






吴恩达深度学习笔记(二)
二、神经网络的编程基础(Basics of Neural Network programming)
1.二分类 (Binary Classification)
- 二分类的输出为1(是)和0(不是)。
二分类问题中数据的保存方法:
对于一张彩色图片,需要保存三个矩阵,它们分别对应图片中的红、绿、蓝三种颜色通道。如果图片的大小为 64x64像素,为了把这些像素值放到一个特征向量中,我们需要把这些像素值提取出来,然后放入一个特征向量 𝑥。那么向量 𝑥 的总维度=64×64×3=𝑛𝑥。
特征向量𝑥作为输入,其输出𝑦为1或0。
对于数据集中的m张照片,第i张照片的输入可表示为𝑥𝑖,输出表示为𝑦𝑖,用矩阵X和Y分别将所有输入和输出整合到一个矩阵。
- 𝑥:表示一个 𝑛𝑥维数据,为输入数据,维度为 (𝑛𝑥,1),
- 𝑦:表示输出结果,取值为(0,1);
- (𝑥𝑖,𝑦𝑖):表示第𝑖组数据,可能是训练组数据,可能是训练数据,也可能是测试数据;
- 𝑋=[𝑥1,𝑥2,…,𝑥𝑚):表示所有的训练数据集的输入值,放在一个 𝑛𝑥×𝑚的矩阵中,其中𝑚表示样本数目;
- 𝑌=[𝑦1,𝑦2,…,𝑦𝑚]:对应表示所有训练数据集的输出值,维度为1×𝑚。
2.逻辑回归 (Logistic Regression)
- 逻辑回归的本质是:假设数据服从这个分布,然后使用极大似然估计做参数的估计。常用于二分类问题。
举例: 𝑋是一张图片,𝑦^ 表示这是一只猫的图片的机率有多大。 若𝑋是一个 𝑛𝑥维的向量(相当于有 𝑛𝑥个特征的特征向量)。用 𝑤来表示逻辑回归的参数,这也是一个 𝑛𝑥维向量(因为 𝑤实际上是特征权重,维度与特征向量相同),参数里面还有 𝑏,这是一个实数(表示偏差)。所以给出输入 𝑥以及参数 𝑤和 𝑏之后,我们要考虑怎样产生输出预测值𝑦^ 。方法是y^ =σ(𝑤T𝑥+𝑏)。

- sigmoid函数
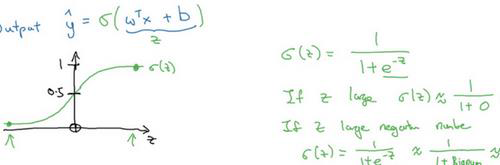
因此当实现逻辑回归时,我们的工作就是去让机器学习参数 𝑤以及 𝑏,这样才使得𝑦^对𝑦=1的概率有很好的估计。
3.逻辑回归的代价函数( Logistic Regression Cost Function)
- 为什么需要代价函数
逻辑回归的输出函数:

为了让模型通过学习调整参数,需要给予一个𝑚样本的训练集,这会让机器在训练集上找到参数 𝑤和参数 𝑏,来得到我们的输出。𝑦^表示对训练集的预测值,更希望它会接近于训练集中的𝑦值。
- 损失函数:又叫做误差函数,用来衡量算法的运行情况,Loss function:𝐿(𝑦^ ,𝑦).
通常损失函数为预测值和实际值的平方差或者它们平方差的一半,但是逻辑回归中用到的损失函数是:𝐿(𝑦^ ,𝑦)=−𝑦log(𝑦^ )−(1−𝑦)log(1−𝑦^)
原因是:
(1)当我们在学习逻辑回归参数的时候,会发现我们的优化目标不是凸优化,只能找到多个局部最优值,梯度下降法很可能找不到全局最优值。
(2)当𝑦=1时损失函数 𝐿=−log(𝑦^ ),如果想要损失函数 𝐿尽可能得小,那么𝑦^ 要尽可能大,因为 sigmoid函数取值 [0,1],所以𝑦^无限接近 1。
当𝑦=0时损失函数 𝐿=−log(1−𝑦^ ),如果想要损失函数 𝐿尽可能得小,那么𝑦^ 尽可能小,因为 sigmoid函数取值 [0,1],所以𝑦^ 无限接近0。
- 代价函数
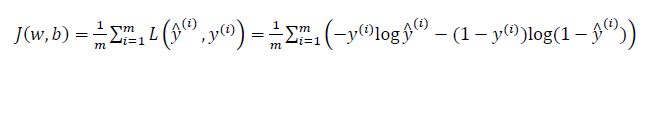
损失函数是在单个训练样本中定义的,它衡量的是算法在单个训练样本中表现,代价函数是为了衡量算法在全部训练样本上的表现。
在训练逻辑回归模型时候,我们需要找到合适的 𝑤和 𝑏,来让代价函数 𝐽 的总代价降到最低。
4.梯度下降法( Gradient Descent)
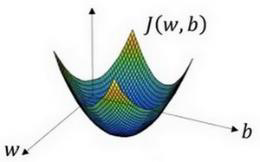
代价函数是一个关于w和b的二维函数,我们所做的就是找到使得代价函数(成本函数) 𝐽(𝑤,𝑏)函数值是最小值,对应的参数 𝑤和 𝑏。
(1)首先将w和b初始化为函数上任意一点。
(2)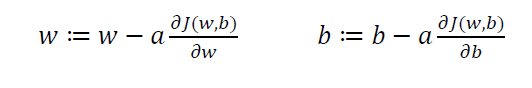
𝑎 表示学习率( learning rate),用来控制步长( step)。
每次对w和b进行一次更新,即实现一次迭代。
(3)整个梯度下降法的迭代过程就是不断地朝着最小值点方向走,直到走到全局最优解或者接近全局最优解的地方。















 912
912











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









