






SQL入门随记
-
求取“平均…“时使用”分组函数“:group by,group by with rollup(在所有的查询记录后面新加一条记录,用于统计所有查询记录的和)
-
SELECT DISTINCT 语句用于返回唯一不同的值。(去重)
-
SQL统计字符串中指定字符出现次数 length(str)-replace(str,‘a’,‘’)
-
SELECT 字段名 FROM 表名 [WHERE 字段 = 值] ORDER BY 字段名 [ASC / DESC]---->排序
-
多表连接时,出现多对一的情况时,“一”会在后面自动补全
-
SQL CONCAT函数用于将两个字符串连接起来,形成一个单一的字符串。
-
SQL truncate(不进行四舍五入)用法类似的函数round(四舍五入)的区别。
-
多表联结查询时,若其中一表所需东西较少,可以先查出较多表所需数据,将其结果当作一个新表然后进行关联
-
ORDER BY ‘选修人数’ DESC,cid ASC------>先满足前面的在满足后面的
-
窗口函数:满足某种条件的记录集合上执行的特殊函数
-
序号函数:row_number()/ rank()/ dense_rank()
-
分布函数:percent_rank():计算 SQL Server 中一组行内某行的相对排名
-----PERCENT_RANK 返回的值范围大于 0 并小于或等于 1。
任何一组中第一行的 PERCENT_RANK 都为 0。 默认情况下包含 NULL 值,且该值被视为最低的可能值 cume_dist():计算某指定值在一组值中的相对位置
-
前后函数:
lag():在 SELECT 语句中使用此分析函数可将当前行中的值与先前行中的值进行比较。
lead():在 SELECT 语句中使用此分析函数可将当前行中的值与后续行中的值进行比较。 -
头尾函数:
first_val():返回有序值集中的第一个值。
last_val():返回有序值集中的最后一个值。 -
其他函数:nth_value():从结果集中的第N行获取值。
窗口函数的基本用法:
函数名([expr]) over 子句----over是关键字,用来指定函数执行的周期
– 进行排名,具体数字的排名
row_number():依次排序不会出现相同排名 1234rank():出现相同排名时,跳跃排序 1224
dense_rank():出现相同排名时,连续排序 1223
-
-
partition by分组- - -例:rank() over(partition by 列名,order by 列名)
-
DATEDIFF() 函数返回两个日期之间的天数。
FLOOR(X)根据官方文档的提示,floor函数返回小于等于该值的最大整数.TIMESTAMPDIFF(返回格式,日期,日期) 后面的日期减去前面的日期
YEARWEEK(date, mode)
返回年份及第几周(0到53),mode为可选参数,其中 中 0 (默认参数)表示从周天开始,1表示周一开始,以此类推:YEAR()、MONTH()、WEEK()等函数的使用
-
SQL类型转化:
cast(表达式 as 数据类型) ---->select 100.0 +cast(‘1000’ as int) – 1100.0 默认把字符串转换成浮整型
convert(数据类型,表达式)----->select 100.0 + convert(int,‘1000’)-- 1100.0 默认把字符串转换成整型
SELECT DISTINCT CAST(datet AS CHAR(30))
FROM test1;convert 是SQLServer函数
-
SQL优化
- 最大化利用索引;
- 尽可能避免全表扫描;
- 减少无效数据的查询;
尽量避免在字段开头进行模糊查询,这样会放弃索引而进行全局扫描
避免使用in 和 not in、or、null、会导致引擎进行全表扫描
order by 条件要与where中条件一致,否则order by不会利用索引进行排序
避免出现select *
使用表的别名
用where字句替换HAVING字句
多表关联查询时,小表在前,大表在后
使用truncate代替delete
使用合理的分页方式以提高分页效率 -
SQL语句执行顺序
-> from–>on–>join–>where–>group by(MySQL这一步开始可以使用select中的别名)–>having–>select–>distinct–>order by–>limit -
SQL语句语法顺序:
->select、from、where、group by、having、order by、limitMySQL24小时制:
H:表示24小时制度;h:表示12小时制度
DATE_FORMAT(NOW(),‘%Y-%m-%d %H:%i:%s’)
DATE_FORMAT(NOW(),‘%Y-%m-%d %h:%i:%s’) -
SQL产生连续日期
# 借助mysql.`help_topic`表 SELECT DATE_ADD(CURDATE(),INTERVAL b.`help_topic_id`+1 DAY) AS dates FROM mysql.`help_topic` b WHERE b.`help_topic_id`<30 -- ---------------------------------------- # 使用变量 set @a=0; SELECT DATE_ADD(CURDATE(),INTERVAL @a:=@a+1 DAY) AS dates FROM mysql.`help_topic` b # 任意表都可,但日期显示数量受表的数据条数影响; WHERE @a<30 -
SQL —A表获取和B表某行FLIGHT_NUM数据等同的某列
flight_num(A表) FLIGHT_NUM(B表) HU123 HU123|HU124 HU124 select a.FLIGHT_NUM from a where (select CONCAT(b.FLIGHT_NUM,'|') FROM b where b.DATA_PERIOD ='20210424') LIKE CONCAT('%',a.FLIGHT_NUM,'|','%');SQL中使用union操作符合并多个select的结果
union和union all:
union对合并结果进行 去重和排序; union all不进行去重和排序获取本周的订单数:
WHERE
WEEKOFYEAR(order_date)=WEEKOFYEAR(CURDATE())
YEAR(order_date)=YEAR(CURDATE())函数随记
group_concat():group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator ‘分隔符’] )
SUBSTR(s, start, length):从字符串 s 的 start 位置截取长度为 length 的子字符串MySQL经过按位运算之后的数值是一位64为的无符号整数;如’1’的二进制最右边为1,取反后前63位为‘1’,最后一位为‘0’
运算符优先级

MySQL函数
ABS(x):返回绝对值
MOD(x,y):x被y除后的余数
CEIL(x)、CEILING(x):返回不小于x的最小整数值,返回值是一个BIGINT
FLOOR(x):返回不大小x的最大整数值,返回值是一个BIGINT类型
RAND():返回0到1间的一个随机数
RAND(x):若参数x相同,则返回相同的随机数,不同的x值产生不同的随机数
ROUND(x):返回最接近x的整数,对x进行四舍五入
TRUNCATE(x):返回最接近x的整数,不对x进行四舍五入
SIGN(x):返回x的符号;负数:-1,0:0,整数:1
POW(x,y)、POWER(x,y):返回x的y次方
EXP(x):返回x的e次方
CHAR_LENGTH(str):返回str的字符个数; 例如:CHAR_LENGTH(‘你的名字’) # 返回4
LENGTH(str):返回str的字节个数; 例如:LENGTH(‘你的名字’) # 返回12,一个汉字3个字节,数字或字母一个字节
coalesce(success_cnt, 1):当success_cnt 为null值的时候,将返回1,否则将返回success_cnt的真实值。
时间戳函数:
UNIX_TIMESTAMP(date):返回date距离1970-01-01 00:00:00之后的秒数
FROM_UNIXTIME(date):将时间戳转换成普通格式的时间,与UNIX_TIMESTAMP(date)互为反函数
DECIMAL:是MySQL中存在的精准数据类型,语法格式“DECIMAL (M,D)”。. 其中,M是数字的最大数(精度),其范围为“1~65”,默认值是10;D是小数点右侧数字的数目(标度),其范围是“0~30”,但不得超过M
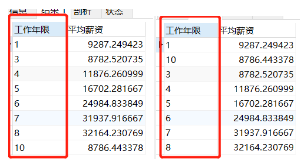
按照text类型数字排序
SELECT
workyear AS 工作年限,
avg( salary_mean ) AS 平均薪资
FROM
v_data_salary_min_max_mean
GROUP BY
workyear
# ORDER BY workyear
ORDER BY LENGTH(workyear),workyear
hive执行顺序:from -->join -->on -->where -->select -->group by–>having–>order by
MySQL执行顺序:from–>join–>on–>where–>group by(MySQL这一步开始可以使用select中的别名)–>having–>select -->oeder by
条件放到On后面和放到where后面的区别?为什么On后面比where后面快
执行顺序On在前where在后,on是作用与临时表生成的时候,where作用于临时表生成之后;所以on会把不符合条件的数据过滤掉在进行统计,减少了中间运算要处理的数据
插入记录的方式汇总:
普通插入(全字段):INSERT INTO table_name VALUES (value1, value2, …)
普通插入(限定字段):INSERT INTO table_name (column1, column2, …) VALUES (value1, value2, …)
多条一次性插入:INSERT INTO table_name (column1, column2, …) VALUES (value1_1, value1_2, …), (value2_1, value2_2, …), …
从另一个表导入:INSERT INTO table_name SELECT * FROM table_name2 [WHERE key=value]
带更新的插入:REPLACE INTO table_name VALUES (value1, value2, …) (注意这种原理是检测到主键或唯一性索引键重复就删除原记录后重新插入)
删除记录的方式汇总:
根据条件删除:DELETE FROM tb_name [WHERE options] [ [ ORDER BY fields ] LIMIT n ]
全部删除(表清空,包含自增计数器重置):TRUNCATE tb_name
时间差:
TIMESTAMPDIFF(interval, time_start, time_end)可计算time_start-time_end的时间差,单位以指定的interval为准,常用可选:
SECOND 秒
MINUTE 分钟(返回秒数差除以60的整数部分)
HOUR 小时(返回秒数差除以3600的整数部分)
DAY 天数(返回秒数差除以3600*24的整数部分)
MONTH 月数
YEAR 年数
表的创建、修改与删除:
1.1 直接创建表:
CREATE TABLE [IF NOT EXISTS] tb_name – 不存在才创建,存在就跳过
(column_name1 data_type1 – 列名和类型必选
[ PRIMARY KEY – 可选的约束,主键
FOREIGN KEY – 外键,引用其他表的键值
AUTO_INCREMENT – 自增ID
COMMENT comment – 列注释(评论)
DEFAULT default_value – 默认值
UNIQUE – 唯一性约束,不允许两条记录该列值相同
NOT NULL – 该列非空], …
) [CHARACTER SET charset] – 字符集编码
[COLLATE collate_value] – 列排序和比较时的规则(是否区分大小写等)
1.2 从另一张表复制表结构创建表: CREATE TABLE tb_name LIKE tb_name_old
1.3 从另一张表的查询结果创建表: CREATE TABLE tb_name AS SELECT * FROM tb_name_old WHERE options
2.1 修改表:ALTER TABLE 表名 修改选项 。选项集合:
{ ADD COLUMN <列名> <类型> – 增加列
CHANGE COLUMN <旧列名> <新列名> <新列类型> – 修改列名或类型
ALTER COLUMN <列名> { SET DEFAULT <默认值> | DROP DEFAULT } – 修改/删除 列的默认值
MODIFY COLUMN <列名> <类型> – 修改列类型
DROP COLUMN <列名> – 删除列
RENAME TO <新表名> – 修改表名
CHARACTER SET <字符集名> – 修改字符集
COLLATE <校对规则名> } – 修改校对规则(比较和排序时用到)
3.1 删除表:DROP TABLE [IF EXISTS] 表名1 [ ,表名2]。














 329
329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









