







当我们查看Excel数据时,有时想要根据工作表某列的值,用不同颜色来区分数据行,以便更直观的浏览数据(图片的数据由Python库faker直接生成,文末附上)。
如下图例子,我想根据B列年龄相同(23岁)且所在行相邻的行使用颜色A填充单元格,下一个不同年龄(24岁)的行用颜色B填充单元格,以此类推····

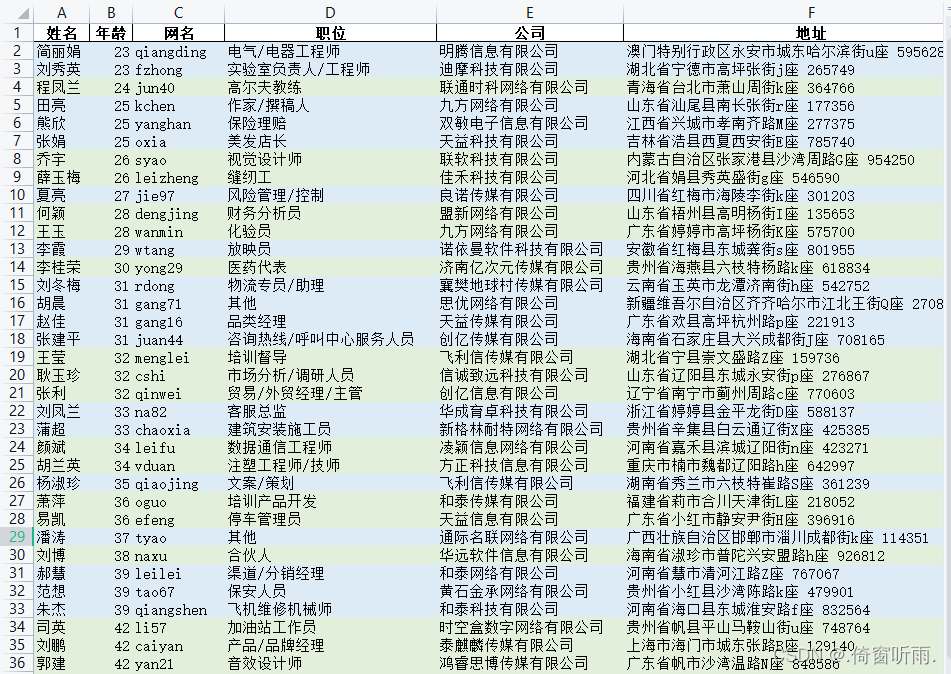
完整实现代码如下,使用前先安装openpyxl
pip install openpyxl"""
日期:2022年10月20日
功能:根据Excel文件的某列的值,用不同颜色进行区分;(支持多文件)
"""
from openpyxl import load_workbook
from openpyxl.styles import PatternFill
import os
def rgb2hex(rgb):
"""rgb颜色转十六进制颜色"""
colorHex = ''
for rg in rgb.split(','):
colorHex += hex(int(rg))[2:].upper()
return colorHex
def colorFill(filePath):
# 文件大于8兆时,文字提示等待
fileSize = os.stat(filePath).st_size / 1024/1024
if fileSize > 8:
print(f'【当前文件较大({round(fileSize,2)}M),数据的读取和保存可能较慢,请耐心等待】')
fill = [PatternFill('solid',fgColor=rgb2hex(h)) for h in bgColors] # 将RGB颜色转为十六进制的颜色值
print('读取中:',filePath)
wb = load_workbook(filePath) # 读取目标文件,文件越大读取越慢
ws = wb[sheetName] # 获取目标工作表
max_r = ws.max_row # 最大行
max_c = ws.max_column # 最大列
max_c = max_c if max_c<100 else 100
# 逐行处理
for r in range(startRow,max_r+1):
if ws[f"{columnName}{r}"].value != ws[f"{columnName}{r-1}"].value: # 判断当前单元格的值和sh
fill = fill[1:]+fill[:1]
# 填充整行或单个单元格
if isFillRow:
for c in range(1,max_c+1):
ws.cell(r,c).fill = fill[0]
else:
ws[f'{columnName}{r}'].fill = fill[0]
print("\r", end="")
p = int(r/max_r*100)
print("进度: {}%: ".format(p), "▋" * (p // 2), end="")
wb.close()
resultFile = 'output\\结果-'+filePath.split('\\')[1]
wb.save(resultFile)
# os.system(resultFile) # 完成后打开结果文件
if __name__=="__main__":
if os.path.exists('input'):
filePaths = os.listdir('input')
else:
os.mkdir('input')
print("当前目录下无input文件夹,请需要处理的文件放进去。")
if not os.path.exists('output'):
os.mkdir('output')
bgColors = ['226,239,218','221,235,247'] # 需要填充的颜色(RGB),至少填两个
sheetName = "Sheet1" # 需要处理的工作表,如:Sheet1
columnName = 'B' # 哪一列需要区分
startRow = 2 # 数据起始行
isFillRow = True # 是否填充整行的颜色,True:填充整行;False:只填充一个某列(columnName)
for filePath in filePaths:
colorFill('input\\'+filePath)
os.system('start output') # 完成后打开存放结果文件的文件夹关于RGB颜色的取值,可自行百度或在Excel中查找自己想要的颜色,并按***,***,***的格式替换代码中的bgColors数组。
生成测试数据的代码,如没用过pandas库和faker,请先自行安装
pip install pandas
pip install fakerfrom faker import Faker
import pandas as pd
f =Faker(locale='zh_CN')
df = pd.DataFrame()
df['姓名'] = [f.name_female() for i in range(50)]
df['年龄'] = [f.random_int(23,54) for i in range(50)]
df['网名'] = [f.user_name() for i in range(50)]
df['职位'] = [f.job() for i in range(50)]
df['公司'] = [f.company() for i in range(50)]
df['地址'] = [f.address() for i in range(50)]
df.sort_values('年龄',inplace=True)
df.to_excel('input\\测试.xlsx',index=False)
















 138
138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









