




 本文深入讲解了爬虫的概念、分类及应用,详细介绍了robot协议与HTTP协议,包括端口号、URL解析、请求与响应过程,适合初学者入门。
本文深入讲解了爬虫的概念、分类及应用,详细介绍了robot协议与HTTP协议,包括端口号、URL解析、请求与响应过程,适合初学者入门。

文章目录
一、在做爬虫之前我们首先需要知道爬虫是什么?
- 概念:一个可以自动抓取互联网上信息的脚本。
- 解决的问题:
- ①解决网站创立之初的冷启动问题;
- ②做搜索引擎少不了爬虫,爬虫是搜索引擎的根基。例如百度搜索引擎;
- ③建立知识图谱,帮助建立机器学习知识图谱;
- ④可以制作各种商品的比价软件,趋势分析;
二、爬虫的分类
- 通用网络爬虫 :关键字获取既定的目标 覆盖率很大(百度 谷歌 雅虎…搜索引擎)
- 聚焦网络爬虫 :到互联网上有选择有目的去抓取特定的目标和相关的主要内容增量网络爬虫
- 增量式网络爬虫 :只采取增量式更新或者只爬行新产生或者是已经发生变化的网页
- 深层网络爬虫 :深层 大部分内容是可以通过静态链接获取到的,隐藏在搜索表单之后的一些数据有可能需要用户提交一些关键词才可以获得的WEB页面
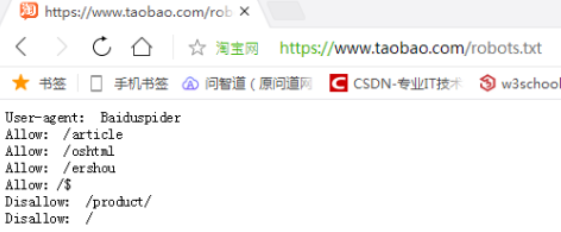
三、robot协议
作为一个守法的公民,我们一定要遵守互联网的规则!因此我么需要遵守robot协议(网址后+robots.txt)。该协议可以告诉搜索引擎哪里可以爬,哪里不可以爬。
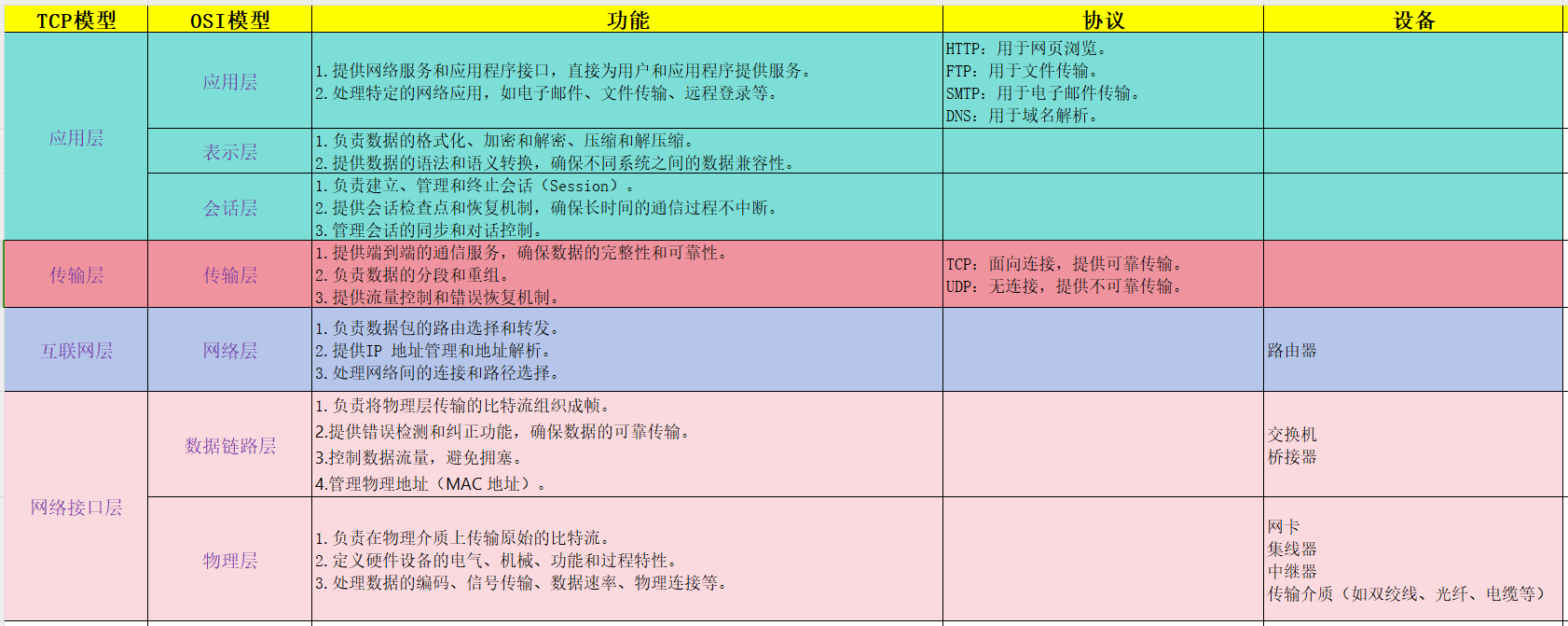
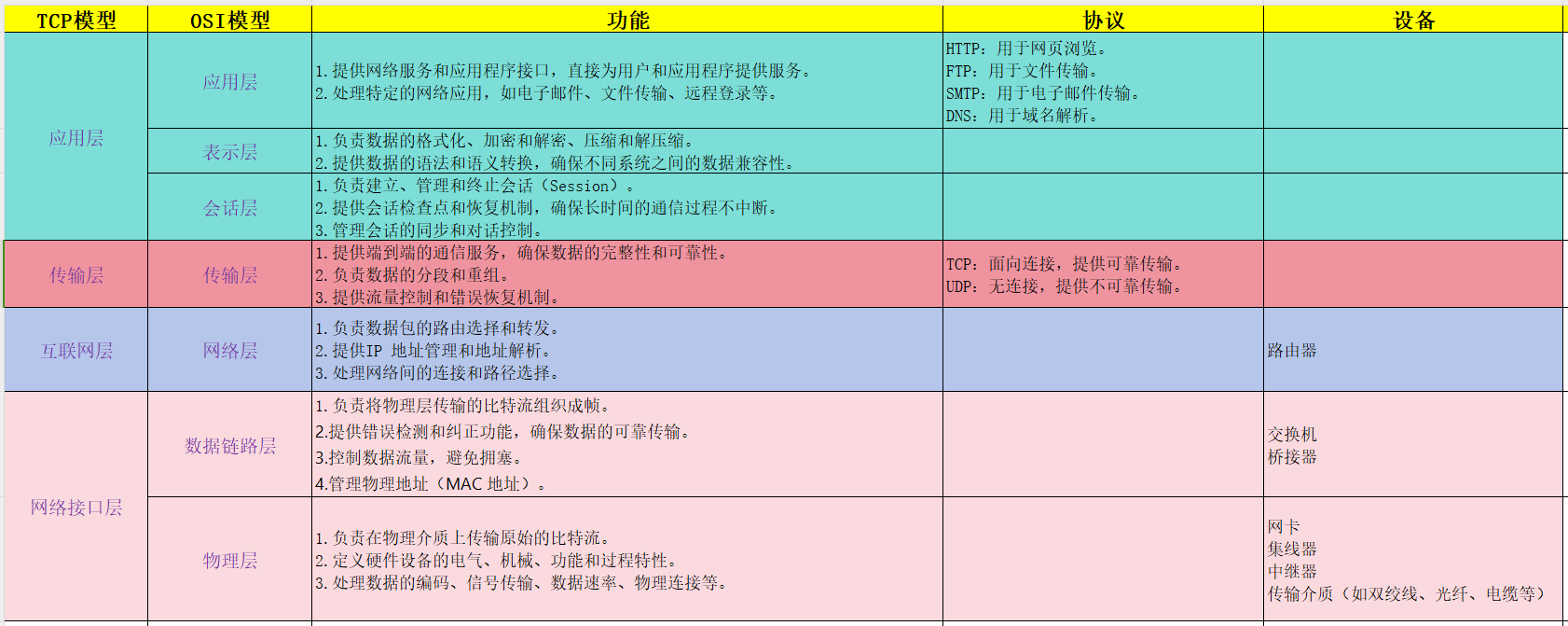
四、网络七层模型
五、HTTP协议
1.网络七层协议
网络七层协议,也称为OSI模型,用于描述网络系统之间的通信过程。OSI 模型将网络通信过程分为七个层次,每一层都有特定的功能和协议。虽然 OSI 模型是一个理想的参考模型,但在实际应用中,TCP/IP 模型更为广泛使用。
2.http协议
HTTP超文本传输协议是用于在互联网上进行数据通信的基础协议。它定义了客户端和服务器之间如何传输超文本信息。
| 特点 | 描述 |
|---|---|
| 简单易用 | 设计简单,易于实现和使用,客户端和服务器通过简单的请求和响应消息进行通信。 |
| 无状态 | 每个请求都是独立的,与之前的请求没有直接关系,服务器不保留客户端的状态信息。 |
| 灵活性 | 可以传输任意类型的数据,通过 MIME 类型支持文本、图像、视频、音频等各种文件。 |
| 可扩展性 | 具有良好的可扩展性,可以通过添加新的方法、头字段和状态码来扩展功能。 |
| 应用层协议 | 位于 OSI 模型的第七层,依赖传输层协议(如 TCP)提供可靠的数据传输。 |
| 请求-响应模型 | 采用请求-响应模型,客户端发送请求消息,服务器返回响应消息。 |
| 支持多种请求方法 | 支持 GET、POST、PUT、DELETE、HEAD、OPTIONS、PATCH 等多种请求方法。 |
| 支持持久连接 | HTTP/1.1 引入持久连接,允许在一个 TCP 连接上发送多个请求和响应,减少连接开销。 |
| 支持缓存 | 支持缓存机制,通过 Cache-Control、Expires、ETag、Last-Modified 等头字段控制缓存。 |
| 支持内容协商 | 允许客户端和服务器根据请求头字段协商返回的资源表示形式,如 Accept、Accept-Language 等。 |
| 安全性 | HTTP 本身是明文传输的,HTTPS 在 HTTP 和传输层安全(TLS)之间添加加密层,确保数据安全。 |
| 支持虚拟主机 | HTTP/1.1 支持虚拟主机,通过 Host 头字段允许在同一台服务器上托管多个网站。 |
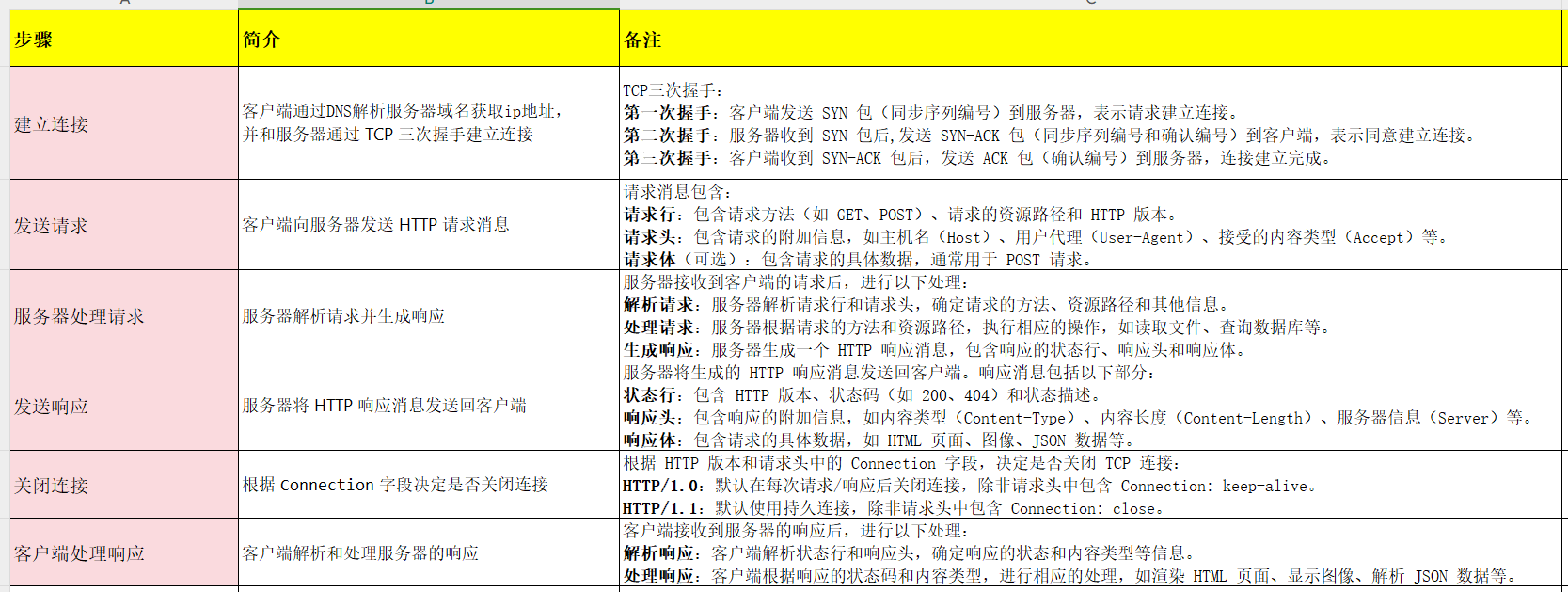
3.http工作过程
4.http协议和https协议的区别
| 特点 | HTTP 协议 | HTTPS 协议 |
|---|---|---|
| 安全性 | 传输数据是明文的,不加密,容易被窃听和篡改。 | 传输数据是加密的,使用 SSL/TLS 协议对数据进行加密,提供更高的安全性。 |
| 数据传输 | 使用 TCP/IP 进行数据传输。 | 使用 SSL/TLS 在 HTTP 上进行加密,然后再使用 TCP/IP 进行数据传输。 |
| 默认端口 | 80 | 443 |
| 证书 | 不需要证书。 | 需要使用数字证书,由可信的证书颁发机构(CA)签发,用于验证服务器的身份。 |
| 连接方式 | 无状态连接,每个请求都是独立的,服务器不保留客户端的状态信息。 | 无状态连接,每个请求都是独立的,服务器不保留客户端的状态信息。 |
| 性能 | 传输速度较快,不需要进行加密和解密操作。 | 传输速度较慢,需要进行加密和解密操作,会增加一定的延迟。 |
| SEO | 不利于搜索引擎优化,搜索引擎难以抓取和索引页面内容。 | 有利于搜索引擎优化,搜索引擎可以更好地抓取和索引页面内容。 |
| 使用场景 | 适用于不需要保密性和完整性的场景,如普通网页浏览、静态资源获取等。 | 适用于需要保密性和完整性的场景,如在线支付、用户登录、敏感数据传输等。 |
5.关于响应常见的响应码
| 状态码 | 意义 | 常见举例1 | 常见举例2 |
|---|---|---|---|
| 1xx | 表示服务器成功接收部分请求,要求客户端继续提交其余请求才能完成整个处理过程 | 100 :服务器仅接收到部分请求,但是一旦服务器并没有拒绝该请求,客户端应该继续发送其余的请求 | 101 :服务器将遵从客户的请求转换到另外一种协议 |
| 2xx | 表示服务器成功接收请求并已完成整个处理过程 | 200:OK 请求成功 | 201 :请求被创建完成,同时新的资源被创建 |
| 3xx | 重定向 | 302:所请求的页面已经临时转移至新的url | 303 :所请求的页面可在别的url下被找到 |
| 4xx | 客户端错误 | 403:对被请求页面的访问被禁止 | 404:服务器无法找到被请求的页面 |
| 5xx | 服务器错误 | 500:请求未完成。服务器遇到不可预知的情况 | 504 :网关超时。 |
6.客户端请求中get和post区别
| 特点 | GET 方法 | POST 方法 |
|---|---|---|
| 参数传递方式 | 参数通过 URL 传递,通常在 URL 的查询字符串部分(?后面)。 | 参数通过请求体传递,不显示在 URL 中。 |
| 数据长度限制 | URL 的长度有限制(通常为 2048 个字符),因此 GET 请求的数据量较小。 | 请求体没有长度限制,可以传递大量数据。 |
| 安全性 | 参数暴露在 URL 中,容易被窃取和篡改,不适合传递敏感信息。 | 参数在请求体中,不直接暴露在 URL 中,相对更安全,适合传递敏感信息。 |
| 缓存 | GET 请求可以被浏览器缓存,适用于获取不变的数据。 | POST 请求不会被浏览器缓存,适用于提交数据或执行操作。 |
| 幂等性 | GET 请求是幂等的,多次请求对资源的状态没有影响。 | POST 请求不是幂等的,多次请求可能会导致资源状态的变化(如多次提交表单)。 |
| 可见性 | 参数在 URL 中可见,容易被记录在浏览器历史、书签和日志中。 | 参数在请求体中不可见,不会被记录在浏览器历史、书签和日志中。 |
| 使用场景 | 适用于获取资源或数据,如网页内容、静态资源等。 | 适用于提交数据或执行操作,如表单提交、文件上传等。 |
| 请求示例 | GET /search?q=example HTTP/1.1 | POST /submit-form HTTP/1.1 |
| 请求体 | 无请求体。 | 包含请求体,传递具体数据。 |
7.常见的请求头和响应头
常见的请求头
User-Agent:客户端请求标识。
Accept: 传输文件类型。
Referer :请求来源。
cookie (cookie):在做登录的时候需要封装这个头。
Content-Type (POST数据类型)
常见的响应头
Content-Type:text/html;资源文件的类型,还有字符编码
Content-Length:响应长度
Content-Size响应大小
Content-Encoding告诉客户端,服务端发送的资源是采用什么编码的。
Connection:keep-alive这个字段作为回应客户端的Connection:keep-alive,告诉客户端服务器的tcp连接也是一个长连接,客户端可以继续使用这个tcp连接发送http请求




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











