







一.SpringBatch概述
SpringBatch主要是一个轻量级的大数据量的并行处理(批处理)的框架。
作用和Hadoop很相似,不过Hadoop是基于重量级的分布式环境(处理巨量数据),而SpringBatch是基于轻量的应用框架(处理中小数据)。
旨在帮助企业建立健壮、高效的批处理应用。Spring Batch是Spring的一个子项目,使用Java语言并基于Spring框架为基础开发,使得已经使用Spring框架的开发者或者企业更容易访问和利用企业服务。
Spring Batch提供了大量可重用的组件,包括了日志追踪、事务、任务作业统计、任务重启、跳过、重复资源管理。对于大数据量和高性能的批处理任 务,Spring Batch同样提供了高级功能和特性来支持比如分区功能、远程功能。总之,通过Spring Batch能够支持简单的、复杂的和大数据量的批处理作业。
Spring Batch是一个批处理应用框架,不是调度框架,但需要和调度框架合作来构建完成的批处理任务。它只关注批处理任务相关的问题,如事务、并发、监控、执行等,并不提供相应的调度功能。如果需要使用调用框架,在商业软件和开源软件中已经有很多优秀的企业级调度框架(如Quartz. Tivoli、 Control-M、 Cron等)可以使用。
框架主要有以下功能: Transaction management (事务管理) Chunk based processing (基于块的处理) Declarative 1/0 (声明式的输入输出) Start/Stop/Restart (启动/停止/再启动) Retry/Skip (重试/跳过)
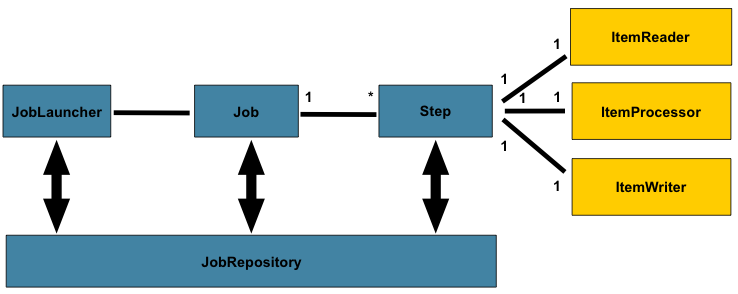
Spring Batch主要包含以下核心概念和组件:
Job:代表着一个具体的任务,一个可以被执行的批业务逻辑。
Step:一个Job中独立的一个小步骤,代表着一个具体的步骤,一个Job可以包含多个Step (想象把大象放进冰箱这个任务需要多少个步骤你就明白了) 。
ExecutionContext:每次Job或者Step执行时,都会创建该对象保存这次执行的上下文状态。
ItemReader:用于读取相应的数据。
ItemProcessor:用于处理ItemReader读取出来的数据并进行相应的业务处理。
ItemWriter: 用于将ItemProcessor处理好后的数据写入到目标存储位置。
JobLauncher是任务启动器,通过它来启动任务,可以看做是程序的入口。
JobRepository是存储数据的地方,可以看做是一个数据库的接口,在任务执行的时候需要通过它来记录任务状态等等信息。
SpringBatch的业务场景有:
- 周期性的提交批处理
- 把一个任务并行处理
- 消息驱动应用分级处理
- 大规模并行批处理
- 手工或调度使用任务失败之后重新启动
- 有依赖步骤的顺序执行(使用工作流驱动扩展)
- 处理时跳过部分记录
- 成批事务:为小批量的或有的存储过程/脚本的场景使用
- 开箱即用组件包括各种资源的读、写。读/写:支持文本文件读/写、XML文件读/写、数据库读/写、JMS队列读/写等。
二.SpringBatch入门程序
这里使用SpringBatch做了一个能跑的最简单例子,进行描述SpringBatch的基本作用。
如果需要进行深入学习,请详细参考阅读 Spring Batch - Reference Documentation ;英文不好的同学,请和我一样右键(翻译成中文查看)。
1 . 新建项目springboot-batch,基本的pom.xml依赖 :
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>name.ealen</groupId>
<artifactId>springboot-batch</artifactId>
<version>1.0</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.1.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>
</project>2 . 你需要在数据库中建立springbatch的相关元数据表,所以你需要在数据库中执行如下来自官方元数据模式的脚本。
-- do not edit this file
-- BATCH JOB 实例表 包含与aJobInstance相关的所有信息
-- JOB ID由batch_job_seq分配
-- JOB 名称,与spring配置一致
-- JOB KEY 对job参数的MD5编码,正因为有这个字段的存在,同一个job如果第一次运行成功,第二次再运行会抛出JobInstanceAlreadyCompleteException异常。
CREATE TABLE BATCH_JOB_INSTANCE (
JOB_INSTANCE_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT ,
JOB_NAME VARCHAR(100) NOT NULL,
JOB_KEY VARCHAR(32) NOT NULL,
constraint JOB_INST_UN unique (JOB_NAME, JOB_KEY)
) ENGINE=InnoDB;
-- 该BATCH_JOB_EXECUTION表包含与该JobExecution对象相关的所有信息
CREATE TABLE BATCH_JOB_EXECUTION (
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT ,
JOB_INSTANCE_ID BIGINT NOT NULL,
CREATE_TIME DATETIME NOT NULL,
START_TIME DATETIME DEFAULT NULL ,
END_TIME DATETIME DEFAULT NULL ,
STATUS VARCHAR(10) ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED DATETIME,
JOB_CONFIGURATION_LOCATION VARCHAR(2500) NULL,
constraint JOB_INST_EXEC_FK foreign key (JOB_INSTANCE_ID)
references BATCH_JOB_INSTANCE(JOB_INSTANCE_ID)
) ENGINE=InnoDB;
-- 该表包含与该JobParameters对象相关的所有信息
CREATE TABLE BATCH_JOB_EXECUTION_PARAMS (
JOB_EXECUTION_ID BIGINT NOT NULL ,
TYPE_CD VARCHAR(6) NOT NULL ,
KEY_NAME VARCHAR(100) NOT NULL ,
STRING_VAL VARCHAR(250) ,
DATE_VAL DATETIME DEFAULT NULL ,
LONG_VAL BIGINT ,
DOUBLE_VAL DOUBLE PRECISION ,
IDENTIFYING CHAR(1) NOT NULL ,
constraint JOB_EXEC_PARAMS_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
-- 该表包含与该StepExecution 对象相关的所有信息
CREATE TABLE BATCH_STEP_EXECUTION (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT NOT NULL,
STEP_NAME VARCHAR(100) NOT NULL,
JOB_EXECUTION_ID BIGINT NOT NULL,
START_TIME DATETIME NOT NULL ,
END_TIME DATETIME DEFAULT NULL ,
STATUS VARCHAR(10) ,
COMMIT_COUNT BIGINT ,
READ_COUNT BIGINT ,
FILTER_COUNT BIGINT ,
WRITE_COUNT BIGINT ,
READ_SKIP_COUNT BIGINT ,
WRITE_SKIP_COUNT BIGINT ,
PROCESS_SKIP_COUNT BIGINT ,
ROLLBACK_COUNT BIGINT ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED DATETIME,
constraint JOB_EXEC_STEP_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
-- 该BATCH_STEP_EXECUTION_CONTEXT表包含ExecutionContext与Step相关的所有信息
CREATE TABLE BATCH_STEP_EXECUTION_CONTEXT (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT ,
constraint STEP_EXEC_CTX_FK foreign key (STEP_EXECUTION_ID)
references BATCH_STEP_EXECUTION(STEP_EXECUTION_ID)
) ENGINE=InnoDB;
-- 该表包含ExecutionContext与Job相关的所有信息
CREATE TABLE BATCH_JOB_EXECUTION_CONTEXT (
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT ,
constraint JOB_EXEC_CTX_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_STEP_EXECUTION_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_STEP_EXECUTION_SEQ);
CREATE TABLE BATCH_JOB_EXECUTION_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_JOB_EXECUTION_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_JOB_EXECUTION_SEQ);
CREATE TABLE BATCH_JOB_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_JOB_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_JOB_SEQ);
3、编辑配置文件,这里要使用mysql数据库,任务信息持久化到数据库中
spring:
datasource:
use 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2183
2183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









