






MODIS数据下载
MODIS数据下载地址:https://lpdaac.usgs.gov/products/mod15a2hv006/
MODIS数据格式为HDF,以FPAR数据为例:
推荐使用wget下载,省时省力,还能断点续传。
HEG工具安装
根据自己的平台选择下载安装
https://wiki.earthdata.nasa.gov/pages/viewpage.action?pageId=170800766
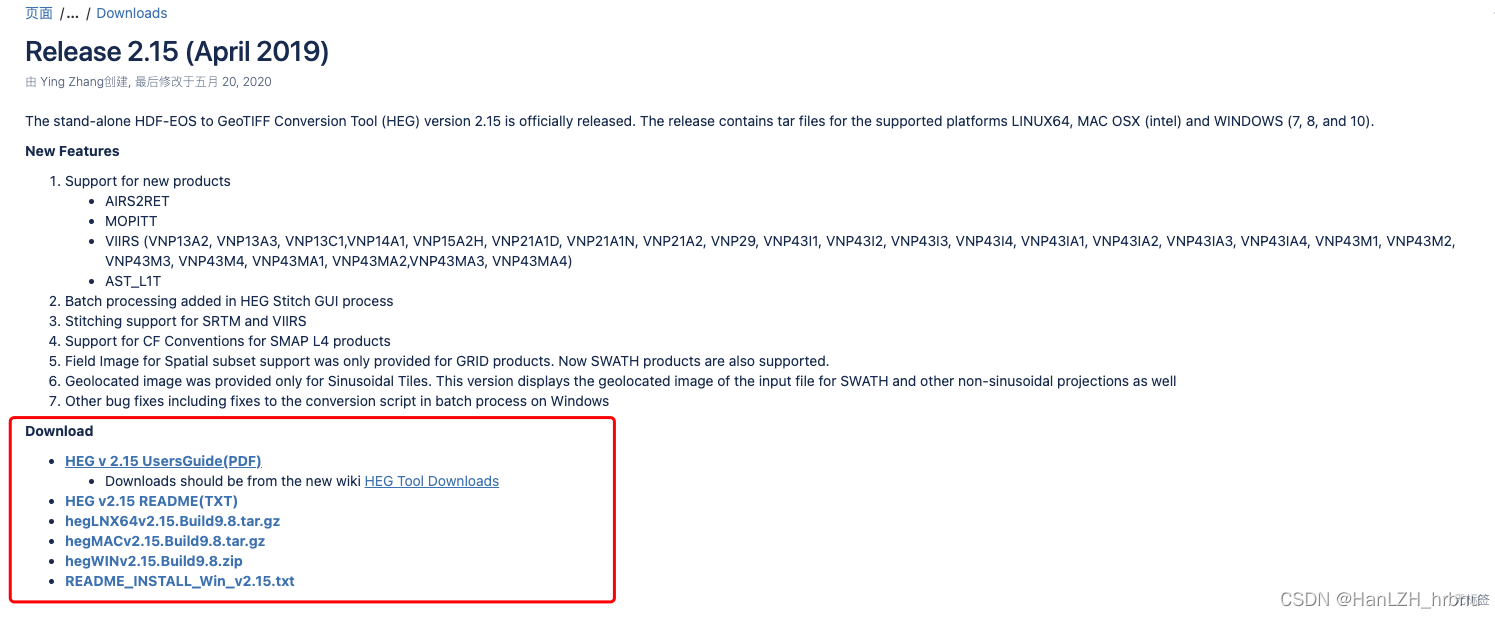
以hegMAC为例,下载完解压后执行./install 根据提示输入’安装目录’、'java/bin位置’和’用户名’即可完成安装。
HEG工具运行
使用终端进入安装目录,这里我安装在了/Users/hanlzh/Documents/HEG。
cd /Users/hanlzh/Documents/HEG/bin #进入bin
./HEG #执行HEG即可运行窗口
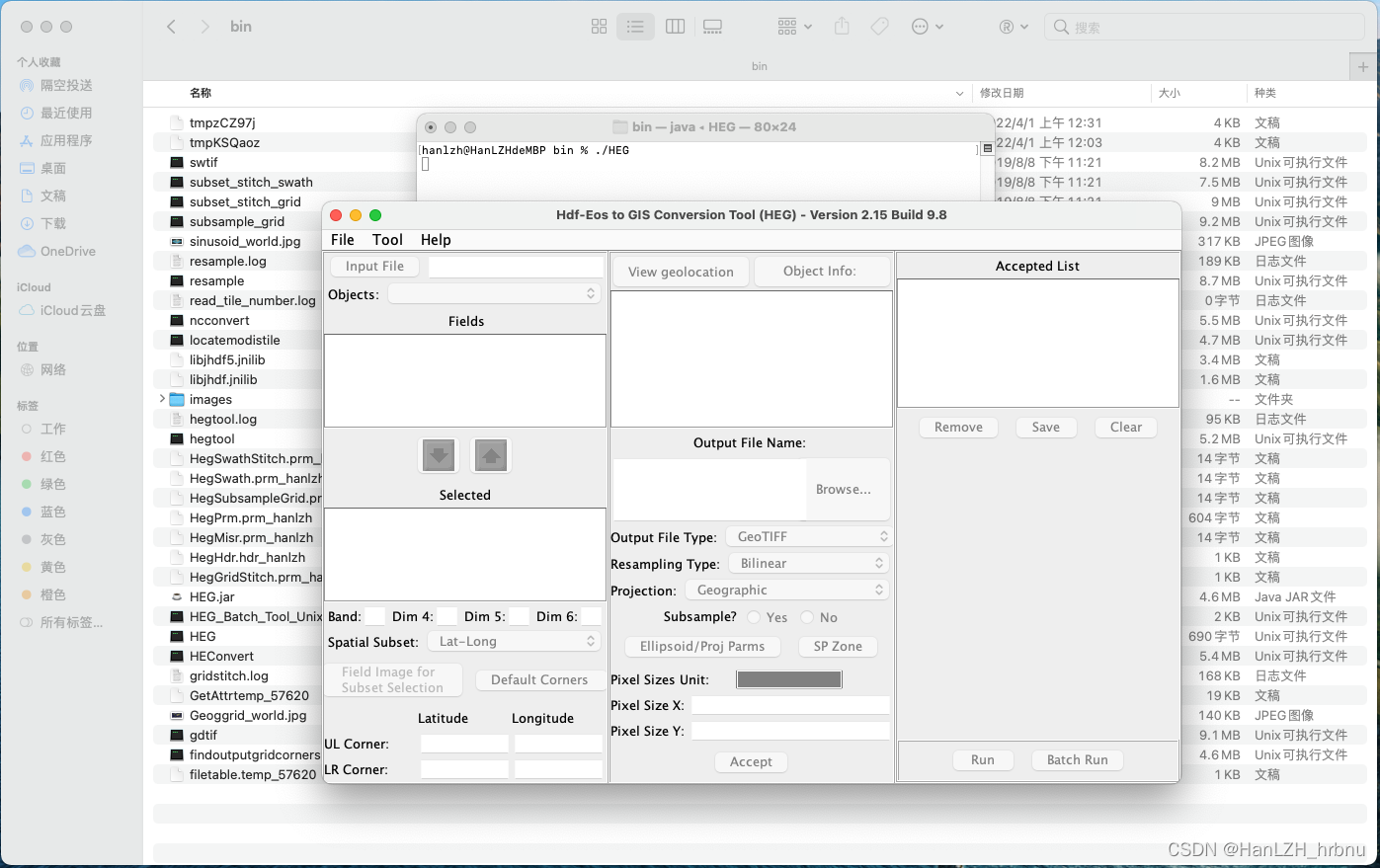
这些操作基本和早期版本的MRT相类似。
基于Python的批处理
将hdf文件按照相同日期归类存档(如图1)
import os
import shutil
sourceDir = '/Users/hanlzh/Desktop/LAI/hdf/2020/'
result_Dir = '/Users/hanlzh/Desktop/LAI/hdf_classify/2020/'
files = os.listdir(sourceDir)
for i in files:
fileday = i[14:17] #列出文件日期,如:2020001
# print(fileday)
target = (result_Dir + fileday)
source_file = (sourceDir + i)
# print(source_file)
target_file = (result_Dir + '/' + fileday + '/' + i)
# print(target_file)
if not os.path.exists(target):
os.makedirs(target)
shutil.copyfile(source_file, target_file)
else:
shutil.copyfile(source_file, target_file)
分类后就得到了这样的目录结构
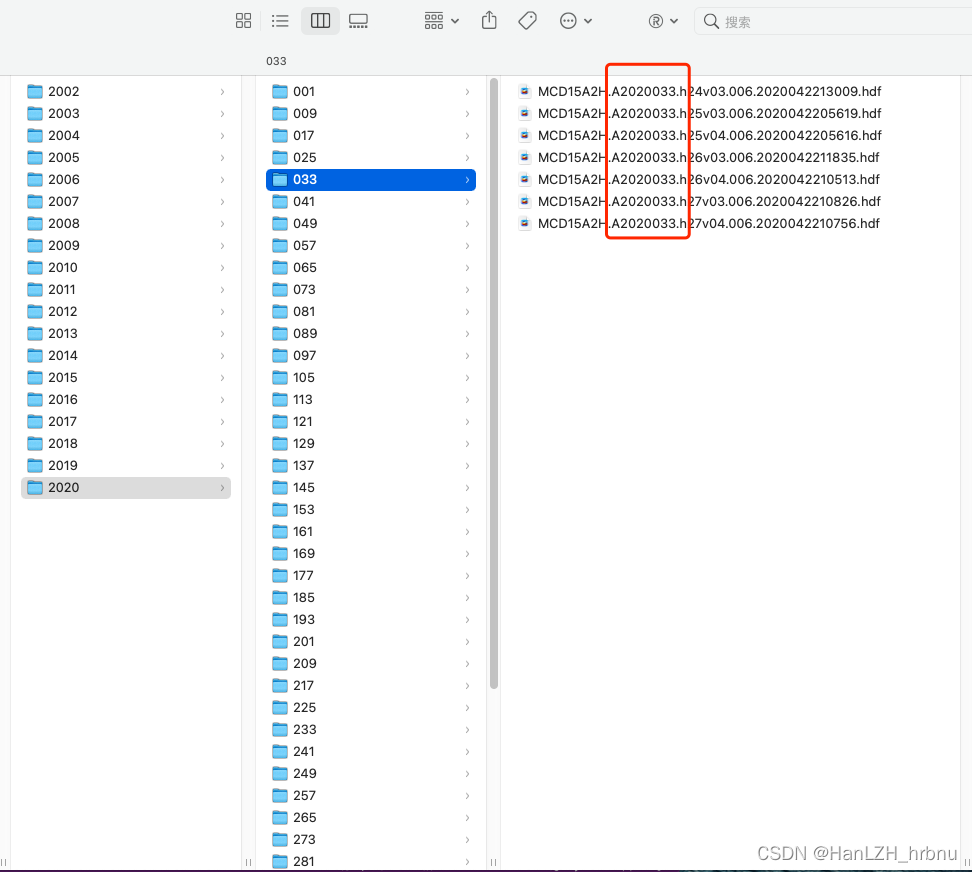
进行拼接重采样
拼接重采样生成tif文件
# -*- coding: utf-8 -*-
import os
# 设置HEG相关环境变量
os.environ['MRTDATADIR'] = '/Users/hanlzh/Documents/HEG/data'
os.environ['PGSHOME'] = '/Users/hanlzh/Documents/HEG/TOOLKIT_MTD'
os.environ['MRTBINDIR'] = '/Users/hanlzh/Documents/HEG/bin'
# 设置HEG的bin路径
hegpath = '/Users/hanlzh/Documents/HEG/bin'
# 指定处理模块的可执行程序文件路径,批处理采用subset_stitch_grid,可以根据具体的处理问题设置
hegdo = os.path.join(hegpath, 'subset_stitch_grid')
# 指定输入数据的路径
inpath = r'/Users/hanlzh/Desktop/LAI/hdf_classify'
# 指定输出数据的路径
outpath = r'/Users/hanlzh/Desktop/LAI/output'
# os.chdir(inpath) #改变当前工作目录到输入数据目录
prmpath = r"/Users/hanlzh/Desktop/LAI"
# 读取目录
allyears = os.listdir(inpath)
# print(allyears)
for year in allyears:
year_path = inpath + '/' + year
# print(year_path)
day_folders = os.listdir(year_path)
# print(day_folders)
for day in day_folders:
day_path = year_path + '/' + day
#print(day_path)
allfiles = os.listdir(day_path)
#print(allfiles)
# 列出每年/每天/*.hdf所有文件
allhdffiles = []
for eachfile in allfiles:
if os.path.splitext(eachfile)[1] == '.hdf':
allhdffiles.append(eachfile)
print('--'*20)
print('文件数量为:', len(allhdffiles), ',所有hdf文件如下')
print(' '+'\n '.join(allhdffiles))
print('--'*20)
# 要求所有文件名首尾串联,且用'|'进行分隔
sd = ""
for eachhdf in allhdffiles:
file_name = day_path + '/' + eachhdf + '|'
sd += file_name.strip()
# print(sd)
# prm文件设置模块,需要首先在HEG工具中生成一个参考的prm文件,示例如下:
# '\n'表示换行
# prm具体设置根据需要做出调整,这里的仅供参考!
prm = ['\n'
'NUM_RUNS = 1\n',
'\n'
'BEGIN\n',
'NUMBER_INPUTFILES = 7\n',
'INPUT_FILENAMES = ' + sd + '\n',
'OBJECT_NAME = MOD_Grid_MOD15A2H|\n',
'FIELD_NAME = Fpar_500m|\n',
'BAND_NUMBER = 1\n',
'SPATIAL_SUBSET_UL_CORNER = ( 59.999999995 91.37851024 )\n',
'SPATIAL_SUBSET_LR_CORNER = ( 39.999999996 179.99999996 )\n',
'OUTPUT_OBJECT_NAME = MOD_Grid_MOD15A2H|\n',
'OUTGRID_X_PIXELSIZE = 500.000000000\n',
'OUTGRID_Y_PIXELSIZE = 500.000000000\n',
'RESAMPLING_TYPE = NN\n',
'OUTPUT_PROJECTION_TYPE = ALBERS\n',
'ELLIPSOID_CODE = WGS84\n',
'OUTPUT_PROJECTION_PARAMETERS = ( 0.0 0.0 25.0 47.0 105.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 )\n',
'OUTPUT_FILENAME = ' + outpath + '/' + 'Fpar_' + year + '_' + day + '.tif' + '\n',
'SAVE_STITCHED_FILE = NO\n',
'OUTPUT_STITCHED_FILENAME = /Users/hanlzh/Desktop/LAI/output/temp' + '_' + year + day + '.hdf'+ '\n',
'OUTPUT_TYPE = GEO\n',
'END\n',
]
# 设置prm文件存储路径
prmfilename = prmpath + '/' + 'python_test' +'_gridstitch'
fo=open(prmfilename,'w',newline='\n')
fo.writelines(prm)
fo.close()
# 执行命令
resamplefiles = '{0} -P {1}'.format(hegdo, prmfilename)
print(resamplefiles)
os.system(resamplefiles)
print('--'*60)
print(year + '/' + day + '_' +'Have Finished!')
print('--'*60)
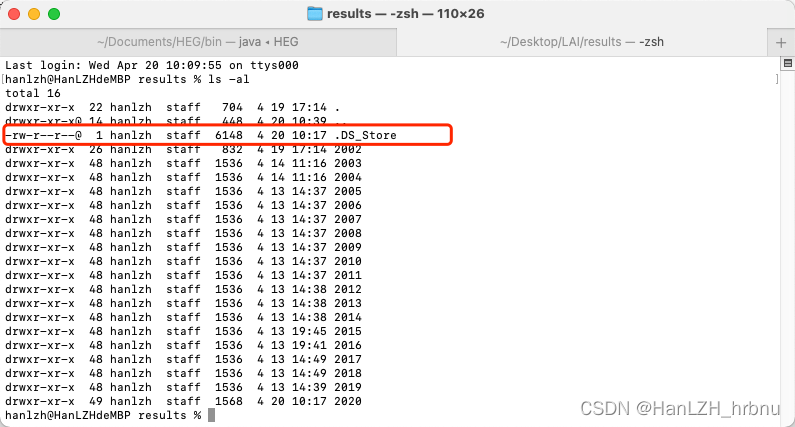
特别注意:macos下会自动生成一个.DS_Store的隐藏文件,要在终端ls -al显示后 rm .DS_Store
否则会影响Python的列表读取,导致报错终止进程。
运行成功后就会出现处理进度,并生成自定义的prm文件(*_gridstitch)和output下的临时hdf文件与tif输出结果。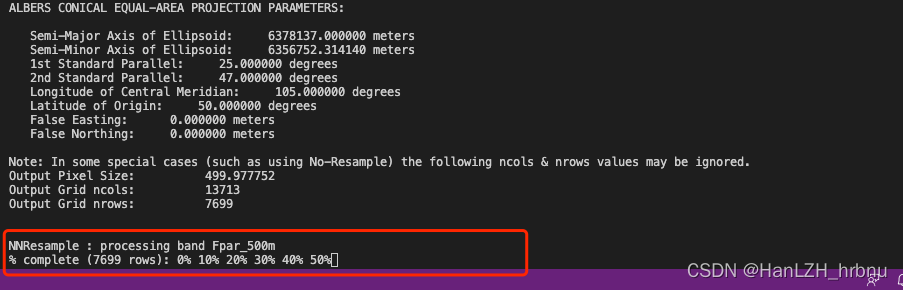
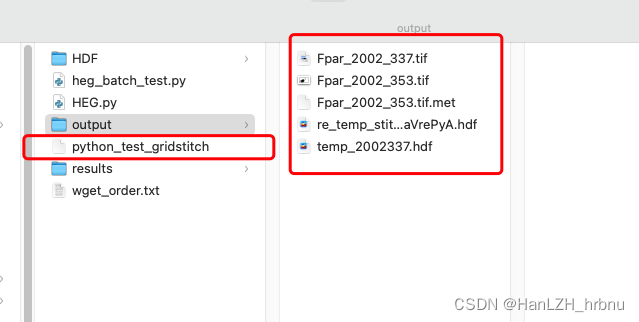
最后等待进程结束即可。


















 368
368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









