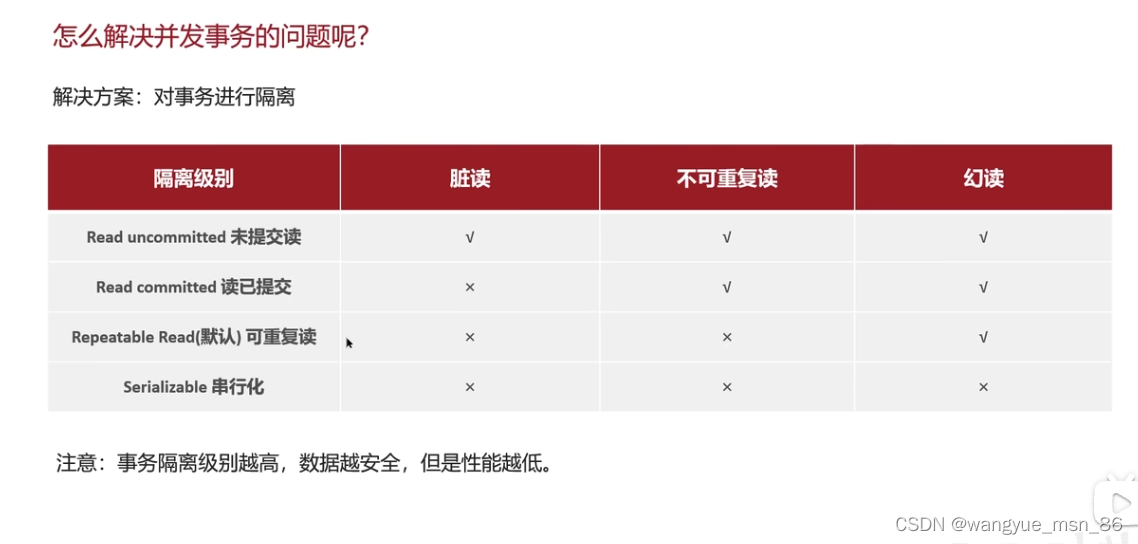
2、隔离性保障——幻读、不可重复、脏读
事务处理过程中的中间状态应该对外部不可见,换句话说,事务在进行过程中是隔离的,事务之间不能互相干扰,不能访问到彼此未提交的数据。
幻读、不可重复需要在同一个事务中进行多次相同的查询才能体现,真是项目中需要这样操作的场景很少。
脏读就是读到其他事务没有提交的数据,只要隔离级别不是读未提交(Read Uncommitted)就不会出现。
所以相比对幻读、不可重复、脏读这些开发过程中基本不会遇到的问题,我们更应该关注事务的隔离性对业务产生的影响。
事务的默认隔离级别可重复读(Repeatable Read)基本满足日常开发90%的场景,一般不建议调整。
隔离性的特点:
1、针对多事务间数据可见性的控制。
2、控制加锁的粒度和加锁、释放锁的时机,提高事务的并发能力。
示例场景:
读到其他事务未提交数据,导致超卖。
1、幻读:
SELECT count(1) FROM books WHERE price < 100; /* 时间顺序:1,事务: T1 /
INSERT INTO books(name,price) VALUES (‘深入理解Java虚拟机’,90); COMMIT; / 时间顺序:2,事务: T2 /
SELECT count(1) FROM books WHERE price < 100; / 时间顺序:3,事务: T1 */
可串行化(Serializable)会对事务所有读、写的数据全都加上读锁、写锁和范围锁,所以由于T1事务对价格小于100的范围内的数据都加读锁、写锁和范围锁,所以T2不能插入价格为90的数据,所以不存在幻读的情况。
其他隔离级别下都会出现幻读。
2、不可重复度
SELECT * FROM books WHERE id = 1; /* 时间顺序:1,事务: T1 /
UPDATE books SET price = 110 WHERE id = 1; COMMIT; / 时间顺序:2,事务: T2 /
SELECT * FROM books WHERE id = 1; COMMIT; / 时间顺序:3,事务: T1 */
假如隔离级别是可重复读的话,由于数据已被事务 T1 施加了读锁且读取后不会马上释放,所以事务 T2 无法获取到写锁,更新就会被阻塞,直至事务 T1 被提交或回滚后才能提交。
读已提交对事务涉及的数据加的写锁会一直持续到事务结束,但加的读锁在查询操作完成后就马上会释放。
读已提交的隔离级别缺乏贯穿整个事务周期的读锁,无法禁止读取过的数据发生变化,此时事务 T2 中的更新语句可以马上提交成功,这也是一个事务受到其他事务影响,隔离性被破坏的表现。
事实上由于Mysql的MVCC机制,可重复读(Repeatable Read)和读已提交(Read Committed)在读的时候都不会加锁。如果读取的行正在执行delete或者update操作,这时读操作不会因此去等待行上锁的释放。相反的,InnoDB存储引擎会去读取行的一个快照数据。实现了对读的非阻塞,读不加锁,读写不冲突。
3、一致性保障——针对多个表的查询统计
很多同学一直认为,一个方法中如果都是查询请求,就不需要添加事务控制。那么真的是这样吗?
假设现在有3个表A,B,C,由于业务请求量非常高,导致3个表一直有新的数据不停的写入。
现在要求分别对3个表中的数据进行聚合统计,然后进行指标计算。
大致逻辑:
select A指标 from 表A; //步骤1
select B指标 from 表B; //步骤2
select C指标 from 表C; //步骤3
汇总指标 = A指标 + B指标 + C指标; //步骤4
如果按照这样去统计,当查询完A指标后,由于业务在正常进行,表B和表C仍然有数据写入,所以最后会导致查询的A,B,C3个指标,并不是同一时刻的,这样的汇总指标也就没有了参考意义。
这个时候就需要对统计的方法添加事务,保证数据的一致性。
一致性:在成功提交或失败回滚之后以及正在进行的事务期间,数据库始终保持一致的状态。如果正在多个表之间更新相关数据,那么查询将看到所有旧值或所有新值,而不会一部分是新值,一部分是旧值。
@Transactional(rollbackFor = Exception.class,isolation = Isolation.REPEATABLE_READ,readOnly = true)
public int count(){
select A指标 from 表A;
select B指标 from 表B;
select C指标 from 表C;
汇总指标 = A指标 + B指标 + C指标;
说明:
对汇总统计的方法添加事务控制,且指定事务的隔离级别为可重复读Isolation.REPEATABLE_READ,并设置只读属性readOnly对查询进行优先。
事务的特性?
ACID:讲解的时候可以转账300块为案例
- 原子性(atomicity):事务是不可分割的最小操作单元,要么同时成功,要么同时失败(如果转账300的人转账失败,收钱的人不能多300块)
- 一致性(Consistency):事务完成时,必须使所有的数据保持一致状态(转账300块,我少了300你就要多300)
- 隔离性(Isolation):数据库系统提供隔离机制,保证事务在不受外部并发操作的影响下独立环境下运行(转账这个事儿不能被别的事儿影响)
- 持久性(durability):事务一旦提交或回滚,对数据库中数据的改变是永久的(转账后的钱要被写进磁盘)
并发事务的问题?即脏读、不可重复读、幻读
脏读:一个事务读到了另一个事务还没有提交的数据。比如张三的工资是5000,事务1涨到了8000,事务2在事务1没有提交的时候就去读到了8000,但是事务1回滚了,最后结果还是5000,那么这个读到的8000就成了脏数据,事务b做了一次脏读
不可重复读:是指一个事务内多次读取数据,两次读取的结果不一样,在事务1两次读取之间有一个事务2修改了改数据。比如事务1要读两次张三的工资,第一次是5000,此时有一个事务2修改了张三工资为8000,事务1第二次读张三工资为8000,两次结果不一样
幻读:幻读,并不是说两次读取获取的结果集不同,幻读侧重的方面是某一次的 select 操作得到的结果所表征的数据状态无法支撑后续的业务操作。
更为具体一些:事务1select 某记录是否存在,不存在,准备插入此记录,但是事务2已经把这个记录插入了,但执行 insert 时发现此记录已存在,无法插入,此时就发生了幻读。
比如,事务1,查看id为1的学生信息,如果没有则插入,select的结果是不存在,此时事务2插入了id为1的学生信息,事务1再想插入id为1的学生信息的时候,发现已经存在了,无法插入。但是再查询的时候多出了这条幻影数据,像是有幻影一样,这就叫幻读。
如何解决这三个问题?事务隔离级别
数据库innodb引擎默认是可重复读
REDO LOG
重做日志,记录的是事务提交时数据页的物理修改,是用来实现事务的持久性。
该日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo logfile),前者是在内存中,后者在磁盘中。当事务提交之后会把所有修改信息都存到该日志文件中, 用于在刷新脏页到磁盘,发生错误时, 进行数据恢复使用。
那为什么每一次提交事务,要刷新redo log到磁盘中呢,而不是直接将buffer pool中的脏页刷新到磁盘呢 ?
因为在业务操作中,我们操作数据一般都是随机读写磁盘的,而不是顺序读写磁盘。而redo log在往磁盘文件中写入数据,由于是日志文件,所以都是顺序写的。顺序写的效率,要远大于随机写。这种先写日志的方式,称之为WAL(Write-Ahead Logging)。
UNDO LOG
回滚日志,用于记录数据被修改前的信息,作用包含两个:提供回滚(保证事务的原子性)和MVCC(多版本并发控制) 。
undo log和redo log记录物理日志不一样,它是逻辑日志。可以认为当delete一条记录时,undolog中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的update记录。当执行rollback时,就可以从undo log中的逻辑记录读取到相应的内容并进行回滚。
Undo log销毁:undo log在事务执行时产生,事务提交时,并不会立即删除undo log,因为这些日志可能还用于MVCC。
Undo log存储:undo log采用段的方式进行管理和记录,存放在rollback segment回滚段中,内部包含1024个undo log segment。
MVCC
MVCC和锁保证隔离性,两个日志保证一致性:
基本概念
当前读
读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。对于我们日常的操作,如:select … lock in share mode(共享锁),select …for update、update、insert、delete(排他锁)都是一种当前读。
快照读
简单的select(不加锁)就是快照读,快照读,读取的是记录数据的可见版本,有可能是历史数据,不加锁,是非阻塞读。
Read Committed:每次select,都生成一个快照读。
Repeatable Read:开启事务后第一个select语句才是快照读的地方。
Serializable:快照读会退化为当前读。
MVCC
MVCC全称``Multi-Version Concurrency Control,多版本并发控制。指维护一个数据的多个版本,使得读写操作没有冲突,快照读为MySQL实现MVCC提供了一个非阻塞读功能。MVCC的具体实现,还需要依赖于数据库记录中的三个隐式字段、undo log日志、readView`。
1.隐藏字段:三个,当表有主键时第三个隐藏字段没有

2.UNDO log 版本链
回滚日志,在insert、update、delete的时候产生的便于数据回滚的日志。当insert的时候,产生的undo log日志只在回滚时需要,在事务提交后,可被立即删除。而update、delete的时候,产生的undo log日志不仅在回滚时需要,在快照读时也需要,不会立即被删除。



最终我们发现,不同事务或相同事务对同一条记录进行修改,会导致该记录的undolog生成一条记录版本链表,链表的头部是最新的旧记录,链表尾部是最早的旧记录。
3.ReadView
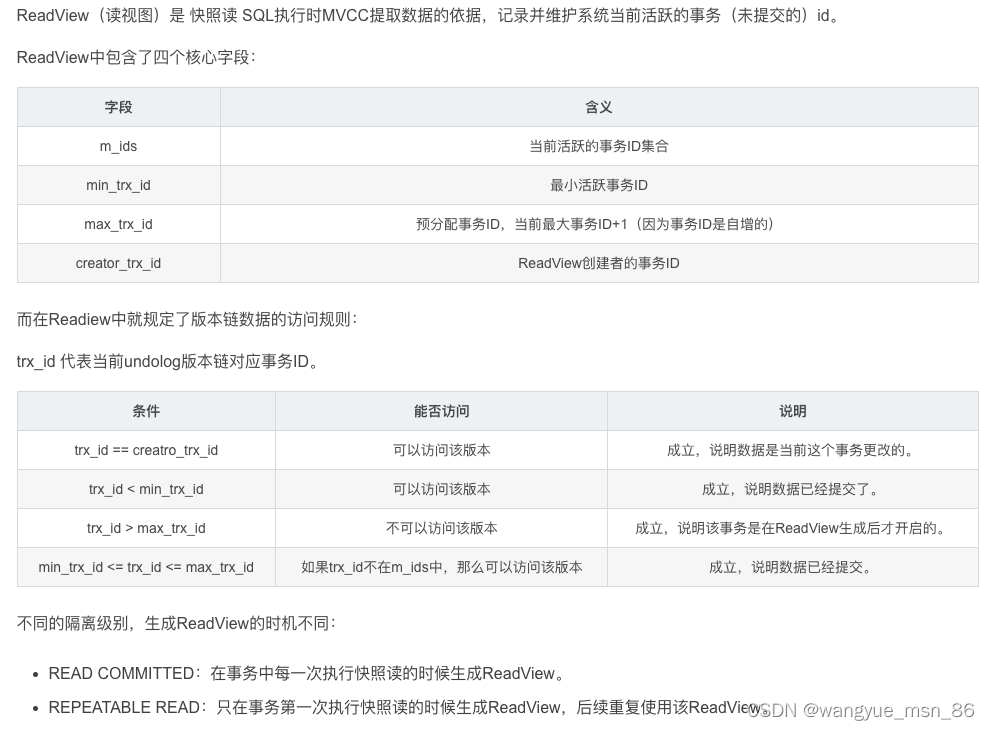
RC(读已提交)级别的readview:事务的每一次查询都会创建readview,按照规则去undolog链中找数据,四个规则都不满足,那么就验证一下个指针指向的数据:
图中第一个readview:当前事务是 4 不等于5,不小于3,不大于6,在3,4,5中,都不满足,去下一个链中的结点,还四个不满足,然后再到下一个,2小于3,说明事务已经提交了,就读这条记录,所以叫读已提交
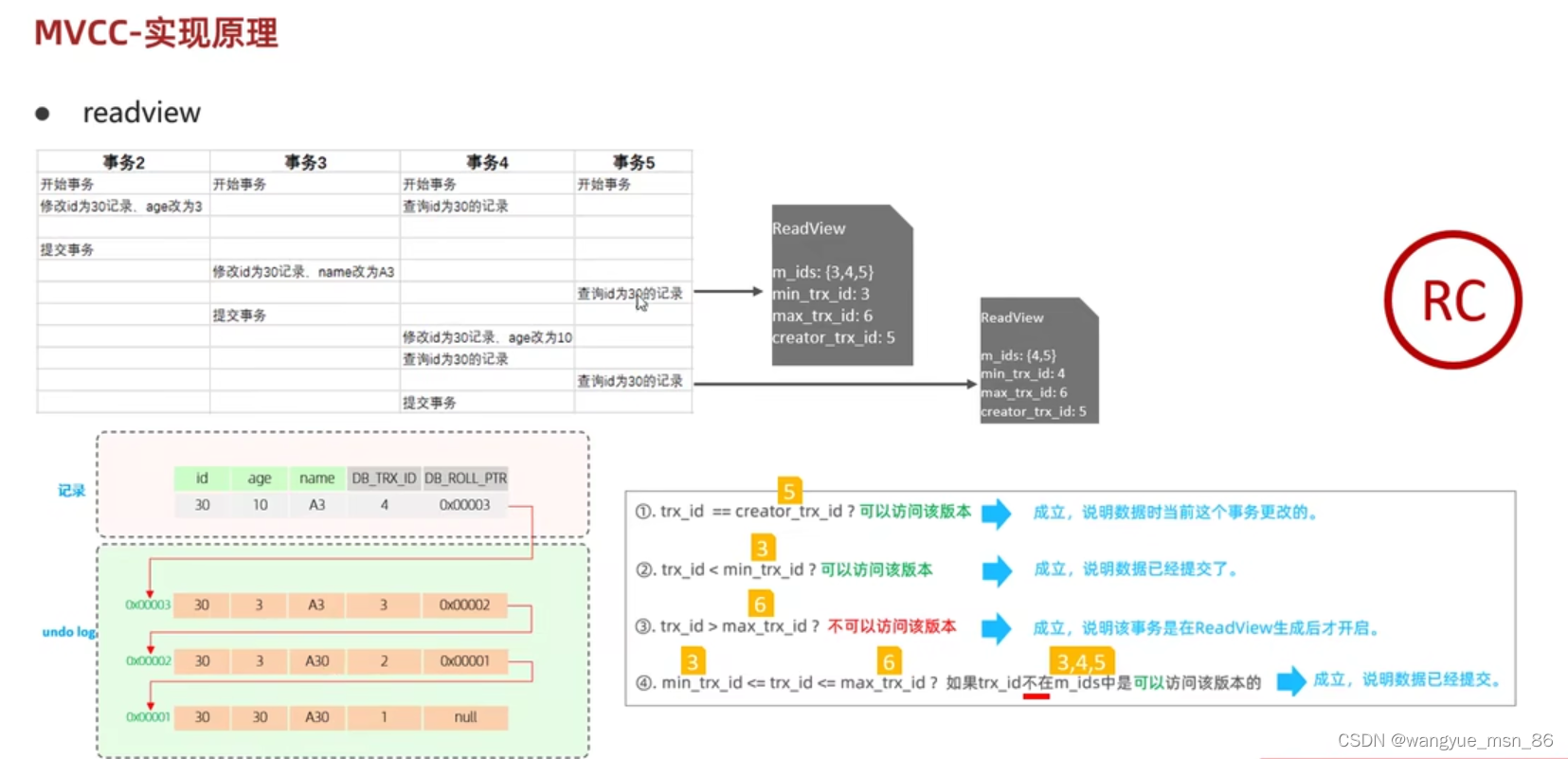
RR(可重复读)下面的查询直接复用上面的readview,规则都是一样的,所以读到的东西都是一样的,所以是可重复读
锁
锁是计算机协调多个进程或线程并发访问某一资源的机制。在数据库中,除传统的计算资源(CPU、RAM、I/O)的争用以外,数据也是一种供许多用户共享的资源。如何保证数据并发访问的一致性、有效性是所有数据库必须解决的一个问题,锁冲突也是影响数据库并发访问性能的一个重要因素。从这个角度来说,锁对数据库而言显得尤其重要,也更加复杂。
在MySQL中,按照粒度可以把锁分为三类:
- 全局锁:锁定数据库中的所有表
- 表级锁:锁定某个数据库中的一整张表
- 行级锁:锁定某个表中对应的某一行数据
全局锁
全局锁就是对整个数据库实例加锁,加锁后整个实例就处于只读状态,后续的DML的写语句,DDL语句,已经更新操作的事务提交语句都将被阻塞。
其典型的使用场景是做全库的逻辑备份,对所有的表进行锁定,从而获取一致性视图,保证数据的完整性。
全库备份语法:
加锁
FLUSH TABLES WITH READ LOCK;
数据备份
MYSQLDUMP -uusername -ppassword database > filename.sql
释放锁
UNLOCK TABLES;
特点:
-
如果在主库上进行加全局锁备份,那么在备份期间都不能执行更新,业务基本无法正常进行。
-
如果在从库上进行加全局锁备份,那么在备份期间从库就无法与主库进行同步,会导致主从不同步。
-
在InnoDB引擎中,可以在备份时加上–single-transaction参数来完成不加锁的一致性备分:
-
MYSQLDUMP --single-transaction -uusername -ppassword database > filename.sql
表级锁
表级锁,每次操作锁住整张表。锁定粒度大,发生锁冲突的概率最高,并发度最低。应用在MyISAM、InnoDB、BDB等存储引擎中。
对于表级锁,主要分为三类:
- 表锁
- 意向锁
- 元数据锁(META DATA LOCK,MDL)
表锁
对于表锁,又可以分为两类:
表共享读锁(read lock)
表独占写锁(write lock)
语法:
加锁
LOCK TABLES 表名… read/write;
释放锁
UNLOCK TABLES; /或者 客户端断开连接
读锁不会阻塞其他客户端的读,但是会阻塞写。写锁既会阻塞其他客户端的读,又会阻塞其他客户端的写。
元数据锁(META DATA LOCK,MDL)
MDL加锁过程是系统自动控制,无需显式使用,在访问一张表的时候会自动加上。MDL锁主要作用是维护表元数据的数据一致性,在表上有活动事务的时候,不可以对元数据进行写入操作。为了避免DML与DDL冲突,保证读写的正确性。
在MySQL5.5中引入了MDL,当对一张表进行增删改查的时候,加MDL读锁(共享);当对表结构进行变更操作的时候,加MDL写锁(排他)。
也就是说,当对数据库有增删改查操作的时候,不能改表表结构,这里锁住的元数据就是表结构,不能用alter语句,元数据读锁共享,元数据写锁排他

查看元数据锁:
select object_type,object_schema,object_name,lock_type,lock_duration from performance_schema.metadata_locks ;
意向锁
为了避免DML在执行时,加的行锁与表锁的冲突,在InnoDB中引入了意向锁,使得表锁不用检查每行数据是否加锁,使用意向锁来减少表锁的检查。
意向锁又可以分为两种:
意向共享锁(IS):由SELECT … LOCK IN SHARE MODE添加
意向排他锁(IX):由INSERT、UPDATE、DELETE、SELECT … FOR UPDATE添加
而两种锁和表锁的兼容情况如下:
意向共享锁(IS):与表锁共享锁(read)兼容,与表锁排他锁(write)互斥
意向排他锁(IX):与表锁共享锁(read)及排他锁(write)都互斥。意向锁之间不会互斥。
就是加表锁的时候加上了意向锁,意向共享锁可以允许加表读锁,意向排他锁不允许加表的任何锁,等事务执行完了才能加表锁。
可以通过以下语句,查看意向锁及行锁的加锁情况:
select object_schema,object_name,index_name,lock_type,lock_mode,lock_data from performance_schema.data_locks;
行级锁
行级锁,每次操作锁住对应的行数据。锁定粒度最小,发生锁冲突的概率最低,并发度最高。应用在InnoDB存储引擎中。
如果行级锁不加索引,会进化为表锁
InnoDB的数据是基于索引组织的,行锁是通过对索引上的索引项加锁来实现的,而不是对记录加的锁。对于行级锁,主要分为以下三类:
行锁(RECORD LOCK):锁定单个行记录的锁,防止其他事务对此行进行update和delete。在RC、RR隔离级别下都支持。
间隙锁(GAP LOCK):锁定索引记录间隙(不含该记录),确保索引记录间隙不变,防止其他事务在这个间隙进行insert,产生幻读。在RR隔离级别下都支持。
临键锁(NEXT-KEY LOCK):行锁和间隙锁组合,同时锁住数据,并锁住数据前面的间隙Gap。 在RR隔离级别下支持。
行锁
InnoDB实现了两种类型的行锁:
共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排它锁。
排他锁(X):允许获取排他锁的事务更新数据,阻止其他事务获得相同数据集的共享锁和排他锁

在默认情况下,InnoDB在REPEATABLE READ可重复读的隔离级别下运行,InnoDB使用NEXT-KEY锁进行搜索和索引扫描,以此来防止幻读。
针对唯一索引进行检索时,对已存在的记录进行等值匹配时,将会自动优化为行锁。
InnoDB的行锁是针对于索引加的锁,不通过索引条件检索数据,那么InnoDB将对表中的所有记录加锁,此时 就会升级为表锁。
可以通过以下语句,查看意向锁及行锁的加锁情况:
select object_schema,object_name,index_name,lock_type,lock_mode,lock_data from performance_schema.data_locks;
间隙锁/临键锁
默认情况下,InnoDB在 REPEATABLE READ事务隔离级别运行,InnoDB使用 next-key 锁进行搜索和索引扫描,以防止幻读。
- 索引上的等值查询(唯一索引),给不存在的记录加锁时,优化为间隙锁
- 索引上的等值查询(非唯一普通索引),向右遍历时最后一个值不满足查询需求时,next-key lock退化为间隙锁
- 索引上的范围查询(唯一索引)会访问到不满足条件的第一个值为止
- 间隙锁唯一目的是防止其他事务插入间隙。间隙锁可以共存,一个事务采用的间隙锁不会阻止另一个事务在同一间隙上采用间隙锁。
慢查询
如何定位慢查询?

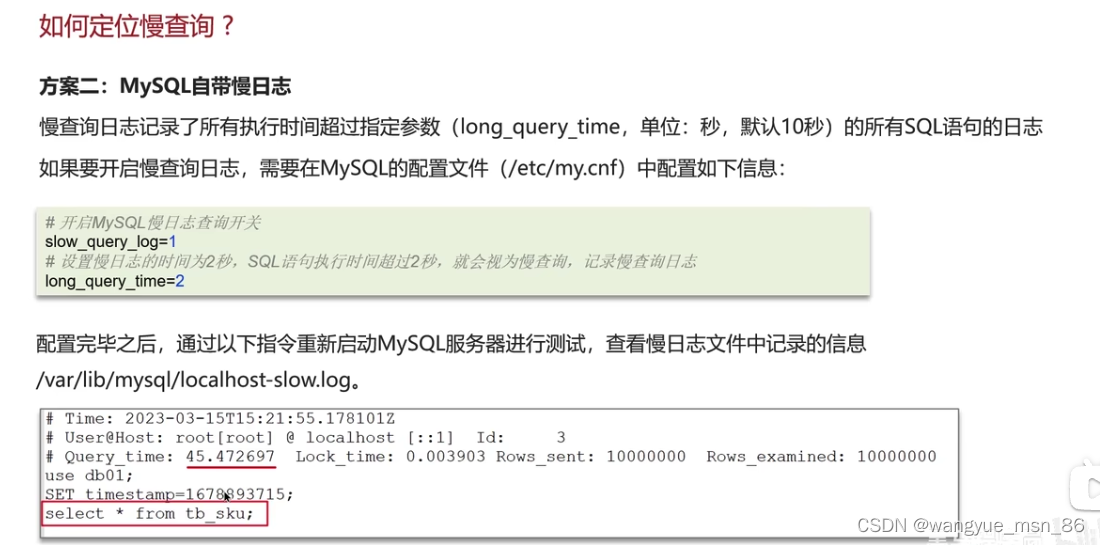
如何分析慢查询?

Redis
Redis数据结构
1.字典
所谓字典,其实就是key value的结构,整个Redis就是这么一个字典结构,因为都是一个key对应一个value,所以整个Redis的结构就是一个Hash表,但是从途中可见,是有两个哈希表的,第二个哈希表平时不使用,只是在第一个需要扩容的时候使用第二个,然后互换身份。
当第一个hash表满足扩容条件了,触发Rehash,慢慢把数据扩容到第二hash表中,这叫渐进式的rehash,因此一次扩容过去会导致停顿时间太长用户无法接受。渐进式rehash期间增删改查需要同时访问两个hash表了就。
触发Rehash的条件有两个:
- 没有执行BGSAVE和BGREWRITEAOF命令时,并且哈希表的负载因子大于等于1
- 在执行BGSAVE和BGREWRITEAOF命令,并且哈希表的负载因子大于等于,虽然在执行持久化,但是此时数组中的元素过多,冲突太频繁
负载因子 = 哈希表已经保存的结点数量/哈希表大小
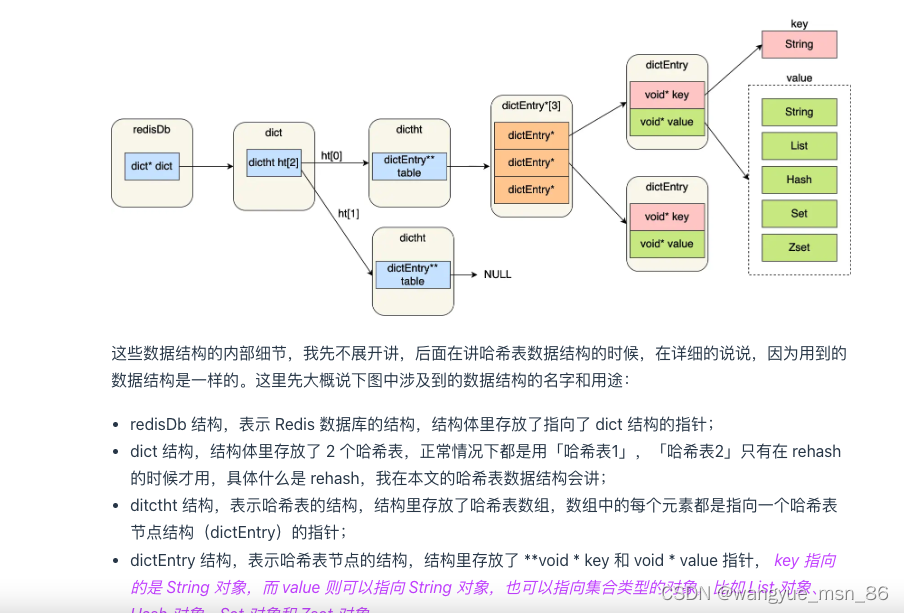
2.String类型:sds
为什么不用c语言的字符数组而是自己实现了一个sds呢?
- 因为c语言字符串判断结尾是通过/0的方式判断的,如果用他的话字符串中不能出现反斜杠0
- 因为c语言字符串获取长度和在尾部追加字符串都需要遍历获取长度,性能太差,用sds以后,有一个字段记录了len,所以性能更好
3.Zset实现:跳表
Zset有两种实现方式:
1.同时满足元素数量小于128和所有成员长度都小于64字节的时候,使用压缩列表实现(ziplist),7.0版本后已经废弃,改为listpack
2.最重要的是使用跳表+hash表(字典的方式来实现),里面既有一个hash表,又有一个跳表··
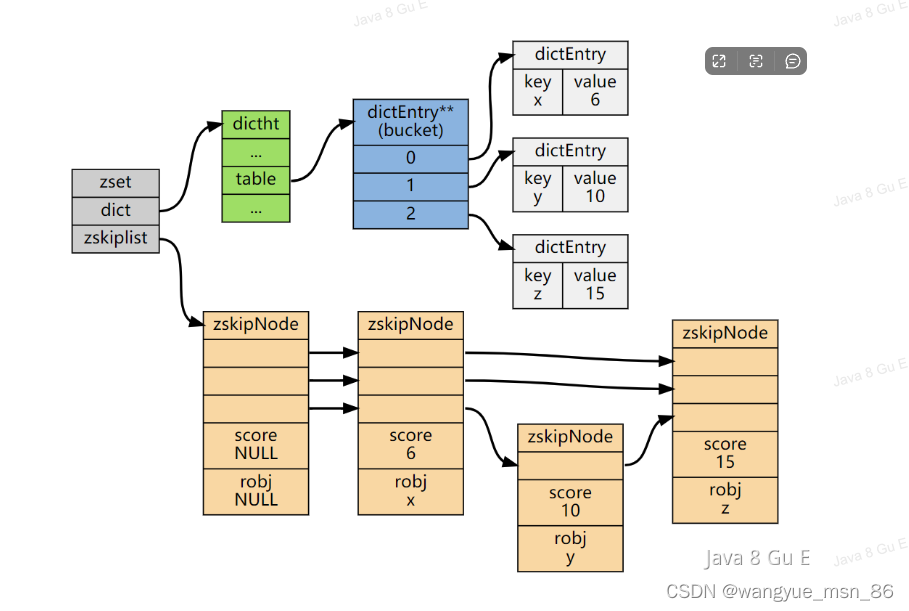
Hash表的作用只是为了查找某个元素排名的时候,有O(1)的复杂度,其余操作是由跳表完成的。
为什么使用跳表,而不是红黑树或者B+树这种数据结构,只是因为跳表实现比较简单,也不需要树结构的调整过程,比较方便。结构上有点像b+树,最底层的叶子结点,指针相连,前后指针
详细一点的话:
- 从内存占用上来比较,跳表比平衡树更灵活一些。平衡树每个节点包含 2 个指针(分别指向左右子树),而跳表每个节点包含的指针数目平均为 1/(1-p),具体取决于参数 p 的大小。如果像 Redis里的实现一样,取 p=1/4,那么平均每个节点包含 1.33 个指针,比平衡树更有优势。
- 在做范围查找的时候,跳表比平衡树操作要简单。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在跳表上进行范围查找就非常简单,只需要在找到小值之后,对第 1 层链表进行若干步的遍历就可以实现。
- 从算法实现难度上来比较,跳表比平衡树要简单得多。平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而跳表的插入和删除只需要修改相邻节点的指针,操作简单又快速。
跳表的相邻两层的节点数量最理想的比例是 2:1,查找复杂度可以降低到 O(logN)。
下图的跳表就是,相邻两层的节点数量的比例是 2 : 1。
因为2比1的话,查找的时候就相当于在链表上进行二分查找了
怎样创建各级索引,产生随机数,随机生成索引
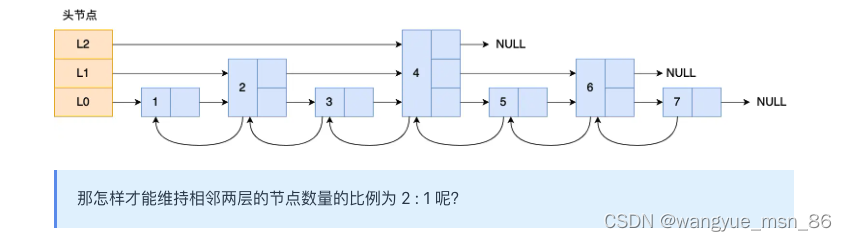
Redis 则采用一种巧妙的方法是,跳表在创建节点的时候,随机生成每个节点的层数,并没有严格维持相邻两层的节点数量比例为 2 : 1 的情况。
具体的做法是,跳表在创建节点时候,会生成范围为[0-1]的一个随机数,如果这个随机数小于 0.25(相当于概率 25%),那么层数就增加 1 层,然后继续生成下一个随机数,直到随机数的结果大于 0.25 结束,最终确定该节点的层数。
这样的做法,相当于每增加一层的概率不超过 25%,层数越高,概率越低,层高最大限制是 64。
虽然我前面讲解跳表的时候,图中的跳表的「头节点」都是 3 层高,但是其实如果层高最大限制是 64,那么在创建跳表「头节点」的时候,就会直接创建 64 层高的头节点。
// 跳表结点信息
typedef struct zskiplistNode {
//Zset 对象的元素值
sds ele;
//元素权重值
double score;
//后向指针,指向上一个元素
struct zskiplistNode *backward;
//节点的level数组,保存每层上的前向指针和跨度
struct zskiplistLevel {
struct zskiplistNode *forward; // 指向右边元素的指针
unsigned long span; // 跨度
} level[];
} zskiplistNode;
有了跨度就可以近似做二分查找了
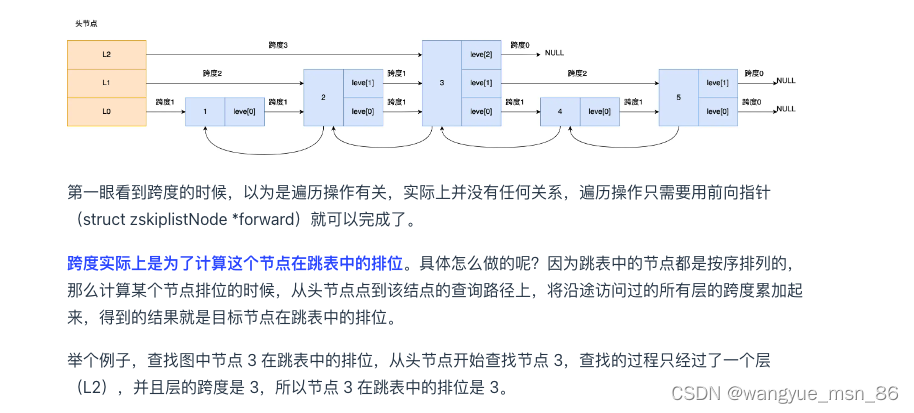
如果上面两个条件都不满足,或者下一个节点为空时,跳表就会使用目前遍历到的节点的 level 数组里的下一层指针,然后沿着下一层指针继续查找,这就相当于跳到了下一层接着查找。
举个例子,下图有个 3 层级的跳表。

如果要查找「元素:abcd,权重:4」的节点,查找的过程是这样的:
- 先从头节点的最高层开始,L2 指向了「元素:abc,权重:3」节点,这个节点的权重比要查找节点的小,所以要访问该层上的下一个节点;
- 但是该层的下一个节点是空节点( leve[2]指向的是空节点),于是就会跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve[1];
- 「元素:abc,权重:3」节点的 leve[1] 的下一个指针指向了「元素:abcde,权重:4」的节点,然后将其和要查找的节点比较。虽然「元素:abcde,权重:4」的节点的权重和要查找的权重相同,但是当前节点的 SDS 类型数据「大于」要查找的数据,所以会继续跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve[0];
- 「元素:abc,权重:3」节点的 leve[0] 的下一个指针指向了「元素:abcd,权重:4」的节点,该节点正是要查找的节点,查询结束。
4.hyperloglog、Geo、bitmap
hyperloglog:
UA统计适合用hyperloglog做,虽然有点误差,但是内存永远小于16kb,有一定的误差容忍的场景非常合适。UA统计可以统计一天大概有多少人来访问,然后合并每天的人数。
- UV:全称Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次访问该网站,只记录1次。
- PV:全称Page View,也叫页面访问量或点击量,用户每访问网站的一个页面,记录1次PV,用户多次打开页面,则记录多次PV。往往用来衡量网站的流量。
通常来说PV会比UV大很多,所以衡量同一个网站的访问量,我们需要综合考虑很多因素,所以我们只是单纯的把这两个值作为一个参考值
UV统计在服务端做会比较麻烦,因为要判断该用户是否已经统计过了,需要将统计过的用户信息保存。但是如果每个访问的用户都保存到Redis中,数据量会非常恐怖,那怎么处理呢?
Hyperloglog(HLL)是从Loglog算法派生的概率算法,用于确定非常大的集合的基数,而不需要存储其所有值。相关算法原理大家可以参考:https://juejin.cn/post/6844903785744056333#heading-0
Redis中的HLL是基于string结构实现的,单个HLL的内存永远小于16kb,内存占用低的令人发指!作为代价,其测量结果是概率性的,有小于0.81%的误差。不过对于UV统计来说,这完全可以忽略
BitMap:
位图,使用一个数组的某一个位来记录某个元素有没有出现过,打比方有个int的数组吧,每个int是32位,来了个数660,先找到这个数是数组的第几个数,用660除32,然后找到在这个数的第几位 设为n,用660余32,置1的时候,把1左移刚才求的n位数,然后按位或1就可以了
// 5.写入Redis SETBIT key offset 1,把某个用户作为key,今天是本月的第几天 对应的位置1,标志用户签到过
stringRedisTemplate.opsForValue().setBit(key, dayOfMonth - 1, true);
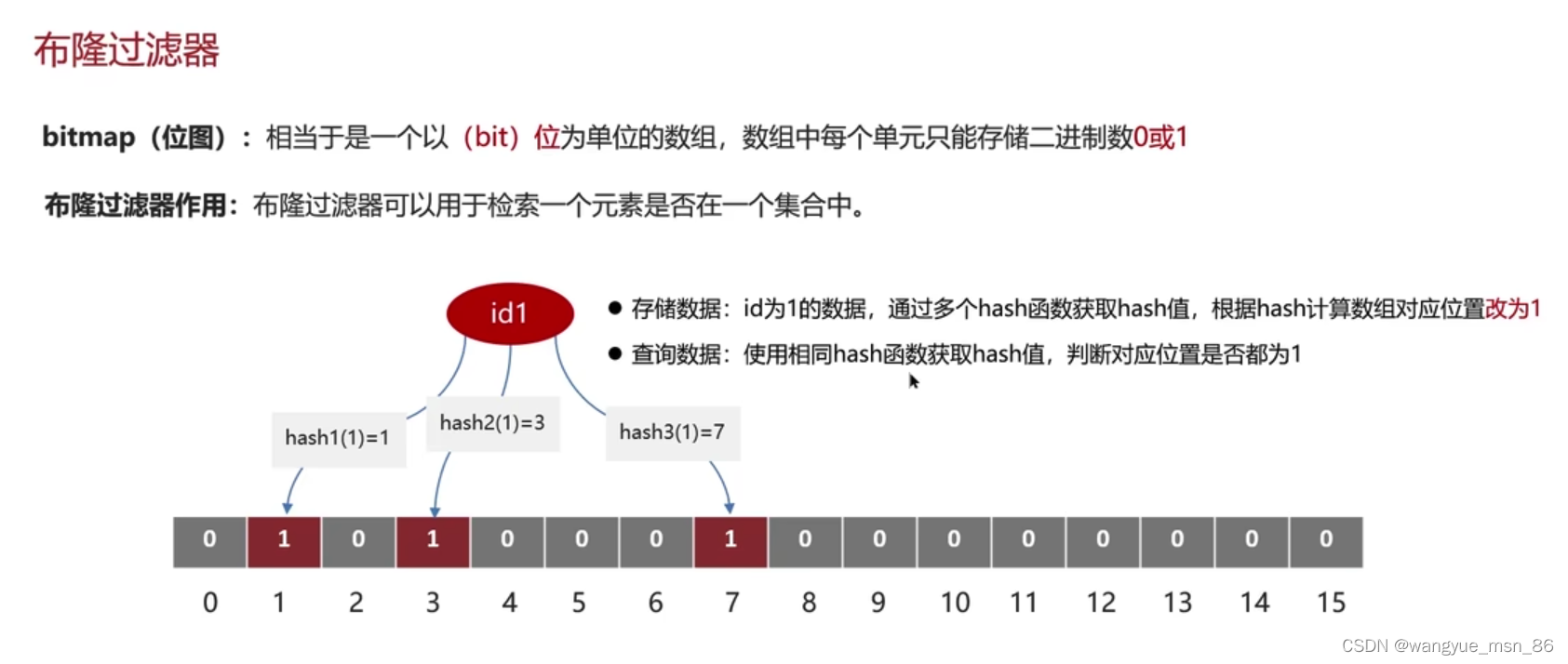
位图有一个升级版,布隆过滤器,使用的就是位图,外加多个hash函数,一个hashcode经过多次hash给不同的位置1,有一定的误判率,可以设置误判率,误判率设置小的话,那么显然数组长度比较大,哈希函数的数量也比较多。
Geo:
Redis GEO 是 Redis 3.2 版本新增的数据类型,主要用于存储地理位置信息,并对存储的信息进行操作
GEO 本身并没有设计新的底层数据结构,而是直接使用了 Sorted Set 集合类型。
GEO 类型使用 GeoHash 编码方法实现了经纬度到 Sorted Set 中元素权重分数的转换,这其中的两个关键机制就是「对二维地图做区间划分」和「对区间进行编码」。一组经纬度落在某个区间后,就用区间的编码值来表示,并把编码值作为 Sorted Set 元素的权重分数。
用途是可以把各个商家的地理位置,就是经纬度存进去,然后可以根据用户的位置排序,计算离用户最近的前几个商家,sortedSet的score可能是两者距离的差值
缓存
如何解决缓存穿透?
缓存穿透就是查询不存在的数据,请求都会到数据库:
- 缓存空数据(该项目使用这种方式)
- 布隆过滤器
缓存空对象的缺点:
- 缓存一致性问题: 使用缓存空数据时,需要考虑如何保持缓存的一致性。如果在数据库中的数据发生变化(例如新增、更新或删除数据),但缓存中的空数据没有及时更新,就会导致缓存与数据库不一致的问题。
- 缓存占用空间: 缓存空数据也会占用一定的内存空间。如果缓存中的空数据过多,可能会导致内存资源不足,从而影响其他重要数据的缓存。
布隆过滤器:
要确定误判率设置成多少,设置小的话需要增加哈希函数个数,并且增加数组长度。
要保证一致性,预热完了以后,那么数据库插入数据也要给布隆过滤器插入,删除就容忍
我们项目中使用的就是缓存空数据的方式来解决缓存穿透的,布隆过滤器比较 复杂,且有一定的误判率,如果想降低误判率要增大数组的大小。而我们的项目只有内网能访问到,使用缓存空数据的方法就可以了。在数据库查不到的时候,

黑马点评解决缓存穿透:
// 防止缓存穿透
public Shop queryWithPassThrough(Long id){
String key = CACHE_SHOP_KEY+id;
String shopJson = stringRedisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(shopJson)){
// redis中存在,直接返回
Shop shop = JSONUtil.toBean(shopJson,Shop.class);
return shop;
}
// 判断命中的是否有空值
if (shopJson!=null){
return null;
}
// 不存在,根据id查询数据库
Shop shop = getById(id);
if (shop == null){
// 将空值写入redis中,防止缓存穿透
stringRedisTemplate.opsForValue().set(key,"",CACHE_NULL_TTL,TimeUnit.MINUTES);
return null;
}
// 存在,写入redis中
stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);
return shop;
}
布隆过滤器:相当于一个大的字节类型的数组,key来了以后,通过3次不同的hash,计算数组对应的位置改为1,如果三个位置都是1,说明存在这个集合中
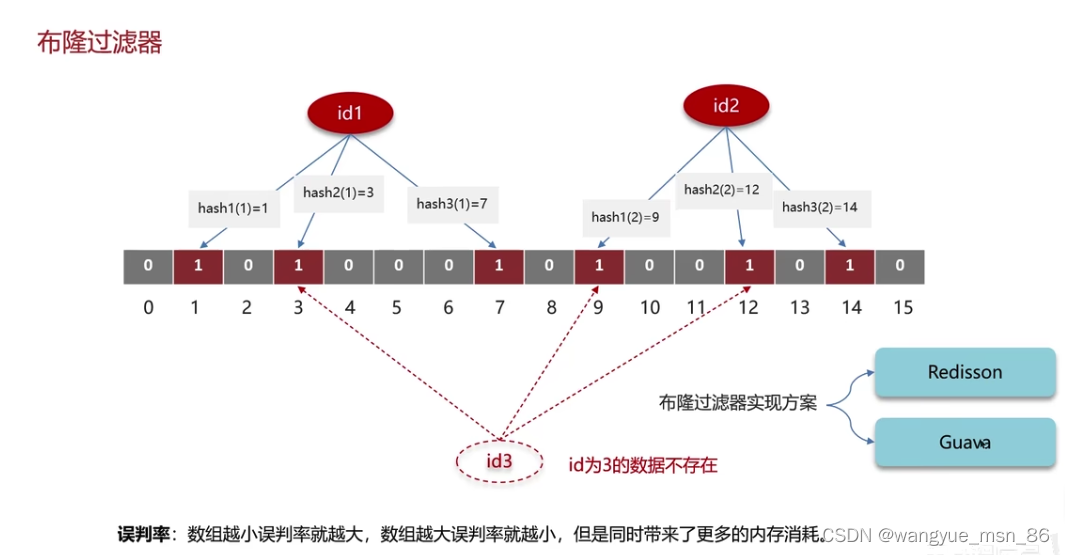
是有一定的误判率的,比如id为3的数据是不存在的,但是经过3次hash,对应位置也都是1,数组大误判率才小
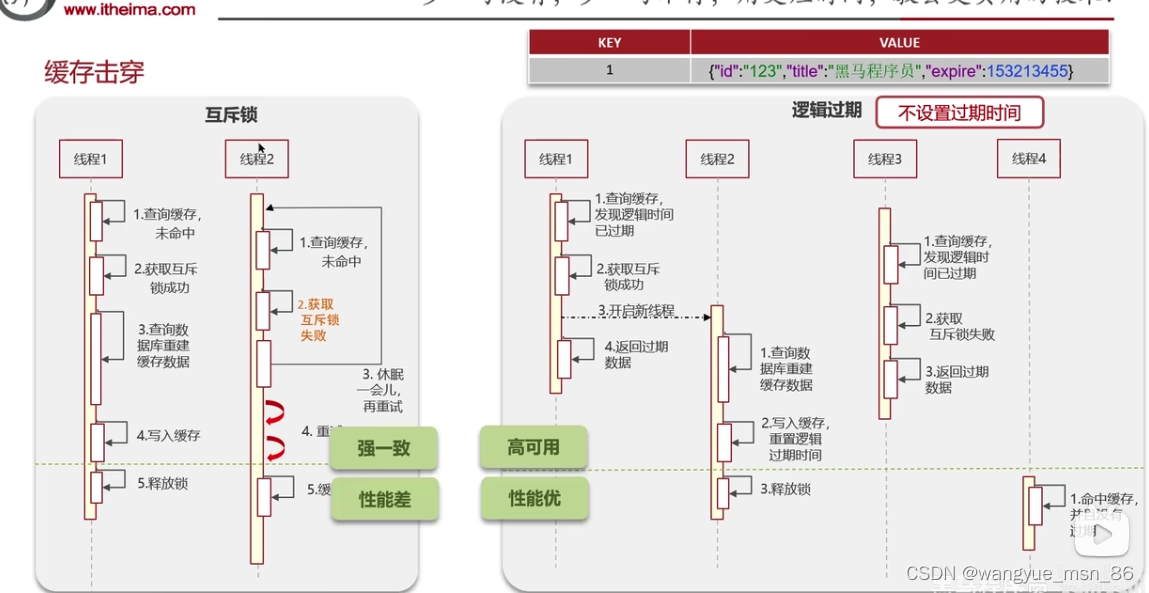
如何解决缓存击穿?
缓存击穿就是热点key突然过期,然后大量的请求打到了数据库,数据库承担不了压力。
本项目使用的是逻辑过期的方式解决的。因为互斥锁的方式性能太低,而本项目一致性要求没有那么高,所以选择逻辑过期方式

互斥锁:就是分布式锁,查询如果拿不到锁就一直等待,性能比较低
逻辑过期:加锁,新开一个线程去查数据库写缓存,其他线程直接返回过期的值,一致性暂时没有那么好
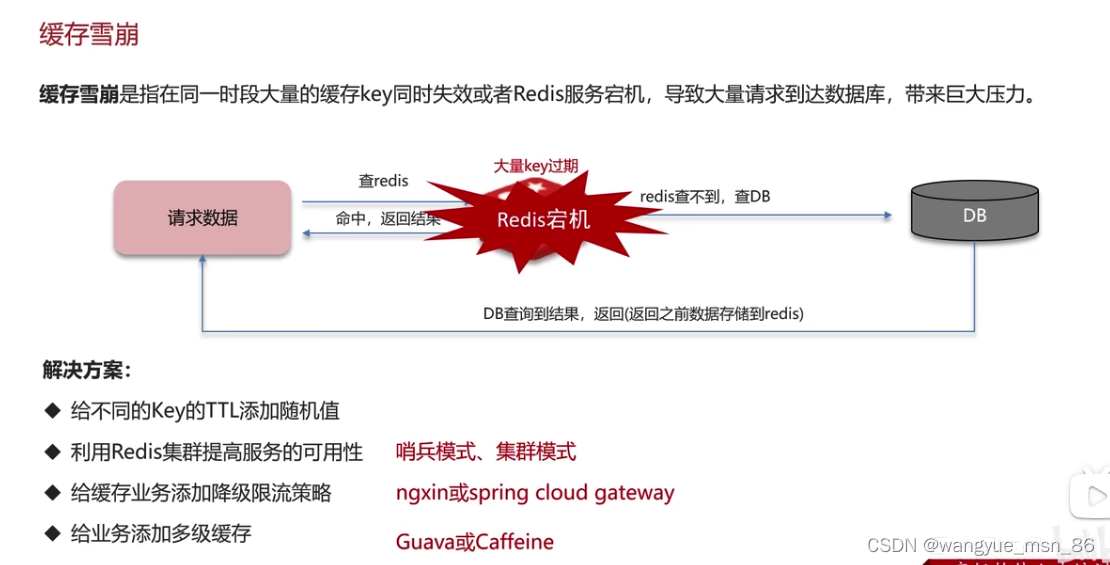
如何解决缓存雪崩?
本项目是尽量给不同的key的ttl添加随机值
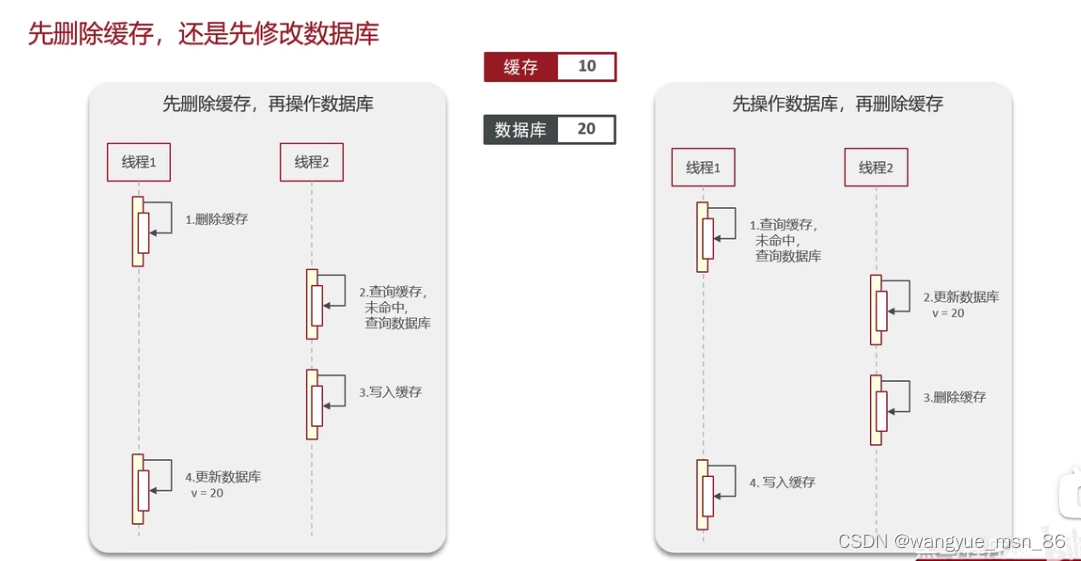
如何保证缓存双写一致性问题?
可见这两种方式都会出现不一致的现象:
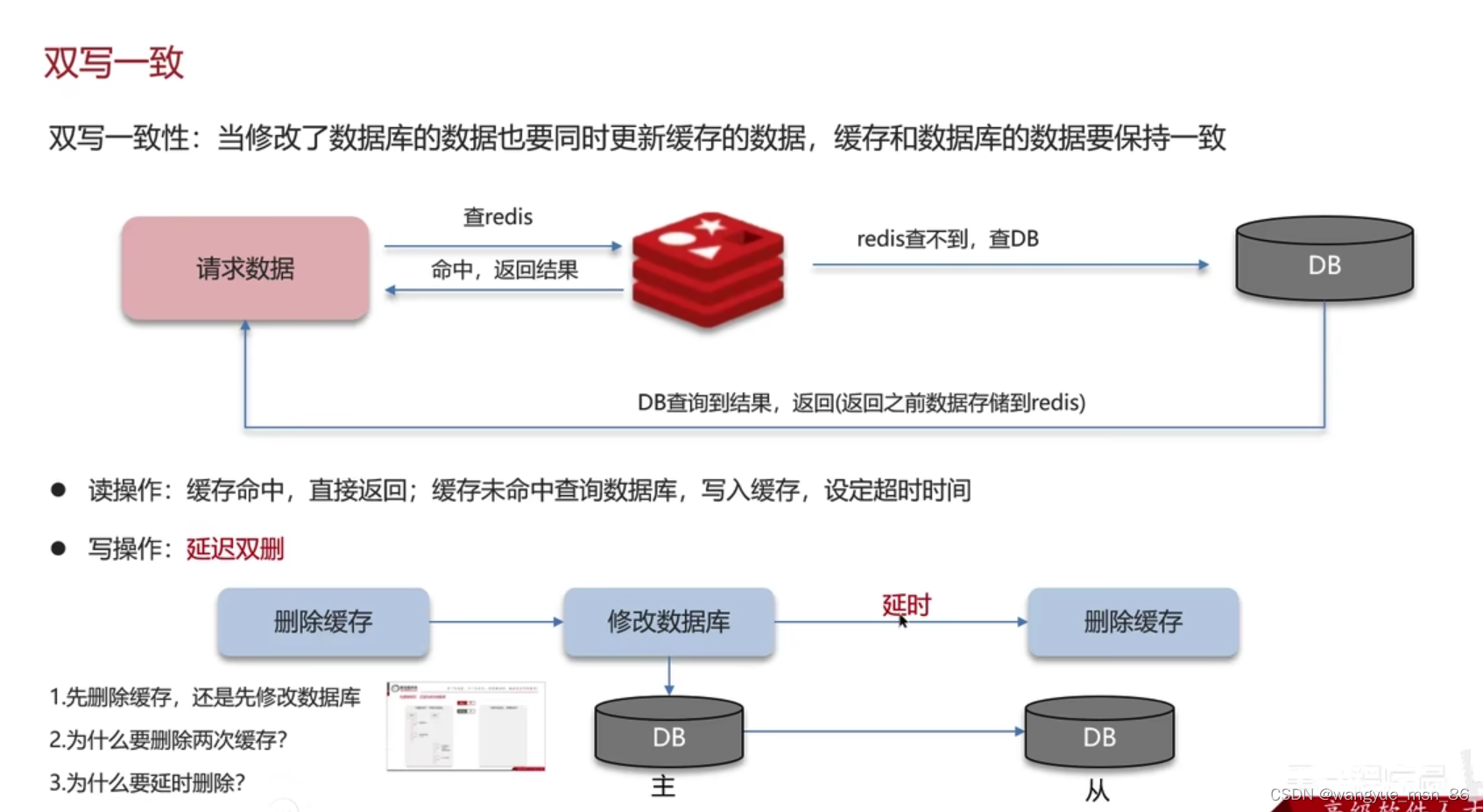
延迟双删:
- 为什么双删? 上面的先删缓存再更新数据库也会出现问题。 所以再删除一次,减少脏数据的出现
- 为什么延时? 因为数据库经常是主从模式 需要一些时间 让主节点把数据传到从节点
但是延迟双删还是有出现脏数据,因为迟时间不容易判断,也没法保证强一致,在延时的时候有可能出现不一致
强一致手段:加分布式锁 redssion等。 加redssion的读写锁
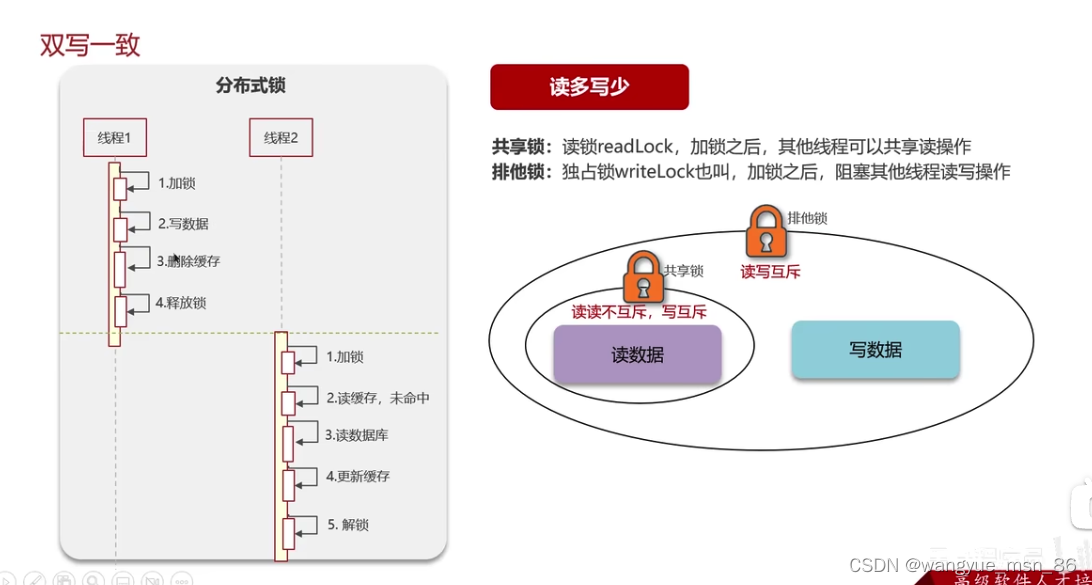
如果不追求强一致性,只追求最终一致性的方法:
- 使用mq来保证最终一致性,数据库修改后发送消息,缓存服务来接收消息,更新缓存,因为MQ是可以保证可靠性的,所以保证了最终一致性
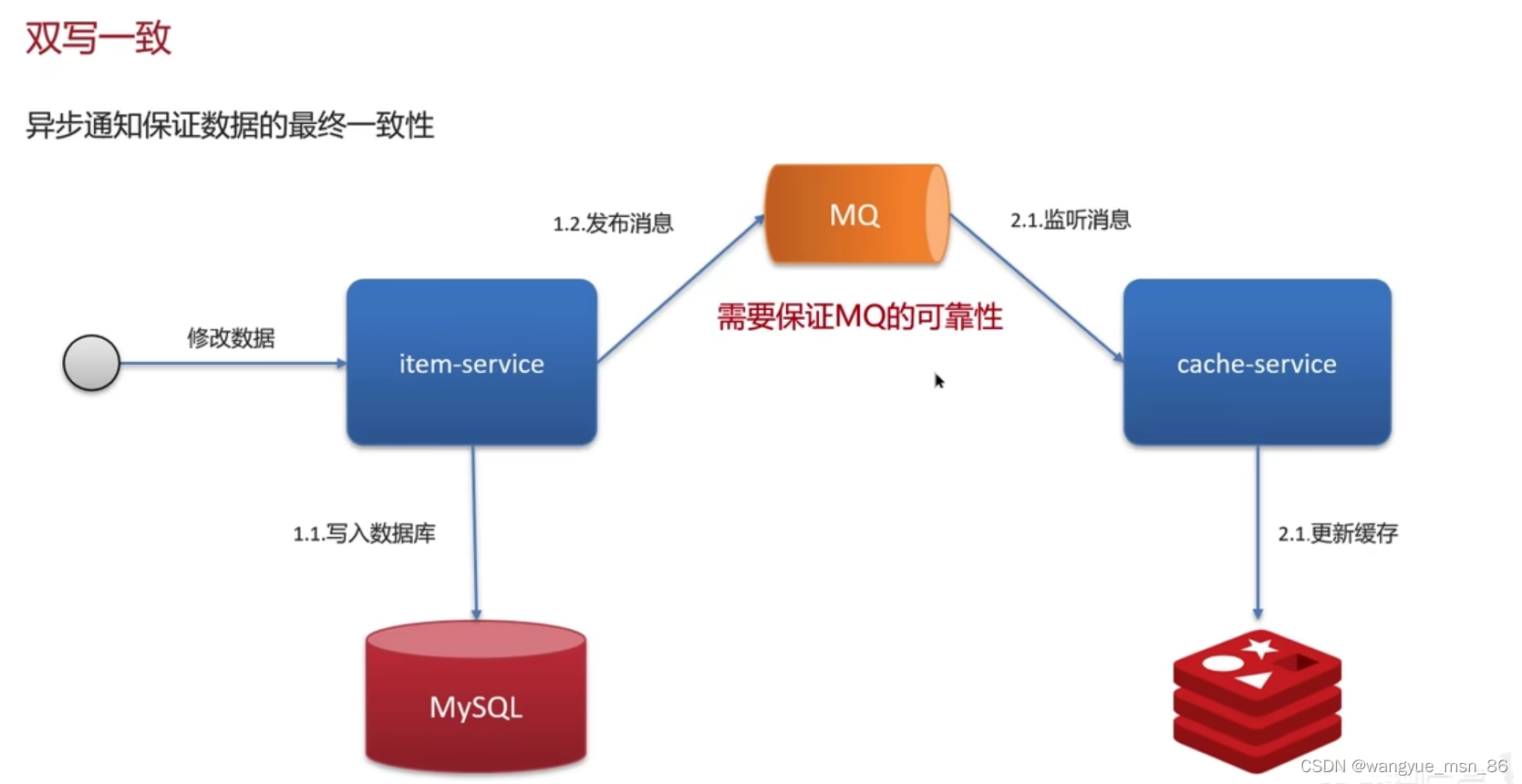
-
使用阿里的canal:基于mysql的主从同步来实现的无侵入性,比较推荐
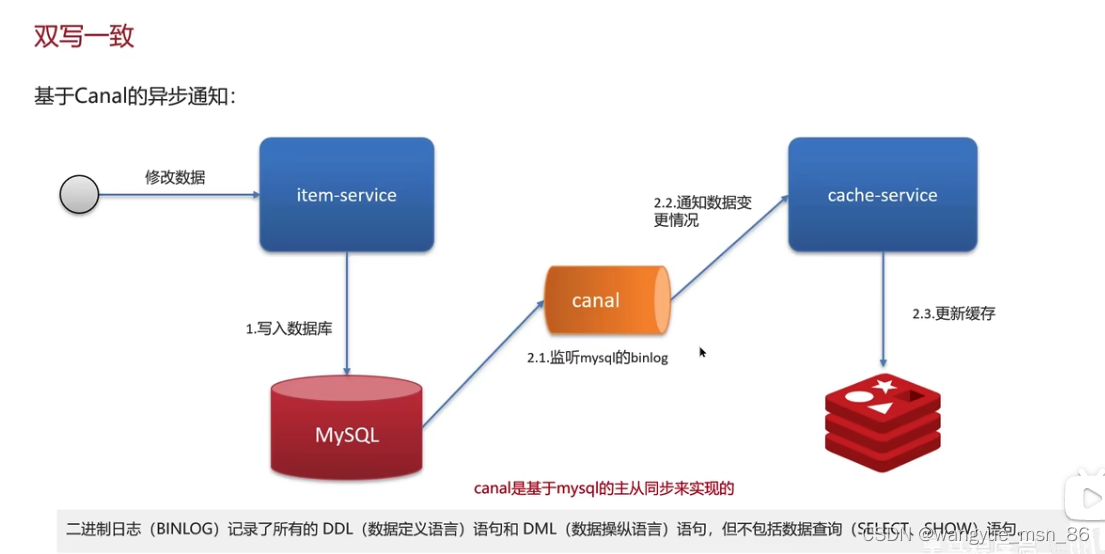
回答:分两种
我的项目是不要求强一致性的,所以使用RabbitMQ的方式实现了最终一致性

Redis数据过期策略
Redis是惰性删除和定期删除配合使用的


只使用惰性删除的缺点:容易有很多过期的没有删除影响内存
只用定期删除:最大的问题是,比如1s钟删除一次,那么如果有正好要过期的,在下一次删除之前过期了,那么你仍然可以访问到这个过期数据,就会造成一致性问题。
还有定期删除会浪费cpu,要定期的执行
Redis数据淘汰策略(LRU和LFU)
记住默认的 理解LRU和LFU

数据淘汰策略建议:


Redis大key的处理方法
什么是Redis大key?
- string类型的值超过10kb
- hash,list,set,zset元素超过5000个
如何找到大key?string类型通过命令查找,其他类型通过一个工具(RDBTools)查找

删除大key:
推荐的方法:使用unlink代替del进行异步删除,会开启一个异步线程,不会阻塞主线程
直接删除会阻塞主线程,影响起来请求的执行,在凌晨挑选用户访问少的时候删除,或者分批次删除,但是还是异步删除的方式比较好

如何大key不能删除,比如业务上还需要用大key,那么可以把大key分掉,就像分库分表一样,比如跟据日期等进行拆分,或者使用分片集群模式,将大key分散到不同的服务器上。
持久化
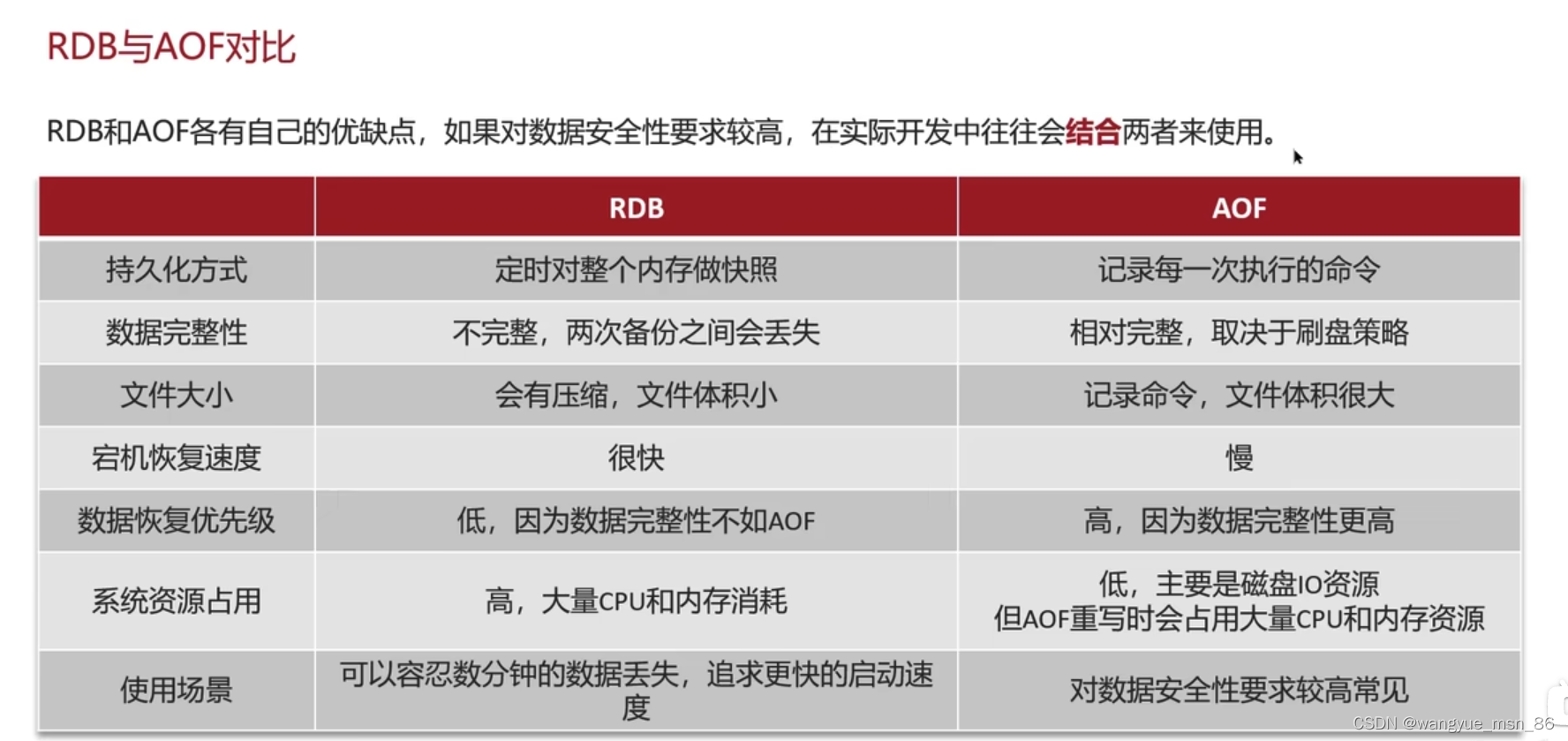
Redis数据持久化是怎么做的?
RDB和AOF
RDB:Redis数据快照,把内存中的数据都记录到磁盘。bgsave比较好,是开启子进程(注意是进程不是线程)执行RDB。通过设置配置文件,可以自动执行bgsave

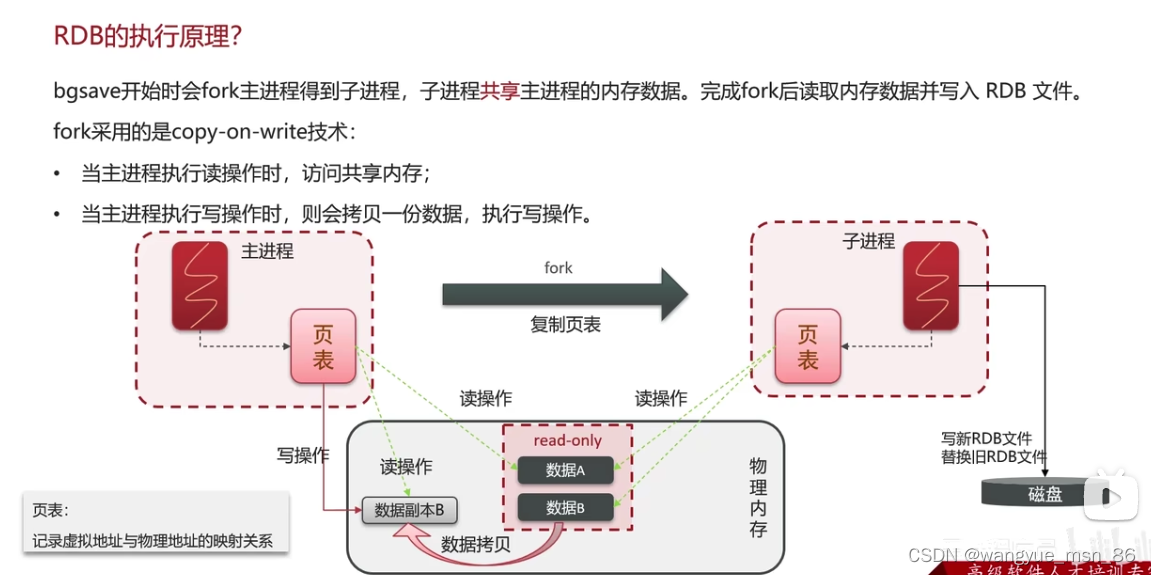
RDB bgsave的原理:
主进程fork一个子进程,fork相当于复制了,操作系统通过页表来映射虚拟地址(逻辑地址)和物理地址,所以只需要复制页表到子进程就行了。
子进程将新的rdb文件替换旧的rdb文件,但是这时候主进程可以写,有可能造成脏数据怎么办
fork采用copy on write技术 当两个进程读时,访问共享内存,当主进程写时,拷贝一份数据,执行写操作,这以后主进程再读也是读拷贝的数据,避免了脏写的问题
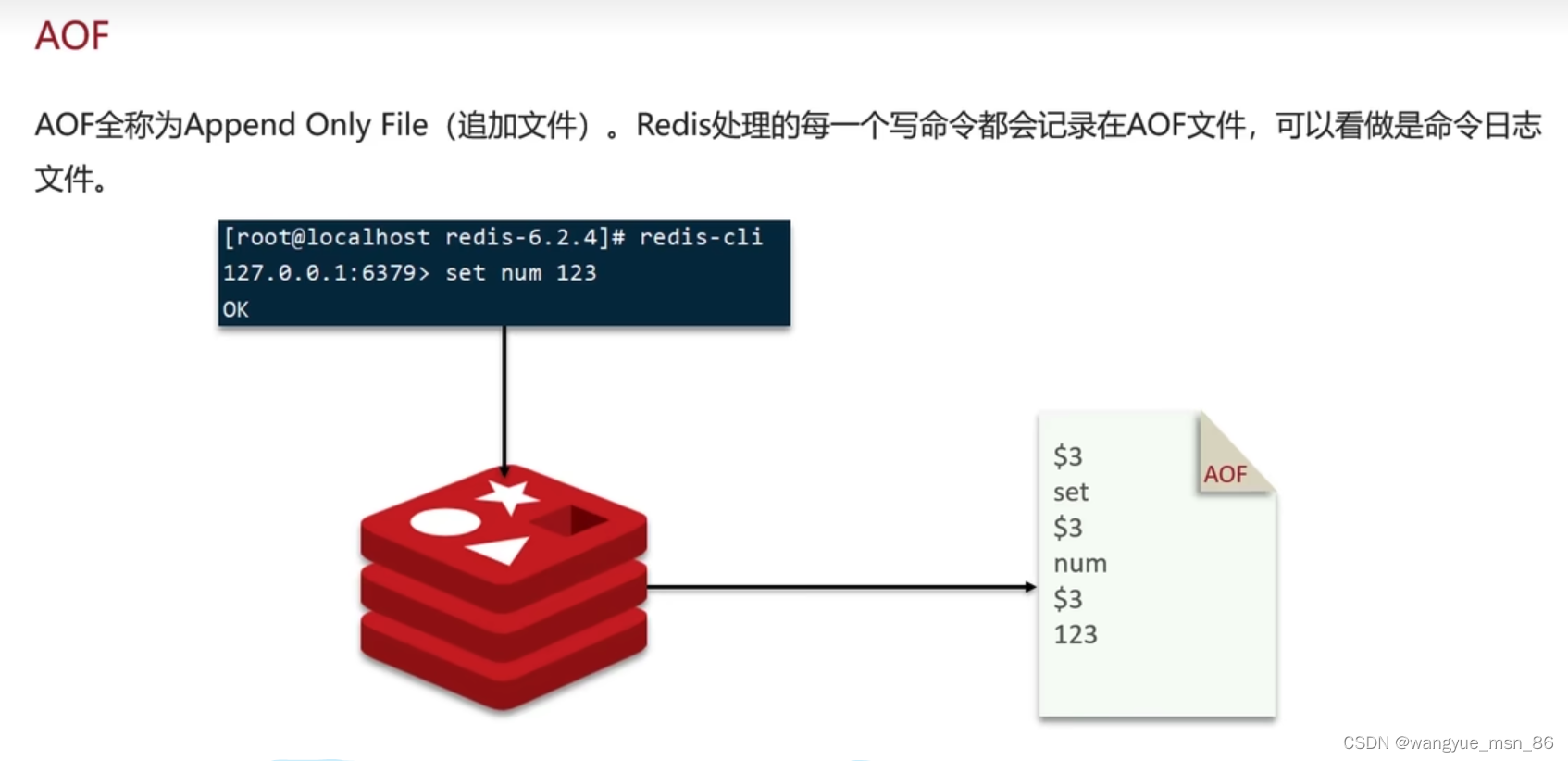
AOF :追加文件,redis处理的写命令都会记录在AOF文件中
AOF默认关闭的:修改配置文件开启
配置频率:always 每执行写命令 都记录
everysec(就用这个):每隔一秒将缓冲区数据写到AOF文件
AOF重写:如果set一个key好几次 是不是只有最后一次有意义,可以对AOF文件重写,合并重复的命令。 也可以修改配置文件达到阈值自动重写

二者的比较:
我们使用的是AOF来恢复的,因为他丢失数据的风险比较小,当是设置的是每秒批量写入一次数据 ,当redis宕机的时候,用AOF文件再运行一遍命令就行了
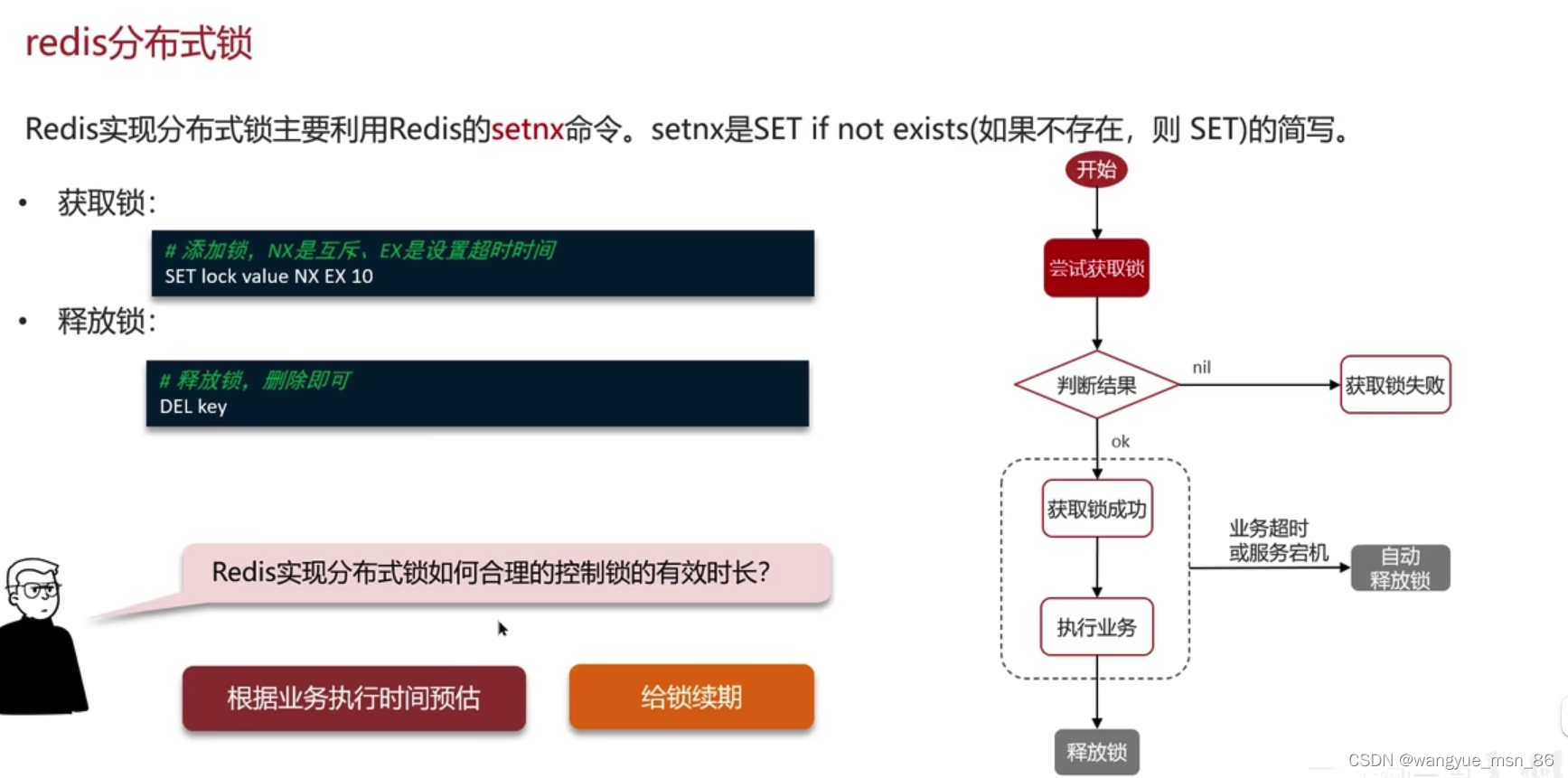
分布式锁
setNX命令,以及他的问题:
如果有个业务时间很长,业务没执行完setNX过期了怎么办:给锁续期,就是看门狗机制
redisson:强化了setNX,开一个看门狗线程为锁进行续期,这就比不设置过期时间强,遇到意外如宕机之类的情况锁可以释放。
其他获取锁的线程通过自旋的方式等待,比阻塞性能要好;
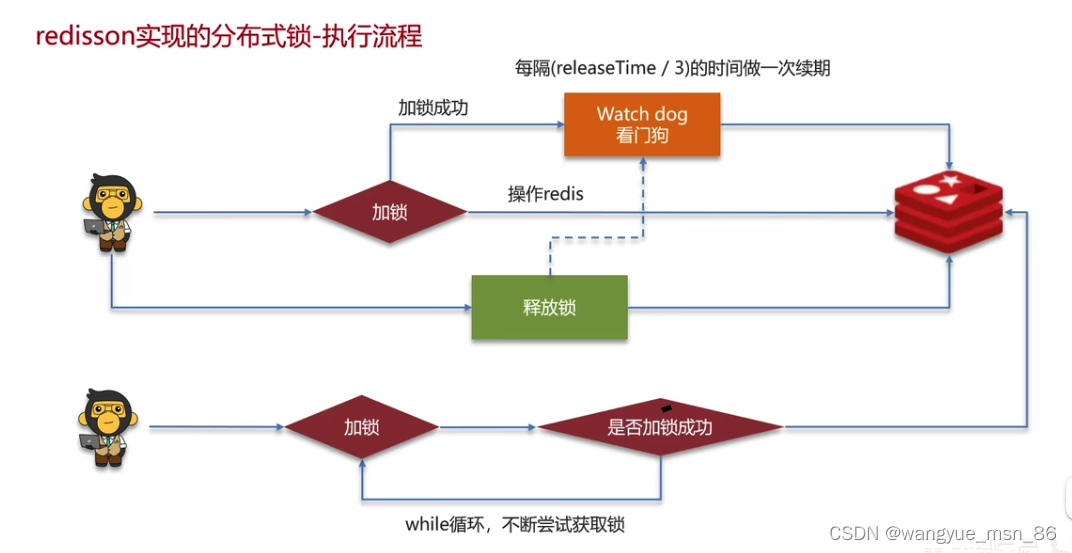
redisson可重入,redisson上锁和设置过期时间是通过lua脚本执行的,保证了原子性。
Redis为什么快
瓶颈在于网络而不是执行速度

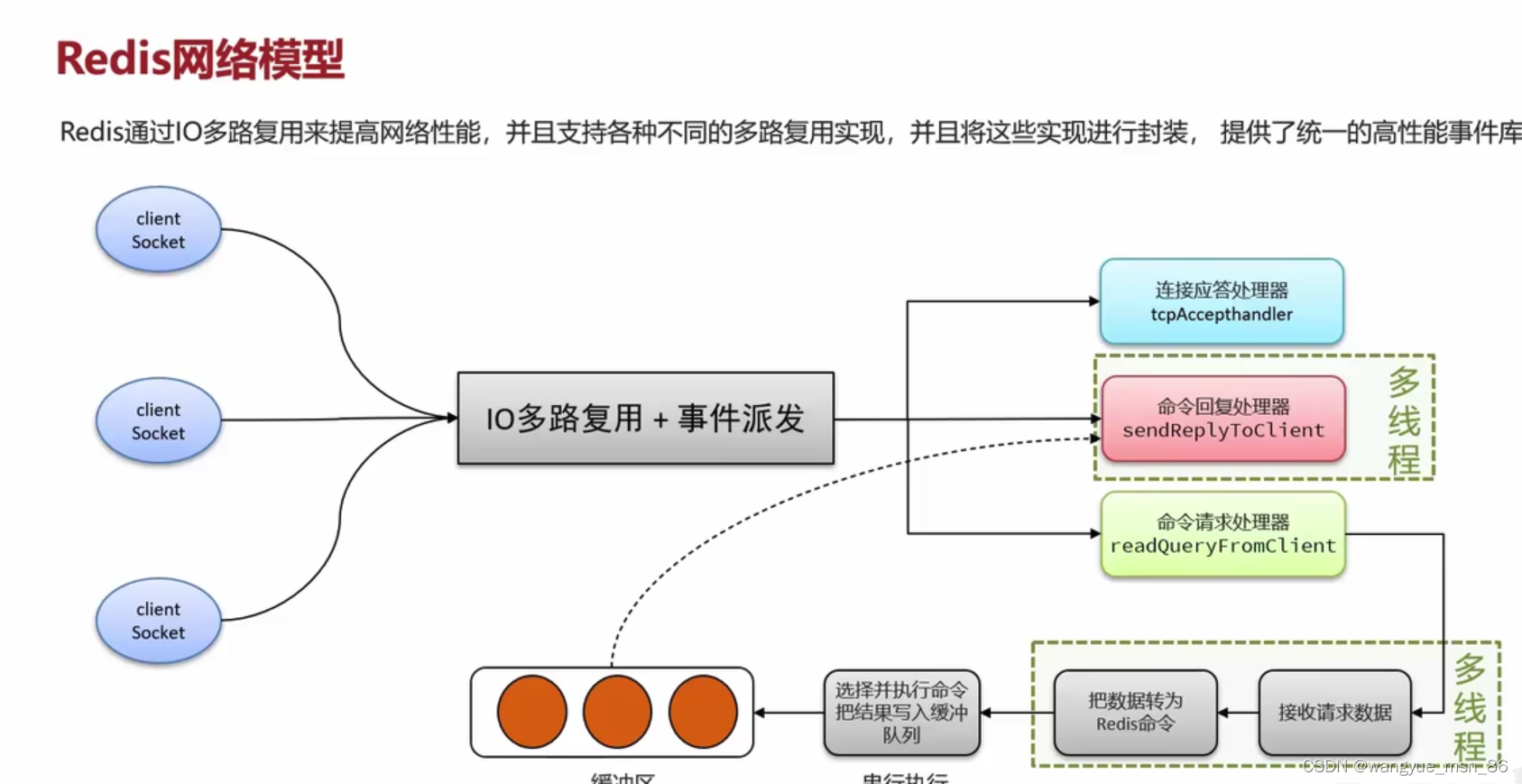
单个线程监听多个Socket,相当于全班人去等饭,只留下一个人等消息,谁的饭好的就发消息告诉他好了,那么是不是其他人的时间就节省了
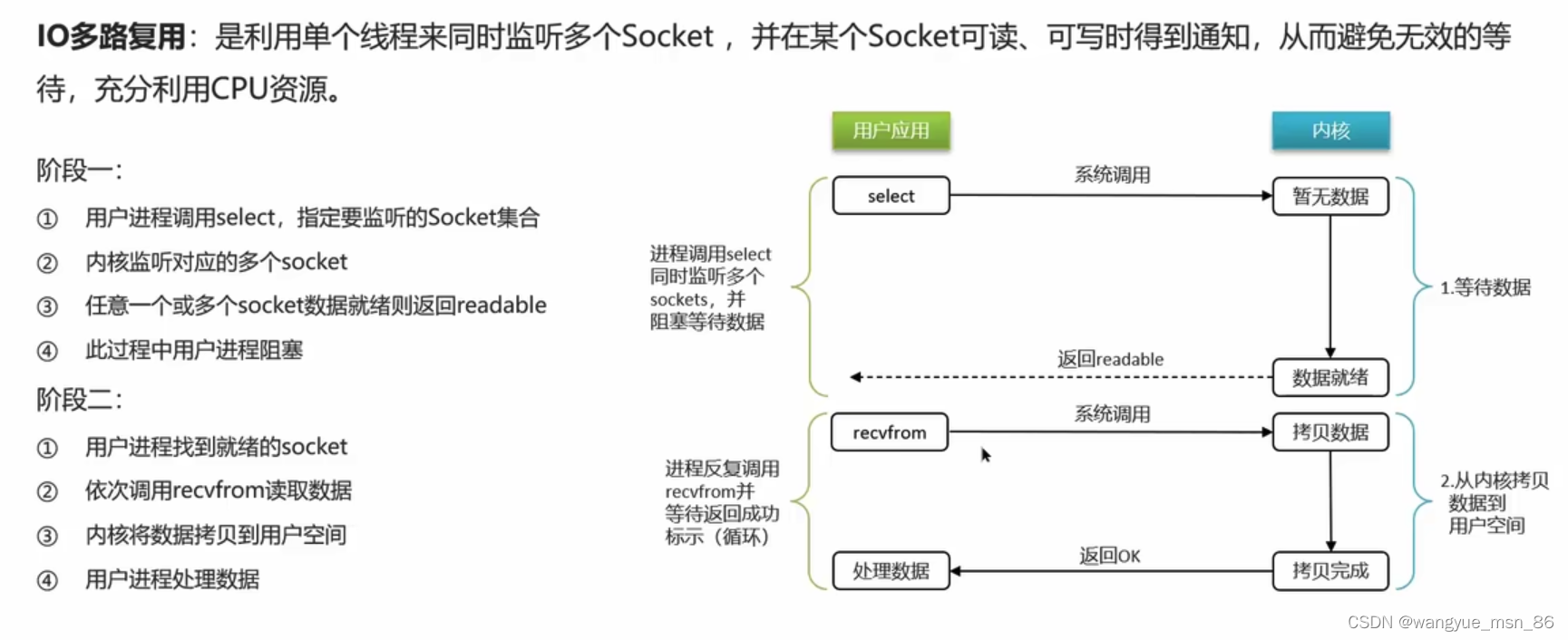
select和poll不知道具体是哪个socket就绪,epoll不用遍历

IO多路复用+事件派发 解析命令和命令回复是多线程
JVM
JVM内存结构
什么是程序计数器?
程序计数器用于保存字节码行号,用来记录正在执行的字节码指令的地址,是线程私有的
JVM内存结构?
共有5部分:
- 程序计数器:记录当前线程执行的字节码行号,线程私有
- 虚拟机栈:存放基本数据类型,引用类型,方法的出口,线程私有
- 本地方法栈:和虚拟机栈类似,不过服务的是本地方法,线程私有
- 堆:Java内存最大的一块,所有对象实例和数组的存放区,线程共享,垃圾回收的主要区域
- 方法区:存放已经被加载的类型信息,常量,静态变量,线程共享
方法区、元空间、永久代的区别?
方法区是Java虚拟机规范中规定的区域,而元空间和永久代是该规范的两个实现,java8之前叫永久代,java8之后叫元空间。
java8之后,元空间移动到了本地内存(防止放在堆里容易产生OOM),但字符串常量池仍留在堆里

讲讲虚拟机栈?
1.比较重要,由多个栈桢组成,对应着每次方法调用时占用的内存,以及只能有一个活动栈桢对应着当前正在执行的方法ddddddddddd
3.默认栈内存是1024k,加入机器总内存512m,那么目前能活动的线程就是512个,如果把栈内存改为2048,能活动的线程就减半了
堆内存不足 :oom outofmemoryError
栈内存不足:stackoverflowError 都是error类型,比较严重

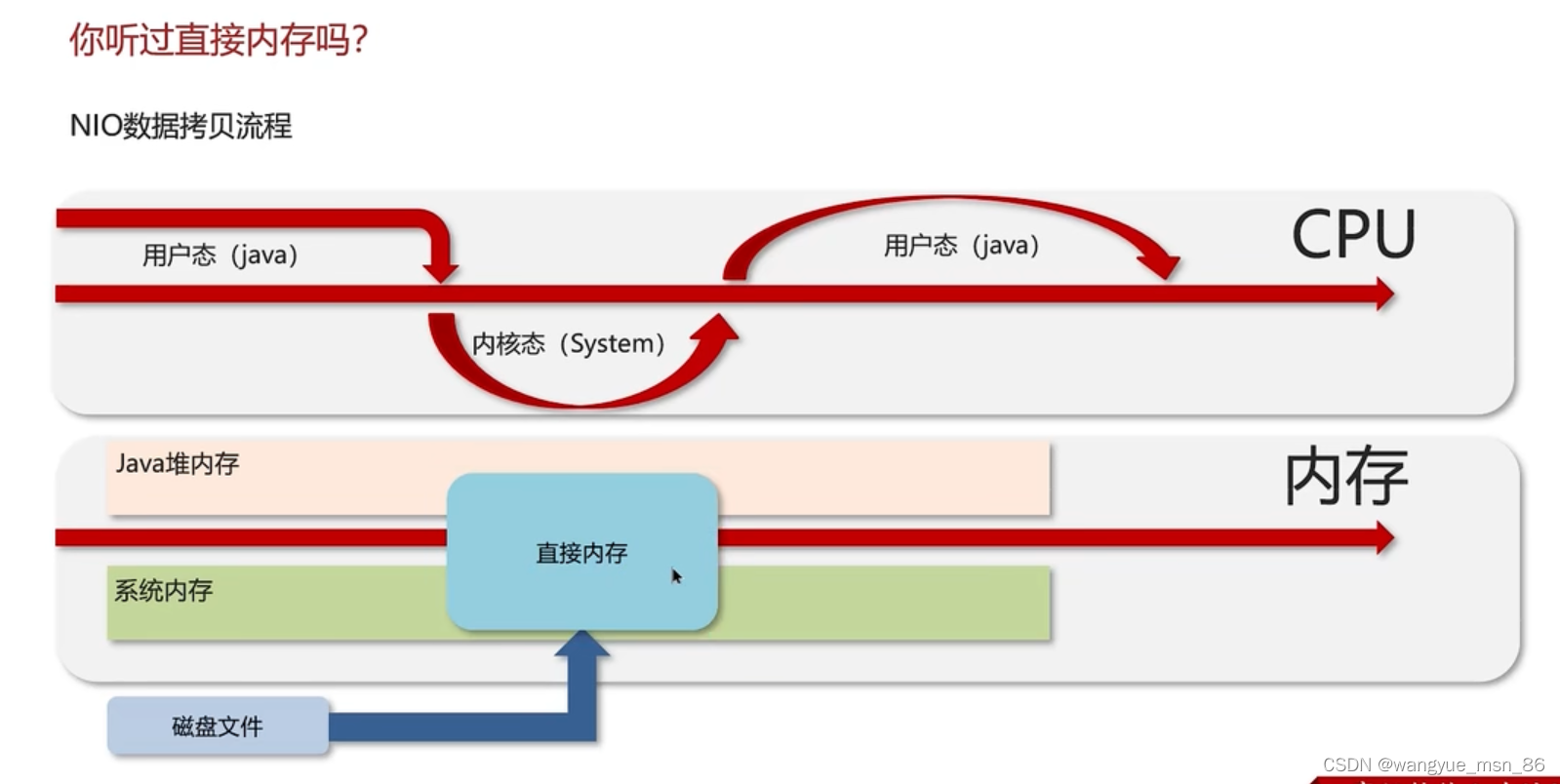
什么是直接内存?
不属于jvm的内存结构,是操作系统分配给虚拟机的内存,操作系统和虚拟机都可以直接读取,常用于NIO,如图,如果系统一个缓冲区,java堆内存一个缓冲区,把数据从一个缓冲区复制到另一个,那么性能较差,就有了系统和java都可以访问的直接内存。
分配回收成本较高,但是读写性能高,不受JVM内存回收影响
垃圾回收
标记方法
有几种标记对象已死的方法?
- 引用计数法
- 可达性分析法
那么在JVM中究竟是如何标记一个死亡对象呢?简单来说,当一个对象已经不再被任何的存活对象继续引用时,就可以宣判为已经死亡。
引用计数法:引用计数算法(Reference Counting)比较简单,对每个对象保存一个整型的引用计数器属性。用于记录对象被引用的情况。
对于一个对象A,只要有任何一个对象引用了A,则A的引用计数器就加1;当引用失效时,引用计数器就减1。只要对象A的引用计数器的值为0,即表示对象A不可能再被使用,可进行回收。
优点:实现简单,垃圾对象便于辨识;判定效率高,回收没有延迟性。
缺点:它需要单独的字段存储计数器,这样的做法增加了存储空间的开销。
如果对象A和对象B相互引用,形成了循环引用。即使没有其他外部引用指向这两个对象,它们的引用计数永远不会达到零,因此无法被垃圾回收。内存就泄漏了
每次赋值都需要更新计数器,伴随着加法和减法操作,这增加了时间开销。
引用计数器有一个严重的问题,即无法处理循环引用的情况。这是一条致命缺陷,导致在Java的垃圾回收器中没有使用这类算法。
可达性分析法:可达性分析算法:也可以称为 根搜索算法、追踪性垃圾收集
相对于引用计数算法而言,可达性分析算法不仅同样具备实现简单和执行高效等特点,更重要的是该算法可以有效地解决在引用计数算法中循环引用的问题,防止内存泄漏的发生。
相较于引用计数算法,这里的可达性分析就是Java、C#选择的。这种类型的垃圾收集通常也叫作追踪性垃圾收集(Tracing Garbage Collection)
所谓"GCRoots”根集合就是一组必须活跃的引用。
基本思路:
- 可达性分析算法是以根对象集合(GCRoots)为起始点,按照从上至下的方式搜索被根对象集合所连接的目标对象是否可达。
- 使用可达性分析算法后,内存中的存活对象都会被根对象集合直接或间接连接着,搜索所走过的路径称为引用链(Reference Chain)
- 如果目标对象没有任何引用链相连,则是不可达的,就意味着该对象己经死亡,可以标记为垃圾对象。
- 在可达性分析算法中,只有能够被根对象集合直接或者间接连接的对象才是存活对象。
总结一句话就是,除了堆空间外的一些结构,比如 虚拟机栈、本地方法栈、方法区、字符串常量池 等地方对堆空间进行引用的,都可以作为GC Roots进行可达性分析,为什么三色标记的时候,第一步是要先标记GCRoots可以直接关联到的对象?
因为GCROOTS是一组引用集合,不是对象集合,先拿到所有关联的对象,然后去堆中去遍历整个对象图。
如果想要并发标记,就采用三色标记,先找到直接关联的对象,再并发的标记整个图,期间用户线程的改动,使用写屏障技术保证正确性,就是不让你写,然后最后再重新标记一下就行了,整个过程,只有并发标记是不需要STW的。

常用的垃圾回收算法
1.标记清除算法
当堆中的有效内存空间(available memory)被耗尽的时候,就会停止整个程序(也被称为stop the world),然后进行两项工作,第一项则是标记,第二项则是清除
- 标记:Collector从引用根节点开始遍历,标记所有被引用的对象。一般是在对象的Header中记录为可达对象。
- 标记的是引用的对象,不是垃圾!!
- 清除:Collector对堆内存从头到尾进行线性的遍历,如果发现某个对象在其Header中没有标记为可达对象,则将其回收(这里所谓的清除并不是真的置空,而是把需要清除的对象地址保存在空闲的地址列表里)
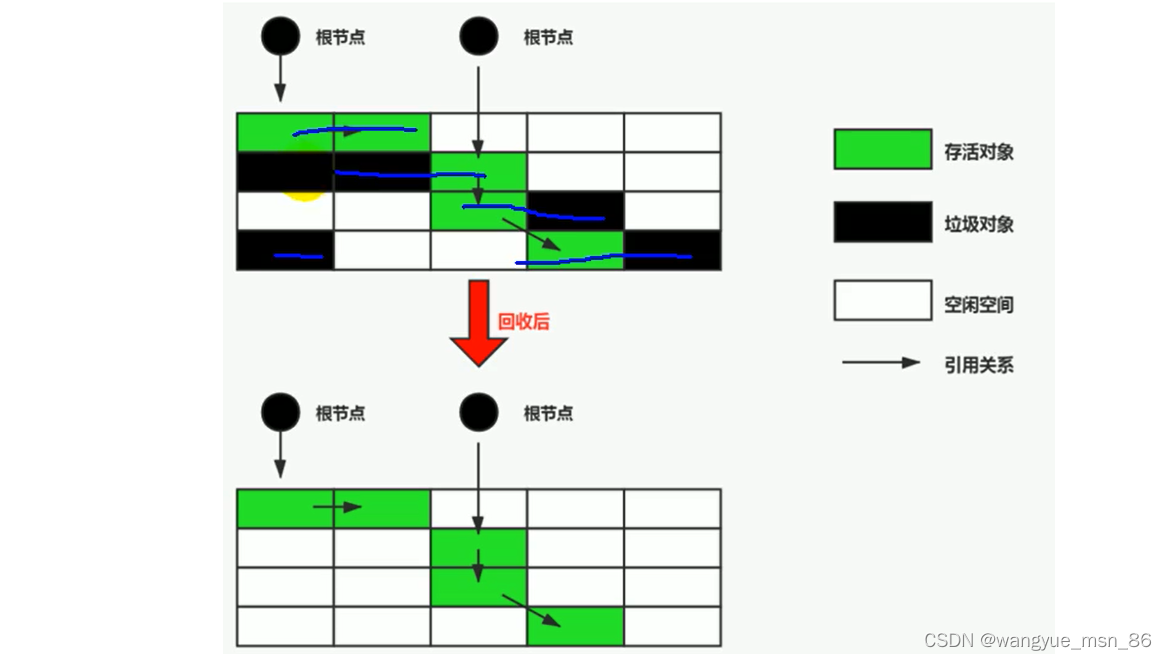
缺点:
- 标记清除算法的效率不算高
- 在进行GC的时候,需要停止整个应用程序,用户体验较差
- 这种方式清理出来的空闲内存是不连续的,产生内碎片,需要维护一个空闲列表
2.标记复制算法(主要用于回收新生代)
将活着的内存空间分为两块,每次只使用其中一块,在垃圾回收时将正在使用的内存中的存活对象复制到未被使用的内存块中,之后清除正在使用的内存块中的所有对象,交换两个内存的角色,最后完成垃圾回收
标记清除算法中分为标记和清除两个阶段,但是标记复制算法并没有标记阶段,为什么呢?
首先要明确判断对象是否存活的核心思想是用根可达算法找出存活对象,由于标记清除算法需要回收垃圾对象,所以需要对存活对象进行标记,然后清除不可用对象。
而复制算法是要复制存活对象到另一块区域,所以在根可达算法发现存活对象后是直接复制到另一块区域,即在根可达分析过程中就已经完成了筛选(复制),待复制完成后,直接清理掉另一块区域即可,所以没有标记的必要。我感觉也没啥提升,标记一下也费不了多少事儿(不还是得可达性分析遍历一遍gcroots吗)。
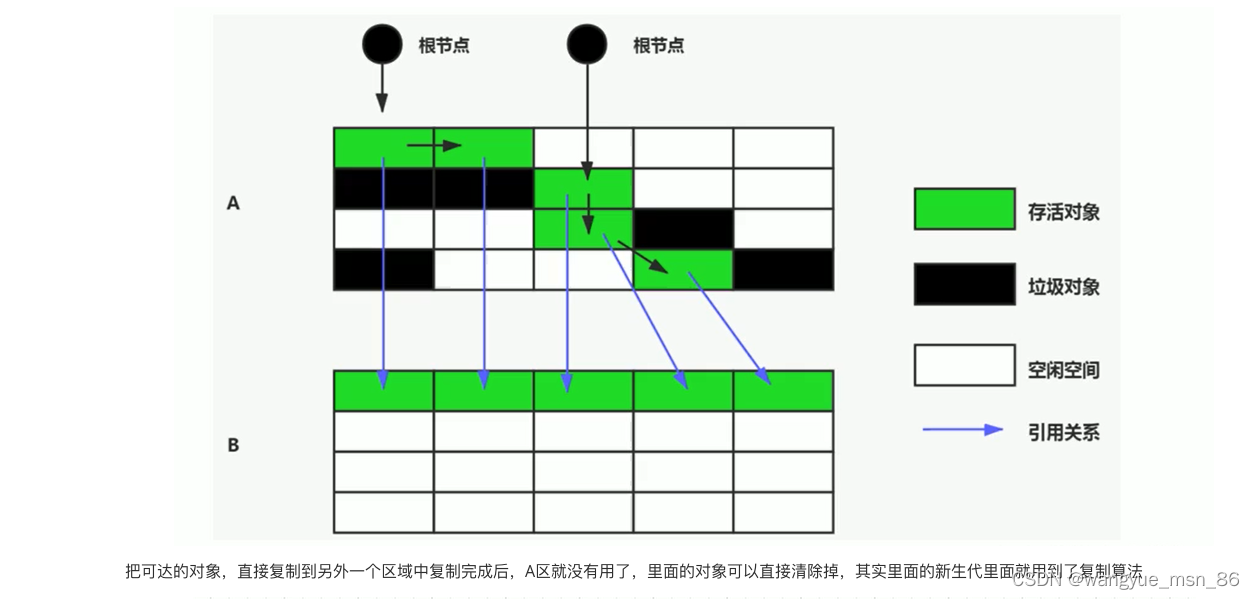
- 没有标记和清除过程,实现简单,运行高效
- 复制过去以后保证空间的连续性,不会出现“碎片”问题。
缺点:
- 此算法的缺点也是很明显的,就是需要两倍的内存空间。
- 对于G1这种分拆成为大量region的GC,复制而不是移动,意味着GC需要维护region之间对象引用关系,不管是内存占用或者时间开销也不小
优化:现在虚拟机新生代默认采用 Eden+survivor1+survivor2 8:1:1 分配,浪费的空间比较少。如果系统中的垃圾对象很多,复制算法需要复制的存活对象数量并不会太大,或者说非常低才行(老年代大量的对象存活,那么复制的对象将会有很多,效率会很低)在新生代,对常规应用的垃圾回收,一次通常可以回收70% - 99% 的内存空间。回收性价比很高。所以现在的商业虚拟机都是用这种收集算法回收新生代。
如图:只使用Eden区和一块from区,回收的时候就把这两块存活的复制到To区,然后from和to的地位互换。如果To区没有足够的空间来存放存活的对象,需要老年区等区域对其进行分配担保
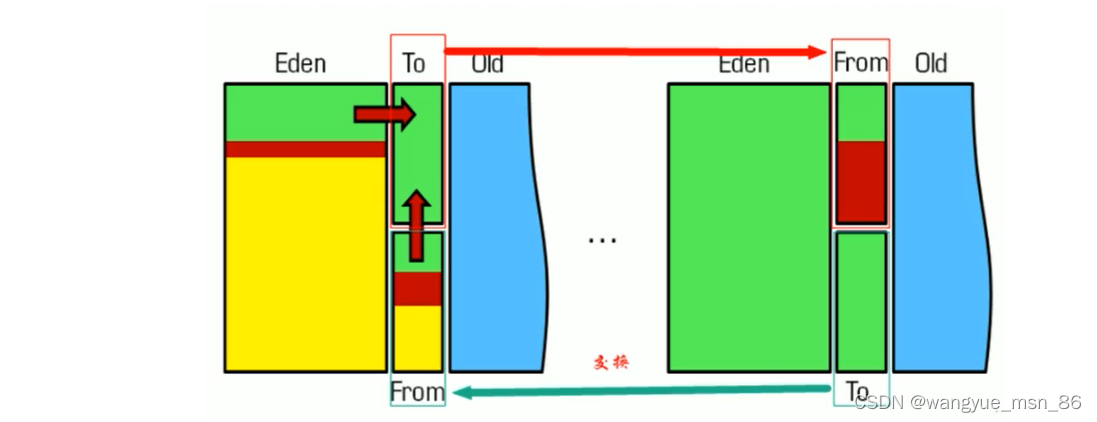
3.标记整理(主要用于老年代)
复制算法的高效性是建立在存活对象少、垃圾对象多的前提下的。这种情况在新生代经常发生,但是在老年代,更常见的情况是大部分对象都是存活对象。如果依然使用复制算法,由于存活对象较多,复制的成本也将很高。因此,基于老年代垃圾回收的特性,需要使用其他的算法。
标记一清除算法的确可以应用在老年代中,但是该算法不仅执行效率低下,而且在执行完内存回收后还会产生内存碎片,所以JvM的设计者需要在此基础之上进行改进。标记-压缩(Mark-Compact)算法由此诞生。
第一阶段和标记清除算法一样,从根节点开始标记所有被引用对象
第二阶段将所有的存活对象压缩到内存的一端,按顺序排放。之后,清理边界外所有的空间。
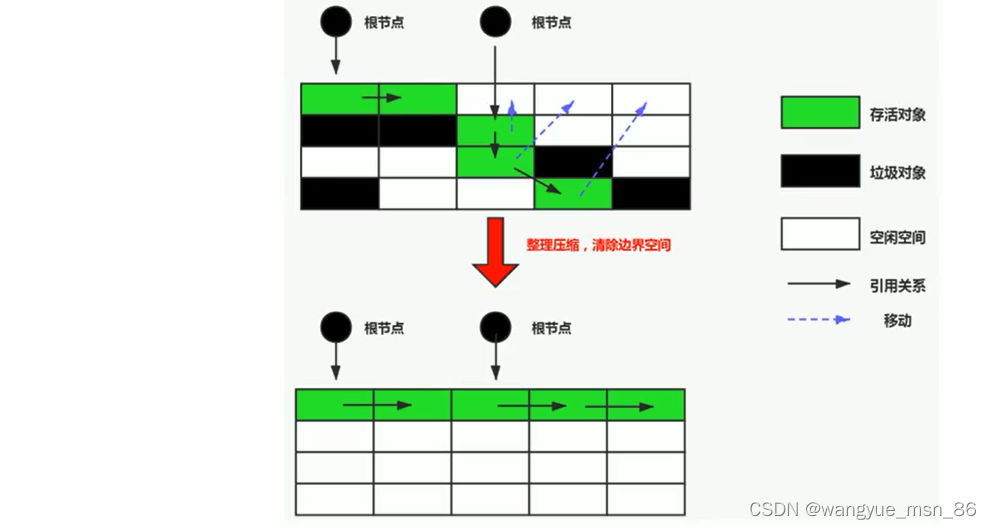
标记-压缩算法的最终效果等同于标记-清除算法执行完成后,再进行一次内存碎片整理,因此,也可以把它称为标记-清除-压缩(Mark-Sweep-Compact)算法。
二者的本质差异在于标记-清除算法是一种非移动式的回收算法,标记-压缩是移动式的。是否移动回收后的存活对象是一项优缺点并存的风险决策。可以看到,标记的存活对象将会被整理,按照内存地址依次排列,而未被标记的内存会被清理掉。如此一来,当我们需要给新对象分配内存时,JVM只需要持有一个内存的起始地址即可,这比维护一个空闲列表显然少了许多开销。
优点
- 消除了标记-清除算法当中,内存区域分散的缺点,我们需要给新对象分配内存时,JVM只需要持有一个内存的起始地址即可。
- 消除了复制算法当中,内存减半的高额代价。
缺点
- 从效率上来说,标记-整理算法要低于复制算法。
- 移动对象的同时,如果对象被其他对象引用,则还需要调整引用的地址
- 移动过程中,需要全程暂停用户应用程序。即:STW
总结:
效率上来说,复制算法是当之无愧的老大,但是却浪费了太多内存。
而为了尽量兼顾上面提到的三个指标,标记-整理算法相对来说更平滑一些,但是效率上不尽如人意,它比复制算法多了一个标记的阶段,比标记-清除多了一个整理内存的阶段。
| 标记清除 | 标记整理 | 复制 | |
|---|---|---|---|
| 速率 | 中等 | 最慢 | 最快 |
| 空间开销 | 少(但会堆积碎片) | 少(不堆积碎片) | 通常需要活对象的2倍空间(不堆积碎片) |
| 移动对象 | 否 | 是 | 是 |
综合我们可以找到,没有最好的算法,只有最合适的算法
所以现代虚拟机都是采用的分代收集方式,对新生代使用复制算法(Eden+Survivor),对老年代使用标清加标整混合方式。
常见的垃圾回收器?
STW:stop the world 垃圾回收的时候,暂停整个应用程序
垃圾回收关注两个指标:

高吞吐量较好因为这会让应用程序的最终用户感觉只有应用程序线程在做“生产性”工作。直觉上,吞吐量越高程序运行越快。
低暂停时间(低延迟)较好因为从最终用户的角度来看不管是GC还是其他原因导致一个应用被挂起始终是不好的。这取决于应用程序的类型,有时候甚至短暂的200毫秒暂停都可能打断终端用户体验。因此,具有低的较大暂停时间是非常重要的,特别是对于一个交互式应用程序。
不幸的是”高吞吐量”和”低暂停时间”是一对相互竞争的目标(矛盾)。
因为如果选择以吞吐量优先,那么必然需要降低内存回收的执行频率,但是这样会导致GC需要更长的暂停时间来执行内存回收。
相反的,如果选择以低延迟优先为原则,那么为了降低每次执行内存回收时的暂停时间,也只能频繁地执行内存回收,但这又引起了年轻代内存的缩减和导致程序吞吐量的下降。
在设计(或使用)GC算法时,我们必须确定我们的目标:一个GC算法只可能针对两个目标之一(即只专注于较大吞吐量或最小暂停时间),或尝试找到一个二者的折衷。
现在标准:在最大吞吐量优先的情况下,降低停顿时间
有了虚拟机,就一定需要收集垃圾的机制,这就是Garbage Collection,对应的产品我们称为Garbage Collector。
- 1999年随JDK1.3.1一起来的是串行方式的serialGc,它是第一款GC。ParNew垃圾收集器是Serial收集器的多线程版本
- 2002年2月26日,Parallel GC和Concurrent Mark Sweep GC跟随JDK1.4.2一起发布·
- Parallel GC在JDK6之后成为HotSpot默认GC。
- 2012年,在JDK1.7u4版本中,G1可用。
- 2017年,JDK9中G1变成默认的垃圾收集器,以替代CMS。
- 2018年3月,JDK10中G1垃圾回收器的并行完整垃圾回收,实现并行性来改善最坏情况下的延迟。
- 2018年9月,JDK11发布。引入Epsilon 垃圾回收器,又被称为 "No-Op(无操作)“ 回收器。同时,引入ZGC:可伸缩的低延迟垃圾回收器(Experimental)
- 2019年3月,JDK12发布。增强G1,自动返回未用堆内存给操作系统。同时,引入Shenandoah GC:低停顿时间的GC(Experimental)。·2019年9月,JDK13发布。增强zGC,自动返回未用堆内存给操作系统。
- 2020年3月,JDK14发布。删除cMs垃圾回收器。扩展zGC在macos和Windows上的应用
重点:serialGC(最开始的)、ParallelGC(Java8默认的)、CMS和G1
- 串行回收器:Serial、Serial old
- 并行回收器:ParNew、Parallel Scavenge、Parallel old
- 并发回收器:CMS、G1
Serial了解:jdk1.3之前只有这个
Serial收集器采用复制算法、串行回收和"stop-the-World"机制的方式执行内存回收。
新生代用Serial GC,且老年代用Serial old GC,新生代复制算法,老年代 标记整理算法,有STW,串行执行
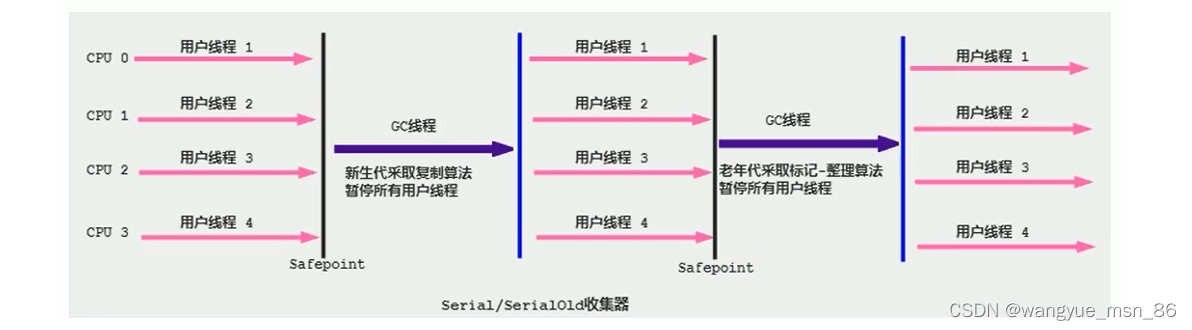
Parallel: jdk8默认 吞吐量优先
ParallelScavenge收集器的目标则是达到一个可控制的吞吐量(Throughput),它也被称为吞吐量优先的垃圾收集器
新生代用Parallel GC(ParallelScavenge),且老年代用Parallel old GC。也是新生代复制算法,老年代 标记整理算法。GC的时候也得Stop the world,并行GC
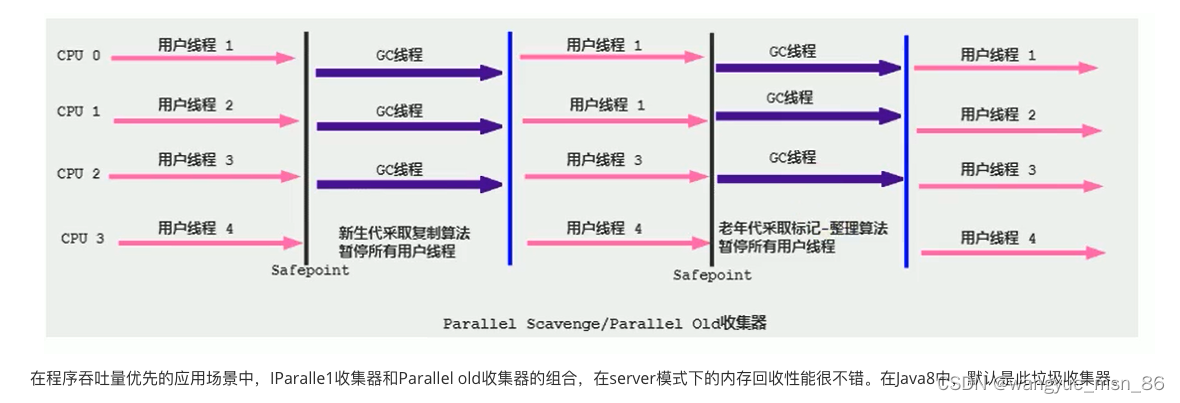
CMS:低延迟收集器
在JDK1.5时期,Hotspot推出了一款在强交互应用中几乎可认为有划时代意义的垃圾收集器:cMS(Concurrent-Mark-Sweep)收集器,这款收集器是HotSpot虚拟机中第一款真正意义上的并发收集器,它第一次实现了让垃圾收集线程与用户线程同时工作。
CMS收集器的关注点是尽可能缩短垃圾收集时用户线程的停顿时间。停顿时间越短(低延迟)就越适合与用户交互的程序,良好的响应速度能提升用户体验。
目前很大一部分的Java应用集中在互联网站或者B/S系统的服务端上,这类应用尤其重视服务的响应速度,希望系统停顿时间最短,以给用户带来较好的体验。CMS收集器就非常符合这类应用的需求。
用于回收老年代,现在高版本jdk停用cms了
收集垃圾的时候可以和用户线程并行了,不需要stop the world
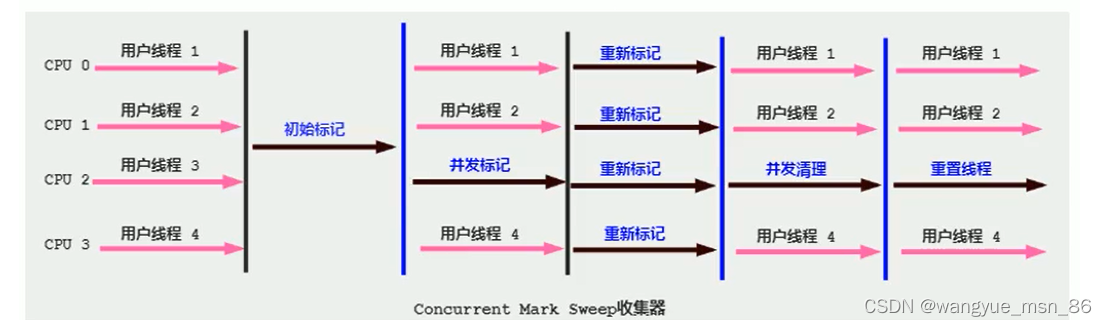
CMS整个过程比之前的收集器要复杂,整个过程分为4个主要阶段,即初始标记阶段、并发标记阶段、重新标记阶段和并发清除阶段。(涉及STW的阶段主要是:初始标记 和 重新标记)
- 初始标记(Initial-Mark)阶段:在这个阶段中,程序中所有的工作线程都将会因为“stop-the-world”机制而出现短暂的暂停,这个阶段的主要任务仅仅只是标记出GCRoots能直接关联到的对象。一旦标记完成之后就会恢复之前被暂停的所有应用线程。由于直接关联对象比较小,所以这里的速度非常快。
- 并发标记(Concurrent-Mark)阶段:从Gc Roots的直接关联对象开始遍历整个对象图的过程,这个过程耗时较长但是不需要停顿用户线程,可以与垃圾收集线程一起并发运行。
- 重新标记(Remark)阶段:由于在并发标记阶段中,程序的工作线程会和垃圾收集线程同时运行或者交叉运行,因此为了修正并发标记期间,因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间通常会比初始标记阶段稍长一些,但也远比并发标记阶段的时间短。
- 并发清除(Concurrent-Sweep)阶段:此阶段清理删除掉标记阶段判断的已经死亡的对象,释放内存空间。由于不需要移动存活对象,所以这个阶段也是可以与用户线程同时并发的
尽管CMS收集器采用的是并发回收(非独占式),但是在其初始化标记和再次标记这两个阶段中仍然需要执行“Stop-the-World”机制暂停程序中的工作线程,不过暂停时间并不会太长,因此可以说明目前所有的垃圾收集器都做不到完全不需要“stop-the-World”,只是尽可能地缩短暂停时间。
采用的是标记清除算法,为什么不用标记整理呢,因为并发没发用标记整理,不能干扰用户线程啊。
G1回收器
与其他GC收集器相比,G1使用了全新的分区算法
并行与并发
- 并行性:G1在回收期间,可以有多个GC线程同时工作,有效利用多核计算能力。此时用户线程STW
- 并发性:G1拥有与应用程序交替执行的能力,部分工作可以和应用程序同时执行,因此,一般来说,不会在整个回收阶段发生完全阻塞应用程序的情况
分代收集
- 从分代上看,G1依然属于分代型垃圾回收器,它会区分年轻代和老年代,年轻代依然有Eden区和Survivor区。但从堆的结构上看,它不要求整个Eden区、年轻代或者老年代都是连续的,也不再坚持固定大小和固定数量。
- 将堆空间分为若干个区域(Region),这些区域中包含了逻辑上的年轻代和老年代。
- 和之前的各类回收器不同,它同时兼顾年轻代和老年代。对比其他回收器,或者工作在年轻代,或者工作在老年代;
G1所谓的分代,已经不是下面这样的了
空间整合
- CMS:“标记-清除”算法、内存碎片、若干次Gc后进行一次碎片整理
- G1将内存划分为一个个的region。内存的回收是以region作为基本单位的。Region之间是复制算法,但整体上实际可看作是标记-压缩(Mark-Compact)算法,两种算法都可以避免内存碎片。这种特性有利于程序长时间运行,分配大对象时不会因为无法找到连续内存空间而提前触发下一次GC。尤其是当Java堆非常大的时候,G1的优势更加明显。
如何选择合适的垃圾回收器?
Java垃圾收集器的配置对于JVM优化来说是一个很重要的选择,选择合适的垃圾收集器可以让JVM的性能有一个很大的提升。怎么选择垃圾收集器?
- 优先调整堆的大小让JVM自适应完成。
- 如果内存小于100M,使用串行收集器
- 如果是单核、单机程序,并且没有停顿时间的要求,串行收集器
- 如果是多CPU、需要高吞吐量、允许停顿时间超过1秒,选择并行或者JVM自己选择
- 如果是多CPU、追求低停顿时间,需快速响应(比如延迟不能超过1秒,如互联网应用),使用并发收集器
- 官方推荐G1,性能高。现在互联网的项目,基本都是使用G1。
最后需要明确一个观点:
- 没有最好的收集器,更没有万能的收集
- 调优永远是针对特定场景、特定需求,不存在一劳永逸的收集器
三色标级多标漏标问题
浮动垃圾(多标)
1.并发标记:用户与GC线程同时运行,假设现在扫描到C对象,B对象变为黑色,用户线程执行C的属性E=null,GC线程扫描C对象引用链,认为E对象是为可达对象,但是C对象根本没有引入到E对象,E对象应该是为垃圾对象,这种问题,可以在重新标记阶段(修正)修复。
2.并发清除阶段:用户与GC线程同时运行,会产生新的对象但是没有及时被GC清理。 只能在下一次GC清理垃圾的修复。
漏标问题
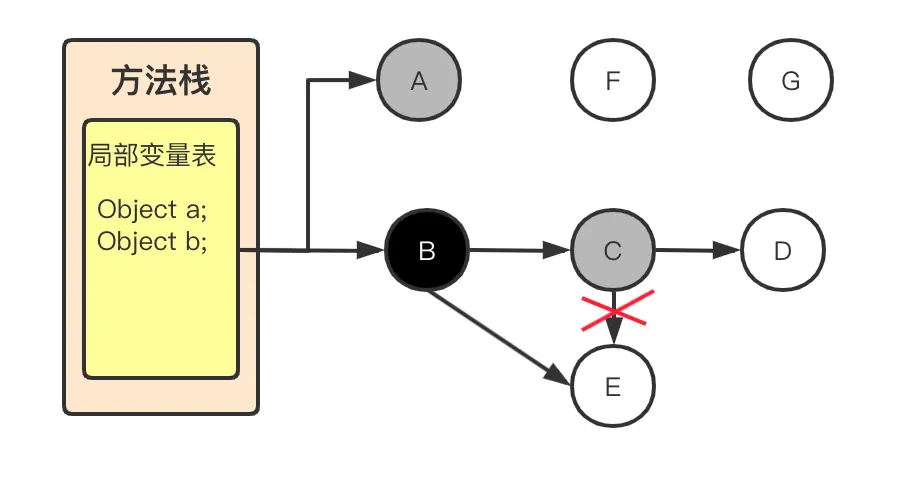
1.用户线程先执行C的E属性=null;GC线程的GcRoot就扫描不到E。Gc就认为E对象就是为垃圾对象,不可达对象。
2.用户线有执行B.E属性=E;E对象就是应该是为可达对象。
3.因为GCRoot是从C开始,不会从黑色的B开始,就会导致漏标的情况发生。
漏标的问题满足两个条件:
1.至少有一个黑色对象指向了白色对象
2.所有灰色对象扫描完整个链时,删除之前所有白色对象。
1.CMS如何解决漏标问题—写屏障+增量更新方式
满足一个条件(灰色对象与白色对象断开连接),在并发标记阶段当我们黑色对象(B)引用关联白色对象(E),记录下B黑色对象。
在重新标记阶段(所有用户线程暂停),有将B对象变为灰色对象将整个引用链全部扫描。
缺点:遍历B整个链的效率非常低,有可能会导致用户线程等待的时间非常长。
2.G1如何解决漏标问题—原始快照方式
在C断开E的时候,会记录原始快照,在重新标记阶段的时候以白色对象变为灰色为起始点扫描整个链,本次GC是不会被清理。
**好处:**如果假设B(黑色对象)引入该白色对象的时候,无需做任何遍历效率是非常高。
**缺点:**如果假设B(黑色对象) 没有引入该白色对象的时候,该白色对象在本次GC继续存活,只能放在下一次GC在做并发标记的时候清理。
tips:以浮动垃圾(占内存空间)换让我们用户线程能够暂停的时间更加短。
总结:
CMS收集器解决漏标问题:增量方式 如果现在B(黑色)对象引入白色对象,写屏障。
好处:避免浮动垃圾,缺点扫描整个引用链效率比较低。
G1收集器解决漏标问题:原始快照方式。
好处:效率非常高,无需扫描整个引用链,缺点:可能会产生浮动垃圾。
G1 垃圾回收器(重点)
G1垃圾回收的过程
G1GC的垃圾回收过程主要包括如下三个环节:
- 年轻代GC(Young GC)
- 老年代并发标记过程(Concurrent Marking)
- 混合回收(Mixed GC)
(如果需要,单线程、独占式、高强度的FullGC还是继续存在的。它针对GC的评估失败提供了一种失败保护机制,即强力回收。)
为了实现低延迟,G1使用了比CMS等回收器多10%到20的空间给每一个Region弄了一个记忆集(remember set),用来存放跨代引用,这样标记过程就不会遍历整个对象图了,用空间换时间,别的垃圾回收器都要遍历整个对象图来解决跨代引用的问题。实现方式就是每次引用类型写的时候,都会有个读屏障暂时中断这个操作,然后如果对象和引用对象不在一个Region时 比如A.B = new B(); A和B不在一个Region,那么就会记录到一个队列中,叫dirty card queue,然后回收的时候去队列里拿脏页,就是需要记录到Set中的cartTable,记录进去,cartTable就是RSEt里红色的小格。为什么不直接记录到RSET中呢,如下所示,因为很大概率是多线程执行的,这个队列相当于一个消息队列了,异步的作用,性能会更好。

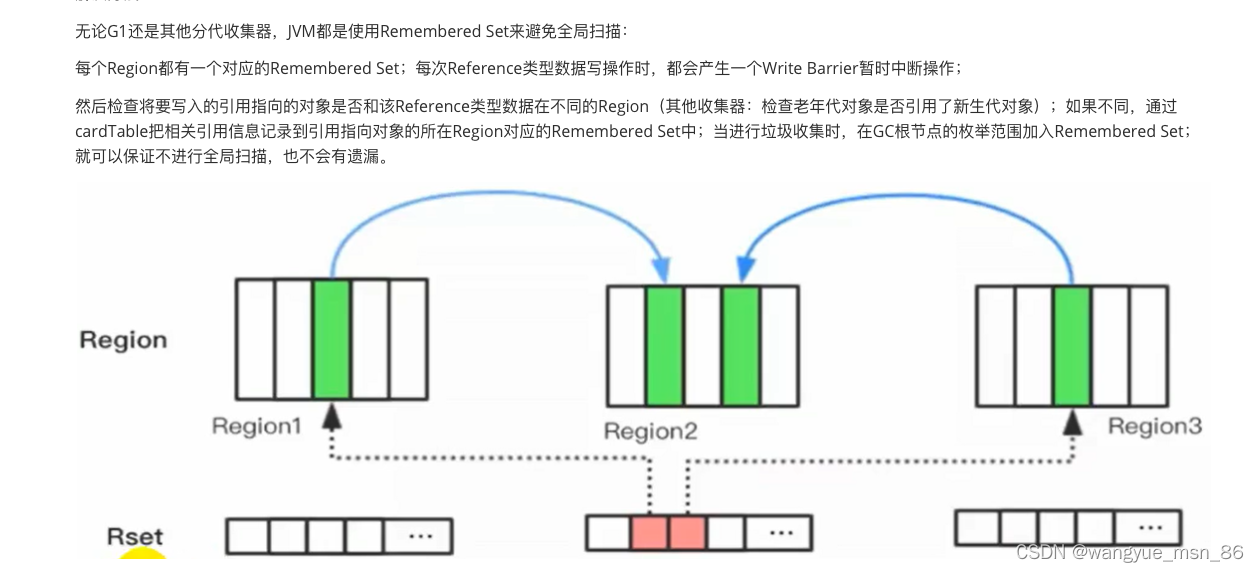
G1年轻代回收:
G1回收过程-年轻代GC
JVM启动时,G1先准备好Eden区,程序在运行过程中不断创建对象到Eden区,当Eden空间耗尽时,G1会启动一次年轻代垃圾回收过程。
YGC时,首先G1停止应用程序的执行(stop-The-Wor1d),G1创建回收集(Collection Set),回收集是指需要被回收的内存分段的集合,年轻代回收过程的回收集包含年轻代Eden区和Survivor区所有的内存分段。因为需要复制算法,和从队列里拿cartTable,不得不stop the world

然后开始如下回收过程:
- 第一阶段,扫描根
根是指static变量指向的对象,正在执行的方法调用链条上的局部变量等。根引用连同RSet记录的外部引用作为扫描存活对象的入口。
- 第二阶段,更新RSet
处理dirty card queue(见备注)中的card,更新RSet。此阶段完成后,RSet可以准确的反映老年代对所在的内存分段中对象的引用。
- 第三阶段,处理RSet
识别被老年代对象指向的Eden中的对象,这些被指向的Eden中的对象被认为是存活的对象。
- 第四阶段,复制对象。
此阶段,对象树被遍历,Eden区内存段中存活的对象会被复制到Survivor区中空的内存分段,Survivor区内存段中存活的对象如果年龄未达阈值,年龄会加1,达到阀值会被会被复制到o1d区中空的内存分段。如果Survivor空间不够,Eden空间的部分数据会直接晋升到老年代空间。
- 第五阶段,处理引用
处理Soft,Weak,Phantom,Final,JNI Weak 等引用。最终Eden空间的数据为空,GC停止工作,而目标内存中的对象都是连续存储的,没有碎片,所以复制过程可以达到内存整理的效果,减少碎片。
JVM中一次完整的GC流程是怎样的,对象如何晋升到老年代?(G1之前的)
思路: 先描述一下Java堆内存划分,再解释Minor GC,Major GC,full GC,描述它们之间转化流程。
我的答案:
Java堆 = 老年代 + 新生代
新生代 = Eden + S0 + S1
当 Eden 区的空间满了, Java虚拟机会触发一次 Minor GC,以收集新生代的垃圾,存活下来的对象,则会转移到 Survivor区。
大对象(需要大量连续内存空间的Java对象,如那种很长的字符串)直接进入老年态;
如果对象在Eden出生,并经过第一次Minor GC后仍然存活,并且被Survivor容纳的话,年龄设为1,每熬过一次Minor GC,年龄+1,若年龄超过一定限制(15),则被晋升到老年态。即长期存活的对象进入老年态。
老年代满了而无法容纳更多的对象,Minor GC 之后通常就会进行Full GC,Full GC 清理整个内存堆 – 包括年轻代和年老代。
Major GC 发生在老年代的GC,清理老年区,经常会伴随至少一次Minor GC,比Minor GC慢10倍以上。
只有CMS有Major GC,一般都是eden满了进行minorGC,老年代满了进行full GC
类加载
JUC
简单的基础问题请看收藏的网站和面试八股文。
CAS
前面看到的 AtomicInteger 的解决方法,内部并没有用锁来保护共享变量的线程安全。那么它是如何实现的呢?
private AtomicInteger balance; //原子整数
public AccountSafe(Integer balance) {
this.balance = new AtomicInteger(balance);
}
@Override
public Integer getBalance() {
return balance.get();
}
public void withdraw(Integer amount) {
while(true) {
// 需要不断尝试,直到成功为止
while (true) {
// 比如拿到了旧值 1000
int prev = balance.get();
// 在这个基础上 1000-10 = 990
int next = prev - amount;
/*
compareAndSet 正是做这个检查,在 set 前,先比较 prev 与当前值
- 不一致了,next 作废,返回 false 表示失败
比如,别的线程已经做了减法,当前值已经被减成了 990
那么本线程的这次 990 就作废了,进入 while 下次循环重试
- 一致,以 next 设置为新值,返回 true 表示成功
*/
if (balance.compareAndSet(prev, next)) {
break;
}
}
}
}
其中的关键是 compareAndSet,它的简称就是 CAS (也有 Compare And Swap 的说法),它必须是原子操作。
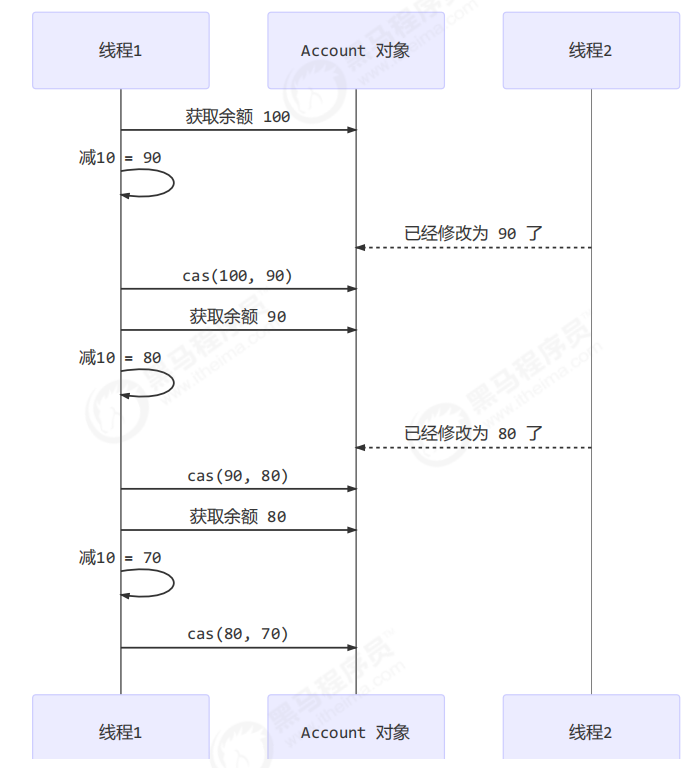
CAS的原子整数是Volitale修饰的,保证了多个线程的可见性
Cas的ABA问题,既然是旧值和最新值比较,那么如果B在A执行前把i加1又减1,就是ABA,又把B改为了A,是不是A线程感知不到呢,但是这种改变又可能是有影响的。可以使用带版本号原子类型,或者原子引用型
Cas底层是通过unsafe方法实现的,就是c++写的可以直接操作操作系统和内存的方法,不可以获取,个人慎用
AQS
抽象队列同步器框架Reentanlock、读写锁,信号量都是AQS实现的
AQS是怎么实现阻塞的呢,是通过LockSupport的park和unpark实现的,是c++的Unsafe类实现的

AQS也用到了模版方法模式:
模版方法模指的就是写一个模版,有的方法是所有人都一样的,可以设计成final的,有的是各不相同的,可以设计成抽象的,由子类实现
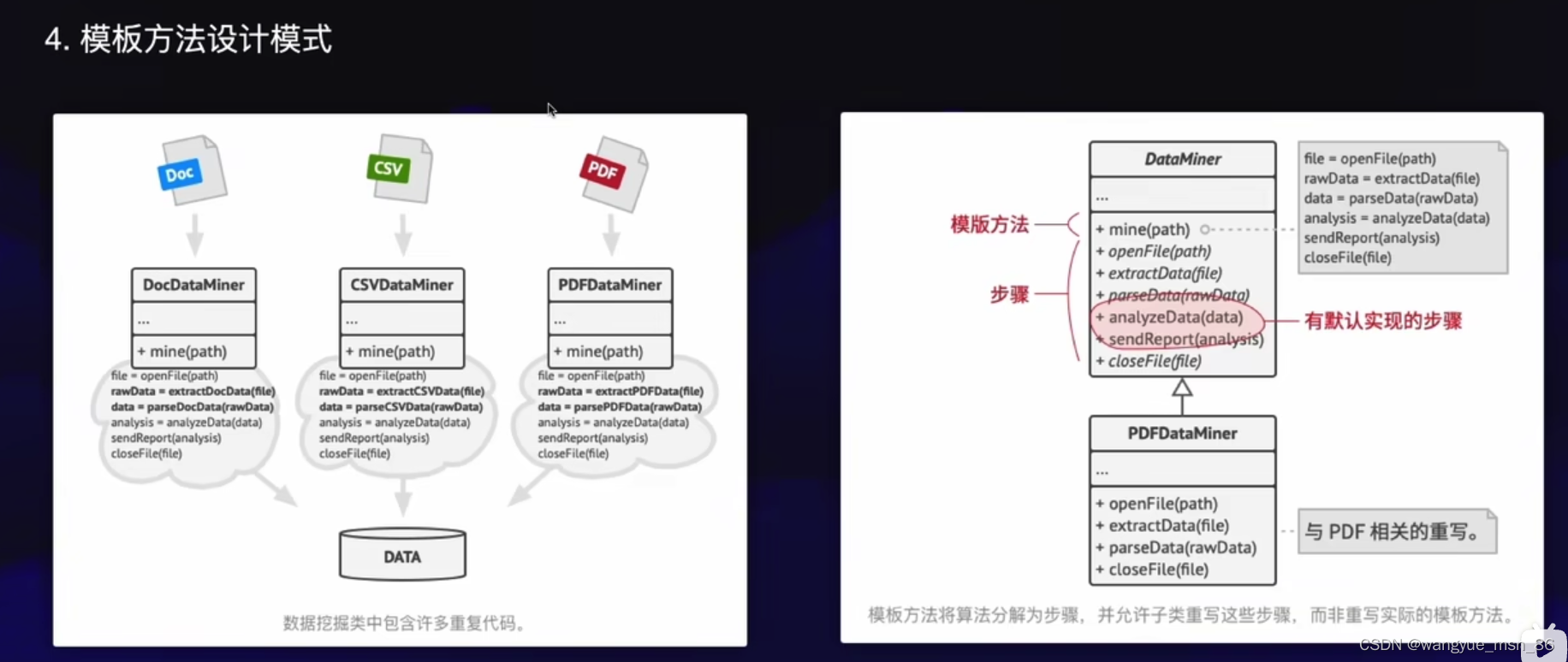
可以看到ReentantLock是通过Sync实现的,Sync继承了AQS框架
lock和unlock这种方法,也不是直接用Sync,而是unfairSync(默认就是这个),和fairSync两种实现
AQS的重要组成部分:
1.volatile类型的变量state,0表示没有被占有,1表示占有了,大于1表示被重入了。volatile保证可见性
2.Node节点,有前驱后继 形成一个队列结构,存放没有获得锁的线程
3.指向当前线程的
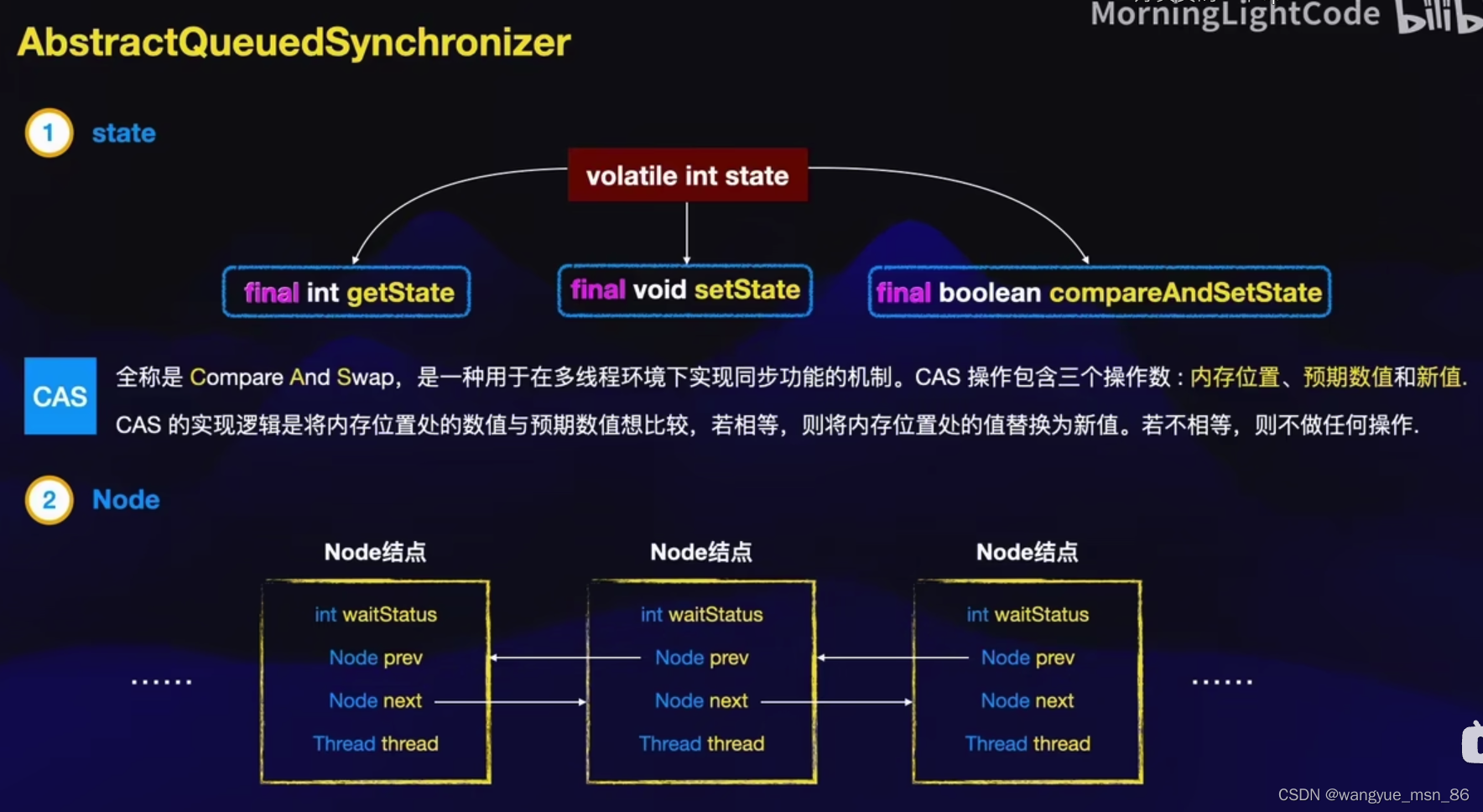
Reentlock 大概就是这样,默认就是非公平的Sync,里面有state, head和tail维护一个对流,exclusiveOwnerThread是指向当前执行的线程,是完全排他的模式
简单示例:
线程0通过cas先把state改为1了,别的线程预期都是0,所有都去队列阻塞等待,等0执行完,执行完了,线程1就不阻塞了,可以进行cas尝试设置state为1,然后把队列前第一个元素出队
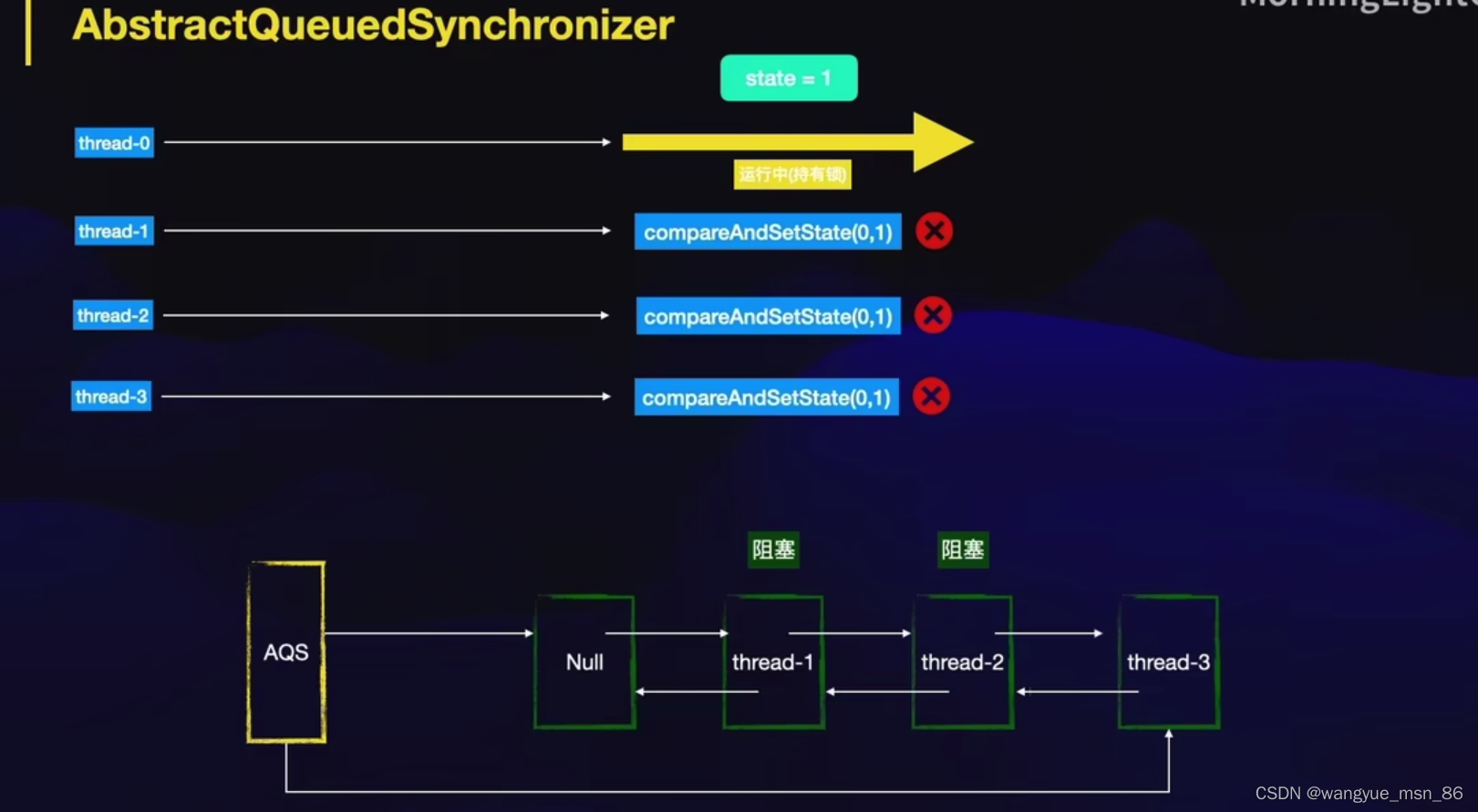
上面的Node结点,不是有个waitStatus吗,有几种值呢
-
为0的时候,这个成员变量刚初始化
-
为1 cancelled的时候,当前等待的这个线程,可能因为中断或者其他原因取消了
-
为-1的时候,当前线程的任务就是唤醒下一个线程
-
-2的condition时用于条件队列
-
-3的porpagate用于共享锁
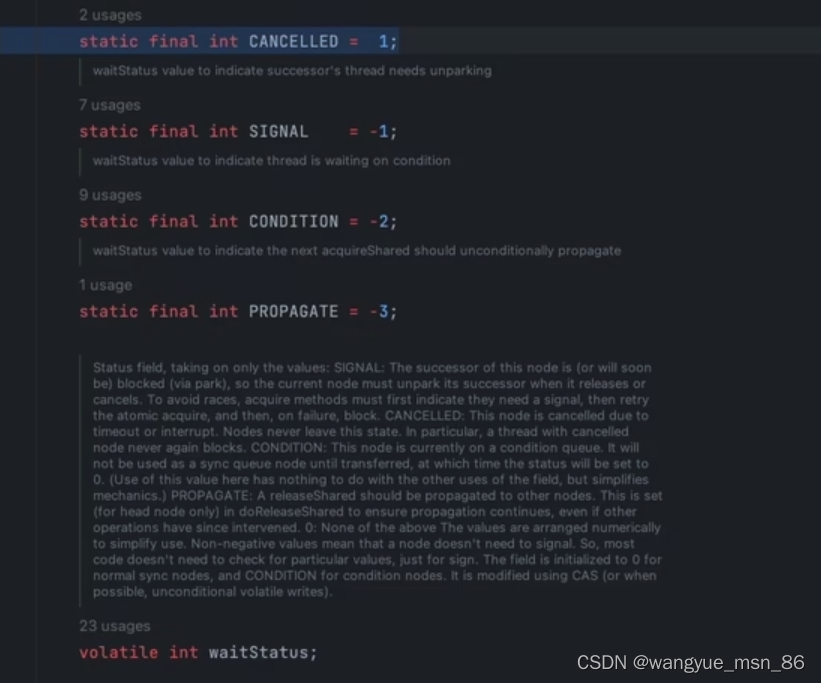
ReentranLock上锁的流程:lock方法
可以看到有多次机会可以获得锁,如果一开始把NofairSync的state通过cas设置为1的话,那么就能执行了,如果cas失败
那么会再尝试一次 tryAcquire,如果还失败,就加入队列中,观察addWaiter方法可知,是加入到队列的后面,可见同步队列是一个先进先出的队列。
加入到队列后,如果前驱结点是头结点的话,又一次说明了是先进先出的,前面的都执行完了他才能出队,然后再尝试获取,再失败就阻塞了,使用park的方式阻塞,等待unpark,前面的执行完了去唤醒他,或者被中断等等。被唤醒后,有机会重新竞争,注意不是立即拿到,而是重新竞争
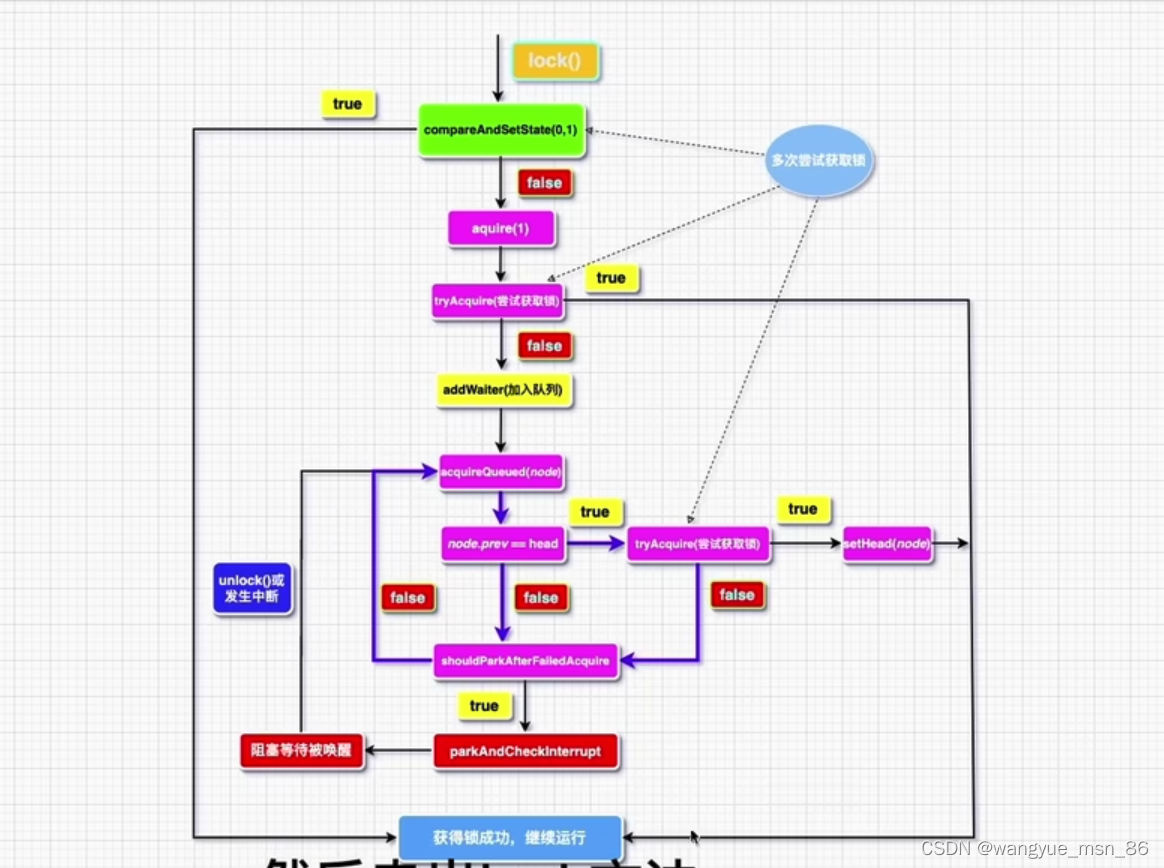
释放锁,如果state没有被减为0,也算解锁失败,因为重入了,只少了一次锁还是没成功,减到0了可以唤醒别的线程了。
JUC常见工具类(基于AQS实现的)
- countDownlatch
用来进行线程同步协作,等待所有线程完成倒计时。
其中构造参数用来初始化等待计数值,await() 用来等待计数归零,countDown() 用来让计数减一
个人理解是这样,主线程new 一个初始值为3的CountDownLatch,属于是预先被park了三次,需要三个unpark,在三个线程里面都运行了countDown以后才行。
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(3);
new Thread(() -> {
log.debug("begin...");
sleep(1);
latch.countDown();
log.debug("end...{}", latch.getCount());
}).start();
new Thread(() -> {
log.debug("begin...");
sleep(2);
latch.countDown();
log.debug("end...{}", latch.getCount());
}).start();
new Thread(() -> {
log.debug("begin...");
sleep(1.5);
latch.countDown();
log.debug("end...{}", latch.getCount());
}).start();
log.debug("waiting...");
latch.await();
log.debug("wait end...");
}
输出
18:44:00.778 c.TestCountDownLatch [main] - waiting...
18:44:00.778 c.TestCountDownLatch [Thread-2] - begin...
18:44:00.778 c.TestCountDownLatch [Thread-0] - begin...
18:44:00.778 c.TestCountDownLatch [Thread-1] - begin...
18:44:01.782 c.TestCountDownLatch [Thread-0] - end...2
18:44:02.283 c.TestCountDownLatch [Thread-2] - end...1
18:44:02.782 c.TestCountDownLatch [Thread-1] - end...0
18:44:02.782 c.TestCountDownLatch [main] - wait end...
2.读写锁 ReentrantReadWriteLock
当读操作远远高于写操作时,这时候使用 读写锁 让 读-读 可以并发,提高性能。
类似于数据库中的 select ... from ... lock in share mode,这里的原理就不探究了,AQS实现共享模式的方式
class DataContainer {
private Object data;
private ReentrantReadWriteLock rw = new ReentrantReadWriteLock();
private ReentrantReadWriteLock.ReadLock r = rw.readLock();
private ReentrantReadWriteLock.WriteLock w = rw.writeLock();
public Object read() {
log.debug("获取读锁...");
r.lock();
try {
log.debug("读取");
sleep(1);
return data;
} finally {
log.debug("释放读锁...");
r.unlock();
}
}
public void write() {
log.debug("获取写锁...");
w.lock();
try {
log.debug("写入");
sleep(1);
} finally {
log.debug("释放写锁...");
w.unlock();
}
}
}
- 信号量
信号量,用来限制能同时访问共享资源的线程上限,即操作系统里学的那个
实现的原理:线程通过cas的方式获取state,此时的state相当于一个信号量,一开始为3,1,2,4线程抢到后就变成0了,然后0和3
线程在队列里阻塞等待,park阻塞
public static void main(String[] args) {
// 1. 创建 semaphore 对象
Semaphore semaphore = new Semaphore(3);
// 2. 10个线程同时运行
for (int i = 0; i < 10; i++) {
new Thread(() -> {
// 3. 获取许可
try {
semaphore.acquire();
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
log.debug("running...");
sleep(1);
log.debug("end...");
} finally {
// 4. 释放许可
semaphore.release();
}
}).start();
}
}
4.CyclicBarrier
循环栅栏,用来进行线程协作,等待线程满足某个计数。构造时设置『计数个数』,每个线程执行到某个需要“同步”的时刻调用 await() 方法进行等待,当等待的线程数满足『计数个数』时,继续执行.
CyclicBarrier cb = new CyclicBarrier(2); // 个数为2时才会继续执行
new Thread(()->{
System.out.println("线程1开始.."+new Date());
try {
cb.await(); // 当个数不足时,等待
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
System.out.println("线程1继续向下运行..."+new Date());
}).start();
new Thread(()->{
System.out.println("线程2开始.."+new Date());
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
}
try {
cb.await(); // 2 秒后,线程个数够2,继续运行
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
System.out.println("线程2继续向下运行..."+new Date());
}).start();
注意 CyclicBarrier 与 CountDownLatch 的主要区别在于 CyclicBarrier 是可以重用的 CyclicBarrier 可以被比喻为『人满发车』
线程基础
wait和sleep的不同:
- sleep 是 Thread 方法,而 wait 是 Object 的方法
- sleep 不需要强制和 synchronized 配合使用,但 wait 需要和 synchronized 一起用
- sleep 在睡眠的同时,不会释放对象锁的,但 wait 在等待的时候会释放对象锁
- 它们状态 TIMED_WAITING

synchronized
synchronized原理:monitor

锁升级:

synchronized和reentra lock的区别:
reentralock相对于 synchronized 它具备如下特点
- 可中断
- 可以设置超时时间
- 可以设置为公平锁
- 支持多个条件变量
与 synchronized 一样,都支持可重入
线程池
核心七个参数?
ThreadPoolExecutor 的通用构造函数:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long
keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory
threadFactory, RejectedExecutionHandler handler)
1、 corePoolSize :当有新任务时,如果线程池中线程数没有达到线程池的基本大小,则会创建新的线
程执行任务,否则将任务放入阻塞队列。当线程池中存活的线程数总是大于 corePoolSize 时,应该考虑
调大 corePoolSize。
2、 maximumPoolSize :当阻塞队列填满时,如果线程池中线程数没有超过最大线程数,则会创建新的
线程运行任务。否则根据拒绝策略处理新任务。非核心线程类似于临时借来的资源,这些线程在空闲时
间超过 keepAliveTime 之后,就应该退出,避免资源浪费。
3、 BlockingQueue :存储等待运行的任务。
4、 keepAliveTime :非核心线程空闲后,保持存活的时间,此参数只对非核心线程有效。设置为0,
表示多余的空闲线程会被立即终止。
5、 TimeUnit :时间单位
TimeUnit.DAYS
TimeUnit.HOURS
TimeUnit.MINUTES
TimeUnit.SECONDS
TimeUnit.MILLISECONDS
TimeUnit.MICROSECONDS
TimeUnit.NANOSECONDS
6、 ThreadFactory :每当线程池创建一个新的线程时,都是通过线程工厂方法来完成的。在ThreadFactory 中只定义了一个方法 newThread,每当线程池需要创建新线程就会调用它。
public class MyThreadFactory implements ThreadFactory {
private final String poolName;
public MyThreadFactory(String poolName) {
this.poolName = poolName;
}
public Thread newThread(Runnable runnable) {
return new MyAppThread(runnable, poolName);//将线程池名字传递给构造函数,用于
区分不同线程池的线程
}
}
7、 RejectedExecutionHandler :当队列和线程池都满了的时候,根据拒绝策略处理新任务。
AbortPolicy:默认的策略,直接抛出RejectedExecutionException
DiscardPolicy:不处理,直接丢弃
DiscardOldestPolicy:将等待队列队首的任务丢弃,并执行当前任务
CallerRunsPolicy:由调用线程处理该任务
线程池大小怎么设置?
如果线程池线程数量太小,当有大量请求需要处理,系统响应比较慢,会影响用户体验,甚至会出现任
务队列大量堆积任务导致OOM。
如果线程池线程数量过大,大量线程可能会同时抢占 CPU 资源,这样会导致大量的上下文切换,从而增
加线程的执行时间,影响了执行效率。
CPU 密集型任务**(N+1)**: 这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1 ,
多出来的一个线程是为了防止某些原因导致的线程阻塞(如IO操作,线程sleep,等待锁)而带来的影
响。一旦某个线程被阻塞,释放了CPU资源,而在这种情况下多出来的一个线程就可以充分利用 CPU 的
空闲时间。
I/O 密集型任务**(2N)**: 系统的大部分时间都在处理 IO 操作,此时线程可能会被阻塞,释放CPU资源,
这时就可以将 CPU 交出给其它线程使用。因此在 IO 密集型任务的应用中,可以多配置一些线程,具体
的计算方法: 最佳线程数 = CPU核心数 * (1/CPU利用率) = CPU核心数 * (1 + (IO耗时/CPU耗时)) ,
一般可设置为2N。
执行原理:
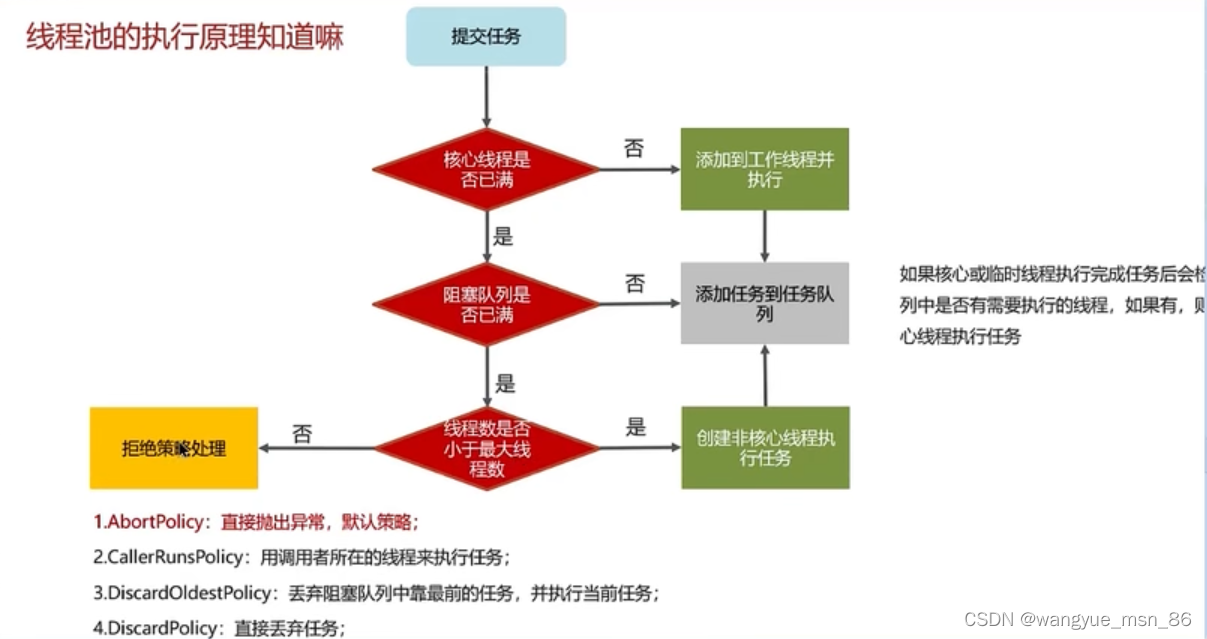
ThreadLocal
谈谈你对threadlocal的理解?
ThreadLocal叫做线程变量,意思是ThreadLocal中填充的变量属于当前线程,该变量对其他线程而言是隔离的,也就是说该变量是当前线程独有的变量。ThreadLocal为变量在每个线程中都创建了一个副本,那么每个线程可以访问自己内部的副本变量。
ThreadLoal 变量,线程局部变量,同一个 ThreadLocal 所包含的对象,在不同的 Thread 中有不同的副本。这里有几点需要注意:
因为每个 Thread 内有自己的实例副本,且该副本只能由当前 Thread 使用。这是也是 ThreadLocal 命名的由来。
既然每个 Thread 有自己的实例副本,且其它 Thread 不可访问,那就不存在多线程间共享的问题。
ThreadLocal 提供了线程本地的实例。它与普通变量的区别在于,每个使用该变量的线程都会初始化一个完全独立的实例副本。ThreadLocal 变量通常被private static修饰。当一个线程结束时,它所使用的所有 ThreadLocal 相对的实例副本都可被回收。
总的来说,ThreadLocal 适用于每个线程需要自己独立的实例且该实例需要在多个方法中被使用,也即变量在线程间隔离而在方法或类间共享的场景
下图可以增强理解
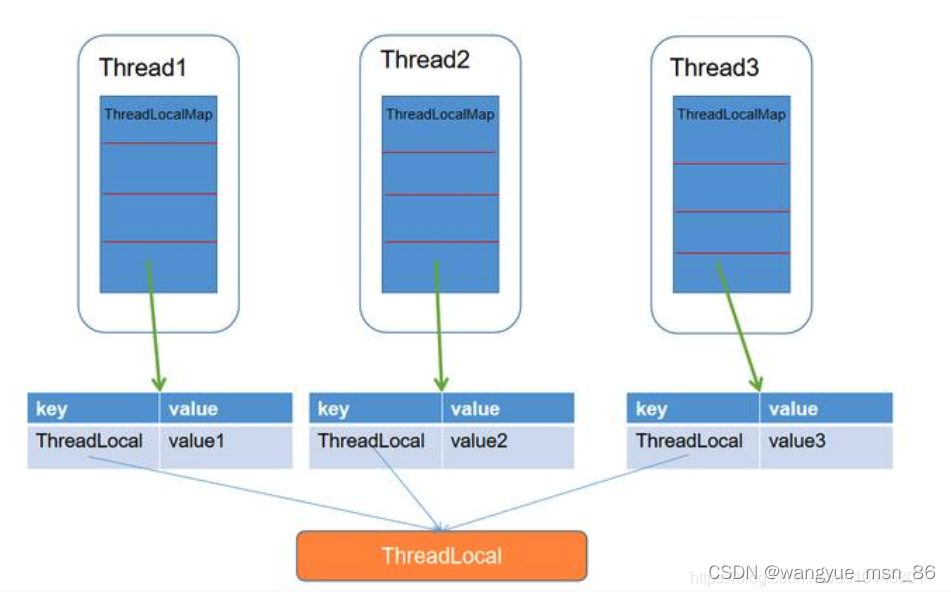
示例代码:
请注意,ThreadLocal变量是几个线程要访问的别的类的成员变量,说白了是线程访问的别人,每个线程都会有自己threadlocalmap副本,这是一个map结构,虽然他们用的key都是一个ThreadLocal对象,但是他们每个人的threadlocalmap都是自己的啊。所以每个线程都有自己的一个副本,保证的隔离访问别的类的成员变量,保存的副本也可以在该线程的不同方法之间传递(比如service controller之间传递)
public class ThreadLocaDemo {
private static ThreadLocal<String> localVar = new ThreadLocal<String>();
static void print(String str) {
//打印当前线程中本地内存中本地变量的值
System.out.println(str + " :" + localVar.get());
//清除本地内存中的本地变量
localVar.remove();
}
public static void main(String[] args) throws InterruptedException {
new Thread(new Runnable() {
public void run() {
ThreadLocaDemo.localVar.set("local_A");
print("A");
//打印本地变量
System.out.println("after remove : " + localVar.get());
}
},"A").start();
Thread.sleep(1000);
new Thread(new Runnable() {
public void run() {
ThreadLocaDemo.localVar.set("local_B");
print("B");
System.out.println("after remove : " + localVar.get());
}
},"B").start();
}
}
A :local_A
after remove : null
B :local_B
after remove : null
Threadlocal原理:
根据上面的示例可以看,两个线程一块访问一个ThreadLocal对象,ThreadLocal对象离不开ThreadlocalMap对象,他们的关系是:
jdk8以后,thread类中有一个成员变量就是ThreadlocalMap
可以看到ThreadlocalMap就是Threadlocal类的一个内部类,其实是一个静态内部类,静态内部类和静态变量是不一样的,可以new多个,也是存放到堆中,但是不存放在外部类在堆中的地方,是独立的,就相当于一个可以访问到外部类资源(threadlocal类)的独立的类。一个线程默认的ThreadlocalMap默认是空的。
上面的代码这一句:
public void run() {
ThreadLocaDemo.localVar.set("local_A");
print("A");
//打印本地变量
System.out.println("after remove : " + localVar.get());
}
当调用threadlocal的set方法的时候,threadlocal类中的set方法是这样的:
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
map.set(this, value);
} else {
createMap(t, value);
}
}
如果当前线程没有ThreadlocalMap(默认不是null嘛)的话,帮他创建一个ThreadLocalMap:
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue); // 默认调用他的构造方法 这个this指的是ThreadLocal对象,因为这是ThreadLocal类中的方法,而不是t
}
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY]; // 跟hashmap差不多 容量默认16
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1); // hash地址映射过程 把entry映射到数组的对应下标位置
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY);
}
get方法源码:
public T get() {
//1、获取当前线程
Thread t = Thread.currentThread();
//2、获取当前线程的ThreadLocalMap
ThreadLocalMap map = getMap(t);
//3、如果map数据不为空,
if (map != null) {
//3.1、获取threalLocalMap中存储的值
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
//如果是数据为null,则初始化,初始化的结果,TheralLocalMap中存放key值为threadLocal,值为null
return setInitialValue();
}
private T setInitialValue() {
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
remove源码:
public void remove() {
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
m.remove(this);
remove方法,直接将ThrealLocal 对应的值从当前相差Thread中的ThreadLocalMap中删除。为什么要删除,这涉及到内存泄露的问题。

所以如果 ThreadLocal 没有被外部强引用的情况下,在垃圾回收的时候会被清理掉的,这样一来 ThreadLocalMap中使用这个 ThreadLocal 的 key 也会被清理掉。但是,value 是强引用,不会被清理,这样一来就会出现 key 为 null 的 value。
ThreadLocal其实是与线程绑定的一个变量,如此就会出现一个问题:如果没有将ThreadLocal内的变量删除(remove)或替换,它的生命周期将会与线程共存。通常线程池中对线程管理都是采用线程复用的方法,在线程池中线程很难结束甚至于永远不会结束,这将意味着线程持续的时间将不可预测,甚至与JVM的生命周期一致。举个例字,如果ThreadLocal中直接或间接包装了集合类或复杂对象,每次在同一个ThreadLocal中取出对象后,再对内容做操作,那么内部的集合类和复杂对象所占用的空间可能会开始持续膨胀。
为什么要弄成弱引用?
为什么要这样做?
要知道,ThreadlocalMap是和线程绑定在一起的,如果这样线程没有被销毁,而我们又已经不会再某个threadlocal引用,那么key-value的键值对就会一直在map中存在,这对于程序来说,就出现了内存泄漏。
为了避免这种情况,只要将key设置为弱引用,那么当发生GC的时候,就会自动将弱引用给清理掉,也就是说:假如某个用户A执行方法时产生了一份threadlocalA,然后在很长一段时间都用不到threadlocalA时,作为弱引用,它会在下次垃圾回收时被清理掉。
而且ThreadLocalMap在内部的set,get和扩容时都会清理掉泄漏的Entry,内存泄漏完全没必要过于担心。
因为一次垃圾回收,弱引用就被清理了。用强引用因为线程池里的线程可能一直不被回收,那么一直存放着键值对,内存可能放不下。
key为null之后,value不为空,通过set,get等会清理key为null的entry
如果value也是空的话,有可能会触发空指针异常。因为使用前提前被清理了。
ThreadLocal在某些情况下可能会导致效率不高的问题,主要有以下几个方面的原因:
- 空间开销:每个线程都会创建一个ThreadLocalMap对象来保存各自的ThreadLocal变量,如果有大量的ThreadLocal变量或者线程数很多,就会导致很大的内存开销。
- 冲突解决:当多个线程同时访问ThreadLocal时,需要进行冲突解决,因为ThreadLocalMap内部使用的数组是基于开放寻址法解决冲突的。当线程数较多或者哈希冲突较多时,查找和插入操作的性能可能会受到影响。
- 生命周期管理:由于ThreadLocal使用了弱引用作为key,因此在使用过程中需要注意合理管理ThreadLocal对象的生命周期。如果没有及时清理不再使用的ThreadLocal对象,可能会导致内存泄漏问题。
- 需要频繁的get和set操作:每次通过ThreadLocal获取或设置变量时,都需要进行一次哈希查找操作,并且由于ThreadLocal使用的是线性探测法来解决冲突,如果哈希冲突较多,可能会导致查找时间增加。
尽管ThreadLocal在某些情况下可能会有一些效率上的问题,但在合适的场景下仍然是一种非常有用的工具,可以实现线程间的隔离和线程局部变量的管理。对于确保性能的需求,可以考虑使用其他方式来实现线程间的数据传递和共享,例如使用参数传递和共享变量等。
总结:想要安全的共享变量,使用ThreadLocal,每个线程保持一个ThreadLocalMap,以共同的ThreadLocal作为key来获取值,实现访问数据的隔离和同一线程不同方法之间的传递。
threadlocal的应用场景?
- 瑞吉外卖中,mp自动填充需要id值,但是需要在session中才能获取,所以在filter中获取sessin,set ThreadLocal的值。然后在字段填充的时候 get 那个值。因为这个过程都是在一个线程中进行的。
- 谷粒商城中,也是在拦截器中把session中的用户信息存在threadlocal中,然后 在servcie中就可以直接拿到用户信息了,使用get
ConcurrentHashMap
1.ConcurrentHashMap是怎么加锁的
在JDK1.7中,ConcurrentHashMap基于Segment+HashEntry数组实现的。Segment是Reentrant的子类,而其内部也维护了一个Entry数组,这个Entry数组和HashMap中的Entry数组是一样的。所以说Segment其实是一个锁,可以锁住一段哈希表结构,而ConcurrentHashMap中维护了一个Segment数组,所以是基于分段锁实现的。 而JDK1.8中,ConcurrentHashMap摒弃了Segment,而是采用synchronized+CAS+红黑树来实现的。锁的粒度也从段锁缩小为结点锁.

2.为什么ConcurrentHashMap不允许null值
为什么ConcurrentHashMap的key和value都不可以是null,但是hashmap可以为null

Spring
spring框架中的bean是单例的吗?spring中的单例bean是线程安全的吗?
spring框架的bean默认是单例的,可以指定scope为singleton(默认的 单例)或者prototype(多例)。单例bean不是线程安全的,或者说不一定是线程安全的。

因为一般在spring中都是注入无状态的对象,没有线程安全问题,如果在bean中定义了可修改的成员变量,是要考虑线程安全的,可以使用多例或者锁来解决。
比如图中count这个成员变量被方法使用了,多线程并发的情况下,因为这个类是单例的,那么这个count的线程安全就不能被保证,service对象一般是无状态的(因为只有方法没有成员变量),所以一般是线程安全的。
Bean标签范围配置?
scope: 指对象的作用范围
| 取值范围 | 说明 |
|---|---|
| singleton | 默认值,单例的 |
| prototype | 多例的 |
| request | WEB 项目中,Spring 创建一个 Bean 的对象,将对象存入到 request 域中 |
| session | WEB 项目中,Spring 创建一个 Bean 的对象,将对象存入到 session 域中 |
| global session | WEB 项目中,应用在 Portlet 环境,如果没有 Portlet 环境那么globalSession 相当 于 session |
Bean的生命周期

IOC

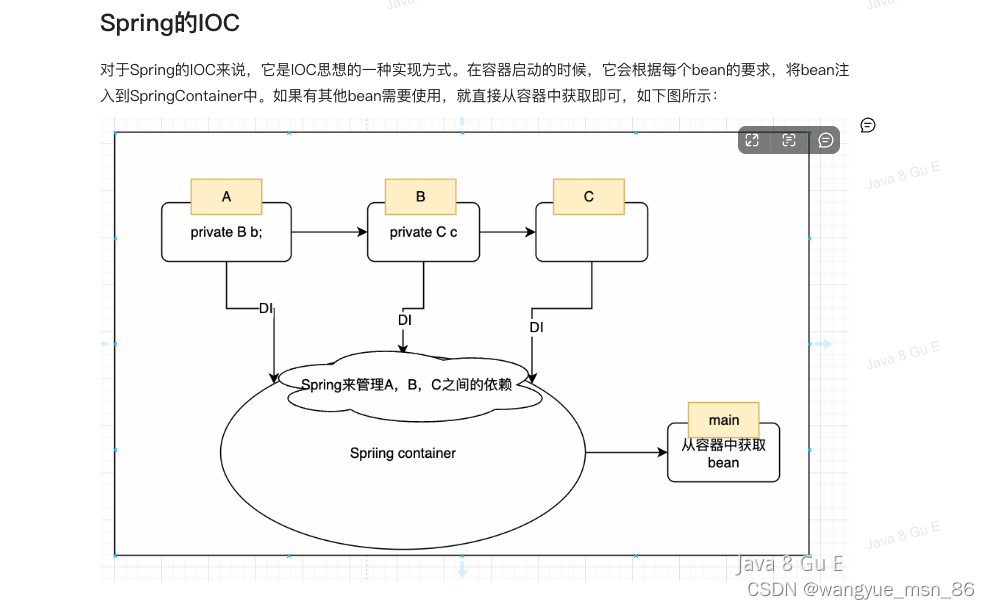

AOP
什么是AOP?
就是面向切面编程,用于那些和业务无关,但是却对多个对象产生影响的公共行为和逻辑,抽取公共模块复用,降低耦合
你们项目中哪里用到了AOP?
- 事务的处理 :项目中用到的@Transactional就是根据数据库事务和AOP机制,Spring会基于这个类生成一个代理对象,会将这个代理对象作为bean,一般我们使用声明式事务,就是基于配置来声明事务,因为没有侵入性,编程式事务是有侵入性的。
- 异常统一处理:使用@RestControllerAdvice注解,通过aop的方式处理全局异常
- 统一记录日志:使用spring aop的环绕通知+切点表达式(找到要记录日志的方法),通过环绕通知的参数获取请求方法的各种参数,然后记录日志,保存到数据库中
- 统一返回格式的设置
- 用户登录和鉴权
说一下 Spring AOP 实现原理?
Spring AOP 是构建在动态代理的基础上实现的,如果我们为 Spring 的某个 bean 配置了切面,那么Spring 在创建这个 bean 的时候,实际上创建的是这个 bean 的一个代理对象,我们后续对 bean 中方法的调用,实际上调用的是代理类重写的代理方法。Spring AOP 支持两种动态代理:JDK Proxy 和 CGLIB 动态代理。默认情况下,实现了接口的类,使用AOP 会基于 JDK 生成代理类,没有实现接口的类,会基于 CGLIB 生成代理类。
JDK动态代理和CGLIB动态代理的区别?
Spring AOP中的动态代理主要有两种方式:JDK动态代理和CGLIB动态代理。
JDK动态代理
如果目标类实现了接口,Spring AOP会选择使用JDK动态代理目标类。代理类根据目标类实现的接口动态生成,不需要自己编写,生成的动态代理类和目标类都实现相同的接口。JDK动态代理的核心是InvocationHandler 接口和 Proxy 类。
缺点:目标类必须有实现的接口。如果某个类没有实现接口,那么这个类就不能用JDK动态代理。
CGLIB动态代理
通过继承实现。如果目标类没有实现接口,那么Spring AOP会选择使用CGLIB来动态代理目标类。CGLIB(Code Generation Library)可以在运行时动态生成类的字节码,动态创建目标类的子类对象,在子类对象中增强目标类。CGLIB是通过继承的方式做的动态代理,因此如果某个类被标记为 final ,那么它是无法使用CGLIB做动态代理的。
优点:目标类不需要实现特定的接口,更加灵活。
什么时候采用哪种动态代理?
-
如果目标对象实现了接口,默认情况下会采用JDK的动态代理实现AOP
-
如果目标对象实现了接口,可以强制使用CGLIB实现AOP
-
如果目标对象没有实现了接口,必须采用CGLIB库
两者的区别:
- jdk动态代理使用jdk中的类Proxy来创建代理对象,它使用反射技术来实现,不需要导入其他依
赖。cglib需要引入相关依赖: asm.jar ,它使用字节码增强技术来实现。
- 当目标类实现了接口的时候Spring Aop默认使用jdk动态代理方式来增强方法,没有实现接口的时
候使用cglib动态代理方式增强方法。
AOP 是如何组成的?
AOP 是由:切面(Aspect)、切点(Pointcut)、连接点(Join Point)和通知(Advice)组成的,它
们的具体含义如下。
**① 切面(**Aspect)
切面(Aspect)由切点(Pointcut)和通知(Advice)组成,它既包含了横切逻辑的定义,也包括了连
接点的定义。
简单来说,切面就是当前 AOP 功能的类型,比如当前 AOP 是用户登录和鉴权的功能,那么它就是一个
切面。
② 切点(Pointcut)
切点 Pointcut:它的作用就是提供一组规则(使用 AspectJ pointcut expression language 来描述)用
来匹配连接点的。
简单来说,切点就是设置拦截规则的,满足规则的方法将会被拦截。
③ 连接点(Join Point)
应用执行过程中能够插入切面的一个点,这个点可以是方法调用时,抛出异常时,甚至修改字段时。切
面代码可以利用这些点插入到应用的正常流程之中,并添加新的行为。
简单来说,所有可以触发切点拦截规则的功能都是连接点。比如所有要登录才能访问的控制器(方
法),它们都属于连接点。
**④ 通知(**Advice)
切面也是有目标的 ——它必须完成的工作。在 AOP 术语中,切面的工作被称之为通知。
简单来说,当控制器(方法)被拦截之后,触发执行的具体方法就是通知。
小结:切面定义了 AOP 的功能,切点提供了具体的拦截规则,通知决定了具体的执行方法,而连接点
就是用来触发 AOP 的这些功能的,它们共同组成了 AOP。
Spring AOP 有几种通知(Advice)?
Spring AOP 中有 5 种通知类型:
-
前置通知使用 @Before 实现:通知方法会在目标方法调用之前执行;
-
后置通知使用 @After 实现:通知方法会在目标方法返回或者抛出异常后调用;
-
返回通知使用 @AfterReturning 实现:通知方法会在目标方法返回后调用;
-
抛出异常通知使用 @AfterThrowing 实现:通知方法会在目标方法抛出异常后调用;
-
环绕通知使用 @Around 实现:通知包裹了被通知的方法,在被通知的方法通知之前和调用之后执
行自定义的行为。
Spring事务失效
Spring事务失效的原因?
1.事务只有捕捉到了目标抛出的异常,才能进行后续的回滚处理,如果目标自己处理掉异常,事务失效
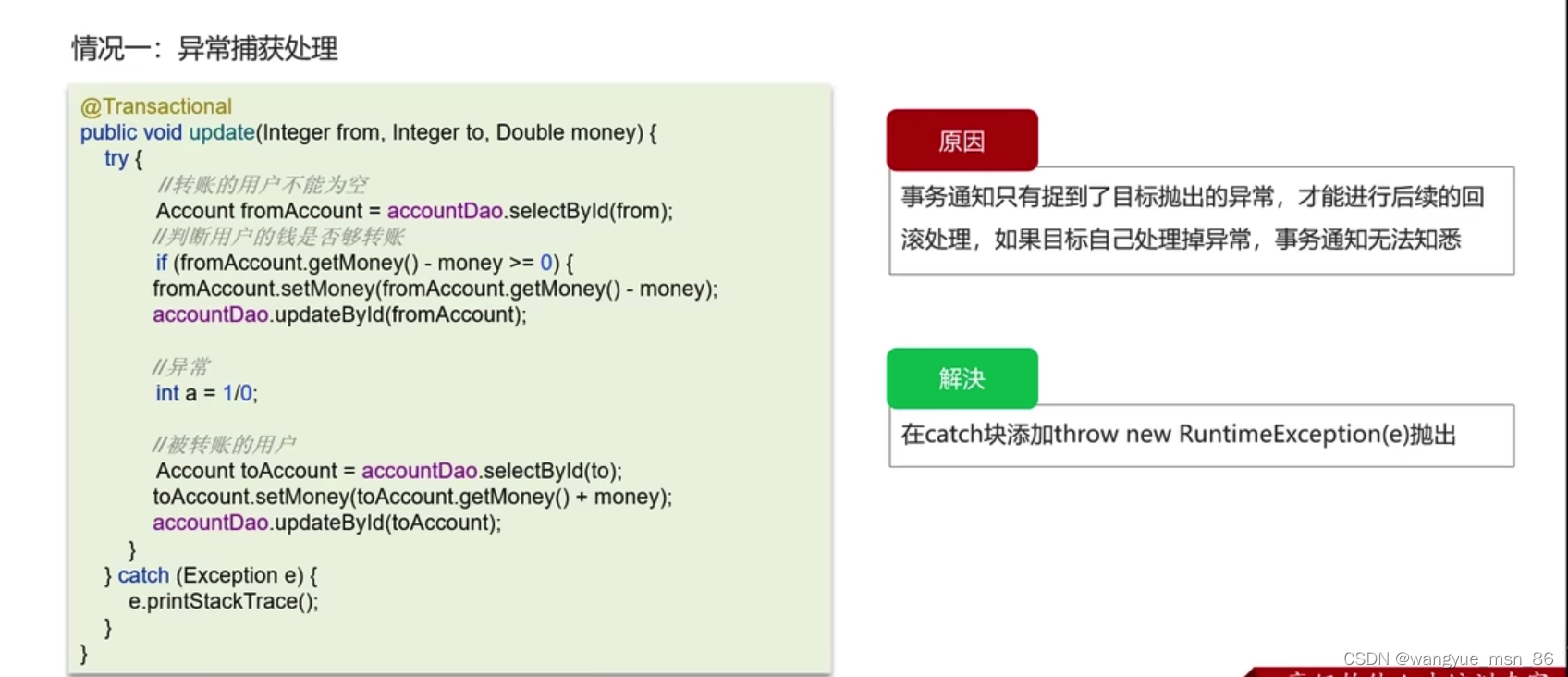
2.抛出检查异常(就是编译器要求你必须处置的异常),通过指定roobackFor属性,让他可以回滚任何异常
3.方法不是public的
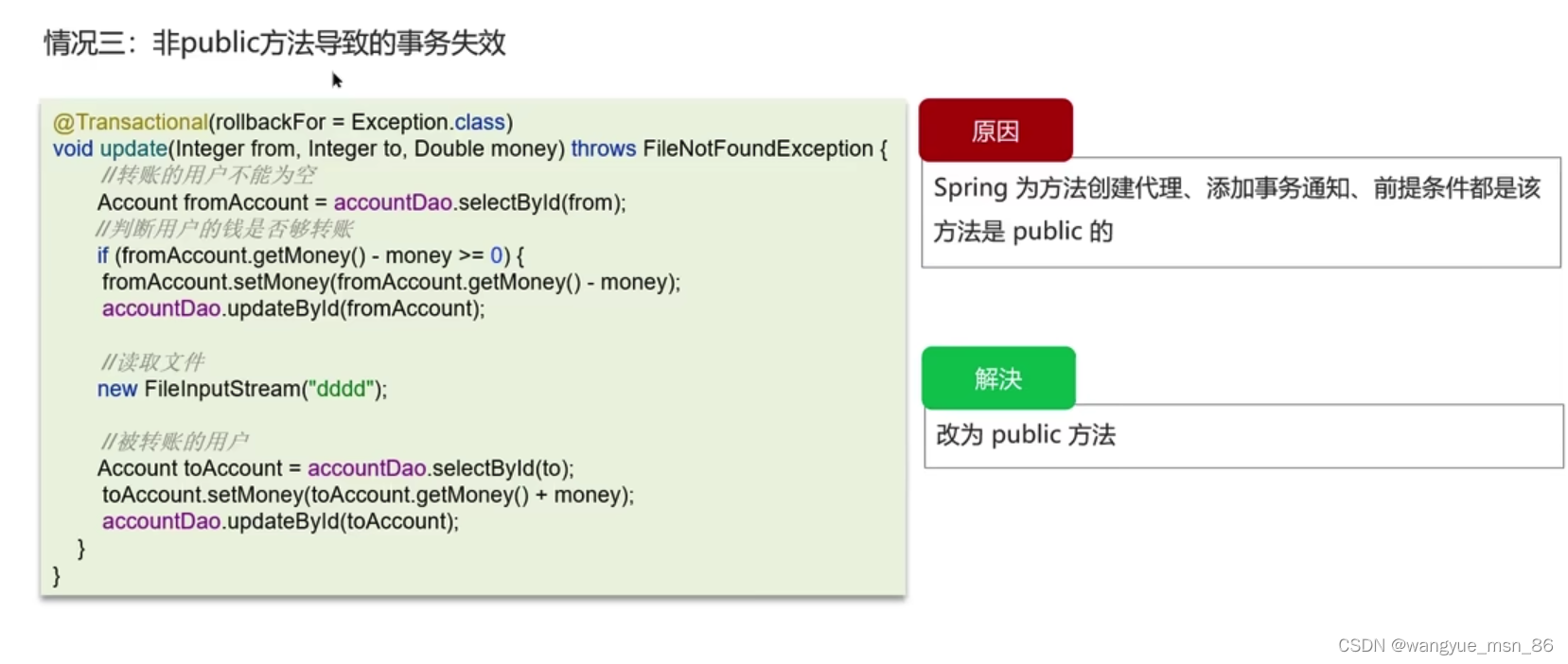
Spring 使用了哪些设计模式?
-
代理模式:在 AOP 中有使用;
-
单例模式:bean 默认是单例模式;
-
模板方法模式:jdbcTemplate;
-
工厂模式:BeanFactory;
-
观察者模式:Spring 事件驱动模型就是观察者模式很经典的一个应用,比如,ContextStartedEvent 就是 ApplicationContext 启动后触发的事件;
-
适配器模式:Spring MVC 中也是用到了适配器模式适配 Controller。
Spring常见的注解有那些?

@Autowired和@Resource的区别?
Autowire是spring的注解。默认情况下@Autowired是按类型匹配的(byType)。如果需要按名称(byName)匹配的话,可以使用@Qualifier注解与@Autowired结合。@Autowired 可以传递一个required=false 的属性,false指明当userDao实例存在就注入不存就忽略,如果为true,就必须注入,若userDao实例不存在,就抛出异常。
Resource是j2ee的注解,默认按 byName模式自动注入。@Resource有两个中重要的属性:name和type。name属性指定bean的名字,type属性则指定bean的类型。因此使用name属性,则按byName模式的自动注入策略,如果使用type属性,则按 byType模式自动注入策略。倘若既不指定name也不指定type属性,Spring容器将通过反射技术默认按byName模式注入。
SpringMVC
springMVC的执行流程

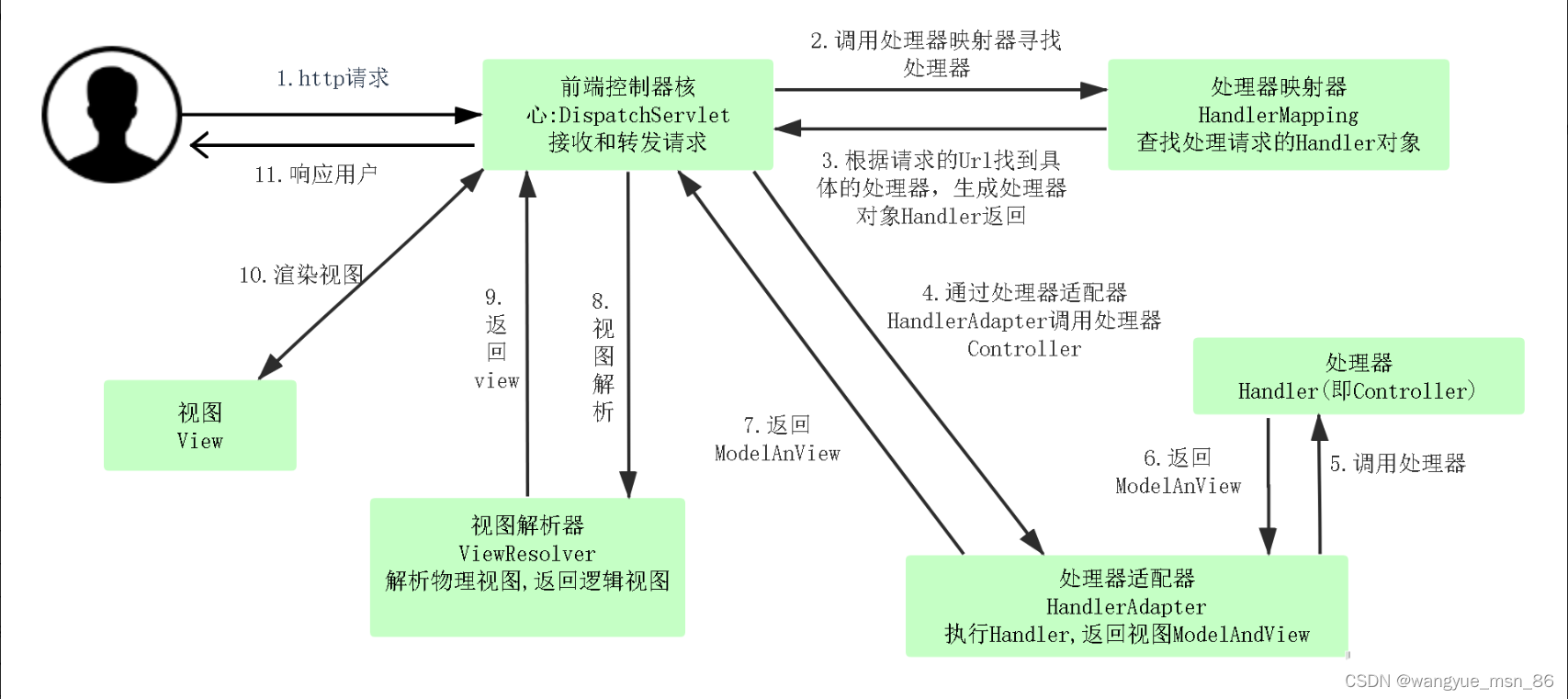
springmvc常用注解?

@RequestParam,@RequestBody,@PathVariable注解区别?
这三个注解是出来处理前端请求,把前端数据映射成java的,使用频率极高。
@RequestParam 和 @RequestBody 都是从 HttpServletRequest request 中取参的,而 @PathVariable 是映射 URI 请求参数中的占位符到目标方法的参数中的。
1、@RequestParam
请求链接举例(GET/POST):?param1=xxx¶m2=yyy
http://javam4.com/m4detail?id=111&tag=java
后端接收举例:
@RequestMapping(value = "/m4detail", method = {RequestMethod.GET,RequestMethod.POST})
public void m4detail(@RequestParam(value="id", required=true) String isId, @RequestParam String tag) {
System.out.println("isId="+isId);
System.out.println("tag="+tag);
}
首先这种方式无论是 GET 还是 POST 请求,都是可以获取到参数的,举例中特意使用了 @RequestParam 注解的一些参数,具体参数如下:
defaultValue 如果本次请求没有携带这个参数,或者参数为空,那么就会启用默认值
name 绑定本次参数的名称,要跟URL上面的一样
required 这个参数不是必须的,如果为 true,不传参数会报错
value 跟name一样的作用,是name属性的一个别名
2、@PathVariable
请求链接举例(GET/POST):/{id}
http://javam4.com/m4detail/111?tag=java
后端接收举例:
RequestMapping(value = "/m4detail/{id}", method = {RequestMethod.GET,RequestMethod.POST})
public void m4detail(@PathVariable String id, @RequestParam String tag) {
System.out.println("id="+id);
System.out.println("tag="+tag);
}
然后有的小伙伴可能会问,你这就接收了一个 {id},那我能接受 2 个参数吗?能。
一个 {xx} 就能对应一个参数,那你的请求链接假如是这样:
http://javam4.com/m4detail/111/java
后端接收方式:
@RequestMapping(value = "/m4detail/{id}/{tag}", method = {RequestMethod.GET,RequestMethod.POST})
public void m4detail(@PathVariable String id, @PathVariable String tag) {
System.out.println("id="+id);
System.out.println("tag="+tag);
}
同样 @PathVariable 也有相应的参数:
name 绑定参数的名称,默认不传递时,绑定为同名的形参。 赋值但名称不一致时则报错
value 跟name一样的作用,是name属性的一个别名
required 这个参数不是必须的,如果为 true,不传参数会报错
总结,使用 @PathVariable 需要注意两点:
参数接收类型使用基本类型
如果@PathVariable标明参数名称,则参数名称必须和URL中参数名称一致
设计模式
3、@ReuqestBody(不能用于GET请求)重点
通常后端与前端的交互大多情况下是 POST 请求,尤其是传递大量参数时,毕竟大量参数暴露在浏览的地址栏还是不怎么优雅的,而在 POST 请求中应用 JSON 串对于 Spring MVC 来说是比较友好的,后端使用 @RequestBody 注解就可以方便的实现 JSON 串到接收参数的数据映射。
说明一下 @RequestBody 为什么不能用用于 GET 请求,RequestBody 顾名思义,是将请求参数设置在请求 Body 中的,也就是请求体,而 GET 请求无请求体。
使用 @RequestBody 需要满足如下条件:
1.Content-Type 为 application/json,确保传递是 JSON 数据;
2.参数转化的配置必须统一,否则无法接收数据,比如 json、request 混用等传递参数举例:(JSON数据)
{
"aaa": {
"id": "759791ec-0175-ff808081",
"title": "我是标题",
"content": "我是内容"
},
"bbb": [
"123456"
],
"ccc": 10
}
后端想要接收这个 JSON 数据有两种方式选择,一种是建立与 JSON 数据与之对应的实体,二是直接使用 Map<String,Object> 对象接收。
因为 SpringMVC 会帮我们把符合要求的参数封装进实体对象中,所以在参数比较多的情况下,直接使用对象方式会比较方便。
后端接收举例:(实体举例)
@PostMapping("/save")
public void save(@RequestBody QuestionVo vo) {
System.out.println(vo.getAaa().getId());
}
QuestionVo.java 实体:
public class QuestionVo {
private Question aaa;
private List<String> bbb;
private List<String> ccc;
省略get\set方法...
}
public class Question {
private String id;
private String title;
private String content;
省略get\set方法...
}
在这给大家说一下 @RequestBody 在一个请求中只能用一次,如下是报错的:
@PostMapping("/save")
public void save(@RequestBody QuestionVo vo, @RequestBody String niceyoo) {
System.out.println(vo.getAaa().getId());
}
报错信息:
I/O error while reading input message; nested exception is java.io.IOException: Stream closed
但是 @RequestParam 是支持多个使用的。
总结(一定要看)
1、在 GET 请求中可以使用 @RequestParam,不能使用 @RequestBody,@RequestBody 是用来获取请求体中的参数,因为 GET 请求没有请求体,所以不能使用。
2、在 POST 请求中,可以使用 @RequestBody 和 @RequestParam ,其中 @RequestParam 是用来获取 application/x-www-form-urlencoded 、form-data 格式数据的,@RequestBody 用来获取非 application/x-www-form-urlencoded 数据的,比如 application/json、application/xml 等。
3、一个方法中,可以同时使用多个 @RequestParam ,但是只能使用一个 @RequestBody,否则会报错。
4、@PathVariable 起到的作用就是 URI 请求参数中的占位符到目标方法参数的映射。
5、前端请求的 Content-Type ,默认值为 application/x-www-form-urlencoded 格式,在这种格式下,后端直接使用 @RequestParam 就可以直接获取指定的参数,但是一旦前端传递的是 JSON 数据,也就是 Content-Type 的值为 application/json,那么使用 @RequestParam 是取不到值的,不但取不到值还报错。
Mybatis
#号和$的区别
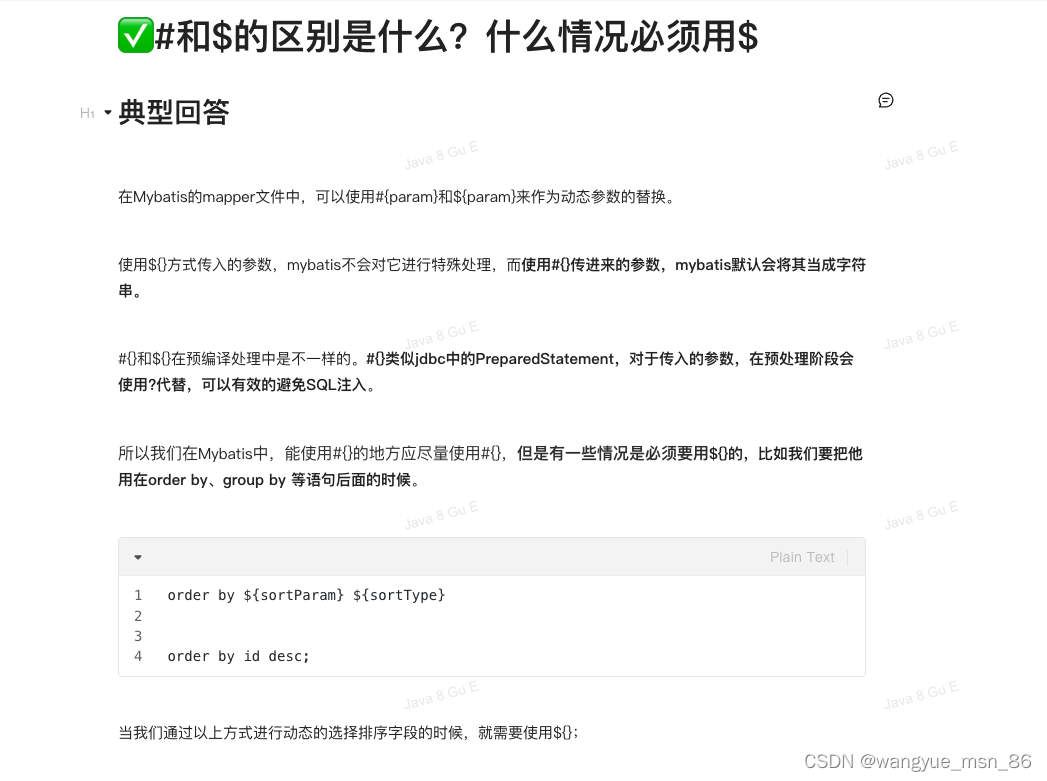
Linux
常用的linux命令?
ps -ef|grep tomcat -e:等价于 ‘-A’ ,表示列出全部的进程
-f:显示全部的列(显示全字段)
sudo命令增加执行权限
rm -rf命令删除文件
ssh 命令连接别的主机
reboot 重启机器
cat查看文件
head查看文件前几行
tail查看文件后几行 可用于查看日志
kill 杀死线程
ifconfig查看ip地址
docker
docker常用命令?
查看自己服务器中docker 镜像列表:docker images
拉取镜像不加tag(版本号) 即拉取docker仓库中 该镜像的最新版本latest 加:tag 则是拉取指定版本:docker pull 镜像名:tag
查看正在运行容器列表:docker ps
运行容器:docker run -d --name nacos -p ‘8848:8848’ -p ‘9848:9848’ -e MODE=standalone nacos/nacos-server:v2.1.0-slim
dubbo
基本使用:springboot版本
远程调用的提供者provider模块,消费者consumer模块,公共接口模块。在公共接口模块定义接口DemoService,然后另外两个模块共同依赖他,
consumer和provider都配置上dubbo的配置信息,在application.yml中
dubbo:
application:
name: dubbo-provider
protocol:
name: dubbo
port: -1
registry:
address: zookeeper://${zookeeper.address:127.0.0.1}:2181
provider模块写一个实现类实现,使用@DubboService,并且使用dubbo的包扫描,以后会把这个类记录到zookeeper中去。
@DubboService
public class DemoServiceImpl implements DemoService{
@Override
public String sayHello(String name) {
return "Hello杨佳兴";
}
}
消费者注入接口即可,通过动态代理来实现 @DubboReference
@Component // CommandLineRunner是springboot提供的一种访问快捷方式,只要类注入到容器中就可以实现run方法,程序执行后就会调用
public class Task implements CommandLineRunner {
@DubboReference
private DemoService demoService;
@Override
public void run(String... args) throws Exception {
String result = demoService.sayHello("world");
System.out.println("Receive result ======> " + result);
new Thread(()-> {
while (true) {
try {
Thread.sleep(1000);
System.out.println(new Date() + " Receive result ======> " + demoService.sayHello("world"));
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupt();
}
}
}).start();
}
}
这个userService接口,双方都要写一个该接口,所以比较好的实现是把该接口的定义放到公共模块中,然后双方都来依赖这个模块
dubbo自动完成了序列化和反序列化,要传输的对象必须实现Serializable接口
dubbo要点:
1.动态代理,把接口代理成实现类
2.网络通信,RPC协议,默认是dubbo协议,适合高并发场景
3.负载均衡:支持多种负载均衡算法

熔断限流降级
1.1 什么是熔断
A 服务调用 B 服务的某个功能, 由于网络不稳定问题, 或者 B 服务卡机, 导致功能时间超长。 如果这样子的次数太多。 我们就可以直接将 B 断路了(A 不再请求 B 接口) , 凡是调用 B 的直接返回降级数据, 不必等待 B 的超长执行。 这样 B 的故障问题, 就不会级联影响到 A。
1.2 什么是降级
整个网站处于流量高峰期, 服务器压力剧增, 根据当前业务情况及流量, 对一些服务和页面进行有策略的降级[停止服务, 所有的调用直接返回降级数据]。 以此缓解服务器资源的的压力, 以保证核心业务的正常运行, 同时也保持了客户和大部分客户的得到正确的相应。
异同:
相同点:
为了保证集群大部分服务的可用性和可靠性, 防止崩溃, 牺牲小我
用户最终都是体验到某个功能不可用
不同点:
熔断是被调用方故障, 触发的系统主动规则
降级是基于全局考虑, 停止一些正常服务, 释放资源
1.3 什么是限流
对打入服务的请求流量进行控制, 使服务能够承担不超过自己能力的流量压力
消息队列
1.如何保证消息的顺序消费?
以rabbitmq为例,想要顺序消费,比如消息123,那么这三个消息是不能被多个消费者消费的,因为多个人消费控制不了消费的顺序,也不能一个消费者直接多线程消费,也会造成乱序。就算你拿分布式锁控制,也是需要同步的,性能跟一个消费者顺序消费比区别不大。
我想到的解决办法:
1.并发量不大的时候,直接只让一个消费者去顺序消费这3个消息,可以弄成rabbithandler那种根据消息类型来匹配的模式,反正核心思想就是顺序去消费
2.并发量大的时候,上面的方案被得物的一面面试官否决了,我又想了一个方案,一个消费者去监听队列,可以把消息编号,1,2,3,号,然后总长度为3,如果收到三个消息了,就开启一个异步线程去处理,可以放到一个队列里,可以先排序,然后顺序消费消息。这样的话消息不会影响后面的消息的消费,虽然必须是同步的,但是不会等3个都执行完了消息队列才继续工作,而是交给一个异步线程慢慢去弄,不影响消息队列后续的操作。
网上的方案
方案一,在 Producer 端,将 Queue 拆成多个子 Queue 。假设原先 Queue 是 QUEUE_USER ,那么我们就分拆成 QUEUE_USER_00 至 QUEUE_USER_…${N-1} 这样 N 个队列,然后基于消息的用户编号取余,路由到对应的子 Queue 中。
方案二,在 Consumer 端,将 Queue 拉取到的消息,将相关联的消息发送到相同的线程中来消费。例如说,还是 Queue 是 QUEUE_USER 的例子,我们创建 N 个线程池大小为 1 的 ExecutorService 数组,然后基于消息的用户编号取余,提交到对应的 ExecutorService 中的单个线程来执行。我觉得我的方案比这个理想。
两个方案,并不冲突,可以结合使用。
项目
项目遇到了哪些难点
1.现场测试问题:和别的单位联调的时候,他们用restTemplate调用我们系统的接口,一直无法登录,后来通过wireshark抓包分析,查看报文,排查出了他们restTemplate没有添加cookie,没有模拟浏览器的环境,没有cookie就没法携带sessionId,就无法保证会话,所以添加了cookie之后就能成功访问了。
2.事务失效,当调用本类的其他事务的方法时,事务会失效,通过注入自己来解决,因为spring三级缓存已经解决了循环依赖问题,所以解决了事务失效
3.终端告警,使用rabbitmq保证消息不丢失,rabbitmq可靠性传递,生产者确认+return回调+持久化+消费者确认。然后消息被消费者消费时,要防止消息被重复消费,在redis中,使用setNx来进行判断。如果是redis集群会有问题,可能会有读从结点但是主结点写操作还没同步过来造成不一致。
拿redis解决有两种方案,1是根据一个唯一id 进行setnx,加上以后后面的重复请求就不能再消费了,只需要设置一个过期时间,比mq重传的msl大即可,2是用token,生成唯一的token,写入redis,消费请求来以后,使用lua脚本进行判断删除,保证只有一个人成功
但是redis集群是ap的,一致性是不能保证的,所以使用第一个方案,防止读到从节点尚未同步主节点新数据的情况。如果大并发的终端告警可以使用方案2,容忍不一致但是换取并发量。或者根据告警dps来自适应的使用这两种方法。
4.任务管理的时候,使用rabbitmq延迟队列实现定时消息,并且做一个终态判断,比如半小时的任务,当计时完成判定任务未完成和用户上传同一时间到来的话,不要产生不一致的问题,使用分布式锁加一个状态字段来判断,整个流程只能有一个终态。延迟队列是给队列设置延迟时间,不能给消息设置,因为rabbitmq消息是惰性过期的。可以弄几个队列,比如2小时的,3小时的,6小时的等等,如果客户在计时结束前完成任务,就会发送消息,回收一系列的资源,如果超时未完成,那么最终资源不回收资源,继续给他们用,但是把时间和状态记录下来,以后会额外收费
5.bug:使用了分布式锁解决幂等性,但是还是出现了重复

出现了事务的粒度和锁的粒度问题,另一个事务已经拿到锁了,上一个事务还没提交,导致不可见,使用aop的注解的事务是方法执行完了后提交的,即使再最后才释放锁也不好使,应该减少事务的粒度
使用编程式事务控制:
项目中有哪些亮点
哪里用到了多线程:
综合态势页面 接口发出了好多请求,比较复杂,还有远程接口调用,使用线程池ThreadPoolExecutor和异步编排CompletableFuture优化加载速度
先在本系统从数据库中拿到我们终端id获取我们终端id在别的厂家的标识,然后以此来去远程调用别的厂家的三个接口,获取终端资源占用情况,终端告警信息,终端经纬度情况等,异步编排,缩短接口响应时间
根据这个改编,先有1线程查出spu,然后2,3,4是对1来说串行化的接口,因为需要使用1查完的spu,5不需要所以可以直接开辟,2,3,4是等1执行完了,他们三个线程竞争,最后6是远程调用别的接口的
@Override
public SkuItemVo item(Long skuId) throws ExecutionException, InterruptedException {
SkuItemVo skuItemVo = new SkuItemVo();
CompletableFuture<SkuInfoEntity> infoFuture = CompletableFuture.supplyAsync(() -> {
//1、sku基本信息的获取 pms_sku_info
SkuInfoEntity info = this.getById(skuId);
skuItemVo.setInfo(info);
return info;
}, executor);
CompletableFuture<Void> saleAttrFuture = infoFuture.thenAcceptAsync((res) -> {
//2、获取spu的销售属性组合
List<SkuItemSaleAttrVo> saleAttrVos = skuSaleAttrValueService.getSaleAttrBySpuId(res.getSpuId());
skuItemVo.setSaleAttr(saleAttrVos);
}, executor);
CompletableFuture<Void> descFuture = infoFuture.thenAcceptAsync((res) -> {
//3、获取spu的介绍 pms_spu_info_desc
SpuInfoDescEntity spuInfoDescEntity = spuInfoDescService.getById(res.getSpuId());
skuItemVo.setDesc(spuInfoDescEntity);
}, executor);
CompletableFuture<Void> baseAttrFuture = infoFuture.thenAcceptAsync((res) -> {
//4、获取spu的规格参数信息
List<SpuItemAttrGroupVo> attrGroupVos = attrGroupService.getAttrGroupWithAttrsBySpuId(res.getSpuId(), res.getCatalogId());
skuItemVo.setGroupAttrs(attrGroupVos);
}, executor);
// Long spuId = info.getSpuId();
// Long catalogId = info.getCatalogId();
//5、sku的图片信息 pms_sku_images
CompletableFuture<Void> imageFuture = CompletableFuture.runAsync(() -> {
List<SkuImagesEntity> imagesEntities = skuImagesService.getImagesBySkuId(skuId);
skuItemVo.setImages(imagesEntities);
}, executor);
CompletableFuture<Void> seckillFuture = CompletableFuture.runAsync(() -> {
//6、远程调用查询当前sku是否参与秒杀优惠活动
R skuSeckilInfo = seckillFeignService.getSkuSeckilInfo(skuId);
if (skuSeckilInfo.getCode() == 0) {
//查询成功
SeckillSkuVo seckilInfoData = skuSeckilInfo.getData("data", new TypeReference<SeckillSkuVo>() {
});
skuItemVo.setSeckillSkuVo(seckilInfoData);
if (seckilInfoData != null) {
long currentTime = System.currentTimeMillis();
if (currentTime > seckilInfoData.getEndTime()) {
skuItemVo.setSeckillSkuVo(null);
}
}
}
}, executor);
//等到所有任务都完成
CompletableFuture.allOf(saleAttrFuture,descFuture,baseAttrFuture,imageFuture,seckillFuture).get();
return skuItemVo;
}
线程池是写了一个配置类来注入的spring容器的:
@EnableConfigurationProperties(ThreadPoolConfigProperties.class)
@Configuration
public class MyThreadConfig {
@Bean
public ThreadPoolExecutor threadPoolExecutor(ThreadPoolConfigProperties pool) {
return new ThreadPoolExecutor(
pool.getCoreSize(), // 核心线程数
pool.getMaxSize(), // 总线程数 核心加救急线程
pool.getKeepAliveTime(), // 救急线程存活时间
TimeUnit.SECONDS, // 救急线程时间单位
new LinkedBlockingDeque<>(100000), // 阻塞队列
Executors.defaultThreadFactory(), // 线程工厂 - 可以为线程创建时起个好名字
new ThreadPoolExecutor.AbortPolicy() // 拒绝策略
// ○ AbortPolicy 让调用者抛出 RejectedExecutionException 异常,这是默认策略
//○ CallerRunsPolicy 让调用者运行任务
//○ DiscardPolicy 放弃本次任务
// ○ DiscardOldestPolicy 放弃队列中最早的任务,本任务取而代之
);
}
}
@ConfigurationProperties(prefix = "gulimall.thread")
// @Component
@Data
public class ThreadPoolConfigProperties {
private Integer coreSize;
private Integer maxSize;
private Integer keepAliveTime;
}
#配置线程池 application.properties
gulimall.thread.coreSize=20
gulimall.thread.maxSize=200
gulimall.thread.keepAliveTime=10
网上的帖子:
面试官:公司项目中Java的多线程一般用在哪些场景?
多线程使用的主要目的在于:
1、吞吐量:你做WEB,容器帮你做了多线程,但是他只能帮你做请求层面的。简单的说,可能就是一个请求一个线程。或多个请求一个线程。如果是单线程,那同时只能处理一个用户的请求。
2、伸缩性:也就是说,你可以通过增加CPU核数来提升性能。如果是单线程,那程序执行到死也就利用了单核,肯定没办法通过增加CPU核数来提升性能。
鉴于是做WEB的,第1点可能你几乎不涉及。那这里我就讲第二点吧。
举个简单的例子:
假设有个请求,这个请求服务端的处理需要执行3个很缓慢的IO操作(比如数据库查询或文件查询),那么正常的顺序可能是(括号里面代表执行时间):
- 读取文件1 (10ms)
- 处理1的数据(1ms)
- 读取文件2 (10ms)
- 处理2的数据(1ms)
- 读取文件3 (10ms)
- 处理3的数据(1ms)
- 整合1、2、3的数据结果 (1ms)
单线程总共就需要34ms。
那如果你在这个请求内,把ab、cd、ef分别分给3个线程去做,就只需要12ms了。
所以多线程不是没怎么用,而是,你平常要善于发现一些可优化的点。然后评估方案是否应该使用。假设还是上面那个相同的问题:但是每个步骤的执行时间不一样了。
- 读取文件1 (1ms)
- 处理1的数据(1ms)
- 读取文件2 (1ms)
- 处理2的数据(1ms)
- 读取文件3 (28ms)
- 处理3的数据(1ms)
- 整合1、2、3的数据结果 (1ms)
单线程总共就需要34ms。
如果还是按上面的划分方案(上面方案和木桶原理一样,耗时取决于最慢的那个线程的执行速度),在这个例子中是第三个线程,执行29ms。那么最后这个请求耗时是30ms。比起不用单线程,就节省了4ms。但是有可能线程调度切换也要花费个1、2ms。因此,这个方案显得优势就不明显了,还带来程序复杂度提升。不太值得。
那么现在优化的点,就不是第一个例子那样的任务分割多线程完成。而是优化文件3的读取速度。可能是采用缓存和减少一些重复读取。
首先,假设有一种情况,所有用户都请求这个请求,那其实相当于所有用户都需要读取文件3。那你想想,100个人进行了这个请求,相当于你花在读取这个文件上的时间就是28×100=2800ms了。那么,如果你把文件缓存起来,那只要第一个用户的请求读取了,第二个用户不需要读取了,从内存取是很快速的,可能1ms都不到。
伪代码:
public class MyServlet extends Servlet{
private static Map<String, String> fileName2Data = new HashMap<String, String>();
private void processFile3(String fName){
String data = fileName2Data.get(fName);
if(data==null){
data = readFromFile(fName); //耗时28ms
fileName2Data.put(fName, data);
}
//process with data
}
}
看起来好像还不错,建立一个文件名和文件数据的映射。如果读取一个map中已经存在的数据,那么就不不用读取文件了。
可是问题在于,Servlet是并发,上面会导致一个很严重的问题,死循环。因为,HashMap在并发修改的时候,可能是导致循环链表的构成!!!(具体你可以自行阅读HashMap源码)如果你没接触过多线程,可能到时候发现服务器没请求也巨卡,也不知道什么情况!
好的,那就用ConcurrentHashMap,正如他的名字一样,他是一个线程安全的HashMap,这样能轻松解决问题。
public class MyServlet extends Servlet{
private static ConcurrentHashMap<String, String> fileName2Data = new ConcurrentHashMap<String, String>();
private void processFile3(String fName){
String data = fileName2Data.get(fName);
if(data==null){
data = readFromFile(fName); //耗时28ms
fileName2Data.put(fName, data);
}
//process with data
}
}
这样真的解决问题了吗,这样虽然只要有用户访问过文件a,那另一个用户想访问文件a,也会从fileName2Data中拿数据,然后也不会引起死循环。
可是,如果你觉得这样就已经完了,那你把多线程也想的太简单了,骚年!你会发现,1000个用户首次访问同一个文件的时候,居然读取了1000次文件(这是最极端的,可能只有几百)。What the fuckin hell!!!
难道代码错了吗,难道我就这样过我的一生!
好好分析下。Servlet是多线程的,那么
public class MyServlet extends Servlet{
private static ConcurrentHashMap<String, String> fileName2Data = new ConcurrentHashMap<String, String>();
private void processFile3(String fName){
String data = fileName2Data.get(fName);
//“偶然”-- 1000个线程同时到这里,同时发现data为null
if(data==null){
data = readFromFile(fName); //耗时28ms
fileName2Data.put(fName, data);
}
//process with data
}
}
复制
上面注释的“偶然”,这是完全有可能的,因此,这样做还是有问题。
因此,可以自己简单的封装一个任务来处理。
public class MyServlet extends Servlet{
private static ConcurrentHashMap<String, FutureTask> fileName2Data = new ConcurrentHashMap<String, FutureTask>();
private static ExecutorService exec = Executors.newCacheThreadPool();
private void processFile3(String fName){
FutureTask data = fileName2Data.get(fName);
//“偶然”-- 1000个线程同时到这里,同时发现data为null
if(data==null){
data = newFutureTask(fName);
FutureTask old = fileName2Data.putIfAbsent(fName, data);
if(old==null){
data = old;
}else{
exec.execute(data);
}
}
String d = data.get();
//process with data
}
private FutureTask newFutureTask(final String file){
return new FutureTask(new Callable<String>(){
public String call(){
return readFromFile(file);
}
private String readFromFile(String file){return "";}
}
}
}
复制
以上所有代码都是直接在bbs打出来的,不保证可以直接运行。
多线程最多的场景:web服务器本身;各种专用服务器(如游戏服务器);
多线程的常见应用场景:
- 后台任务,例如:定时向大量(100w以上)的用户发送邮件;
- 异步处理,例如:发微博、记录日志等;
- 分布式计算
项目哪里用到了mq
场景:比如未付款订单,超过一定时间后,系统自动取消订单并释放占有物品。常用解决方案:spring的 schedule 定时任务轮询数据库缺点:消耗系统内存、增加了数据库的压力、存在较大的时间误差解决:rabbitmq的消息TTL和死信Exchange结合
拿mq做了定时任务,减少数据库压力,减少内存消耗,时间误差小。 延迟队列的实现方式
谷粒商城做的是订单取消,如果下单以后1分钟没有付款就取消的这个功能
Rabbitmq笔记
Rabbit MQ概念 生产者和消费者都是一个连接,多个信道,一个客户端只有一个连接,虚拟主机类似docker沙箱机制 可以给java环境配一个,php环境配另一个。或者开发环境配一个,测试环境配一个,线上的环境配一个。
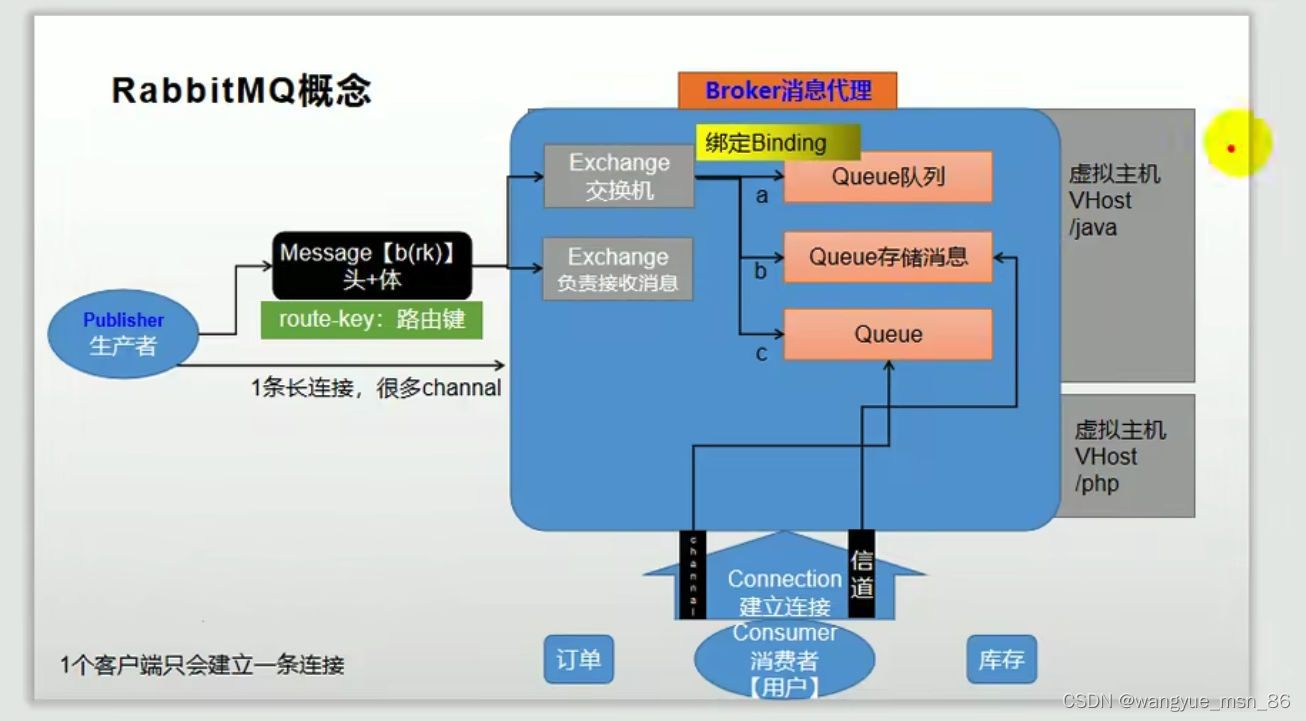
生产者发消息发到Exchange中,Exchage按照规则转发给各个队列,按照AMQP协议,Exchage有四种 规则:Exchage要绑定(Bingding)想要发送消息的队列,绑定时要指定一个路由键,Exchange发送消息的时候也要写一个路由键,如果这两个路由键对应规则一致,就能收到消息
- direct Exchange的路由键必须和message的路由键一样才能收到消息
- fanout Exchange绑定的所有队列都能收到消息
- topic 可以使用通配符分组收到消息,如下图,绑定的路由键为usa.#的队列,可以收到 usa.news和usa.weather两条消息
- headers 性能差基本用不到了

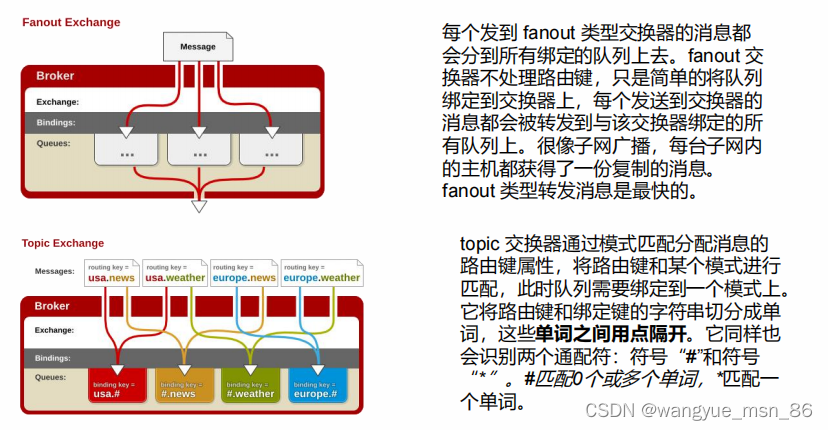
SrpingBoot整合rabbitmq:
amqpAdmin:创建交换机,创建队列,创建二者的绑定
rabbitTemplate:发送消息
package com.xunqi.gulimall.order;
import com.xunqi.gulimall.order.entity.OrderReturnReasonEntity;
import lombok.extern.slf4j.Slf4j;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.amqp.core.*;
import org.springframework.amqp.rabbit.connection.CorrelationData;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.Date;
import java.util.HashMap;
import java.util.UUID;
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest
public class GulimallOrderApplicationTests {
@Autowired
private AmqpAdmin amqpAdmin;
@Autowired
private RabbitTemplate rabbitTemplate;
// rabbitTemplate发送消息
//convertAndSend 转化并发送
@Test
public void sendMessageTest() {
OrderReturnReasonEntity reasonEntity = new OrderReturnReasonEntity();
reasonEntity.setId(1L);
reasonEntity.setCreateTime(new Date());
reasonEntity.setName("reason");
reasonEntity.setStatus(1);
reasonEntity.setSort(2);
String msg = "Hello World";
//1、发送消息,如果发送的消息是个对象,会使用序列化机制,将对象写出去,对象必须实现Serializable接口
//2、发送的对象类型的消息,可以是一个json,需要配置Json转化器,写一个配置类注入到ioc容器
// @Bean
// public MessageConverter messageConverter() {
// return new Jackson2JsonMessageConverter();
// }
rabbitTemplate.convertAndSend("hello-java-exchange" // 发送消息的交换机
,"hello2.java" // 路由键
, reasonEntity // 消息 ,可转化
,new CorrelationData(UUID.randomUUID().toString())); //
log.info("消息发送完成:{}",reasonEntity);
}
/**
* 1、如何创建Exchange、Queue、Binding
* 1)、使用AmqpAdmin进行创建
* 2、如何收发消息
*/
@Test
public void createExchange() {
// 使用amqpAdmin创建direct交换机
Exchange directExchange = new DirectExchange("hello-java-exchange",true,false);
amqpAdmin.declareExchange(directExchange);
log.info("Exchange[{}]创建成功:","hello-java-exchange");
}
// amqpadmin创建队列
@Test
public void testCreateQueue() {
// 注意这里的queue是ampq核心包中的queue
Queue queue = new Queue("hello-java-queue",true,false,false);
amqpAdmin.declareQueue(queue);
log.info("Queue[{}]创建成功:","hello-java-queue");
}
// amqpadmin可以创建绑定关系
@Test
public void createBinding() {
Binding binding = new Binding("hello-java-queue", // 目的地队列
Binding.DestinationType.QUEUE, // 对队列进行绑定 而不是对交换机进行绑定
"hello-java-exchange", // 用该交换机对队列进行绑定
"hello.java", // 路由键
null); // 参数
amqpAdmin.declareBinding(binding);
log.info("Binding[{}]创建成功:","hello-java-binding");
}
@Test
public void create() {
HashMap<String, Object> arguments = new HashMap<>();
arguments.put("x-dead-letter-exchange", "order-event-exchange");
arguments.put("x-dead-letter-routing-key", "order.release.order");
arguments.put("x-message-ttl", 60000); // 消息过期时间 1分钟
Queue queue = new Queue("order.delay.queue", true, false, false, arguments);
amqpAdmin.declareQueue(queue);
log.info("Queue[{}]创建成功:","order.delay.queue");
}
}
rabbitTemplate发送消息,使用注解接收消息
@RabbitListener可以加到方法上或者类上,加到方法上:要使用这个注解,要先在 启动类上加 @EnableRabbit注解
queues是需要监听的所有队列,可以一个或者多个
被绑定的方法的参数:
- Message message:原生消息详细信息 头+体
- T 发送消息的类型 消息体中的类型如果是T的话,用这个就可以自动转化并赋值
- Channel channel 当前传输数据的通道
Queue可以有多个人(方法)来监听,只要收到了消息,队列就会删除消息,而且只能有一个收到这个消息
只有一个消息完全处理完,方法运行结束,我们就可以接收到下一条消息
@RabbitListener(queues = {"hello-java-queue"})
public void revieveMessage(Message message,
OrderReturnReasonEntity content,
Channel channel) {
//拿到主体内容
byte[] body = message.getBody();
//拿到的消息头属性信息
MessageProperties messageProperties = message.getMessageProperties();
System.out.println("接受到的消息...内容" + message + "===内容:" + content);
}
@RabbitHanlder和@RabbitListener一起使用,@RabbitListener加在类上表明接受消息的队列,@RabbitHanlder加在方法上表明不同消息类型的重载,进入到不同的方法
@Service("orderItemService")
@RabbitListener(queues = {"hello-java-queue"})
public class OrderItemServiceImpl extends ServiceImpl<OrderItemDao, OrderItemEntity> implements OrderItemService {
@RabbitHanlder
public void revieveMessage(Message message,
OrderReturnReasonEntity content) {
//拿到主体内容
byte[] body = message.getBody();
//拿到的消息头属性信息
MessageProperties messageProperties = message.getMessageProperties();
System.out.println("接受到的消息...内容" + message + "===内容:" + content);
}
@RabbitHanlder
public void revieveMessage2(OrderEntity content) {
System.out.println("接受到的消息...内容" + message + "===内容:" + content);
}
}
RabbitMQ消息确认机制,
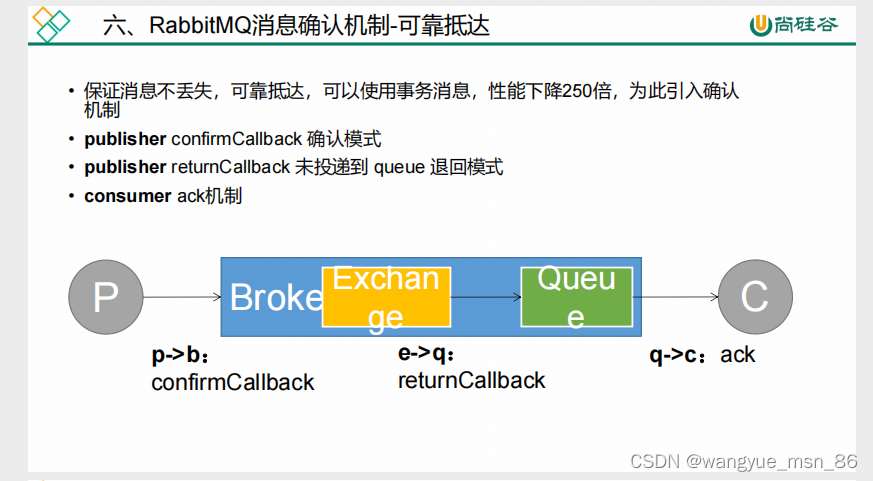
/**
* 定制RabbitTemplate
* 1、服务收到消息就会回调
* 1、要开启:spring.rabbitmq.publisher-confirms: true
* 2、设置确认回调
* 2、消息正确抵达队列就会进行回调
* 1、要开启:spring.rabbitmq.publisher-returns: true
* spring.rabbitmq.template.mandatory: true(这个不开也行)
* 2、设置确认回调ReturnCallback
*
* 3、消费端确认(保证每个消息都被正确消费,此时才可以broker删除这个消息)
*
*/
// @PostConstruct //MyRabbitConfig对象创建完成以后,执行这个方法
public void initRabbitTemplate() {
/**
* 1、只要消息抵达Broker就ack=true
* correlationData:当前消息的唯一关联数据(这个是消息的唯一id)
* ack:消息是否成功收到
* cause:失败的原因
*/
//设置确认回调
rabbitTemplate.setConfirmCallback((correlationData,ack,cause) -> {
System.out.println("confirm...correlationData["+correlationData+"]==>ack:["+ack+"]==>cause:["+cause+"]");
});
/**
* 只要消息没有投递给指定的队列,就触发这个失败回调
* message:投递失败的消息详细信息
* replyCode:回复的状态码
* replyText:回复的文本内容
* exchange:当时这个消息发给哪个交换机
* routingKey:当时这个消息用哪个路邮键
*/
rabbitTemplate.setReturnCallback((message,replyCode,replyText,exchange,routingKey) -> {
System.out.println("Fail Message["+message+"]==>replyCode["+replyCode+"]" +
"==>replyText["+replyText+"]==>exchange["+exchange+"]==>routingKey["+routingKey+"]");
});
}

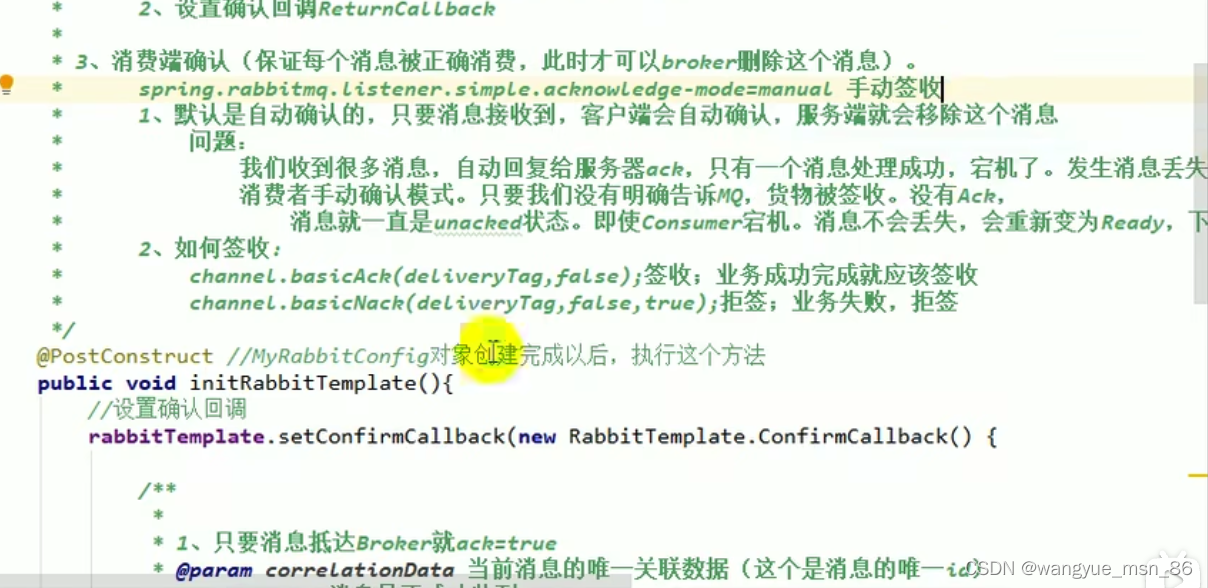
消息的TTL就是消息的存活时间。RabbitMQ可以对队列和消息分别设置TTL。对队列设置就是队列没有消费者连着的保留时间,也可以对每一个单独的消息做单独的 设置。超过了这个时间,我们认为这个消息就死了,称之为死信。如果队列设置了,消息也设置了,那么会取小的。所以一个消息如果被路由到不同的队 列中,这个消息死亡的时间有可能不一样(不同的队列设置)。这里单讲单个消息的TTL,因为它才是实现延迟任务的关键。可以通过设置消息的expiration字段或者x- message-ttl属性来设置时间,两者是一样的效果。
一个消息在满足如下条件下,会进死信路由,记住这里是路由而不是队列, 一个路由可以对应很多队列。(什么是死信)一个消息被Consumer拒收了,并且reject方法的参数里requeue是false。也就是说不 会被再次放在队列里,被其他消费者使用。(basic.reject/ basic.nack)requeue=false上面的消息的TTL到了,消息过期了。队列的长度限制满了。排在前面的消息会被丢弃或者扔到死信路由上Dead Letter Exchange其实就是一种普通的exchange,和创建其他exchange没有两样。只是在某一个设置Dead Letter Exchange的队列中有 消息过期了,会自动触发消息的转发,发送到Dead Letter Exchange中去。我们既可以控制消息在一段时间后变成死信,又可以控制变成死信的消息 被路由到某一个指定的交换机,结合二者,其实就可以实现一个延时队列
推荐方式:给队列设置300秒,就是五分钟的过期时间 x是一个普通的路由 ,发送消息到一个没人接收消息的队列中,这个红色的队列死去的消息不乱丢,而是给指定的交换机,也没人访问这个队列,所以有延时5分钟的效果。
生产者 》普通exchange 〉死信队列 》 死信路由 〉普通队列 》消费者
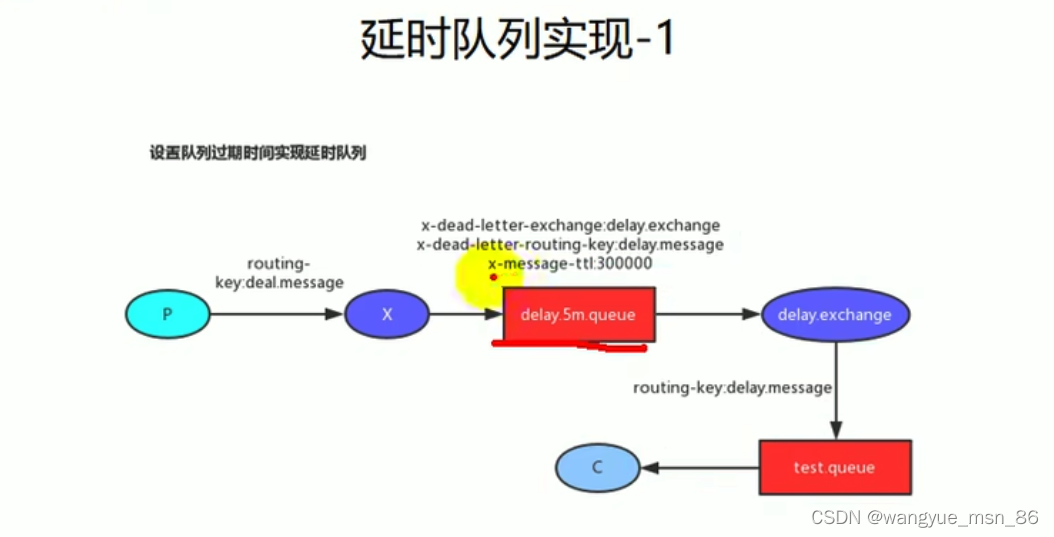
给消息设置不推荐,因为rabbitmq惰性加载,前面5s的没过期,就不会看后面1s的消息,而是再等5s
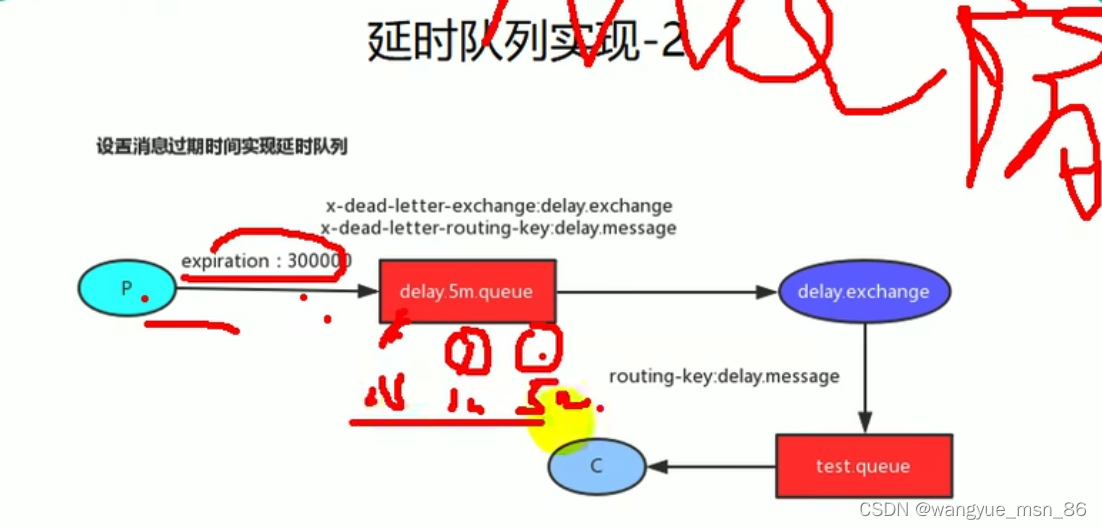
谷粒商城实现mq的方式:
复用了一个exchange,每个微服务一个exchange(topic类型的),死信队列消息死的时候,以另一个路由键再发给上面的exchange,然后再发给普通队列
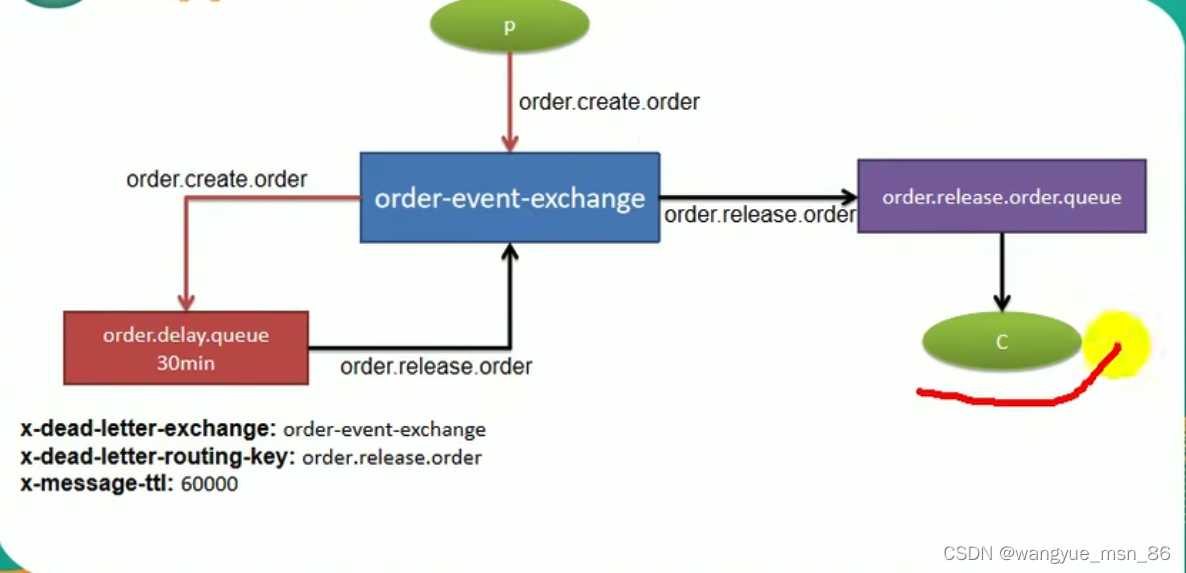
在order服务中的config文件中创建上述队列、交换机,使用@bean注入,使用spring的方式便捷的创建
@Configuration
public class MyRabbitMQConfig {
/* 容器中的Queue、Exchange、Binding 会自动创建(在RabbitMQ)不存在的情况下 */
/**
* 死信队列
*
* @return
*/@Bean
public Queue orderDelayQueue() {
/*
Queue(String name, 队列名字
boolean durable, 是否持久化
boolean exclusive, 是否排他
boolean autoDelete, 是否自动删除
Map<String, Object> arguments) 属性
*/
HashMap<String, Object> arguments = new HashMap<>();
// 这里设置这三个参数,指定这个队列是死信队列
arguments.put("x-dead-letter-exchange", "order-event-exchange");
arguments.put("x-dead-letter-routing-key", "order.release.order");
arguments.put("x-message-ttl", 60000); // 消息过期时间 1分钟
Queue queue = new Queue("order.delay.queue", true, false, false, arguments);
return queue;
}
/**
* 普通队列
*
* @return
*/
@Bean
public Queue orderReleaseQueue() {
Queue queue = new Queue("order.release.order.queue", true, false, false);
return queue;
}
/**
* TopicExchange
*
* @return
*/
@Bean
public Exchange orderEventExchange() {
/*
* String name,
* boolean durable,
* boolean autoDelete,
* Map<String, Object> arguments
* */
return new TopicExchange("order-event-exchange", true, false);
}
@Bean
public Binding orderCreateBinding() {
/*
* String destination, 目的地(队列名或者交换机名字)
* DestinationType destinationType, 目的地类型(Queue、Exhcange)
* String exchange,
* String routingKey,
* Map<String, Object> arguments
* */
return new Binding("order.delay.queue",
Binding.DestinationType.QUEUE,
"order-event-exchange",
"order.create.order",
null);
}
@Bean
public Binding orderReleaseBinding() {
return new Binding("order.release.order.queue",
Binding.DestinationType.QUEUE,
"order-event-exchange",
"order.release.order",
null);
}
/**
* 订单释放直接和库存释放进行绑定
* @return
*/
@Bean
public Binding orderReleaseOtherBinding() {
return new Binding("stock.release.stock.queue",
Binding.DestinationType.QUEUE,
"order-event-exchange",
"order.release.other.#",
null);
}
/**
* 商品秒杀队列
* @return
*/
@Bean
public Queue orderSecKillOrrderQueue() {
Queue queue = new Queue("order.seckill.order.queue", true, false, false);
return queue;
}
@Bean
public Binding orderSecKillOrrderQueueBinding() {
//String destination, DestinationType destinationType, String exchange, String routingKey,
// Map<String, Object> arguments
Binding binding = new Binding(
"order.seckill.order.queue",
Binding.DestinationType.QUEUE,
"order-event-exchange",
"order.seckill.order",
null);
return binding;-
}
}
谷粒商城mq设计:
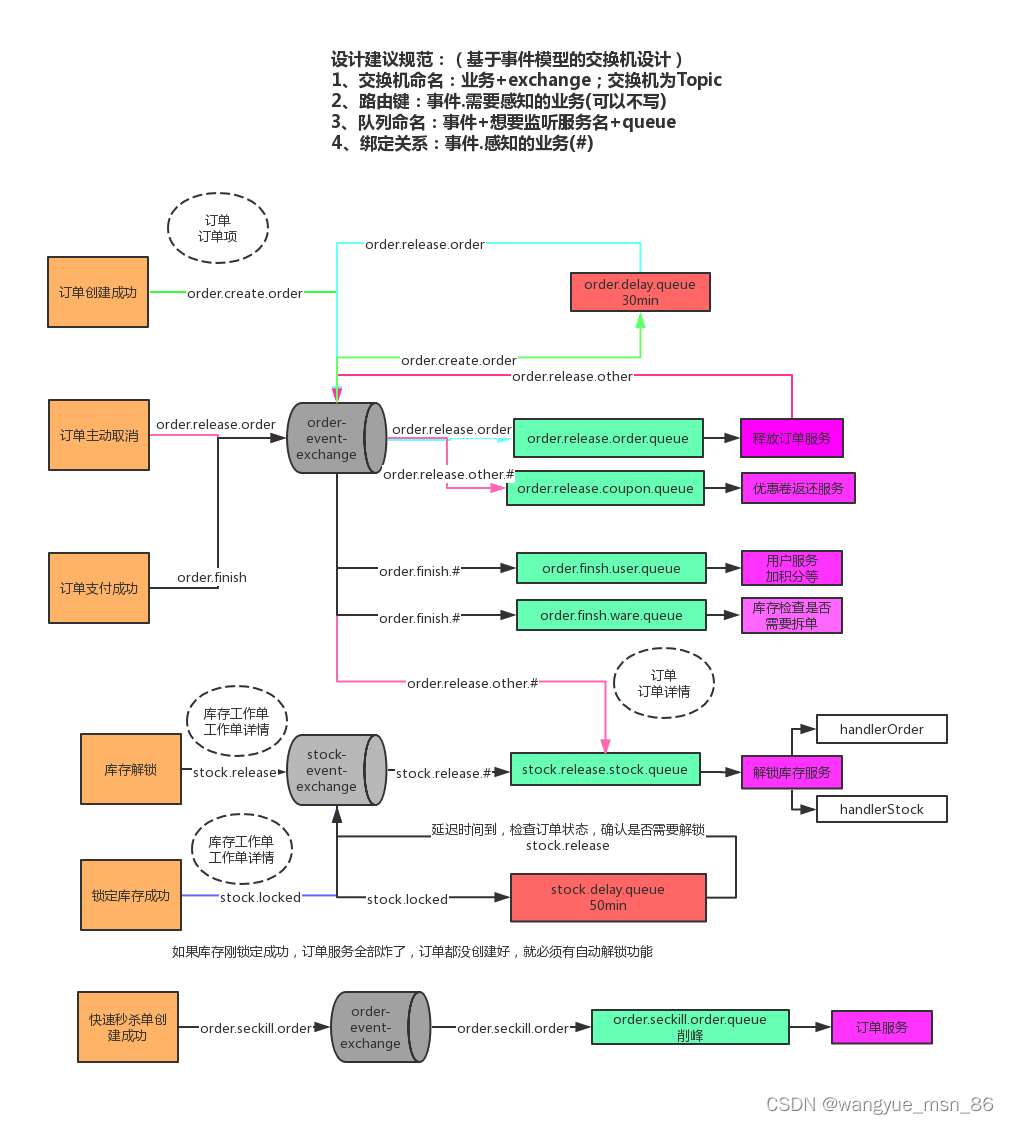
项目中怎么用到了Redis
本项目使用redis做了缓存,缓存了验证码、左侧目录的数据。
redis应用场景:
1.String
我用他缓存了终端信息(比如通道 IP地址 滚降系数 输出功率等等),以Json的格式进行缓存,cdma终端的信息。
常用指令
普通字符串的基本操作:
# 设置 key-value 类型的值
> SET name lin
OK
# 根据 key 获得对应的 value
> GET name
"lin"
# 判断某个 key 是否存在
> EXISTS name
(integer) 1
# 返回 key 所储存的字符串值的长度
> STRLEN name
(integer) 3
# 删除某个 key 对应的值
> DEL name
(integer) 1
批量设置 :
# 批量设置 key-value 类型的值
> MSET key1 value1 key2 value2
OK
# 批量获取多个 key 对应的 value
> MGET key1 key2
1) "value1"
2) "value2"
计数器(字符串的内容为整数的时候可以使用):
# 设置 key-value 类型的值
> SET number 0
OK
# 将 key 中储存的数字值增一
> INCR number
(integer) 1
# 将key中存储的数字值加 10
> INCRBY number 10
(integer) 11
# 将 key 中储存的数字值减一
> DECR number
(integer) 10
# 将key中存储的数字值键 10
> DECRBY number 10
(integer) 0
过期(默认为永不过期):
# 设置 key 在 60 秒后过期(该方法是针对已经存在的key设置过期时间)
> EXPIRE name 60
(integer) 1
# 查看数据还有多久过期
> TTL name
(integer) 51
#设置 key-value 类型的值,并设置该key的过期时间为 60 秒
> SET key value EX 60
OK
> SETEX key 60 value
OK
不存在就插入:
# 不存在就插入(not exists)
>SETNX key value
(integer) 1
缓存对象
使用 String 来缓存对象有两种方式:
- 直接缓存整个对象的 JSON,命令例子:
SET user:1 '{"name":"xiaolin", "age":18}'。 - 采用将 key 进行分离为 user:ID:属性,采用 MSET 存储,用 MGET 获取各属性值,命令例子:
MSET user:1:name xiaolin user:1:age 18 user:2:name xiaomei user:2:age 20。
常规计数
因为 Redis 处理命令是单线程,所以执行命令的过程是原子的。因此 String 数据类型适合计数场景,比如计算访问次数、点赞、转发、库存数量等等。
比如计算文章的阅读量:
# 初始化文章的阅读量
> SET aritcle:readcount:1001 0
OK
#阅读量+1
> INCR aritcle:readcount:1001
(integer) 1
#阅读量+1
> INCR aritcle:readcount:1001
(integer) 2
#阅读量+1
> INCR aritcle:readcount:1001
(integer) 3
# 获取对应文章的阅读量
> GET aritcle:readcount:1001
"3"
共享 Session 信息
通常我们在开发后台管理系统时,会使用 Session 来保存用户的会话(登录)状态,这些 Session 信息会被保存在服务器端,但这只适用于单系统应用,如果是分布式系统此模式将不再适用。
例如用户一的 Session 信息被存储在服务器一,但第二次访问时用户一被分配到服务器二,这个时候服务器并没有用户一的 Session 信息,就会出现需要重复登录的问题,问题在于分布式系统每次会把请求随机分配到不同的服务器。
2.hash
在介绍 String 类型的应用场景时有所介绍,String + Json也是存储对象的一种方式,那么存储对象时,到底用 String + json 还是用 Hash 呢?
一般对象用 String + Json 存储,对象中某些频繁变化的属性可以考虑抽出来用 Hash 类型存储。
String 的存储场景应用在频繁读操作,他的存储结构是json字符串。即把java对象转换为json。然后存入redis中。
Hash 的存储场景应用在频繁写的操作。即。当对象的某个属性频繁修改时,不适合用JSON+String的方式进行存储,因为不灵活,每次修改都要把整个对象转成JSON在进行存储。如果采用hash,就可以针对某个属性进行针对性的单独修改。不用序列化去修改整个对象,
结论:频繁读操作用string。频繁写入用hash
购物车
以用户 id 为 key,商品 id 为 field,商品数量为 value,恰好构成了购物车的3个要素,如下图所示。使用hash,增加商品数量比较简单,有商品id就可以直接增加,但是使用string就是要反复json转bean,bean转json
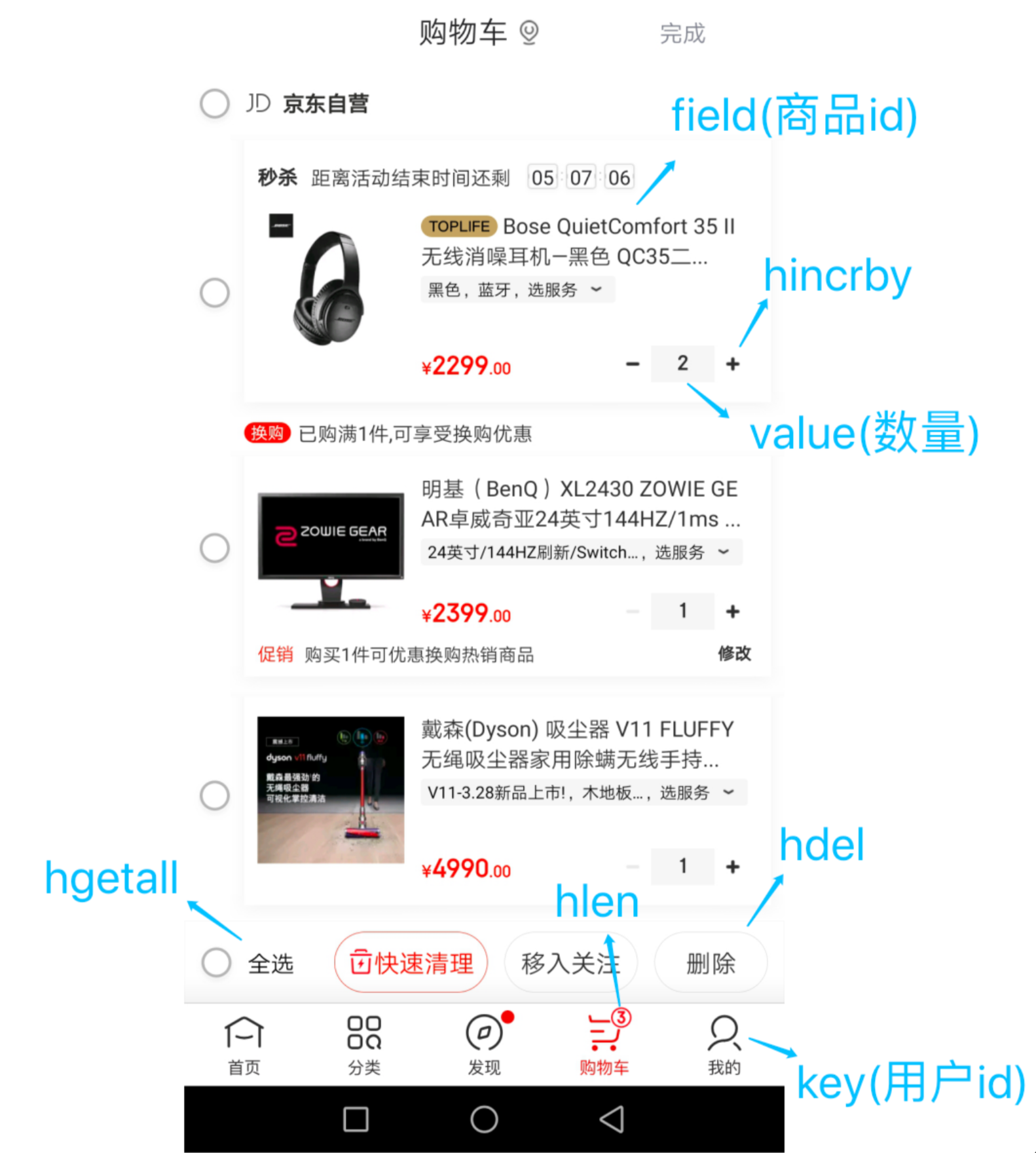
涉及的命令如下:
- 添加商品:
HSET cart:{用户id} {商品id} 1 - 添加数量:
HINCRBY cart:{用户id} {商品id} 1 - 商品总数:
HLEN cart:{用户id} - 删除商品:
HDEL cart:{用户id} {商品id} - 获取购物车所有商品:
HGETALL cart:{用户id}
当前仅仅是将商品ID存储到了Redis 中,在回显商品具体信息的时候,还需要拿着商品 id 查询一次数据库,获取完整的商品的信息。
双写一致性
什么是双写一致性?
如何保证:黑马点评,先操作数据库,后删除缓存。 只有在数据库改的时候需要考虑,读的时候不需要。
// 更新数据库的时候
@Override
@Transactional
public Result update(Shop shop) {
Long id = shop.getId();
if (id == null) {
return Result.fail("店铺id不能为空");
}
// 1.更新数据库
updateById(shop);
// 2.删除缓存
stringRedisTemplate.delete(CACHE_SHOP_KEY + id);
return Result.ok();
}
查的时候逻辑简单: 有了就从缓存拿,没了查数据库
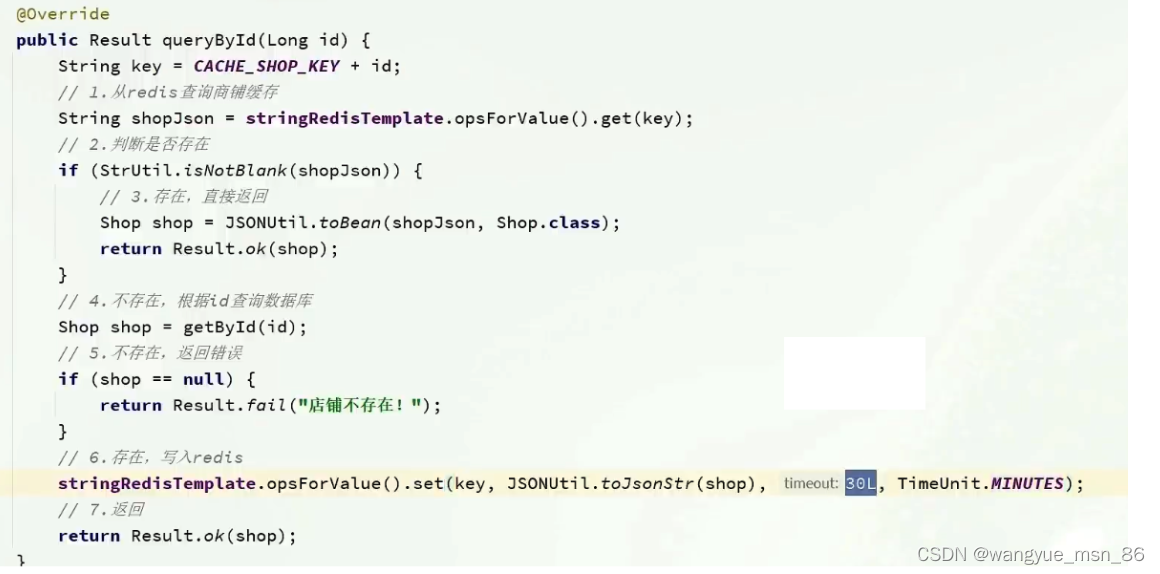
如何保证强一致性?
使用redssion读写锁,在写(更新操作的时候),给更新数据库和删除缓存操作增加一个写锁,读操作的时候,给整个过程加一个读锁。
保证最终一致性?
- 使用rabbitmq,在前面写的时候先操作数据库再删除缓存的方式已经解决了很多不一致问题,再加过期时间,出现不一致的情况就比较少了,因为操作数据库的时间比较长,写缓存的时间比较短。再加上有过期时间保证。但是如果删除缓存那一步没有执行,还是用的旧的数据,所以可以
Feign远程调用丢失
远程调用和自己在浏览器发不一样,如果不添加拦截器,就没有任何请求头,认为没登录就请求失败了。
添加拦截器
@Configuration
public class GuliFeignConfig {
@Bean("requestInterceptor")
public RequestInterceptor requestInterceptor() {
RequestInterceptor requestInterceptor = new RequestInterceptor() {
@Override
public void apply(RequestTemplate template) {
//1、使用RequestContextHolder拿到刚进来的请求数据
ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
if (requestAttributes != null) {
//老请求
HttpServletRequest request = requestAttributes.getRequest();
if (request != null) {
//2、同步请求头的数据(主要是cookie)
//把老请求的cookie值放到新请求上来,进行一个同步 原理是threadlocal 都在一个线程里
String cookie = request.getHeader("Cookie");
template.header("Cookie", cookie);
}
}
}
};
return requestInterceptor;
}
}
但是这里使用了异步,为了加快响应速度,多线程执行,还是丢失了,请求头,因为RequestContextHolder.getRequestAttributes使用threadlocal实现的,当你新开辟了两个线程,自然访问不到别的线程threadlocal里的东西了
//TODO :获取当前线程请求头信息(解决Feign异步调用丢失请求头问题)
RequestAttributes requestAttributes = RequestContextHolder.getRequestAttributes();
//开启第一个异步任务
CompletableFuture<Void> addressFuture = CompletableFuture.runAsync(() -> {
//每一个线程都来共享之前的请求数据
RequestContextHolder.setRequestAttributes(requestAttributes);
//1、远程查询所有的收获地址列表
List<MemberAddressVo> address = memberFeignService.getAddress(memberResponseVo.getId());
confirmVo.setMemberAddressVos(address);
}, threadPoolExecutor);。
//开启第二个异步任务
CompletableFuture<Void> cartInfoFuture = CompletableFuture.runAsync(() -> {
//每一个线程都来共享之前的请求数据
RequestContextHolder.setRequestAttributes(requestAttributes);
//2、远程查询购物车所有选中的购物项
List<OrderItemVo> currentCartItems = cartFeignService.getCurrentCartItems();
confirmVo.setItems(currentCartItems);
//feign在远程调用之前要构造请求,调用很多的拦截器
}
在每个线程里都加上这个数据RequestContextHolder.setRequestAttributes(requestAttributes);
接口幂等性
在谷粒商城提交订单时,如果网速慢,用户点了好几下,不能让订单重复在数据库中创建,幂等性的意思就是点了几次和点了一次的效果是相等的。
谷粒商城解决接口幂等性的方法,使用防重令牌
token 机制
1、服务端提供了发送 token 的接口。我们在分析业务的时候,哪些业务是存在幂等问题的,
就必须在执行业务前,先去获取 token,服务器会把 token 保存到 redis 中。
2、然后调用业务接口请求时,把 token 携带过去,一般放在请求头部。
3、服务器判断 token 是否存在 redis 中,存在表示第一次请求,然后删除 token,继续执行业 务。
4、如果判断 token 不存在 redis 中,就表示是重复操作,直接返回重复标记给 client,这样 就保证了业务代码,不被重复执行。
使用lua脚本保证令牌验证和删除的原子性
这个token是唯一的,用uuid生成的,如果是第二次提交token的值不一样
重点:谷粒商城解决流程,下订单按钮解决幂等性:
- 下订单按钮是订单确认页的一个按钮,在进入这个页面的时候调用了confirmOrder方法,不止返回订单确认页的基本信息,最后还给他生成了一个token,用来防重复下单用,往redis里存一个,再给前端返回一个
- 这样点按钮下单的时候,前端的信息就带着token来了,后端的VO类接受以后就可以get到这个token,如果页面刷新,token也是会刷新的。
- 如果页面不刷新的情况,连点好几下,那么只有第一下会生效,可以用分布式锁,也可以是lua脚本保证redis get 比较前端和redis token,删除token的原子性,保证了他的原子性在这就能保证防止重复提交。如果没有原子性也不加分布式锁,那么可以两个Java线程同时判断对比成功,同时下单成功。但是如果加了lua脚本,因为Redis是单线程的,所以第二个lua脚本一定等第一个执行完了才执行,所以可以保证
/**
* 订单确认页返回需要用的数据
* @return
*/
@Override
public OrderConfirmVo confirmOrder() throws ExecutionException, InterruptedException {
//构建OrderConfirmVo
OrderConfirmVo confirmVo = new OrderConfirmVo();
//获取当前用户登录的信息
MemberResponseVo memberResponseVo = LoginUserInterceptor.loginUser.get();
//TODO :获取当前线程请求头信息(解决Feign异步调用丢失请求头问题)
RequestAttributes requestAttributes = RequestContextHolder.getRequestAttributes();
//开启第一个异步任务
CompletableFuture<Void> addressFuture = CompletableFuture.runAsync(() -> {
//每一个线程都来共享之前的请求数据
RequestContextHolder.setRequestAttributes(requestAttributes);
//1、远程查询所有的收获地址列表
List<MemberAddressVo> address = memberFeignService.getAddress(memberResponseVo.getId());
confirmVo.setMemberAddressVos(address);
}, threadPoolExecutor);
//开启第二个异步任务
CompletableFuture<Void> cartInfoFuture = CompletableFuture.runAsync(() -> {
//每一个线程都来共享之前的请求数据
RequestContextHolder.setRequestAttributes(requestAttributes);
//2、远程查询购物车所有选中的购物项
List<OrderItemVo> currentCartItems = cartFeignService.getCurrentCartItems();
confirmVo.setItems(currentCartItems);
//feign在远程调用之前要构造请求,调用很多的拦截器
}, threadPoolExecutor).thenRunAsync(() -> {
List<OrderItemVo> items = confirmVo.getItems();
//获取全部商品的id
List<Long> skuIds = items.stream()
.map((itemVo -> itemVo.getSkuId()))
.collect(Collectors.toList());
//远程查询商品库存信息
R skuHasStock = wmsFeignService.getSkuHasStock(skuIds);
List<SkuStockVo> skuStockVos = skuHasStock.getData("data", new TypeReference<List<SkuStockVo>>() {});
if (skuStockVos != null && skuStockVos.size() > 0) {
//将skuStockVos集合转换为map
Map<Long, Boolean> skuHasStockMap = skuStockVos.stream().collect(Collectors.toMap(SkuStockVo::getSkuId, SkuStockVo::getHasStock));
confirmVo.setStocks(skuHasStockMap);
}
},threadPoolExecutor);
//3、查询用户积分
Integer integration = memberResponseVo.getIntegration();
confirmVo.setIntegration(integration);
//4、价格数据自动计算
//TODO 5、防重令牌(防止表单重复提交)
//为用户设置一个token,三十分钟过期时间(存在redis)
String token = UUID.randomUUID().toString().replace("-", "");
redisTemplate.opsForValue().set(USER_ORDER_TOKEN_PREFIX+memberResponseVo.getId(),token,30, TimeUnit.MINUTES);
confirmVo.setOrderToken(token);
CompletableFuture.allOf(addressFuture,cartInfoFuture).get();
return confirmVo;
}
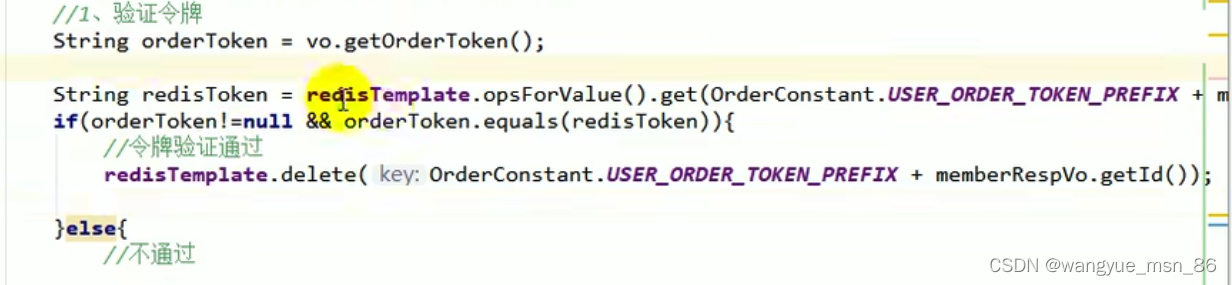
//1、验证令牌是否合法【令牌的对比和删除必须保证原子性】
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
String orderToken = vo.getOrderToken();
//通过lua脚本原子验证令牌和删除令牌 返回值不是0就是1 0是失败
Long result = redisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class),
Arrays.asList(USER_ORDER_TOKEN_PREFIX + memberResponseVo.getId()),
orderToken);
if (result == 0L) {
//令牌验证失败
responseVo.setCode(1);
return responseVo;
} else {
//令牌验证成功
//1、创建订单、订单项等信息
OrderCreateTo order = createOrder();
分布式事务
本地事务失效的解决方案:问题用Transactional注解,如果a想调用b,c的话,还想让b,c的事务生效,比较麻烦,因为直接调用b,c调用的不是代理类的代码,直接复制了本类的代码,Transactional是通过AOP来实现的。如果给自己的类注入自己那么就会有循环依赖的问题。(这个目前好像有问题,给自己的类注入自己好像不会有循环依赖)
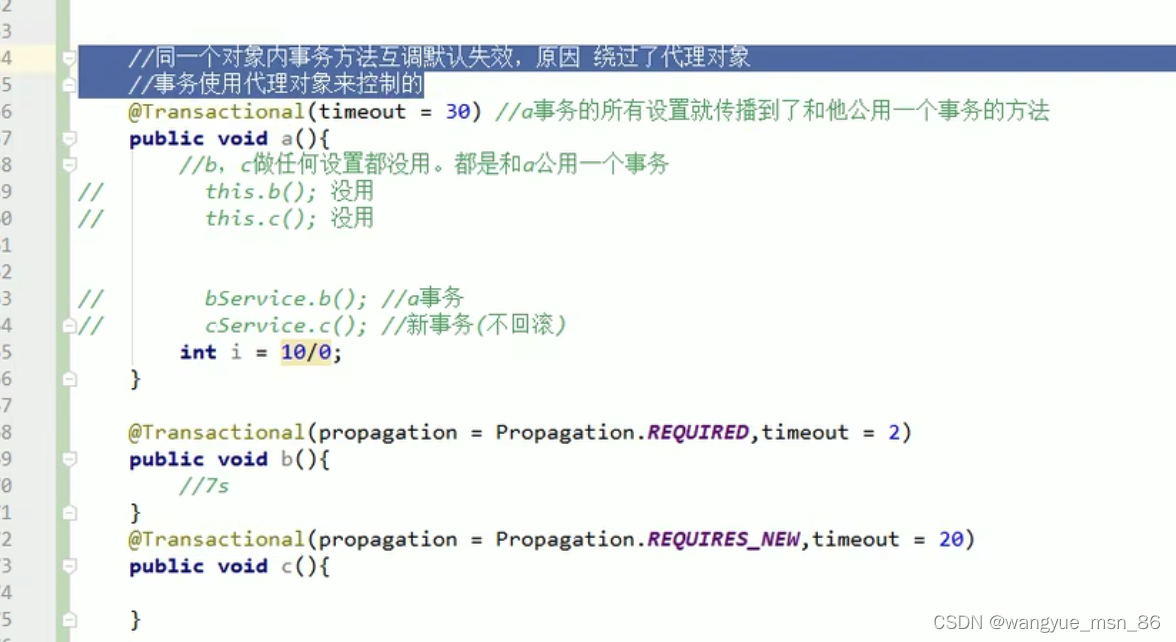
解决方案:引入aspectj,通过aop上下文拿到本类代理对象,然后调用

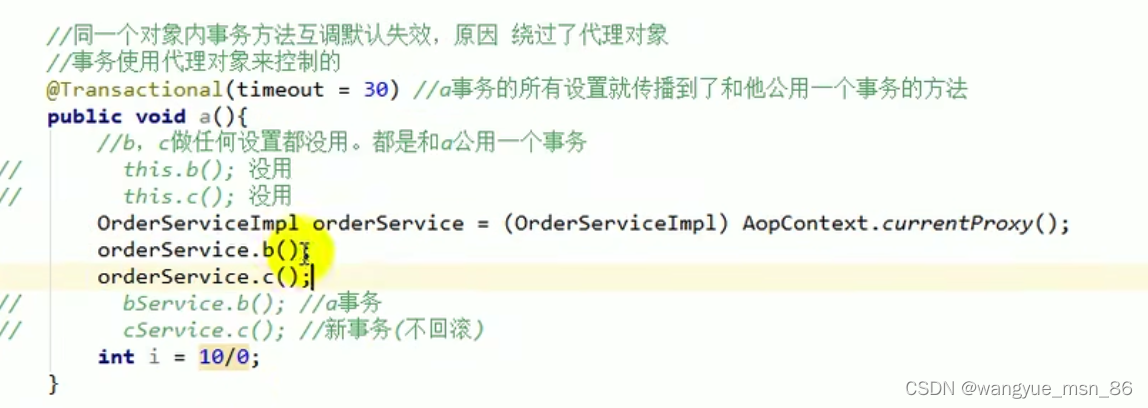
分布式事务:感知不到别的服务的网络状态,例如订单模块锁库存的时候,库存那边成功了,但是网络问题,返回的是失败的结果,订单回滚了,但是库存却没有回滚。
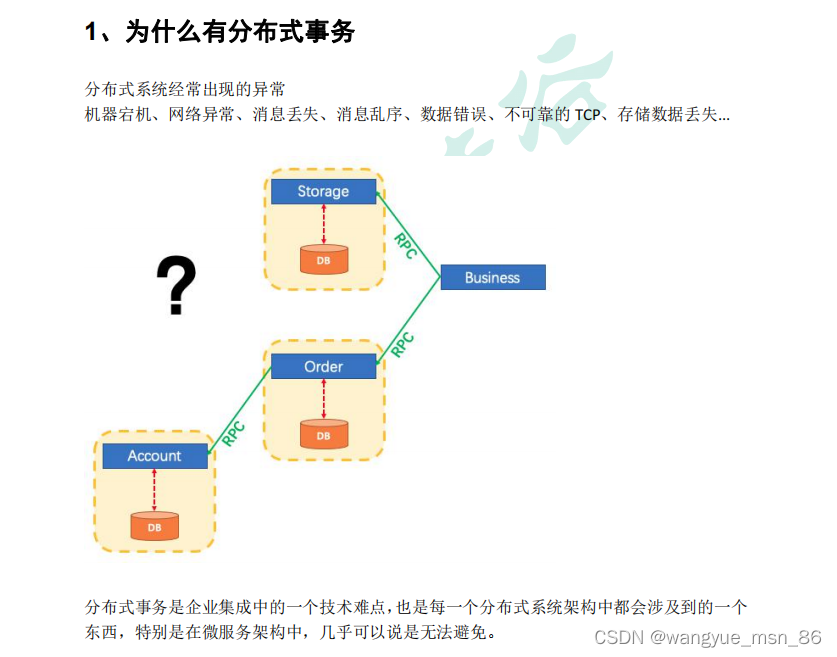
分布式CAP定理和BASE定理
- 一致性:跟事务那个差不多,保证的是分布式系统各个结点的值是一致的,是新数据就都是新数据,是旧数据就都是旧数据
- 可用性:集群整体是否还能响应,是集群整体的可用性
- 分区容错:主要讲的是网络通信的问题,不同结点通信的时候网络可能会出现故障
三者最多同时实现两者,网络通信在所难免,也必须解决,所以P必须保证,所以你的系统就是在AP和CP中去选。
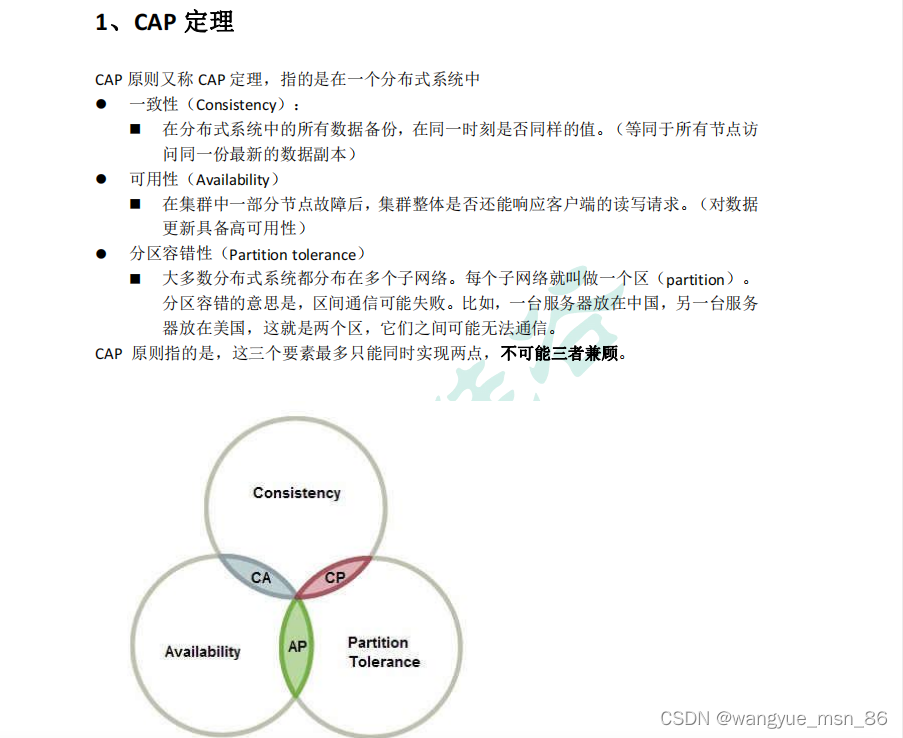
一般来说,分区容错无法避免,因此可以认为 CAP 的 P 总是成立。CAP 定理告诉我们,
剩下的 C 和 A 无法同时做到。
分布式系统中实现一致性的 raft 算法、paxos
http://thesecretlivesofdata.com/raft/
谷粒商城举例:现在有123三个结点,1,3之间的网络通信断了。如果保证了可用性,访问3的时候就保证不了一致,如果想一致就得把3给去掉,这样3就不可用了。
对于多数大型互联网应用的场景,主机众多、部署分散,而且现在的集群规模越来越大,所
以节点故障、网络故障是常态,而且要保证服务可用性达到 99.99999%(N 个 9),即保证
P 和 A,舍弃 C。
Base定理:

分布式事务的四种解决方案:
1.2PC
两阶段提交,就像司仪问新郎新娘愿不愿意嫁给对方,都yes以后,两个人再提交,有一个no,让两个人都回滚
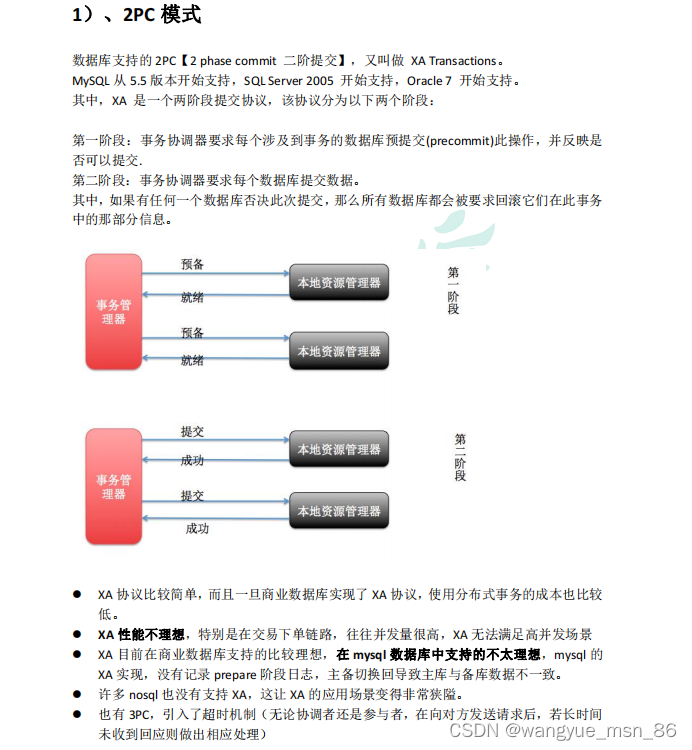
2.TCC
三阶段提交的手动版,由开发者写三段代码 try confirm cancel 由框架决定执行哪一部分
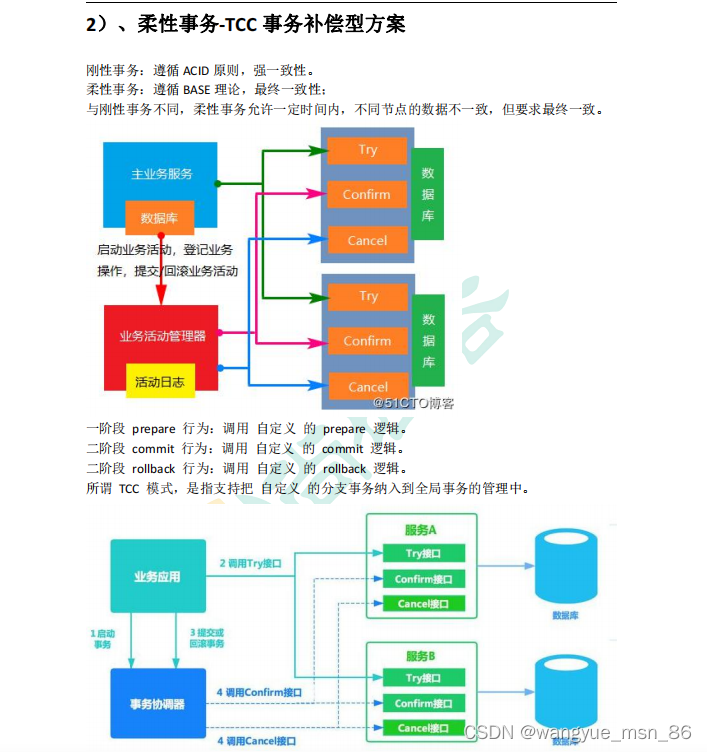
- 最大努力通知型

- 最终一致性方案

分布式事务组件seata
seata的at模式示例:at模式全称叫自动事务提交。改良版的两阶段事务提交。TC代表中间管理者的角色,TM代表大事务,比如需要多个远程调用的一个方法,RM是小事务,比如各个远程调用接口的代码。TCC方式是手动去写的,比如try confirm 和cancel,cancel的时候,比如提交把字段值加2,cancel就要把字段值减2.但是at模式是自动的,需要在每个数据库中加一个回滚(undolog)表。默认使用的就是at模式
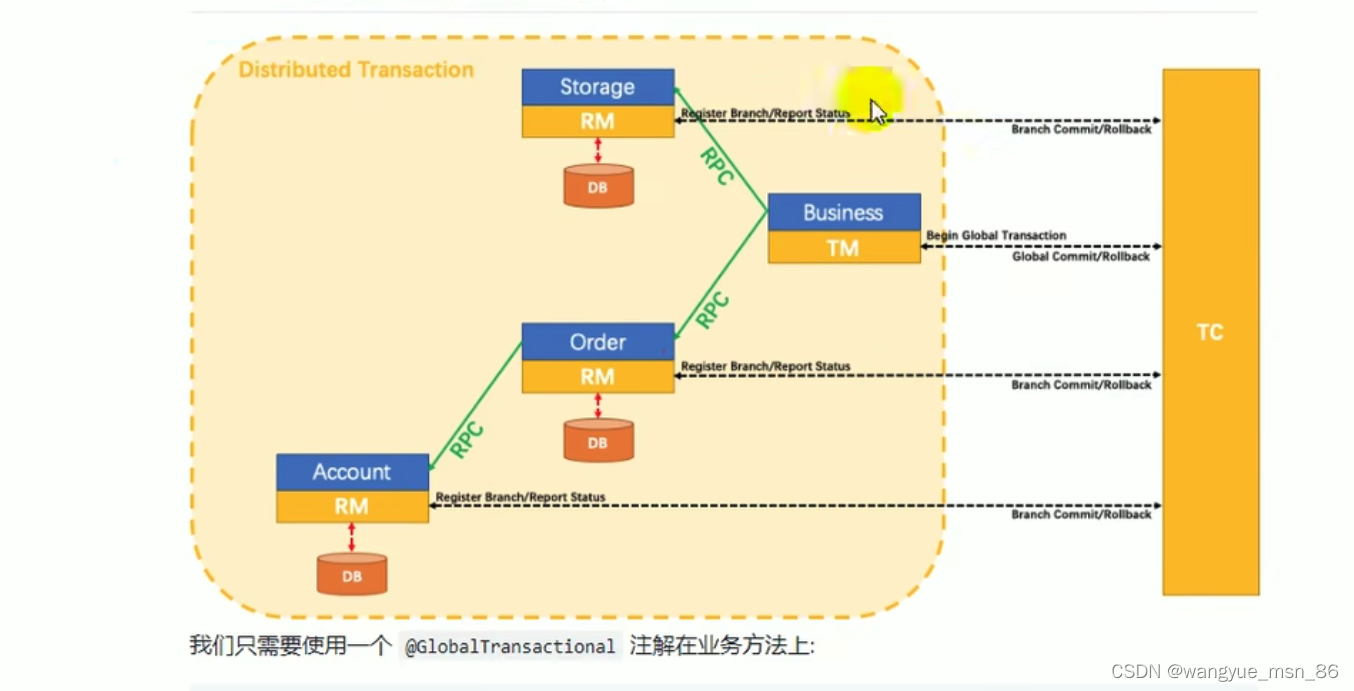
undolog表,在提交前先记录下原来的数据,以便于以后回滚
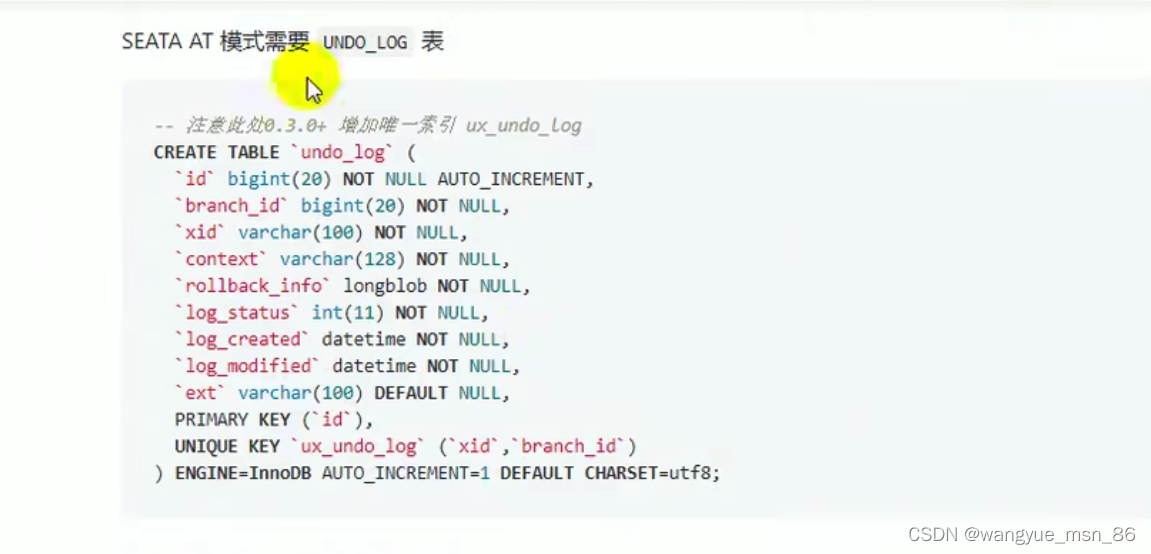
谷粒商城代码:
如果不用seata,扣库存后,方法发生异常,本方法会回滚,但是远程的库存不会回滚。
使用seata,默认at模式,使用@GlobalTransactional即可,标准当前事务是个大事务。
使用seata的配置流程:
但是这里不能使用at模式,因为at模式是基于两阶段提交的方式的改进,性能很差。不适合高并发的场景,适合后台管理系统等并发量较小的场景。
所以使用第四种事务提交方式:最终一致性方案
Seata控制分布式事务
* 1)、每一个微服务必须创建undo_Log
* 2)、安装事务协调器:seate-server
* 3)、整合
* 1、导入依赖
* 2、解压并启动seata-server:
* registry.conf:注册中心配置 修改 registry : nacos
* 3、所有想要用到分布式事务的微服务使用seata DataSourceProxy 代理自己的数据源
* 4、每个微服务,都必须导入 registry.conf file.conf
* vgroup_mapping.{application.name}-fescar-server-group = "default"
* 5、启动测试分布式事务
* 6、给分布式大事务的入口标注@GlobalTransactional(大事务也要使用小事务注解@Transactional)
* 7、每一个远程的小事务用@Transactional
/**
* 提交订单
* @param vo
* @return
*/
// @Transactional(isolation = Isolation.READ_COMMITTED) 设置事务的隔离级别
// @Transactional(propagation = Propagation.REQUIRED) 设置事务的传播级别
@Transactional(rollbackFor = Exception.class)
// @GlobalTransactional(rollbackFor = Exception.class)
@Override
public SubmitOrderResponseVo submitOrder(OrderSubmitVo vo) {
confirmVoThreadLocal.set(vo);
SubmitOrderResponseVo responseVo = new SubmitOrderResponseVo();
//去创建、下订单、验令牌、验价格、锁定库存...
//获取当前用户登录的信息
MemberResponseVo memberResponseVo = LoginUserInterceptor.loginUser.get();
responseVo.setCode(0);
//1、验证令牌是否合法【令牌的对比和删除必须保证原子性】
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
String orderToken = vo.getOrderToken();
//通过lua脚本原子验证令牌和删除令牌
Long result = redisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class),
Arrays.asList(USER_ORDER_TOKEN_PREFIX + memberResponseVo.getId()),
orderToken);
if (result == 0L) {
//令牌验证失败
responseVo.setCode(1);
return responseVo;
} else {
//令牌验证成功
//1、创建订单、订单项等信息
OrderCreateTo order = createOrder();
//2、验证价格
BigDecimal payAmount = order.getOrder().getPayAmount();
BigDecimal payPrice = vo.getPayPrice();
if (Math.abs(payAmount.subtract(payPrice).doubleValue()) < 0.01) {
//金额对比
//TODO 3、保存订单
saveOrder(order);
//4、库存锁定,只要有异常,回滚订单数据
//订单号、所有订单项信息(skuId,skuNum,skuName)
WareSkuLockVo lockVo = new WareSkuLockVo();
lockVo.setOrderSn(order.getOrder().getOrderSn());
//获取出要锁定的商品数据信息
List<OrderItemVo> orderItemVos = order.getOrderItems().stream().map((item) -> {
OrderItemVo orderItemVo = new OrderItemVo();
orderItemVo.setSkuId(item.getSkuId());
orderItemVo.setCount(item.getSkuQuantity());
orderItemVo.setTitle(item.getSkuName());
return orderItemVo;
}).collect(Collectors.toList());
lockVo.setLocks(orderItemVos);
//TODO 调用远程锁定库存的方法
//出现的问题:扣减库存成功了,但是由于网络原因超时,出现异常,导致订单事务回滚,库存事务不回滚(解决方案:seata)
//为了保证高并发,不推荐使用seata,因为是加锁,并行化,提升不了效率,可以发消息给库存服务
R r = wmsFeignService.orderLockStock(lockVo);
if (r.getCode() == 0) {
//锁定成功
responseVo.setOrder(order.getOrder());
// int i = 10/0;
//TODO 订单创建成功,发送消息给MQ
rabbitTemplate.convertAndSend("order-event-exchange","order.create.order",order.getOrder());
//删除购物车里的数据
redisTemplate.delete(CART_PREFIX+memberResponseVo.getId());
return responseVo;
} else {
//锁定失败
String msg = (String) r.get("msg");
throw new NoStockException(msg);
// responseVo.setCode(3);
// return responseVo;
}
} else {
responseVo.setCode(2);
return responseVo;
}
}
}
你们项目如何采集日志的?
ELK或者按天保存到一个日志文件。
在linux系统,可以通过tail命令看日志,默认后10行
- tail -f -n 300 filename (查看底部即最新300条日志记录,并实时刷新)
我们是用的常规采集方式,使用tail查看日志文件
我们也做了日志管理模块,可以查看异常日志信息
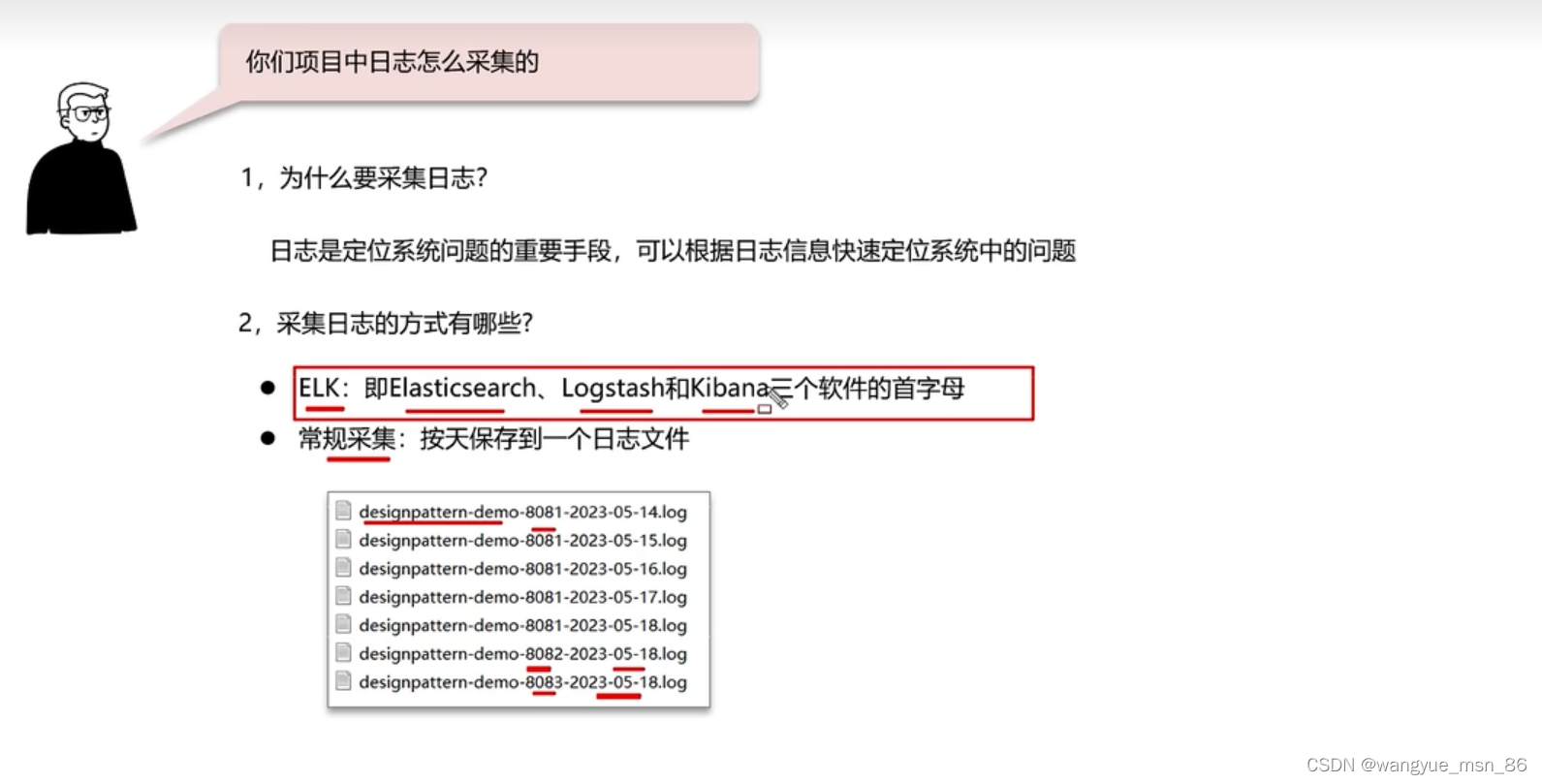
ELK:收集、存储、可视化展示
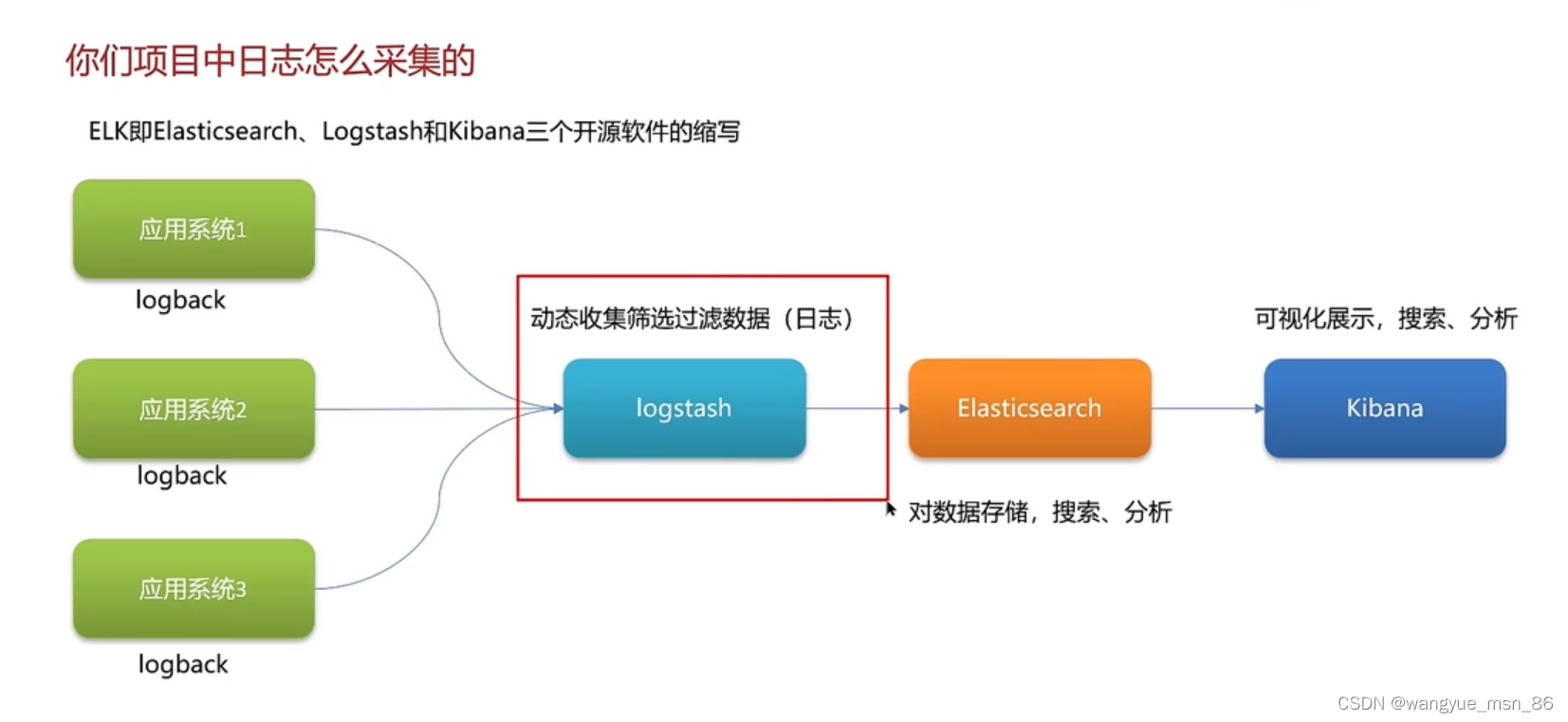
谷粒商城秒杀笔记
spring定时任务@Scheduled默认是阻塞的,线程池里就一个线程,执行一个就不能执行别的定时任务了,使用springboot提供的异步任务,使用springboot的线程池完成,需要 @EnableAsync和 @Async注解
@Slf4j
@Component
@EnableAsync
@EnableScheduling
public class HelloScheduled {
/**
* 1、在Spring中表达式是6位组成,不允许第七位的年份
* 2、在周几的的位置,1-7代表周一到周日
* 3、定时任务不该阻塞。默认是阻塞的
* 1)、可以让业务以异步的方式,自己提交到线程池
* CompletableFuture.runAsync(() -> {
* },execute);
*
* 2)、支持定时任务线程池;设置 TaskSchedulingProperties
* spring.task.scheduling.pool.size: 5
*
* 3)、让定时任务异步执行
* 异步任务
*
* 解决:使用异步任务 + 定时任务来完成定时任务不阻塞的功能
*
*/
@Async
@Scheduled(cron = "*/5 * * ? * 4")
public void hello() {
log.info("hello...");
try { TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) { e.printStackTrace(); }
}
}
秒杀流程:没有走数据库,秒杀商品提前上架,redis信号量代表库存,下单成功直接给用户结果,MQ异步处理

/**
* 当前商品进行秒杀(秒杀开始)
* @param killId
* @param key
* @param num
* @return
*/
@Override
public String kill(String killId, String key, Integer num) throws InterruptedException {
long s1 = System.currentTimeMillis();
//获取当前用户的信息
MemberResponseVo user = LoginUserInterceptor.loginUser.get();
//1、获取当前秒杀商品的详细信息从Redis中获取
BoundHashOperations<String, String, String> hashOps = redisTemplate.boundHashOps(SECKILL_CHARE_PREFIX);
String skuInfoValue = hashOps.get(killId);
if (StringUtils.isEmpty(skuInfoValue)) {
return null;
}
//(合法性效验)
SeckillSkuRedisTo redisTo = JSON.parseObject(skuInfoValue, SeckillSkuRedisTo.class);
Long startTime = redisTo.getStartTime();
Long endTime = redisTo.getEndTime();
long currentTime = System.currentTimeMillis();
//判断当前这个秒杀请求是否在活动时间区间内(效验时间的合法性)
if (currentTime >= startTime && currentTime <= endTime) {
//2、效验随机码和商品id
String randomCode = redisTo.getRandomCode();
String skuId = redisTo.getPromotionSessionId() + "-" +redisTo.getSkuId();
if (randomCode.equals(key) && killId.equals(skuId)) {
//3、验证购物数量是否合理和库存量是否充足
Integer seckillLimit = redisTo.getSeckillLimit();
//获取信号量
String seckillCount = redisTemplate.opsForValue().get(SKU_STOCK_SEMAPHORE + randomCode);
Integer count = Integer.valueOf(seckillCount);
//判断信号量是否大于0,并且买的数量不能超过库存
if (count > 0 && num <= seckillLimit && count > num ) {
//4、验证这个人是否已经买过了(幂等性处理),如果秒杀成功,就去占位。userId-sessionId-skuId
//SETNX 原子性处理
String redisKey = user.getId() + "-" + skuId;
//设置自动过期(活动结束时间-当前时间)
Long ttl = endTime - currentTime;
Boolean aBoolean = redisTemplate.opsForValue().setIfAbsent(redisKey, num.toString(), ttl, TimeUnit.MILLISECONDS);
if (aBoolean) {
//占位成功说明从来没有买过,分布式锁(获取信号量-1)
RSemaphore semaphore = redissonClient.getSemaphore(SKU_STOCK_SEMAPHORE + randomCode);
//TODO 秒杀成功,快速下单
boolean semaphoreCount = semaphore.tryAcquire(num, 100, TimeUnit.MILLISECONDS);
//保证Redis中还有商品库存
if (semaphoreCount) {
//创建订单号和订单信息发送给MQ
// 秒杀成功 快速下单 发送消息到 MQ 整个操作时间在 10ms 左右
String timeId = IdWorker.getTimeId();
SeckillOrderTo orderTo = new SeckillOrderTo();
orderTo.setOrderSn(timeId);
orderTo.setMemberId(user.getId());
orderTo.setNum(num);
orderTo.setPromotionSessionId(redisTo.getPromotionSessionId());
orderTo.setSkuId(redisTo.getSkuId());
orderTo.setSeckillPrice(redisTo.getSeckillPrice());
rabbitTemplate.convertAndSend("order-event-exchange","order.seckill.order",orderTo);
long s2 = System.currentTimeMillis();
log.info("耗时..." + (s2 - s1));
return timeId;
}
}
}
}
}
long s3 = System.currentTimeMillis();
log.info("耗时..." + (s3 - s1));
return null;
}
就一个队列:削峰用 订单服务来监听: 避免大量请求同时进来影响订单服务

得物一面:
- 接口幂等性怎么做的 toekn redis lua 前端按钮置灰
- new 一个对象 jvm是怎么做的 没答好
- sychonized如何实现的
- hotspot虚拟机的组成部分
- 字符串拼接的时候用什么拼
- 实现100的阶乘,如何优化
- 5个小sql
hotspot虚拟机:
- 类加载器(ClassLoader):负责将类的字节码加载到内存中,并转换为可以执行的类对象。类加载器按照一定的加载顺序来加载类,包括启动类加载器、扩展类加载器和应用程序类加载器。
- 运行时数据区(Runtime Data Areas):包括堆、栈、方法区等内存区域,用于存储程序在运行时所需的数据和信息。其中,堆用于存储对象实例,栈用于保存方法调用的局部变量和方法调用栈帧,方法区用于存储类的结构信息、常量池等。
- 即时编译器(Just-In-Time Compiler,JIT):负责将字节码转换为与特定硬件平台相关的本地机器码,以提高程序的执行效率。HotSpot 虚拟机中的即时编译器包括客户端编译器(C1)和服务端编译器(C2),根据代码的执行热度和优化级别选择合适的编译策略。
- 垃圾回收器(Garbage Collector):负责自动管理堆内存中不再使用的对象的回收。HotSpot 虚拟机中提供了多种垃圾回收器算法,例如新生代和老年代的分代回收、并行回收、并发回收等。
- 即时编译器和垃圾回收器接口:即时编译器和垃圾回收器之间存在一定的协作关系,它们通过共享的运行时数据区等机制来实现优化和内存管理。
当在 Java 中使用 new 关键字创建一个对象时,JVM(Java 虚拟机)会执行以下操作:
- 类加载:首先,JVM会检查该对象的类是否已被加载。如果尚未加载,则JVM通过类加载器加载该类的字节码信息,并将其转换为运行时的类对象。
- 分配内存:一旦类加载完成,JVM会计算出对象所需的内存大小,并在堆中分配足够的内存空间来存储对象的实例变量。
- 初始化:在分配内存后,JVM会对对象的实例变量进行初始化,即设置默认值(如0、null等)或使用构造函数进行初始化。
- 设置对象头:JVM会在对象的内存空间中添加一个对象头,用于存储一些额外的信息,如对象的哈希码、锁信息等。
- 执行构造函数:在对象的内存空间分配和初始化完成后,JVM会调用对象的构造函数,执行构造函数的代码逻辑,对对象进行进一步的初始化。
- 返回对象引用:当构造函数执行完毕后,JVM会将对象的引用返回给程序,以便后续对该对象进行访问和操作。
需要注意的是,具体的对象创建过程可能受到JIT(即时编译器)的影响。在JIT的优化下,JVM可能会对对象的分配和初始化过程进行优化,如栈上分配、逃逸分析等。
总结起来,当在 Java 中使用 new 关键字创建对象时,JVM会依次进行类加载、内存分配、初始化、设置对象头、构造函数执行等步骤,并最终返回对象的引用给程序使用。这个过程保证了对象的正确创建和初始化。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}