







 博主使用Python的wordcloud库分析了网易云音乐歌曲评论,生成了反映歌曲印象的词云图,包括《我们》、《拥抱》等六首热门歌曲的评论情感和主题。
博主使用Python的wordcloud库分析了网易云音乐歌曲评论,生成了反映歌曲印象的词云图,包括《我们》、《拥抱》等六首热门歌曲的评论情感和主题。
最近试着抓了一下网易歌曲的评论。因为听说python有个wordcloud的包很好用,然后就想用歌词的评论来形成一个词云,用来描述大家对这首歌曲的印象和感慨。
每首歌都抓了前30页评论。
总共抓取了六首歌:
陈奕迅《我们》
五月天《拥抱》
五月天《后来的我们》
《光辉岁月》
《你的名字:前前前世》
《七月上》
赵雷《成都》
GALA《追梦赤子心》
许嵩《千古》
爱丽丝镇楼。

下面是原图。

下面简单说说过程:

这是我们的目标。我抓了每首歌曲前三十页的评论。
然后分析网页结构:
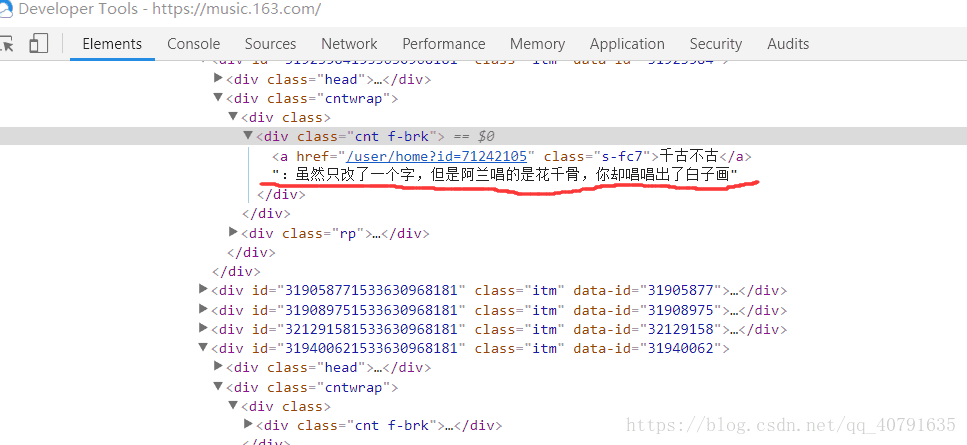
找到标签之后,把程序写好:

成功!每一条评论都保存到了一个数组中。
好了,到底这些词云是什么样子的呢:
陈奕迅《我们》:

后来的我们,却没有了我们。
五月天《拥抱》:

昨天太近,明天太远,默默聆听那黑夜。
分不清是诗还是歌。
五月天《后来的我们》:

后来呢?后来啊。没有后来了。
《光辉岁月》:

风雨中爆干基友???那么重点来了。。。歌友开的玩笑。
世上再无黄家驹,世间再无黄家驹,出现很多很多。
《你的名字:前前前世》:

没想到吧!这首歌,刷卢本伟和卢姥爷比较多,因为卢姥爷在B站很火,听这首歌一般都是二次元来的。
《七月上》:

我欲乘风破浪,踏遍黄沙海洋。
赵雷《成都》:

回忆是思念的愁,带不走的只有你。
GALA《追梦赤子心》:

满满的正能量,加油加油加油!干巴爹!
许嵩《千古》:

不悔做你的信徒。
最后还有更好玩的:
爱心形状的词云:


帅气酷炫的龙图腾:



像这种比较窄的图片,没有大面积连在一起的,都是把句子用Jieba打碎成了一个一个的词语形成的,所以看起来语义上并没有太多意思,就是一个个单个的词语。
用成都做成的吉他:



用《千古》做的大树词云图:


正文到这里就结束了!
代码部分:
import re
from selenium.webdriver import *
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
chrome_options = ChromeOptions()
chrome_options.add_argument('--headless')
browser = Chrome(chrome_options=chrome_options)
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import jieba
import matplotlib.pyplot as plt
import numpy
import PIL.Image as Image
# browser = Chrome()#不把浏览器隐藏
wait = WebDriverWait(browser, 1.5)#显示等待
browser.implicitly_wait(2)#隐式等待
sen_list=[]
def main():
url = 'https://music.163.com/#/song?id=551816010'#陈奕迅《我们》
url='https://music.163.com/#/song?id=386542'#五月天《拥抱》
url='https://music.163.com/#/song?id=553310243'#五月天《后来的我们》
url='https://music.163.com/#/song?id=346576'#《光辉岁月》
url='https://music.163.com/#/song?id=426881487'#《你的名字:前前前世》
url='https://music.163.com/#/song?id=31445554'#《七月上》
url='https://music.163.com/#/song?id=355992'#《追梦赤子心》
browser.get(url)
browser.switch_to.frame('contentFrame')#进入框架才能进行提取!
div_out = browser.find_elements_by_css_selector('div.cmmts.j-flag div div.cnt.f-brk')
for div in div_out:
text1 = re.search(':.*', div.text, re.S)
text2 = re.sub(':', '', text1.group())
text3 = re.sub('.*?:', '', text2)
text4 = re.sub(',|。', ' ', text3)
if text4:
print(text4, '\n')
sen_list.append(text4)
for i in range(2,20):
print(i)
js = "window.scrollTo(0,document.body.scrollHeight)"
browser.execute_script(js)
#必须将页面滑动到最底部,否则会因为点击的是播放器的框架而发生,the element is not clickable 的错误。
string = 'a.zbtn.znxt'
submit = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, string))
)
print(submit)
print(submit.text)
submit.click()
submit = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, string))
)
div_out = browser.find_elements_by_css_selector('div.cmmts.j-flag div div.cnt.f-brk')
#CSS选择器,找到元素
for div in div_out:
text1=re.search(':.*',div.text,re.S)
text2=re.sub(':','',text1.group())
text3=re.sub('.*?:','',text2)
text4 = re.sub(',|。', ' ', text3)#把逗号和句号去掉,用|连接。
if text4:
print(text4,'\n')
sen_list.append(text4)
# print(div.text,'\n')
text = ' '.join(sen_list)#join函数把数组元素之间用空格连接起来
wordlist_jieba = jieba.cut(text,cut_all=False)#jieba的cut函数会把传入的字符串剪切成一个个词语,返回一个数组,数组元素皆为词语。如果开启了全模式,cut_all=True,会把字符串中的空格去掉。
wordlist_jieba = ''.join(wordlist_jieba)#把分完的词语再次拼接起来,如果用空格拼接,则词云是以词语为单位组成的,如果用“空”无间隙连接,那等于没用jieba,直接是以句子为单位拼接起来。
print(wordlist_jieba)
mask_pic = numpy.array(Image.open("./black_dragon.png"))
#遮罩图片必须通过numpy数组进行转化。我大概猜想是形成一个rgb的矩阵,来对图片的色彩方案进行描述。
mask_pic_color = numpy.array(Image.open("./black_dragon.png"))
# wordcloud = WordCloud(font_path="FZMWFont.ttf",
# background_color='white', width=1000,
#height=500,mask=mask_pic,max_font_size=60,max_words=500).generate(wordlist_jieba)
#上面是有遮罩图片的写法,有mask参数,就是能形成任意形状的词云。
#下面没有遮罩图片
wordcloud = WordCloud(font_path="FZMWFont.ttf",
background_color='white', width=1000,
height=500,max_words=1000).generate(wordlist_jieba)
image_colors = ImageColorGenerator(mask_pic)
#上面是采用原来遮罩图片的色彩方案。
#下面可以指定图片的色彩方案,来自于不同的图片。
#image_colors = ImageColorGenerator(mask_pic_color)
# wordcloud.recolor(color_func=image_colors)
#这是将色彩方案进行加载。
image = wordcloud.to_image()
image.show()
image.save('./15.jpg')#这个方法不靠谱,很多次都没有保存成功,要等比较久,有时候很久都不行。大多数情况下采取的方法是在图片show出来之后,直接右键另存为。
# 以下另一种显示图片的方式而已,和Matlab基本上一样
# plt.figure()#先要形成一个空白图像
# plt.imshow(wordcloud)
# plt.axis("off")#去除坐标轴
# plt.show()#最后要记得show出来
main()
python小结:
1、json.dumps()
json.dumps()用于将dict类型的数据转成str,因为如果直接将dict类型的数据写入json文件中会发生报错,因此在将数据写入时需要用到该函数。
2、json.loads()
json.loads()用于将str类型的数据转成dict。
3、json.dump()
json.dump()用于将dict类型的数据转成str,并写入到json文件中
4、json.load()
json.load()用于从json文件中读取数据。
5、
##使用worldCloud模块对刚刚整理好的分词信息进行处理.
##max_font_size参数是可以调整部分当个词语最大尺寸
##max_words是最大可以允许多少个词去组成这个词云图
##height高度,width宽度,
##background_color背景颜色
6、
with open() as file:
file.readlines()
readlines()方法返回列表,包含所有的行。
7、
使用matplotlib的pyplot来进行最后的渲染出图
from matplotlib import pyplot as plt
plt.imshow(wc)
8、
##目标文件另存为这个名录下
wc.to_file('wolfcodeTarget.png'
9、
jieba.cut(content,cut_all=True)
cut_all 全模式
cut_all=false 精确模式
精确模式,试图将句子最精确地切开,适合文本分析;
全模式,把句子中所有的可以成词的词语都扫描出来,
10、
"fzmw.ttf"
‘FZMWFont.ttf’ 喵呜体
字体文件,比较好看
11、
wc=
WordCloud(font_path="msyh.ttc",background_color="black",max_words=1000,max_font_size=100,width=1500,height=1500,mask=maskImages).generate(content)
生成词云图的最重要的函数
12、
images = Image.open("wolfcode.png")
maskImages = np.array(images)
遮罩层的图片需要弄过numpy包进行转换。
13、result=re.search(':.*',div.text,re.S)
直接打出result只是一个类。
正则表达式中result.group(1)返回第一个括号所匹配的内容,这里是1不是0!
result.group()返回所有括号的内容,或者当没有括号的时候返回整条内容。
14、re.compile函数只是对正则表达式做了一层封装,其实并没有什么用。
方便一点吧。
pattern=re.compile(‘\d{2}:\d{2}’)#大括号表示前面的匹配式子重复两次,一个式子一个字符
re.sub(pattern,’’,content1)
15、text1=re.search(':.*',div.text,re.S)
re.S使得.*可以匹配换行符,空格符之类
search 只能返回第一个匹配到的,返回所有要用findall,返回的是列表类型
match函数只能从头开始写匹配,只要开头没有匹配上他就GG。
16、
#滑到底部
js="window.scrollTo(0,document.body.scrollHeight)"
driver.execute_script(js)
目前在firefox,chrome上验证都是可以跑通的
#滑动到顶部
js="window.scrollTo(0,0)"
driver.execute_script(js)
scrollHeight 获取对象的滚动高度。
scrollLeft 设置或获取位于对象左边界和窗口中目前可见内容的最左端之间的距离。
scrollTop 设置或获取位于对象最顶端和窗口中可见内容的最顶端之间的距离。
scrollWidth 获取对象的滚动宽度。
你不滑动到底部再点击,网易云的播放器就会浮现出来,就会发生elemeng is not clickable的错误。
17、
在官网https://pypi.python.org/pypi/jieba/下载jieba安装包
下载后解压至Python的目录下
打开cmd,输入 cd C:\Python27\jieba-0.39 运行
然后输入 python setup.py install 即可安装
18、python spider常用快捷键
1.常用快捷键: Ctrl + 1: 注释/反注释 Ctrl + 4/5: 块注释/块反注释 Ctrl + L: 跳转到行号 Tab/Shift + Tab: 代码缩进/反缩进 Ctrl +I:显示帮助 2. 可以在Ipython Console输入变量进行快速验证,类似matlab
19、
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
清华大学开源网站,这是anaconda的分支,anaconda是python的一个科学计算环境,里面集成了许多许多的包。
20、html=re.sub(‘<a.*?>|</a>’,’’,html)
sub是正则表达式的替换方法,用或者符号|来进行多个符号的替换。
sub函数可以把“所有”满足条件的式子全部去掉,不仅仅是第一个。
sub函数直接返回字符串。
21、
ValueError: ImageColorGenerator is smaller than the canvas
用来设置颜色的图片一定要比用来框定位置的图片要大。
22、
browser.switch_to.frame('contentFrame')#进入框架才能进行提取!
很多网页都有框架,这里用name参数就行了。
23、
mask_pic = numpy.array(Image.open("./black_dragon.png"))
#遮罩图片必须通过numpy数组进行转化。我大概猜想是形成一个rgb的矩阵,来对图片的色彩方案进行描述。
24、
text4 = re.sub(',|。', ' ', text3)#用|连接,省事啊。
25、
browser.switch_to.frame('contentFrame')#进入框架才能进行提取!
26、
wordlist_jieba = jieba.cut(text,cut_all=False)#jieba的cut函数会把传入的字符串剪切成一个个词语,返回一个数组,数组元素皆为词语。如果开启了全模式,cut_all=True,会把字符串中的空格去掉。
wordlist_jieba = ''.join(wordlist_jieba)#把分完的词语再次拼接起来,如果用空格拼接,则词云是以词语为单位组成的,如果用“空”无间隙连接,那等于没用jieba,直接是以句子为单位拼接起来。
是不是看起来很酷炫呢?python装逼必备技能啊!


















 2160
2160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









