






Hadoop高可用集群搭建
一、简介
本文简单使用三台机器模拟hadooop集群搭建,简易化安装,详细描述集群搭建步骤,亲测使用时稳定高效无报错
集群各节点相关配置如下表所示:
| 主机名 | ip | NameNode | DateNode | ResourceManager | NodeManager | ZooKeeper | JournaNode | ZKFC |
|---|---|---|---|---|---|---|---|---|
| hadoop01 | 192.168.206.131 | √ | √ | √ | √ | √ | √ | √ |
| hadoop02 | 192.168.206.132 | √ | √ | √ | √ | √ | √ | √ |
| hadoop03 | 192.168.206.133 | √ | √ | √ | √ |
二、准备工作
2.1 新创建一个空白虚拟机
虚拟机名称设为: hadoop01
ip地址设为:192.168.206.131
参考:https://blog.csdn.net/and52696686/article/details/107279611
2.2 安装单机版hadoop
参考:https://blog.csdn.net/and52696686/article/details/107287066
2.3 安装zookeeper
参考:https://blog.csdn.net/and52696686/article/details/107007037
2.4 克隆两台机器
①:复制虚拟机hadoop01(hadoop01需为关闭状态),克隆两台机器分别为haoop02、haoop03



设置复制过虚拟机的名称,存放路径

重复上述操作复制创建hadoop03
②:启动虚拟机hadoop03,输入:
vi /etc/sysconfig/network-scripts/ifcfg-ens33
设置ip地址为:192.168.206.133
保存退出,重启网络
systemctl restart network
设置主机名为 hadoop03
hostnamectl set-hostname hadoop03
重启机器: reboot
③:启动虚拟机hadoop02,输入:
vi /etc/sysconfig/network-scripts/ifcfg-ens33
设置ip地址为:192.168.206.132
保存退出,重启网络
systemctl restart network
设置主机名为 hadoop02
hostnamectl set-hostname hadoop02
重启机器: reboot
④:启动虚拟机hadoop01,直接启动即可,不需要更改
⑤:使用MobaXter创建Session连接hadoo01、hadoo02、hadoo03
⑥:设置主机列表: vi /etc/hosts
添加三台虚拟机的ip,主机名,三台虚拟机都需要分别设置
如下图:
三、修改相关配置文件
3.1 集群机器之间设置免密登录
①:以hadoop01为操作对象,由于之前创建主机时配置过免密登录,需要先删除私钥
cd /root/.ssh
rm -rf id_rsa
②:回到家目录,生成私钥,需连按两次回车键
cd
ssh-keygen -t rsa -P ""
如图:

③:复制私钥到公钥:
cat /root/.ssh/id_rsa.pub > /root/.ssh/authorized_keys
④:对于hadood02、hadoop03,需重复上述①②③步骤
⑤:配置与其他虚拟机的远程免密登录:(本机除外,集群其他节点都需要分别添加一次)
ssh-copy-id -i .ssh/id_rsa.pub -p22 root@hadoop02
ssh-copy-id -i .ssh/id_rsa.pub -p22 root@hadoop03
会提示是否要添加(yes/no),输入yes
再输入相应虚拟机的密码,
会提示密钥添加1,Number of key(s) added: 1
如下图所示:

至此主机hadoop-01远程免密登录配置完成,对于虚拟机hadoop-02、hadoop-03需分别进行上述操作
注:若root@虚拟机名报错,提示找不到名称,可以试试roo@ip地址
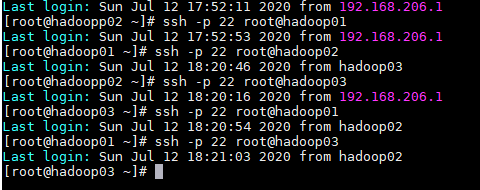
⑥:测试连接,虚拟机相互切换,若虚拟机间切换不需要输入密码直接可以切换,说明配置成功:
切换虚拟机代码:
ssh -p 22 root@hadoop01
ssh -p 22 root@hadoop01
ssh -p 22 root@hadoop03
ssh -p 22 root@hadoop01
ssh -p 22 root@hadoop03
ssh -p 22 root@hadoop02
ssh -p 22 root@hadoop03
ssh -p 22 root@hadoop01
如下图,相互切换,免密登录配置成功
3.2 修改hadoop01配置文件
以hadoop01为操作对象,进入hadoop配置文件目录,修改以下5个文件
core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、slaves
cd /opt/install/hadoop260/etc/hadoop
①:vi core-site.xml
configuration 标签中插入以下代码:
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/install/hadoop260/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
如下图:

②:vi hdfs-site.xml
configuration 标签中插入以下代码:
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop01:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop02:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop02:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/mycluster</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/install/hadoop260/data/jn</value>
</property>
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop03:50090</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
③:vi mapred-site.xml
configuration 标签中插入以下代码:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
如下图:

④:vi yarn-site.xml
configuration 标签中插入以下代码:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop01</value> </property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop02</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
⑤:vi slaves
添加集群所有的主机名:
hadoop01
hadoop02
hadoop03
3.3同步配置文件至hadoop02、hadoop03
在hadoop01节点,切换至配置文件目录
cd /opt/install/hadoop260/etc/hadoop
将以上修改的5个配置文件,分别远程发送给hadoop02、hadoop03
scp core-site.xml root@hadoop02:$PWD
scp core-site.xml root@hadoop03:$PWD
scp hdfs-site.xml root@hadoop02:$PWD
scp hdfs-site.xml root@hadoop03:$PWD
scp mapred-site.xml root@hadoop02:$PWD
scp mapred-site.xml root@hadoop03:$PWD
scp yarn-site.xml root@hadoop02:$PWD
scp yarn-site.xml root@hadoop03:$PWD
scp slaves root@hadoop02:$PWD
scp slaves root@hadoop03:$PWD
3.4修改hadoop02、hadoop03中zookeeper配置文件
因为hadoop02、hadoop03是复制hadoop01过来的,需将每台机器更改为集群的zookeeper配置
①:分别修改hadoop02、hadoop03中,/opt/install/zookeeper/zookeeperdata/目录下的myid文件,数值分别设为 2 、3
vi /opt/install/zookeeper/zookeeperdata/myid
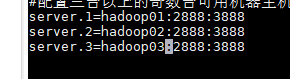
②:在hadoop01中
vi /opt/install/zookeeper/conf/zoo.cfg
添加hadooop02、hadoop03节点,如下图
将修改后的问价分别发送至hadoop02、hadoop03
scp /opt/install/zookeeper/conf/zoo.cfg root@hadoop02:/opt/install/zookeeper/conf/
scp /opt/install/zookeeper/conf/zoo.cfg root@hadoop03:/opt/install/zookeeper/conf/
三、启动(按顺序启动)
①:下载 psmisc 依赖包
对每个设置了NameNode的节点(hadoop01、hadoop02)需要下载 psmisc 依赖包,该包可以实现standby节点发现activenamenode节点宕机以后,自动切换另一个NameNode节点
yum install -y psmisc
②:对每台设置了zookeeper的节点都启动服务(3台)
zkServer.sh start
输入:zkServer.sh status 查看zookeeper的运行状态,若有一台机器为leader,其余两台为follow,则zookeeper集群运行成功
③:.在各个 JournalNode 节点上,启动 journalnode 服务:
hadoop-daemon.sh start journalnode

④:对任意一个namenode的节点进行格式化(hadoop01、hadoop02)
注:如果之前已格式化并且启动过hdfs、yarn服务,格式化前需先删除hadoop的安装目录下的tmp目录(opt/install/hadoop260/tmp),因为之前启动过已产生信息,第二遍格式化可能会引起信息冲突报错(都要删除tmp)
以hadoop01为例
hadoop namenode -format
⑤:同步两个namenode的元数据
查看你配置的 core-site.xml 中的 hadoop.tmp.dir 这个配置信息,得到hadoop工作的目录,我配置的是/opt/install/hadoop260/tmp,把hadoop01上的 tmp 目录发送给hadoop02的相同路径下,同步两个namenode的元数据
scp -r /opt/install/hadoop260/tmp/ root@hadoop02:/opt/install/hadoop260/
也可以直接在hadoop02中输入:
hadoop namenode -bootstrapStandby
⑥:对任意一台设置了NameNode的节点(hadoop01、hadoop02),格式化 ZKFC
以hadoop01为例
hdfs zkfc -formatZK
如下图表示格式化成功

⑥:启动hdfs服务(任意节点,以hadoop01为例)
start-dfs.sh
⑦:启动yarn服务(以hadoop01为例)
start-yarn.sh
在另一个配置了ResourceManager节点手动启动(hadoop02)
yarn-daemon.sh start resourcemanager
四、测试集群高可用
4.1 网页端口测试
hdfs服务:
- 192.168.206.131:50070
- 192.168.206.132:50070
yarn服务:
- 192.168.206.131:8088
- 192.168.206.132:8088



输入192.168.206.132会自动切换至主节点,但是这边暂时无法访问

4.2 验证集群高可用
由上图观察到haddoop02 NameNode为激活状态,杀死进程该进程
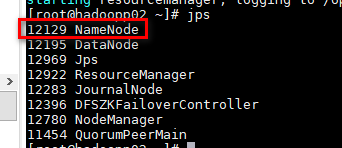
[root@hadoopp02 ~]# kill -9 12129
hadoop02 NameNode网页现在无法访问

但是刷新hadoop01 的NameNode网页端口,状态由刚才的standby自动切换为active状态,说明集群测试通过,可以实现高可用的功能

4.3切换节点的active/standby状态
- 将某节点切换为 Active
$HADOOP_HOME/bin/hdfs haadmin -transitionToActive nn1
- 将某节点切换为 Standby
$HADOOP_HOME/bin/hdfs haadmin -transitionToStandby nn1















 438
438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









