







一、文档映射
文档映射分静态映射和动态映射
1.静态映射
1).静态映射是在Elasticsearch中也可以事先定义好映射,包含文档的各字段类型、分词器等,这种方式称之为静态映射。
2).设置文档静态映射
PUT /es_db
{
"mappings": {
"properties": {
"name": {
"type": "keyword",
"index": true,
"store": true
},
"sex": {
"type": "integer",
"index": true,
"store": true
},
"age": {
"type": "integer",
"index": true,
"store": true
},
"book": {
"type": "text",
"index": true,
"store": true,
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
},
"address": {
"type": "text",
"index": true,
"store": true
}
}
}
}
注意:book字段指定了ik分词器,如果没有装ik分词器会报错
3).根据静态映射创建文档
PUT /es_db/_doc/1
{
"name": "Jack",
"sex": 1,
"age": 25,
"book": "elasticSearch入门至精通",
"address": "广州车陂"
}2.动态映射
1).Elasticsearch中不需要显示定义Mapping映射(即关系型数据库的表、字段等),在文档写入Elasticsearch时,会根据文档字段自动识别类型,这种机制称之为动态映射。
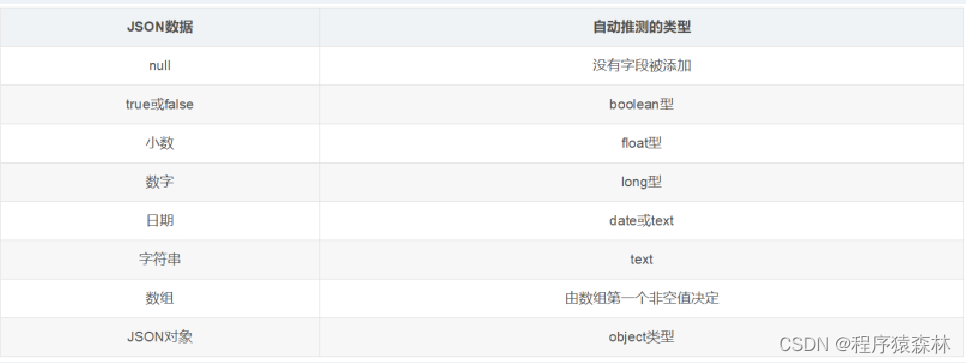
2).映射规则如下
3). 先删除索引 es_db,然后执行下面语句,则会自动创建映射
DELETE es_db
PUT /es_db/_doc/1
{
"name": "Jack",
"sex": 1,
"age": 25,
"book": "java入门至精通",
"address": "广州小蛮腰"
}
获取文档映射
GET /es_db/_mapping 3. 对已存在的mapping映射进行修改
具体方法如下:
1)如果要推倒现有的映射, 你得重新建立一个静态索引
2)然后把之前索引里的数据导入到新的索引里
3)删除原创建的索引
4)为新索引起个别名, 为原索引名
PUT /db_index
{
"mappings": {
"properties": {
"name": {
"type": "keyword",
"index": true,
"store": true
},
"sex": {
"type": "integer",
"index": true,
"store": true
}
}
}
}
POST _reindex
{
"source": {
"index": "db_index"
},
"dest": {
"index": "db_index_2"
}
}
DELETE /db_index
PUT /db_index_2/_alias/db_index二、核心类型
1.字符串:string 类型包含 text 和 keyword。
text:该类型被用来索引长文本,在创建索引前会将这些文本进行分词,转化为词的组合,建立索引;允许es来检索这些词,text类型不能用来排序和聚合。(能模糊查询, 能分词查询,不能聚合、排序)
keyword:该类型不能分词,可以被用来检索过滤、排序和聚合,keyword类型不可用text进行分词模糊检索。(只能精准查询, 不能分词查询,能聚合、排序)
2.数值型:long、integer、short、byte、double、float
3.日期型:date
4.布尔型:boolean
三、Elasticsearch乐观并发控制
1.Elasticsearch 中使用的这种方法假定冲突是不可能发生的,并且不会阻塞正在尝试的操作。 如果源数据在读写当中被修改,更新将会失败。应用程序将决定该如何解决冲突。 例如,可以重试更新、使用新的数据、或者将相关情况报告给用户等等。
2.ES新版本(7.x)使用 if_seq_no=版本值&if_primary_term=文档位置 进行版本控制
_seq_no:文档版本号,作用同_version
_primary_term:文档所在位置
_primary_term也和_seq_no一样都是整数,每当Primary Shard发生重新分配时,比如重启,Primary选举等,_primary_term会递增1。_primary_term主要是用来恢复数据时处理当多个文档的_seq_no一样时的冲突,比如当一个shard宕机了,raplica需要用到最新的数据,就会根据_primary_term和_seq_no这两个值来拿到最新的document。
DELETE /es_sc
POST /es_sc/_doc/1
{
"id": 1,
"name": "学院",
"desc": "学院老师",
"create_date": "2021-02-24"
}
POST /es_sc/_update/1
{
"doc": {
"name": "教育6666"
}
}
//当_seq_no = 6 && primary_term = 1 时,才能成功,否则操作不成功
POST /es_sc/_update/1/?if_seq_no=6&if_primary_term=1
{
"doc": {
"name": "学院1"
}
}















 237
237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









