







 本文介绍如何使用Python的tushare库批量下载股票数据。通过获取股票列表并利用循环逐个下载指定时间段内的前复权股票数据,最后将数据保存为CSV文件。
本文介绍如何使用Python的tushare库批量下载股票数据。通过获取股票列表并利用循环逐个下载指定时间段内的前复权股票数据,最后将数据保存为CSV文件。
# 数据接口调用
import tushare as ts
pro= ts.pro_api()
# stock_basic()获取所有,股票列表
Data = pro.stock_basic(exchange='', list_status='L', fields='ts_code,symbol,name,area,industry,list_date')
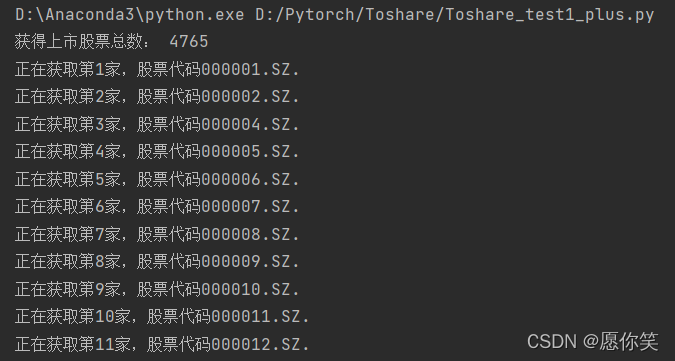
print('获得上市股票总数:', len(Data)-1)
# 截取所有股票编号
stocks=Data['ts_code']
j = 1
for i in list(stocks):
# 1.通过股票编号i,ts.pro_bar()获取股票i前复权信息,时间2010~2021
data = ts.pro_bar(ts_code=i, adj='qfq', start_date='20100101', end_date='20211231')
# 2.保存数据
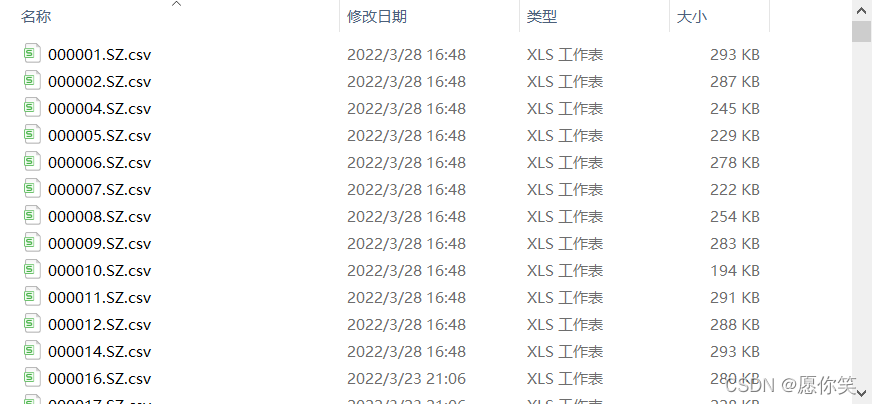
data.to_csv('E:\QuantDate/test/' + i + '.csv', index = False)
# 3.进度打印
print('正在获取第%d家,股票代码%s.' % (j, i))
j+=1
前提:1.tushare注册账号,并获得个人的token(数据获取权限)
2.python环境(这个不多讲)
运行效果:
注:如果觉得有用话,点个赞吧!

















 1393
1393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









