







8.2 结构
数组是相同类型元素的集合。相反,struct是任意类型元素的集合。例如:
struct Address{
const char* name; // “Jim Dandy”
int number; // 61
const char* street; // “South St”
const char* town; // “New Providence”
char state[2]; // ‘N’ ‘J’
const char* zip; // “07974”
};
该结构定义了一个名为Address的类型,它包含给身处美国的某人发信所需的全部信息。注意不要忽略结构最后的分号。
声明Address类型的变量与声明其他类型变量的方式一模一样。我们可以用点运算符(.)为每个成员分别赋值。例如:
void f()
{
Address jd;
jd.name = “Jim Dandy”;
jd.number = 61;
}
struct类型的变量能使用{ }的形式初始化(见6.3.5节),例如:
Address jd = {
“Jim Dandy”,
61,
“South St”,
“New Providence”,
{‘N’, ‘J’},
“07974”
};
请注意,我们不能用字符串 “NJ”初始化jd.state。字符串以符号 ‘\0’ 结尾,因此 “NJ” 实际上包含3个字符,比jd.state需要多出了一个。在这里,我故意将结构的成员定义成底层数据类型,这样读者就能对如何定义结构以及可能面临哪些问题有切身体会了。
我们通常使用 -> 运算符(struct指针解引用)访问结构的内容,例如:
void print_addr(Address* p)
{
cout << p->name << ‘\n’
<< p->number << ‘ ’ << p->street << ‘\n’
<< p->town << ‘\n’
<< p->state[0] << p->state[1] << ‘ ’ << p->zip << ‘\n’;
}
如果p是一个指针,则p->m等价于(*p).m。
除此之外,我们也能以引用的方式传递struct,并且使用 . 运算符(struct成员访问)访问它:
void print_addr2(const Address& r)
{
cout << p.name << ‘\n’
<< p.number << ‘ ’ << p.street << ‘\n’
<< p.town << ‘\n’
<< p.state[0] << p.state[1] << ‘ ’ << p.zip << ‘\n’;
}
关于实参传递的内容将在12.2节详细讨论。
结构类型的对象可以被赋值、作为实参传入函数,或者作为函数的结果返回。例如:
Address current;
Address set_current(Address next)
{
address prev = current;
current = next;
return prex;
}
默认情况下,比较运算符( == 和 != )等一些似是而非的操作并不适用于结构类型。当然用户有权自定义这些运算符(见3.2.1.1节和第18章)。
8.2.1 struct的布局
在struct的对象中,成员按照声明的顺序依次存放。例如,我们存储一个简单的读取器的方式可能如下所示:
struct Readout{
char hour; // [0:23]
int value;
char seq; // 序列标识 [‘a’ : ‘z’]
};
你可以设想Readout对象的成员在内存中的分布情况形如下图所示:

在内存中为成员分配空间时,顺序与声明结构的时候保持一致。因此,hour的地址一定在value的地址之前,见8.2.6节。
然而,一个struct对象的大小不一定恰好等于它所有元素大小的累积之和。因为很多机器要求一些特定类型的对象沿着系统结构设定的边界分配空间,以便机器能高效地处理这些对象。例如,整数通常沿着字地边界分配空间。在这类机器上,我们说对象对齐(aligned,见6.2.9节)得很好。这种做法会导致在结构中存在“空洞”。在4字节int的机器上,Readout的布局很可能是:
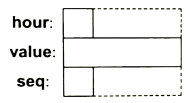
在预测Readout所占的空间大小时,很多人简单地把每个成员的尺寸加在一起,得到的结果是6。其实,在此例中sizeof(Readout)真正的结果是12,在很多机器上都是如此。
你也可以把成员按照各自的尺寸排序(大的在前),这样能在一定程度上减少空间浪费。例如:
struct Readout{
int value;
char hour; // [0:23]
char seq; // 序列标识 [‘a’ : ‘z’]
};
此时,Readout的存储方式是:
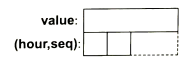
在Readout中仍然包含一个2字节的“空洞”(未使用空间),sizeof(Readout) == 8。这一点也不奇怪,毕竟当我们将来把两个Readout对象放在一起时(构成数组),肯定也希望它们是对齐的。包含10个Readout对象的数组大小是10*sizeof(Readout)。
通常情况下,我们应该从可读性的角度出发设计结构成员的顺序。只有当需要优化程序的性能时,才按照成员的大小排序。
在结构中如果用到了多个访问修饰符(即,public、private 和 protected),有可能影响布局(见20.5节)。
8.2.2 struct的名字
类型名字只要一出现就能马上使用了,无须等到该类型的声明全部完成。例如
struct Link{
Link* previous;
Link* successor;
};
但是,只有等到struct的声明全部完成,才能声明它的对象。例如:
struct No_good{
No_good member; //错误:递归定义
};
因为编译器无法确定No_good的大小,所以程序会报错。要想让两个或更多struct互相引用,必须提前声明好struct的名字。例如:
struct List; //结构名字声明:稍后再定义List
struck Link{
Link* pre;
Link* suc;
List* member_of;
int data;
};
struct List{
Link* head;
};
如果没有一开始声明List,则在稍后声明Link时使用List*类型的指针将造成错误。
我们可以在真正定义一个struct类型之前就使用它的名字,只要在此过程中不使用成员的名字和结构的大小就行了。然而,直到struct的声明全部完成之前,它都是一个不完整的类型。例如:
struct S; // “S”是类型的名字
extern S a;
S f();
void g(S);
S* h(S*);
我们必须先定义S才能继续使用上面这些声明:
void k(S* p)
{
S a; //错误:还没定义S,分配空间需要用到S的尺寸
f(); //错误:还没定义S,返回值需要用到S的尺寸
g(a); //错误:还没定义S,传递实参需要用到S的尺寸
p->m = 7; //错误:还没定义S,成员名字未知
S* q = h(p); //OK:允许分配和传递指针
q->m = 7; //错误:还没定义S,成员名字未知
}
为了符合C语言早期的规定,C++允许在同一个作用域中分别声明一对同名的struct和非struct。例如:
struct stat{/*...*/};
int stat(char* name, struct stat* buf);
此时,普通的名字(stat)默认是非struct的名字,要想表示struct必须在stat前加上前缀struct。类似地,我们还可以让关键字class、union(见8.3节)和enum(见8.4节)作为名字的前缀以避免二义性。我的建议是程序员应该尽量避免使用这种同名实体。
8.2.3 结构与类
struct是一种class,它的成员默认是public的。struct可以包含成员函数(见2.3.2节和第16章),尤其是构造函数。例如:
struct Points{
vector<Point> elem; //必须至少包含一个Point
Points(Point p0){elem.push_back(p0);}
Points(Point p0, Point p1){elem.push_back(p0);elem.push_back(p1);}
//...
};
Points x0; //错误:缺少默认构造函数
Points x1{{100, 200}}; //一个Point
Points x2{{100, 200}, {300, 400}}; //两个Point
只要你只想按照默认的顺序初始化结构的成员,则不需要专门定义一个构造函数,例如:
struct Point{
int x, y;
};
Point p0; //危险的行为:如果位于局部作用域中,则p0未初始化(见6.3.5.1节)
Point p1{}; //以默认方式构造:{{ }, { }};即{0, 0}
Point p2{1}; //以默认方式构造第二个成员:{1, { }};即{1, 0}
Point p3{1, 2}; //{1, 2}
但是如果你需要改变实参的顺序、检验实参的有效性、修改实参或者建立不变式(见2.4.3.2节和13.4节),则应该编写一个专门的构造函数。例如:
struct Address{
string name; // “Jim Dandy”
int number; // 61
string street; // “South St”
string town; // “New Providence”
char state[2]; // ‘N’ ‘J’
char zip[5]; // 07974
Address(const string n, int nu, const string& s, const string& t, const string& st, int z);
};
我添加了一个构造函数以确保每个成员都被初始化。同时,我能够输入string和int作为邮政编码,而不必再伪造一些字符。例如:
Address jd = {
“Jim Dandy”,
61,
“South St”,
“New Providence”,
{‘N’, ‘J’},
7974 //07974是八进制数值(见6.2.4.1节)
};
Address的构造函数可以定义成下面所示的形式:
Address(const string n, int nu, const string& s, const string& t, const string& st, int z)
//检验邮政编码的有效性
:name{n},
number{nu},
street{s},
town{t}
{
if(st.size() != 2)
error(“State abbreviation should be two characters”)
state = {st[0], st[1]}; //把邮政编码的简称存成字符
ostringstream ost; //输出字符串流,见38.4.2节
ost<<z; //从int中抽取字符
string zi{ost.str()};
switch(zi.size()){
case 5:
zip = {zi[0], zi[1], zi[2], zi[3], zi[4]};
break;
case 4: //以‘0’开始
zip = { ‘0’, zi[0], zi[1], zi[2], zi[3]};
break;
default:
error(“unexpected ZIP code format”);
}
// ... 检查编码是否是有意义的 ...
}
8.2.4 结构与数组
很自然地,我们可以创建struct的数组,也可以让struct包含数组。例如:
struct Point{
int x, y
};
Point points[3]{{1, 2}, {3, 4}, {5, 6}};
int x2 = points[2].x;
struct Array{
Point elem[3];
};
Array points2{{1, 2}, {3, 4}, {5, 6}};
int y2 = points.elem[2].y;
把内置数组置于struct的内部意味着我们可以把该数组当成一个对象来使用:我们可以在初始化(包括函数传参及函数返回)和赋值时直接拷贝struct。例如:
Array shift(Array a, Point p)
{
for(int i = 0; i != 3; ++i){
a.elem[i].x += p.x;
b.elem[i].y += p.y;
}
return a;
}
Array ax = shift(points2.{10, 20});
Array的定义还很初级,存在很多问题:为什么i != 3?为什么反复使用 .elem[i]?为什么只有Point类型的元素?标准库在固定尺寸的数组的基础上做了进一步的提升,设计了std::array(见34.2.1节)。标准库array是一种struct,与内置数组相比,它更完善,设计思想也更巧妙:
template<typename T.size_t N>
struct array{
T elem[N];
T* begin() noexcept{return elem;}
const T* begin() const noexcept{return elem;}
T* end() noexcept {return elem+N;}
const T* end() const noexcept {return elem+N;}
constexpr size_t size() noexcept;
T& operator[](size_t n) {return elem[n]}
const T& operator[](size_type n) const {return elem[n];}
T * data() noexcept {return elem;}
const T * data() const noexcept {return elem;}
//...
};
这里的array是个模板,它可以存放任意数量、任意类型的元素。它还可以直接处理异常(见13.5.1.1节)和const对象(见16.2.9.1节)。我们基于array继续编写下面的程序:
struct Point{
int x, y
};
using Array = array<Point, 3>; //包含3个Point的array
Array points{{1, 2}, {3, 4}, {5, 6}};
int x2 = point[2].x;
int y2 = point[2].y;
Array shift(Array a, Point p)
{
for(int i = 0; i != a.size(); ++i){
a[i].x += p.x;
a[i].y += p.y;
}
return a;
}
Array ax = shift(points, {10, 20});s
与内置数组相比,std::array有两个明显的优势:首先它是一种真正的对象类型(可以执行赋值操作),其次它不会隐式地转换成指向元素的指针:
ostream& operator<<(ostream& os, Point p)
{
cout << ‘{‘ << p[i].x << ‘,’ << p[i].y << ‘}’;
}
void print(Point a[], int s) //必须指定元素的数量
{
for(int i = 0; i != s; ++i)
cout << a[i] << ‘\n’;
}
template<typename T, int N>
void print(array<T, N>& a)
{
for(int i = 0; i != a.size(); ++i)
cout << a[i] << ‘\n’;
}
Point point1[] = {{1, 2}, {3, 4}, {5, 6}}; //3个元素
array<Point, 3> point2 = {{1, 2}, {3, 4}, {5, 6}}; //3个元素
void f()
{
print(point1,4); //4是一个糟糕的错误
print(point2);
}
std::array也有不足,我们无法从初始化器的长度推断元素的数量:
Point point1[] = {{1, 2}, {3, 4}, {5, 6}}; //3个元素
array<Point, 3> point2 = {{1, 2}, {3, 4}, {5, 6}}; //3个元素
array<Point> point3 = {{1, 2}, {3, 4}, {5, 6}}; //错误:未指定元素的数量
8.2.5 类型等价
对于两个struct来说,即使它们的成员相同,它们本身仍是不同的类型。例如:
struct S1{int a;};
struct S2{int a;};
S1和S2是两种类型,因此:
S1 x;
S2 y = x; //错误:类型不匹配
struct本身的类型与其成员的类型不能混为一谈,例如:
S1 x;
int i = x; //错误:类型不匹配
在程序中,每个struct只能有唯一的定义(见15.2.3节)。
8.2.6 普通旧数据
有时候,我们只想把对象当成“普通旧数据”(内存中的连续字节序列)而不愿考虑那些高级语义概念,比如运行时多态(见3.2.3节和20.3.2节)、用户自定义的拷贝语义(见3.3节和17.5节)等。这么做的主要动机是在硬件条件允许的范围内尽可能高效地移动对象。例如,要执行拷贝含有100个元素的数组的任务,调用100次拷贝构造函数显然不像直接调用std::memcpy()有效率,毕竟后者只需要使用一个块移动机器指令即可。即使构造函数是内联的,对于优化器来说要想发现这样的优化机会也并不容易。这种“小把戏”在实现vector等容器以及底层I/O程序时都很常见,并且非常重要。但是在高层代码中就没什么必要了,应该尽量避免使用。
POD(“普通旧数据”)是指能被“仅当作数据”处理的对象,程序员无须顾及类布局的复杂性以及用户自定义的构造、拷贝和移动语义。例如:
struct S0 {}; //是POD
struct S1 {int a;}; //是POD
struct S2 {int a; S2(int aa) : a(aa) { }}; //不是POD(不是默认构造函数)
struct S3 {int a; S3(int aa) : a(aa){ } S3(){}}; //是POD(用户自定义的默认构造函数)
struct S4 {int a; S4(int aa) : a(aa){ } S4() = default;} //是POD
struct S5 {virtual void f(); /*...*/}; //不是POD(含有一个虚函数)
struct S6 : S1{ }; //是POD
struct S7 : S0{int b;}; //是POD
struct S8 : S1{int b;}; //不是POD(数据既属于S1也属于S8)
struct S9 : S0, S1{ }; //是POD
我们如果想把某个对象“仅当作数据”处理(当作POD),则要求该对象必须满足下述条件:
- 不具有复杂的布局(比如含有vptr,见3.2.3节和20.3.2节)。
- 不具有非标准(用户自定义的)拷贝含义。
- 含有一个最普通的默认构造函数。
显然,我们在定义POD时必须慎之又慎,从而确保在不破坏任何语言规则的前提下使用这些优化措施。正式的规定是(§ iso.3.9,§iso.9):POD必须是属于下列类型的对象:
- 标准布局类型(standard layout type)
- 平凡可拷贝类型(trivially copyable type)
- 具有平凡默认构造函数的类型
一个与之有关的概念是平凡类型(trivial type),它具有以下属性:
- 一个平凡默认构造函数
- 平凡拷贝和移动操作
通俗地说,当一个默认构造函数无须执行任何实际操作时(如果需要定义一个默认构造函数,使用=default,见17.6.1节),我们认为它是平凡的。
一个类型具有标准布局,除非它:
- 含有一个非标准布局的非static成员或基类;
- 包含virtual函数(见3.2.3节和20.3.2节);
- 包含virtual基类(见21.3.5节);
- 含有引用类型(见7.7节)的成员;
- 其中的非静态数据成员有多种访问修饰符(见20.5节);
- 阻止了重要的布局优化:
- 在多个基类中都含有非static数据成员,或者在派生类和基类中都含有非static数据成员,或者
- 基类类型与第一个非static数据成员的类型相同。
基本上,标准布局类型是指与C语言的布局兼容的类型,并且应该能被常规的C++应用程序二进制接口(ABI)处理。
除非在类型内部含有非平凡的拷贝操作、移动操作或者析构函数(见3.2.1.2节和17.6节),否则该类型就是平凡可拷贝的类型。通俗地说,如果一个拷贝操作能被实现成逐位拷贝的形式,则它是平凡的。那么,是什么原因让拷贝、移动和析构函数变得不平凡呢?
- 这些操作是用户定义的。
- 这些操作所属的类含有virtual函数。
- 这些操作所属的类含有virtual基类。
- 这些操作所属的类有非平凡的基类或者成员。
内置类型的变量都是平凡可拷贝的,且拥有标准布局。同样,由平凡可拷贝对象组成的数组是平凡可拷贝的,由标准布局对象组成的数组拥有标准布局。思考下面的例子:
template<typename T>
void mycopy(T* to, const T* from, int count);
已知T是POD,我们希望对它进行优化。一种优化的思路是只对POD调用mycopy()函数,但是这么做充满了风险:如果使用了mycopy(),你能确保代码的用户永远不会对非POD调用该函数吗?现实情况是,谁也无法做出这种保证。另一种可行的措施是调用std::copy(),标准库在实现该函数时应该已经进行了必要的优化。无论如何,下面所示的是经过优化后的代码:
template<typename T>
void mycopy(T* to, const T* from, int count)
{
if(is_pod<T>::value)
memcpy(to, from, count*sizeof(T));
else
for(int i = 0; i != count; ++i)
to[i] = from[i];
}
is_pod是一个标准库类型属性谓词(见35.4.1节),它定义在<type_traits>中,我们可以通过它在代码中提问:“T是POD吗?”程序员能从is_pod中受益良多,尤其是不必再记忆那些判断T是否是POD所需的繁琐规则。
请注意,增加或删除非默认构造函数不会影响布局和性能(在C++98标准中可不是这样)。
如果你确实对C++语言的深层次内容有非常浓厚的兴趣,不妨花点时间研究一下C++标准中对布局和平凡性概念的规定(§ iso.3.9,§ iso.9),并且思考这些规定是如何影响程序员和编译器作者的。当然,思考这些问题可能需要占用你的很多时间,坚持下去,别轻易放弃。
8.2.7 域
看起来用一整个字节(一个char或者一个bool)表示一个二元变量(比如on/off开关)有点浪费,但是char已经是C++中能独立分配和寻址的最小对象了(见7.2节)。我们也可以把这些微小的变量组织在一起作为struct的域(field)。域也称为位域(bit-field)。我们只要指定成员所占的位数,就能把它定义成域了。C++允许未命名的域。未命名的域不会干扰命名域的含义,同时能以某种依赖于机器的方式优化布局:
struct PPN{ //R6000 物理页编号
unsigned int PFN : 22; //页框编号
int : 3; //未使用
unsigned int CCA : 3; //缓存一致性算法
bool nonreachable : 1;
bool dirty : 1;
bool valid : 1;
bool global : 1;
};
这个例子还展示了域的另外一个作用:即,为外部设定的布局中的部件命名。域必须是整型或枚举类型(见6.2.1节)。我们无法获取域的地址,除此之外,域的用法和其他变量一样。我们能用一个单独的二进制位表示bool域,在操作系统内核及调试器中,类型PPN的用法与之类似:
void part_of_VM_system(PPN* p)
{
//...
if(p->dirty){ //更改了内容
//拷贝到磁盘
p->dirty = 0;
}
}
出乎人们意料之外的事实是,用域把几个变量打包在一个字节内并不一定能节省空间。这种做法虽然节省了数据空间,但是负责管理和操作这些变量的代码在绝大多数机器上都会更长。经验表明,当二进制变量的存储方式从位域变成字符时,程序的规模会显著缩小!同时,直接访问char或者int也比访问位域更快。位域不过是用位逻辑运算符(见11.1.1节)从字中提取信息或插入信息的一种便捷手段罢了。
















 601
601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











