






一、HA集群搭建节点分布

这里准备4台物理机,对图上的意思进行讲解:
- node1机器中需要搭建NN角色、JN角色、ZKFC角色。
- node2机器中需要搭建NN角色、JN角色、DN角色、ZKFC角色、ZK角色。
- node3机器中需要搭建JN角色、DN角色、ZK角色。
- node4机器中需要搭建DN角色、ZK角色。
二、HA集群应用搭建
1、解决HA集群中逻辑的一对多以及逻辑的物理映射问题
在搭建HA模式的时候,有个问题,你的NameNode有两台,在某一时刻,如何确定谁是Active呢?client是只能连接Active的NameNode。
在非HA模式下通过core-site.xml文件中的fs.defaultFs对应的value来指定NameNode的地址。但是在HA模式下,就不能这么设置
按照官网的配置,需要把fs.defaultFS的值变成如下:
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
其中fs.defaultFS对应的value指定成了hdfs://mycluster,之前在非HA模式下则是NameNode所在的主机名与端口号,这里改成了一个字符串(可自定义),来充当nameservice ID。
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- dfs.ha.namenodes.[nameservice ID] -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- dfs.namenode.rpc-address.[nameservice ID].[name node ID]
machine1.example.com需要换成你对应的主机名称,比如图中的node01和node02部署NN节点,则对应到node01:8020,node02:8020即可-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>machine1.example.com:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>machine2.example.com:8020</value>
</property>
<!-- 下面配置的时nn1、nn2节点的web ui访问主机和端口 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>machine1.example.com:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>machine2.example.com:50070</value>
</property>
在dfs.ha.namenodes.mycluster 这里,其中这里的mycluster则是fs.defaultFS中定义的value,也就是nameservice ID,并不是关键字。这里指定了集群中存在两台NN,他们的逻辑名称分别时nn1和nn2,用于让DataNode确定集群多少NN。
在dfs.namenode.rpc-address.mycluster.nn2中,这个key命名的格式为
dfs.namenode.rpc-address.[nameservice ID].[name node ID]
其中对应的nameservice ID 为mycluster,name node ID 为dfs.ha.namenodes.mycluster中定义的value的其中之一。
这个key表示在nameservice ID为mycluster,NN所在的机器逻辑名为nn2所对应的rpc调用物理机的地址和端口号。
总结下上面的配置文件的含义就是:
当HA集群模式下,客户端想要连接某个集群的NameNode时,根据fs.defaultFS查看对应的nameservieID,再根据查到的nameSrvice ID,查询dfs.ha.namenodes.[nameSrvice ID]对应的NN逻辑名。通过对应的逻辑名,可以根据
dfs.namenode.rpc-address.[nameservice ID].[name node ID] 指定对应的物理主机,得到这个HA集群的NN所处于哪台物理机上。
2、共享editlog数据的目录配置
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/mycluster</value>
</property>
这个配置是配置JN的,我们使用三台物理机node1、node2、node3来搭建存放JN,所以这里对应的要在qjournal:// 后面拼接上这三个JN角色所在的物理机对应的主机名和端口,并使用分号间隔开。
除此之外,在value中我们还在末尾拼接了/mycluster,它的用意主要是做目录共享用的。比如两个业务部门的集群互相独立,如果他们各自都使用自己的JN集群存放EditLog,开销成本很大,并且不能够复用JN。所以最好的办法就是统一使用一套JN,比如部门A的集群的nameServiceID为mycluseterA,部门B的集群的nameServiceID为mycluseterB。 则JN就为他们独立创建目录**/mycluseterA** ,/mycluseterB来存放他们NN各自生成的EditLogs日志文件。这就是dfs.namenode.shared.edits.dir的用意。
配置本地JN所存放的数据的目录
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/bigdata/hadoop/ha/dfs/jn</value>
</property>
上面的配置表明,JN会将自己存的数据信息,放在它所在的机器上的/var/bigdata/hadoop/ha/dfs/jn目录。
3、配置ZKFC
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
这个配置表明,当mycluster所指的集群节点NameNode角色发生切换的时候,这个切换Active的操作交给哪个实现代理类来做。ZKFC如何发送切换消息,可以通过下面的方式配置
免密的方式:
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--你所在的机器的密钥存放目录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
注意,这里使用免密的原因是ZKFC要能够监听连接NN,那就要免密操作,如果备ZKFC想要打探主NN的状态,那这个连接过程,也是要免密才可以的。
hdfs中ssh免密的用处有两个,第一个是管理hdfs中的脚本,第二个就是ZKFC中免密访问主备NN节点。

4、 部署配置ZK
在开始部署配置zk前,需要在hdfs-site.xml文件中加入下面配置
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
这个配置表示当start-dfs启动hdfs的时候,同时会帮你启动zkfc,而且会在你NN同一台机器上启动。
下面我们需要指定zk节点在哪些机器上启动,需要在core-site.xml文件中添加如下:
<property>
<name>ha.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
格式化zkfc
在HA启动之前,需要格式化zkfc
hdfs zkfc -formatZK
三、HA集群初始化启动
在配置上面的内容之后,需要先启动JN。
在启动HA集群的时候,需要挑一台NN所在的机器启动,用以格式化JN和hdfs,注意这里在格式化的时候,需要第一个格式化JN,删除其存储的旧数据,避免NN格式化并启动之后,又重新拉取到旧数据到NN中。
在这一台NN格式化成功之后,另一台机器上的NN就一定不要再格式化了,不然他们会生成两个不同的集群id,集群id是描述这两个NN是否属于同一家的。如果不是一家的话,就不会再有数据的同步过程了。另一台机器上只需要启动并同步JN中记录的数据即可。
初始化启动流程如下:
- 先启动JN ,使用命令
hadoop-daemon.sh start journalnode - 选择一个NN 做格式化,键入命令
hdfs namenode -format(第一次启动使用!) - 启动这个格式化的NN,以备另外一台同步·
hadoop-daemon.sh start namenode - 在另外一台namenode机器中键入 :
hdfs namenode -bootstrapStandby - 格式化zookeeper,使用命令
hdfs zkfs -formatZK - 上面步骤都做完了,才可以使用
start-dfs.sh启动hdfs集群。这个命令在你免密管理脚本的节点(node1)中使用。
四、动手搭建HA
在开始之前,你需要停止之前启动的hdfs集群。使用jps命令查看对应的java进程是否包含hdfs中的角色,如果有,就在主NN节点机器执行下面命令,停止hdfs集群。
stop-dfs.sh
我们这里使用三台机器搭建HA集群,主机名分别是node1、node2、node3
其中之前搭建伪集群的时候,node1作为主NN,并分发它的公钥给node2、node3实现ssh免登录到node2、node3中。
HA集群模式下新增了一个备用的NN节点,我们把它放到node2机器上,由于node2机器需要使用ZKFC检测主NN的状态,所以node2机器到node1机器也需要设置成ssh免密连接。
同样的,node2之前已经有node1的公钥了,还没有node2自己的私钥,我们需要为node2生成密钥
[root@node2 ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
生成成功后,将.ssh/id_dsa的内容追加到.ssh/authorized_keys文件中
cat id_dsa.pub >> authorized_keys
此时node2的.ssh/authorized_keys文件就保存了两份公钥,一份是node1的,另一份是自己的。我们还需要让node2免密登陆到node1,所以需要将node2的公钥分发。
scp ./id_dsa.pub node1:`pwd`/node2.pub
此时node1中就有node2的公钥了,并且需要把 node2.pub的内容追加到node1的.ssh目录下的 authorized_keys 文件。
[root@node1 .ssh]# ls
authorized_keys id_dsa id_dsa.pub known_hosts node2.pub
[root@node1 .ssh]# cat node2.pub >> authorized_keys
为节点搭建zk环境
我们需要为node1、node2、node3三个节点进行搭建zk环境,ZKFC需要使用到zk集群自动化进行管理主备NN的切换。
将node1、node2、node3三个节点都下载 zookeeper-3.4.14.tar.gz包,并解压到/opt/bigdata目录中。
解压完成后键入下面命令
cd /opt/bigdata/zookeeper-3.4.14/conf
cp zoo-sample.cfg zoo.cfg
将zoo.cfg配置如下
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/var/bigdata/hadoop/zk
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
#zk集群中存在三个zk节点,value值的格式是:【主机名】:【主从通信端口】:【主从选举投票端口】
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
配置完毕之后,我们可以将node1中配置好的zk目录直接使用scp命令传递给node2、node3即可。
scp -r ./zookeeper-3.4.14/ node3:`pwd`
scp -r ./zookeeper-3.4.14/ node2:`pwd`
我们需要为本机的zk节点指定上myid,这一步很重要,在zk主从投票时,需要传递myid,让对方知道你是谁。
我们cd到zoo.cfg配置文件中的dataDir指定的目录,这个目录用来存放的是当前zk节点的存储数据目录。然后在这个目录下键入:
#格式 echo 【zk名字,唯一即可】 > myid
echo 1 > myid
搞定之后,我们需要在/etc/profile中,指定zk的bin目录路径
export ZOOKEEPER_HOME=/opt/bigdata/zookeeper-3.4.14
PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin
此时保存修改内容,然后使用source命令让/etc/profile文件的内容生效。此时你就可以在linux任意位置使用zk命令了。
启动zk
为了验证zk选举时只要投票过半就可以选出主节点,我们先启动node1中的zk:
[root@node1 bigdata]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/bigdata/zookeeper-3.4.14/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@node1 bigdata]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/bigdata/zookeeper-3.4.14/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
[root@node1 bigdata]# jps
23687 Jps
23641 QuorumPeerMain
观察上面结果,启动之后,使用zkServer.sh status查看当前机器的zk节点状态,提示并没在运行中,但是jps有zk的进程。 那么这种情况下,由于只有一台zk节点启动了,在zoo.cfg文件中指定了它还要和另外两台机器建立连接,但是它连接不到另外两台中的任何一台zk节点,此时zk集群就只有它自己一个zk节点运行。由于投票的票数只有自己1票,没有达到过半机器数目的票数,故此自己不能够把自己升为主master,产生了一种脑裂现象。这个情况下,该zk节点就把对外公开的服务停掉,但是自己本身的进程还是继续运行的。
然后我们继续的来启动node2中的zk
[root@node2 zk]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/bigdata/zookeeper-3.4.14/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@node2 zk]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/bigdata/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: leader
发现查看到node2中启动的zk状态时,它已经是leader了,我们可以去看下node1中的zk,已经变成了flower了。因为zxid事务id都是空的,所以这里比较myid大小,node2的myid相比node1大,故此node2是leader
[root@node1 zk]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/bigdata/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: follower
当然当我们启动node3节点,node3就是flower。
这就验证了我们所说的过半选主策略。
配置Hadoop使用HA集群
首先我们需要修改hadoop里的etc目录下的core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
</configuration>
其次我们需要修改hadoop里的etc目录下的hdfs-site.xml:
<configuration>
<!--以下是逻辑一对多到物理节点的映射关系-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/var/bigdata/hadoop/ha/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/var/bigdata/hadoop/ha/dfs/data</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- dfs.ha.namenodes.[nameservice ID] -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- dfs.namenode.rpc-address.[nameservice ID].[name node ID] -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node2:8020</value>
</property>
<!-- 下面配置的时nn1、nn2节点的web ui访问主机和端口 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node2:50070</value>
</property>
<!-- 以下是JN在哪里启动,数据存在哪个磁盘的配置-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/bigdata/hadoop/ha/dfs/jn</value>
</property>
<!-- HA角色切换的代理类和实现方法,我们使用ssh免密-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--你所在的机器的密钥存放目录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
<!-- 开启自动化启动zkfc进程-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
然后将hadoop的core-site.xml和hdfs-site.xml 同步到node2、node3中
[root@node1 hadoop]# scp core-site.xml hdfs-site.xml node2:`pwd`
core-site.xml 100% 1006 183.0KB/s 00:00
hdfs-site.xml 100% 2898 164.6KB/s 00:00
[root@node1 hadoop]# scp core-site.xml hdfs-site.xml node3:`pwd`
core-site.xml 100% 1006 31.2KB/s 00:00
hdfs-site.xml 100% 2898 63.4KB/s 00:00
在node1、node2、node3节点执行下面命令,启动jn
[root@node1 hadoop]# hadoop-daemon.sh start journalnode
启动完毕之后,我们可以cd到/opt/bigdata/hadoop-2.6.5/logs目录中,并查看node3节点存放的jn日志。
[root@node3 logs]# pwd
/opt/bigdata/hadoop-2.6.5/logs
[root@node3 logs]# tail -f hadoop-root-journalnode-node3.log
2020-05-14 21:55:47,509 INFO org.apache.hadoop.http.HttpServer2: Added filter static_user_filter (class=org.apache.hadoop.http.lib.StaticUserWebFilter$StaticUserFilter) to context journal
2020-05-14 21:55:47,509 INFO org.apache.hadoop.http.HttpServer2: Added filter static_user_filter (class=org.apache.hadoop.http.lib.StaticUserWebFilter$StaticUserFilter) to context static
2020-05-14 21:55:47,509 INFO org.apache.hadoop.http.HttpServer2: Added filter static_user_filter (class=org.apache.hadoop.http.lib.StaticUserWebFilter$StaticUserFilter) to context logs
2020-05-14 21:55:47,588 INFO org.apache.hadoop.http.HttpServer2: Jetty bound to port 8480
2020-05-14 21:55:47,588 INFO org.mortbay.log: jetty-6.1.26
2020-05-14 21:55:50,093 INFO org.mortbay.log: Started HttpServer2$SelectChannelConnectorWithSafeStartup@0.0.0.0:8480
2020-05-14 21:55:51,305 INFO org.apache.hadoop.ipc.CallQueueManager: Using callQueue: class java.util.concurrent.LinkedBlockingQueue queueCapacity: 500
2020-05-14 21:55:51,355 INFO org.apache.hadoop.ipc.Server: Starting Socket Reader #1 for port 8485
2020-05-14 21:55:51,448 INFO org.apache.hadoop.ipc.Server: IPC Server Responder: starting
2020-05-14 21:55:51,450 INFO org.apache.hadoop.ipc.Server: IPC Server listener on 8485: starting
[root@node3 logs]# jps
7397 Jps
5630 JournalNode
发现jn已经在8485端口启动成功了。
jN启动之后,随机挑选一个NN节点键入下面命令进行格式化。(注意,如果hdfs之前格式化了,请勿操作)
hdfs namenode -format
格式化完成之后,我们再看下node3节点的jn日志变化
2020-05-14 21:55:47,588 INFO org.apache.hadoop.http.HttpServer2: Jetty bound to port 8480
2020-05-14 21:55:47,588 INFO org.mortbay.log: jetty-6.1.26
2020-05-14 21:55:50,093 INFO org.mortbay.log: Started HttpServer2$SelectChannelConnectorWithSafeStartup@0.0.0.0:8480
2020-05-14 21:55:51,305 INFO org.apache.hadoop.ipc.CallQueueManager: Using callQueue: class java.util.concurrent.LinkedBlockingQueue queueCapacity: 500
2020-05-14 21:55:51,355 INFO org.apache.hadoop.ipc.Server: Starting Socket Reader #1 for port 8485
2020-05-14 21:55:51,448 INFO org.apache.hadoop.ipc.Server: IPC Server Responder: starting
2020-05-14 21:55:51,450 INFO org.apache.hadoop.ipc.Server: IPC Server listener on 8485: starting
2020-05-16 12:26:44,969 INFO org.apache.hadoop.hdfs.qjournal.server.JournalNode: Initializing journal in directory /var/bigdata/hadoop/ha/dfs/jn/mycluster
2020-05-16 12:26:45,288 WARN org.apache.hadoop.hdfs.server.common.Storage: Storage directory /var/bigdata/hadoop/ha/dfs/jn/mycluster does not exist
2020-05-16 12:26:51,995 INFO org.apache.hadoop.hdfs.qjournal.server.Journal: Formatting org.apache.hadoop.hdfs.qjournal.server.Journal@6aec5952 with namespace info: lv=-60;cid=CID-44652eaf-9599-4b62-83dc-9c61b405a866;nsid=1383736034;c=0;bpid=BP-1181962499-192.168.199.11-1589603211493
2020-05-16 12:26:51,996 INFO org.apache.hadoop.hdfs.server.common.Storage: Formatting journal Storage Directory /var/bigdata/hadoop/ha/dfs/jn/mycluster with nsid: 1383736034
2020-05-16 12:26:52,126 INFO org.apache.hadoop.hdfs.server.common.Storage: Lock on /var/bigdata/hadoop/ha/dfs/jn/mycluster/in_use.lock acquired by nodename 5630@node3
可以看到。执行格式化hdfs命令,还有个用意在于格式化JN,创建出存放jn的数据目录。此时可以看到jn目录下面已经有mycluster目录了。在node1上格式化完成后,就不要在其他的node节点上执行格式化命令了。
启动namenode
格式化完后,我们在node1节点上执行启动namenode。
[root@node1 hadoop]# hadoop-daemon.sh start namenode
在node2中其中备namenode
[root@node2 dfs]# hdfs namenode -bootstrapStandby`````
我们可以使用hdfs namenode -help 查看hdfs namenode命令后可用的参数选项即含义
启动ZKFC
启动好了之后,我们还需要启动ZKFC。在上面我们启动了zk节点,我们随便挑个ZK节点,这里选node2上的ZK节点,键入下面命令连接
[root@node2 current]# zkCli.sh
[zk: localhost:2181(CONNECTED) 2] ls /
[zookeeper]
上面连接node2的zk节点时,查看zk的根目录发现只有zookeeper这个节点。然后我们在node1键入下面的命令,格式化zookeeper
[root@node1 hadoop]# hdfs zkfc -formatZK
20/05/17 16:34:49 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/mycluster in ZK.
我们关注上面打印出的这一句日志,说明在node2中的zk节点创建了/hadoop-ha/mycluster目录,我们可以看下node2中的zk节点目录结构:
[zk: localhost:2181(CONNECTED) 3] ls /
[zookeeper, hadoop-ha]
[zk: localhost:2181(CONNECTED) 5] ls /hadoop-ha
[mycluster]
[zk: localhost:2181(CONNECTED) 6] ls /hadoop-ha/mycluster
[]
启动hdfs集群
完成上面的这些步骤后,所有的启动准备工作全部结束了,我们在node1节点中键入启动hdfs命令
[root@node1 hadoop]# start-dfs.sh
Starting namenodes on [node1 node2]
node1: namenode running as process 2768. Stop it first.
node2: starting namenode, logging to /opt/bigdata/hadoop-2.6.5/logs/hadoop-root-namenode-node2.out
node3: starting datanode, logging to /opt/bigdata/hadoop-2.6.5/logs/hadoop-root-datanode-node3.out
node2: starting datanode, logging to /opt/bigdata/hadoop-2.6.5/logs/hadoop-root-datanode-node2.out
Starting journal nodes [node1 node2 node3]
node1: journalnode running as process 2661. Stop it first.
node3: journalnode running as process 2089. Stop it first.
node2: journalnode running as process 2310. Stop it first.
Starting ZK Failover Controllers on NN hosts [node1 node2]
node1: starting zkfc, logging to /opt/bigdata/hadoop-2.6.5/logs/hadoop-root-zkfc-node1.out
node2: starting zkfc, logging to /opt/bigdata/hadoop-2.6.5/logs/hadoop-root-zkfc-node2.out
执行命令成功后,我们就可以得到上面的日志结果。我们返回node2中查看其zk节点的变化
[zk: localhost:2181(CONNECTED) 7] ls /hadoop-ha/mycluster
[ActiveBreadCrumb, ActiveStandbyElectorLock
可以发现/hadoop-ha/mycluster目录下多了两个目录,其中ActiveStandbyElectorLock就是我们上面所说的当NN启动之后,zkfc会在zk集群上注册一把锁,两台机器的NN谁抢到这把锁即为主NN,其余一个时备NN。
我们可以看下ActiveStandbyElectorLock的具体内容
[zk: localhost:2181(CONNECTED) 8] get /hadoop-ha/mycluster/ActiveStandbyElectorLock
myclusternn2node2 �>(�>
cZxid = 0xa00000007
ctime = Sun May 17 16:40:17 CST 2020
mZxid = 0xa00000007
mtime = Sun May 17 16:40:17 CST 2020
pZxid = 0xa00000007
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x300002858200000
dataLength = 29
numChildren = 0
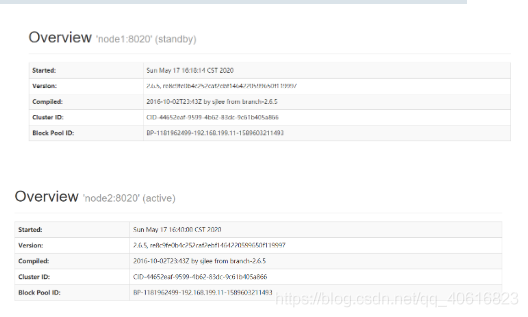
大致意思是说,现在的这把锁是归属于node2中的NN所占领,也即是node1中的NN为standby状态,而node2的NN为active状态
我们可以通过访问node1、node2的50070端口查看:
我们还可以通过zkfc的日志信息,在hadoop的logs目录下查看node1节点的zkfc log信息
[root@node1 logs]# tail -f hadoop-root-zkfc-node1.log
2020-05-17 17:49:52,850 INFO org.apache.zookeeper.ClientCnxn: Session establishment complete on server node1/192.168.199.11:2181, sessionid = 0x100005eac7d0002, negotiated timeout = 5000
2020-05-17 17:49:52,864 INFO org.apache.hadoop.ha.ActiveStandbyElector: Session connected.
2020-05-17 17:49:52,895 INFO org.apache.hadoop.ipc.CallQueueManager: Using callQueue: class java.util.concurrent.LinkedBlockingQueue queueCapacity: 300
2020-05-17 17:49:52,941 INFO org.apache.hadoop.ipc.Server: Starting Socket Reader #1 for port 8019
2020-05-17 17:49:52,998 INFO org.apache.hadoop.ipc.Server: IPC Server Responder: starting
2020-05-17 17:49:53,032 INFO org.apache.hadoop.ipc.Server: IPC Server listener on 8019: starting
2020-05-17 17:49:53,076 INFO org.apache.hadoop.ha.HealthMonitor: Entering state SERVICE_HEALTHY
2020-05-17 17:49:53,076 INFO org.apache.hadoop.ha.ZKFailoverController: Local service NameNode at node1/192.168.199.11:8020 entered state: SERVICE_HEALTHY
2020-05-17 17:49:53,095 INFO org.apache.hadoop.ha.ZKFailoverController: ZK Election indicated that NameNode at node1/192.168.199.11:8020 should become standby
2020-05-17 17:49:53,108 INFO org.apache.hadoop.ha.ZKFailoverController: Successfully transitioned NameNode at node1/192.168.199.11:8020 to standby state
日志说明node1节点所在的nn为备nn。
除此之外,我们关注下node2中jn节点的变化
[root@node2 current]# ls
committed-txid edits_0000000000000000007-0000000000000000008 edits_inprogress_0000000000000000015 VERSION
edits_0000000000000000001-0000000000000000002 edits_0000000000000000009-0000000000000000010 last-promised-epoch
edits_0000000000000000003-0000000000000000004 edits_0000000000000000011-0000000000000000012 last-writer-epoch
edits_0000000000000000005-0000000000000000006 edits_0000000000000000013-0000000000000000014 paxos
观测到有很多namenode节点的editLog,待备NN去做数据同步。
初始化步骤总结

五、模拟namenode出现宕机
1、模拟主namnode宕机
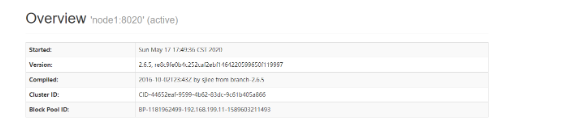
上面的步骤中,我们启动了hdfs集群,其中主NN为node2,备NN为node1。
现在模拟主NN宕机的情况,我们使用kill命令强制停止node2中的NN:
[root@node2 data]# jps
2852 DFSZKFailoverController
2310 JournalNode
2636 NameNode
3100 Jps
2734 DataNode
2495 QuorumPeerMain
[root@node2 data]# kill -9 2636
当主NN宕机之后,和其所连接的ZKFC将会第一时间收到消息,并删除zk集群的锁。备ZKFC就会收到回调通知,在ZK集群创建锁。我们看下zk集群中的锁信息变化
[zk: localhost:2181(CONNECTED) 3] get /hadoop-ha/mycluster/ActiveStandbyElectorLock
myclusternn1node1 �>(�>
cZxid = 0xb0000001a
ctime = Sun May 17 17:54:58 CST 2020
mZxid = 0xb0000001a
mtime = Sun May 17 17:54:58 CST 2020
pZxid = 0xb0000001a
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x100005eac7d0002
dataLength = 29
numChildren = 0
大致可以发现这个锁的临时持有者ephemeralOwner发生了变化,归属node1占有了。
在这里如果希望ZKFC正常切换主备,必须要在节点上的机器安装psmisc!
yum install -y psmisc
2、模拟主NN的ZKFC宕机
当ZKFC宕机了之后,将会失去和ZK集群的tcp连接,并且主NN的锁也会消失,此时会回调备NN的ZKFC,备ZKFC会去查询之前的主NN的状态,如果发现主NN还在运行,就将它降级为备NN,并且将自己所连接的NN升为主NN。
我们在node1节点上,将zkfc模拟宕机。
[root@node1 logs]# jps
6721 Jps
6548 DFSZKFailoverController
6391 JournalNode
5432 QuorumPeerMain
6205 NameNode
[root@node1 logs]# kill -9 6548
此时查看ZK集群的锁
[zk: localhost:2181(CONNECTED) 4] get /hadoop-ha/mycluster/ActiveStandbyElectorLock
myclusternn2node2 �>(�>
cZxid = 0xb0000001f
ctime = Sun May 17 18:04:14 CST 2020
mZxid = 0xb0000001f
mtime = Sun May 17 18:04:14 CST 2020
pZxid = 0xb0000001f
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x300005e6d5d0004
dataLength = 29
numChildren = 0
已经被node2占据。我们再查看下node2中的zkfc日志信息
[root@node2 logs]# tail -f hadoop-root-zkfc-node2.log
2020-05-17 17:58:38,256 INFO org.apache.hadoop.ha.ActiveStandbyElector: Session connected.
2020-05-17 17:58:38,260 INFO org.apache.hadoop.ha.ZKFailoverController: ZK Election indicated that NameNode at node2/192.168.199.12:8020 should become standby
2020-05-17 17:58:38,270 INFO org.apache.hadoop.ha.ZKFailoverController: Successfully transitioned NameNode at node2/192.168.199.12:8020 to standby state
2020-05-17 18:04:14,371 INFO org.apache.hadoop.ha.ActiveStandbyElector: Checking for any old active which needs to be fenced...
2020-05-17 18:04:14,379 INFO org.apache.hadoop.ha.ActiveStandbyElector: Old node exists: 0a096d79636c757374657212036e6e311a056e6f64653120d43e28d33e
2020-05-17 18:04:14,385 INFO org.apache.hadoop.ha.ZKFailoverController: Should fence: NameNode at node1/192.168.199.11:8020
2020-05-17 18:04:14,450 INFO org.apache.hadoop.ha.ZKFailoverController: Successfully transitioned NameNode at node1/192.168.199.11:8020 to standby state without fencing
2020-05-17 18:04:14,450 INFO org.apache.hadoop.ha.ActiveStandbyElector: Writing znode /hadoop-ha/mycluster/ActiveBreadCrumb to indicate that the local node is the most recent active...
2020-05-17 18:04:14,453 INFO org.apache.hadoop.ha.ZKFailoverController: Trying to make NameNode at node2/192.168.199.12:8020 active...
2020-05-17 18:04:14,741 INFO org.apache.hadoop.ha.ZKFailoverController: Successfully transitioned NameNode at node2/192.168.199.12:8020 to active state
从中可以发现,node2节点的机器被升为了active,而node1的namenode节点降级为standy
验证完之后,使用下面命令恢复node1的zkfc
[root@node1 logs]# hadoop-daemon.sh start zkfc
starting zkfc, logging to /opt/bigdata/hadoop-2.6.5/logs/hadoop-root-zkfc-node1.out
3、模拟主NN所在机器的网卡出现问题
现在模拟下极端情况,当主NN网卡出现问题,其机器上的ZKFC不能和zk集群通信,且备ZKFC无法连接到主NN查询它的状态。 故此最终备NN状态无法升级成主NN提供服务。我们来执行下具体的操作。
首先禁掉node2中的网卡(node2现在式主NN所在机器)
[root@node2 logs]# ifconfig
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 0.0.0.0
ether 02:42:79:8a:c0:5b txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.199.12 netmask 255.255.255.0 broadcast 192.168.199.255
inet6 fe80::eefa:ed73:2b77:d217 prefixlen 64 scopeid 0x20<link>
inet6 fe80::24f0:f282:bda9:a62b prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:0a:3d:97 txqueuelen 1000 (Ethernet)
RX packets 47478 bytes 14048077 (13.3 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 33864 bytes 5525482 (5.2 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 31870 bytes 4160446 (3.9 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 31870 bytes 4160446 (3.9 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@node2 logs]# ifconfig ens33 down
此时node2的网卡就禁用了。
我们观测下zk集群的锁状态:
[zk: localhost:2181(CONNECTED) 5] get /hadoop-ha/mycluster/ActiveStandbyElectorLock
myclusternn1node1 �>(�>
cZxid = 0xb0000002d
ctime = Sun May 17 18:15:23 CST 2020
mZxid = 0xb0000002d
mtime = Sun May 17 18:15:23 CST 2020
pZxid = 0xb0000002d
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x100005eac7d0004
dataLength = 29
numChildren = 0
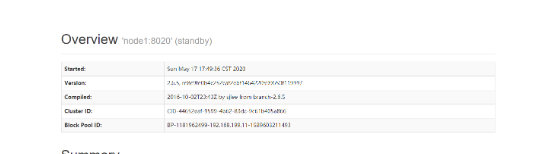
发现node1的ZKFC确实设置了锁。
然后再看下node1中的zkfc日志
2020-05-17 18:16:43,433 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: node2/192.168.199.12:8020. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=1, sleepTime=1000 MILLISECONDS)
2020-05-17 18:16:45,438 WARN org.apache.hadoop.ha.FailoverController: Unable to gracefully make NameNode at node2/192.168.199.12:8020 standby (unable to connect)
java.net.NoRouteToHostException: No Route to Host from node1/192.168.199.11 to node2:8020 failed on socket timeout exception: java.net.NoRouteToHostException: No route to host; For more details see: http://wiki.apache.org/hadoop/NoRouteToHost
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:791)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:757)
at org.apache.hadoop.ipc.Client.call(Client.java:1474)
at org.apache.hadoop.ipc.Client.call(Client.java:1401)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232)
at com.sun.proxy.$Proxy9.transitionToStandby(Unknown Source)
at org.apache.hadoop.ha.protocolPB.HAServiceProtocolClientSideTranslatorPB.transitionToStandby(HAServiceProtocolClientSideTranslatorPB.java:112)
at org.apache.hadoop.ha.FailoverController.tryGracefulFence(FailoverController.java:172)
at org.apache.hadoop.ha.ZKFailoverController.doFence(ZKFailoverController.java:514)
at org.apache.hadoop.ha.ZKFailoverController.fenceOldActive(ZKFailoverController.java:505)
at org.apache.hadoop.ha.ZKFailoverController.access$1100(ZKFailoverController.java:61)
at org.apache.hadoop.ha.ZKFailoverController$ElectorCallbacks.fenceOldActive(ZKFailoverController.java:892)
at org.apache.hadoop.ha.ActiveStandbyElector.fenceOldActive(ActiveStandbyElector.java:902)
at org.apache.hadoop.ha.ActiveStandbyElector.becomeActive(ActiveStandbyElector.java:801)
at org.apache.hadoop.ha.ActiveStandbyElector.processResult(ActiveStandbyElector.java:416)
at org.apache.zookeeper.ClientCnxn$EventThread.processEvent(ClientCnxn.java:599)
at org.apache.zookeeper.ClientCnxn$EventThread.run(ClientCnxn.java:498)
Caused by: java.net.NoRouteToHostException: No route to host
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:530)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:494)
at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:609)
at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:707)
at org.apache.hadoop.ipc.Client$Connection.access$2800(Client.java:370)
at org.apache.hadoop.ipc.Client.getConnection(Client.java:1523)
at org.apache.hadoop.ipc.Client.call(Client.java:1440)
... 14 more
2020-05-17 18:16:45,439 INFO org.apache.hadoop.ha.NodeFencer: ====== Beginning Service Fencing Process... ======
2020-05-17 18:16:45,439 INFO org.apache.hadoop.ha.NodeFencer: Trying method 1/1: org.apache.hadoop.ha.SshFenceByTcpPort(null)
2020-05-17 18:16:45,442 INFO org.apache.hadoop.ha.SshFenceByTcpPort: Connecting to node2...
2020-05-17 18:16:45,443 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: Connecting to node2 port 22
可以发现,使用tail命令查看node1的zkfc日志时,zkfc一直再尝试的去连接node2,查询状态,并报上面的异常信息。
此时node1的NN状态依旧不能变成Active。
我们再将node2的网卡恢复过来
ifconfig ens33 up
然后观测node1的zkfc日志:
cessful by method org.apache.hadoop.ha.SshFenceByTcpPort(null) ======
2020-05-17 18:20:25,427 INFO org.apache.hadoop.ha.ActiveStandbyElector: Writing znode /hadoop-ha/mycluster/ActiveBreadCrumb to indicate that the local node is the most recent active...
2020-05-17 18:20:25,431 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: Caught an exception, leaving main loop due to Socket closed
2020-05-17 18:20:25,432 INFO org.apache.hadoop.ha.ZKFailoverController: Trying to make NameNode at node1/192.168.199.11:8020 active...
2020-05-17 18:20:25,668 INFO org.apache.hadoop.ha.ZKFailoverController: Successfully transitioned NameNode at node1/192.168.199.11:8020 to active state
发现node1的zkfc最终和node2连接上了,并做升降级操作。把node1的nn升为了active
4、验证步骤总结
















 1358
1358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









