






一、概念
MERGE INTO 的用途 MERGE INTO 是Oracle 9i 以后才出现的新的功能。那这个功能 是什么呢? 简单来说,就是:“有则更新,无则插入”。
此语法在 Oracle、Sql Server、DB2中都可以使用。
二、merge into 语法
Oracle 中 merge into 用法解析:
merge into 语法:
merge into [target-table] a
using [source-table sql] b on([conditional expression] and [...]...)
when matched then
[update sql]
when not matched then
[insert sql]
作用:
判断B表和A表是否满足on中条件,如果满足则用b表去更新a表,如果不满足,则将b表数据插入a表但是有很多可选项。
如下:
1.正常模式
2.只update模式
3.只insert模式
4.带条件的update或带条件的insert
5.全插入insert实现
6.带delete的update
例如:
merge into sx_credit_info sci
using (select ? as agent_id, ? as customer_id, ? as credit_type from dual) tmp
on (tmp.agent_id = sci.agent_id and tmp.customer_id = sci.customer_id and tmp.credit_type = sci.credit_type)
when not matched then
insert
(agent_id,
company_id,
deposit,
deposit_flag,
long_credit,
temp_credit,
join_fee,
join_fee_deducted,
order_consume,
order_collect_verify,
prepayment,
prepayment_used,
avail_credit,
add_user,
add_date,
customer_id,
credit_type,
upd_user,
upd_date)
values
(?, ?, ?, '1', ?, ?, 0, 0, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
when matched then
update
set order_consume = ?,
order_collect_verify = ?,
prepayment = ?,
prepayment_used = ?,
avail_credit = ?,
upd_user = ?,
upd_date = ?
where agent_id = ?
and customer_id = ?
and credit_type = ?
三、动手实践
测试建以下表:
create table A_MERGE
(
id NUMBER not null,
name VARCHAR2(12) not null,
age NUMBER
);
create table B_MERGE
(
id NUMBER not null,
aid NUMBER not null,
name VARCHAR2(12) not null,
age NUMBER,
city VARCHAR2(12)
);
create table C_MERGE
(
id NUMBER not null,
name VARCHAR2(12) not null,
city VARCHAR2(12) not null
);
1.正常模式
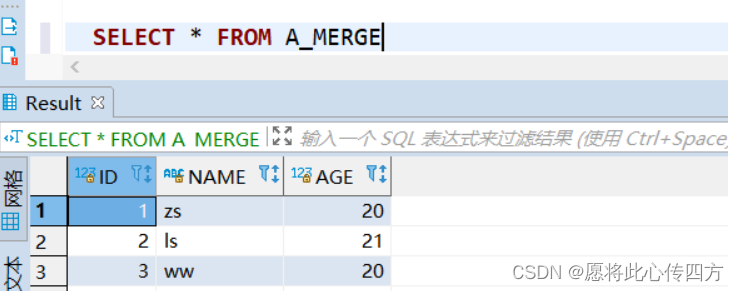
先向a_merge和b_merge插入测试数据:
insert into A_MERGE values(1,'zs',20);
insert into A_MERGE values(2,'ls',21);
insert into A_MERGE values(3,'ww',20);
commit;
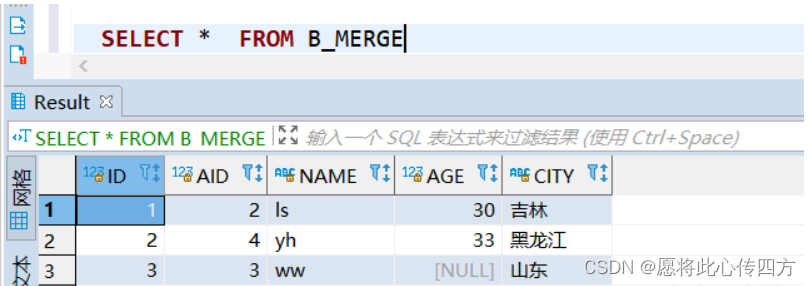
insert into B_MERGE values(1,2,'ls',30,'吉林');
insert into B_MERGE values(2,4,'yh',33,'黑龙江');
insert into B_MERGE values(3,3,'ww','','山东');
commit;
然后再使用 merge into 用 B_MERGE 来更新 A_MERGE 中的数据:
-- 判断B表和A表是否满足ON中条件,如果满足则用B表去更新A表,如果不满足,---则将B表数据插入A表
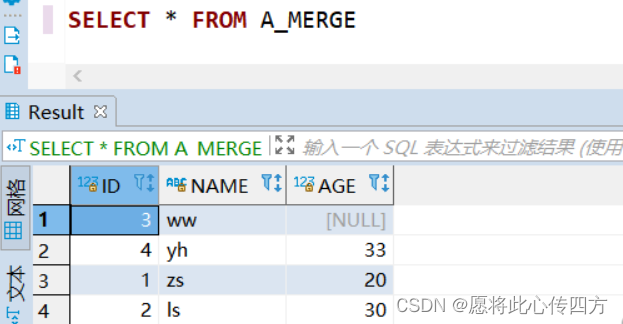
MERGE INTO A_MERGE A
USING (select B.AID, B.NAME, B.age from B_MERGE B) C
ON (A.id = C.AID)
--当满足on后面条件时,目标表中的age被更新只有matched,也就是只更新不插入
WHEN MATCHED THEN
UPDATE SET A.age = C.age
--当不满足on后面条件时,则插入相关数据只有NOT matched,也就是只插入不更新
WHEN NOT MATCHED THEN
INSERT (A.ID, A.NAME, A.age) VALUES (C.AID, C.NAME, C.age);
此时 A_MERGE 中的表数据截图如下:
2.只UPDATE
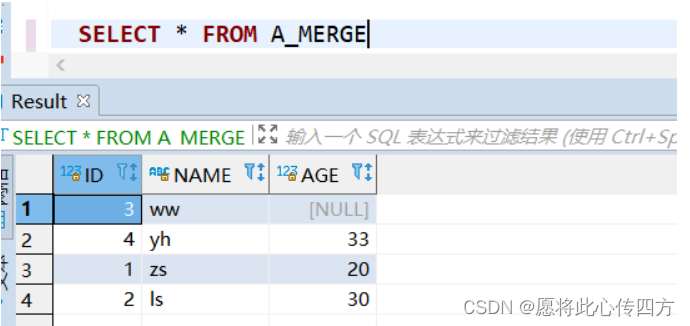
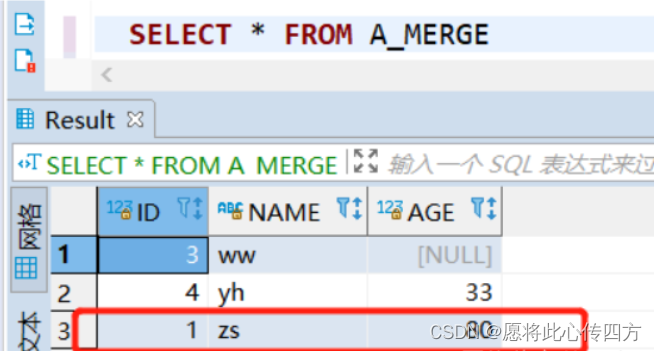
首先向B_MERGE中插入两个数据,体现出只update没有insert,必须有一个数据是A中已经存在的。另一个数据时A中不存在的,插入数据语句如下:
insert into B_MERGE values(4,1,'zs',80,'江西');
insert into B_MERGE values(5,5,'tiantian',23,'河南');
此时 A_MERGE 和 B_MERGE 表数据截图如下:
A_MERGE表数据截图
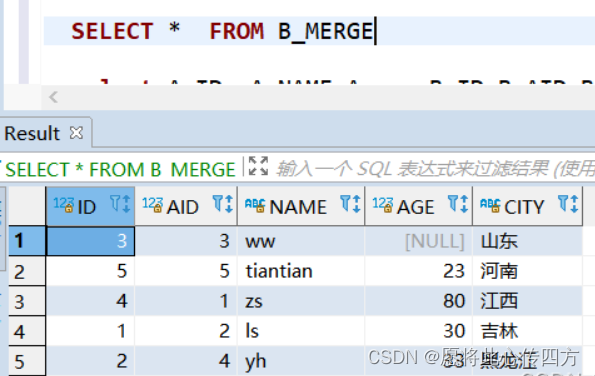
然后再次用 B_MERGE来更新 A_MERGE,但是仅仅update,没有写insert部分。
MERGE into A_MERGE A
USING (select B.AID, B.NAME, B.AGE from B_MERGE B) C
ON (A.ID = C.AID)
WHEN MATCHED THEN
UPDATE SET A.AGE = C.AGE;
merge完之后A_MERGE表数据截图如下:可以发现仅仅更新了AID=1的年龄,没有插入AID=4 的数据
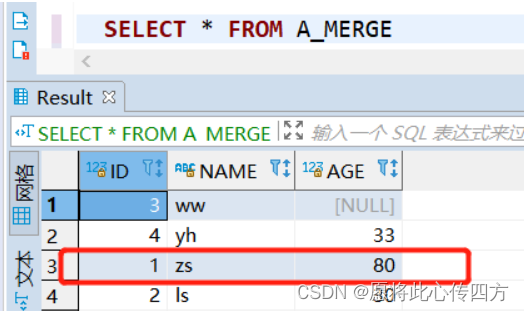
3. 只insert模式
首先改变B_MERGE中的一个数据,因为上次测试update时新增的数据没有插入到A_MERGE,这次可以用。
update B_MERGE SET AGE = 60 where AID=2;
此时A_MERGE 和 B_MERGE的表数据截图如下:
A_MERGE表数据:
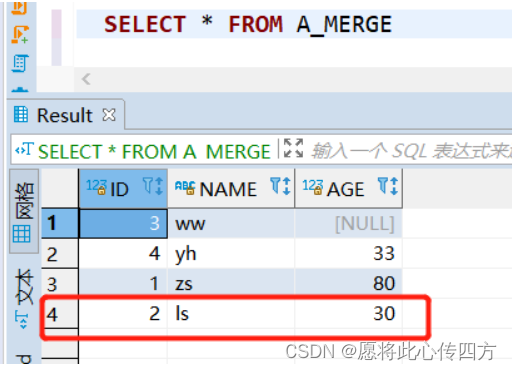
B_MERGE表数据:
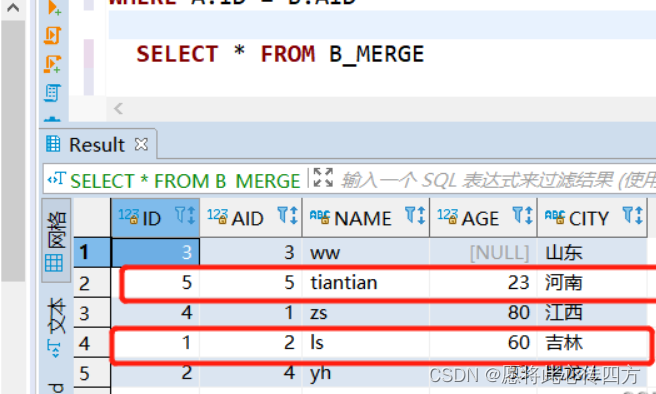
然后用 B_MERGE 来更新 A_MERGE中的数据,此时只写了insert,没有写update:
merge into A_MERGE A
USING (select B.AID, B.NAME, B.AGE from B_MERGE B) C
ON (A.ID = C.AID)
WHEN NOT MATCHED THEN
insert (A.ID, A.NAME, A.AGE) VALUES (C.AID, C.NAME, C.AGE);
此时A_MERGE 的表数据截图如下:
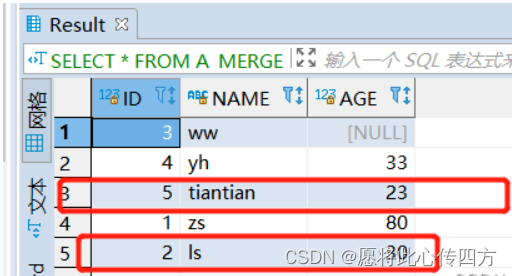
4. 带where条件的insert和update
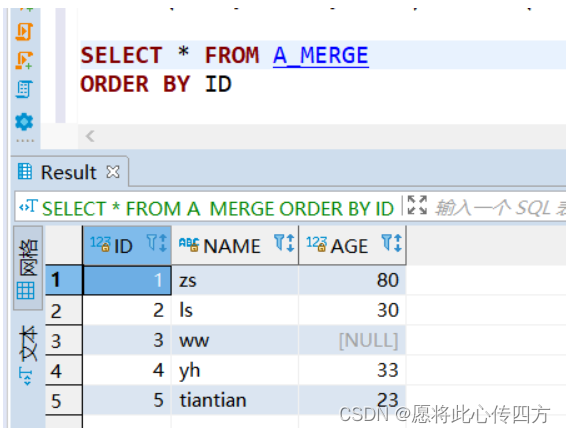
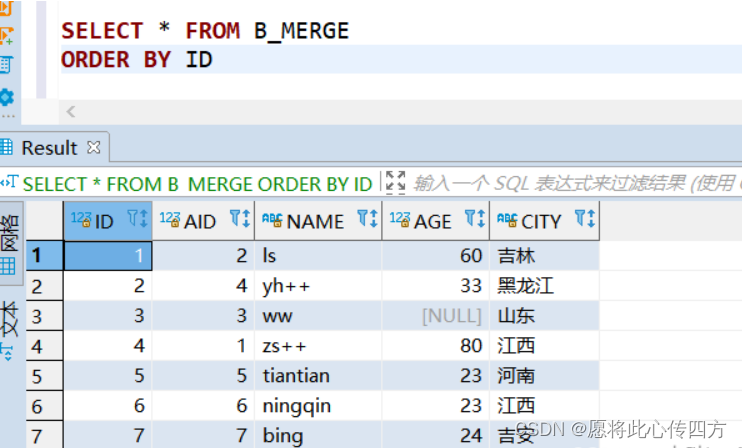
在on中进行完条件匹配之后,还可以在后面的insert和update中对on筛选出来的记录再做一次条件判断,用来控制哪些要更新,哪些要插入。 测试数据的sql代码如下,我们在B_MERGE修改了两个人名,并且增加了两个人员信息,但是他们来自的省份不同, 所以我们可以通过添加省份条件来控制哪些能修改,哪些能插入.
A_MERGE表数据:
B_MERGE 表数据:
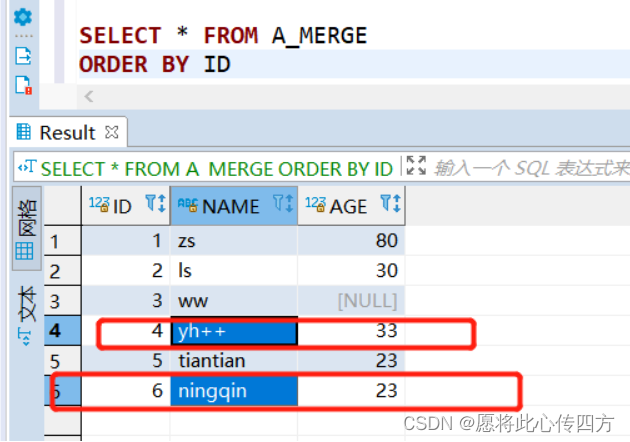
用B_MERGE去更新A_MERGE,但是分别在insert和update后面添加了条件限制,控制数据的更新和插入:
merge into A_MERGE A
USING (select B.AID, B.name, B.age, B.city from B_MERGE B) C
ON (A.id = C.AID)
when matched then
update SET A.name = C.name where C.city != '江西'
when not matched then
insert
(A.ID, A.name, A.age)
values
(c.AID, C.name, C.age) where C.city = '江西';
此时A_MERGE 表的截图。
5. 无条件的insert
有时我们需要将一张表中所有的数据插入到另外一张表,此时就可以添加常量过滤来实现,让其只满足匹配和不匹配,这样就只有update或者只有insert。这里我们要无条件全插入,则只需将on中条件设置为 1=1 即可。用B_MERGE来更新C_MERGE代码如下:
merge into C_MERGE C
USING (select B.AID, B.NAME, B.City from B_MERGE B) B
ON (1 = 1)
when not matched then
insert (C.ID, C.NAME, C.City) values (B.AID, B.NAME, B.City);
C_MERGE表在merge之前的数据截图如下
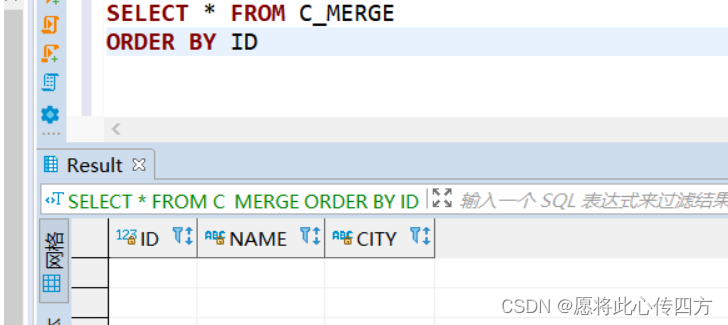
B_MERGE数据截图如下:
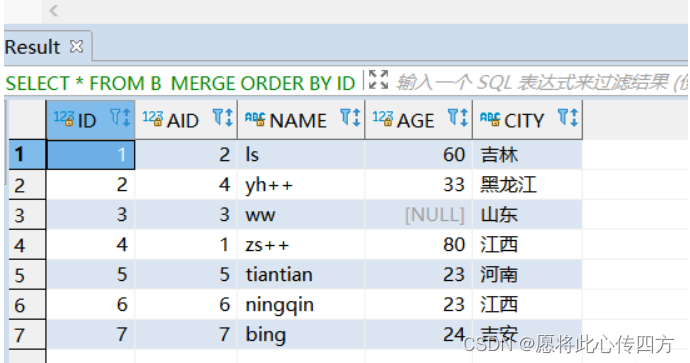
C_MERGE表在merge之后数据截图如下:
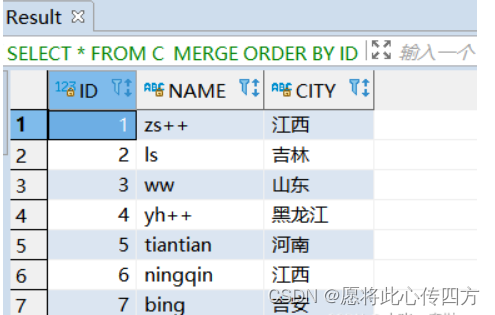
6.带delete的update
有时候实际开发中既有更新又有删除的操作。
MERGE into A_MERGE A
USING (select B.AID, B.NAME, B.AGE from B_MERGE B) C
ON (A.ID = C.AID)
WHEN MATCHED THEN
UPDATE SET A.AGE = C.AGE
DELETE WHERE A.NAME = 'ls';
A_MERGE表在merge之后数据截图如下:
四、MySql 类似 merge 功能
通常情况下,如果需要实现“有则更新,无则新增”这样的业务操作时,我们会先从数据库中根据某个条件(比如主键id)查询数据是否存在,然后再调用更新或者保存操作。但是在高并发下可能会带来某些问题:
1、性能花销:查询操作执行一次sql,更新或新增执行一次sql。
2、并发问题:假设2个请求同时插入1条数据,在查询阶段两个请求皆查询不到数据,都认为数据不存在,故两个请求都执行了插入操作,导致数据出现异常。
为了解决上述问题,我们可以使用on duplicate key update语句来实现,一个使用样例: 
insert into t_user ( id, `name`, age )
value( 1, '小明', 18 )
on duplicate key update
`name` = values(name),
age = values(age)
--说明
/**
1、在insert语句结尾加上on duplicate key update并指明需要进行更新的字段。
2、on duplicate key update只有在表有`唯一索引`(primary key或unique key)的情况下才有效。
3、values(col_name)函数意思是,取出当前插入语句中col_name字段对应的值。如上述语句中:values(name)的值为“小明”。
4、on duplicate key update即使执行的是更新操作,仍然会占用自增id序号。
5、上述语句的意思是:插入一条id为1,名字为小明,年龄18的记录。如果记录存在(id冲突)则更新名字和年龄字段
*/
扩展:如果我们插入的时候需要和已经存在的数据进行比较判断该怎么实现?还是使用上述的例子:
1、插入时,如果数据已经存在,则给小明加1岁:
insert into t_user ( id, `name`, age )
value( 1, '小明', 18 )
on duplicate key update
age = age+1
2、插入时,如果数据已经存在,判断年龄大小,取年龄最大值:
引用已经存在的数据直接写字段名,引用本次插入的数据使用values函数
insert into t_user ( id, `name`, age )
value( 1, '小明', 18 )
on duplicate key update
age = if(values(age)>age,values(age),age)
--配合if函数使用即可。
五、其他数据库对marge 的支持

六、oracle中merge into、update性能(官方的例子)
在Oracle数据库的使用中,向表中插入数据时,如果待插入的记录表中已经存在,就用新记录的值更新原记录;如果不存在,就插入新记录。这时候,就需要用merge语句。
MERGE语法一步就执行了这些改变。通过merge语句能够避免自己手写好多if判断,程序简洁,更好维护。
下面官方例子:
bonuses表记录奖金。原来有销售记录的员工每个人发100。后来公司人力修改了奖金政策,薪水小于等于8000的才会收到奖金,没有销售记录的奖金为其薪水的1%,有销售记录的奖金增加薪水的1%。
CREATE TABLE bonuses (employee_id NUMBER, bonus NUMBER DEFAULT 100);
INSERT INTO bonuses(employee_id)
(SELECT e.employee_id FROM employees e, orders o
WHERE e.employee_id = o.sales_rep_id
GROUP BY e.employee_id);
SELECT * FROM bonuses ORDER BY employee_id;
EMPLOYEE_ID BONUS
----------- ----------
153 100
154 100
155 100
156 100
158 100
159 100
160 100
161 100
163 100
merge into 模式处理:
MERGE INTO bonuses D
USING (SELECT employee_id, salary FROM employees) S
ON (D.employee_id = S.employee_id)
WHEN MATCHED THEN UPDATE SET D.bonus = D.bonus + S.salary*.01
DELETE WHERE (S.salary > 8000)
WHEN NOT MATCHED THEN INSERT (D.employee_id, D.bonus)
VALUES (S.employee_id, S.salary*.01)
WHERE (S.salary <= 8000);
SELECT * FROM bonuses ORDER BY employee_id;
EMPLOYEE_ID BONUS
----------- ----------
153 180
154 175
155 170
159 180
160 175
161 170
164 72
165 68
166 64
167 62
171 74
172 73
173 61
179 62
update采用的类似 nested loop 的方式,对更新的每一行,都会对查询的表扫描一次;
merge into这里选择的是hash join,则针对每张表都是做了一次 full table scan,对每张表都只是扫描一次。
hash join 原理是什么呢?后期抽时间说下这块。
Oracle官方建议, This statement is a convenient way to combine multiple operations. It lets you avoid multiple INSERT, UPDATE, and DELETE DML statements. merge方法是最简洁,效率最高的方式,在大数据量更新时优先使用这种方式。
update和merge into 都更新1w条记录,update耗时25.24,逻辑读消耗2282027;merge into 耗时01.14s,消耗逻辑读964。相差太大了:
详见如下
















 268
268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









