







目录
前言
本文主要是记录一次博主做接口性能压测时发现的线上接口性能问题,由于部分公司内容需要脱敏,所以本次只记录问题发现及排查过程,及最终处理方案。希望可以对大家日常发现并解决线上性能问题或者有接口性能压测需求时有所帮助。
一、背景
目前我们组核心系统A,日常qps保持在15K以上,高峰期会达到40K,所以日常pod数保持在600台以上,高峰期会扩容到1000+,单pod是8核12G内存配置。从稳定性和方便日常运维考虑,我们计划将目前的小容量pod扩容为高性能的大pod(期望16核32G内存及以上)。由于可选择的配置组合有很多(主要是cpu与内存的组合),需要对各个不同的配置方案的资源利用率做摸底,因此需要最大pod做接口级别的性能压测。
二、现象
首先,先说机器,当前线上机器配置与我们实际压测的机器配置如下表(这里只关注cpu与内存,并且只给了部分有代表性的机器):
| 单Pod压测实验 | |||
|---|---|---|---|
| 对比项 | Pod配置 | 预期结果(线上单pod的qps峰值50的倍数) | 实际结果(线上单pod的qps峰值50的倍数) |
| 线上基准 | 8C12G | 2倍 | 2.5倍 |
| 实验一 | 16c32G | 4倍 | 3倍(吞吐量刚加到3倍,失败率骤增) |
| 实验二 | 28C32G | 6倍 | 3.5倍(基本同上) |
| 实验三 | 28C64G | 7倍 | 3.5倍(基本同上) |
再来看一下具体的压测QPS
以上是我们在前期压测过程中发现吞吐量只能到线上3倍的过程中,尝试不同配置的压测结果(这个时候只观察了GC日志与JVM指标,由于在失败率上涨前GC时间明显上涨,一般是由0.07s逐步上涨到5s甚至更长,因此认为是GC的问题)。
这里给出一次压测时的性能指标图:
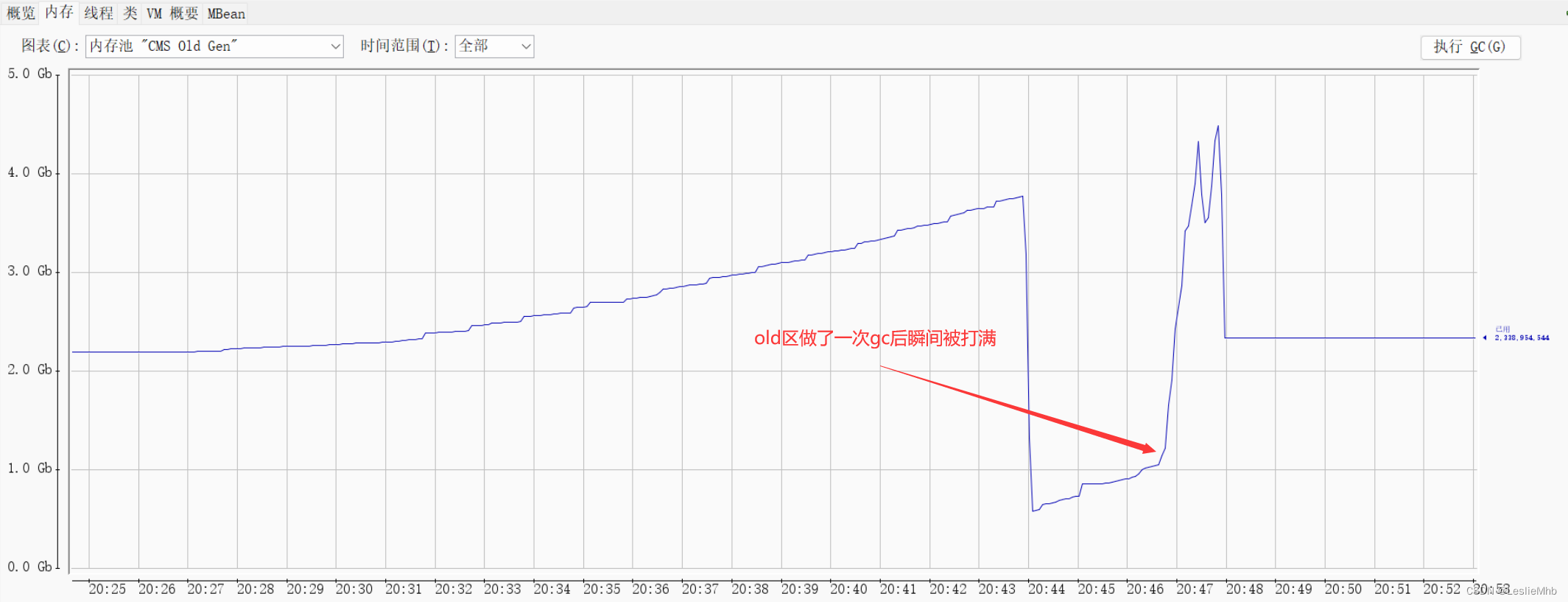

以上的图都能发现系统是在极短的时间内被压崩,并不是正常的吞吐量缓慢上涨导致。
接下来看一段有代表性的GC日志(删除部分内容,只看重点,并且以下日志内容是连续打印的gc日志)
2023-07-27T15:19:30.727+0800: 815.229: [GC pause (G1 Evacuation Pause) (young), 0.1130691 secs] (这里用的是G1,因为前期认为是垃圾回收算法的问题,但是不影响分析,因为现象基本一致) [Object Copy (ms): Min: 11.5, Avg: 12.2, Max: 12.3, Diff: 0.8, Sum: 340.8] [Times: user=1.12 sys=0.04, real=0.11 secs] (gc时间0.11s,在可接受的范围内,目前线上young gc平均耗时在0.16s左右) 2023-07-27T15:19:34.012+0800: 818.514: [GC pause (G1 Evacuation Pause) (young), 2.0252629 secs] [Object Copy (ms): Min: 1669.7, Avg: 1807.3, Max: 1903.2, Diff: 233.5, Sum: 50604.2] (这里关注到对象复制时间1.6s,占用大部分gc时间) [Times: user=16.51 sys=0.03, real=2.03 secs] (gc时间已经到2秒了,已经不是能接受的范围,这个时候已经开始出现请求失败现象) 2023-07-27T15:19:39.147+0800: 823.649: [GC pause (G1 Evacuation Pause) (young), 4.1699841 secs] [Object Copy (ms): Min: 3410.7, Avg: 3697.9, Max: 3908.8, Diff: 498.1, Sum: 103542.5] (复制时间4s) [Times: user=33.26 sys=0.04, real=4.17 secs] (gc时间飙到4.17) 2023-07-27T15:19:46.221+0800: 830.723: [GC pause (G1 Evacuation Pause) (young), 5.9299562 secs] [Object Copy (ms): Min: 5122.1, Avg: 5534.4, Max: 5767.8, Diff: 645.7, Sum: 154962.8] [Times: user=47.57 sys=0.10, real=5.93 secs] (继续飙) 2023-07-27T15:19:55.248+0800: 839.750: [GC pause (GCLocker Initiated GC) (young), 8.2720394 secs] [Object Copy (ms): Min: 7191.5, Avg: 7658.1, Max: 7985.0, Diff: 793.4, Sum: 214425.9] [Times: user=65.80 sys=0.09, real=8.27 secs] (不想看了,停止压测) |
在以上日志中可以看到gc时间是在大约20s的时间内就直接飙升到被迫停止压测。
Object Copy耗时大约占了gc时间的90%以上,因此怀疑是系统里面有大对象,dump了内存准备排查。
三、排查
首先,怀疑了当时系统中存在大对象并且回收不掉,可以先看一下dump的内存到底啥样:

这个时候没有任何思路,因为dump的内存看不出来任何异常,并且这些报价会在一次gc后被正常回收。但是想到了还有一种情况,或许是dump的时机不对,因此在一次测试中,在不同的时间点都做了内存dump,终于有了一些不同的发现,
接下来看一下记录了不同时间段的dump结果(为了避免频繁dump,导致机器重启,以下dump结果并不是在同一次压测中、同一个配置下完成的):
第一次:

第二次:
第三次:
第四次:注意这里的3000万个实例
这里发现了java.util.concurrent.LinkedBlockingDeque$Node 和com.qunar.hotel.qmonitor.QMonitor$TDigestQueueItem十分可疑,从命名上看起来有点像Qmonitor,并且还有一个是阻塞双端队列,本来这里用的VisualVM分析的内存,发现了可疑点直接切换到MAT上看一下:

发现几百个线程全部堵在我们核心系统A的一个过滤模版组件上,再往下走是堵在了com.qunar.hotel.qmonitor.QMonitor.recordQuantile上。
接下来去看一下这段代码到底在干啥?为啥都会堵在这里:
public boolean doFilter(PriceEngineContext context, WrapperPriceEntry wp) {
long start = System.currentTimeMillis();
try {
// 一部分业务代码
} catch (Exception e) {
} finally {
// 这里是线程卡住的起点
QMonitorUtils.recordOne(name(), System.currentTimeMillis() - start);
} |
再看一下recordOne做了什么:
public static void recordOne(String metricName, long time) {
// 这里调用这个方法记录P98等指标
QMonitor.recordQuantile(metricName, time);
}
public static void recordQuantile(String metricName, long time) {
QMonitorInternal.recordCerberusTimer(metricName, 1L, time);
// 继续往下调用
QMonitorInternal.recordComboMany(metricName, 1L, time, true);
}
static void recordComboMany(String name, long count, long time, final boolean saveSample) {
QtraceMetricSample.qtraceMetricSample(name,time);
ComboMonitorItem comboMonitorItem = getOrCreateValueFromConcurrentMap(comboMonitorItems, name, new Supplier<ComboMonitorItem>() {
@Override
public ComboMonitorItem get() {
return new ComboMonitorItem(saveSample);
}
});
// 进来这里开始往tDigestSampleQueue 里塞值,需要看一下tDigestSampleQueue 是个啥?
comboMonitorItem.add(count, time, saveSample ? tDigestSampleQueue : null);
}
// 到了这里突然就看到了两个关键点,一个LinkedBlockingDeque,一个TDigestQueueItem对象(前面提到这两在dump的内存中有3000万个对象,原来在这里)
private final static BlockingQueue<TDigestQueueItem> tDigestSampleQueue = new LinkedBlockingDeque<TDigestQueueItem>();
// 继续往下走,看这个在干嘛
tDigestWorker.execute(new Runnable() {
@Override
public void run() {
try {
TDigestQueueItem tdItem = null;
while ((tdItem = tDigestSampleQueue.take()) != null) {
try {
// 这里看到调用了tDigestCalc方法,看起来是一个计算方法,是在一个线程池中计算的,那就看看这个线程池
tdItem.item.tDigestCalc(tdItem.time);
} catch (Exception e) {
LOGGER.error("qmonitor t-digest thread error", e);
}
}
} catch (InterruptedException e) {
LOGGER.info("qmonitor t-digest thread stopped");
}
}
});
// 这里可以看到是一个单线程的线程池在执行
private static final ExecutorService tDigestWorker = Executors.newSingleThreadExecutor(new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "hotel-QMonitor-tDigest-worker");
}
});
|
四、猜测
到了这里基本可以确定是Qmonitor记录监控处理有问题,以上代码是用来计算P98、P99等分位数指标的方法,结合代码看就是业务往这个LinkedBlockingDeque中添加的指标太多,单线程计算指标根本计算不过来,导致了队列元素飙升,并且这个队列没有抛弃策略,长度为 MAX_VALUE = 0x7fffffff(这也是为什么前面的第四次dump结果会出现3000w个指标实例的原因),因此导致了内存飙升、GC时间疯狂上涨,业务线程全部卡死。
目前的解决办法有两个:
第一,不要记录这么多的指标,但是日常运维需要这些P99、P98指标来观测系统稳定性,因此否定;
第二,更换监控测略,比如升级Qmonitor实现方式等
在思考解决办法之前,为了验证猜测的准确性,我准备找到代码中所有调用Qmonitor.recordQuantile()的地方全部替换为普通监控,先看看实际效果,本来以为修改的地方较多,好在核心系统A做完DDD后,只在组件模版处做了统一监控调用,因此,只修改了两行代码:
// 这里是我们业务自己简单封装的一层Qmonitor
public class QMonitorUtils {
public static void recordOne(Enum monitorKey, long time) {
// 这里用到了recordQuantile,因此直接注释掉,换成普通的监控recordOne,不记录P98
//QMonitor.recordQuantile(monitorKey.name(), time);
QMonitor.recordOne(monitorKey.name());
}
public static void recordOne(String metricName, long time) {
// 此处同理
//QMonitor.recordQuantile(metricName, time);
QMonitor.recordOne(metricName);
}
} |
五、验证
接下来就是重新发布,验证猜测的准确性,还是同样的配置,同样的请求,再来一次!
接下来,看一下重新发布后的压测结果,已经达到了260qps,是线上的5倍流量
接下来看一些系统指标,这下再也没有在某个时间点突然飙升了(之前的所有压测中,飙升现象是必现的)


六、优化
前面提到我们线上目前使用的是com.qunar.hotel.qmonitor.QMonitor,它的特点是使用了LinkedBlockingQueue存放指标,长度为 MAX_VALUE = 0x7fffffff,并且没有抛弃策略,最终导致内存飙升;
因此我们替换为com.qunar.flight.qmonitor.QMonitor包,他的不同点之一在于使用了LinkedBlockingQueue存放指标,但是长度默认为1000000,并且有丢弃策略,得益于此,在失败率没有上涨之前,没有发现内存飙升的现象,但是暴露出来了另外一个问题,这个问题就是由于LinkedBlockingQueue是一个线程安全的队列,在高并发情况下,可能会导致内部锁竞争(主要是发生在java.util.concurrent.LinkedBlockingDeque#offer(E)这个存放指标元素的API),这可能导致性能下降或线程阻塞,当qps上升后,触发堵塞的概率会更大,因此前面的分析其实遗漏了这个问题。可以从线程栈中对这点进行验证,下面给出了一个线程堵塞时的栈,可以看到阻塞在了LinkedBlockingQueue.offer(),因为内部实现使用了锁来保证线程安全。
基于以上,目前我仍然没有彻底解决QMonitor引起的吞吐量问题,但是可以发现限制系统吞吐量的罪魁祸首是QMonitor里的阻塞队列,因此只要解决队列这个卡点理论上就可以提高系统的吞吐量。咨询相关团队后,了解到com.qunar.flight.qmonitor.Qmonitor包下的监控可以开启同步策略模式,即配置core.calc.strategic=0就可以将默认的记录方式由异步切换为同步,由于同步方式不再使用阻塞队列记录指标,因此将不再是目前吞吐量的卡点,以下是更换策略为同步模式后的压测结果:
但是,值得注意的点是开启同步策略后,接口的响应时间理论上会上涨,因为需要业务线程自己去计算分位数监控值。经过我的的测试,以下统计了不同配置、不同qps压力、监控模式为同步模式下的响应时间及P98的变化值(红色表示相较于线上基准时间上涨,绿色表示相较于线上基准时间有所下降)
从以下表格展示的数据可以得出一个初步的结论:使用同步模式会让系统A的接口的平均响应时间上涨;在一定qps阈值以内,系统A的接口的P98会有所下降,这可能得益于单机pod性能的提升(这里需要继续研究为什么没有上涨)。未来如果系统A使用同步模式记录监控,为了不让响应时间上涨太多,可能需要针对部分监控做一定程度的精简。
| 指标类别 | 线上基准 | 28C32G | 16C16G | ||||
| 单机 | 50qps | 92(14+68) | 155(28+127) | 251(51+200) | 93(16+77) | 171(26+145) | 210(44+156) |
| 接口响应时间 | D: Max=156 , Avg= 114, Min=68 L: Max= 121, Avg=83 , Min=59 | D: Max=167 , Avg= 151(+32%), Min=126 L Max= 102, Avg= 92(+10.8%), Min=86 | D: Max=171 , Avg= 140(+31%), Min=1004 L Max= 102, Avg= 93(+12%), Min=86 | D: Max=171 , Avg= 144(+26.3%), Min=104 L Max= 102, Avg= 93(+12%), Min=86 | D: Max=130 , Avg= 104(-5%),Min=83 L: Max= 93, Avg= 90(+8%), Min=88 | D: Max=130 , Avg= 111(-2.6%),Min=83 L: Max= 99, Avg= 93(+12%), Min=88 | D: Max=157 , Avg= 122(+7%), Min=83 L: Max= 119, Avg= 98(+18%), Min=88 |
| P98响应时间 | D: Max= 271, Avg= 385, Min=137 L: Max= 870, Avg= 204, Min=158 | D Max= 441, Avg=367(-4.6%), Min=312 L Max= 246, Avg= 201(-1.4%), Min=172 | D: Max=441 , Avg= 360(-6.4%), Min=312 L Max= 246, Avg= 201(-1.4%), Min=172 | D: Max=451 , Avg= 386(+1.3%), Min=312 L Max= 264, Avg= 214(+4.9%), Min=172 | D: Max=364 , Avg= 314(-18.4%), Min=257 L Max= 202, Avg= 196(-2%), Min=189 | D: Max=396 , Avg= 337(-2%), Min=257 L Max= 217, Avg= 201(-1.4%), Min=189 | D: Max=606 , Avg= 391(+1.5%), Min=257 L Max= 375, Avg= 236(+15%), Min=189 |
| CPU利用率 | 20% | 37% | 55% | 20% | 35% | 68% | |
| 内存利用率 | 60% | 63% | 65% | 69% | 75% | 82% | |
七、结论
- 本来至少能提升5倍吞吐量的高性能大pod,在压测阶段发现每次只能压测到线上基准吞吐量的3倍,排查后发现使用的QMonitor监控是卡点;
- 当前线上,我们的核心系统A使用的是com.qunar.hotel.qmonitor.Qmonitor包下的API记录P99等分位数,它在底层使用了LinkedBlockingDeque异步记录指标数据,队列长度为默认值0x7fffffff,将指标数据处理为分位数的线程池为newSingleThreadExecutor,这种异步单线程的实现方式可以更少的占用资源,但是在压测时发现吞吐量达到一定限制后会出现两个问题:第一个问题是高并发情况下单线程处理速度较慢,LinkedBlockingDeque没有限制长度和没有丢弃策略,大量的业务线程往队列里面塞指标,会导致队列无限制增长,最终会导致使用内存飙升;第二个问题是高并发情况下,由于LinkedBlockingDeque是线程安全队列,大量的业务线程往LinkedBlockingDeque中使用offer操作添加元素,会导致线程之间的锁竞争与堵塞,最终影响吞吐量;
- 基于上一点,压测环境中的代码切换为使用com.qunar.flight.qmonitor.Qmonitor包下的API记录P99等分位数,该包下的API支持通过配置的方式修改队列长度(默认值10000000),以及线程池的线程数量(默认核心线程数为2,最大线程数为2),再次压测后依然没有解决系统吞吐量问题,原因在于限制队列长度以及增加处理线程数虽然解决了内存飙升的问题,但是不能解决高并发情况下锁竞争导致的线程堵塞问题;
- 因此,为了进一步解决堵塞问题,通过配置的方式,将监控记录方式从异步计算调整为同步计算,即业务线程本地计算分位数,不再依赖异步队列实现,最终解决吞吐量问题;
- 但是,切换为同步计算策略后,会导致接口的响应时间上涨,具体上涨多少依赖于分位数监控的使用量以及分位数算法的性能。从稳定性上看,如果是类似于sirius这种高并发、分位数监控记录较多的系统,可以考虑使用Flight包下的监控API,同时开启同步计算策略,因为一旦单机QPS上涨就有出现线程堵塞的可能性,如果接口的响应时间上涨较多可以通过优化业务代码降低影响。
最后,为什么以前没有发现过这个问题呢?其实主要是因为以前pod数较多,导致单机qps基本保持在50qps左右,而从压测结果来看,通过单线程来记录P98是完全扛得住的,他的极限大概在120Qps左右,但是当单机qps起来后,大量的业务线程打点都需要这个单线程处理,已经明显扛不住了,所以本次压测刚好暴露出了这个潜在的问题。















 2600
2600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









