






探索机器学习的分类:监督学习、无监督学习、半监督学习与强化学习
引言
机器学习作为人工智能的核心领域之一,正在改变我们与世界互动的方式。它通过从数据中自动学习和改进模型,帮助我们解决复杂问题、提高效率,并推动技术进步。从智能推荐系统到自动驾驶汽车,机器学习的应用无处不在。在这篇文章中,我们将深入探讨机器学习的基本概念、分类以及其在光网络等领域中的具体应用,帮助读者更好地理解这一技术的重要性与未来发展潜力。
机器学习正在改变世界,也在改变未来
第一章:机器学习分类
机器学习是一种通过算法和统计模型,从数据中自动学习和识别模式的技术,而不需要显式编程。它使计算机能够从经验中学习,并根据所获得的知识做出决策或预测。机器学习可分为不同的类型,每种类型适用于不同的问题和场景,主要包括监督学习、无监督学习、半监督学习和强化学习。
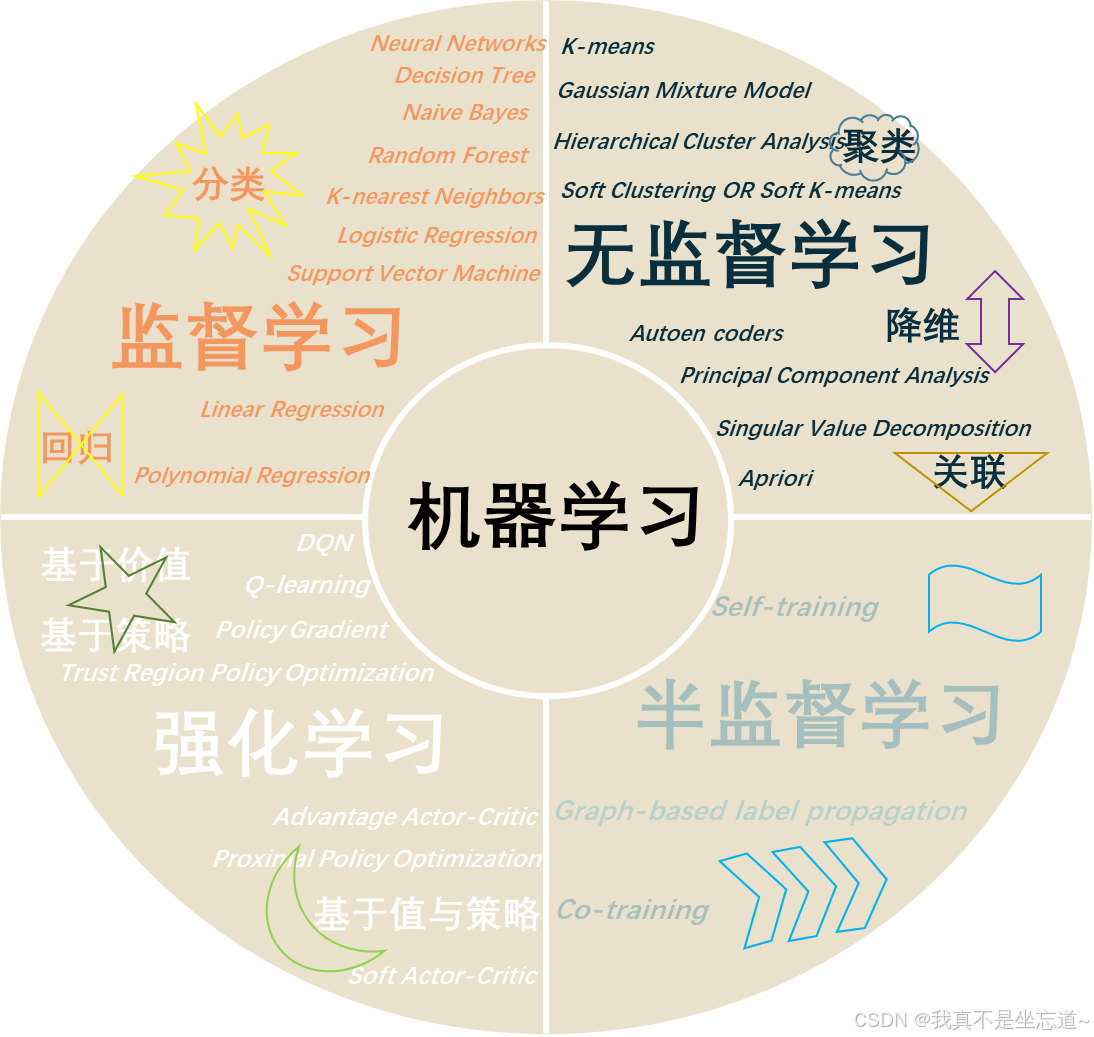
1.1 监督学习(Supervised Learning)
监督学习是一种基于已标注数据进行训练的机器学习方法。在训练过程中,模型会学习输入数据(特征)和输出标签(目标值)之间的关系,最终用于预测新数据的输出。常见的监督学习任务包括分类和回归。分类用于预测离散的、有限个类别或标签的目标,输出也是以类别如"0","1"作为标签进行区分。回归用于预测连续的目标,输出是一个连续的实数值。下面简单介绍了几种常用的分类和回归算法。
1.1.1分类
Naive Bayes:基于贝叶斯定理并假设特征之间条件独立,通过计算特征的概率来进行分类,任务常用于文本分类。
Neural Networks:模仿大脑神经元工作原理的算法,通过多个层级的神经元连接进行学习和预测,广泛用于图像、语音处理等复杂任务。
Decision Tree:通过构建二叉树模型进行分类,递归地将数据集划分为不同的特征子集,直观易理解。
Random Forest:通过构建多个决策树并综合其输出,引入了随机性来提高模型的鲁棒性并减少过拟合。
K-nearest Neighbors (KNN):基于距离度量进行分类,预测时根据与样本最近的K个点来决定类别。
Logistic Regression:通过使用Sigmoid函数将线性回归的输出映射到概率空间,逻辑回归用于二分类任务并预测样本属于某个类别的概率。
Support Vector Machine (SVM):通过找到最大化类别间隔的超平面,将数据分为不同类别,并可以处理线性不可分问题(基于核函数)。
1.1.2回归
Linear Regression:通过拟合一条直线来最小化预测值与真实值之间的误差,用于预测连续的数值目标。
Polynomial Regression:通过引入多项式特征,使用线性回归技术来拟合数据的非线性关系,实现对复杂数据模式的预测。
注:有些算法既可以用来做分类也可以用来做回归,甚至可以用到其它机器学习种类中,如神经网络。
1.2 无监督学习(Semi-Supervised Learning)
无监督学习用于处理未标注的数据。算法在没有明确的标签或目标值的情况下,分析数据中的模式和结构,包括聚类、降维和关联。聚类任务旨在将数据分为不同的组,降维旨在帮助简化数据集的复杂性,而关联则是发掘数据集中的关联规则。简单介绍下它们的典型代表算法。
1.2.1聚类
K-means:通过迭代地分配数据点到最近的质心并更新质心位置,将数据点分为K个不重叠的簇。
Gaussian Mixture Model (GMM):基于概率模型,假设数据点由多个高斯分布组成,计算每个数据点属于某个簇的概率,并使用期望最大化算法优化。。
Hierarchical Cluster Analysis:通过递归地将数据点合并(自底向上)或分割(自顶向下),逐步形成层次结构的簇,直到满足停止条件。
SoftClustering / Soft K-means:一种允许数据点属于多个簇的聚类方法,通过软分配计算每个点属于每个簇的概率。
1.2.2降维
Autoencoders:基于神经网络架构,通过将输入数据编码为低维表示并再解码回原始维度,学习数据的有效压缩表示和重建数据的核心特征。
Principal Component Analysis (PCA):通过线性变换,PCA将数据投影到方差最大的正交主成分方向上,减少维度的同时保留最多的数据信息。
Singular Value Decomposition (SVD):将矩阵分解为三个矩阵(U、Σ、V),SVD通过提取数据矩阵的主要模式进行降维或数据压缩。
1.2.3关联
Apriori:通过先找到频繁项集,然后基于这些频繁项集生成关联规则,Apriori算法利用"频繁项集的所有子集也必须是频繁的"这一性质来高效地发现数据中的关联规则。
1.3 半监督学习(Unsupervised Learning)
半监督学习结合了监督学习和无监督学习的特点。它在少量标注数据和大量未标注数据的基础上进行训练,通过利用未标注数据来提高模型的准确性。半监督学习特别适用于标注数据获取成本高昂的情况,常见应用场景有文本分类和图像识别。
Self-training:通过使用模型的初始预测结果来标记未标记的数据,自训练逐步扩展训练集,使用模型自信的预测结果作为新的训练数据进行迭代训练。
Co-training:通过在两个或多个不同特征视图上训练独立的分类器,协同训练在每一轮中使用一个分类器的高置信度预测结果为另一个分类器提供标记数据,互相提升学习效果。
Graph-based Label Propagation:通过构建一个图,节点表示数据点,边的权重表示相似度,标签传播算法逐步在图中传播已标记点的标签信息到未标记点,直到达到收敛。
1.4 强化学习(Reinforcement Learning)
强化学习是一种基于奖励和惩罚的学习方法,适用于在环境中通过试错来寻找最佳决策策略。强化学习的核心在于代理(Agent)与环境的交互,代理通过观察环境状态采取行动,并根据行动获得的奖励来调整策略。强化学习在游戏、机器人控制和资源分配等领域有广泛的应用。根据智能体学习策略的方式和优化目标的不同,可以分为基于值的强化学习、基于策略的强化学习和基于值与策略相结合的强化学习。
1.4.1基于价值
Q-learning:通过更新Q值来学习每个状态-动作对的价值,智能体基于Q值采取价值最大的动作,最终找到最优的决策策略。
DQN (Deep Q-Network):一种结合深度学习的Q-Learning算法,通过深度神经网络逼近Q值函数,解决高维状态空间中的 Q-learning 计算问题,适用于复杂环境。
在DQN的研究上,研究者们陆续提出了7种不同结构的DQN算法,将它们结合在一起,如葫芦兄弟合体般强大,起名叫做Rainbow DQN
1.4.2基于策略
Policy Gradient:直接优化智能体策略的强化学习方法,使用策略梯度来最大化期望回报,直接更新策略函数,通常更适用于连续动作空间的问题。
Trust Region Policy Optimization (TRPO):在策略梯度方法的基础上,通过限制策略更新的幅度,保证策略变化的稳定性与收敛性,防止过大的策略更新导致性能不稳定。
1.4.3基于价值和策略
Advantage Actor-Critic (A2C/A3C):结合了基于值和基于策略的方法,同时学习值函数和策略,通过优势函数来减少方差,加速了学习过程。A2C 为同步版本,A3C 为异步版本。
Proximal Policy Optimization (PPO):一种改进的策略优化算法,通过引入限制(如裁剪)保证策略更新的稳定性和效率,广泛应用于强化学习任务。
Soft Actor-Critic (SAC):一种基于最大熵的强化学习算法,兼顾探索和策略稳定性,通过最大化奖励和熵(不确定性)提高策略表现,适用于连续控制任务。
第二章:强化学习、无监督学习与监督学习的区别
每种学习范式在目标、应用场景和学习过程上都有显著的差异,理解它们之间的区别有助于更好地选择适合的技术来解决特定问题。接下来,我们将从学习目标、数据类型和应用场景等方面,探讨强化学习、无监督学习与监督学习这三类学习方法的区别。
注:半监督学习是监督学习和无监督学习的结合版
1. 学习目标
-
强化学习
强化学习的目标是让智能体通过与环境的交互,学习到一个最优策略,使其在给定环境中最大化累计奖励。智能体在每一步采取行动后,会从环境中获得奖励或惩罚,从而调整其行为。目标是最大化整个回合获得的总体累积奖励。 -
有监督学习
有监督学习的目标是根据标注好的训练数据,学习从输入到输出的映射关系。模型通过给定的输入(特征)和已知的标签(目标值)进行训练,来预测新数据的输出。目标是对给出的数据进行准确的预测或分类。 -
无监督学习
无监督学习的目标是通过分析数据中的模式、结构或相关性来学习数据的内在特征,而无需标签或目标值。目标是自动发现数据中的潜在模式或结构。
2. 数据类型
-
强化学习
数据在强化学习中是智能体与环境之间的交互序列。通常由状态、行动、奖励和下一个状态组成。数据是由系统交互生成的,不需要提前标注。数据类型是动态的,数据包括环境的状态、智能体的行动、环境返回的奖励等。 -
有监督学习
有监督学习需要大量标注好的训练数据集,数据类型通常是静态的,预先收集并标注好。数据集包括输入样本(特征)和对应的输出标签。 -
无监督学习
无监督学习不需要任何标签,只使用未标注的原始数据。数据类型通常是静态的,模型通过发现数据的内在结构或分布来进行学习,数据集包括了未标注的数据。
3. 采用策略
-
强化学习
强化学习强调决策和策略优化,智能体需要根据当前状态选择行动,随着时间推移最大化累积回报。每一步决策都会影响未来的状态和回报,因此有长期规划的特性。强化学习的策略是动态调整的,策略主要解决决策和控制问题。 -
有监督学习
有监督学习的目标是学到一个静态的映射关系,从输入到输出,模型只需要根据当前样本预测其输出,不需要做长期规划。监督学习的策略是学习输入到输出的直接映射。 -
无监督学习
无监督学习不涉及策略选择或行为决策。它更多关注数据的聚类、降维或关联,主要是从数据中发现潜在模式。策略用于寻找数据中的模式或隐含结构。
4. 应用场景
-
强化学习
适用于有明确目标、需要持续决策的场景,特别是当环境变化时,智能体需要自适应调整行为。典型应用包括机器人控制、自动驾驶、游戏对抗、AlphaGo、通信网络优化、智能交通管理等。 -
有监督学习
只要有充足的标注数据,几乎所有的预测任务都可以使用有监督学习。典型应用包括图像识别、文本分类、语音识别、疾病诊断、股票价格预测、文本情感分析等。 -
无监督学习
适用于数据未标注或无法获取标签的场景,常用于数据的探索性分析。典型应用包括市场细分、客户聚类、异常检测、推荐系统等。
5. 优缺点
-
强化学习
能在动态环境中做出最优决策,适用于长期回报优化;可以处理复杂的序列决策问题。但是数据效率低,需要大量交互;且训练时间长;有时会面临“探索与利用”问题的困扰,模型的稳定性和泛化能力不足。
-
有监督学习
对已标注的数据能提供精确的学习指导,模型训练效果直观,准确性高,适用于许多实际问题。但需要大量标注数据,数据标注成本高;在标签不完全或不准确的情况下效果不佳。
-
无监督学习
不需要标注数据,适合探索性数据分析;可用于发现隐藏模式和结构。但是模型评估标准模糊,难以直接评估效果;同时算法对参数和初始化较为敏感。
总结
本文对机器学习的四大类-监督学习、无监督学习、半监督学习和强化学习进行了介绍,并列举了每个类别下的经典算法。同时,文章对监督学习、无监督学习、强化学习算法进行了深入的比较,分析了它们的适用性和优缺点等。希望通过这一系列的分析,能够加深大家对机器学习各类方法的理解,帮助大家在实际问题上做出合适的算法选择。

















 838
838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









