







时空超分辨论文阅读笔记(一)---- Zooming Slow-Mo

CVPR 2020
论文地址:https://arxiv.org/abs/2002.11616
代码地址:https://github.com/Mukosame/Zooming-Slow-Mo-CVPR-2020
目录
Abstract
关于时空超分辨(STVSR)模型的设计策略:
- 二阶段模型(two-stage)
- 一阶段模型(one-stage)
模型设计
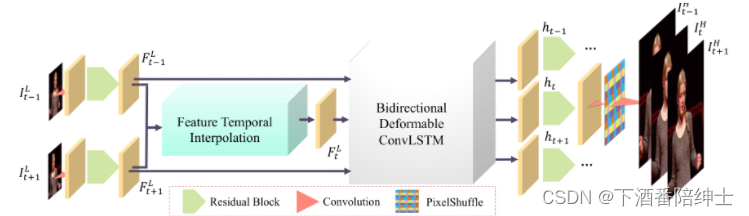
1. 模型主要由四个部分组成:
-
特征提取模块(feature extractor)
该模块由一个Conv layer + k 1 k_1 k1个残差块组成,负责提取输入帧特征。
-
中间帧特征插值模块(frame feature temporal interpolation module)
该模块根据输入的特征序列信息 { F 2 t − 1 L } t = 1 n + 1 \{F^L_{2t-1}\}^{n+1}_{t=1} { F2t−1L}t=1n+1,预测输出中间帧序列的特征 { F 2 t L } t = 1 n \{F^L_{2t}\}^{n}_{t=1} { F2tL}t=1n。
-
Deformable ConvLSTM
该模块则是对整个特征序列进行一个时间对齐和特征聚合 。
-
高分辨率帧重建模块(HR frame reconstructor)
利用经过时空融合后的特征序列生成最后的高清高分辨视频序列
2.主要模块
2.1 中间帧特征插值模块
二阶段方法(VFI+VSR)中往往是在像素级(pixel-wise)上先生成中间帧,然后对插帧后的序列进行超分辨,为了以one-stage的方式完成插帧和超分,该模块对输入帧特征进行采样融合来生成中间帧特征。根据插帧的经验,要生成中间帧特征,需要利用上下文特征间的双向运动信息来近似估计两侧到中间的运动信息(forward motion information and backwarp motion information),然后再进一步融合这两侧运动信息和上下文特征从而生成中间帧特征。
至于如何估计上下文特征间的双向运动信息,该模块采用了可变形卷积,认为其不规则的采样区域,具备比较强大的对几何物体运动建模的能力,能够从上下文特征中捕捉比较丰富的运动信息,以更好应对包含复杂运动和大幅运动的视频场景,运动信息估计模块如下图所示:
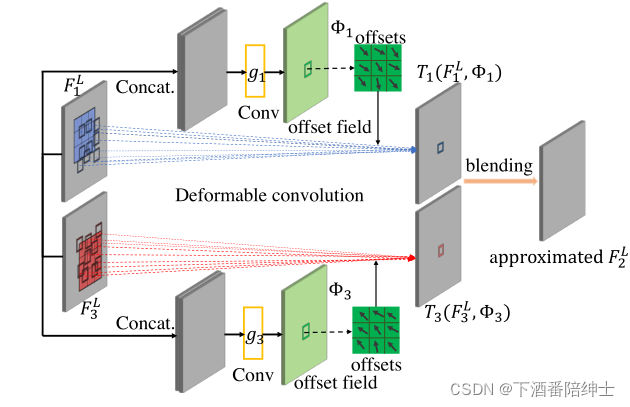
值得注意的是这里的blending操作采用的是简单的线性混合函数来结合 T 1 T_1 T1以及 T 3 T_3 T3,具体公式如下:
F 2 L = α ∗ T 1 ( F 1 L , Φ 1 ) + β ∗ T 3 ( F 3 L , Φ 3 ) F^L_2 = \alpha*T_1(F^L_1,\Phi_1)+\beta*T_3(F^L_3,\Phi_3)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 424
424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











