







一起学习Linux下的C编程,就从利用fork开辟一个新的进程开始吧。
我们先来谈一谈fork()函数:
fork函数
函数原型
pid_t fork( void);
(pid_t 是一个宏定义,其实质是int 被定义在#include中)
!返回值: 若成功调用一次则返回两个值,子进程返回0,父进程返回子进程ID;否则,出错返回-1
函数原型
pid_t fork( void);
(pid_t 是一个宏定义,其实质是int 被定义在#include中)
!返回值: 若成功调用一次则返回两个值,子进程返回0,父进程返回子进程ID;否则,出错返回-1
函数说明
一个现有进程可以调用fork函数创建一个新进程。由fork创建的新进程被称为子进程(child process)。fork函数被调用一次但返回两次。两次返回的唯一区别是子进程中返回0值而父进程中返回子进程ID。
一个现有进程可以调用fork函数创建一个新进程。由fork创建的新进程被称为子进程(child process)。fork函数被调用一次但返回两次。两次返回的唯一区别是子进程中返回0值而父进程中返回子进程ID。
为什么fork会返回两次?
由于在复制时复制了父进程的堆栈段,所以两个进程都停留在fork函数中,等待返回。因此fork函数会返回两次,一次是在父进程中返回,另一次是在子进程中返回,这两次的返回值是不一样的。
下面我们来写个fork( )的调用来一起看看它的实现过程:
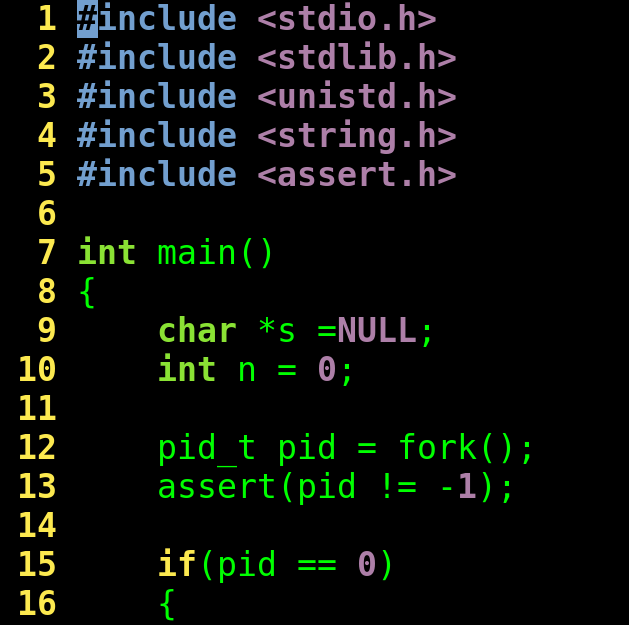
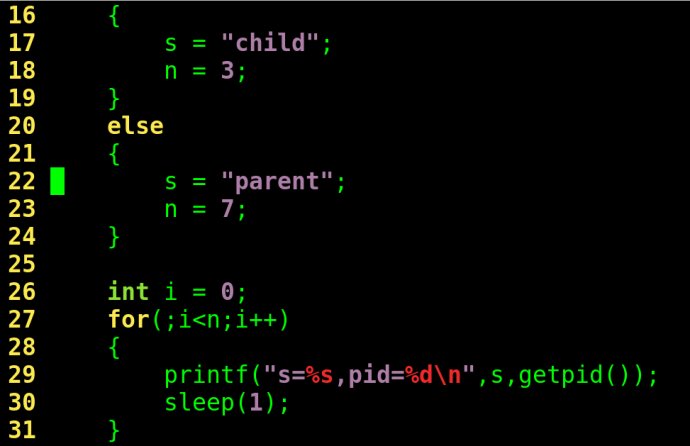

fork执行完毕后,出现两个进程,
有人会对这个运行结果产生一种错觉,就是程序中if语句的两条分支if(pid == 0)和else if(pid > 0)都得到了执行,其实完全不是这么回事,出现这种运行结果的原因是因为,在main()函数中fork后增加了一个进程,这个进程称为原来进程的子进程,原来的那个进程称为父进程,这个进程与原来的进程并发执行,谁先税后没有规律,由操作系统调度决定。
写时复制(COW):
在Linux程序中,fork()会产生一个和父进程完全相同的子进程,但子进程在此后多会exec系统调用,出于效率考虑,linux中引入了“写时复制“技术,也就是只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进程。
传统的fork()系统调用直接把所有的资源复制给新创建的进程。这种实现过于简单并且效率低下,因为它拷贝的数据或许可以共享。Linux的fork()使用写时拷贝(copy-on-write)页实现。
写时拷贝是一种可以推迟甚至避免拷贝数据的技术。内核此时并不复制整个进程的地址空间,而是让父子进程共享同一个地址空间。只用在需要写入的时候才会复制地址
空间,从而使各个进行拥有各自的地址空间。也就是说,资源的复制是在需要写入的时候才会进行,在此之前,只有以只读方式共享。这种技术使地址空间上的页的拷贝被推迟到实际发生写入的时候。在页根本不会被写入的情况下---例如,fork()后立即执行exec(),地址空间就无需被复制了。fork()的实际开销就是复制父进程的页表以及给子进程创建一个进程描述符。在一般情况下,进程创建后都为马上运行一个可执行的文件,这种优化,可以避免拷贝大量根本就不会被使用的数据。
父进程和子进程共享页面而不是复制页面。然而,只要页面被共享,它们就不能被修改。无论父进程和子进程何时试图写一个共享的页面,就产生一个错误,这时内核就把这个页复制到一个新的页面中并标记为可写。原来的页面仍然是写保护的:当其它进程试图写入时,内核检查写进程是否是这个页面的唯一属主;如果是,它把这个页面标记为对这个进程是可写的。
那么子进程的物理空间没有代码,怎么去取指令执行exec系统调用呢?















 432
432











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









