







project2上
Task1
1 总体介绍
要求实现三种PageGuard类,分别是BasicPageGuard、ReadPageGuard和WritePageGuard,防止用户遗漏调用Unpin方法导致缓冲页被固定无法驱逐,与智能指针相似,当PageGuard对象生命周期结束时,在析构函数中调用Unpin方法来确保释放缓冲页;进一步的,ReadPageGuard和WritePageGuard还会保护缓存页的读写一致性,且避免死锁(若其他时候后忘记解锁,则在析构时解锁)。当然,PageGuard类也要对外提供方法用于手动释放。实现Task1中的类会为后面Task3的可扩展哈希做铺垫。
具体函数:(cmu里的)
对BasicPageGuard、ReadPageGuard和WritePageGuard实现以下函数:
PageGuard(PageGuard &&that):移动构造函数。
operator=(PageGuard &&that):移动赋值运算符。
Drop():解除固定和/或释放锁。
~PageGuard():析构函数。
为BasicPageGuard实现以下升级函数。这些函数需要保证在升级过程中,受保护的页面不会被从缓冲池中逐出。(这个写完好像没用,不写也能跑通)
UpgradeRead():升级为ReadPageGuard
UpgradeWrite():升级为WritePageGuard
使用新的page guard,在BufferPoolManager中实现以下包装函数:
FetchPageBasic(page_id_t page_id)
FetchPageRead(page_id_t page_id)
FetchPageWrite(page_id_t page_id)
NewPageGuarded(page_id_t *page_id)
2 头文件(page_guard.h)
里面注释写的挺好,功能实现按注释写
需要用到的变量是,BasicPageGuard类里是
private:
friend class ReadPageGuard;
friend class WritePageGuard;
BufferPoolManager *bpm_{nullptr};
Page *page_{nullptr};
bool is_dirty_{false};
ReadPageGuard和WritePageGuard里是
BasicPageGuard guard_
注意:
1、在写移动赋值函数的时候,要先清空里面的【Drop();】 再往里放,不然内存会冲突;
2、返回ReadPageGuard或者WritePageGuard之前需要先加RLatch或WLatch。
3 代码
page_guard.cpp
// noexcept表示该函数不会抛出异常
// 新的守卫对象的行为与原来的守卫对象完全相同
BasicPageGuard::BasicPageGuard(BasicPageGuard &&that) noexcept {
bpm_ = that.bpm_;
page_ = that.page_;
that.page_ = nullptr;
that.bpm_ = nullptr;
this->is_dirty_ = that.is_dirty_;
}
// 释放页面守卫应清除所有内容
void BasicPageGuard::Drop() {
if (bpm_ != nullptr && page_ != nullptr) {
bpm_->UnpinPage(page_->GetPageId(), is_dirty_);
}
bpm_ = nullptr;
page_ = nullptr;
}
// 移动赋值函数
auto BasicPageGuard::operator=(BasicPageGuard &&that) noexcept -> BasicPageGuard & {
// 释放this当前持有的资源
Drop();
bpm_ = that.bpm_;
page_ = that.page_;
that.page_ = nullptr;
that.bpm_ = nullptr;
this->is_dirty_ = that.is_dirty_;
return *this;
}
BasicPageGuard::~BasicPageGuard(){ Drop(); } // NOLINT
auto BasicPageGuard::UpgradeRead() -> ReadPageGuard {
if (page_ != nullptr) {
page_->RLatch();
}
auto read_page_guard = ReadPageGuard(bpm_, page_);
bpm_ = nullptr;
page_ = nullptr;
return read_page_guard;
}
auto BasicPageGuard::UpgradeWrite() -> WritePageGuard {
if (page_ != nullptr) {
page_->WLatch();
}
auto write_page_guard = WritePageGuard(bpm_, page_);
bpm_ = nullptr;
page_ = nullptr;
return write_page_guard;
}; // NOLINT
// ReadPageGuard 的移动构造函数 和BasicPageGuard很像
ReadPageGuard::ReadPageGuard(ReadPageGuard &&that) noexcept {
guard_ = std::move(that.guard_);
}
auto ReadPageGuard::operator=(ReadPageGuard &&that) noexcept -> ReadPageGuard & {
//Drop一定要加!要把里面的删掉,新的才能往里放
Drop();
guard_ = std::move(that.guard_);
return *this;
}
void ReadPageGuard::Drop() {
if (guard_.page_ != nullptr) {
guard_.page_->RUnlatch();
}
guard_.Drop();
}
ReadPageGuard::~ReadPageGuard() { Drop(); } // NOLINT
WritePageGuard::WritePageGuard(WritePageGuard &&that) noexcept {
guard_ = std::move(that.guard_);
}
auto WritePageGuard::operator=(WritePageGuard &&that) noexcept -> WritePageGuard & {
Drop();
guard_ = std::move(that.guard_);
return *this;
}
void WritePageGuard::Drop() {
if (guard_.page_ != nullptr) {
guard_.page_->WUnlatch();
}
guard_.is_dirty_ = true;
guard_.Drop();
}
WritePageGuard::~WritePageGuard() { Drop(); } // NOLINT
buffer_pool_manager
auto BufferPoolManager::FetchPageBasic(page_id_t page_id) -> BasicPageGuard {
auto page = FetchPage(page_id);
return {this, page};
}
auto BufferPoolManager::FetchPageRead(page_id_t page_id) -> ReadPageGuard { auto page = FetchPage(page_id);
if (page != nullptr) {
page->RLatch();
}
return {this, page};
}
auto BufferPoolManager::FetchPageWrite(page_id_t page_id) -> WritePageGuard { auto page = FetchPage(page_id);
if (page != nullptr) {
page->WLatch();
}
return {this, page};
}
auto BufferPoolManager::NewPageGuarded(page_id_t *page_id) -> BasicPageGuard { auto page = NewPage(page_id);
return {this, page};
}
Task2 Extendible Hash Table Pages
1 总体要求
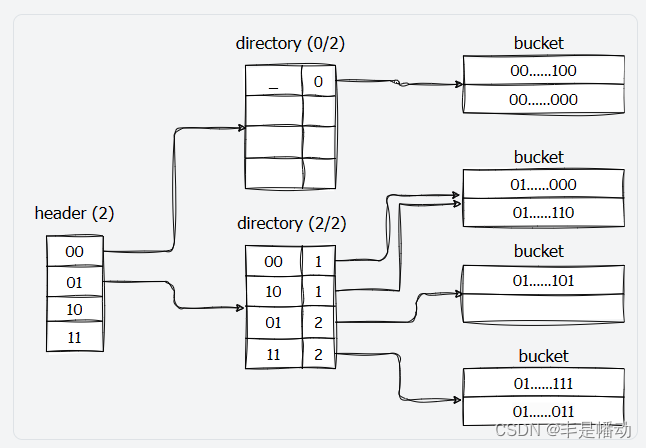
要求实现三种可扩展哈希中使用的数据结构,也就是三层结构中每一层的页面布局。分别是HeaderPage、DirectoryPage和BucketPage,如下图:
注意:在实现 Task2 的时候,对于接口的使用可以不懂,只要知道这是个三级的数据结构就行了,其余的会在后面 Task 中被使用。因此只需要按照注释实现不同接口,通过测试即可。我写出来的都是对注释的简单翻译,可以作为参考。
第一级是header采用hash值的高位决定将key-value插入到哪个directory,第二级是dierctory,第二级采用hash值的低位决定将key-value插入到哪个bucket,最后找到bucket后将key-value插入。
大体如图所示,后面还会详细说。
2 Hash Table Header Page
2.1变量名和方法含义
| 变量名 | 含义 |
|---|---|
| directory_page_id[] | 第二层DirectoryPage的PageId数组 |
| max_depth_ | 位深度x,PageId数组的大小为 2^x |
| 方法名 | 含义 |
|---|---|
| Init | 初始化数组 |
| HashToDirectoryIndex | 获取该键哈希对应的目录索引,如位深度为2,32位哈希值为0x5f129982,最高有效位前2位为01,应该返回01 |
| GetDirectoryPageId | 获取在指定索引处(directory_page_ids_[directory_idx])的值 |
| SetDirectoryPageId | 设置directory page_id在指定索引处的值 |
| MaxSize | 获取页头可处理的最大目录页ID数(2^max_depth) |
2.2代码
void ExtendibleHTableHeaderPage::Init(uint32_t max_depth) {
this->max_depth_ = max_depth;
// 初始化目录页ID数组,将所有值设为无效ID
auto size = MaxSize();
for (uint32_t i = 0; i < size; ++i) {
directory_page_ids_[i] = INVALID_PAGE_ID;
}
}
auto ExtendibleHTableHeaderPage::HashToDirectoryIndex(uint32_t hash) const -> uint32_t {
if (this->max_depth_ == 0) {
return 0;
}
// 将hash右移(32 - this->max_depth_)位,丢弃哈希值的低this->max_depth_位,保留高位的部分。
return hash >> (sizeof(uint32_t) * 8 - this->max_depth_);
}
auto ExtendibleHTableHeaderPage::GetDirectoryPageId(uint32_t directory_idx) const -> uint32_t {
if (directory_idx >= this->MaxSize()) {
return INVALID_PAGE_ID;
}
return this->directory_page_ids_[directory_idx];
}
void ExtendibleHTableHeaderPage::SetDirectoryPageId(uint32_t directory_idx, page_id_t directory_page_id) {
if(directory_idx >= this->MaxSize()){
return;
}
directory_page_ids_[directory_idx] = directory_page_id;
}
auto ExtendibleHTableHeaderPage::MaxSize() const -> uint32_t {
//用了移位运算符 << 来计算 2^max_depth_,对于任何整数 x,1 << x 的结果是 2^x。
return 1 << this->max_depth_;
}
3 Hash Table Directory Page
3.1变量名和方法含义
全局深度(Global Depth)表示目录对桶进行分类的位数。它决定了在查找过程中使用的哈希值的位数。例如,如果全局深度为2,那么就会使用哈希值的高(或低)2位来作为索引(这里用的是后几位做全局深度位),将记录分配到不同的桶中。
局部深度(Local Depth)代表了特定桶中记录所使用的哈希值的位数。在某些情况下,不是所有的桶都会使用全局深度的全部位数。局部深度可以在桶分裂或目录扩展时进行调整,以确保数据的均匀分布和高效查找。
| 变量名 | 含义 |
|---|---|
| max_depth_ | 页头可以处理的最大深度 |
| global_depth_ | 当前目录的全局深度 |
| local_depths_ | 一个桶局部深度的数组 |
| bucket_page_id | 包含第三层的BucketPage的PageId数组 |
| 方法名 | 含义 |
|---|---|
| Init | 初始化数组 |
| HashToBucketIndex | 获取键对应的哈希桶索引 |
| GetBucketPageId | 获取在指定索引处(bucket_page_ids_[bucket_idx])的值 |
| SetBucketPageId | 设置bucket_page_id在指定索引处的值 |
| GetSplitImageIndex | 分裂桶,并返回新的桶索引 |
| GetGlobalDepthMask() | DirectoryIndex = Hash(key) & GLOBAL_DEPTH_MASK其中,GLOBAL_DEPTH_MASK 是一个从最低有效位开始恰好有 GLOBAL_DEPTH 个1的掩码。例如,在32位表示中,全局深度3对应于0x00000007。return 由 global_depth 个1(从最低有效位开始)和其余为0组成的掩码(.h文件定义了但.cpp文件里没有要自己写) |
| GetLocalDepthMask(uint32_t bucket_idx) | 与全局深度掩码类似,只不过它使用的是位于 bucket_idx 的桶的局部深度(.cpp文件里没有要自己写) |
| GetGlobalDepth() | 获得当前目录的全局深度 |
| IncrGlobalDepth | 目录全局深度加一 |
| DecrGlobalDepth | 目录全局深度减一 |
| CanShrink() | 如果目录可以收缩(即可以减少全局深度)返回true |
| Size() | 返回目录全局深度的大小 |
| GetLocalDepth(uint32_t bucket_idx) | 获得固定桶(bucket_idx)的局部深度 |
| SetLocalDepth(uint32_t bucket_idx, uint8_t local_depth) | 设置固定桶(bucket_idx)的局部深度 |
| IncrLocalDepth(uint32_t bucket_idx) | bucket_idx 的桶的局部深度加一 |
| DecrLocalDepth(uint32_t bucket_idx) | bucket_idx 的桶的局部深度减一 |
3.2 GetSplitImageIndex详解
功能:获取某个 bucket_idx 所对应的下一个可分裂 bucket_idx
用这个图来详细解释一下可扩展哈希
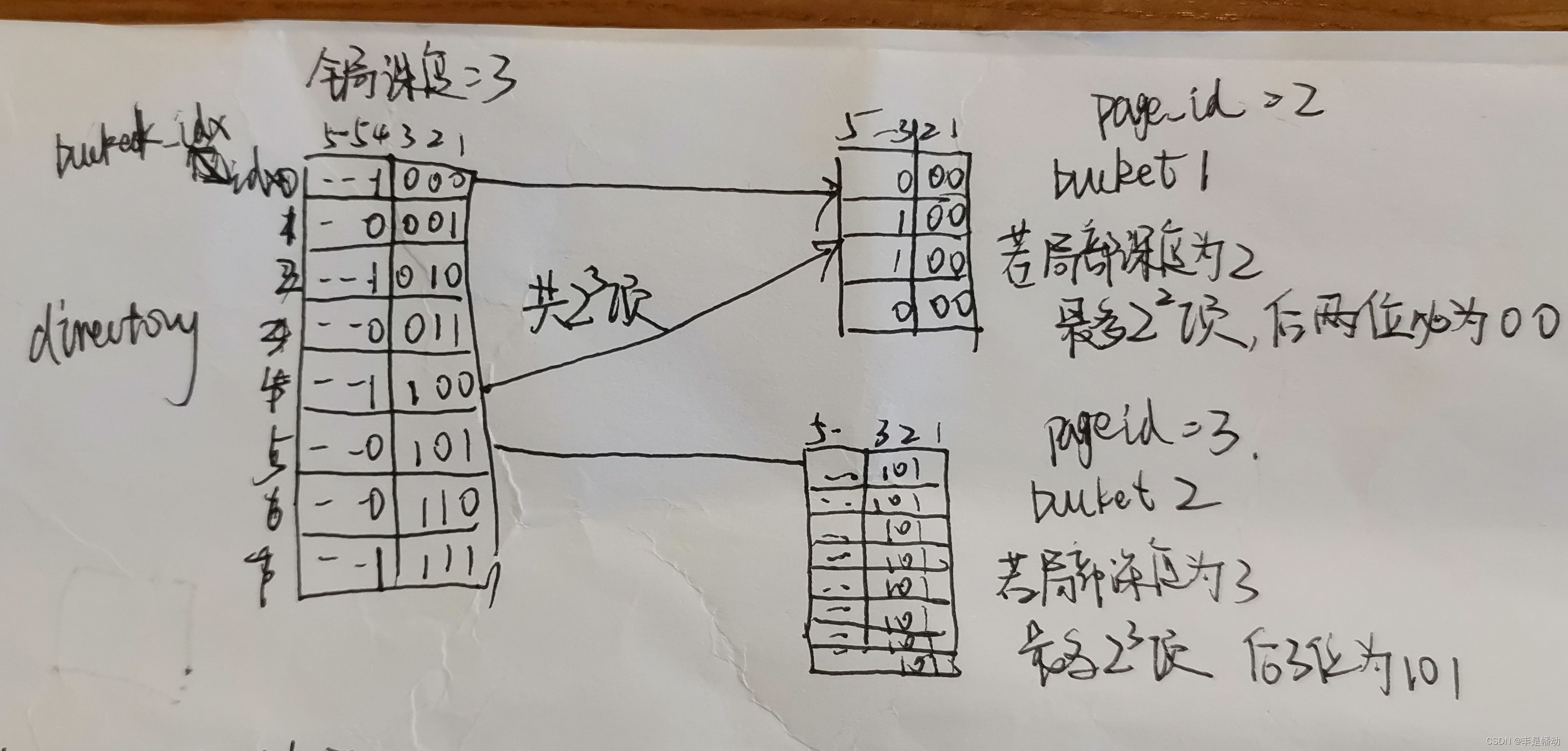
directory全局深度为3。即每个数通过倒数三位的不同进行区分,找自己对应的目录项。如果两个数都在一个目录项里,那么他俩后面三位都是一样的,比如011000和110000,对应的都是第一个目录项;
bucket1的局部深度为2,就是只要两个数都在一个桶里,后面2位都是一样的,比如还有一个数011100,虽然和011000不是一个目录项,但它俩在一个桶里。就是说一个目录项只能对应一个桶,但一个桶可以有好几个目录项。
要求是全局深度>=局部深度,假如桶2都满了需要分裂桶(分裂也就是增加局部深度)。我们要
1、增加全局深度,全局深度变为4
2、获得新桶的idx------>GetSplitImageIndex函数要干的
原桶对应的是idx=5->(101),这个桶应该分裂成0101和1101,idx分别为5和13
13就是5+2的三次方所以新桶idx为:原桶索引 + 2的原本全局深度次方
auto ExtendibleHTableDirectoryPage::GetSplitImageIndex(uint32_t bucket_idx) const -> uint32_t {
return bucket_idx + (1 << (global_depth_ - 1));
}
3.3代码
void ExtendibleHTableDirectoryPage::Init(uint32_t max_depth) {
this->max_depth_ = max_depth;
global_depth_ = 0;
// 初始化目录页ID数组,将所有值设为无效ID
std::fill(local_depths_, local_depths_ + (1 << max_depth), 0);
std::fill(bucket_page_ids_, bucket_page_ids_ + (1 << max_depth), INVALID_PAGE_ID);
}
auto ExtendibleHTableDirectoryPage::HashToBucketIndex(uint32_t hash) const -> uint32_t {
// 返回hash的后global_depth位
return hash & GetGlobalDepthMask();
}
auto ExtendibleHTableDirectoryPage::GetBucketPageId(uint32_t bucket_idx) const -> page_id_t {
return this->bucket_page_ids_[bucket_idx];
}
void ExtendibleHTableDirectoryPage::SetBucketPageId(uint32_t bucket_idx, page_id_t bucket_page_id) {
this->bucket_page_ids_[bucket_idx] = bucket_page_id;
}
auto ExtendibleHTableDirectoryPage::GetSplitImageIndex(uint32_t bucket_idx) const -> uint32_t {
return bucket_idx + (1 << (global_depth_ - 1));
}
// 计算掩码,全局深度位的低位是 1,其余位是 0
auto ExtendibleHTableDirectoryPage::GetGlobalDepthMask() const -> uint32_t {
// 例如,如果全局深度为 2,则掩码是二进制的 11(即十进制的 3)
auto depth = global_depth_;
uint32_t result = (1 << depth) - 1;
return result;
}
auto ExtendibleHTableDirectoryPage::GetLocalDepthMask(uint32_t bucket_idx) const -> uint32_t {
// 首先检查 bucket_idx 是否有效
if (bucket_idx >= static_cast<uint32_t>(1 << global_depth_)) {
throw std::out_of_range("Bucket index out of range");
}
// 获取 bucket_idx 处的局部深度
uint32_t local_depth = local_depths_[bucket_idx];
// 计算掩码,局部深度位的低位是 1,其余位是 0
return 1 << (local_depth - 1);
}
auto ExtendibleHTableDirectoryPage::GetGlobalDepth() const -> uint32_t { return global_depth_; }
void ExtendibleHTableDirectoryPage::IncrGlobalDepth() {
if (global_depth_ >= max_depth_) {
return;
}
for (int i = 0; i < 1 << global_depth_; i++) {
bucket_page_ids_[(1 << global_depth_) + i] = bucket_page_ids_[i];
local_depths_[(1 << global_depth_) + i] = local_depths_[i];
}
global_depth_++;
}
void ExtendibleHTableDirectoryPage::DecrGlobalDepth() {
if (global_depth_ <= 0) {
return;
}
global_depth_--;
}
auto ExtendibleHTableDirectoryPage::CanShrink() -> bool { // 如果全局深度为0,则不能再收缩
if (global_depth_ == 0) {
return false;
}
// 检查所有桶的局部深度是否都小于全局深度
for (uint32_t i = 0; i < Size(); i++) {
// 有局部深度等于全局深度的->不能收缩
if (local_depths_[i] == global_depth_) {
return false;
}
}
return true;
}
auto ExtendibleHTableDirectoryPage::Size() const -> uint32_t {
// 目录的当前大小是2的global_depth_次方
return 1 << global_depth_;
}
auto ExtendibleHTableDirectoryPage::GetLocalDepth(uint32_t bucket_idx) const -> uint32_t {
return local_depths_[bucket_idx];
}
auto ExtendibleHTableDirectoryPage::GetMaxDepth() const -> uint32_t { return max_depth_; }
void ExtendibleHTableDirectoryPage::SetLocalDepth(uint32_t bucket_idx, uint8_t local_depth) {
local_depths_[bucket_idx] = local_depth;
}
void ExtendibleHTableDirectoryPage::IncrLocalDepth(uint32_t bucket_idx) {
if (local_depths_[bucket_idx] < global_depth_) {
++local_depths_[bucket_idx];
}
}
void ExtendibleHTableDirectoryPage::DecrLocalDepth(uint32_t bucket_idx) {
if (local_depths_[bucket_idx] > 0) {
--local_depths_[bucket_idx];
}
}
4 Hash Table Bucket Page
4.1变量名和方法含义
| 变量名 | 含义 |
|---|---|
| size_ | 桶中已存储的键值对数量 |
| max_size_ | 桶可以处理的键值对的最大数量 |
| array_[] | 一个桶本地深度的数组 |
| 方法名 | 含义 |
|---|---|
| Init | 初始化数组 |
| Lookup(const KeyType &key, ValueType &value, const KeyComparator &cmp) | 查找key,如果找到了把key(array[i],first)对应的值(array[i].second)赋给value,返回true |
| Insert(const KeyType &key, const ValueType &value, const KeyComparator &cmp) | 插入一个键值对 |
| Remove(const KeyType &key, const KeyComparator &cmp) | 删除一个键值对 |
| EntryAt(uint32_t bucket_idx) | 获取桶中指定索引处的键值对[key,value] |
| KeyAt(uint32_t bucket_idx) | 获得bucket_idx对应的key |
| ValueAt(uint32_t bucket_idx) | 获得bucket_idx对应的value |
| Size() | 桶里有几个键值对 |
| IsFull() | 桶是否满了 |
| IsEmpty() | 桶是否为空 |
4.2代码
template <typename K, typename V, typename KC>
void ExtendibleHTableBucketPage<K, V, KC>::Init(uint32_t max_size) {
this->max_size_ = max_size;
this->size_ = 0;
}
template <typename K, typename V, typename KC>
auto ExtendibleHTableBucketPage<K, V, KC>::Lookup(const K &key, V &value, const KC &cmp) const -> bool {
for (uint32_t i = 0; i < size_; ++i) {
if (cmp(array_[i].first, key) == 0) {
value = array_[i].second;
return true;
}
}
return false;
}
template <typename K, typename V, typename KC>
auto ExtendibleHTableBucketPage<K, V, KC>::Insert(const K &key, const V &value, const KC &cmp) -> bool {
if (this->IsFull()) {
return false;
}
for (uint32_t i = 0; i < size_; ++i) {
if (cmp(this->array_[i].first, key) == 0) {
return false;
}
}
array_[size_++] = std::make_pair(key, value);
return true;
}
template <typename K, typename V, typename KC>
auto ExtendibleHTableBucketPage<K, V, KC>::Remove(const K &key, const KC &cmp) -> bool {
for (uint32_t i = 0; i < size_; ++i) {
if (cmp(array_[i].first, key) == 0) {
// 找到键并删除
for (uint32_t j = i + 1; j < size_; ++j) {
array_[j - 1] = array_[j];
}
size_--;
return true;
}
}
return false;
}
template <typename K, typename V, typename KC>
void ExtendibleHTableBucketPage<K, V, KC>::RemoveAt(uint32_t bucket_idx) {
for (uint32_t i = bucket_idx; i <= size_; ++i) {
array_[i] = array_[i + 1];
}
size_--;
}
template <typename K, typename V, typename KC>
auto ExtendibleHTableBucketPage<K, V, KC>::KeyAt(uint32_t bucket_idx) const -> K {
return EntryAt(bucket_idx).first;
}
template <typename K, typename V, typename KC>
auto ExtendibleHTableBucketPage<K, V, KC>::ValueAt(uint32_t bucket_idx) const -> V {
return EntryAt(bucket_idx).second;
}
template <typename K, typename V, typename KC>
auto ExtendibleHTableBucketPage<K, V, KC>::EntryAt(uint32_t bucket_idx) const -> const std::pair<K, V> & {
return array_[bucket_idx];
}
template <typename K, typename V, typename KC>
auto ExtendibleHTableBucketPage<K, V, KC>::Size() const -> uint32_t {
return this->size_;
}
template <typename K, typename V, typename KC>
auto ExtendibleHTableBucketPage<K, V, KC>::IsFull() const -> bool {
return this->size_ == this->max_size_;
}
template <typename K, typename V, typename KC>
auto ExtendibleHTableBucketPage<K, V, KC>::IsEmpty() const -> bool {
return this->size_ == 0;
}
参考文章
[1]https://blog.csdn.net/cpp_juruo/article/details/134859050?spm=1001.2014.3001.5506 (【CMU 15-445】Proj2 Hash Index)
[2]https://blog.csdn.net/qq_58887972/article/details/137065392?spm=1001.2014.3001.5502(cmu15445 2023fall project2)
[3]https://blog.csdn.net/p942005405/article/details/84644069(c++ 之 std::move 原理实现与用法总结)
[4]https://zhuanlan.zhihu.com/p/679864158(CMU15-445 2023 Fall Project#2 - Extensible Hash Index)
[5]https://zhuanlan.zhihu.com/p/622221722?utm_campaign=&utm_medium=social&utm_psn=1758461816148398080&utm_source=qq(CMU 15-445 P1 Extendible Hash Table 可扩展哈希详细理解)
[6]https://blog.csdn.net/MarksSa/article/details/135646298?spm=1001.2014.3001.5502([15-445 fall 2023] P2代码解析)
[7]https://zhuanlan.zhihu.com/p/686889091(CMU 15445 2023fall Project2)
[8]https://zhuanlan.zhihu.com/p/690666760(CMU 15-445 Bustub 2023-Fall Project 2 Extendible Hash Index 思路分享)
[9]https://zhuanlan.zhihu.com/p/664444839(CMU15-445(2023FALL)-Project#2: Extendible Hash Index)















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









