







背景
最近在看socket编程,这里面需要用到stream进行数据的读取和写入。于是代码中用到了BufferedInputStream提高读的效率。所以就一直在想为什么加上buffer就能提高效率了,加上之前面试的时候曾有面试官问到过这个问题,当时没有回答上来,并且就上网搜索了一下,发现有个文章是为什么缓存能提高io效率,这个文章中说是因为缓存可以让DMA来处理io流,后面我一直都是这么认为的,今天在网上搜索发现即使你用的是inputstream来读也会用到DMA,那篇文章中的缓存可能指的是内核态的缓存。所以之前以为的应该都是错误的吧。
猜想
在进行io流的读时,最消耗时间的应该是数据从内核态拷贝到用户态这个过程,这个过程会进行上下文的切换,详细的内容可以搜索一下。
接下来看一下BufferedInputStream的代码。
1、首先是初始化,如果不指定缓冲区的大小,会默认8192长度的数组

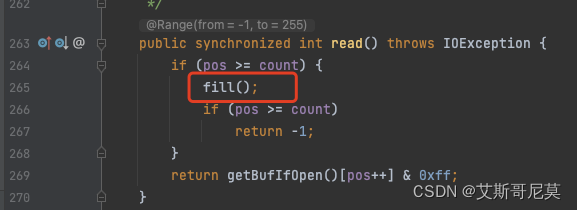
2、查看BufferedInputStream的read()方法。
read()方法中有个fill()方法,这里的read()方法其实是加锁的,猜想应该是防止多线程调用的时候造成缓存数组的数据混乱,查看full方法的调用的是原生inputstream的public int read(byte b[], int off, int len) throws IOException 方法,注意这里第一个参数是传入了一个byte数组。

分析
既然BufferedInputStream的read()方法最终还是会调用FileInputStream的read方法,那是不是所如果直接使用FileInputStream的public int read(byte b[]) 方法也能提高效率。
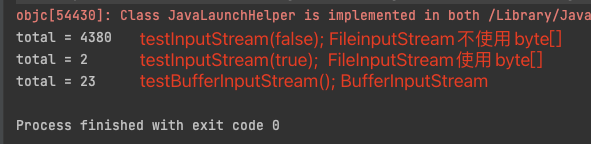
用三种方法读取7.8M的文件,测试结果如下:
结果基本可以看出使用原生FileInputStream的read(byte[] b)方法效率也是可以高很多的
测试代码
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileWriter;
import java.io.IOException;
/**
* @author
* @Description
* @create 2022-02-17 14:56
*/
public class TestInputStream {
private final static String FILENAME = "input-test.txt";
public static void main(String[] args) {
testOutputStream();
testInputStream(false);
testInputStream(true);
testBufferInputStream();
}
/**
*
* @param isbuffer 是否使用原生的inputstream中的byte[]
*/
public static void testInputStream(boolean isbuffer) {
FileInputStream in = null;
int byteLen = 8192;
// 每次读取1024字节
byte[] buffer = new byte[byteLen];
try {
in = new FileInputStream(FILENAME);
long start = System.currentTimeMillis();
while (true) {
int read;
if (isbuffer) {
read = in.read(buffer);
if (read == -1 || read < byteLen) {
break;
}
}else {
read = in.read();
if (read == -1) {
break;
}
}
}
long end = System.currentTimeMillis();
System.out.println("total = " + (end - start));
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (in != null) {
in.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void testBufferInputStream() {
FileInputStream inputStream = null;
BufferedInputStream in = null;
try {
inputStream = new FileInputStream(FILENAME);
in = new BufferedInputStream(inputStream);
long start = System.currentTimeMillis();
while (true) {
int read = in.read();
if (read == -1) {
break;
}
}
long end = System.currentTimeMillis();
System.out.println("total = " + (end - start));
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
if (in != null) {
in.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void testOutputStream() {
String context = "年薪百万,年薪百万,年薪百万,年薪百万,年薪百万,年薪百万,年薪百万,年薪百万,年薪百万,年薪百万,年薪百万\r\n";
FileWriter fileWriter = null;
try {
fileWriter = new FileWriter(FILENAME);
// 文件大概7.8M
for (int i = 0; i < 50000; i++) {
fileWriter.append(context);
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
if (fileWriter != null) {
fileWriter.close();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
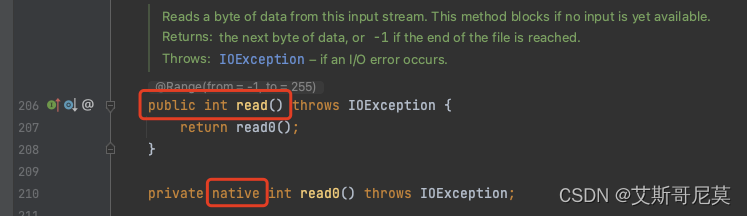
以下是FileInputStream中的read(byte b[])和read()的代码,native方法调用的就是系统方法了。耗时应该都是在这里。

总结猜想
BufferInputStream提高效率应该是针对read()方法,也就是不带任何参数的read方法,BufferInputStream会调用FileInputStream的read(byte b[], int off, int len),这个方法可以直接指定从系统中一次读取多大的文件,当用户调用read()方法时其实是从read(byte b[], int off, int len) 返回的结果中取一个字节数据,这样也就减少了和系统的交互次数,进而减少上下文切换的时间消耗,体现给我们的就是读取文件的时间大幅减小。
举个例子:
假如一个文件大小为100,如果调用FileInputStream没有参数的read() 方法,则需要和系统交互100次,但是如果调用read(byte b[], int off, int len),并且指定一次读取的大小为20,那么只需要和系统交互5次就能将文件全部读完,这样就大大的降低的读取时间。














 1080
1080











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









