







Kafka笔记
一、概述
Apache Kafka® is a distributed streaming platform——分布式的流数据平台
Kafka具备三项关键能力:
- 发布订阅记录流(Record),类似于消息队列(MQ)或者企业级消息系统(记录流可以重复进行处理,处理后不会直接删除))
- 存储记录流,以一种容错持久化方式
- 实时处理加工流数据
Kafka的应用场景:
- 构建实时的流数据管道,可靠的在系统和应用间获取数据(MQ)
- 构建实时的流数据应用,传输或者处理加工流数据
Kafka中的核心概念:
- Broker(中间人或者代理人): 一个kafka服务实例
- Topic(主题): 某一个类别的记录
- Partition(分区): 对主题进行数据分区,一个主题有多个数据分区构成
- Replication(复制): 主题主分区中的数据备份,故障恢复
- Leader(主分区): 主题的主分区 读写操作默认使用主分区
- Follower(复制分区): 同步主分区中的数据(冗余备份),并且当主分区不可用时,某个follower会自动升级为主分区
- Offset(偏移量): 标识读写操作的位置,读offset <= 写offset
Kafka的四大核心API:
- The Producer API:允许应用发布记录流给一个或者多个Topic
- The Consumer API : 允许应用订阅一个或者多个主题,并且对主题中新产生的记录进行处理
- The Streams API : 允许应用扮演流处理器,消费来自于一个或者多个主题流数据记录,并且将处理的结果输出到一个或者多个主题中,Streams API可以高效的处理传输数据。
- The Connector API: 连接外部的存储系统
架构图

工作原理
- 首先
Producer产生Record发送给指定的Kafka Topic(Topic实质是有多个分区构成,每一个分区都会相应的复制分区),在真正存放到Kafka集群时会进行计算key.hashCode%topicPartitionNums等于要存放的分区序号。 Leader分区中的数据会自动同步到Follower分区中,ZooKeeper会实时监控服务健康信息,一旦发生故障,会立即进行故障转移操作(将一个Follower复制分区自动升级为Leader主分区)- Kafka一个分区实际上是一个有序的Record的
Queue(符合队列的数据结构,先进先出), 分区中新增的数据,会添加到队列的末尾,在处理时,会从队列的头部开始消费数据。Queue在标识读写操作位置时,会使用一个offset(读的offset <= 写的offset) - 最后
Consumer会订阅一个Kafka Topic,一旦Topic中有新的数据产生,Conumser立即拉取最新的记录,进行相应的业务处理。
二、环境搭建
kafka完全分布式集群
准备工作
- 3个节点
- 确保ZooKeeper集群运行正常
安装
[root@node1 ~]# scp kafka_2.11-2.2.0.tgz root@node2:~
kafka_2.11-2.2.0.tgz 100% 61MB 100.2MB/s 00:00
[root@node1 ~]# scp kafka_2.11-2.2.0.tgz root@node3:~
kafka_2.11-2.2.0.tgz
[root@nodex ~]# tar -zxf kafka_2.11-2.2.0.tgz -C /usr
配置
broker.id=0 | 1 | 2
# 第二个虚拟机使用 PLAINTEXT://node2:9092
# 第三个虚拟机使用 PLAINTEXT://node3:9092
listeners=PLAINTEXT://node1:9092
# kafka服务数据存放目录
log.dirs=/usr/kafka_2.11-2.2.0/data
# kafka集群中的数据最多保留7天
log.retention.hours=168
zookeeper.connect=node1:2181,node2:2181,node3:2181
启动服务
[root@nodex kafka_2.11-2.2.0]# bin/kafka-server-start.sh -daemon config/server.properties
[root@node1 kafka_2.11-2.2.0]# jps
1777 QuorumPeerMain
96294 Kafka # kafka的服务实例
关闭服务
[root@nodex kafka_2.11-2.2.0]# bin/kafka-server-stop.sh config/server.properties
三、基本操作
Topic管理
创建Topic
[root@node1 kafka_2.11-2.2.0]# bin/kafka-topics.sh --create --topic baizhi --partitions 3 --replication-factor 3 --bootstrap-server node1:9092,node2:9092,node3:9092
注意:
--create: 创建动作
--topic: 操作的主题名
--partitions: Leader分区的数量
--replication-factor: 复制因子,包含Leader分区本身
--bootstrap-server: Kafka集群地址列表
展示Topic列表
[root@node1 kafka_2.11-2.2.0]# bin/kafka-topics.sh --list --bootstrap-server node1:9092,node2:9092,node3:9092
baizhi
注意:
--list: 展示主题列表
查看指定的Topic描述
[root@node1 kafka_2.11-2.2.0]# bin/kafka-topics.sh --describe --topic baizhi --bootstrap-server node1:9092,node2:9092,node3:9092
Topic:baizhi PartitionCount:3 ReplicationFactor:3 Configs:segment.bytes=1073741824
Topic: baizhi Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: baizhi Partition: 1 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
Topic: baizhi Partition: 2 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
[root@node1 kafka_2.11-2.2.0]# bin/kafka-topics.sh --describe --topic baizhi --bootstrap-server node1:9092,node2:9092,node3:9092
[2019-08-22 17:49:40,572] WARN [AdminClient clientId=adminclient-1] Connection to node -2 (node2/192.168.12.131:9092) could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient)
Topic:baizhi PartitionCount:3 ReplicationFactor:3 Configs:segment.bytes=1073741824
Topic: baizhi Partition: 0 Leader: 0 Replicas: 1,0,2 Isr: 0,2
Topic: baizhi Partition: 1 Leader: 0 Replicas: 0,2,1 Isr: 0,2
Topic: baizhi Partition: 2 Leader: 2 Replicas: 2,1,0 Isr: 2,0

删除Topic
Kafka早期版本是不允许删除Topic,需要在配置文件 server.properties 添加一行配置
delete.topic.enable=true
[root@node1 kafka_2.11-2.2.0]# bin/kafka-topics.sh --delete --topic baizhi --bootstrap-server node1:9092,node2:9092,node3:9092
修改Topic
# baizhi topic 分区数量修改为2个
[root@node1 kafka_2.11-2.2.0]# bin/kafka-topics.sh --describe --topic baizhi --bootstrap-server node1:9092,node2:9092,node3:9092
Topic:baizhi PartitionCount:1 ReplicationFactor:1 Configs:segment.bytes=1073741824
Topic: baizhi Partition: 0 Leader: 2 Replicas: 2 Isr: 2
[root@node1 kafka_2.11-2.2.0]#
[root@node1 kafka_2.11-2.2.0]# bin/kafka-topics.sh --alter --topic baizhi --patitions 2 --bootstrap-server node1:9092,node2:9092,node3:9092
[root@node1 kafka_2.11-2.2.0]# bin/kafka-topics.sh --alter --topic baizhi --partitions 2 --bootstrap-server node1:9092,node2:9092,node3:9092
[root@node1 kafka_2.11-2.2.0]# bin/kafka-topics.sh --describe --topic baizhi --bootstrap-server node1:9092,node2:9092,node3:9092 Topic:baizhi PartitionCount:2 ReplicationFactor:1 Configs:segment.bytes=1073741824
Topic: baizhi Partition: 0 Leader: 2 Replicas: 2 Isr: 2
Topic: baizhi Partition: 1 Leader: 0 Replicas: 0 Isr: 0
发布订阅记录
发布消息
[root@node1 kafka_2.11-2.2.0]# bin/kafka-console-producer.sh --topic baizhi --broker-list node1:9092,node2:9092,node3:9092
>Hello Kafka
>Hello World
订阅消息
[root@node2 kafka_2.11-2.2.0]# bin/kafka-console-consumer.sh --topic baizhi --bootstrap-server node1:9092,node2:9092,node3:9092 --from-beginning
Hello Kafka
Hello World
四、Kafka中的基本概念
Topic和日志
Kafka的一个Topic(主题)在集群内部实际是有1到N个Partition(分区)构成,每一个Partition都是一个有序的,持序追加的Record队列,一个Partition是一个structured commit log(结构化的提交日志)。
Record持久化存放在Kafka集群中的,Record会有一个保留周期(默认是168小时),如果超过保留期,不论Record是否消费,Kafka都会丢弃。理论上来说,Kafka容量为维持在一个合理的范围区间之内(不断的产生新数据,不断丢失过期的数据)
kafka中的每一个Record在分区中都一个唯一的offset,offset会随着分区不断写入数据有序递增。并且Consumer会保留一个元数据(offset | position,记录了Consumer消费的位置),Kafka这种机制为我们提供Record重复处理或者跳过不感兴趣Record处理的功能
生产者(Producer)
Kafka Producer(生产者)是用来产生持续的Record,并发布到kafka某一个或者多个Topic中.
一个Record是由key,value,timestamp构成
发布Record时的策略:
key = null: 轮询Partitionkey != null: key.hashCode % partitionNum = 存放Record分区的序号手动指定Partition序号: Producer一方在发布Record时手动指定要存放的分区序号
消费者(Consumer)
Kafka Comsumer(消费者)订阅一个或者多个感兴趣的Topic,一旦这些Topic中有新的数据产生,会立即拉取到本地(Consumer)一方,进行相应的业务处理。
Kafka使用Consumer Group组织管理Conumser,Consumer Group特点: 组外广播,组内负载均衡
`
五、Kafka Java API
发布/订阅
Maven依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.2.0</version>
</dependency>
配置windows kafka集群的hosts映射
192.168.12.130 node1
192.168.12.131 node2
192.168.12.132 node3

生产者API
package pubsub;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.IntegerSerializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class KafkaProducerDemo {
public static void main(String[] args) {
//1. 创建配置对象 指定Producer的信息
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092,node2:9092,node3:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class); // 对record的key进行序列化
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
//2. 创建Producer对象
KafkaProducer<Integer, String> producer = new KafkaProducer<Integer, String>(properties);
//3. 发布消息
ProducerRecord<Integer, String> record = new ProducerRecord<Integer, String>("t1",1,"Hello World");
producer.send(record);
//4. 提交
producer.flush();
producer.close();
}
}
消费者API
package pubsub;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.IntegerDeserializer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class KafkaConsumerDemo {
public static void main(String[] args) {
//1. 创建配置对象 指定Consumer信息
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092,node2:9092,node3:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class); // k v按照反序列化进行解析
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "g1"); // 消费组的ID 同组负载均衡 不同组广播
//2. 创建消费者
KafkaConsumer<Integer, String> consumer = new KafkaConsumer<Integer, String>(properties);
//3. 订阅主题
consumer.subscribe(Arrays.asList("t1"));
//4. 拉取主题内新增的数据
while (true) {
ConsumerRecords<Integer, String> records = consumer.poll(Duration.ofSeconds(5));// 拉取的超时时间
for (ConsumerRecord<Integer, String> record : records) {
// 1 HelloWorld xxxx 0
System.out.println(record.key() + " | " + record.value() + " | " + record.timestamp() + " | " + record.offset() +" | "+ record.partition());
}
}
}
}
Topic管理
package topic;
import org.apache.kafka.clients.admin.*;
import org.apache.kafka.common.KafkaFuture;
import java.util.Arrays;
import java.util.Map;
import java.util.Properties;
import java.util.Set;
import java.util.concurrent.ExecutionException;
/**
* topic: 创建 删除 展示列表 查看详情 修改(不支持)
*/
public class TopicManagerDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
//1. 创建配置对象 指定Topic管理信息
Properties properties = new Properties();
properties.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG,"node1:9092,node2:9092,node3:9092");
AdminClient client = AdminClient.create(properties);
//2. 创建Topic
//client.createTopics(Arrays.asList(new NewTopic("t2",3,(short)3)));
//3. 展示Topic列表
/*
ListTopicsResult result = client.listTopics();
Set<String> topics = result.names().get();
// topics.forEach(topic -> System.out.println(topic));
for (String topic : topics) {
System.out.println(topic);
}
*/
//4. 查看topic详情
/*
DescribeTopicsResult result = client.describeTopics(Arrays.asList("t1"));
Map<String, KafkaFuture<TopicDescription>> values = result.values();
// values.forEach((k,v) -> System.out.println(k +" | " +v));
for (Map.Entry<String,KafkaFuture<TopicDescription>> entry: values.entrySet()) {
System.out.println(entry.getKey() + " | "+ entry.getValue().get());
}
*/
//5. 删除topic
client.deleteTopics(Arrays.asList("t2"));
// 关闭连接
client.close();
}
}
六、偏移量控制
Kafka的消费者在消费Record时会通过offset记录消费位置。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2KlU9T8G-1578322989662)(assets/1566973547250.png)]
Kafka会使用一个特殊的topic__consumer_offsets记录消费组的读的offset,__consumer_offsets由50个分区构成,每一个分区包含它本身有3个冗余备份。消费者在消费消息时,会根据所属的消费组的ID,去__consumer_offsets的特殊Topic中查找上一个提交的offset,然后从offset +1的位置继续消费。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZfZLWQ4T-1578322989663)(assets/2019-09-09_090059.png)]
业务解耦:功能都写在一个系统中代码的维护困难,系统的健壮性无法保证,一个环节出现错误,都会带来严重后果。引入消息中间件后,订单系统只负责产生订单,其他的附加操作都由订阅者完成。
Kafka偏移量的提交策略有两种**:
-
自动提交(默认):默认情况下kafka consumer在拉取完分区内的数据后,会自动提交读的offset
-
手动提交:大多数情况自动提交offset可以满足我们的需求,但是在一些特殊情况,我们需要手动提交offset。保证分区内数据都能够得到正确的处理。
# 关闭kafka consumer的offset自动提交 enable.auto.commit = falsepackage offset; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.serialization.IntegerDeserializer; import org.apache.kafka.common.serialization.StringDeserializer; import java.time.Duration; import java.util.Arrays; import java.util.Properties; public class KafkaConsumerDemo { public static void main(String[] args) { //1. 创建配置对象 指定Consumer信息 Properties properties = new Properties(); properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092,node2:9092,node3:9092"); properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class); // k v按照反序列化进行解析 properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); properties.put(ConsumerConfig.GROUP_ID_CONFIG, "g1"); // 消费组的ID 同组负载均衡 不同组广播 properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false); // 关闭kafka consumer的offset自动提交功能 //2. 创建消费者 KafkaConsumer<Integer, String> consumer = new KafkaConsumer<Integer, String>(properties); //3. 订阅主题 consumer.subscribe(Arrays.asList("t3")); //4. 拉取主题内新增的数据 while (true) { ConsumerRecords<Integer, String> records = consumer.poll(Duration.ofSeconds(5));// 拉取的超时时间 for (ConsumerRecord<Integer, String> record : records) { // 业务处理 // 支付 加积分 减去优惠券 // ... } // 手动提交offset偏移量 consumer.commitAsync(); } } }
七、指定分区消费
订阅Topic
subscribe订阅一个或者多个主题,一旦主题中有新的数据产生,consumer会收到topic内所有分区内的消息
//3. 订阅主题
consumer.subscribe(Arrays.asList("t1"));
指定消费Topic特定的分区
指定消费的topic的分区序号,一旦分区序号内有新的数据产生,consumer会收到特定分区的新产生的记录
// 分配方法: 只消费t1主题0号分区内的消息
consumer.assign(Arrays.asList(new TopicPartition("t1",0)));
手动控制消费offset
手动控制消费的offset,可以重置offset重复处理已经处理过的消息,设定offset跳过不感兴趣的消息
// 分配方法: 只消费t1主题0号分区内的消息 assign(分配)
consumer.assign(Arrays.asList(new TopicPartition("t1",0)));
// 手动指定消费的offset:从t1主题的0号分区offset=0的位置开始消费消息 seek(寻求,寻找)
consumer.seek(new TopicPartition("t1",0),0);
NOTE:
如果手动控制消费位置,offset提交策略就没有作用了,因为每次都是从指定的offfset位置开始向后消费消息
八、自定义对象类型传输与接收
kafka Serializer接口
public interface Serializer<T> extends Closeable {
void configure(Map<String, ?> configs, boolean isKey);
// 序列化方法
// topic: 操作主题名 T: 操作数据
// T ---> byte[]
byte[] serialize(String topic, T data);
@Override
void close();
}
kafka Deserializer接口
void configure(Map<String, ?> configs, boolean isKey);
// 反序列化方法
// byte[] ---> T
T deserialize(String topic, byte[] data);
@Override
void close();
添加JDK序列化和反序列化的工具类依赖
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.6</version>
</dependency>
创建自定义对象
public class User implements Serializable {
private String name;
private Boolean sex;
private Double salary;
//...
}
创建自定义对象的序列化器
package transfer;
import org.apache.commons.lang.SerializationUtils;
import org.apache.kafka.common.serialization.Serializer;
import java.io.Serializable;
import java.util.Map;
/**
* User ---> byte[]
*/
public class UserSerializer implements Serializer<User> {
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
}
// user ---> json --->byte[]
// byte[] ---> json ---> user
@Override
public byte[] serialize(String topic, User user) {
byte[] bytes = SerializationUtils.serialize((Serializable) user);
return bytes;
}
@Override
public void close() {
}
}
创建自定义对象的反序列化器
package transfer;
import org.apache.commons.lang.SerializationUtils;
import org.apache.kafka.common.serialization.Deserializer;
import java.util.Map;
public class UserDeserializer implements Deserializer<User> {
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
}
@Override
public User deserialize(String topic, byte[] bytes) {
User user = (User) SerializationUtils.deserialize(bytes);
return user;
}
@Override
public void close() {
}
}
测试
package transfer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.IntegerSerializer;
import java.util.Properties;
public class UserProducerDemo {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092,node2:9092,node3:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, UserSerializer.class);
KafkaProducer<Integer, User> producer = new KafkaProducer<Integer, User>(properties);
producer.send(new ProducerRecord<Integer, User>("t4", 1, new User("zs", true, 100D)));
producer.flush();
producer.close();
}
}
//--------------------------------------------------------------------------------------------
package transfer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.IntegerDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class UserConsumerDemo {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"node1:9092,node2:9092,node3:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,UserDeserializer.class);
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"g2");
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false); // 关闭offset自动提交
// properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,3000); // 自动提交offset间隔时间 单位毫秒
KafkaConsumer<Integer, User> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Arrays.asList("t4"));
while(true){
ConsumerRecords<Integer, User> records = consumer.poll(Duration.ofSeconds(5));
for (ConsumerRecord<Integer, User> record : records) {
System.out.println(record.key() +" " + record.value().getName() + " "+ record.offset());
}
}
}
}
九、Kafka和Spring Boot整合
创建SpringBoot工程
(略)
修改application.properties
# =====================生产者配置信息==========================
spring.kafka.producer.bootstrap-servers=node1:9092,node2:9092,node3:9092
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.IntegerSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
# =====================消费者配置信息==========================
spring.kafka.consumer.bootstrap-servers=node1:9092,node2:9092,node3:9092
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.IntegerDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.group-id=g1
定时任务
spring框架中有一个特殊的工具包
spring-task定时任务需要满足两个条件:
触发时机: cron表达式 秒 分 时 日 月 周 年
1 * 10 * * * *
固定数值 特殊字符: *(任意值) ?(不关心内容) / (增幅)
# 每秒执行一次 * * * * * ?
任务内容
生产者
package com.baizhi.kafka;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.FailureCallback;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.SuccessCallback;
import java.util.Date;
import java.util.concurrent.atomic.AtomicInteger;
@Component // 当前类自动注册为spring容器中的bean
public class ProducerDemo {
// 从10点23分0秒开始 每隔10秒触发一次
// @Scheduled(cron = "0/10 26 10 * * ?")
// public void m1(){
// System.out.println(new Date());
// }
@Autowired
public KafkaTemplate<Integer, String> kafkaTemplate;
private AtomicInteger atomicInteger = new AtomicInteger();
// 每隔5秒发送一条数据
@Scheduled(cron = "0/5 * * * * ?")
public void send() {
int num = atomicInteger.getAndIncrement();
ListenableFuture<SendResult<Integer, String>> future = kafkaTemplate.send("t4", num, "Hello World: " + num);
// 函数式编程
future.addCallback((t) -> {
System.out.println("发送成功:" + t);
}, (e) -> {
System.out.println("发送失败:" + e.getMessage());
});
}
}
消费者
package com.baizhi.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class ConsumerDemo {
/**
* 接受方法 消费消息方法
*/
@KafkaListener(topics = "t4") //订阅指定主题
public void receive(ConsumerRecord<Integer,String> record){
System.out.println(record.key() +" | " + record.value() + " | " +record.offset());
}
}
十、生产者批处理(优化)
好处是:节省我们的系统资源,传统是一个Record发送一次(占用系统资源)把多个数据打包一次性进行发送。
生产者会尝试缓冲record,实现批量发送,通过以下配置控制发送时机,以下是使用条件
batch.size # 当多条消息发送到一个分区时,生产者会进行批量发送,这个参数指定了批量消息的大小上限(以字节为单位)。
linger.ms # 这个参数指定生产者在发送批量消息前等待的时间,当设置此参数后,即便没有达到批量消息的指定大小,到达时间后生产者也会发送批量消息到broker
# 生产者一方的配置
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,2048); // 批量发送数据上限为 2kb
properties.put(ProducerConfig.LINGER_MS_CONFIG,1000); // 批量发送最大等待时间 1s
十一、消费组
消费组实际上是用来管理组织消费者,原则:组外广播,组内负载均衡
组外广播
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "g1");
// 或
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "g2");
组内负载均衡
# 注意: 多个消费者的消费组必须得一样
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "g1");
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "g1");
结论:
消费组组内负载均衡是针对于分区,组内的消费者在负载均衡时,一个消费者负责Topic一个或者多个分区内数据处理
十二、生产者的幂等性(idempotence)
幂等:多次操作的结果和一次操作的结果相同,就称为幂等性操作。读操作一定是幂等性操作,写操作一定不是幂等性操作。
Restful: 微服务系统设计架构
GET: 查询
POST: 新增
PUT: 修改
DELETE:删除幂等性操作: GET \ Delete \Put
实际生活中的案例:当我们付款以后,我们没有收到回应,这时会再次操作。
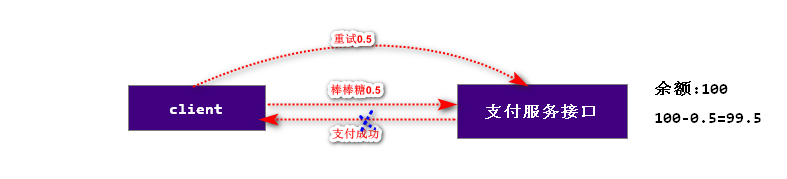
Kafka的producer和broker之间默认有应答(ack)机制,当kafka的producer发送数据给broker,如果在规定的时间没有收到应答,生产者会自动重发数据,这样的操作可能造成重复数据(at least once语义)的产生。

使用方法
开启kafka生产者的幂等性支持
acks = all // 0 无需应答 1 只写入Leader分区后立即ack -1(all) 写入到leader和follower分区后再进行应答
retries = 3 // 表示重试次数
request.timeout.ms = 3000 //等待应答超时时间
enable.idempotence = true //开启幂等性
properties.put(ProducerConfig.ACKS_CONFIG,"all"); // ack的机制
properties.put(ProducerConfig.RETRIES_CONFIG,3); // 重试发送record的次数
properties.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG,3000); // 请求的超时时间 单位毫秒
properties.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG,true); // 开启幂等性支持
十三、Kafka事务
数据库事务回顾
数据库事务:多个操作是一个原子操作,不可分割,同时成功或者同时失败。
事务问题: 脏读、不重复读、幻影读
事务隔离级别(解决事务问题):读未提交、读提交、可重复读、序列化读
Kafka事务
kafka事务指的是在一个事务内多个Record发送或者处理是一个原子操作,不可分割,同时成功,或者同时失败。
kafka事务的隔离级别:读未提交(默认:read_uncommitted)、读提交(read_commmitted)
Kafka Producer对象中的事务方法
// 初始化事务
public void initTransactions() {
throwIfNoTransactionManager();
if (initTransactionsResult == null) {
initTransactionsResult = transactionManager.initializeTransactions();
sender.wakeup();
}
try {
if (initTransactionsResult.await(maxBlockTimeMs, TimeUnit.MILLISECONDS)) {
initTransactionsResult = null;
} else {
throw new TimeoutException("Timeout expired while initializing transactional state in " + maxBlockTimeMs + "ms.");
}
} catch (InterruptedException e) {
throw new InterruptException("Initialize transactions interrupted.", e);
}
}
// 开启事务
public void beginTransaction() throws ProducerFencedException {
throwIfNoTransactionManager();
transactionManager.beginTransaction();
}
// 提交事务
public void commitTransaction() throws ProducerFencedException {
throwIfNoTransactionManager();
TransactionalRequestResult result = transactionManager.beginCommit();
sender.wakeup();
result.await();
}
// 将事务内的offset发送kafka集群
public void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,
String consumerGroupId) throws ProducerFencedException {
throwIfNoTransactionManager();
TransactionalRequestResult result = transactionManager.sendOffsetsToTransaction(offsets, consumerGroupId);
sender.wakeup();
result.await();
}
// 取消事务
public void abortTransaction() throws ProducerFencedException {
throwIfNoTransactionManager();
TransactionalRequestResult result = transactionManager.beginAbort();
sender.wakeup();
result.await();
}
仅生产者事务
Kafka生产者在一个事务内生产的Record是一个不可分割的整体,要么同时写入Kafka集群,或者某个出错,回滚撤销所有的写操作
开启生产者事务:
我们想使用kafka生产者事物的话要保证幂等性要设置为true,还要定义一个事物编号。每一个生产者需要唯一的事物编号。
ENABLE_IDEMPOTENCE_CONFIG=true每一个生产者,需要唯一的事务编号:TransactionID事务的超时时间(可选):TRANSACTION_TIMEOUT_CONFIG
package transaction;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.errors.ProducerFencedException;
import org.apache.kafka.common.serialization.IntegerSerializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.UUID;
public class KafkaProducerDemo {
public static void main(String[] args) {
//1. 创建配置对象 指定Producer的信息
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092,node2:9092,node3:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class); // 对record的key进行序列化
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
properties.put(ProducerConfig.ACKS_CONFIG,"all"); // ack的机制
properties.put(ProducerConfig.RETRIES_CONFIG,3); // 重试发送record的次数
properties.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG,3000); // 请求的超时时间 单位毫秒
properties.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG,true); // 开启幂等性支持
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,2048); // 批处理的数据上限
properties.put(ProducerConfig.LINGER_MS_CONFIG,1000); // 批处理的时间上限
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, UUID.randomUUID().toString()); // 生产者事务的ID
properties.put(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG,1000); // 事务的超时时间
//2. 创建Producer对象
KafkaProducer<Integer, String> producer = new KafkaProducer<Integer, String>(properties);
// 初始化kafka的事务
producer.initTransactions();
// 开启Kafka的事务
producer.beginTransaction();
//3. 发布消息
// ProducerRecord<Integer, String> record = new ProducerRecord<Integer, String>("t1",1,"Hello World");
// ProducerRecord<Integer, String> record = new ProducerRecord<Integer, String>("t1",2,"Hello World2");
try {
for (int i = 80; i < 100; i++) {
ProducerRecord<Integer, String> record = new ProducerRecord<Integer, String>("t1",i,"Hello World"+i);
producer.send(record);
}
// 正常操作 提交Kafka事务
producer.commitTransaction();
} catch (ProducerFencedException e) {
e.printStackTrace();
// 异常操作 回滚kafka事务
producer.abortTransaction();
}
//4. 提交
producer.flush();
producer.close();
}
}
Consume-Transfer-Produce
消费和生产并存事务: 消费和生产在一个事务内完成,同时成功或者同时失败

准备测试使用的topic
[root@node1 kafka_2.11-2.2.0]# bin/kafka-topics.sh --create --topic t5 --partitions 3 --replication-factor 3 --bootstrap-server node1:9092,node2:9092,node3:9092
[root@node1 kafka_2.11-2.2.0]# bin/kafka-topics.sh --create --topic t6 --partitions 3 --replication-factor 3 --bootstrap-server node1:9092,node2:9092,node3:9092
[root@node1 kafka_2.11-2.2.0]# bin/kafka-topics.sh --list --bootstrap-server node1:9092,node2:9092,node3:9092
t5
t6
消费生产并存事务(重点)
特点:消费kafka的A主题进行业务操作,将操作的结果写入到B主题中。如果开启
consume-transfer-produce事务,读A和写B在一个事务环境中,不可分割,要么同时成功,要么同时失败。
package transaction;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.errors.ProducerFencedException;
import org.apache.kafka.common.serialization.IntegerDeserializer;
import org.apache.kafka.common.serialization.IntegerSerializer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.time.Duration;
import java.util.*;
/**
* 消费生产并存事务
*/
public class ConsumeTransferProduce {
public static void main(String[] args) {
KafkaProducer<Integer, String> producer = initProducer();
KafkaConsumer<Integer, String> consumer = initConsumer();
//1. 消费者订阅
consumer.subscribe(Arrays.asList("t5"));
//2. 初始化kafka的事务
producer.initTransactions();
while (true) {
//3. 开启kafka事务环境
producer.beginTransaction();
try {
ConsumerRecords<Integer, String> records = consumer.poll(Duration.ofSeconds(5));
Map<TopicPartition, OffsetAndMetadata> commitOffset = new HashMap<>();
for (ConsumerRecord<Integer, String> record : records) {
// 业务操作
System.out.println(record.key() + " ---> " + record.value());
// 人为模拟业务错误
//==============================================
/*
if (record.value().equals("AA")){
int m = 1/0;
}
*/
//==============================================
// 手动维护消费的偏移量信息
commitOffset.put(new TopicPartition(record.topic(), record.partition()), new OffsetAndMetadata(record.offset() + 1));
// 消费啥内容 发送啥内容
producer.send(new ProducerRecord<Integer, String>("t6", record.key(), record.value()));
}
//4. 将事务内的消费的偏移量提交
producer.sendOffsetsToTransaction(commitOffset, "g1");
//5. 提交kafka的事务
producer.commitTransaction();
} catch (ProducerFencedException e) {
e.printStackTrace();
//6. 回滚事务
producer.abortTransaction();
}
}
}
/**
* 初始化 生产者实例
*
* @return
*/
public static KafkaProducer<Integer, String> initProducer() {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092,node2:9092,node3:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 2048);
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1000);
properties.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
properties.put(ProducerConfig.ACKS_CONFIG, "all");
properties.put(ProducerConfig.RETRIES_CONFIG, 3);
properties.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG, 2000);
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, UUID.randomUUID().toString()); // 事务的ID
properties.put(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 1000);
return new KafkaProducer<Integer, String>(properties);
}
/**
* 初始化 消费者实例
*
* @return
*/
public static KafkaConsumer<Integer, String> initConsumer() {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092,node2:9092,node3:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "g1");
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false); // 手动提交消费的offset
properties.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed"); // 读已提交 不会读到别的事务未提交的记录
return new KafkaConsumer<Integer, String>(properties);
}
}
十四、MQ的应用场景
异步通信
系统解耦
流量削峰
日志处理
MQ的应用场景:https://www.jianshu.com/p/a4186a6b51b4
作业:Kafka异步通信作业
用户注册系统
- 用户信息保存到MySQL中
- 发送邮件通知(email):
java mail - 发送短信通知(可选): 免费的短信服务接口
技术选项:springboot + html + mysql + kafka 生产者和消费者API
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092,node2:9092,node3:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "g1");
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false); // 手动提交消费的offset
properties.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed"); // 读已提交 不会读到别的事务未提交的记录
return new KafkaConsumer<Integer, String>(properties);
}
}
## 十四、MQ的应用场景
### 异步通信
[外链图片转存中...(img-KlWpygzK-1578322989668)]
### 系统解耦
[外链图片转存中...(img-HYplotyx-1578322989668)]
### 流量削峰
[外链图片转存中...(img-GsgcpnLN-1578322989669)]
### 日志处理
[外链图片转存中...(img-RtE9rIci-1578322989670)]
[外链图片转存中...(img-UI7JEB8e-1578322989671)]
MQ的应用场景:<https://www.jianshu.com/p/a4186a6b51b4>
### 作业:Kafka异步通信作业
用户注册系统
- 用户信息保存到MySQL中
- 发送邮件通知(email):` java mail`
- 发送短信通知(可选): 免费的短信服务接口
技术选项:springboot + html + mysql + kafka 生产者和消费者API














 3181
3181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









