






背景
Datawhale联合科大讯飞、阿里云天池平台开设了机器学习、深度学习、AI for Science 三个方向的夏令营学习。其中,深度学习实践-NLP方向以讯飞平台“基于论文摘要的文本分类与关键词抽取挑战赛” (2023 iFLYTEK A.I.开发者大赛-讯飞开放平台)为学习命题,并提供了一些解题代码供夏令营的初学者、学习者学习研究。本笔记在此学习过程中产出。
赛题背景:医学领域的文献库中蕴含了丰富的疾病诊断和治疗信息,如何高效地从海量文献中提取关键信息,进行疾病诊断和治疗推荐,对于临床医生和研究人员具有重要意义。赛题一个目的是根据包含标题、作者、摘要、关键词的数据集变量构建模型判断文献是否为医学领域文献,为二分类问题。该笔记为学习笔记3。
学习任务
任务三:
1. 跑通大模型方法Topline,获得自己的成绩
2. 提交任务三打卡,查看个人成绩排行榜
大模型实践
大模型是指在自然语言处理领域中,使用大型神经网络来进行文本分析和生成的大型语言模型。这些模型通常包括多个训练好的神经网络,可以处理长文本、复杂句子和语法结构等复杂情况。大模型的优点在于能够处理长文本和上下文信息,可以自动地从原始数据中提取出知识和意图,并且可以经过微调来适应特定的任务。但是,大模型的训练和部署通常需要大量的计算资源和时间,并且需要进行专门的数据预处理和数据增强,以提高模型的性能和泛化能力。
Datawhale 在提供的学习资料时就已经处理好了基于比赛题目用于大模型的训练执行文件以及预测代码。所以跑通只需要按提供的流程下载和运行就能顺利跑通,主要是目前结果不是很稳定。下面先记录跑通流程。
1. 完成服务器的部署后,在终端输入下面代码,下载 clone 微调脚本
git clone https://github.com/KMnO4-zx/xfg-paper.git执行成功:
2. 下载 chatglm2-6b 模型,输入
git clone https://huggingface.co/THUDM/chatglm2-6b执行成功:
这里需要注意看一下 tokenizer.model、pytorch_model-00001-of-00007.bin、pytorch_model-00002-of-00007.bin、pytorch_model-00003-of-00007.bin、pytorch_model-00004-of-00007.bin、pytorch_model-00005-of-00007.bin、pytorch_model-00006-of-00007.bin、pytorch_model-00007-of-00007.bin 这几个文件是否下载成功,一些教程显示直接下载中,实际上这几个文件并没有真正跟随下载,需要将其删除后再单独下载。但我这里没有出现这种情况。如果遇见这种情况,先删除文件
cd ./chatglm2-6b/
rm tokenizer.model
rm *.bin删除后重新依次下载
wget https://huggingface.co/THUDM/chatglm2-6b/resolve/main/tokenizer.model
wget https://huggingface.co/THUDM/chatglm2-6b/resolve/main/pytorch_model-00001-of-00007.bin
wget https://huggingface.co/THUDM/chatglm2-6b/resolve/main/pytorch_model-00002-of-00007.bin
wget https://huggingface.co/THUDM/chatglm2-6b/resolve/main/pytorch_model-00003-of-00007.bin
wget https://huggingface.co/THUDM/chatglm2-6b/resolve/main/pytorch_model-00004-of-00007.bin
wget https://huggingface.co/THUDM/chatglm2-6b/resolve/main/pytorch_model-00005-of-00007.bin
wget https://huggingface.co/THUDM/chatglm2-6b/resolve/main/pytorch_model-00006-of-00007.bin
wget https://huggingface.co/THUDM/chatglm2-6b/resolve/main/pytorch_model-00007-of-00007.bin以上就完成了所有文件的下载,下载过程可能会多次出现连接失败的情况,多次重复操作直至连接成功开始下载即可。
3. 安装符合的依赖库,在 xfg-paper 目录下的 requirements.txt 已列举了需要的清单,执行下载安装即可
#如果进行了单独安装tokenizer等文件,记得先 cd - 切换到原工作空间目录
cd ./xfg-paper/
pip install -r requirements.txt这里需要注意的是我们部署阿里服务器时,选择了 torch 1.12 的版本,跟要求里 torch 2.0 不一致,所以安装时会提示,但可以不管,因为这里选择 torch 2.0 是为了提高效率,使用非 torch 2.0 也可以运行的。我这里也尝试了去实例里更改配置,但发现官方最高就是 torch 1.12,所以就没有更改了。
4. 开始训练前先确认 xfg_train.sh 中的模型目录 model_name_or_path 是否正确,在服务器中可以直接双击文件打开,也可以使用 vim xfg_train.sh 打开文件。
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--model_name_or_path ../chatglm2-6b \ 本地模型的目录
--stage sft \ 微调方法
--use_v2 \ 使用glm2模型微调,默认值true
--do_train \ 是否训练,默认值true
--dataset paper_label \ 数据集名字
--finetuning_type lora \
--lora_rank 8 \ LoRA 微调中的秩大小
--output_dir ./output/label_xfg \ 输出lora权重存放目录
--per_device_train_batch_size 4 \ 用于训练的批处理大小
--gradient_accumulation_steps 4 \ 梯度累加次数
--lr_scheduler_type cosine \
--logging_steps 10 \ 日志输出间隔
--save_steps 1000 \ 断点保存间隔
--learning_rate 5e-5 \ 学习率
--num_train_epochs 4.0 \ 训练轮数
--fp16 是否使用 fp16 半精度 默认值:False注:上面代码加注释是为了笔记记录,原文件不可加注释,且最后一个参数最后不能加" \ "。
在下载的文件模型目录为 ../chatglm2-6b。如果按照教程走,那么这个目录是不需要更改的。因为按流程的话,chatglm2-6b 和 xfg-paper 都在空间目录下,而在这一步时,当前目录在 xfg-paper 目录下," ./ " 表示当前目录,但要访问 chatglm2-6b 要返回上一级目录,所以使用 “ ../ ”(没想到刚学的 linux 操作在这里派上了用场)。如果不是自选的安装目录,或者是本地运行,需要更改。
在 linux 系统(服务器也是),进入 vim 后,没有问题的话,就在界面下输入“ :q " 退出即可。若要更改,定位到 model_name_or_path 后面,按 " i "后进行插入模式,就可以更改和删除了,更改后,按 " Esc " 键退出插入模式,然后输入 “ :wq " 保存退出。(注意是英文输入法)
确认目录更改正确后,终端执行
# 确定当前目录在 xfg-paper下后执行
sh xfg_train.sh训练较久,耐心等待。
5. 加载权重,进行预测。运行 xfg-paper 目录下的 submit_demo.py 文件。
顺利完成以上流程,便已成功跑通了大模型 Topline 。
一些应用尝试
打开 chatglm2-6b 聊天功能页面
上面介绍的是已知配置得很完善的代码了。所以我在思考如果我只是拿到官方的文件,我该如何应用 chatglm2-6b。简单开始的话,那就是配置 chatglm2-6b 聊天功能页面。所以下面先简述一下如何打开 chatglm2-6b 聊天功能页面。
1. 下载文件包
git clone https://github.com/THUDM/ChatGLM2-6B.git下载后打开 ChatGLM-6B 目录下的 web_demo.py 文件,修改导入模型的目录
tokenizer = AutoTokenizer.from_pretrained("/mnt/workspace/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("/mnt/workspace/chatglm2-6b", trust_remote_code=True).cuda()以及修改最后一行代码为:
demo.queue().launch(server_port=6006,share=False, inbrowser=True)然后关闭保存。保存后,在终端输入运行 web_demo.py 文件
python web_demo.py得到下面结果即为运算成功

此时结果出现一个链接,点击进入即可,页面如下,可以进行问答。
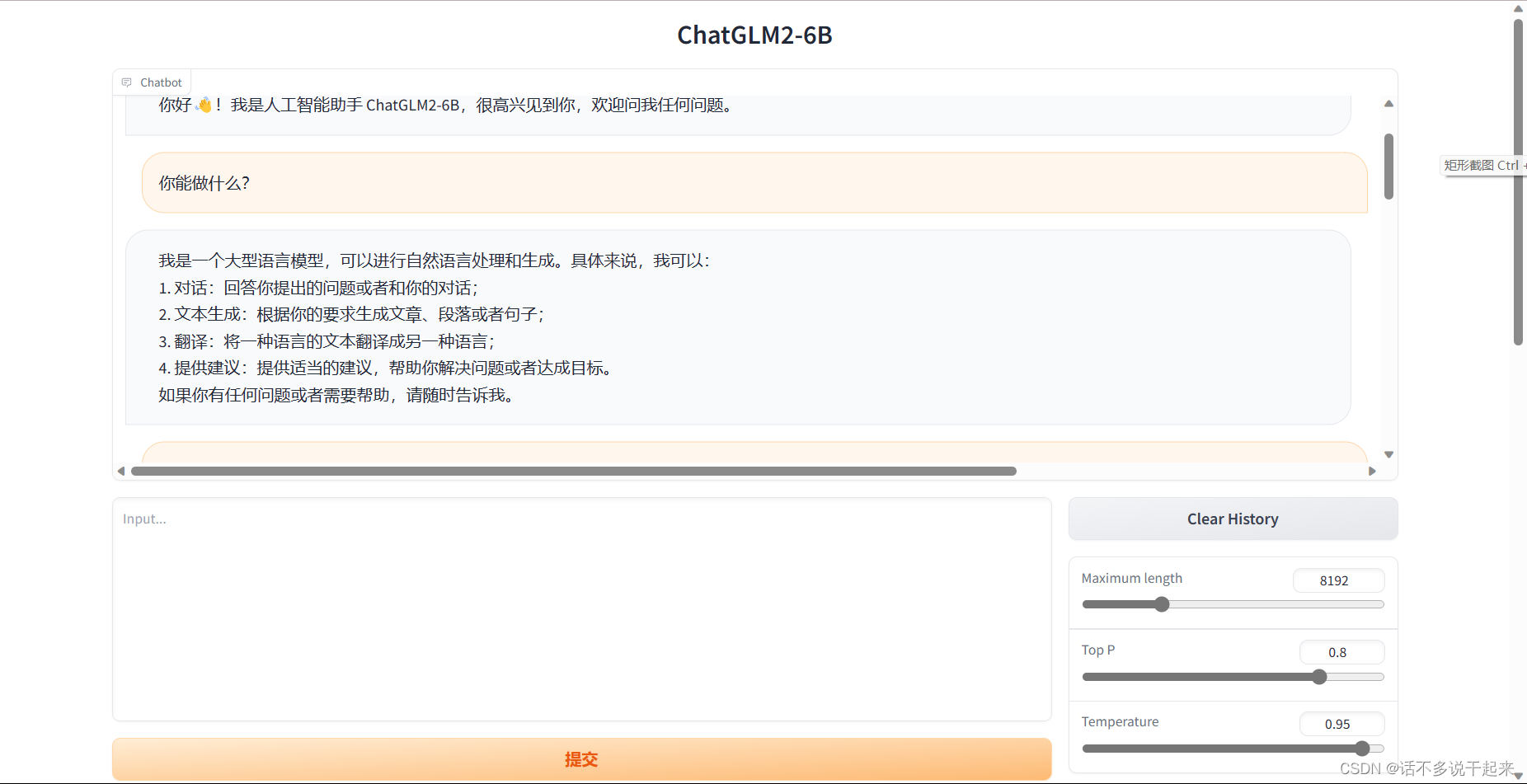
比如你还可以问 TA 怎么运行大模型的 train.sh 文件,TA 的回答如下:
=======================================================================
train.sh 是训练一个语言模型的脚本,通常需要使用深度学习框架来运行。以下是使用在 Ubuntu 和 TensorFlow 2.x 上的基本步骤:
1. 安装必要的依赖项:
sudo apt update
sudo apt install python3-pip
pip3 install torch torchvision
pip3 install transformers
1. 获取训练数据:
如果你的数据集已经准备好了,可以使用以下命令来读取数据:
sudo tar -xvf train.tar.gz
如果你的数据集没有准备好的话,需要先进行数据清洗和准备,比如去除停用词、特殊字符等。
1. 准备数据:
确保你的数据是准备好了的,并且所有文本数据都是合理的、具有代表性的。如果你的数据集很大,你可以使用 train.sh 中的 --max_seq_length 参数来限制每次训练的最大序列长度。
1. 训练模型:
运行以下命令来训练模型:
python3 train.sh --model-parallel --num-layers 12 --hidden-size 768 --num-attention-heads 12 --batch-size 16 --seq-length 512 --lr 0.001 --lr-decay-style cosine --num-warmup-steps 400000 --num-training-steps 1000000
这个命令中,--model-parallel 表示使用分布式训练,--num-layers 表示神经网络的层数,--hidden-size 表示隐藏层的神经元数,--num-attention-heads 表示注意力头数,--batch-size 表示每次训练的批量大小,--seq-length 表示每次训练的序列长度,--lr 表示学习率,--lr-decay-style cosine 表示衰减策略,--num-warmup-steps 表示预热步骤,--num-training-steps 表示训练步骤。
1. 评估模型:
训练完成后,你可以使用以下命令来评估模型的性能:
python3 train.sh --model-parallel --num-layers 12 --hidden-size 768 --num-attention-heads 12 --batch-size 16 --seq-length 512 --lr 0.001 --num-evaluation-steps 1000000
这个命令中,与训练时相同的参数,但是评估使用了更大的批量大小,并且去掉了训练步骤。
注意:在运行训练和评估命令时,请确保你的电脑有足够的计算资源来完成训练和评估。
希望这些步骤能够帮助你运行 train.sh 脚本。
=========================================================================
从上面可以看出 chatglm2-6b 问答还是很强大的。
关于 P-tuning v2微调
在学习资料里,使用的是 lora 微调,所以我就想如果我能用 P-tuning 微调的话,那我就真的掌握了其应用,所以我就去看了资料,首先需要下载的也是前面打开 chatglm2-6b 聊天页面的文件包以及模型包,前面都下载好了。在下载好的 ChatGLM2-6B 目录下有一个 ptuning 目录,目录下有 train.sh 文件
PRE_SEQ_LEN=128
LR=2e-2
NUM_GPUS=1
torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \
--do_train \
--train_file AdvertiseGen/train.json \
--validation_file AdvertiseGen/dev.json \
--preprocessing_num_workers 10 \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path /mnt/workspace/chatglm2-6b \
--output_dir output/adgen-chatglm2-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 128 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 16 \
--predict_with_generate \
--max_steps 3000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 4首先需要将 train.sh 文件应用到我们所要训练的数据集上,需要 json 格式(前面 xfg 作者已经创建好了 train.json),所以可以将其更改到对应 train_file 的位置,以及更改对应的prompt_column 和 response_column。然后就是 “torchrun ......." 语句的报错问题,可以知道官方作者是希望通过这来实现多卡训练,但我配置的是单卡,所以这个地方我也做了更改,不过需要注意,删除 “torchrun ......." 语句后,看似在这个文件中 NUM_GPUS 变量没有用到了,但实际上 main.py 文件里用到,所以不能删掉。另外,就是没有验证集的话,可以将 “--validation_file ...." 这一行去掉,当然也可以参考 train.json 的构建方法,从训练集中抽一部分去构建 test.json,所以主要更改这两部分:
CUDA_VISIBLE_DEVICES=0 python main.py \
--do_train \
--train_file ./data/paper_label.json \ --prompt_column input \
--response_column output \prompt 和 response 根据构建的数据量输入和输出的标签更改。
修改完毕后,执行该文件即可。
下面进行预测推理,一开始我想的也是直接用官方的 evaluate.sh 文件,文件打开如下
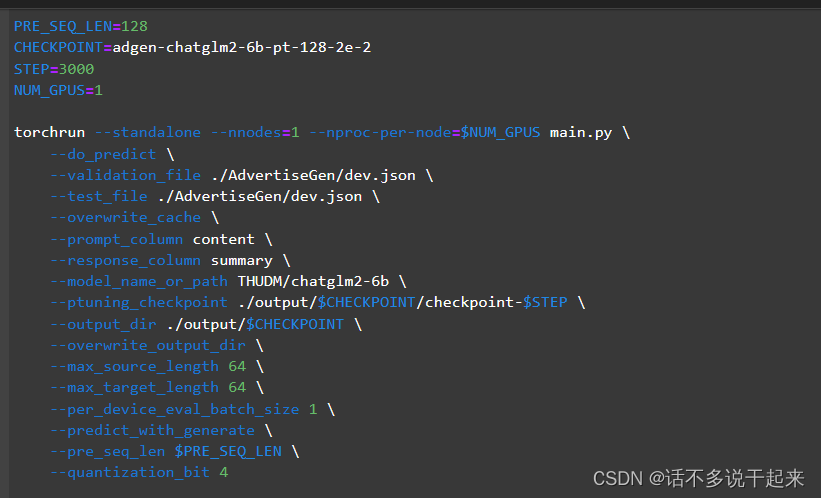
可以看到该文件虽然用于推理,但还是需要传入 response 内容的。这是因为 main.py 文件还包括了对模型预测效果的评估,所以我们这里不能直接用 evaluate.sh 文件。但是这个文件也说明了 main.py 里是包含对训练好的模型载入的过程,所以我们可以找到导入训练输出的模块。上一个训练任务将训练结果保存到了 output 中,对应就可以找到 punting_checkpoint 参数就是导入训练结果的参数。找到该参数的内容就可找到相应模块,找到的结果见下图:
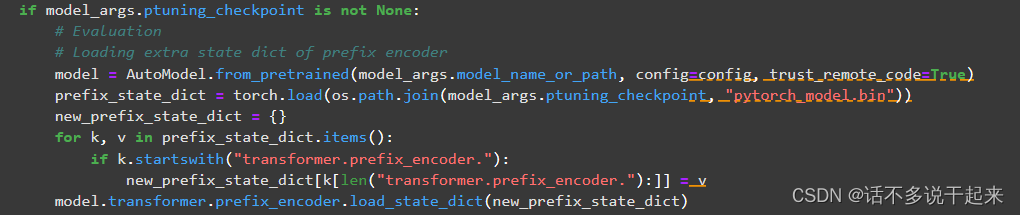
所以可以应用这一块代码,做修改,便可以将训练结果载入模型,后面输入 input 内容到模型就可以进行预测啦。修改代码如下:
from peft import PeftModel
from transformers import AutoTokenizer, AutoModel, AutoModelForCausalLM, AutoConfig
import torch
import os
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
config = AutoConfig.from_pretrained("/mnt/workspace/chatglm2-6b", trust_remote_code=True)
config.pre_seq_len = 128
tokenizer = AutoTokenizer.from_pretrained("/mnt/workspace/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("/mnt/workspace/chatglm2-6b", config=config, trust_remote_code=True).half().cuda()
prefix_state_dict = torch.load(os.path.join("/mnt/workspace/xfg-paper/ChatGLM2-6B/ptuning/output/adgen-chatglm2-6b-pt-128-2e-2/checkpoint-3000", "pytorch_model.bin"))
new_prefix_state_dict = {}
for k, v in prefix_state_dict.items():
if k.startswith("transformer.prefix_encoder."):
new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)载入后进行量化,并输入"你好" 测试一下。
model.transformer.prefix_encoder.float()
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
response载入后,预测就跟 submit_demo.py 里的一样啦。这里就不介绍了。
任务一笔记: https://blog.csdn.net/qq_40647231/article/details/132331704
任务二笔记: https://blog.csdn.net/qq_40647231/article/details/132380215














 197
197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









