






背景
Datawhale联合科大讯飞、阿里云天池平台开设了机器学习、深度学习、AI for Science 三个方向的夏令营学习。其中,深度学习实践-NLP方向以讯飞平台“基于论文摘要的文本分类与关键词抽取挑战赛” (https://challenge.xfyun.cn/topic/info?type=abstract-of-the-paper&ch=ymfk4uU)为学习命题,并提供了一些解题代码供夏令营的初学者、学习者学习研究。本笔记在此学习过程中产出。
赛题背景:医学领域的文献库中蕴含了丰富的疾病诊断和治疗信息,如何高效地从海量文献中提取关键信息,进行疾病诊断和治疗推荐,对于临床医生和研究人员具有重要意义。赛题一个目的是根据包含标题、作者、摘要、关键词的数据集变量构建模型判断文献是否为医学领域文献,为二分类问题。
学习任务
| 任务一:(2023.8.16-2023.8.18) 1. 阅读赛题信息,理解赛题解题思路 2. 跑通机器方法Baseline,获得自己的成绩
3. 提交任务一打卡,查看个人成绩排行榜 |
ps:目前编辑任务一笔记,任务二、三根据情况在本文增加记录或另起文章。
题目解题思路
任务一采取特征提取方法结合机器学习模型对本文进行分类。所以下面提供特征提取+机器学习的解题思路(在学习资料的基础上,增加了一些自己的理解):
1. 数据预处理:首先,对文本数据进行预处理,包括文本清洗(如去除特殊字符、标点符号)、分词等操作。可以使用常见的NLP工具包(如nltk或SpaCy)来辅助进行预处理。本文会介绍一点nltk的使用。此外,数据处理还包括缺失值处理、异常值处理、数据分桶、特征归一化/标准化等流程。
2. 特征提取:文本特征提取的目的是为了将文本转换成向量,这样才能应用于模型训练。TF-IDF(词频-逆文档频率)或BOW(词袋模型)方法是进行文本特征提取的两个经典方法。TF-IDF(词频-逆文档频率)或BOW(词袋模型)方法可以分别用scikit-learn库的TfidfVectorizer和CountVectorizer来实现。
3. 构建数据集:在机器学习研究中经常将数据划分为训练集、验证集和测试集三部分。训练集用于训练模型,以简单的线性模型为例,训练集的作用就是用来训练模型得到模型参数,即模型得到建立。验证集用于在训练过程中检验模型的状态,收敛情况。验证集通常用于调整超参数,根据几组模型验证集上的表现决定哪组超参数拥有最好的性能。测试集用来评估该模型对未知样本进行预测时的精确度,即评估得到的模型的泛化能力。在比赛中,测试集就是不提供分类结果的数据集,这样参赛者提交预测结果后,官方可以根据真实结果验证参数者的模型精确度。
4. 选择机器学习模型:对于二分类问题,可以采取一些经典的分类机器学习模型,如逻辑回归、决策树、朴素贝叶斯、支持向量机、AdaBoost集成模型等。学习过程中可以多次提交,因此可以尝试多个模型来观察最终效果。
5. 模型训练和验证:选择模型后,则进行模型训练。训练后需要验证结果,即模型的预测效果。一般我们自己操作时,测试集的分类已知的情况下,我们可以根据准确率、精确率、召回率、F1值等评估指标来得到预测效果。但比赛过程中,官方会自己定义指标,这个比赛采用的评价指标是F1值。
6.调参优化:机器学习通常包含较多参数,选择不同参数可以得到不同的结果,例如支持向量机的gap大小等。
代码实现分析
在代码实现上,夏令营学习资料提供一键运行的代码模板,可供初学者实现解题思路以及理解代码。代码如下所示。这里先放上代码,一方面是可以供学习者对解题思路有直观理解,并实现运行代码,学会在编程平台上操作,另一方面是后面我将逐一根据前面的解题思路分析代码,并在该模板基础上提供实现思路里说到的其他一些模型的代码。
# 导入pandas用于读取表格数据
import pandas as pd
# 导入BOW(词袋模型),可以选择将CountVectorizer替换为TfidfVectorizer(TF-IDF(词频-逆文档频率)),注意上下文要同时修改,亲测后者效果更佳
from sklearn.feature_extraction.text import CountVectorizer
# 导入LogisticRegression回归模型
from sklearn.linear_model import LogisticRegression
# 过滤警告消息
from warnings import simplefilter
from sklearn.exceptions import ConvergenceWarning
simplefilter("ignore", category=ConvergenceWarning)
# 读取数据集
train = pd.read_csv('./基于论文摘要的文本分类与关键词抽取挑战赛公开数据/train.csv')
train['title'] = train['title'].fillna('')
train['abstract'] = train['abstract'].fillna('')
test = pd.read_csv('./基于论文摘要的文本分类与关键词抽取挑战赛公开数据/testB.csv')
test['title'] = test['title'].fillna('')
test['abstract'] = test['abstract'].fillna('')
# 提取文本特征,生成训练集与测试集
train['text'] = train['title'].fillna('') + ' ' + train['author'].fillna('') + ' ' + train['abstract'].fillna('')+ ' ' + train['Keywords'].fillna('')
test['text'] = test['title'].fillna('') + ' ' + test['author'].fillna('') + ' ' + test['abstract'].fillna('')
vector = CountVectorizer().fit(train['text'])
train_vector = vector.transform(train['text'])
test_vector = vector.transform(test['text'])
# 引入模型
model = LogisticRegression()
# 开始训练,这里可以考虑修改默认的batch_size与epoch来取得更好的效果
model.fit(train_vector, train['label'])
# 利用模型对测试集label标签进行预测
test['label'] = model.predict(test_vector)
# 因为任务一并不涉及关键词提取,而提交中需要这一行所以我们用title列填充Keywords列
test['Keywords'] = test['title'].fillna('')
# 生成任务一推测结果
test[['uuid', 'Keywords', 'label']].to_csv('submit_task1.csv', index=None)数据处理
数据处理前,先导入数据。这里使用pandas库的read_csv函数导入,一般pandas库安装时是自动安装的,在 AI studio 也是预装好的,所以只要做import就行。赛题提供train数据集,即给参赛者用于训练,此外提供testB数据集作为测试集。下面导入这两个数据集
import pandas as pd
train = pd.read_csv('/home/aistudio/data/data231041/train.csv')
test = pd.read_csv('/home/aistudio/data/data231041/testB.csv')代码模板中导入数据后就进行处理了,因为原作者是了解数据集构成的,但一般建议导入后先观察数据集具体内容,可以只输出前五行。
train.head(5)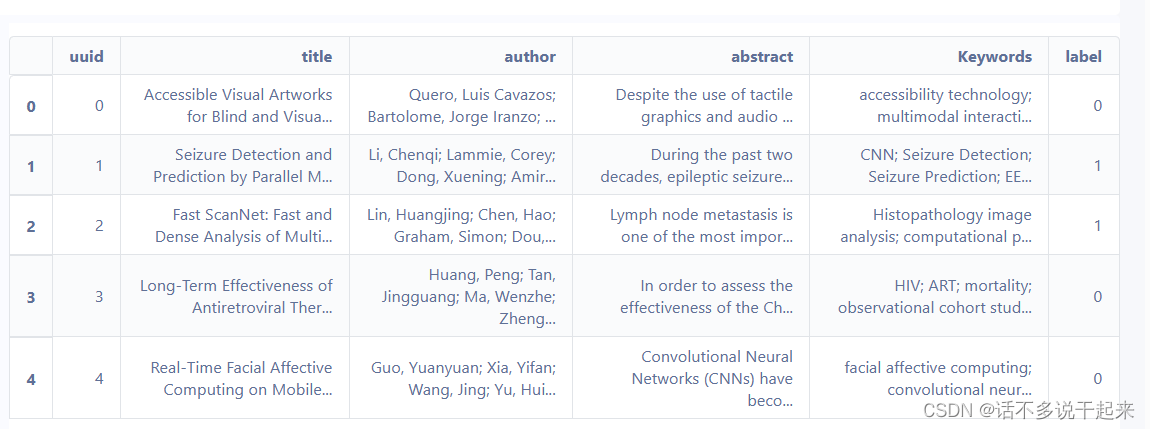
test.head(5)
可以看到训练集有题目、作者、摘要、关键词、标签五个变量;测试集包含题目、作者、摘要三个变量。实际上科大讯飞比赛的任务包含文本分类和获取关键词两个任务,所以测试集没有关键词、标签两个变量。
分类问题一般在各类别数量比较均匀的情况下才能依靠机器学习得到较好的预测。所以可以先观察两个分类分别的数量,代码如下:
print(train["label"].value_counts())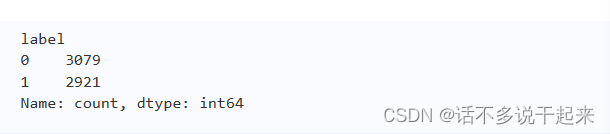
可以看到训练集中医学领域文章和非医学领域文章的样本数量差不多,数据平衡。在一般数据处理中,若两类数量差距较大,一些研究者会采取一些处理方法来使得两者数量关系达到一致。
对于不平衡数据处理实践,可看https://blog.csdn.net/weixin_45734379/article/details/117283496
数据处理还包括缺失值处理、异常值处理、数据分桶、特征归一化/标准化等流程。这里文本处理需要将文本转换成向量,放在了特征提取了,所以这里只简单介绍一下缺失值处理。当数据存在缺失时,最简单的是可以将缺失值填充为空值。对train和test的各个字段进行处理后拼接,代码如下
train['text'] = train['title'].fillna('') + ' ' + train['author'].fillna('') + ' ' + train['abstract'].fillna('')+ ' ' + train['Keywords'].fillna('')
test['text'] = test['title'].fillna('') + ' ' + test['author'].fillna('') + ' ' + test['abstract'].fillna('')另一方面,在文本数据中,特殊字符和标点符号不存在信息,所以可以在文本清洗时去除特殊字符和标点符号。在一键运行的代码中有写到nltk库的安装,但后面没运用到,所以我就自学了一下用nltk简单文本清洗的内容。例如运用nltk.tokenize可以对文本运行分词(更多可看https://zhuanlan.zhihu.com/p/137402283)
from nltk.tokenize import word_tokenize
input_str = "Today's weather is good, very windy and sunny, we have no classes in the afternoon,We have to play basketball tomorrow."
tokens = word_tokenize(input_str)nltk库可以使用pip安装,但注意在 AI studio 中pip默认从清华镜像中安装,会报错,所以这里换成阿里云镜像源:
!pip install nltk -i https://mirrors.aliyun.com/pypi/simple/ps:我还使用过豆瓣镜像,但安装时会卡在 regex的获取那一步,这个是在 AI studio 会出现的问题,不会报错,会一直卡在那里,需要手动中断,可以注意一下。
特征提取
TF-IDF(词频-逆文档频率)或BOW(词袋模型)方法是进行文本特征提取的两个经典方法。
基于BOW方法的特征提取
其中模板使用的就是基本BOW的特征提取。词袋模型最初被用在文本分类中,将文档表示成特征矢量。它的基本思想是假定对于一个文本,忽略其词序和语法、句法,仅仅将其看做是一些词汇的集合,而文本中的每个词汇都是独立的。简单说就是讲每篇文档都看成一个袋子(因为里面装的都是词汇,所以称为词袋,Bag of words即因此而来),然后看这个袋子里装的都是些什么词汇,将其分类。如果文档中猪、马、牛、羊、山谷、土地、拖拉机这样的词汇多些,而银行、大厦、汽车、公园这样的词汇少些,我们就倾向于判断它是一篇描绘乡村的文档,而不是描述城镇的。这里以实践为主,如果想详细了解可以点词向量之词袋模型(BOW)详解_bow词袋模型_Elenstone的博客-CSDN博客。
词袋模型首先会进行分词,在分词之后,通过统计每个词在文本中出现的次数,我们就可以得到该文本基于词的特征,如果将各个文本样本的这些词与对应的词频放在一起,就是我们常说的向量化。在这里可以使用sklearn库中的CountVectorizer来实现。
若未安装sklearn库,可如下安装
pip install scikit-learn
安装后便可从中导入CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer具体实践:
vector = CountVectorizer().fit(train['text'])
train_vector = vector.transform(train['text'])
test_vector = vector.transform(test['text'])基于TF-IDF方法的特征提取
TF-IDF是Term Frequency - Inverse Document Frequency的缩写,即“词频-逆文本频率”。它由两部分组成,TF和IDF。
词频(Term Frequency, TF)即词的频率,表示词条项在一个文档中出现的频率。
逆向文档频率(inverse document frequency, IDF)是一种度量词条项在文档中重要性的方式。IDF的原理是对于某一个特征词条项,包含此词条项的文档数量越少,此词条项就具有越强的文档类别特征。公式:
其中为t词条项的逆文档频率,
为所有文档数量,
为文档频率,t词条项的所有文本的数量。需要强调的是,在具体计算过程中,常常会将分母+1,防止出现词条项不在语料库中而造成分母为0的现象。
TF-IDF的使用跟BOW一样,更改对应的代码便可。
from sklearn.feature_extraction.text import TfidfVectorizer
vector = TfidfVectorizer().fit(train['text'])
train_vector = vector.transform(train['text'])
test_vector = vector.transform(test['text'])构建数据集
赛题所给数据集分为训练集和测试集,若我们只考虑分成训练集和测试集进行研究,那可以不再划分数据集,直接用官方给的数据集进行研究。但若想划分为训练集、验证集和测试集三部分进行研究,则可以把训练集进行划分。
from sklearn.model_selection import train_test_split
trian_data, eval_data = train_test_split(data, test_size = 0.2)上面代码表示从训练集中抽取20%的数据用来做测试集。而且shuffle默认为true,所以这里为打乱数据中从中抽取20%,即可理解为随机抽取20%。
当然上面是简单划分做验证,但实际上还可以使用K折交叉验证法。多次划分采取平均值的方式来衡量模型效果。可以用来挑选参数。
选择机器学习模型
原代码采用逻辑回归模型进行研究,但对二分类问题可以采用决策树、支持向量机、集成模型Adaboost和朴素贝叶斯等其他机器学习方法。这些模型都可以用sklearn包调用,实现简单,下面一一实践。
决策树模型
使用sklearn包,只需要更改导入的模型代码以及训练代码,将逻辑回归部分替换即可。
# 导入决策树模型
from sklearn.tree import DecisionTreeClassifier
#模型训练
model = DecsionTreeClassifier()运行后得到返回的分数如下,显示结果未优于逻辑回归。

支持向量机
同理,更改对应代码
# 导入支持向量机
from sklearn.svm import SVC
# 模型训练
model = SVC(gamma='scale', C=1.0, decision_function_shape='ovr', kernel='rbf')运行分数:
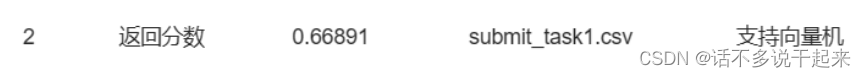
Adaboost模型
# 导入Adaboost模型
from sklearn.ensemble import AdaBoostClassifier
# 模型训练
model = AdaBoostClassifier(n_estimators=10)运行分数:

朴素贝叶斯
# 导入朴素贝叶斯
from sklearn.naive_bayes import ComplementNB
# 训练模型
model = ComplementNB()
运行分数

可以看到这之中朴素贝叶斯的分数最高。
ps:由于作者对机器学习模型比较熟悉,有基础,就没有过多介绍模型,更聚焦于不同模型在这个数据集的表现。所以这里写了简单代码,笔记二直接打算进军深度学习。
模型预测与结果输出
在这方面,我没对原代码进行修改。预测上,运用sklearn库后,只需要输入代码model.predict(训练集)即可得到预测分类。唯一需要注意的是test数据集的输出是除了类别还有增加一列关键词列,这是由于比赛平台原来还有一个提取关键词任务。在里面,原作者用“title”列填充了关键词列。
# 利用模型对测试集label标签进行预测
test['label'] = model.predict(test_vector)
# 因为任务一并不涉及关键词提取,而提交中需要这一行所以我们用title列填充Keywords列
test['Keywords'] = test['title'].fillna('')
# 生成任务一推测结果
test[['uuid', 'Keywords', 'label']].to_csv('submit_task1.csv', index=None)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









