







在查询的时候,我们会遇到因为数据量太大,查询的数据太多,导致加载速度缓慢。给用户带来不好的体验,那么有什么方法可以解决吗?这里我们会演示两种解决方案。
分页
数据库里有多少数据,就查询多少。比如我数据库里面的数据有1千条。查询用了812ms
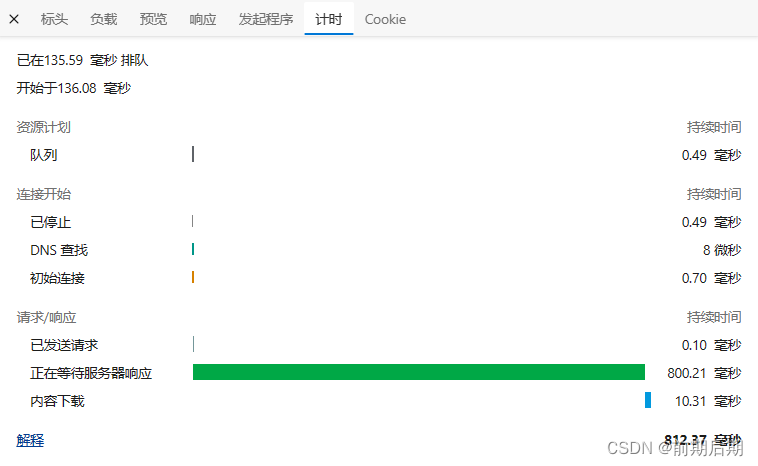
那么还有什么方法可以把查询速度提高吗?给用户更好的体验。
最能想到的方法,就是给其增加分页,限制数据量的查询。
1.使用分页,24ms,每页查询8条数据。

那么分页可以解决问题,为什么还要使用redis呢?看使用场景,数据量不大的情况,我们可以通过分页来解决,减少redis的成本,如果查询的数据很多,尤其是像一些数据统计,那么分页就使用不了,这个时候我们就可以使用缓存机制,redis
redis
引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>2.6.4</version>
</dependency>
编写配置
spring:
redis:
port: 6379
host: localhost
database: 0
接下来我们先测试一下是否可以往redis里面存储数据
1.我们使用RedisTemplate可以对redis进行操作。
@Test
public void testRedis(){
//现在,我们来测试一下,如何往redis里面存储数据
//1.使用redisTemplate获得操作redis的功能,opsForValue表示使用string数据结构类型
ValueOperations opsForValue = redisTemplate.opsForValue();
//2.增加数据
opsForValue.set("name","zwl");
opsForValue.set("age",25);
User user = new User();
user.setUserAccount("asdfasdf");
opsForValue.set("user",user);
//2.查询数据
String name = (String)opsForValue.get("name");
System.out.println(name);
Object age = opsForValue.get("age");
System.out.println(age);
User user1 = (User)opsForValue.get("user");
System.out.println(user1);
}
打印:

我们看看redis里面是如何存储这些数据的。这里我们可以使用QuickRedis可视化工具看一下我们存储的数据,我们发现数据有点奇怪,有乱码。
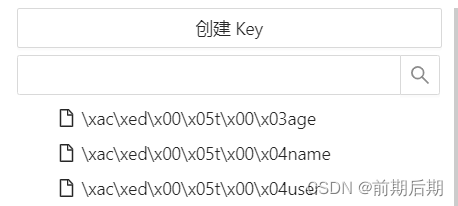
使用命令行也查询不了数据。
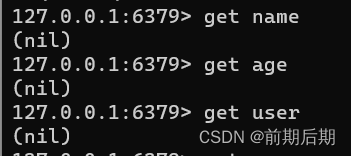
问题肯定是落在这个乱码这里。因为我们使用了它默认的序列化器,它会默认给我们的key加入一些东西,所以我们借助一些其他工具进行查询的时候就有问题。
接下来我们可以使用自定义的序列化器。
我们发现使用StringRedisTemplate ,而不是用RedisTemplate,问题得到了解决。但是存储的内容也就只能局限string类型。
@Resource
private StringRedisTemplate stringRedisTemplate;
@Test
public void testRedis(){
//现在,我们来测试一下,如何往redis里面存储数据
//1.使用redisTemplate获得操作redis的功能,opsForValue表示使用string数据结构类型
ValueOperations opsForValue = stringRedisTemplate.opsForValue();
//2.增加数据
opsForValue.set("name","zwl");
//2.查询数据
String name = (String)opsForValue.get("name");
System.out.println(name);
Object age = opsForValue.get("age");
System.out.println(age);
User user1 = (User)opsForValue.get("user");
System.out.println(user1);
}
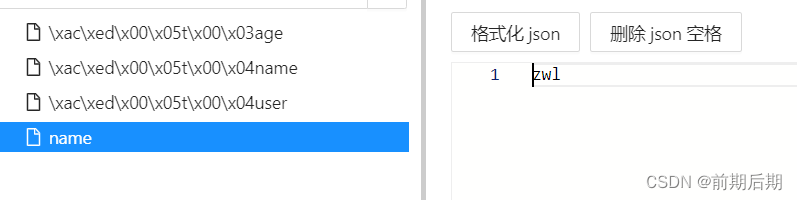
所以,我们也可以参考StringRedisTemplate 使用的是什么序列化器。然后对默认的进行修改。
@Configuration
public class RedisTemplateConfig {
@Bean
public RedisTemplate<String ,Object> redisTemplate(RedisConnectionFactory redisConnectionFactory){
RedisTemplate<String ,Object> redisTemplate = new RedisTemplate();
redisTemplate.setConnectionFactory(redisConnectionFactory);
//设置key序列化器
//设置类型
redisTemplate.setKeySerializer(RedisSerializer.string());
return redisTemplate;
}
}

数据有了。也可以取出来。
那么缓存应该在什么时候使用呢?接下来我们会演示一个例子,比如在查询用户数据的时候,查询一千条,看查询的耗时。
@GetMapping("/recommend")
public BaseResponse<Page<User>> recommendUsers(long pageSize, long pageNum, HttpServletRequest request){
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
/**
* 增加缓存。 怎么理解呢???????
* 1.首先查询缓存,如果缓存中没有,则从数据库中查询,并且存储一份到缓存,
* 1.1 每个用户的推荐页面可能都不一样,所以我们需要根据用户的id来进行存储缓存
* 2.如果缓存中有了。则从缓存中开始查询
*/
User userData = getCurrentUser(request).getData();
String key = String.format("pao:user:recommend:%s",userData.getId());
ValueOperations opsForValue = redisTemplate.opsForValue();
Object result = opsForValue.get(key);
if (result!=null) {
System.out.println("----查询redis");
Page<User> userList = (Page<User>) result;
return ResultUtils.success(userList);
}
System.out.println("----查询mysql");
Page<User> userList = userService.page(new Page<>(pageNum, pageSize), queryWrapper);
try{
//缓存如果出现问题,不要影响数据库查询
opsForValue.set(key,userList);
}catch (Exception e){
log.error("redis set key error",e);
}
return ResultUtils.success(userList);
}
可以看到第一次的时候是140ms,第二次以后30ms,甚至20ms

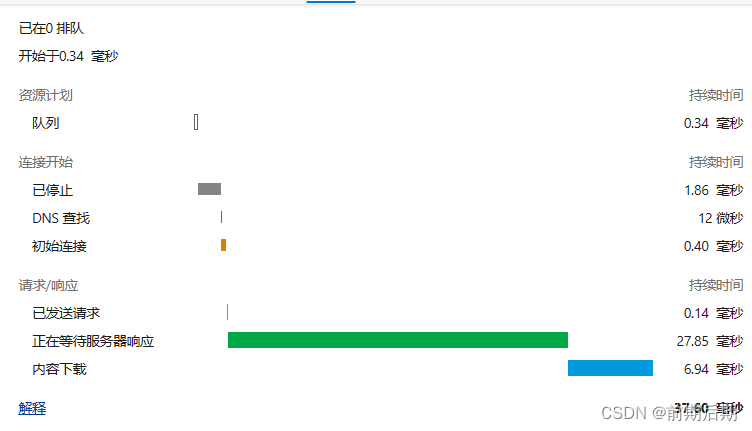
上面的代码还存在一些问题。就是这个内容没有过期,那么每次用户取到的数据都是不变的,并且对我们redis内存是占用的。所以我们要加上过期时间。如何设置呢?比如下面我们设置100s
opsForValue.set(key,userList,100000, TimeUnit.MILLISECONDS);
但是第一次还是很慢,有没有什么方法可以解决这个问题,可以提供过提前缓存,模拟有个人提前缓存过。
缓存预热
虽然缓存预热可以帮助我们解决第一次加载慢的问题,但使用缓存预热也需要考虑一些问题。
- 数据更新不及时。
- 应该什么时候使用缓存预热呢?
- 会占用资源,如果用户没有访问的情况下。
一般,我们会选择一个重点客户进行缓存预热,比如老板账户,根据实际场景进行缓存预热,比如数据统计,1,2个小时统计也可以(根据自己的业务场景进行调整。)
这里我们会用到定时任务。
开启定时任务注解
@SpringBootApplication
@EnableScheduling
public class UserCenterApplication {
public static void main(String[] args) {
SpringApplication.run(UserCenterApplication.class, args);
}
}
开启定时任务
@Component
@Slf4j
public class PreCacheJob {
@Resource
private UserService userService;
@Resource
private RedisTemplate redisTemplate;
private List<Long> idList = Arrays.asList(1L);
@Scheduled(cron = "0 55 * * * ? ") // 秒 分钟 小时 日 月 周 年
public void doCacheRecommendUser(){
//根据id,查询指定的用户出来,然后进行数据缓存。
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
for (Long id : idList) {
String key = String.format("pao:user:recommend:%s",id);
ValueOperations opsForValue = redisTemplate.opsForValue();
Page<User> userList = userService.page(new Page<>(1, 20), queryWrapper);
try{
//缓存如果出现问题,不要影响数据库查询
opsForValue.set(key,userList,100000, TimeUnit.MILLISECONDS);
}catch (Exception e){
log.error("redis set key error",e);
}
}
}
}
那么我们第一次获取数据也会很快。
那么到这里,大家觉得写法上面还存在什么问题???加入我部署了两个这样的项目,有些情况下,我们可以部署多个项目到服务器的。那么这个定时任务,是不是会执行两遍。有一些大公司可能会附属个100台,那么消耗量就极大了,如果这个定时任务不是查询,而是增加,那么就乱套了。
解决方案,需要用到锁,分布式锁。
分布式锁
但为什么要使用分布式锁呢,为什么不用锁呢?众所周知,普通锁只对同一个jvm有效,如果你有两台服务器,运行在不同的环境中,也就是你本来一个商场,只有一个厕所,只能一个人先上,现在两个商场了,那么就是两个厕所,就可以两个人上,所以肯定是不行。而分布式锁,则是把厕所变为一个,只有一个人能用。
具体实现,我们需要借助Redission,Redisson是一个java操作Redis的客户端,提供了大量的分布式数据集来简化对Redis的操作和使用,可以让开发者像使用本地集合一样使用Redis,完全感知不到Redis的存在。
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.18.0</version>
</dependency>
/**
* Redisson 配置
*/
@Configuration
@ConfigurationProperties(prefix = "spring.redis")
@Data
public class RedissonConfig {
private String host;
private String port;
@Bean
public RedissonClient redissonClient(){
//1、创建配置
Config config = new Config();
String redisAddress = String.format("redis://%s:%s", host, port);
config.useSingleServer().setAddress(redisAddress).setDatabase(0);
//2.创建实例
RedissonClient redisson = Redisson.create(config);
return redisson;
}
}
@Component
@Slf4j
public class PreCacheJob {
@Resource
private UserService userService;
@Resource
private RedisTemplate redisTemplate;
@Resource
private RedissonClient redissonClient;
private List<Long> idList = Arrays.asList(1L);
@Scheduled(cron = "0 55 * * * ? ") // 秒 分钟 小时 日 月 周 年
public void doCacheRecommendUser(){
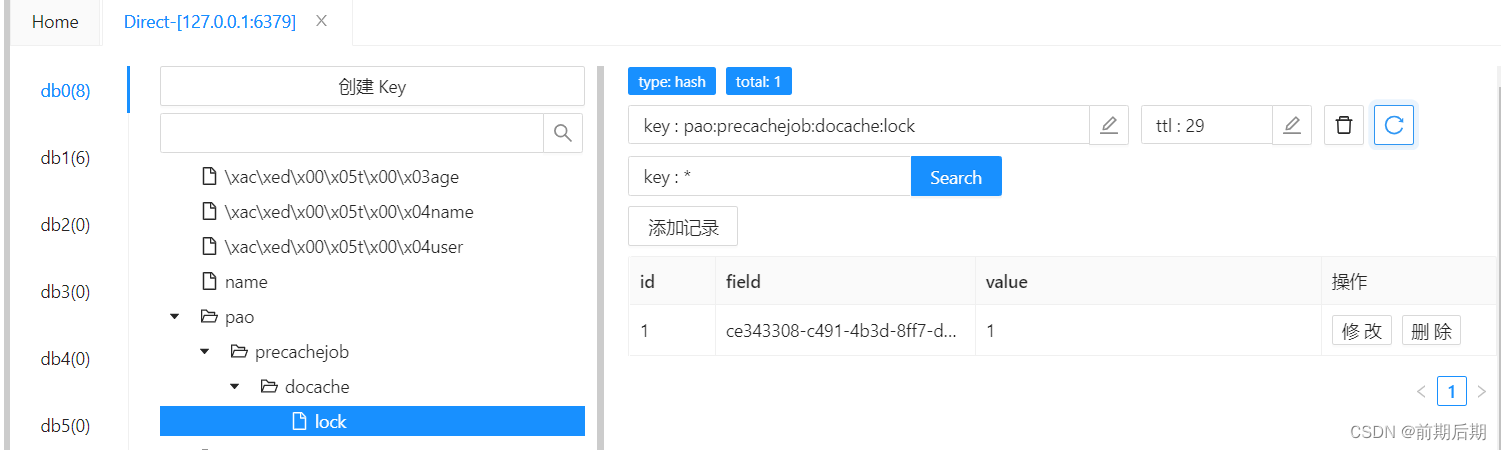
RLock lock = redissonClient.getLock("pao:precachejob:docache:lock");
try {
if (lock.tryLock(0,30000, TimeUnit.MILLISECONDS)) {
//根据id,查询指定的用户出来,然后进行数据缓存。
for (Long id : idList) {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
String key = String.format("pao:user:recommend:%s",id);
ValueOperations opsForValue = redisTemplate.opsForValue();
Page<User> userList = userService.page(new Page<>(1, 20), queryWrapper);
try{
//缓存如果出现问题,不要影响数据库查询
opsForValue.set(key,userList,100000, TimeUnit.MILLISECONDS);
}catch (Exception e){
log.error("redis set key error",e);
}
}
}
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
}
其实这里还有问题,如果这个方法执行的实现很长,比如超过了30秒,那么锁不是会被释放吗?那么其他服务器的也还是会执行。那么怎么办呢?我们就需要用到这个自动续期机制,也就是给锁续过期时间,redisson默认是30秒的过期时间,每10秒续期一次。那么如何修改呢?如下,这里修改为-1即可。
@Scheduled(cron = "0 55 * * * ? ") // 秒 分钟 小时 日 月 周 年
public void doCacheRecommendUser(){
RLock lock = redissonClient.getLock("pao:precachejob:docache:lock");
try {
if (lock.tryLock(0,-1, TimeUnit.MILLISECONDS)) {
//根据id,查询指定的用户出来,然后进行数据缓存。
for (Long id : idList) {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
String key = String.format("pao:user:recommend:%s",id);
ValueOperations opsForValue = redisTemplate.opsForValue();
Page<User> userList = userService.page(new Page<>(1, 20), queryWrapper);
try{
//缓存如果出现问题,不要影响数据库查询
opsForValue.set(key,userList,100000, TimeUnit.MILLISECONDS);
}catch (Exception e){
log.error("redis set key error",e);
}
}
}
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
可以看到锁,注意需要睡眠的方式,才能看到锁,如果使用断电,则不会有看到哈。这个需要注意的。
好了。今天的分享就到这里,希望能对大家有所帮助














 2037
2037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









