







索引的底层原理(四)
索引常见问题
-
我们要给区分度比较高的字段添加索引,有些字段可能就几个取值,那这样构建的二级索引树的分叉就比较少,那利用二级索引树查询效率的提升就不明显了,而且如果通过索引过滤出来的数据和整表搜索的数据量差不多,那么MySQL Server就会优化不使用索引。
-
如果查询条件有多个字段,其中部分建立了索引,就比如 a=1 AND b=2 AND c=3, a和b分别有单独的索引,那么需要注意一张表的一次SQL查询只能用到一个索引,到底用哪个,就要看使用哪个索引过滤出来的数据少,哪个过滤出来的数据少就使用哪个索引。
-
我们也可以指定使用某个索引
select * from xxx FORCE INDEX(索引名) where ...;
-
对于内连接查询来说,通过两张表的相同字段(比如uid)进行关联(on),并且需要根据数据量来区分大小表(这里注意有时候我们不能很直观的判断哪个是大表,哪个是小表,因为执行where过滤条件会过滤掉表中的一些数据),在小表上进行整表扫描,取出所有uid,然后拿着这些uid到大表上进行搜索,所以要在大表上建立索引,基于B+索引树进行搜索,所以说==小表决定循环的次数,而大表决定每次循环的查询时间==。
-
关于like、not in 、or能否用到索引
select * from student where name lke 'zhangsan%';// 可以用到索引,可以拿'zhangsan'进行前缀匹配
select * from student where name lke '%zhangsan%';// 不能用到索引,无法拿%zhangsan%进行搜索
// 尽管Mysql Server可以把not in(20)解释成age<20 or age>20,然后在二级索引树上进行范围搜索,但是select后面跟的是*,这意味着范围搜索后还要进行回表操作,所以Mysql server认为不如直接进行整表搜索,优化成不使用索引
select * from student where age not in(20);
// select 后面是age(主键uid应该也可以),这样就不用涉及回表操作,MySQL Server就会使用索引
select age from student where age not in(20);
从上面的几个例子,我们知道like、not in 、or到底能否用到索引,还是要看具体的情况。
- where后面涉及类型强转、使用Mysql函数都用不上索引
// 根据password建立二级索引树,应该拿password值去搜索,md5转换后的值无法在索引树上进行搜索,所以用不到索引
select ... where md5(password)='xxx';
// mobile字段是char类型,而13451235161是整型,所以会涉及整型到char型的类型强转,无法用到索引
select ... where mobile=13451235161;
select * from student where age<20 or name='linfeng';
// 上面的SQL语句会被Mysql Server优化成
select * from student where age<20 union all select * from student where name='linfeng';
// union all 两边的select都可以用到索引,但是实际用没用到索引,决定权依然在mysql server上,如果过滤出来的数据量和整表数据量接近(也不一定是接近,占到几成),那MySQL server也不会去使用索引
慢查询日志
虽然我们知道使用explain可以分析SQL语句的执行,但是要知道一个实际的项目中包含很多业务,使用到的SQL语句甚至能够达到上千、上万条,所以使用explain语句一句一句分析过去是不现实的,**正确的流程应该是:我们能否从什么地方获取那些运行时间长,耗性能的sql,然后再用explain去分析它呢? **
慢查询日志:slow_query_log
MySQL可以设置慢查询日志,当SQL执行的时间超过我们设定的时间,那么这些SQL就会被记录在慢查询日志中,然后我们通过查看日志,使用explain分析这些SQL的执行计划,来判断为什么效率低下,是没有使用到索引?还是索引本身的创建有问题? 或者是索引使用了,但是由于表的数据量太大,花费的时间就是很长,那么此时我们可以把表分成n个小表,比如订单表按年份分成多个小表等。
-
慢查询日志相关的参数如下所示:
show variables like '%slow_query%';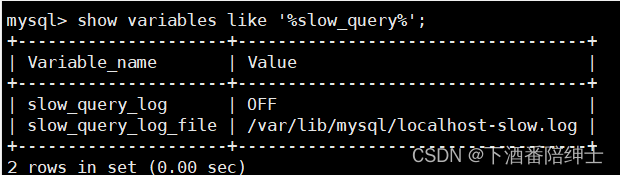
这里可以看到慢查询日志默认是没有打开的
-
打开慢查询日志
// slow_query_log这个变量是作用于全局的,而不是某个会话,所以要加上global set global slow_query_log = ON;查看慢查询日志是否打开了:
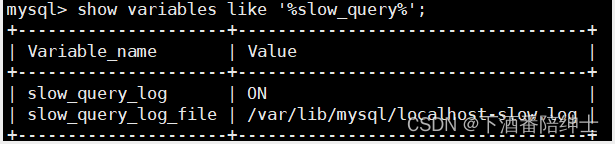
-
查看以及设置合理的慢查询时间
// 查看慢查询时间,单位是s show variables like 'long_query%'; // 设置慢查询时间为0.1s,long_query_time并不作用于全局,仅作用于当前会话 set long_query_time=0.1;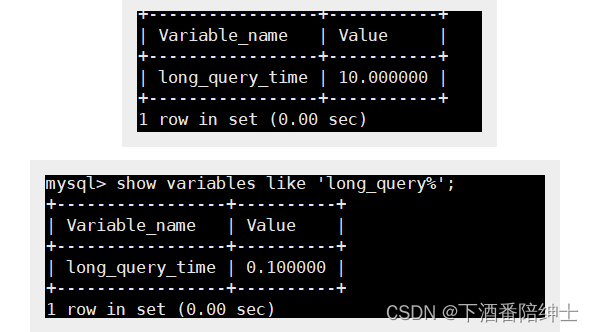
-
慢查询日志的文件路径:
/var/lib/mysql/localhost-slow.log看一下日志记录的信息:
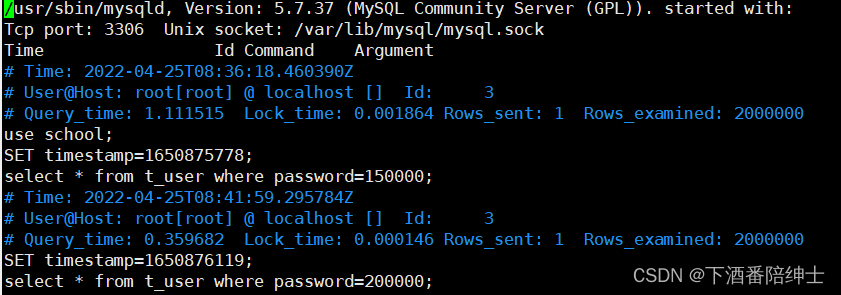
我们可以看到语句执行的时间 Query_time,也可以看到是哪些语句执行时间超过了我们设置的慢查询时间
-
结合慢查询日志的记录,我们可以使用explain来分析这些执行超时的语句的执行过程

发现没有使用到password上的索引,检查后发现是因为类型强转,所以我们修改SQL语句后,查询时使用上索引:
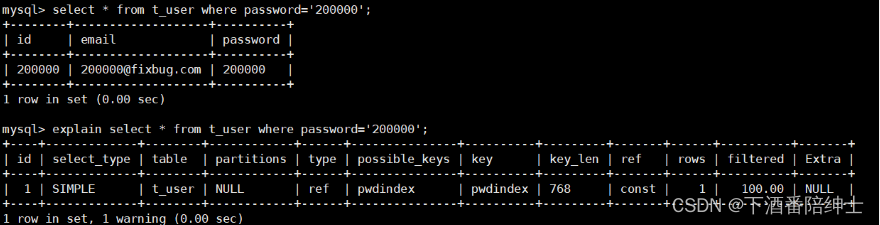
实际业务中进行索引优化的过程梳理
当谈及SQL和索引优化的问题时,我们正确的切入方式是:
- 在处理实际业务时,我们先确保打开慢查询日志,然后设置合理的、业务可以接受的慢查询时间;
- 然后压测执行各种业务;
- 查看慢查询日志,找出所有执行耗时的sql;
- 使用explain分析这些耗时的sql;
- 举例子(做xxx项目时,通过查看慢查询日志发现XXX语句执行耗时,使用explain去分析它的执行过程,发现哪些问题(没有使用上索引,使用外部排序等),如何解决(创建多列索引,确保没有类型强转等))
补充一点:
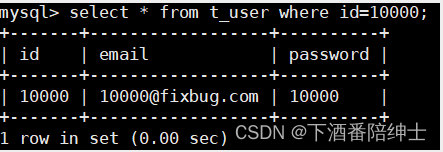
有的时候,当我们执行SQL语句,语句的执行时间是比较短的,以致于我们无法直接得知其具体的一个执行时间,这样不便于我们去做进一步的一个优化,比如下面的语句执行时间这里仅保留了小数点后两位
select * from t_user where id=10000
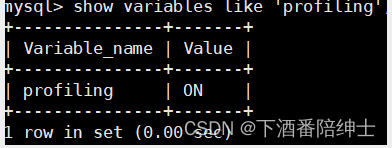
对此,我们可以设置profiling这个变量
show variables like 'profiling'; // 是否打开(启用)
set profiling=ON;// 启用profiling,作用于会话所以不用添加global
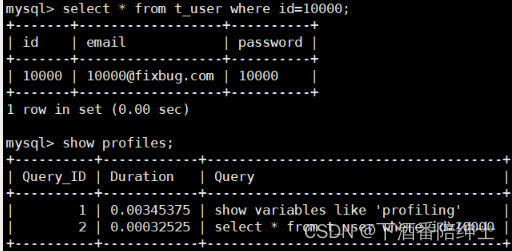
然后,当我们执行SQL语句后,可以通过执行下面的语句查看SQL语句的执行时间:
show profiles;















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











