







1.正则表达式语法
1.1 普通字符
[]:一个字符组,代表一位字符
[0-9]:判断0-9
[a-zA-Z]:判断英文字母
[0-9][0-9]:判断长度为2的字符串是否数字
[Yy]es:判断用户输入的Yes或者yes
1.2 字符转义
对于-[]这种元字符,需要转义
[0\-9]:匹配0,\,9三个字符
1.3 元字符
\:转义
^:匹配输入的开始部分
$:匹配输入的结束部分
*:0次或多次
+:1次或多次
?:0次或1次
.:匹配任何单个字符,但换行符除外
(pattern):匹配模式并记住匹配项
|:或
{n}:精确匹配n次
{n,}:至少匹配n次
[abc]:字符集abc
[^abc]:否定字符集abc
[a-z]:字符范围
[^a-z]:否定字符范围
\A:仅匹配字符串的开头
\b:匹配单词的边界
\B:匹配非单词边界
\d:匹配数字字符
\D:匹配非数字字符
\f:匹配换页字符
\n:匹配换行符
\r:匹配回车字符
\s:匹配任何空白字符
\S:匹配任何非空白字符
\t:匹配跳进字符
\v:匹配垂直跳进字符
\w:匹配任何单词字符,包括下划线
\W:匹配任何非单词字符
\z:仅匹配字符串的结尾
\Z:仅匹配字符串的结尾,或者结尾的换行符之前
2.re模块
2.1 re模式介绍
re模块中str和bytes不能混合使用。而且因为正则的\和python的\有冲突,我们可以在定义字符串时在前面添加"r"前缀。
print('\\\\')
print('\\')
print(r'\\')
print('\n')
print(r'\n')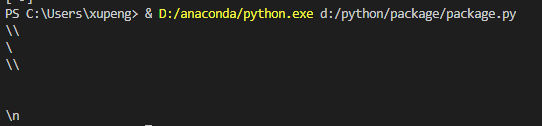
2.2 compile函数
compile函数用于编译正则表达式,生成一个Pattern对象
import re
pattern = re.compile(r'\w+')
2.3 match函数
match方法用于查找字符串指定位置正则匹配,它只匹配一次,找到一个匹配的结果就返回,不会返回所有匹配结果
import re
pattern = re.compile(r'\d+')
m1 = pattern.match('one123')
print(m1)
#匹配位置从3-5,包含头不包含尾
m2 = pattern.match('one123',3,5)
print(m2)
print(m2.group())
m3 = re.match(r'\d+','one123')
print(m3)
#使用忽略大小写模式
m4 = re.match(r'[a-z]+','Abcde',re.I)
print(m4)
print(m4.group())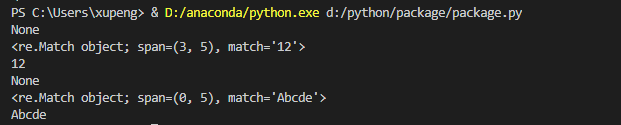
2.4 re.search
search方法用于查找字符串指定位置正则匹配。它只匹配一次,找到一个匹配的结果就返回,不会返回所有匹配结果
search和match区别:match函数需要完全满足正则表达式才返回,而search函数只要字符串包含匹配正则表达式的字串就认为匹配。
import re
pattern = re.compile(r'\d+')
m1 = pattern.search('one123')
print(m1)
#匹配位置从3-5,包含头不包含尾
m2 = pattern.search('one123',3,5)
print(m2)
print(m2.group())
m3 = re.search(r'\d+','one123')
print(m3)
#使用忽略大小写模式
m4 = re.search(r'[a-z]+','Abcde',re.I)
print(m4)
print(m4.group())

2.5 re.findall
match函数和search函数都是一次匹配,只要找到一个就返回。获取全部匹配结果需要findall函数。
findall函数无论是否匹配到都会返回一个list对象
import re
pattern = re.compile(r"\d{2}")
m1 = pattern.findall("one1234")
print(m1)
m2 = pattern.findall("one1234",0,4)
print(m2)
m3 = re.findall(r"\d+","one1234")
print(m3)
#忽略大小写模式
m4 = re.findall(r"[a-z]","123Abcd",re.I)
print(m4)

2.6 re.split
字符串的split只能匹配完全相同的字符。re模块中的split可以用正则表达式丰富切割规则。
import re
#匹配空格,和;
pattern = re.compile(r"[\s\,\;]+")
m1 = pattern.split("a,b;;c d")
print(m1)
m2 = re.split(r"[\s\,\;]+","a,b;;c d")
print(m2)
2.7 re.sub
使用正则表达式来替换字符串的方法
import re
s = "hello 123 world 456"
pattern = re.compile(r"(\w+)(\w+)")
m1 = pattern.sub("hello world",s)
print(m1)
#只替换一次
m2 = pattern.sub("hello world",s,1)
print(m2)
m3 = re.sub(r"(\w+)(\w+)","hello world",s,1)
print(m3)
3.re模块的分组匹配
分组就是通过()扩起来的正则表达式,匹配出的内容就表示一个分组。
分完组后,要想获得某个分组的内容,直接使用group(n)和groups()即可。
import re
#不分组
p1 = re.compile("\d-\d-\d")
m1 = p1.match("1-2-3")
print(m1.groups())
print(m1.group())
#分组
p2 = re.compile("(\d)-(\d)-(\d)")
m2 = p2.match("1-2-3")
print(m2.groups())
print(m2.group())
m3 = re.findall("(\d)-(\d)-(\d)","1-2-3 4-5-6")
print(m3)
4.贪婪与分贪婪匹配
贪婪和非贪婪模式指的是限定符操作时尽可能多的匹配字符串还是尽可能少的匹配字符串。
贪婪模式:限定符尽可能多的匹配字符串
非贪婪模式:限定符尽可能少的匹配字符串,限定符后加?表示非贪婪模式。
5.零宽断言
零宽断言指一种零宽度的匹配,它匹配的内容不会保存到匹配结果中。表达式的匹配内容只是代表一个位置而已。
?= :它断言自身出现的位置的后面可以匹配后面跟的表达式
?<=:它断言自身出现的位置的前面可以匹配后面跟的表达式
?!:它断言自身出现的位置的后面不可以匹配后面跟的表达式
?<!:它断言自身出现的位置的前面不可以匹配后面跟的表达式
6.常见正则表达式
6.1 邮箱地址
^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$6.2 url
^(https?:W)?([\da-z.-]+)\.([a-z.]{2,6})([V\w.-])V?$6.3 匹配首尾空白字符的正则表达式
^\s|\s$6.4 手机号码
^(13[0-9]|14[0-9]|15[0-9]|166|17[0-9]|18[0-9]|19[8|9])\d{8}$6.5 电话号码
^(\d{3,4}-)?\d{7,8}$6.6 18位身份证号码
^((\d{18}|([0-9x]{18})|(0-9X){18}))$6.7 账号是否合法(字母开头,允许5-16字节,允许字母、数字、下划线)
^[a-zA-Z][a-zA-Z0-9_]{4,15}$6.8 一年的12个月(01-09和1-12)
^(0?[1-9]|1[0-2])$6.9 日期格式(2018-01-01只做粗略匹配,格式不限制。2月有30天)
^\d{4}-\d{1,2}-\d{1,2}$6.10 一个月的31天(01-09和1-31)
^((0?[1-9])|((1|2)[0-9])|30|31)$6.11 IP地址
^(([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5]\.){3}([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])$
















 3758
3758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











