



mysql分页查询优化
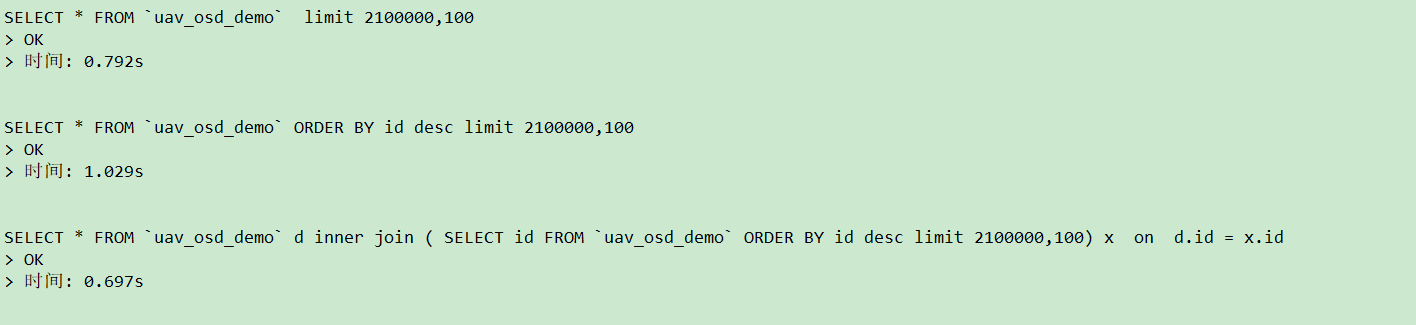
一, SELECT * FROM `uav_osd_demo` limit 2100000,100;
二, SELECT * FROM `uav_osd_demo` ORDER BY id desc limit 2100000,100;
三, SELECT * FROM `uav_osd_demo` d
inner join
( SELECT id FROM `uav_osd_demo` ORDER BY id desc limit 2100000,100) x
on d.id = x.id ;
三条sql ,先看执行效率
一,二对比
一, SELECT * FROM uav_osd_demo limit 2100000,100;

二, SELECT * FROM uav_osd_demo ORDER BY id desc limit 2100000,100;

为什么1没有走索引 比2走索引快 ?
-
1执行了一个看似效率低下的“全表扫描”并跳过了大量的记录,但由于不需要进行排序或复杂的索引查找,其实际的I/O模式非常直接,即顺序读取数据文件。这种情况下,对于现代硬盘来说,连续读取速度通常比随机读取要快得多,尤其是在大数据量的情况下。
-
InnoDB 的 B+ 树索引在正向扫描时,可以通过叶子节点的双向链表快速移动;反向扫描则需要从右向左遍历链表节点,操作更复杂。
-
正向扫描的数据在内存中连续分布,更易被 CPU 缓存命中;反向扫描的数据访问模式随机,缓存命中率低。
-
2使用了索引,但由于需要对大范围的数据进行排序,导致了更高的计算和I/O开销。特别是当数据量非常大时,排序操作可能会成为瓶颈,因为它不仅消耗更多的CPU资源,还可能导致额外的磁盘I/O操作。
其他问题
SELECT * FROM `uav_osd_demo` order by id asc limit 2100000,100;
SELECT * FROM `uav_osd_demo` limit 2100000,100; 有什么区别吗?
有的. 传统我们认为mysql 默认没有order by的情况 , 排序规则默认是order by id asc的, 其实这是错误的.
始终牢记:SQL 标准中未指定 ORDER BY 的查询,其顺序是“未定义”的,MySQL 的默认行为可能随时因版本、配置或数据变化而改变。显式排序是唯一可靠的方式。
主要影响因素
- 存储引擎与索引
- InnoDB:默认按主键顺序返回(若存在主键),但若查询使用了其他索引,可能按该索引的顺序返回。
- MyISAM:默认按数据插入的物理顺序返回(若表未发生删除或碎片整理)。
- MEMORY:结果顺序可能完全随机。
- 查询优化器的选择
- 优化器可能根据索引统计、查询条件、连接方式等选择不同的执行计划,导致结果顺序变化。
例如:当查询使用 WHERE 条件时,优化器可能选择某个索引扫描,结果按该索引顺序返回。
数据修改操作
- 插入、删除、更新等操作可能改变数据的物理存储顺序(尤其是 InnoDB 的 MVCC 机制)。
小结
正向查询比逆向更快, 分页查询必须order by 保证顺序, 通常业务需要desc
二,三对比
二, SELECT * FROM uav_osd_demo ORDER BY id desc limit 2100000,100;

三, SELECT * FROM uav_osd_demo d
inner join
( SELECT id FROM uav_osd_demo ORDER BY id desc limit 2100000,100) x
on d.id = x.id ;

回顾执行计划顺序, 先大后小,先上后下
type字段:反映数据访问方式,从最优到最差排序为:system > const > eq_ref > ref > range > index > ALL。应尽量避免ALL(全表扫描)。
Extra字段:若出现Using temporary(临时表)或Using filesort(文件排序),通常意味着性能瓶颈。
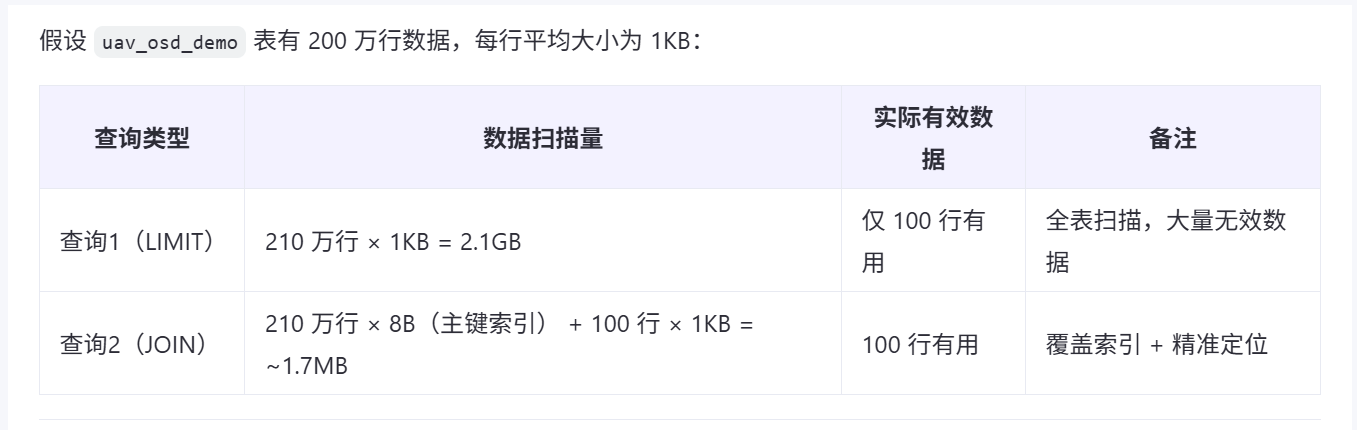
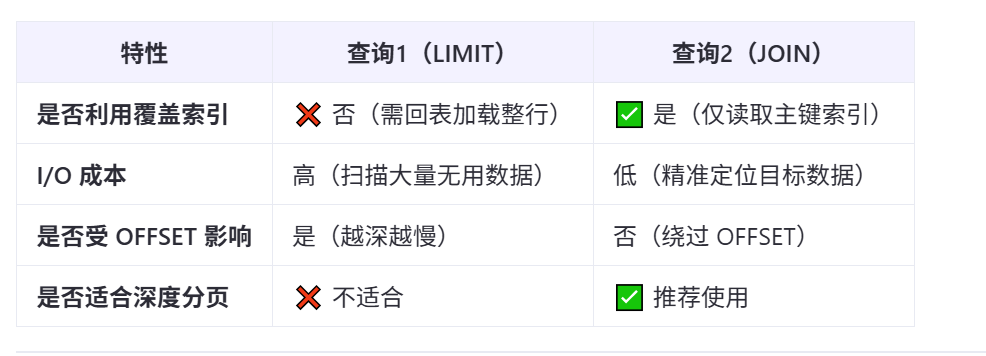
1慢的主要原因
在向下遍历,排序中。 每遍历一行都需要从磁盘或内存读取完整的行数据(包含所有字段),即使这些数据最终会被丢弃。
查询2中
子查询:先通过反向扫描(或主键索引)获取第 2100000-2100100行的 id。 (在这一操作中, 只需缓存这些数据的id-在聚簇索引的叶子节点精确定位id,而不是全量数据,减少了io操作)
外层查询:通过主键 id 快速定位这 10 条记录的完整数据。


















 605
605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









