







来源:《算法》第四版 第五章
1、暴力字符匹配算法
public static int search(String pt, String txt){
int j, M = pat.length();
int i, N = txt.length();
for(i = 0, j = 0; i < N && j < M; i++){
if(txt.charAt(i) == pat.charAt(j)) j++;
else{ i -= j; j = 0;}
}
if(j == M) return i - M; //找到匹配
else return N; //未找到匹配
}
可以看到,第6句,每次匹配失败的时候,i 就会回退一些。这样在最坏的情况下,就造成了效率的低下。所以,我们不希望每一次 i 都回退到上一次匹配的开头,我们希望可以利用我们已经使用过的信息来完成回退的减少。
2、DFA考虑回退
和大多数的教程不同,大多数的教程是用 next[] 数组来运算和记录它的会退,而《算法》中,采用了更好理解的 DFA(deterministic finite automation,确定有限状态自动机),比如对于 pattern字串“ABABAC”,根据这个字串就能确认它所对应的自动机:
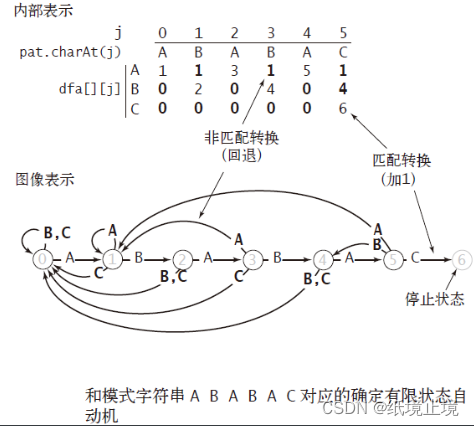
同时,它的 dfa[][] 也能很快的确定下来了,那根据我们画出的 自动状态机,我们去匹配各个字符串,以及清楚的知道它们的回退机制之后,我们就能很快的在 text字串 中开始O(N+M)复杂度的匹配了。
dfa[][] 第一个 [] 中填充的是,i 所指的字符在字母表中的序号,第二个 [] 是 j ,也就是 pattern 中的第几个字符。在这个例子中,pattern的长度为6,也就是当 j 达到 6 的时候就已经是 自动状态机的停止状态了。
3、构造DFA
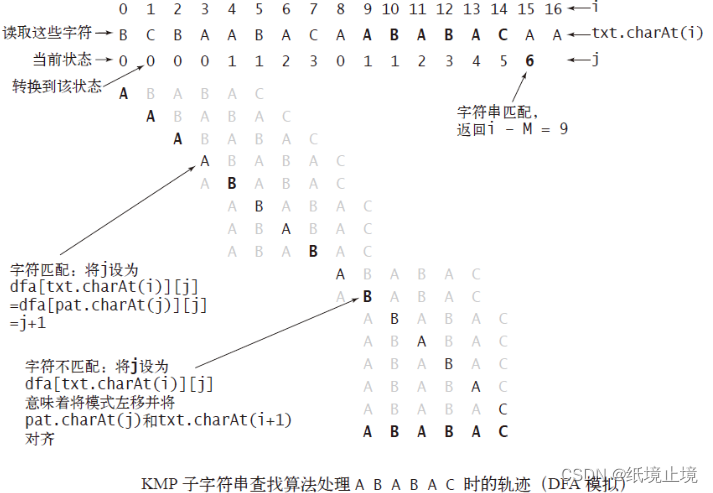
当我们在匹配 i 指针 和 j 指针的字符的失败的时候,i 指针每次依然在前进,j 指针所执行的操作不像是回退,而更像是 状态自动机 中的状态重置。
所以,我们现在只考虑它的重启状态:我们在扫描当前的 字符的值 的之前,就已经可以通过之前的已知信息来知道:如果它失败了,它应当回退到什么位置去。
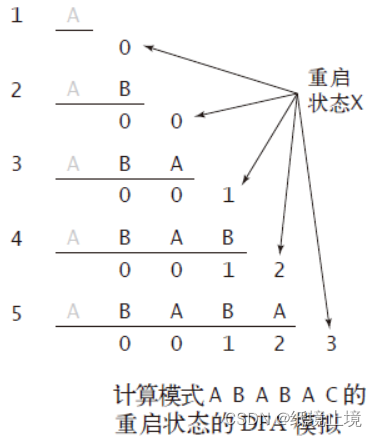
我们在以下的构造流程中,可以清楚的看到,模板 X 的走向会因为输入的变化而变化。
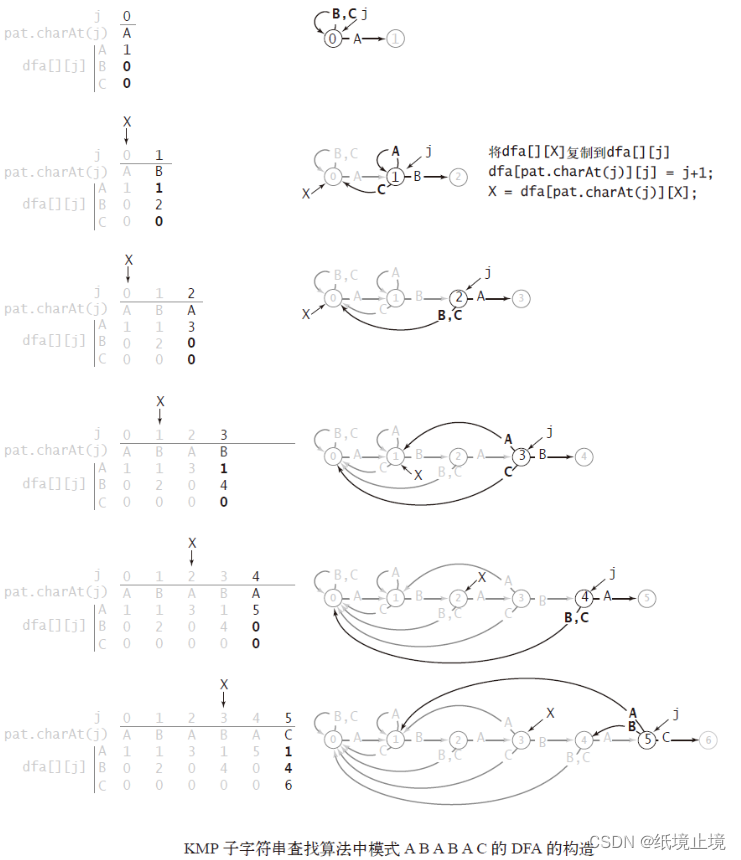
构造出来的感觉就比较像是 KMP中的next[]数组。它的构造过程就分为 3 个步骤:
① 将
dfa[][X]复制到dfa[][j](对于匹配失败的情况);
② 将dfa[pat.charAt(j)][j]设为j+1(对于匹配成功的情况);
③ 更新X。
dfa[pat.charAt(0)][0] = 1;
for(int X = 0,j = 1; j < M; j++){
for(int c = 0; c < R; c++){
dfa[c][j] = dfa[c][X];
}
dfa[pat.charAt(j)][j] = j + 1;
X = dfa[pat.charAt(j)][X];
}















 4038
4038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









