






操作系统
-
进程、线程的区别
- 进程:是系统进行资源调度和分配的一个独立单位;
- 线程是进程的实体,是CPU调度和分派的基本单位;
- 一个进程可以有多个线程,多个线程可以并发执行;
-
多进程和多线程?

-
同步与异步?
- 同步:一个进程在请求的时候,如果需要一段时间才能返回信息,那么这个进程会一直等待下去;
- 异步:进程不需要等待下去,而是继续执行下面的操作,不管其他进程的状态;
-
join()
Thread.Join把指定的线程加入到当前线程,可以将两个交替执行的线程合并为顺序执行的线程。
-
进程间的通信方式:
管道:管道可用于具有亲缘关系的父子进程间的通信,有名管道还可以允许无亲缘关系进程间的通信。
套接字:可用于网络中不同的进程间通信。
共享内存:多个进程可以访问同一块内存空间,不同进程可以及时看到对方进程中对共享内存中的数据更新,需要靠同步;
消息队列:是一种消息链表,放在内核中并由消息队列标识符标识,消息队列克服了信号传递信息少,管道只能承载无格式字节流以及缓冲区大小受限等特点。具有写权限的进程可以按照一定的规则向消息队列中添加新信息;
具有读权限的进程可以从消息队列中读取信息;
信号:通知接收进程某个事件已经发生;
信号量:信号量是一个计数器,可以用来控制多个线程对共享资源的访问,它不是用于交换大批数据,而用于多线程之间的同步。
-
线程同步的方式:
- 互斥量;与临界区较为相似,只不过互斥量允许进程间去访问。
- 信号量:当需要一个计数器来限制可以使用某共享资源的线程数目时
- 事件:一个线程处理完一个任务之后,主动去唤醒另外一个线程去执行任务
- 临界区:多个线程访问一个资源的时候,拥有临界区的线程可以访问,其他资源如果想要访问,必须等到临界区的线程放弃临界区。
-
什么是死锁?
- 在两个或多个并发进程中,双方互相持有对方想要的资源,然后他们就形成了相互等待的局面,就是所谓的死锁。
-
死锁产生的必要条件:
- 互斥:表示有一个资源是非共享的,每次只能由一个进程访问;
- 占有并等待:双方都占有资源,而双方又在同时等待对方释放资源;
- 非抢占:进程不能被抢占,只能等进程主动释放资源;
- 循环等待:若干进程形成一种头尾相接的循环等待;
-
怎么解决死锁?
-
进程有哪几种状态?
就绪、运行、等待

-
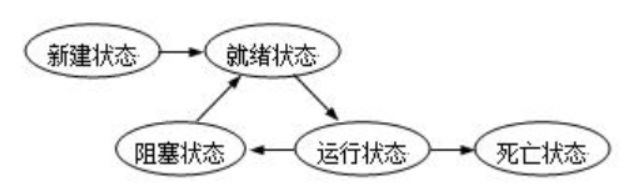
线程有哪几种状态?
- 新建、就绪、阻塞、运行、死亡
-
分段和分页
- 分段:将程序的地址空间划分为若干段,如代码段、数据段、堆栈段,这样每个进程都有一个二维地址空间,相互独立,互不干扰。
- 分页:将程序的逻辑地址划分为固定大小的页,而无力地址划分为同样大小的帧,程序加载的时候,可以将任意一页放入内存中任意一个帧。
- 区别:
- 大小不同:页的大小固定且由系统决定,而段的长度却不固定,由其所完成的功能决定;
- 地址空间不同:段向用户提供二维地址空间,页向用户提供的是一维地址空间;
Java
-
volatile
-
对于可见性,Java提供了volatile关键字来保证可见性。
当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。
而普通的共享变量不能保证可见性,因为普通共享变量被修改之后,什么时候被写入主存是不确定的,当其他线程去读取时,此时内存中可能还是原来的旧值,因此无法保证可见性。
另外,通过synchronized和Lock也能够保证可见性,synchronized和Lock能保证同一时刻只有一个线程获取锁然后执行同步代码,并且在释放锁之前会将对变量的修改刷新到主存当中。因此可以保证可见性。
保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
-
-
Hashtable是安全的吗?
是,每个方法都是同步方法,sysnchronized修饰
-
HashMap实现原理
哈希表+链表
-
Java内存模型:
- 原子性(处理器优化):在一个操作中就是cpu不可以在中途暂停然后再调度,既不被中断操作,要不执行完成,要不就不执行
- 可见性(缓存一致性):当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值
- 有序性(指令重排):程序执行的顺序按照代码的先后顺序执行(在Java内存模型中,允许编译器和处理器对指令进行重排序,但是重排序过程不会影响到单线程程序的执行,却会影响到多线程并发执行的正确性。),
-
Java集合:
- List:可以出现重复的元素,利用通过下标去获得元素。
- ArrayList:数组
- LinkedList:链表
- Map:key-value存储。
- HashMap:没有排序的
- TreeMap:排序的
- Set:不能通过元素的下标获得元素,也不能通过元素获得下标,只能遍历,不能有重复的元素。
- HashSet
- TreeSet:排序的
- List:可以出现重复的元素,利用通过下标去获得元素。
-
Java中的数据结构
栈、链表、数组、红黑二叉树
-
Spring的IOC,AOP原理
-
Bean的生命周期
- 实例化一个bean;将会调用postProcessBeforeInitialization(Object obj, String s)方法
- 进行IOC注入;
- 如果这个bean已经实现了BeanNameAware接口,会调用它实现的setBeanName(String),传递的是bean中的id;
- 如果这个bean实现了BeanFactoryAware接口,会调用它的setBeanFactory();
- 如果这个bean实现了ApplicationContextAware接口,那么会调用它的setApplicationContext();
- 如果这个bean关联了BeanPostProcessor接口,将会调用postProcessBeforeInitialization(Object obj, String s)方法;
- 如果这个bean中配置了init-method属性,会自动调用它的初始化方法;
- 如果这个bean关联了BeanPostProcessor接口,将会调用postProcessAfterInitialization(Object obj, String s)方法;
- 当Bean不再需要时,会经过清理阶段,如果Bean实现了DisposableBean这个接口,会调用那个其实现的destroy()方法;
- 最后,如果这个Bean的Spring配置中配置了destroy-method属性,会自动调用其配置的销毁方法。
-
Java的四种引用
- 强引用:JVM宁愿抛出outOfMemoryError也不愿意回收掉强引用;
- 虚引用:不管内存空间足不足,都会回收掉,若某个对象与虚引用关联,那么在任何时候都可能被JVM回收掉。虚引用不能单独使用,必须配合引用队列一起使用;
- 软引用:只有当内存空间不足的时候,JVM才会回收;
- 弱引用:java中使用WeakReference来表示弱引用。如果某个对象与弱引用关联,那么当JVM在进行垃圾回收时,无论内存是否充足,都会回收此类对象;
-
Bean的作用域
- Singleton:单例模式,只要那个创建的name和这个id一样,那么无论多少次,都会返回这个同一个对象;
- prototype:每次调用bean时,都会返回一个新的对象,getBean()相当于执行了一次new 的过程
- request:针对每次HTTP请求,一个bean对应一个实例,仅在基于web的Spring ApplicationContext情形下有效;
- session:表示在HTTP Session中,同一个Session共享一个Bean实例。不同Session使用不同的实例。该作用域仅在基于web的Spring ApplicationContext情形下有效;
- globalSession:同session作用域不同的是,所有的Session共享一个Bean实例。
-
topK
方法一:可以建立小堆,用其他元素和堆顶元素比较,如果比堆顶这个最小元素都小,那么就不用换;如果比堆顶元素大的话,就换堆顶,然后重新组装数据结构;
方法二:可以用冒泡排序,排k次,就可以找到前k个最大数了。
-
如何在海量数据中查找某个特定值?
- 分治法:写个hash函数,将那么多个值存在hash表中,然后就可以根据函数查找它属于哪个位置,就在哪个位置上查找了;
-
内存泄漏和内存溢出
内存泄漏:分配出去的内存无法回收(不再使用的对象或者变量仍占内存空间);
内存泄漏的几种场景:
- 长生命周期的对象持有短生命周期对象的引用;静态集合类 static HashMap,map里面存放局部变量,越放越多,就会造成内存泄漏;
- 变量不合理的作用域;
- 没有及时的将对象设置为null;
- 各种连接没有显示关闭;(数据库,IO,网络)
- 监听器(释放对象时,没有删除监听器)
内存溢出:程序要求的内存超出了系统所能分配的范围;(栈满入栈、栈空出栈)
-
HashMap HashTable ConcurrentHashMap
- HashMap:不安全,不能处理并发;
- HashTable:每个方法都是同步方法,添加了sychronized关键字,造成了一个线程在操作数据的时候,其他线程既不能改也不能获取到,效率很低;
- ConcurrentHashMap:分段锁,是由Segment[]和HashEntry[]构成的,Segment这个类继承了ReentrantLock这个类,所以自身就是带锁的。一个线程在操作一个segment中的HashEntry时,其他线程可以操作另外一个segment中的HashEntry;
-
syschronized Lock ReentrantLock
- syschronized :可重入锁,非公平锁
- Lock:可中断锁,可以显式的看到加锁与解锁的位置;
- ReentrantLock:可以设置成公平锁,可中断锁,可重入锁,lock.lockInterruptibly()
-
CAS(Compare And Swap)
CAS是实现并发时常用到的一门技术,比如说,AtomicInteger,线程A和线程B同时访问getAndAdd()操作,线程A进来之后通过getValue看到value的值是3,线程B看到的也是3,但是不幸的是,线程A被挂起来了,B执行操作,将value的值改成了2,线程B结束;此时线程A开始执行,他发现此时的value和刚才的value不一样,因为value是由volatile修饰的,那么他就要重新执行getValue和add方法。
-
getAttribute() 与 getParameter()
首先这两个方法都是HTTPServletRequest类中的方法
**getAttribute()**是通过前面的request.setAttribute()获得的,但是没有setParameter()这个方法;
**getParameter()**是获取前端页面的参数
-
JVM内存模型
- 程序计数器:在一个确定的时刻都只会执行一条线程中的指令,一个线程有多条指令,为了线程切换可以恢复到正确执行位置,每个线程都需要有一个独立的程序计数器,不同线程之间的程序计数器互不影响,独立存储;
- 虚拟机栈:线程私有,用来存放方法参数,以及方法内部定义的局部变量,存放编译期间一直的数据类型(八大基本类型 对象引用)
- 本地方法栈: native方法
- 堆:线程共享,存放所有对象实例以及数组,也是GC管理的主要区域;
- 方法区:线程共享,存储已被虚拟机加载的类信息、常量、静态变量
-
gc垃圾回收算法
- 标记-清除(Mark-Sweep)算法
- 分为标记和清除两个阶段,首先标记出需要回收的对象,标记完成后统一回收所有被标记的对象;效率不高;
- 复制(Coping)算法
- 为了解决效率问题而出现,它将可用的内存分为两块,每次只用其中一块,当这一块内存用完了,就将还存活着的对象复制到另外一块上面,然后把已使用过的内存空间进行清理;
- 不足:内存缩小了一半,代价很高;
- 标记-整理(Mark-Compact)算法
- 让所有存活对象都向一端移动,然后直接清理掉边界以外的内存;
- 分代收集算法:
- 根据对象的生命周期的不同,将内存划分为几块,然后根据各块的特点采用最适合的收集算法。大批对象死去、少量对象存活(新生代),使用复制算法;对象存活率高,没有额外空间进行分配担保的(老年代),采用标记-清除算法;
- 标记-清除(Mark-Sweep)算法
-
Java的快速失败和安全失败
- 快速失败:迭代器遍历的时候,对元素进行修改,就会抛出这个异常;
- 安全失败:在遍历时,不是对元集合进行遍历,而是对复制的对象进行遍历,在遍历期间如果原集合修改了某个值,这个线程是获取不到被修改的值的;
-
守护线程
当用户线程执行完毕后,守护线程自动退出。
-
HashMap解决hash冲突?
使用拉链法,HashMap使用key来确定它的hashcode,不同的key可能会有相同的hashcode,那么如果遇到两个相同的hashcode的话,第二个元素就放在第一个元素的后面,类似于链表。
数据库
-
二叉树 二叉查找数 平衡二叉树(AVL) B-tree B+tree
-
索引 MyISAM InnoDB
MyISAM:B-tree
InnoDB:B+tree,因为B+tree的数据都在叶子节点,所以只需要遍历一遍就可以找到;B-tree是中序遍历。
为什么不用哈希表呢?
- 哈希表占用内存比较大,因为树的话是按照节点查找的,哈希表的话,需要全部存在内存中。
-
隔离事务机制
- read uncommitted 什么问题都解决不了
- read committed 解决了脏读
- repeatable read 解决了脏读,不可重复读(MySQL默认的)
- 为什么默认是重复读?
- 因为MySQL在5.0之前,默认的binlog是statement,master的执行顺序是:先删后插,而statement记录的顺序是先插后删,所以这回导致两个数据不一致,所以就默认是重复读。
- 为什么我们一般设置成读已提交?
- 因为重复读加入了间隙锁,会导致死锁的可能性很大;
- 为什么默认是重复读?
- SERIALIZABLE(可串行化) 解决了脏读,不可重复读,幻读
-
并发造成的问题:脏读 幻读 不可重复读
-
聚簇索引与非聚簇索引:
- 聚簇索引按照数据的物理存储进行划分的。对于一堆记录来说,使用聚集索引就是对这堆记录进行堆划分,即主要描述的是物理上的存储。正是因为这种划分方法,导致聚簇索引必须是唯一的。聚集索引可以帮助把很大的范围,迅速减小范围。但是查找该记录,就要从这个小范围中Scan了;
- 非聚集索引是把一个很大的范围,转换成一个小的地图,然后你需要在这个小地图中找你要寻找的信息的位置,最后通过这个位置,再去找你所需要的记录。
-
数据库事务(ACID)
- 原子性:
- 一致性:
- 隔离性:
- 永久性:
-
行级锁 表级锁 页级锁
-
行级锁:
共享锁:
SELECT ... LOCK IN SHARE MODE; 共享锁又称读锁,是读取操作创建的锁。其他用户可以并发读取数据,但任何事务都不能对数据进行修改(获取数据上的排他锁),直到已释放所有共享锁。排他锁:
SELECT ... FOR UPDATE;排他锁又称写锁,如果事务T对数据A加上排他锁后,则其他事务不能再对A加任任何类型的封锁。获准排他锁的事务既能读数据,又能修改数据。
-
-
数据库的优化:
- 遵循三大范式;
- SQL语句的优化;
- 索引优化;
- 数据库表结构的优化;
- 选择合适的数据类型:(较小的数据类型、使用int而非varchar、使用 not null、避免使用text)
- 表的垂直查分(1. 不常用的字段 2. 大字段 3. 经常使用的字段)
- 表的水平拆分(对id进行hash计算,取模运算,不同的id放入不同的表中);
-
五大约束
- 主键约束:
- 唯一性约束
- 默认值约束
- 非空约束
- 外键约束
-
悲观锁、乐观锁、公平锁的实现原理
- 悲观锁:syschronized、ReentrantLock
- 乐观锁:使用版本号机制或者CAS算法实现
- 公平锁:
-
什么情况下使用索引但无法使用?
- 模糊查询 % like
- or前后语句没有同时使用索引;
-
delete drop truncate的区别
- 运行速度:drop > truncate > delete
- 只删除数据,不删除表:truncate delete
- truncate和delete不带where条件语句是等价的,删除数据;drop删除数据和表
- truncate和drop是DDL(数据库定义语言)语句,不能rollback;
- delete(DML)数据库语言,必须提交;
-
DDL DML DQL DCL
- DDL:数据定义语言(create关键字),用来创建索引,表之类的。truncate drop
- DML:数据操纵语言:insert delete update
- DQL:数据查询语言:select
- DCL:数据控制语言:rollback commit
计算机网络
-
http与https的区别
- http 标准端口是80 ,https是443;
- http:超文本传输协议,不安全,连接无状态;
- https:是使用http协议和SSL构建的可进行加密传输
-
输入url的过程;
-
TCP/IP四层模型:
3.1 网络接口层
3.2 网际层
3.3 运输层
3.4 应用层
-
OSI七层模型;
4.1 物理层
4.2 数据链路层
4.3 网络层
4.4 传输层 TCP UDP
4.5 会话层 RPC SQL
4.6 表示层 ASII
4.7 应用层 FTP HTTP WWW NFS SMTP
-
TCP UDP 传输层
- TCP提供面向连接的、可靠的数据流传输,而UDP提供的是非面向连接的、不可靠的数据流传输;
- TCP传输单位:TCP报文段,UDP传输单位成为:用户数据报;
- TCP注重数据安全性,UDP传输效率很快因为不需要等待连接,但是不安全。
-
TCP 拥塞控制
-
TCP三次握手 四次挥手;
-
arp与rarp
-
应用层协议:http SMTP(简单邮件传送协议)DNS(域名系统)FTP(文本传输协议)
-
IP地址的分类
- A类地址:以0开头,0-127 (1.0.0.0 - 126.255.255.255),10.0.0.0到10.255.255.255是私有地址
- B类地址:以10开头,128-191 (128.0.0.0-191.255.255.255),172.16.0.0到172.31.255.255是私有地址
- C类地址:以110开头,192-223(192.0.0.0-223.255.255.255);192.168.0.0到192.168.255.255是私有地址
-
各种协议
- ICMP协议:因特网控制报文协议。属于TCP/IP协议族的子协议,用于在IP主机、路由器之间传递控制消息。
- TFTP:提供不复杂、开销不大的文件传输服务;
-
TCP对应的协议:
- FTP:定义了文件传输协议,使用端口21;
- POP3:接收邮件,使用端口:110;
- HTTP:Web服务器传输超文本到本地浏览器的传送协议;
- SMTP:邮件传送协议,用于发送邮件,端口是25.
-
UDP对应的协议:
- DNS:用于域名解析服务,将域名解析为IP地址,端口是53端口;
- SNMP:简单网络管理协议,使用161端口,管理网络设备。
- TFTP:简单文件传输协议,端口69。
-
面向连接和非面向连接的服务的特点?
面向连接:通信双方在进行通信之前,要先在双方简历起一个完整的可以彼此沟通的通道,在通信的过程中,整个连接的情况可以一直被实时的监控;
非面向连接:不需要预先建立一个联络两个通信节点的连接
-
http1.0与1.1的区别,http1.1与2.0的区别
HTTP1.0 使用短连接Connection:close,客户端和服务器每进行一次HTTP操作,就建立一次连接,服务器每遇到一个web资源,就会建立一次http连接;
HTTP1.1 使用长连接,头部加了 Connection:keep-alive,一直保持连接,但是服务器必须按照客户端的请求顺序来给出应答,不能出现两个并行的应答请求;
HTTP2.0 引入了帧和流的概念,其中帧对数据进行顺序标识,这样,服务器收到数据之后,就可以按照序列对数据进行合并,而不会出现合并后出现数据错误的情况,服务器就可以并行的发送数据了。使用encoder来减少需要传输的header大小















 3295
3295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









