







正则表达式
文章目录
课前补充
转义字符\
<script type="text/javascript">
// 表示反斜杠后面的引号就是普通引号而已 不影响字符串的引号成对
var str = "abcd\"edf";
</script>

多行字符串
// 系统规定字符串不能多行显示
<script type="text/javascript">
var test = "\
<div></div>\
<span></span>\
";
console.log(test);
</script>
字符串换行符\n
<script type="text/javascript">
// \n换行
var str = "abcd\nedf";
</script>
| 转义字符 | 字符值 | 输出结果 |
|---|---|---|
| \’ | 一个单撇号(') | 输出单撇号字符’ |
| \" | 一个双撇号(") | 输出双撇号字符" |
| ? | 一个问号(?) | 输出问号字符? |
| \\ | 一个反斜杠() | 输出反斜杠字符\ |
| \a | 警告(alert) | 产生声音或视觉信号 |
| \b | 退格(backspace) | 将光标当前位置后退一个字符 |
| \f | 换页(from feed) | 将光标当前位置移到下一页的开头 |
| \n | 换行 | 将光标当前位置移到下一页的开头 |
| \r | 回车(carriagereturn) | 将光标当前位置移到本行的开头 |
| \t | 水平制表符 | 将光标当前位置移到下一个Tab位置 |
| \v | 垂直制表符 | 将光标当前位置移到下一个垂直表对齐点 |
| \o、\oo、\ooo其中o表示一个八进制数字 | 与该八进制对应的ASCII字符 | 与该八进制码对应的字符 |
| \xh[h…]其中h表示一个十六进制数字 | 与该十六进制对应的ASCII字符 | 与该十六进制码对应的字符 |
正则表达式
正则表达式的作用:
匹配特殊字符或有特殊搭配原则的字符的最佳选择。
正则表达式是构成*搜索模式(search pattern)*的字符序列。
当您搜索文本中的数据时,您可使用搜索模式来描述您搜索的内容。
正则表达式可以是单字符,或者更复杂的模式。
正则表达式可用于执行所有类型的文本搜索和文本替换操作。
两种创建方式
直接量(推荐)
<script type="text/javascript">
var reg = /abc/; // 这就创建了一个正则表达式abc
// 正则表达式会验证一下字符串内有没有规定的片段abc(顺序大小写都得一致)
var str = "abcd";
</script>
调用test方法 有就返回true 没有就返回false
/pattern/i; i是修饰符(把搜索修改为大小写不敏感,也就是忽视大小写)。
<script type="text/javascript">
var reg = /abcd/i;
var str = "ABCD";
</script>
new RegExp();
<script type="text/javascript">
var str = "abcd"; // 字符串abcd
var reg = new RegExp("abc"); // 正则表达式abc
</script>
<script type="text/javascript">
var str = "aBcD";
var reg = new RegExp("abc","i"); // 忽略大小写
</script>
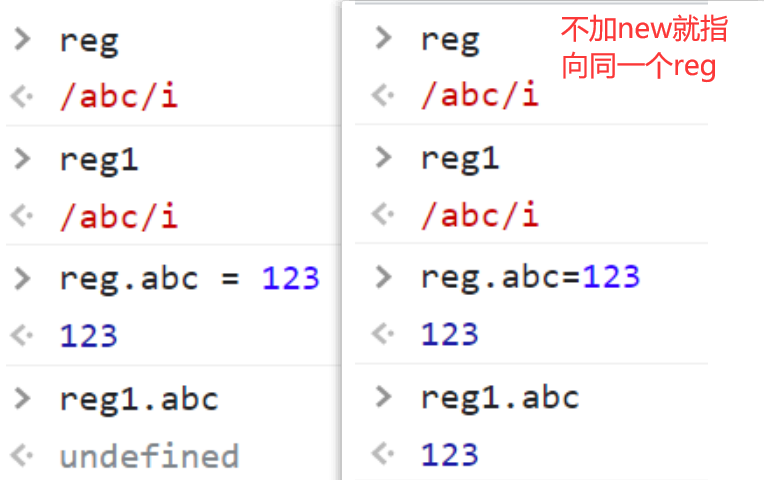
<script type="text/javascript">
var str = "aBcD";
var reg = new RegExp("abc","i");
// 通过这种方式复制一个一样的正则表达式
var reg1 = new RegExp(reg); // 如果这里不写new 那就是指向同一个reg 因为表示的是正则表达式的引用
</script>
正则表达式修饰符
修饰符可用于大小写不敏感的更全局的搜素:
| 修饰符 | 描述 | 试一试 |
|---|---|---|
| i | 执行对大小写不敏感的匹配。(忽略大小写) | 试一试 |
| g | 执行全局匹配(查找所有匹配而非在找到第一个匹配后停止)。 | 试一试 |
| m | 执行多行匹配。 | 试一试 |
<script type="text/javascript">
var reg = /ab/gi; // 全局匹配 忽略大小写
var str = "ababababab";
console.log(str.match(reg));
</script>
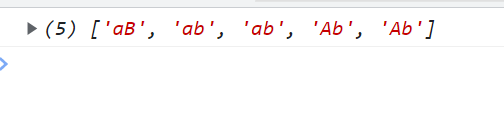
reg = /ab/mgi
<script type="text/javascript">
var reg = /a/g; // 这么匹配a能匹配两个
var str = "abcdea";
console.log(str.match(reg));
</script>
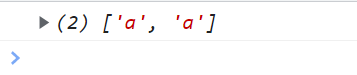
<script type="text/javascript">
// 匹配以a开头的字符串的a 这样只有一个
var reg = /^a/g;
var str = "abcdea";
console.log(str.match(reg));
</script>
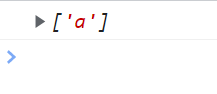
<script type="text/javascript">
var reg = /^a/g;
// 在字符串之后加换行符也还是只有一个
// 因为没有多行匹配的功能 认为\n和字符串是一个整体
var str = "ab\ncdea";
console.log(str.match(reg));
</script>
<script type="text/javascript">
var reg = /^a/gm;
// 加上多行匹配符m之后才有多行匹配的功能 然后匹配出两个a
var str = "abcde\na";
console.log(str.match(reg));
</script>

正则表达式模式
正则表达式上的方法test():
判断字符是否符合要求,返回true和false
字符串上的方法match():
可以把所有东西匹配出来并返回,更加直观
括号用于查找一定范围的字符串:
| 表达式 | 描述 |
|---|---|
| [abc] | 查找方括号之间的任何字符 |
| [^abc] | 查找任何不在方括号之间的字符 |
| [0-9] | 查找任何从0-9的数字 |
| [a-z] | 查找任何从小写a到小写z的字符 |
| [A-Z] | 查找任何从大写A到大写Z的字符 |
| [A-z] | 查找任何从大写A到小写z的字符 |
| [adgk] | 查找给指定集合内的任何字符 |
| [^adgk] | 查找给指定集合外的任何字符 |
| (x|y) | 查找由|分割的任何选项(或) |
<script type="text/javascript">
// 表示在全局中匹配三个数字相邻 只会匹配前三位
// 比如这123匹配成功就不会往后继续看数字09了 而是看字母后的三个数字相连的数987
var reg = /[0-9][0-9][0-9]/g;
var str = "12309u98723zpoixcuypiouqwer";
console.log(str.match(reg));
</script>

<script type="text/javascript">
// 第一个只能在ab取值 第二个只能在cd取 第三个只能取d
var reg = /[ab][cd][d]/g;
var str = "abcd"; // 取的数满足范围的同时还要注意顺序
console.log(str.match(reg));
</script>
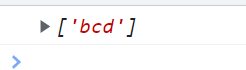
<script type="text/javascript">
var reg = /[0-9A-z][cd]d/g;
var str = "ab1cd";
console.log(str.match(reg));
</script>

[^] 不加[]是代表开头 加[]表示非
<script type="text/javascript">
var reg = /[^a][^b]/g; // 第一位不是a 第二位不是b
var str = "ab1cd"; // b1和cd
console.log(str.match(reg));
</script>

(x|y) 查找由 | 分隔的任何选项 意思就是x或y的意思。
<script type="text/javascript">
var reg = /(a|b)/g; // 只写a|b就会把ab都匹配出来
var str = "ab1cd";
console.log(str.match(reg));
</script>
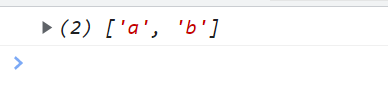
<script type="text/javascript">
// 第一位 a或b 第二位范围是bc 第三位0-9 所以是ab1
var reg = /(a|b)[bc][0-9]/g;
var str = "ab1cd";
console.log(str.match(reg));
</script>
元字符(Metacharacter)是拥有特殊含义的字符:
| 元字符 | 取值区间 | 描述 | ||
|---|---|---|---|---|
| . | [^\r\n] | 查找单个字符,除了换行和结束符 | ||
| \w | [0-9A-z_] | 查找单词字符 | ||
| \W | [^\w] | 查找非单词字符 | ||
| \d | [0-9] | 查找数字字符 | ||
| \D | [^\d] | 查找非数字字符 | ||
| \s | [\t\n\r\v\f加空格] | 查找空白字符 | ||
| \S | [^\s] | 查找非空白字符 | ||
| \b | 单词边界 | 匹配单词边界 | ||
| \B | 非单词边界 | 匹配非单词边界 | ||
| \0 | 查找NUL字符 | |||
| \n | 查找换行符 | |||
| \f | 查找换页符 | |||
| \r | 查找回车符 | |||
| \t | 查找制表符 | |||
| \v | 查找垂直制表符 | |||
| \xxx | 查找以八进制数xxx规定的字符 | |||
| \xdd | 查找十六进制数dd规定的字符 | |||
| \uxxxx | 查找以十六进制数xxxx规定的Unicode字符 | |||
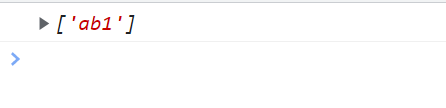
\w和\W \w查找单词字符 \W查找非单词字符
\w === [0-9A-z_] \w代表的是0-9和字母大小写和下划线的区间
<script type="text/javascript">
// 第一位取值范围[0-9A-z_] 后面几位是b1cd
var reg = /\wb1cd/g;
var str = "ab1cd";
console.log(str.match(reg));
</script>
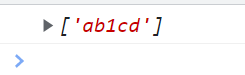
\W === [^\w] \W代表的是除了0-9和字母大小写和下划线的其他区间
<script type="text/javascript">
// 第一位取值范围是除了[0-9A-z_]的区间 后面几位是b1cd
var reg = /\Wb1cd/g;
var str = "ab1cd";
console.log(str.match(reg));
</script>
找不到会返回null
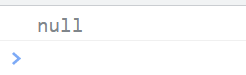
<script type="text/javascript">
// 第一位取值范围是除了[0-9A-z_]的区间 后面几位是b1cd
var reg = /\Wb1cd/g;
var str = "a@b1cd";
console.log(str.match(reg));
</script>
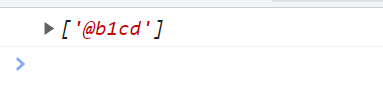
\d和\D \d查找数字字符 \D查找非数字字符
\d === [0-9] 表示取值区间是0-9
<script type="text/javascript">
var reg = /\dcd/g; // 第一位区间是0-9 后面两位是cd
var str = "ab1cd"; // 能取出1cd
console.log(str.match(reg));
</script>
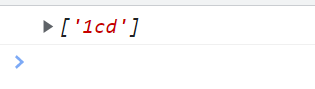
\D === [^\d] 表示取值区间是除了0-9的其他区间
<script type="text/javascript">
var reg = /\D1c/g;
var str = "ab1cd";
console.log(str.match(reg));
</script>
\s和\S \s查找空白字符 \S查找非空白字符
空白符

\s === [\t\n\r\v\f加空格]
\S === [^\s]
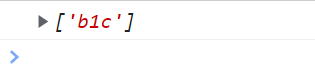
\b和\B \b匹配单词边界 \B匹配非单词边界
<script type="text/javascript">
var reg = /\bcde/g; // \bc是指匹配c是单词边界 后面跟的单词
var str = "abc cde fgh"; // 6个单词边界 头尾各两个
console.log(str.match(reg));
</script>
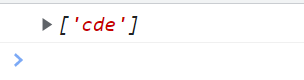
<script type="text/javascript">
var reg = /\bcde\B/g; // c是单词边界后面跟de和非边界的单词
var str = "abc cdefgh"; // h这么写就不是边界了
console.log(str.match(reg));
</script>

\t 只能匹配在字符串中出现的\t(制表符)
<script type="text/javascript">
var reg = /\tc/g; // 匹配制表符后面跟了个c
var str = "abc\tcdefgh";
console.log(str.match(reg));
</script>
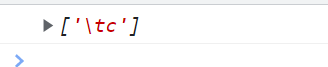
\n 也是只能匹配字符串中出现的\n(换行符)
<script type="text/javascript">
var reg = /\nc/g; // 匹配换行符后面跟了个c
var str = "abc\ncdefgh";
console.log(str.match(reg));
</script>
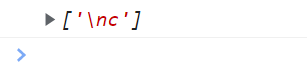
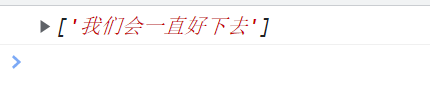
. === [^\r\n] 能匹配除回车符和换行符的区间。
<script type="text/javascript">
// .能匹配除回车符和换行符的区间
var reg = /. /g;
// 加空格也能识别出来
var str = "我们会一直好下去,会在一起很久很久。";
console.log(str.match(reg));
</script>

Unicode编码拓展
Unicode表达形式
- \u0000 (十六进制)
- \u0affff (十六进制)
- \u101abe
分层展示
前两位代表不同的层 后四位撑死代表Unicode代表的范围
\u010000 - \u01ffff
\u020000 - \u02ffff
\u100000 - \u10ffff
\uxxxx 查找以十六进制数xxxx规定的Unicode字符
<script type="text/javascript">
// 这个Unicode就是我们会一直好下去的编码
var reg = /\u6211\u4eec\u4f1a\u4e00\u76f4\u597d\u4e0b\u53bb/g;
var str = "我们会一直好下去,会在一起很久很久。";
console.log(str.match(reg));
</script>
\uxxxx 也有区间 区间[\u0000-\uffff]就包含了所有字符 能匹配一切
<script type="text/javascript">
// 这里换成编码区间
var reg = /[\u3000-\ua000]/g;
var str = "我们会一直好下去,会在一起很久很久。";
console.log(str.match(reg));
</script>
区间生效了 但是会把文字分开

\s和\S组合也能匹配所有字符
<script type="text/javascript">
var reg = /[\s\S]/g;
var str = "我们会一直好下去,会在一起很久很久。";
console.log(str.match(reg));
</script>

\d和\D组合也能匹配所有字符
<script type="text/javascript">
var reg = /[\d\D]/g;
var str = "我们会一直好下去,会在一起很久很久。";
console.log(str.match(reg));
</script>

Quantifiers 定义量词:
| 量词 | 听得懂的描述 | n匹配区间 | 官方描述 |
|---|---|---|---|
| n+ | n是个变量,一次可以匹配1到无数个符合条件的值 | {1,+∞} | 匹配任何包含至少一个n的字符串 |
| n* | 一次可以匹配0到无数个符合条件的值 | {0,+∞} | 匹配任何包含零个或多个n的字符串 |
| n? | 一次可以匹配0到1个符合条件的值 | {0,1} | 匹配任何包含零个或一个n的字符串 |
| n{X} | {3}这样就是符合条件的值3个3个匹配 | {X} | 匹配包含X个n的序列的字符串 |
| n{X,Y} | x-y个进行匹配,{1,3}这样就是一次匹配1-3个符合条件的值 | {X,Y} | 匹配包含X至Y个n的序列的字符串 |
| n{X,} | 每次最少匹配x个符合条件的值 | {X,+∞} | 匹配包含至少X个n的序列的字符串 |
| n$ | 判断最后一位是否在取值区间,在则返回该值,不在则是null | 匹配任何结尾为n的字符串 | |
| ^n | 判断第一位是否在取值区间,在则返回该值,不在则是null | 匹配任何开头为n的字符串 | |
| ?=n | 匹配任何其后紧接指定字符串n的字符串 | ||
| ?!n | 匹配任何其后没有紧接指定字符串n的字符串 |
贪婪匹配原则:
能一起匹配出来绝不一个个取值,就好比下面的a1c@32d 会先匹配出一组a1c 再匹配后面那组符合条件的32d 要是去掉@ 会把a1c32d全部返回在一组数上 能全部返回就不会一个个返回
非贪婪匹配:
能少取就别多取 实现就是在两次后面加一个问号?
<script type="text/javascript">
var reg = /\w+?/g; // w的取值区间是[0-9A-z_]
var str = "a1c@32d";
console.log(str.match(reg));
</script>
贪婪匹配会把a1c 32d以两组返回 非贪婪模式能少就不多 所以每次只返回一个

n+ 一次可以匹配1到无数个符合条件的值
<script type="text/javascript">
var reg = /\w+/g; // w的取值区间是[0-9A-z_]
var str = "a1c@32d";
console.log(str.match(reg));
</script>

n* 一次可以匹配0到无数个符合条件的值
<script type="text/javascript">
var reg = /\w*/g; // w的取值区间是[0-9A-z_]
var str = "abc";
console.log(str.match(reg));
</script>
光标在abc之前停留的时候会判断后面的数是否能识别 能识别就返回那个数
注意还有一个空串 这是因为abc选出后光标在c后面 还有一段逻辑距离
没有满足条件的值还会匹配出一个空字符出来
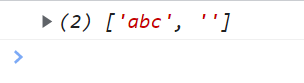
<script type="text/javascript">
var reg = /\d*/g; // d的取值区间是[0-9]
var str = "abc";
console.log(str.match(reg));
</script>
所以找不到符合条件的就会匹配四个空字符出来(因为有光标定位点 光标在a之前匹配不到就返回空 b之前也匹配不到返回空 c之后和c之后的光标定位点都返回空)

n? 一次可以匹配0到1个符合条件的值
所以这里的返回值都是单个单个返回
<script type="text/javascript">
var reg = /\w?/g; // w的取值区间是[0-9A-z_]
var str = "abc@123";
console.log(str.match(reg));
</script>
最后也是有一个空字符 最后一个光标定位点匹配不到就返回空

n{X} 几个几个匹配 凑不够指定个数的时候不匹配
<script type="text/javascript">
var reg = /\w{3}/g; // w区间[0-9A-z_] 3个3个匹配
var str = "abcadjladlajdajdlajason";
console.log(str.match(reg));
</script>
最后的on不足三位 不进行匹配

n{x,y} x-y个进行匹配 优先匹配y个 不足y个再匹配x个
<script type="text/javascript">
var reg = /\w{1,3}/g; // 这里{}后面也可以加? 非贪婪模式 只匹配一个
var str = "abcadjladlajdajdlajason";
console.log(str.match(reg));
</script>
能三个匹配就三个匹配 最后不足三位的地方也能匹配上

n{X,} 每次最少匹配x个符合条件的值
然后根据贪婪原则会优先匹配多的 那都是会把所有的数取出来的 都是全取出来了
<script type="text/javascript">
var reg = /\w{1,}/g;
var str = "abcadjladlaj@dajdlajason";
console.log(str.match(reg));
</script>
这里是加了@隔断了 所以取出了两组数 这个跟n+ n* 差不多

n$ 判断最后一位是否在取值区间,在则返回该值,不在则是null
<script type="text/javascript">
var reg = /\w$/g;
var str = "abc";
console.log(str.match(reg));
</script>

<script type="text/javascript">
var reg = /\w$/g;
var str = "abc@"; // 加个@
console.log(str.match(reg));
</script>
最后一位不满足\w条件 所以返回null

^n 匹配任何开头为n的字符串
<script type="text/javascript">
var reg = /^\w/g;
var str = "abc@";
console.log(str.match(reg));
</script>
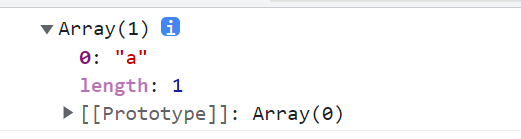
第一位不满足\w条件 所以返回null
<script type="text/javascript">
var reg = /^\w/g;
var str = "@abc"; // 头部加@
console.log(str.match(reg));
</script>

<script type="text/javascript">
var reg = /^abc$/g; // 以abc开头也以这个abc结尾
var str = "abcabc";
console.log(str.match(reg));
</script>
这里的以abc开头 以abc结尾的abc是同一个abc 不是两个 所以返回null 所以开头就是结尾 把内容限定死了

?=n 正向预查/正向断言:匹配任何其后紧接指定字符串n的字符串
<script type="text/javascript">
var reg = /a(?=b)/g;
var str = "abaaaa";
console.log(str.match(reg));
</script>
取出后面紧跟着b的a (只取出a 不取出b b只是修饰)
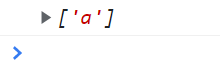
?!n 非正向预查:匹配任何其后没有紧接指定字符串n的字符串
<script type="text/javascript">
var reg = /a(?!b)/g;
var str = "abaaaa";
console.log(str.match(reg));
</script>
查出后面没有紧跟着b的a

练习
写一个正则表达式,检验字符串首或尾是否含有数字?
<script type="text/javascript">
var reg = /^\d|\d$/g; // 第一位或者最后一位是数字
// 首尾都满足就都取该位 \d一次只能取一位 别忘了
var str = "123abc123";
console.log(str.match(reg));
</script>

写一个正则表达式,检验字符串首尾是否都含有数字?
<script type="text/javascript">
// 第一位和最后一位是数字 中间取任意位任意数 (\s\S可取所有字符)
var reg = /^\d[\s\S]*\d$/g;
var str = "123abc123";
console.log(str.match(reg));
</script>
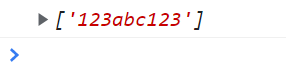
RegExp对象属性
| 属性 | 描述 | 火狐 |
|---|---|---|
| global | RegExp对象是否具有标志g。 | 1 |
| ignoreCase | RegExp对象是否具有标志i。 | 1 |
| lastIndex | 一个整数,标示开始下一次匹配的字符位置。 | 1 |
| multiline | RegExp对象是否具有标m。 | 1 |
| source | 正则表达式的源文本。 | 1 |
<script type="text/javascript">
var reg = /^\d[\s\S]*\d$/gmi;
var str = "123abc123";
console.log(str.match(reg));
</script>
有gmi 所以gmi相关的三个属性都返回true reg.source就是正则表达式的内容 lastIndex就是下一次匹配开始的位置 具体看后面结合reg.exec()使用
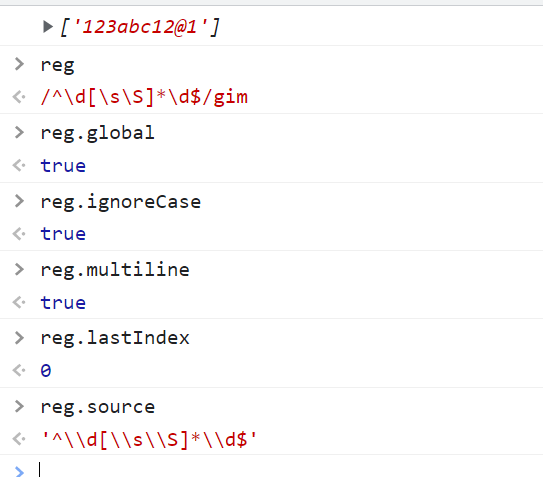
RegExp对象方法
| 方法 | 描述 | 火狐 |
|---|---|---|
| compile | 编译正则表达式 | 1 |
| exec | 检索字符串中指定的值。返回找到的值,并确定其位置。 | 1 |
| test | 检索字符串中指定的值。返回true或false。 | 1 |
<script type="text/javascript">
var reg = /^\d[\s\S]*\d$/gmi;
var str = "123abc12@1";
console.log(str.match(reg));
</script>
test
检索字符串中指定的值。返回true或false。
reg.compile 就是获取正则表达式的内容
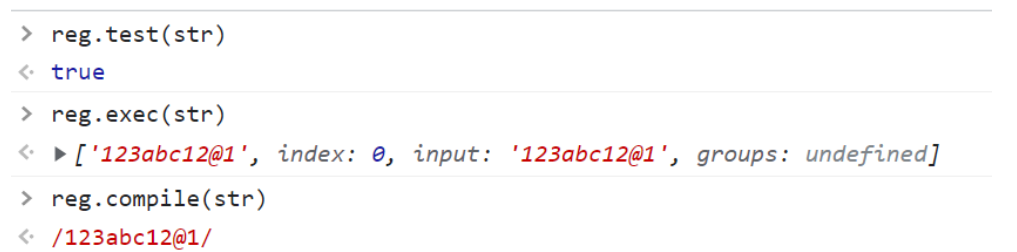
reg.exec();
lastIndex
lastIndex就是光标 lastIndex就是为了exec方法而存在的
<script type="text/javascript">
var reg = /ab/g;
var str = "abababab";
console.log(reg.lastIndex);
console.log(reg.exec(str));
console.log(reg.lastIndex);
console.log(reg.exec(str));
console.log(reg.lastIndex);
console.log(reg.exec(str));
console.log(reg.lastIndex);
console.log(reg.exec(str));
console.log(reg.lastIndex);
console.log(reg.exec(str));
console.log(reg.lastIndex);
console.log(reg.exec(str));
</script>
依次索引:
第一次取的是光标位置在0-1的ab(第一对) 取完之后光标在第二位上
第二次取的是光标2-3的ab(第二对)取完之后光标在第四位上
第三次取的是光标4-5的ab(第三对)取完之后光标在第六位上
第四次取的是光标6-7的ab(第四对)取完之后光标在第八位上
第五次取的时候光标在的位置在b后面 没有内容 所以匹配的是null
然后继续打印又重复从光标0-1开始匹配ab
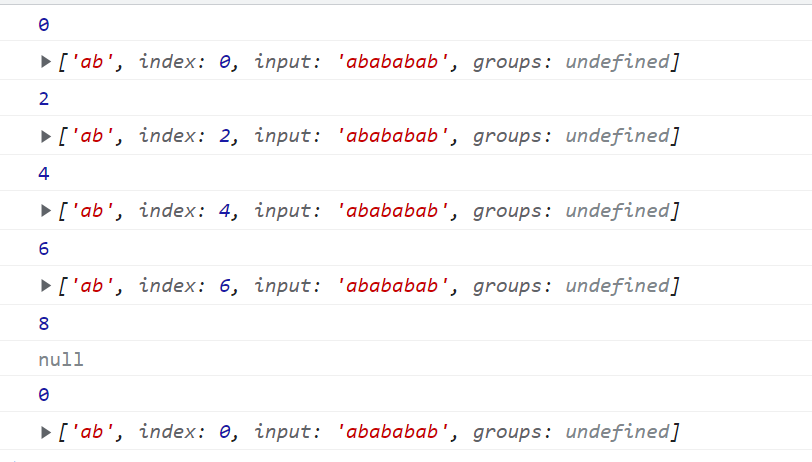
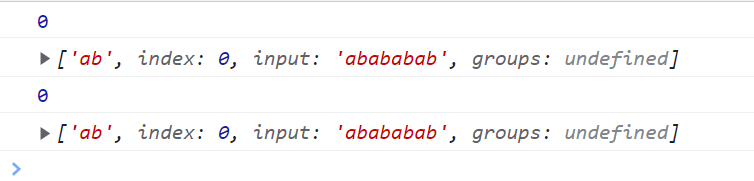
不加\g的话 lastIndex光标永远在第0位 永远从第0位开始索引
<script type="text/javascript">
// 不加\g的话 lastIndex光标永远在第0位 永远从第0位开始索引
var reg = /ab/;
var str = "abababab";
console.log(reg.lastIndex);
console.log(reg.exec(str));
console.log(reg.lastIndex);
console.log(reg.exec(str));
</script>
匹配xxxx形式的数据
四个一样的值都能匹配出来
(子表达式)\1 括号会记录子表达式里面的内容 然后通过\1反向引用第一个第一个子表达式里面的内容
// 匹配四个a
<script type="text/javascript">
var reg = /(\w)\1\1\1/g; // 注意 括号别忘了
var str = "aaaa";
console.log(reg.exec(str));
</script>

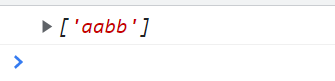
匹配aabb形式的数据
// 匹配aabb
<script type="text/javascript">
var reg = /(\w)\1(\w)\2/g; // b是引用第二个子表达式的内容 (\w){2}(\w){2} 这样写也可以
var str = "aabb";
console.log(reg.exec(str));
</script>
a是第一位子表达式内容 b是第二位子表达式内容

支持正则表达式的String对象方法
| 方法 | 描述 | 火狐 |
|---|---|---|
| search | 检索与正则表达式相匹配的值 | 1 |
| match | 找到一个或多个正则表达式的匹配 | 1 |
| replace | 替换与正则表达式匹配的子串 | 1 |
| split | 把字符串分割为字符串数组 | 1 |
match 找到一个或多个正则表达式的匹配
<script type="text/javascript">
var reg = /(\w)\1(\w)\2/g;
var str = "aabb";
// 注意是string方法 所以是str.match(reg) reg和str位置互换一下
console.log(str.match(reg));
</script>
加g 只返回匹配出的内容
不加g 返回的结果类似exec

search 检索与正则表达式相匹配的值
<script type="text/javascript">
var reg = /(\w)\1(\w)\2/g;
var str = "aabb";
console.log(str.search(reg));
</script>
返回的是匹配到数据所在的位置(光标在0位就匹配到了就返回0) 匹配不到数据就返回-1

<script type="text/javascript">
var reg = /(\w)\1(\w)\2/g;
var str = "eiqvaabb";
console.log(str.search(reg));
</script>
由于\1或者\2都是引用子表达式的内容 所以前提就是子表达式中的内容存在连续且重复 所以光标匹配到a时 光标所在位置是4(光标下标从0开始) 所以返回4

split 把字符串分割为字符串数组
<script type="text/javascript">
var reg = /\d/g; // 数字作为分隔符
var str = "ei1qva3ab5b";
console.log(str.split(reg));
</script>
情况比较复杂 可以自己多加练习

replace 替换与正则表达式匹配的子串
<script type="text/javascript">
var str = "aa";
console.log(str.replace("a", "b"));
</script>
非正则表达式的缺陷 只能访问一个 没有访问全局的能力 所以只能把第一个a替换成b 返回ba
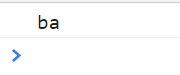
<script type="text/javascript">
var reg = /a/g; // 不写g依旧返回ba 因为不是全局
var str = "aa";
console.log(str.replace(reg, "b"));
</script>
返回bb 因为加g之后 具有全局访问能力 所以可以替换与正则表达式匹配的子串 所以返回bb

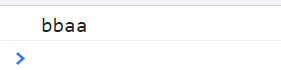
aabb形式的字符改成bbaa 方法一
<script type="text/javascript">
var reg = /(\w)\1(\w)\2/g; // 不写g依旧返回ba 因为不是全局
var str = "aabb";
// $1代表第一个子表的内容 $2代表第二个子表达式的内容
console.log(str.replace(reg, "$2$2$1$1"));
</script>
方法二
<script type="text/javascript">
var reg = /(\w)\1(\w)\2/g;
var str = "aabb";
// 第一个参数是匹配的内容 这里就是aabb 第二个参数是第一个子表达式的内容 第三个参数是第二个子表达式的内容
console.log(str.replace(reg, function ($,$1,$2) {
return $2 + $2 + $1 + $1; // 返回的字符串替换匹配内容
}));
</script>

toUpperCase() 把字符串变大写
toLowerCase() 把字符串变小写
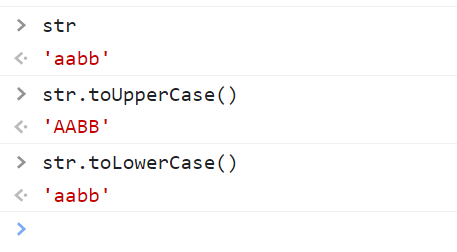
练习:
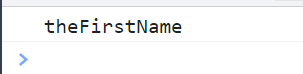
the-first-name 变成小驼峰式写法(theFirstName)
<script type="text/javascript">
var reg = /-(\w)/g; // 匹配-f和-n 把\w圈起来表示子表达式 然后通过$1引用
var str = "the-first-name";
console.log(str.replace(reg, function ($,$1) {
return $1.toUpperCase();
}));
</script>
注意 $1表示的是第一个子表达式的内容 而这个子表达式就包含了-f和-n 因为匹配了两次 所以function就执行了两次 所以一起变成大写返回了
转义字符补充
| 匹配值 | 写法 |
|---|---|
| \ | \\ |
| ? | ? |
| ( | \( |
| + | \+ |
| - | \- |
| * | \* |
都需要加转义字符 因为这些符号有特殊含义
练习
字符串去重
方法一
匹配内容分三次选出来 每次都用$1(\w内容) 也就是a和b和c去分别替换匹配出来的内容
<script type="text/javascript">
var reg = /(\w)\1*/g; // 反向引用一个或多个
var str = "aaaabbbbbbbbcccccc";
console.log(str.replace(reg, "$1"));
</script>
方法二: 也是返回的$1替换$
<script type="text/javascript">
var reg = /(\w)\1*/g;
var str = "aaaabbbbbbbbcccccc";
console.log(str.replace(reg, function ($,$1) {
return $1;
}));
</script>
把数据转换成科学计数法
10000000000 转换成100.000.000.00
<script type="text/javascript">
var reg = /\d{1,3}/g;//查1-3位数字以逗号做连接
var str = "10000000000";
console.log(str.match(reg).join(","));
</script>
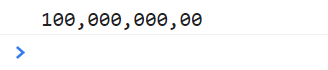
Doctype
1.渲染模式
在多年以前(IE6诞生以前),各浏览器都处于各自比较封闭的发展中(基本没有兼容性可谈)。随着WEB的发展,兼容性问题的解决越来越显得迫切,随即,各浏览器厂商发布了按照标准模式(遵循各厂商制定的统一标准)工作的浏览器,比如IE6就是其中之一。但是考虑到以前建设的网站并不支持标准模式,所以各浏览器在加入标准模式的同时也保留了混杂模式(即以前那种未按照统一标准工作的模式,也叫怪异模式)。
三种标准模式的写法
1.<!DOCTYPE html>
2.<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
3.<!DOCTYPE html PUBLIC "-//w3C//DTD XHTML 1.0Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
















 3957
3957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











