







前言: 目前在看HTTP关于实体部分的内容编码部分,是一个很有趣的东西。在这里简单记录一下,学习到的概念,并通过两个程序来实际测试一下内容编码在传输上的效率。推荐阅读《HTTP权威指南》,内容丰富有趣,本人力荐!
内容编码
HTTP应用程序有时在发送之前需要对内容进行编码,以奖少传输实体的时间或者对内容进行加密,防止第三方看到传输的内容。经过内容编码的实体,还是和正常的实体一样进行发送。(这里的实体指的是HTTP报文的数据体)我们常见的内容编码就是压缩,实体经过压缩之后,体积会大大减少,这也在网络上传输的时间也会缩短很多,对于用户(慢速网络)和服务器都是有好处的。
内容编码的过程如下:
1.网站服务器生成原始响应报文,其中有原始的 Content-Type 和 Content-Length 首部。
2.内容编码服务器(也可能是原始的服务器或者下行的代理服务器)创建编码后的报文。编码后的报文同样具有 Content-Type 首部,但是 Content-Length 通常会变化,因为报文主体被压缩了。内容编码服务器在编码后的报文中增加 Content-Encoding 首部,这也客户端就可以对其进行解码了。
3.接受程序(客户端)得到编码后的报文,进行解码,获得原始报文。
内容编码相关首部
Content-Encoding 首部
Content-Encoding 首部的值是用来说明,报文实体采用了何种编码类型。
| Content-Encoding 值 | 描述 |
|---|---|
| gzip | 表明实体采用GNU zip编码 |
| compress | 表明实体采用Unix的文件压缩程序 |
| deflate | 表明实体是用zlib的格式压缩的 |
| identity | 表明没有对实体进行编码。当没有Content-Encoding首部时,就默认是这种清空 |
注:gzip、compress以及deflate编码都是无损压缩算法,用于减少报文传输的大小,不会导致信息损失。这些算法中,gzip通常是效率最高的,使用最广泛的。我们平时如果多留意观察的话,基本上遇见的都是gzip。
Accept-Encoding 首部
因为客户端不可能支持所有的编码方式,如果服务器发送了客户端无法解码的文件,这是一件需要避免的事。所以,客户端需要将自己支持的内容编码方式列表放在请求的Accept-Encoding首部里发出去。如果没有这个首部,服务器就假设客户端能够接受任何编码方式(等价于**Accept-Encoding: ***)。但是我自己的测试结果似乎并不是这样的。
几个例子:
Accept-Encoding: compress, gzip
Accept-Encoding:
Accept-Encoding: *
当然了,还有更加复杂的用法,但是这里作为一个初步的学习,就不去深入了。
说明:
这里只需要了解到 Accept-Encoding 是客户端向服务器请求我可以接受的内容编码类型;
Content-Encoding 是服务器向客户端通知我发送的实体的内容编码类型就足够了。
编码实战
测试压缩后报文实体的效率
注意:这里只是一个简单的比较,不具有代表性,只是为了说明:压缩报文实体是有效的,但是具体的效率不确定,而且也不一定就是快速,因为这却决于很多因素。如果你本身的网络传输速度就很快,也许压缩之后反而慢了,编码(压缩)也是需要时间的,解码当然也是耗时的。
使用代码实验
使用socket进行原始的实验
不使用:Accept-Encoding: gzip
注:我这里不使用这个首部,服务器默认我就是不能接受任何编码。并不是上面那样的接受所有的编码。
package com.dragon;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.Socket;
import java.net.UnknownHostException;
import java.nio.charset.Charset;
import java.util.HashMap;
import java.util.Map;
import java.util.UUID;
import javax.net.ssl.SSLSocket;
import javax.net.ssl.SSLSocketFactory;
/**
* @author Alfred
* @version 1.0
* */
public class SocketDownload {
private static final int TIMEOUT = 10*1000; // 超时时间
private static final String BLANK = " "; // 空格
private static final String CRLF = "\r\n"; // 回车换行符
/**
* 程序执行的入口
* */
public static void main(String[] args) {
SocketDownload socketDownload = new SocketDownload();
long start = System.currentTimeMillis();
socketDownload.httpDownload("xiaohua.zol.com.cn", 80, ".html");
System.out.println("耗时:" + (System.currentTimeMillis()-start) + "ms");
}
/**
* 下载方法
*
* @param ip 请求连接的ip地址
* @param port 端口号
* @param suffix 下载资源的后缀名
*
* 使用网络图片来进行测试,测试图片地址为:它的服务器可以接收范围请求,即ranges
*
*http://xiaohua.zol.com.cn/detail60/59420.html
* */
public void httpDownload(String ip, int port, String suffix){
try (Socket socket = new Socket(ip, port)) {
socket.setSoTimeout(TIMEOUT); // 设置超时时间
// 获取输出流和输入流
OutputStream output = new BufferedOutputStream(socket.getOutputStream());
// 使用输出流发送请求数据
InputStream input = new BufferedInputStream(socket.getInputStream());
StringBuilder msgBuilder = new StringBuilder();
// 构造简单的请求报文,这里报文非常简单
msgBuilder.append("GET").append(BLANK)
.append("/detail60/59420.html").append(BLANK).append("HTTP/1.1").append(CRLF)
.append("Host").append(":").append(BLANK).append(ip).append(CRLF)
// .append("Accept-Encoding").append(":").append(BLANK).append("gzip").append(CRLF)
.append("User-Agent").append(":").append(BLANK).append("Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
+ " AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36").append(CRLF)
.append(CRLF);
// 请求报文转成字符串
String msg = msgBuilder.toString();
// 查看请求报文格式
System.out.println(msg);
// 请求报文字符串转成字节数组,网络上的数据最终都是以字节数据发送的,
// 我们这是在TCP的层面看的,如果你往下一层,也可以说是比特流了。
byte[] request = msg.getBytes(Charset.forName("UTF-8"));
// 发送请求报文,这里其实可以一步到位的,但是为了表达清晰,还是分步来写
output.write(request);
output.flush(); // 刷新输出流,不然未发送请求,导致无法接收到响应
// 使用输入流接收请求数据,但是此处我无法直接读取请求流,不然就是将整个报文的内容读取下来了
// 注意整个报文指的是整个响应报文,包含报文头和报文体。虽然我也可以通过打开整个报文,
// 删除报文头,然后修改文件名,它就是一个图片了,但是这样感觉不是很规范。
char ch;
Map<String, String> headMap = new HashMap<>(); // 定义一个map结构,用于存储报文头部
StringBuilder statusLine = new StringBuilder(); // 响应报文的首行
StringBuilder key = new StringBuilder(); // 存储键
StringBuilder value = new StringBuilder(); // 存储键
boolean flag = true; // 定义一个标志标量,用于读取首行
// 读取响应报文头部数据
dragon: while (true) {
// 响应报文的首行需要单独处理
if (flag) {
while (true) {
ch = (char) input.read();
if (ch == '\n') {
flag = false; // 标志位置为假
break;
}
statusLine.append(ch);
}
}
// 读取一个 key
while (true) {
ch = (char) input.read();
if (ch == ':') {
break;
}
key.append(ch);
// 如果 ch 是\n字符,那么就认为读取到了头部和数据部分的分隔符 \r\n,
// 即头部已经读取完毕了,直接退出循环即可。
if (ch == '\n') {
break dragon;
}
}
// 读取一个键
while (true) {
ch = (char) input.read();
if (ch == '\n') {
break;
}
value.append(ch);
}
// 存储读取的key和value,并去除左右空格
headMap.put(key.toString().trim(), value.toString().trim());
// 清空 key 和 value,为下一次读取做准备。
key.delete(0, key.length());
value.delete(0, value.length());
}
String fileName = UUID.randomUUID().toString() + suffix;
String content_Length = headMap.get("Content-Length");
System.out.println("网络资源大小:Content-Length --> " + content_Length);
System.out.println("网络资源编码:Content-Encoding --> " + headMap.get("Content-Encoding"));
int length = Integer.parseInt(content_Length);
// 读取响应报文数据部,即图片本身的二进制数据
try (OutputStream outputFile = new BufferedOutputStream(new FileOutputStream(new File("D:/DBC/socketPic", fileName)))) {
int hasRead = 0;
int len = 0;
byte[] b = new byte[1024];
while ((hasRead != length) && (len = input.read(b)) != -1) { // 这个如果是 || 非的话,永远也结束不了了!哈哈
outputFile.write(b, 0, len);
hasRead += len;
}
}
} catch (UnknownHostException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("网络资源已经下载完成了!");
}
}
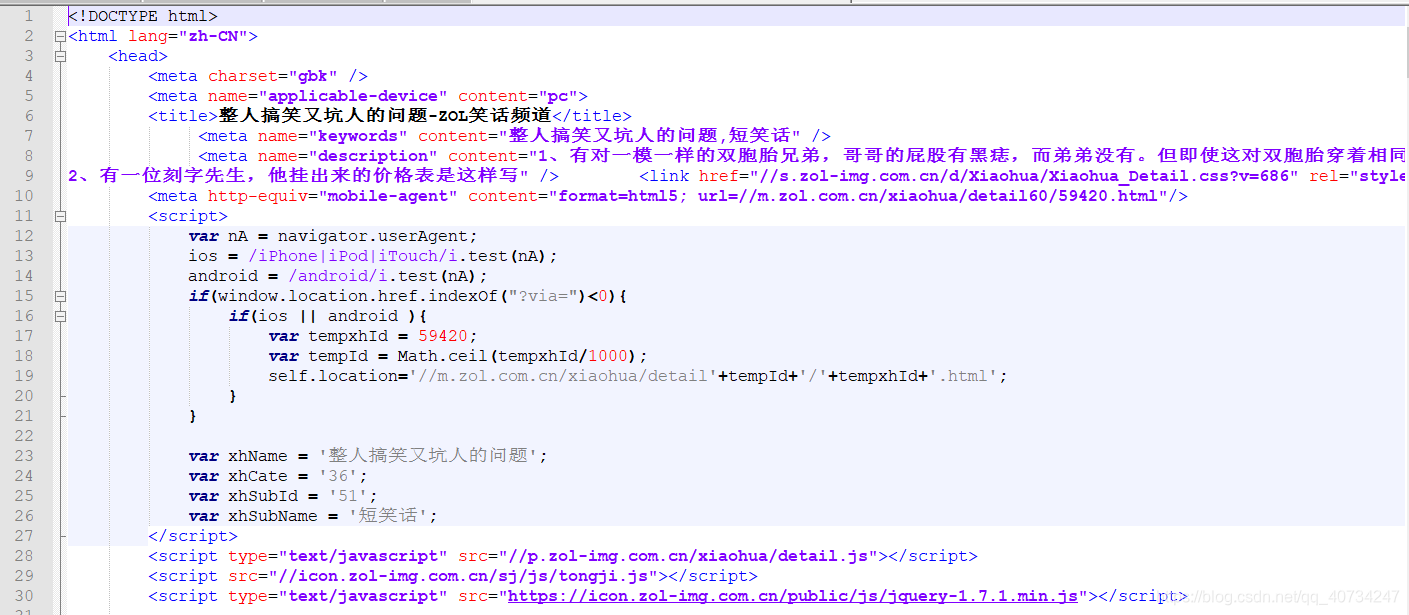
测试结果:主要此处没有Content-Encoding首部
这里测试3次,不过这个程序是没有缓存功能的,每次都是重新请求。
三次测试的结果



下载的文件
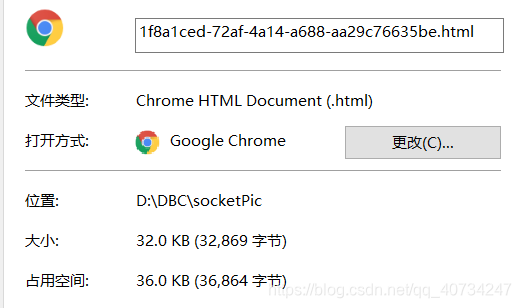
文件的内容
使用:Accept-Encoding: gzip
这里的注释去掉即可!
msgBuilder.append("GET").append(BLANK)
.append("/detail60/59420.html").append(BLANK).append("HTTP/1.1").append(CRLF)
.append("Host").append(":").append(BLANK).append(ip).append(CRLF)
.append("Accept-Encoding").append(":").append(BLANK).append("gzip").append(CRLF)
.append("User-Agent").append(":").append(BLANK).append("Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
+ " AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36").append(CRLF)
.append(CRLF);
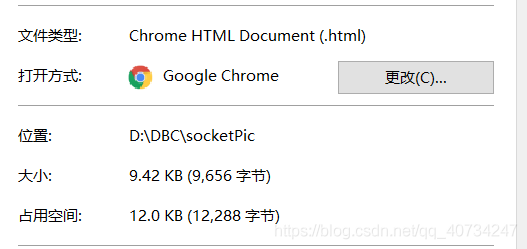
三次测试的结果



文件的大小
可以看出来,对于文件的压缩率还是非常可观的,但是对于图片这样的二进制数据,不建议使用gzip了。因为可能没什么效果,还拜拜增加了编码、解码的时间。(图片本身就是被编码了,打开的时候再解码,如果你还可以压缩,那只能说明图片本身的编码压缩率不行,但是这显然是不可能的!因为你这是在挑战那些顶点上的人物的权威!)
文件的内容
文件压缩率非常可观,但是文件却无法直接读取了。所以,需要一个额外的解码步骤。

解码gzip文件
package com.dragon;
import java.io.BufferedInputStream;
import java.io.ByteArrayOutputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.zip.GZIPInputStream;
public class GzipTest {
public static void main(String[] args) throws FileNotFoundException, IOException {
String fileName = "D:/DBC/socketPic/fa6bdfda-a0ad-4664-8297-4694f18f0304.html";
try (GZIPInputStream gzip = new GZIPInputStream(new BufferedInputStream(new FileInputStream(fileName)))) {
ByteArrayOutputStream output = new ByteArrayOutputStream();
int len = 0;
byte[] b = new byte[1024];
while ((len = gzip.read(b)) != -1) {
output.write(b, 0, len);
}
Files.write(Paths.get("D:", "DBC", "socketPic", "decode.html"), output.toByteArray());
}
}
}
注意:解码后的文件大小似乎不太对,但是对于这种文本格式的文件,基本上是没有什么问题的,并且具体原因我也不清楚。
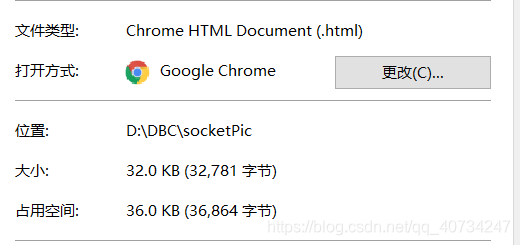
解码后的文件内容
使用高级类进行实验
使用URLConnection类来进行实验
package com.dragon;
import java.io.BufferedInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
import java.net.URLConnection;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.StandardCopyOption;
import java.util.UUID;
public class AdvancedMethod {
public static void main(String[] args) throws IOException {
long start = System.currentTimeMillis();
URL url = new URL("http://xiaohua.zol.com.cn/detail60/59420.html");
URLConnection connection = url.openConnection();
// connection.setRequestProperty("Accept-Encoding", "gzip");
System.out.println("Content-Length: " + connection.getContentLength());
System.out.println("Content-Encoding: " + connection.getContentEncoding());
try (InputStream input = new BufferedInputStream(connection.getInputStream())) {
String filename = UUID.randomUUID().toString() + ".html";
Path path = Paths.get("D:", "DBC", "socketPic", filename);
Files.copy(input, path, StandardCopyOption.REPLACE_EXISTING);
}
System.out.println("下载完成, 总耗时:" + (System.currentTimeMillis()-start) + " ms");
}
}
不使用 Accept-Encoding: gzip

使用 Accept-Encoding: gzip
解除上面那段注释代码即可!

注意:使用高级类库的代码来实验,计时时间和上面那个有所区别了。所以两个时间不能进行比较,这里重点应该关注的是文件的 Content-Length,这是gzip最大的作用,对于常用的html压缩效率非常好!
服务器需要支持gzip才行
还是使用这段高级类库来请求我的你愁啥服务器,虽然返回的是图片,但是它本身也是没有什么响应头的,总之它基本上什么功能都不支持。所以,Accept-Encoding 对于它还是没有任何用处的!但是,现在几乎所有网站都应该支持它了,我们应该很难遇到不支持压缩报文实体的Web服务器了。
package com.dragon;
import java.io.BufferedInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
import java.net.URLConnection;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.StandardCopyOption;
import java.util.UUID;
public class AdvancedMethod {
public static void main(String[] args) throws IOException {
long start = System.currentTimeMillis();
URL url = new URL("http://localhost:10000");
URLConnection connection = url.openConnection();
connection.setRequestProperty("Accept-Encoding", "gzip");
System.out.println("Content-Length: " + connection.getContentLength());
System.out.println("Content-Encoding: " + connection.getContentEncoding());
try (InputStream input = new BufferedInputStream(connection.getInputStream())) {
String filename = UUID.randomUUID().toString() + ".html";
Path path = Paths.get("D:", "DBC", "socketPic", filename);
Files.copy(input, path, StandardCopyOption.REPLACE_EXISTING);
}
System.out.println("下载完成, 总耗时:" + (System.currentTimeMillis()-start) + " ms");
}
}

总结
好了,也算是了解了一波内容编码了。这些较为细节的知识,还是很值的掌握的。有些技能,例如网络爬虫,其实对这个计算机网络,尤其是应用层的知识要求是很高的,虽然入门只是一个发送请求和接收响应就行了。但是真正的学习,还是需要那些底层的知识来支持(这里的底层是相对于爬虫这类高层应用而言,HTTP协议算是底层了,但是在所有协议中HTTP协议是高层协议!)。我也是觉得自己得基础知识还是不足以支持自己去学习爬虫得高级技术,所以还需要努力学习!














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









