






论文地址:https://arxiv.org/abs/1608.00859
文章目录
1.TSN的含义
Temporal Segment Networks(TSN) 是一种用于视频中动作识别的框架。
TSN通过一种基于分段的采样和聚合模块对长程时间结构进行建模,从而能够使用整个动作视频有效地学习动作模型。通过简单的平均池和多尺度时间窗集成,学习的模型可以很容易地分别适用于修剪和未修剪视频中的动作识别。
2.TSN的作用
2.1.背景
- 对于视频中的动作识别,有两个关键且互补的线索:外观和时间动态。识别系统的性能在很大程度上取决于它是否能够从中提取和利用相关信息。
- 卷积神经网络(ConvNets)在目标、场景和复杂事件的图像分类方面取得了巨大成功。ConvNet也被引入来解决基于视频的动作识别问题。
2.2.一般卷积神经网络在视频动作识别中的困难
- 缺乏整合长程时间结构的能力。
一般卷积神经方法通常侧重于外观和短期运动,对于长程时间问题的解决方法大多依赖于具有预定义采样间隔的密集时间采样。这种方法会产生大量的计算开销和内存需求。 - 处理未剪辑的视频效果差。
现有的动作识别方法大多是针对剪辑过的视频设计的。未剪辑的视频中,每个动作实例只占据一小部分,主要背景部分可能干扰动作识别模型的预测。 - 训练样本问题
(1)公开数据集如UCF101等在规模和多样性方面仍然有限,容易过拟合。
(2)获取短期运动信息的光流提取成为将学习模型部署到大规模动作识别数据集的计算瓶颈。
总结为三个问题:1)如何有效地学习捕获远程时间结构的视频表示;2) 如何利用这些学习到的ConvNet模型来设置更真实的未剪辑视频;3) 如何在有限的训练样本下有效地学习ConvNet模型,并将其应用于大规模数据。
2.3.论文提出的解决方法
- 稀疏和全局时间采样策略
TSN框架首先将长视频划分为固定数量的片段,每个片段中随机采样一个片段。然后聚合来自采样片段的信息。论文提出了五个聚合函数:平均池、最大池和加权平均,top-K池和自适应注意加权。
时间段网络以该方式对整个视频的长距离时间结构建模,其计算成本与视频持续时间无关。 - 多尺度时间窗口集成的分层聚合策略
将未经剪辑的视频分割成一系列固定持续时间的短窗口,然后对每个窗口分别执行动作识别。最后采用top-K池或注意加权来聚合来自这些窗口的预测,产生识别结果。
聚合模块能够隐式地选择具有区分性动作实例的区间,同时抑制噪声背景的影响,因此对于未剪辑的视频识别是有效的。 - (1)跨模态初始化策略
将学习到的表示从RGB模态转换到其他模态,如光流和RGB差分。
(2)部分BN
其中只有第一个BN层的均值和方差自适应更新以处理域移位
(3)使用不同的输入类型
四种类型的输入模式,即单个RGB图像、叠加RGB差分、叠加光流场和叠加扭曲光流场。
总结为三个贡献:1)提出了一个端到端的框架,即时间段网络(TSN),用于学习捕获长期时间信息的视频表示;2)设计了一个分层聚合方案,将动作识别模型应用于未剪辑的视频;3) 调查了一系列学习和应用深度动作识别模型的良好实践。
3.TSN的详细介绍
3.1.网络框架

一个输入视频被分成K个段(上图展示了K=3的情况),并从每个段中随机选择一个短片段。片段由模式表示,例如RGB帧、光流(高灰度图像)和RGB差异(低灰度图像)。不同片段的类分数通过分段一致性函数进行融合,产生分段一致性,得到视频级别的预测。所有模式的预测都融合在一起以产生最终预测。所有代码段上的CONVnet共享参数。
3.2.基于分段的采样策略
-
TSN不是处理单个帧或短帧堆栈,而是处理从整个视频中采样的一系列短片段。
-
给定一个视频 V V V,把它分成 K K K个持续时间相等的段: { S 1 , S 2 , ⋅ ⋅ ⋅ , S K } \{S_{1},S_{2},···,S_{K}\} {S1,S2,⋅⋅⋅,SK}。从对应段 S K S_{K} SK中随机采样一个片段 T K T_{K} TK,然后TSN将片段序列 { T 1 , T 2 , ⋅ ⋅ ⋅ , T K } \{T_{1},T_{2},···,T_{K}\} {T1,T2,⋅⋅⋅,TK}建模为:
T S N ( T 1 , T 2 , ⋅ ⋅ ⋅ , T K ) = H ( g ( F ( T 1 ; W ) , F ( T 2 ; W ) , ⋅ ⋅ ⋅ , F ( T K ; W ) ) ) TSN(T_{1},T_{2},···,T_{K})=H(g(F(T_{1};W),F(T_{2};W),···,F(T_{K};W))) TSN(T1,T2,⋅⋅⋅,TK)=H(g(F(T1;W),F(T2;W),⋅⋅⋅,F(TK;W)))- F ( T K ) F(T_{K}) F(TK)表示参数为 W W W的ConVet的函数。它对片段 T K T_{K} TK处理并在所有类上生成类分数。 g g g为将多个片段的输出组合在一起的分段一致性函数。 H H H为预测整个视频中每个动作类别的概率的预测函数,通常为Softmax函数。
-
G = g ( F ( T 1 ; W ) , F ( T 2 ; W ) , ⋅ ⋅ ⋅ , F ( T K ; W ) ) G=g(F(T_{1};W),F(T_{2};W),···,F(T_{K};W)) G=g(F(T1;W),F(T2;W),⋅⋅⋅,F(TK;W))的损失函数为:
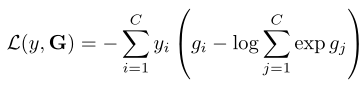
- C C C为行为类别的数量, y i y_{i} yi是关于类别 i i i的真实值, g i g_{i} gi是 G G G的第 j j j维。
-
损失值 L L L关于模型参数 W W W的导数为
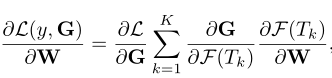
- K K K为TSN中的段数
-
优点
通过固定所有视频的 K K K的方式,采取稀疏的时间采样来选择少量片段。与以前使用密集采样帧的工作相比,它大大降低了在帧上评估ConvNet的计算成本。
3.3.聚合函数
-
Max pooling : g i = m a x k ∈ { 1 , 2 , ⋅ ⋅ ⋅ , K } f i k g_{i}=max_{k \in \{1,2,···,K\}}f^{k}_{i} gi=maxk∈{1,2,⋅⋅⋅,K}fik(其中 f i k f^{k}_{i} fik为 F k = ( T k ; W ) F^{k}=(T_{k};W) Fk=(Tk;W)的第 i i i个元素)
- 梯度
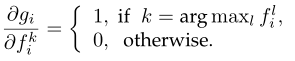
- 特点:将重点放在单个片段上,而完全忽略其他片段的响应。
优点:促进时间段网络从每个动作类的最有区别的片段中学习。
缺点:缺乏为视频级动作理解的联合建模多个片段的能力。
- 梯度
-
Average pooling: g i = 1 K ∑ k = 1 K f i k g_{i}=\frac{1}{K}\sum^{K}_{k=1}f^{k}_{i} gi=K1∑k=1Kfik
- 梯度
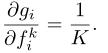
- 优点:能够联合建模多个片段,并从整个视频中捕获视觉信息。
缺点:对于复杂背景的嘈杂视频,一些片段可能与动作无关,对这些背景片段进行平均可能会影响最终的识别性能。
- 梯度
-
Top-K pooling: g i = 1 K ∑ k = 1 K α k f i k g_{i}=\frac{1}{K}\sum^{K}_{k=1}\alpha _{k}f^{k}_{i} gi=K1∑k=1Kαkfik( α K \alpha _{K} αK是选择的标记,如果选择,则设置为1,否则为0。)
- 梯度
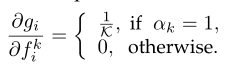
- 优点:能够为不同的视频自适应地确定鉴别片段的子集。因此,它拥有最大池化和平均池化的优点,能够联合建模多个相关片段,同时避免背景片段的影响。
- 梯度
-
Linear weighting: g i = ∑ k = 1 K w k f i k g_{i}=\sum^{K}_{k=1}w_{k}f^{k}_{i} gi=∑k=1Kwkfik( w k w_{k} wk为第 k k k个片段的权重)
- 梯度
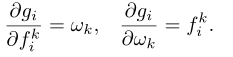
- 特点:用于学习动作类不同阶段的重要性权重。与以前基于池的聚合函数相比,此线性加权充当代码段选择的软版本。
- 梯度
-
Attention weighting: g i = ∑ k = 1 K A ( T k ) f i k g_{i}=\sum^{K}_{k=1}A(T_{k})f^{k}_{i} gi=∑k=1KA(Tk)fik
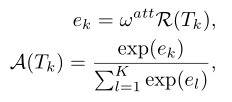
A ( T k ) A(T_{k}) A(Tk)是片段 T k T_{k} Tk的注意权重; w a t t w^{att} watt是注意权重函数的参数,与网络权重 W W W一起学习; R ( T k ) R(T_{k}) R(Tk)是第 k k k个片段的视觉特征。- 梯度
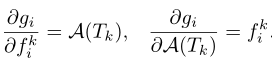
A ( T k ) A(T_{k}) A(Tk)关于注意模型参数 w a t t w^{att} watt的梯度:
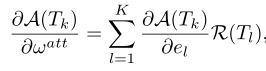
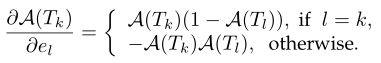
进一步将之前的反向传播公式修改为:
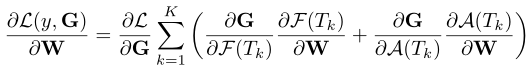
- 引入注意模型
A
(
T
k
)
A(T_{k})
A(Tk)的优点:
(1)注意模型通过基于视频内容自动评估每个片段的重要性权重,增强了TSN框架的建模能力
(2)注意模型基于ConvNet表示 R R R,因此它利用额外的反向传播信息来引导ConvNet参数 W W W的学习过程,并可能加速训练的收敛。
- 梯度
3.4.TSN的输入

上图为四种输入模态的示例:RGB图像、RGB差分、光流(optical flow)和扭曲光流(Warped Optical Flow))。
- 扭曲光流场(Warped Optical Flow):作者受改善的密集轨迹(improved dense trajectories )工作的启发。扭曲光流场对摄像机运动具有鲁棒性,有助于集中注意力于人体运动。
- RGB差分( RGB Differences):光流提取尽管具有较高的识别精度,但在双流网络(Two stream)中应用的一个问题是巨大时间成本。作者探讨了表观运动感知的最简单线索:连续帧之间RGB像素强度的叠加差异。 假设光流在表示运动时的强度可以从RGB差异的简单线索中学习。
3.5.解决过拟合策略
- 跨模态初始化
对于光流和RGB差分的输入模式,首先通过线性变换将光流场离散为0到255的区间,然后在第一层中对经过预训练的RGB模型在RGB通道上的权重进行平均,并通过TSN输入的通道数复制平均值。最后,直接从预训练的RGB网络复制TSN剩余层的权重。 - 局部BN
在使用预训练模型初始化后,冻结除第一层之外的所有BN层的均值和方差参数。由于光流的分布与RGB图像不同,第一卷积层的激活值将具有明显不同的分布,因此需要相应地重新估计均值和方差。同时,在全局池层之后增加一个Dropout层(实验中设置为0.8)。 - 数据增强
- 角裁剪(corner cropping ):提取的区域仅从图像的角点或中心选择,以避免更多地隐式聚焦于中心区域。
- 尺度抖动(scale jittering):将输入大小固定为256×340,裁剪区域的宽度和高度从{256,224,192,168}中随机选择。最后,这些裁剪区域将调整为224×224,用于网络训练。
4.TSN实验结果
4.1.不同训练策略

Table1是关于不同训练策略下双流网络的效果对比。可以看出交叉预训练(主要提升了temporal convnets的效果)和带有dropout的部分BN 又明显提升。
4.2.不同输入模式

Table2是关于网络的几种不同输入模式下双流网络的效果对比,数据集是UCF101。可以看到一般而言融合多种类型的输入可以达到更好的效果,尤其是利用光流信息。
4.3.不同片段数K

Table3是稀疏片段采样方案中不同片段数K的效果对比。可以观察到增加片段数通常会带来更好的性能。然而,当段数K从7增加到9时,性能饱和。实验中设置了K=7。
4.4.不同聚合函数

Table4是不同聚合函数的效果对比。在UCF101上,数据集由修剪过的人类动作视频组成,平均池化性能最佳,权重平均和注意权重性能相似。ActivityNet上,topK和注意力权重聚合函数性能相当,并优于基本函数,如平均池化。表明在具有更复杂和多样时间结构的数据集上,高级聚合函数会有更好的识别精度。
4.5.不同CNN架构

Table5是不同CNN架构在UCF101数据集上的效果对比。可以看到TSN使用 BN-Inception 的权重进行预训练,可以达到94.9%的准确率,说明TSN和主流的网络模型一起使用也十分有效。
4.6.与其他最新方法的对比

Table8是TSN与其他最新方法在在HMDB51、UCF101、THUMOS14和ActivityNet数据集上的效果对比。可以观察到TSN(3段)和TSN(7段)学习的模型的结果都优于最新的方法。















 431
431











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









