







前言
本文和大家一起讨论查询语句在 MySQL 中的执行过程。
为了理解这个问题,我们先从 MySQL 的架构说起,对于 MySQL 来说,虽然经历了多个版本迭代,但每次的迭代,都是基于 MySQL 基架的。
下面我们开始分析下 MySQL 的架构体系。
MySQL 的架构分层

-
连接层
Connectors:最上层是一些客户端和连接服务。 -
服务层
Management Serveices & Utilities: 系统管理和控制工具 Connection Pool: 每一个客户端发起一个新的请求都由服务器端的线程处理工具负责接收客户端的请求并开辟一个新的内存空间,在服务器端的内存中生成一个新的线程,当每一个用户连接到服务器端的时候就会在进程地址空间里生成一个新的线程用于响应客户端请求,用户发起的查询请求都在线程空间内运行, 结果也在此线程内缓存并返回给服务器端。线程的重用和销毁都是由线程处理管理器实现的。 SQL Interface: 接受用户的SQL命令,并且返回用户需要查询的结果。 Parser:解析器,将SQL语句进行语义和语法分析,按照不同的操作类型进行分类后做出针对性的转发到后续步骤。 Optimizer:查询优化器,SQL语句在执行前MySql会使用查询优化器对查询语句进行优化,根据客户端请求的query语句和数据库中的一些统计信息,在一系列算法的基础上进行分析后得出一个最优的策略,告诉后面的程序如何取得这个query语句的结果。 Cache和Buffer:查询缓存,主要功能是将客户端提交给MySQL的select请求的返回结果集缓存到内存中,该查询语句所查询的中的数据或结构发生任何变化后, MySQL会使该查询语句的缓存失效。在读写比例非常高的应用系统中, 查询缓存对性能的提高是非常显著的,当然也增加了对内存的消耗。 -
引擎层
Pluggable Storage Engines:存储引擎接口真正的负责了MySQL中数据的存储和获取,服务器通过API与存储引擎进行通信。不同的存储引擎具有的功能不同,MySQL支持存储引擎的可插拔,这样我们可以根据自己的实际需要进行选取。 -
存储层
数据存储层:主要将数据存储在运行于裸设备的文件系统上,并完成于存储引擎的交互。
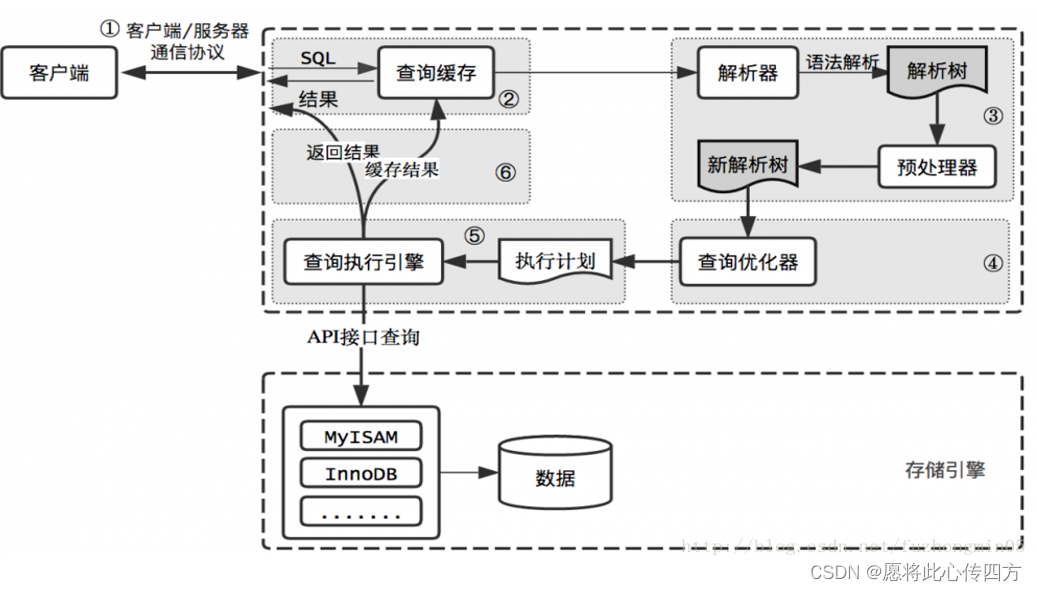
通过 MySQL 的架构分层,我们可以清晰的了解到一个 SQL 大致的执行过程。
- 首先客户端发送请求到服务端,跟连接器建立连接
- 服务端先看下查询缓存是否命中,命中就直接返回,否则继续往下执行。
- 接着来到分析器,进行词法分析、语法分析,一些系统关键字校验,校验语法是否合规等等。
- 然后优化器进行 SQL 优化,比如怎么选择索引之类,然后生成执行计划。
- 最后执行器调用存储引擎 API 查询数据,返回结果。
MySQL 的架构分层
连接器
客户端通过连接器访问 Server 层。连接器主要负责身份认证和权限鉴别的工作。即校验账户密码,权限。
如果用户名或密码不对,就会收到一个 Access denied for user 的错误提示,然后客户端程序结束执行。
如果用户名密码认证通过,连接器会到权限表里面查出登录用户所拥有的权限。之后,这个连接里面的权限判断,都将依赖于此时读到的权限。

如果客户端太长时间没动静,连接器就会自动将连接断开。这个时间是由参数 wait_timeout 控制的,默认值是 8 小时。
show variables like 'wait_timeout';
如果在连接被断开之后,客户端再次发送请求的话,就会收到一个错误提醒: Lost connection to MySQL server during query。这时候如果要继续,就需要重连,然后再执行请求了。
数据库将连接分为:长链接和短连接。
长连接是指连接成功后,如果客户端持续有请求,则一直使用同一个连接。
短连接则是指每次执行完 SQL 的请求操作就断开连接,如果再有请求会重新建立连接。
因为频繁建立连接,消耗系统的资源,所以建议在使用中尽量减少建立连接的动作,也就是尽量使用长链接。
但是如果全部使用长链接也会出现问题。
长链接的问题
如果全部使用长链接,我们会发现,有些时候 MySQL 占用内存涨得特别快。
这是因为 MySQL 在执行过程中,临时使用的内存是管理在连接对象里面的。这些资源会在连接断开的时候才释放。
所以如果长链接累积下来,导致内存占用太大,被系统强行杀掉(OOM),从现象看就是 MySQL 异常重启了。
我们该如何解决这个问题呢?
- 定期断开长连接。每隔一段时间或者执行一个占用内存的大查询以后断开连接,从而释放内存,当查询的时候再重新创建连接。
- 使用 MySQL 5.7 或更高的版本,通过执行 mysql_reset_connection
来重新初始化连接。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。 - 使用连接池的方式,将短连接变为长连接。
查询缓存
MySQL 拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句。
之前执行过的语句及其结果会以 key-value 对的形式,被直接缓存在内存中。key 是查询的语句,value 是查询的结果。
如果客户端发送的查询请求能够直接在这个缓存中找到 key,那么这个 value 就会被直接返回给客户端。
如果查询命中缓存,MySQL 不需要执行后面的复杂操作,就可以直接返回结果,这个效率会很高。
但是,MySQL 查询不建议使用缓存:因为查询缓存的失效非常频繁。如果这张表不断地被更新、查询,查询缓存会频繁地失效,那么获取查询缓存也失去了意义。
MySQL 8.0 版本直接将查询缓存的整块功能删掉了。
分析器:
语法分析,根据语法规则判断当前的sql是否满足mysql的语法,如果不满足则报错。
优化器:
在具体执行SQL语句之前,语句要经过优化处理:如,当表中有多个索引时,决定用哪个索引;当表需要进行join时,需要决定表的连接顺序等。不同的执行顺序对性能影响很大。
执行器:
执行实际的SQL语句,主要是跟存储引擎进行交互。
存储引擎:
定义数据不同的存放位置以及文件不同的存储格式:
InnoDB:存储在磁盘
MyIsam:存储在磁盘
memory:存储在内存
other:其他存储引擎
数据库性能调优
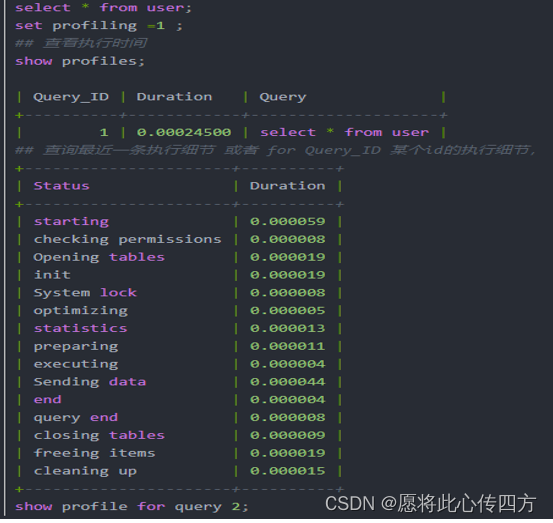
- show profiles分析SQL 执行的线程的状态及消耗的时间
- 利用explain分析查询语句
explain命令是查看优化器如何决定执行查询的主要方法,从而知道MySQL如何处理SQL语句以及查询语句是否走了合理的索引。

(1)id:反映的是表的读取顺序或查询中执行select子句的顺序。
SQL 执行的顺序的标识,SQL 从大到小的执行
id 相同时,执行顺序由上至下;
id 不同时,id 值越大优先级越高,越先被执行;
id 有相同也有不同时,id 相同的可以认为是一组,从上往下顺序执行;在所有的组中,id 的值越大的组,优先级越高,越先执行;
(2)select_type:表示select的类型,主要用于区别普通查询、联合查询、子查询等复杂查询。

(3)table:显示这一步所访问数据库中表名称(显示这一行的数据是关于哪张表的),有时不是真实的表名字,可能是第几步执行的结果的简称。
(4)type:对表的访问方式,表示MySQL在表中找到所需行的方式,又称“访问类型”。常见的访问类型有ALL、index、range、 ref、eq_ref、const、system、NULL(从左到右,性能从差到好)。

(5)possible_keys:指出MySQL能使用哪个索引在该表中找到行,查询涉及的字段上若存在索引,则该索引将被列出,但不一定会被用。
(6)key:显示MySQL实际决定使用的索引,如果没有选择索引,则显示是NULL。要想强制MySQL使用或忽视possible_keys列中的索引,在查询中使用FORCE INDEX或者IGNORE INDEX。查询中若使用了覆盖索引(select后要查询的字段刚好和创建的索引字段完全相同),则该索引仅出现在key列表中。
(7)key_len:显示索引中使用的字节数。

(8)ref:表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值。
(9)rows:显示MySQL根据表统计信息以及索引选用的情况,估算找到所需的记录要读取的行数。
(10)Extra:该列包含MySQL解决查询的说明和描述,包含不适合在其他列中显示但是对执行计划非常重要的额外信息。

总结:首先关注查询类型type列,如果出现all关键字,代表全表扫描,没有用到任何index;再看key列,如果key列是NULL,代表没有使用索引;然后看rows列,该列数值越大意味着需要扫描的行数越多,相应耗时越长;最后看Extra列,要避免出现 Using filesort或 Using temporary这样的字眼,这是很影响性能的。
数据库性能调优-优化措施
官方优化相关:
https://dev.mysql.com/doc/refman/8.0/en/optimization.html
(1)表结构设计,索引,字段类型,锁等。
(2)读写分离。
(3)增加缓存, 给数据库增加缓存系统,把热数据缓存到内存中,如果缓存中有要请求的数据就不再去数据库中返回结果,提高读性能。
缓存实现有本地缓存和分布式缓存,本地缓存是将数据缓存到本地服务器内存中或者文件中。
分布式缓存可以缓存海量数据,扩展性好,主流的分布式缓存系统有memcached、redis。
(4)分库分表,分库是根据业务不同把相关的表切分到不同的数据库中;
数据量的日剧增加,数据库中某个表有几百万条数据,导致查询和插入耗时太长,怎么能解决单表压力呢?你就该考虑是否把这个表拆分成多个小表,来减轻单个表的压力,提高处理效率,此方式称为分表。
分表分为垂直拆分和水平拆分:
垂直拆分:把原来的一个很多字段的表拆分多个表,解决表的宽度问题。你可以把不常用的字段单独放到一个表中,也可以把大字段独立放一个表中,或者把关联密切的字段放一个表中。
水平拆分:把原来一个表拆分成多个表,每个表的结构都一样,解决单表数据量大的问题。
















 1011
1011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









