







Golang map和 sync.Map
- map底层实现和扩容机制
- sync.map安全机制
1. map
和java中hashmap一样,Go中的map是基于哈希来实现的,同样也是采用链地址法来解决法系冲突,采用的是数组+链表的方式来表达map,这一点和java不同,java是通过数组+链表+红黑树来实现的。
1.1. 结构体
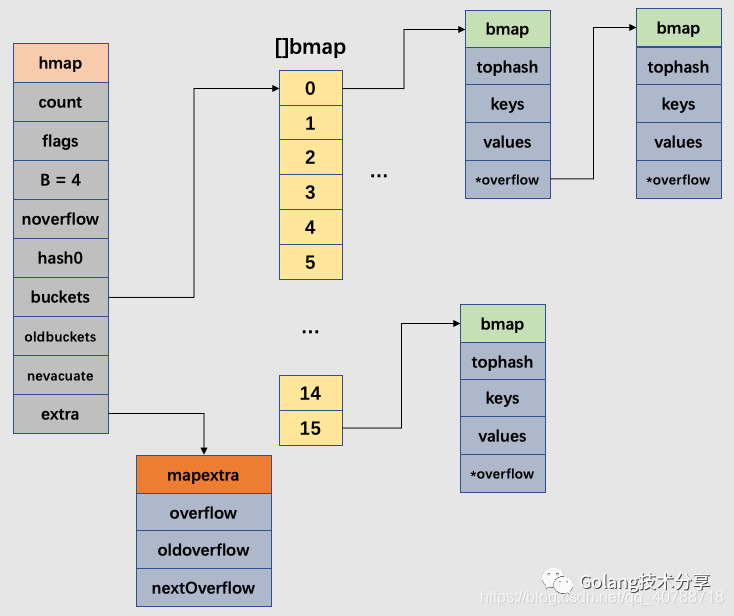
hmap
type hmap struct {
count int //当前保存元素的个数
flags uint8
B uint8 // bucket数组的大小(幂)
noverflow uint16 // 溢出的bucket数量
hash0 uint32 // hash seed
buckets unsafe.Pointer // bucket数组指针,数组的大小为2^B
oldbuckets unsafe.Pointer
nevacuate uintptr // 迁移进度计数器(小于此值的桶已被迁移)
extra *mapextra
}
bmap
bucket的结构体
type bmap struct {
tophash [8]uint8
keys [8]keytype //长度为8 这里和Java要求的链表长度相同
values [8]valuetype
pad uintptr
overflow uintptr // 溢出区
}
注:说明链表中的每个节点可以存放8组kv
问题:
-
为啥一个bucket存8个kv,而不是一个bucket存一个kv,然后形成链表
- 一次分配8个kv的空间,可以减少内存的分配频次
- 减少了overflow指针的内存占用
type bmap struct { tophash [8]uint8 keys [8]uintptr // values [8]uintptr // pad uintptr overflow uintptr } type bmapEle struct { tophash uint8 key uintptr // value uintptr // overflow uintptr } func main() { var b bmap size := unsafe.Sizeof(b) fmt.Println("bmap结构体大小:",size) //152 var e bmapEle size = unsafe.Sizeof(e) fmt.Println("bmapEle结构体大小:",size*8) //256 } -
为啥key和value要分开存
- key 和val 都是自定义的。如果key是定长的(比如是数字,或者 指针之类的,大概率是这样。)内存是比较整齐的,利于寻址吧。
-
为啥容量大小为8
- java中的hashmap链表长度也为8,根据统计学节点数为8的概率接近千分之一,而此时的单个链表的性能已经变差。所以golang中超过8个的都在溢出区中
图片展现
map中的数据被存放于一个数组中的,数组的元素是桶,每个桶至多包含8个键值对数据。哈希值低位用于选择桶,哈希值高位用于在一个独立的桶中区别出键。所以tophash = 10010111,在buckets[10]中

容量为16的数组大致是这个样子
1.2. 创建map的方法
创建map的重点:
- map的大小的设置
// make(map[string]string)
func makemap_small() *hmap {
h := new(hmap)
h.hash0 = fastrand()
return h
}
// make(map[string]string, size)
func makemap64(t *maptype, hint int64, h *hmap) *hmap {
if int64(int(hint)) != hint {
hint = 0
}
return makemap(t, int(hint), h)
}
// map[string]string{"1":"1"}
func makemap(t *maptype, hint int, h *hmap) *hmap {
//判断存储的长度是否越界
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
if h == nil {
h = new(hmap)
}
//*
//设置hash种子 应该是防止攻击的,赋值的情况是在创建和清空的时候
h.hash0 = fastrand()
//*
//判断hint是否大于当前的桶长度*负载因子, hint < 6.5 * (2 ^ B) 且 B最大为63
//也就是将桶长度变成大于且最接近hint的2的B次方(和java相同)
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
//B!=0 m := map[string]string{"1":"1"} 这种情况,直接创建bucket数组
//B=0 bucket采用mapssign方法中的lazily分配
if h.B != 0 {
var nextOverflow *bmap
// makeBucketArray创建一个map的底层保存buckets的数组,它最少会分配h.B^2的大小。
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}
问题:
- 为啥是2的幂次方
- 为了做完hash后,通过位运算的方式取到数组的偏移量, 省掉了不必要的计算。
1.3. 操作(insert)
通过位运算获取tophash
func tophash(hash uintptr) uint8 {
top := uint8(hash >> (sys.PtrSize*8 - 8))
if top < minTopHash {
top += minTopHash
}
return top
}
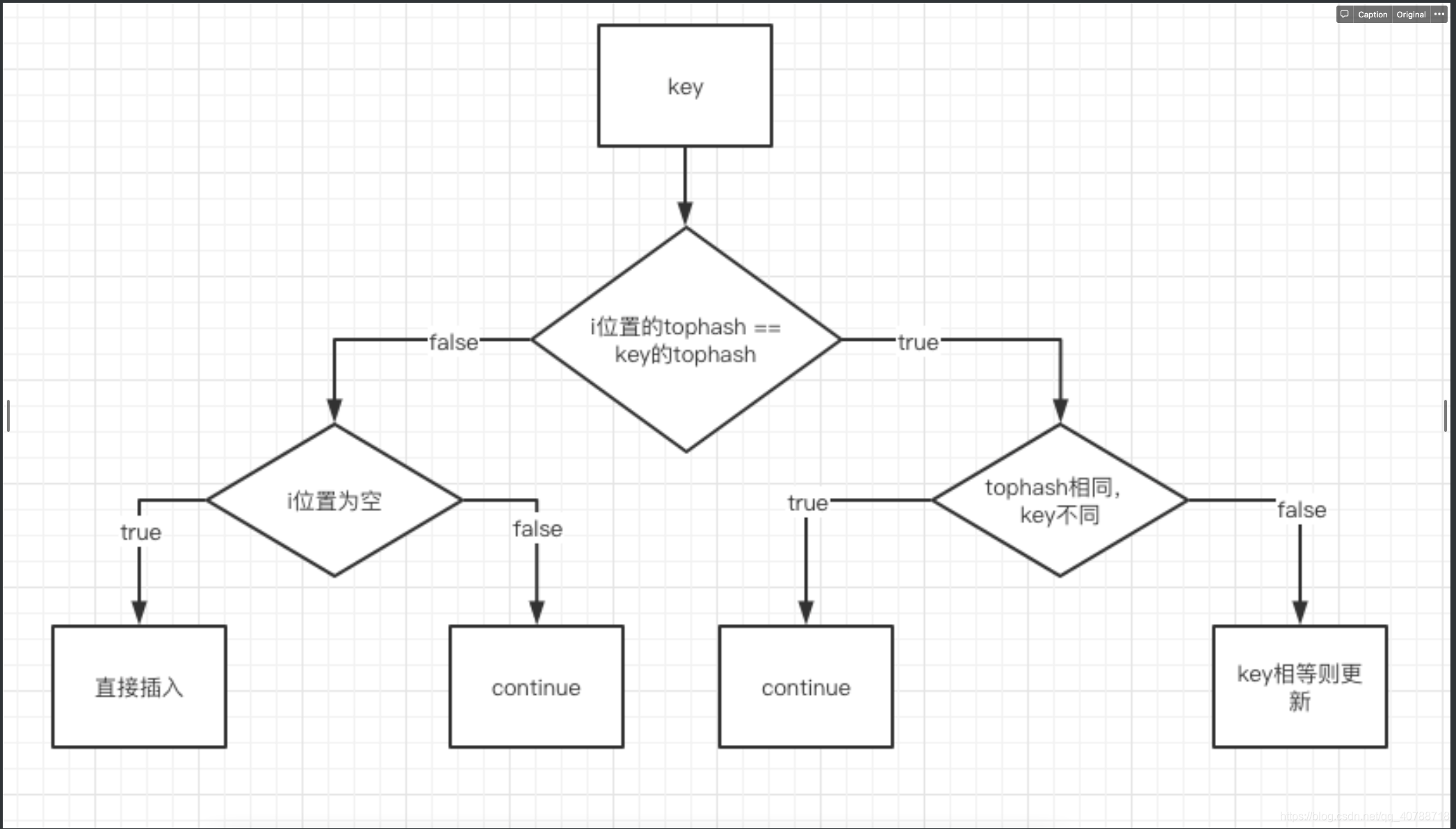
当两个不同的key落在了同一个桶中,这时就发生了哈希冲突。go的解决方式是链地址法:
在同一个bucket中一直往下找合适位置,如果没找到,则进入溢出桶找
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
//省略部分
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
//计算hash值
hash := t.hasher(key, uintptr(h.hash0))
//记录当前有正在写入的goroutine
h.flags ^= hashWriting
//懒加载
if h.buckets == nil {
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
again:
//获取桶的位置,bucketMask返回的是2^B-1
bucket := hash & bucketMask(h.B)
//协助迁移
if h.growing() {
growWork(t, h, bucket)
}
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
top := tophash(hash)
var inserti *uint8
var insertk unsafe.Pointer
var elem unsafe.Pointer
bucketloop:
for {
//遍历每组8个kv
for i := uintptr(0); i < bucketCnt; i++ {
//第一种:如果cell为空,就可以在对应位置插入
if b.tophash[i] != top {
if isEmpty(b.tophash[i]) && inserti == nil {
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
}
//若后续无数据,则选定这个cell
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
//第二种:cell位置的tophash和key的tophash相同
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
//可能只是tophash相等,但是key不等
if !t.key.equal(key, k) {
continue
}
//如果key相等则更新
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
//获取value的内存地址
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
goto done
}
//如果8个cell都没放进去,则进入下一个溢出桶
ovf := b.overflow(t)
//溢出桶都没有位置
if ovf == nil {
break
}
b = ovf
}
//触发扩容机制
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again
}
//创建新的溢出桶,并放入key
if inserti == nil {
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.keysize))
}
if t.indirectkey() {
kmem := newobject(t.key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
if t.indirectelem() {
vmem := newobject(t.elem)
*(*unsafe.Pointer)(elem) = vmem
}
typedmemmove(t.key, insertk, key)
*inserti = top
//元素的个数加1
h.count++
done:
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
h.flags &^= hashWriting
if t.indirectelem() {
elem = *((*unsafe.Pointer)(elem))
}
return elem
}
通过对mapassign的代码分析之后,发现该函数并没有将插入key对应的value写入对应的内存,而是返回了value应该插入的内存地址。
问题:
- 为什么用tophash来比较
- 一般的hash,实现逻辑是直接和key比较,如果比较成功,这找到相应key的数据。但是这里用到了tophash,好处是可以减少key的比较成本
1.4. map扩容 - 渐进式扩容
触发扩容的场景:
-
达到负载,(kv太多)
判断已经达到装载因子的临界点,即元素个数 >= 桶的总数 * 6.5,这时候说明大部分的桶可能都快满了(即平均每个桶存储的键值对达到6.5个),如果插入新元素,有大概率需要挂在溢出桶上。
解决方案:
将 B + 1,新建一个buckets数组,新的buckets大小是原来的2倍,然后旧buckets数据搬迁到新的buckets。该方法我们称之为增量扩容。
-
溢出桶过多,(kv分布太分散)
判断溢出桶是否太多
当桶总数 < 2 ^ 15 时,如果溢出桶总数 >= 桶总数,则认为溢出桶过多。
当桶总数 >= 2 ^ 15 时,直接与 2 ^ 15 比较,当溢出桶总数 >= 2 ^ 15 时,即认为溢出桶太多了。
解决方案:
并不扩大容量,buckets数量维持不变,重新做一遍类似增量扩容的搬迁动作,把松散的键值对重新排列一次,以使bucket的使用率更高,进而保证更快的存取。该方法我们称之为等量扩容。
```go
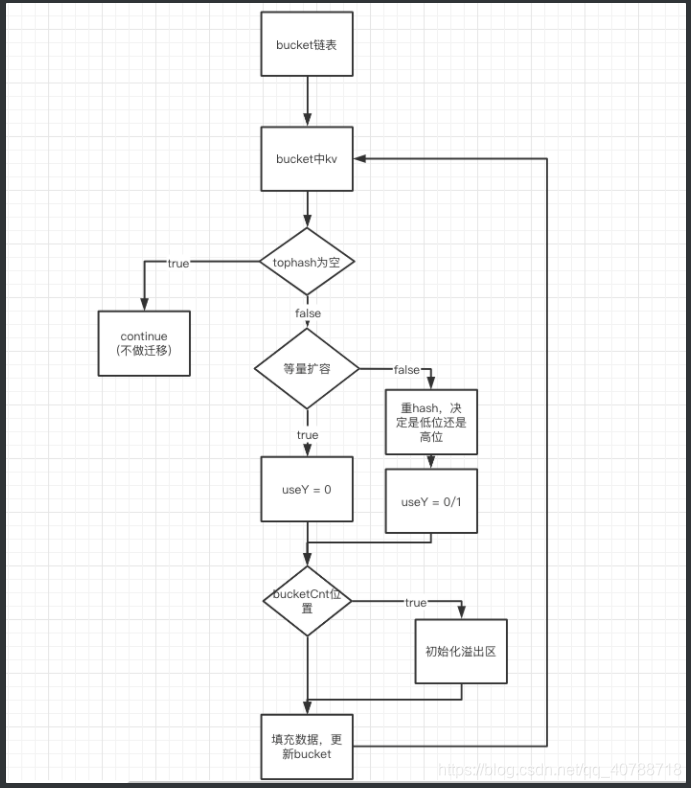
func growWork(t *maptype, h *hmap, bucket uintptr) {
//首先把需要操作的bucket搬迁
evacuate(t, h, bucket&h.oldbucketmask())
// 再顺带搬迁一个bucket
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}
```
```go
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
//先要判断当前bucket是不是已经转移。
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
newbit := h.noldbuckets()
if !evacuated(b) {
//如果没有被转移,那就要迁移数据了
//x 表示 迁移到相同的位置
//y 表示 迁移到当前位置2倍的位置
var xy [2]evacDst
x := &xy[0]
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.keysize))
//2倍扩容的情况下
if !h.sameSizeGrow() {
//计算高位
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.keysize))
}
// 确定bucket位置后,需要按照kv 一条一条做迁移。(目的就是清除空闲的kv)
for ; b != nil; b = b.overflow(t) {
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.keysize))
// 遍历数组中的每个kv
for i := 0; i < bucketCnt;
i, k, e = i+1, add(k, uintptr(t.keysize)), add(e, uintptr(t.elemsize)) {
top := b.tophash[i]
if isEmpty(top) { //空的不做迁移
b.tophash[i] = evacuatedEmpty
continue
}
if top < minTopHash { //
throw("bad map state")
}
k2 := k
if t.indirectkey() {
k2 = *((*unsafe.Pointer)(k2))
}
var useY uint8
//如果是增量扩容
if !h.sameSizeGrow() {
hash := t.key.alg.hash(k2, uintptr(h.hash0))
if h.flags&iterator != 0 && !t.reflexivekey() && !t.key.alg.equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
if hash&newbit != 0 {
useY = 1
}
}
}
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY
dst := &xy[useY] // evacuation destination
//最后一位的话,初始化溢出区
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.keysize))
}
// 填充tophash
dst.b.tophash[dst.i&(bucketCnt-1)] = top
if t.indirectkey() {
*(*unsafe.Pointer)(dst.k) = k2
} else {
typedmemmove(t.key, dst.k, k)
}
if t.indirectelem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.elem, dst.e, e)
}
//更新目标的bucket
dst.i++
dst.k = add(dst.k, uintptr(t.keysize))
dst.e = add(dst.e, uintptr(t.elemsize))
}
}
// 对于key 非间接使用的数据(即非指针数据),做内存回收
if h.flags&oldIterator == 0 && t.bucket.ptrdata != 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))
// Preserve b.tophash because the evacuation
// state is maintained there.
ptr := add(b, dataOffset)
n := uintptr(t.bucketsize) - dataOffset
memclrHasPointers(ptr, n)
}
}
// 设置完成的标记值
if oldbucket == h.nevacuate {
advanceEvacuationMark(h, t, newbit)
}
}
```
2. sync.map
sync.Map是goroutine-safe的,采用的是读写分离的机制,降低锁的粒度,提高并发性能。
sync.map 适用于读多写少的场景。对于写多的场景,会导致 read map 缓存失效,需要加锁,导致冲突变多;而且由于未命中 read map 次数过多,导致 dirty map 提升为 read map,会进一步降低性能。
2.1. 结构体
map
type Map struct {
// 当涉及到dirty数据的操作的时候,需要使用此锁
mu Mutex
//一个只读的数据结构,因为只读,所以不会有读写冲突
read atomic.Value
//包含当前最新的数据,对于dirty的操作
dirty map[interface{}]*entry
// 当从Map中读取entry的时候,如果read中不包含这个entry,
// 会尝试从dirty中读取,这个时候会将misses加一,
// 当misses累积到 dirty的长度的时候,
// 就会将dirty提升为read,避免从dirty中miss太多次。因为操作dirty需要加锁。
misses int
}
readonly
type readOnly struct {
//
m map[interface{}]*entry
//如果Map.dirty有些数据不在其中则为true
amended bool
}
设计方面
read map指向了readOnly结构体对象,readOnly结构体本身是只读的 但是read map指向的引用是可变的dirty map是一个结构为map[interface{}]*entry的内建map类型- 让他俩之间产生关联的是sync.Map 中的
misses字段。
2.2. Load操作
Load操作返回存储在map中指定key的value,有两个返回值,ok表示key对应的value是否存在。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-a5z2F2G3-1627825923876)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/a9532537-a85f-45b1-9f42-6b151302b2ea/Untitled.png)]](https://img-blog.csdnimg.cn/70c15aeac83e44f2aa7dce46c40e8bac.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQwNzg4NzE4,size_16,color_FFFFFF,t_70)
func (m *Map) Load(key interface{}) (value interface{}, ok bool) {
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
//read中没有并且read不是最新的,
if !ok && read.amended {
m.mu.Lock()
// 双重效验锁
// double-check 避免我们获得锁期间 ditry map已经晋升为了read map
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended {
e, ok = m.dirty[key]
//记录miss 当前这个key会一直执行slow path直到dirty map晋升为read map
m.missLocked()
}
m.mu.Unlock()
}
if !ok {
return nil, false
}
return e.load()
}
func (m *Map) missLocked() {
m.misses++
//当缺失数据的数量 >= dirty中元素时 dirty会晋升到ready
if m.misses < len(m.dirty) {
return
}
m.read.Store(readOnly{m: m.dirty})
m.dirty = nil
m.misses = 0
}
2.3. Store操作(insert)
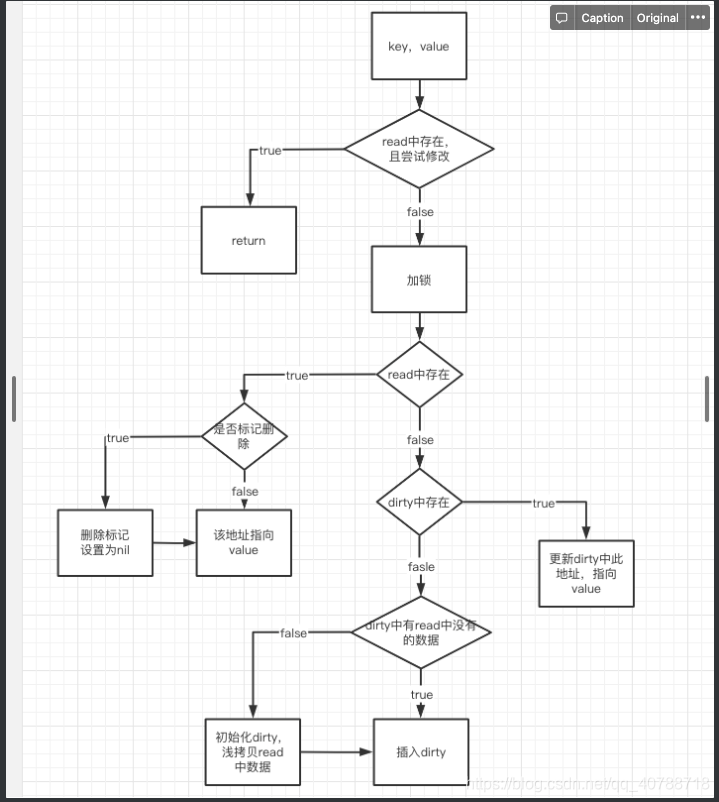
func (m *Map) Store(key, value interface{}) {
read, _ := m.read.Load().(readOnly)
//尝试修改
if e, ok := read.m[key]; ok && e.tryStore(&value) {
return
}
//依旧采用双重效验锁
m.mu.Lock(
read, _ = m.read.Load().(readOnly)
if e, ok := read.m[key]; ok {
if e.unexpungeLocked() { //如果标记为被删除,取消删除,重新利用该地址,算是update操作
m.dirty[key] = e
}
e.storeLocked(&value)
} else if e, ok := m.dirty[key]; ok { //update操作
e.storeLocked(&value)
} else { //insert操作
if !read.amended {
//dirty是空,构建新的dirty,将read中的数据浅拷贝一次
m.dirtyLocked()
//amended: true 说明dirty中有些数据不在read中
m.read.Store(readOnly{m: read.m, amended: true})
}
m.dirty[key] = newEntry(value)
}
m.mu.Unlock()
}
func (m *Map) dirtyLocked() {
if m.dirty != nil {
return
}
read, _ := m.read.Load().(readOnly)
// 生成新的dirty,将read中的让入dirty中
m.dirty = make(map[interface{}]*entry, len(read.m))
for k, e := range read.m {
if !e.tryExpungeLocked() {
m.dirty[k] = e
}
}
}
mux在read缺失数据的时候会锁全表,可能会影响map的性能,更适合读多写少的场景
参考:
https://zhuanlan.zhihu.com/p/273666774
https://blog.csdn.net/m0_37579159/article/details/79344079














 2927
2927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









