






一、执行命令
python3 ~/DataMerge.py -r hadoop hdfs://mynode1:8020/python_hadoop/data -o hdfs://mynode1:8020/python_hadoop/output3
二、错误现象
map和reduce进度均为100%,但是提示Job not successful,可能失败的原因中显示程序执行过程中超出了虚拟内存的限制。


三、解决办法
解决办法(一)
编辑yarn-site-xml配置文件,调整内存参数:
<property>
<name>mapreduce.map.memory.mb</name>
<value>1536</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1024M</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>3072</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2560M</value>
</property>
解决办法(二)
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
四、参数说明
解决办法三、(一)
(一)mapreduce.map.memory.mb:map任务的内存限制
(二)mapreduce.reduce.memory.mb:reduce任务的内存限制
(三)mapreduce.map.java.opts:map任务JVM虚拟机内存限制
(四)mapreduce.reduce.java.opts:reduce任务JVM虚拟机内存限制
原则上(一)的值>(三)的值;(二)的值>(四)的值;
当(三)的值>(一)的值或者(四)的值>(二)的值时,就会出现“二、错误现象”中的内容。
解决办法三、(二)
yarn.nodemanager.pmem-check-enabled:是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true ,这里设置值为false,关闭掉该检查就不会进行解决办法三、(一)里面的校验啦
五、分发到各个节点

由于Reduce执行了100%,已经生成了输出文件,故在重新执行前,需要删除已经生成的输出文件。

不然会报文件在hadoop的目录上已经存在的错误。

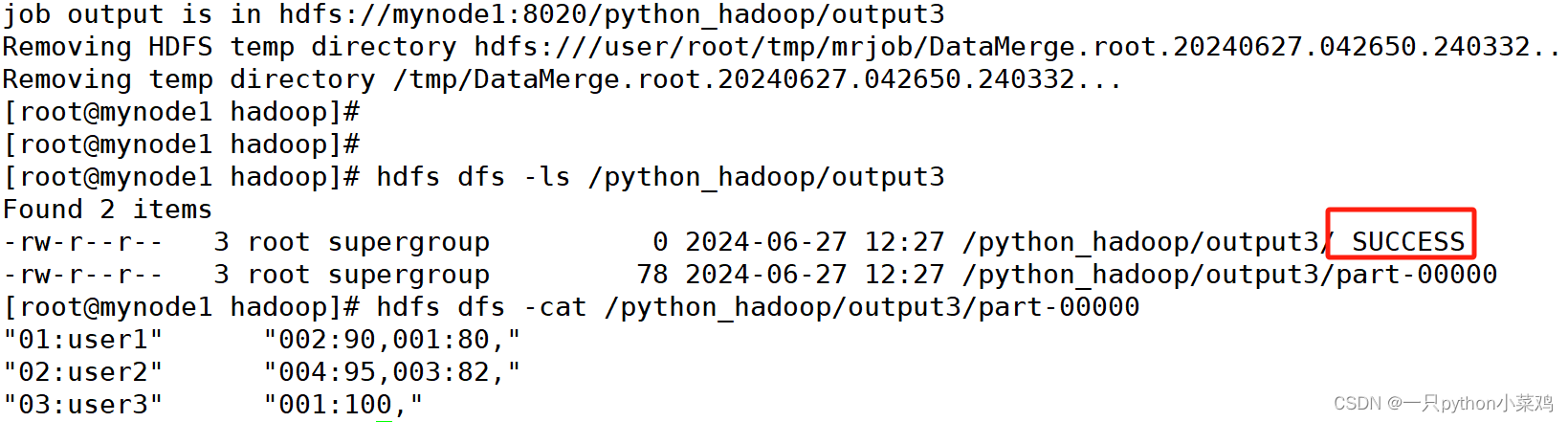
六、重新执行“一、执行命令”内容,验证结果,执行成功。
















 3762
3762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









