







目录
0.0 前言
树 是非线性结构
线性 VS 非线性 参见:
https://blog.csdn.net/qq_40893824/article/details/105028928 1 线性结构 VS 非线性结构
0.1 联系
二叉树很重要!
| 分类 | 遍历 |
|---|---|
| 二叉树 | 3 个递归遍历 3 个非递归遍历(栈) 1 个层次遍历(队列,非递归) 分别是前、中、后序遍历 + 层次遍历 |
| 树 和 森林 | 先序、后序遍历 先序两个一样 后序:树是真 后序 森林是真 中序! |
| 为方便 非递归遍历,有了 前、中、后序线索化二叉树 |
1 基本概念
1.1 基本概念
| 术语 | 解释 |
|---|---|
| 结点 | 数据元素 + 指针(可能不止2个) |
| 叶子结点 终端结点 | 它的子树为0 |
| 非终端结点 分支结点 | 它的子树不为0 |
| ----------- | ---------------------------- |
| 结点的度 | 它的子树个数 |
| 树的度 | 结点度的 最大值 |
| 层次 | 从1开始 = 从根结点开始 |
| 路径长度 ---------------------- 区别哈夫曼树的路径长度!见4 哈夫曼树 | 包括首位结点 a→b→c,路径是 3---------------------- 结点 a 到 结点 b 的路径上 线段个数a→b→c,2 个线段,故 a 到 c 的路径长度是 2 |
| 结点的深度 | 根结点 到 该结点的路径上 结点的个数 |
| 结点的高度 | 该结点 到叶子结点的 最长路径 |
| 树的高度 深度 | 层次的 最大值 = 根结点的高度 |
| -------------- | ----------------------------- |
| 孩子 | 结点的全部子树 |
| 子孙 | 以该结点为根 的子树的 所有结点(自己除外) |
| 双亲 | 孩子的相反 该结点 上一层次 对应的结点 |
| 兄弟 | 双亲一样 |
| 堂兄弟 | 双亲层次一样 |
| 祖先 | 该结点 到 根结点 路径上 除自己外 的所有结点 |
| ---------- | ---------------- |
| 有序树 | 有次序,不能交换 |
| 无序树 | 无顺序,可任意交换 |
| 丰满树 理想平衡树 | 除了底层,其它层次都是满的 |
| 森林 | 不相交的树 的集合 |
1.2 存储结构
1 顺序存储
2 链式存储
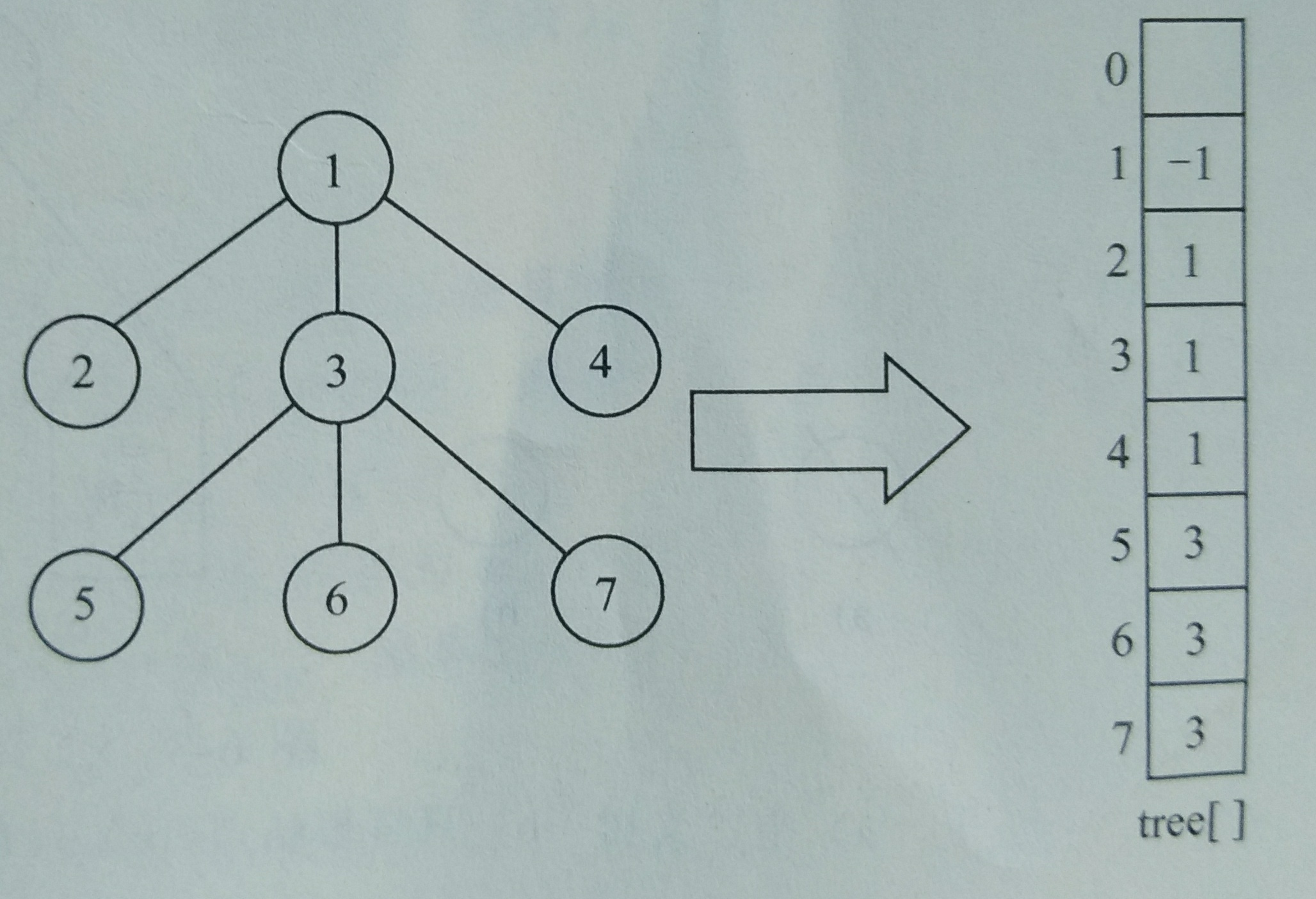
1.2.1 顺序存储 - 双亲表示法 ( 双亲存储结构 )
一位数组即可
数组每个元素保存 该结点双亲的位置
1.2.2 链式存储 - 2 种
1 孩子表示法 ( 孩子存储结构 )
2 孩子兄弟表示法 ( 孩子兄弟存储结构 )
2 二叉树
2.1 条件
- 结点最多 2 个子树,即:结点的度 最大为 2
- 子树有左右顺序,不能颠倒
2.2 5 个状态 + 2 个特殊树
| 序号 | 情况 | 图 |
|---|---|---|
| 1 | 空二叉树 |  |
| 2 | 只有根结点 |  |
| 3 | 只有左子树 |  |
| 4 | 只有右子树 |  |
| 5 | 左右子树都有 | 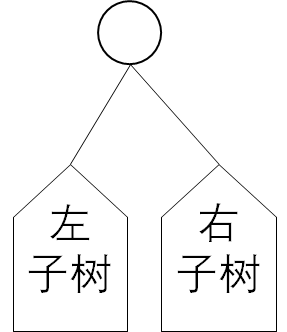 |
| 满二叉树 | 非终端结点(分支结点)都有 左孩子 和 右孩子 且 叶子结点在 最下一层 | 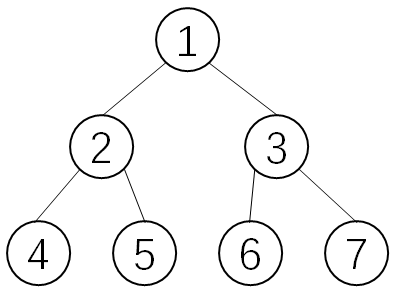 |
|---|---|---|
| 完全二叉树 | 是满二叉树 从右至左、从下向上 依次删除结点得到的 | 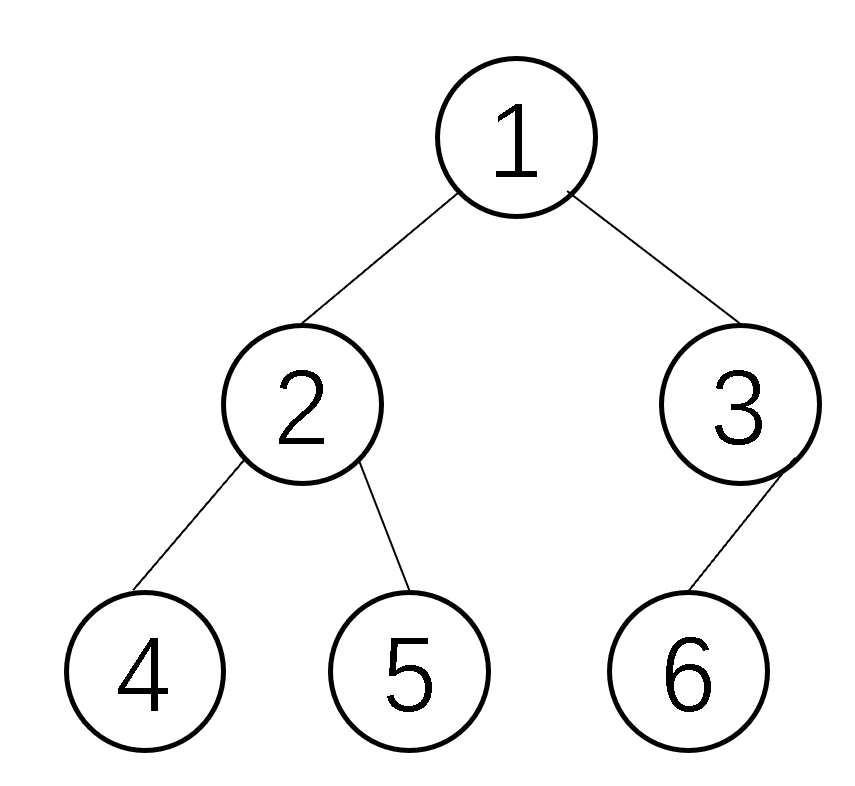 |
2.3 5 个性质 + 1个公式
单分支 = 只有 1 个子树
双分支 = 有 2 个子树
叶子结点数 n0
单分支数 n1
双分支数 n2
| 序号 | 结论 | 过程推导 |
|---|---|---|
| 1 | 非空二叉树的叶子结点数 = 双分支数 + 1 | 总结点数 = n0 + n1 + n2 总分支数 = n1 + 2n2 任何结点都有分支 指向它,跟结点除外! 总结点数 - 1 = 总分支数 n0 + n1 + n2 - 1 = n1 + 2n2 n0 - 1 = n2 扩展 ( 度为 m 的树 ):总结点数 - 1 = 总分支数 n0 + n1 + n2 + … + nm - 1 = n1 + 2n2 + … + mnm 即:n0 = 1 + n2 + 2n3 + … + (m - 1)nm |
| 2 | 二叉树的第 i 层最多 2(i-1) 个结点i ≥ 1 ! | 证明略 |
| 3 | 高度为 k 的二叉树结点最多 2k - 1 个即: 满二叉树前 k 层的结点数是 2k - 1 | k 层 满二叉树是对应 其他二叉树 结点最多的状态 1 + 21 + 22 + … + 2k-1 = 1 − 2 k 1 − 2 \frac{1 - 2^k}{1 - 2} 1−21−2k = 2k - 1 |
| 4 | 有 n 个结点的完全二叉树,从上到下、从右往右 依次编号,从 1 开始① 编号 i ≠ 1的结点的 双亲的编号是 ⌊i/2⌋(向下取整,⌊2/2⌋ = ⌊3/2⌋ = 1) ② 编号 i 的结点: 若 2i ≤ n,则 2i 是它的左孩子的编号,否则 它没有左孩子,同时 更不可能有右孩子 若 (2i + 1) ≤ n,则 (2i + 1)是它右孩子的编号,则否 它没有右孩子 若编号 从 0 开始简单说,编号 i 的结点 它的双亲编号是 ⌊(i - 1)/2⌋(向下取整) = ⌈ i / 2 ⌉-1 ( i ≠ 0 ) (向上取整) 若存在左孩子,其编号 2i + 1 若存在右孩子,其编号 2i + 2 | 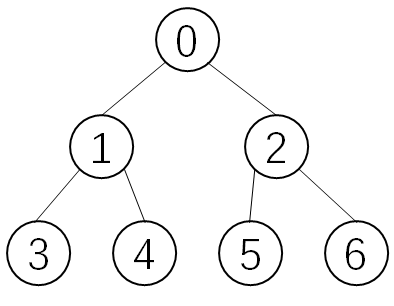 |
| 5 | 有 n 个结点的完全二叉树 的高度(或深度)是 ⌊ log2n ⌋ + 1或 ⌈ log2(n+1) ⌉ | 设 h 是其高度(深度) 2h-1 - 1 < n ≤ 2h - 1 2h-1 ≤ n < 2h h - 1 ≤ log2n < h h - 1 = ⌊ log2n ⌋ h = ⌊ log2n ⌋ + 1 2h-1 - 1 < n ≤ 2h - 1 2h-1 < n + 1 ≤ 2h h - 1 < log2(n+1) ≤ h h = ⌈ log2(n+1) ⌉ |
| 1 | n 个结点的二叉树,有h(n)种h(n) = C 2 n n n + 1 \frac{C^n_{2n}}{n + 1} n+1C2nn | 类似栈的 入栈顺序排列数,证明在下面 |
不严格 - 证明:
思路来源:https://www.zhihu.com/search?type=content&q=卡特兰数
n 个结点出入栈,每个结点 有入出栈 2 种选择,一共 2n 个选择
每个结点入栈前,前面的结点可能出栈
简化模型,入栈是 +1,出栈是 -1,n 个+1 和 n 个 -1 放在 2n 个位置,就是
C
2
n
n
C^n_{2n}
C2nn 种可能
但没完!
C
2
n
n
C^n_{2n}
C2nn 包含了 正确的摆法 和 错误的摆法
错误的摆法,最简单的是 先出栈 再入栈,n 个 -1 放前 n 个位置,n 个 +1 放后 n 个位置,很容易知道这是错误的摆法
2n 个位置,从位置 1 到 任意位置,其中的 +1 数量一定是 大于等于 -1 的数量的!若不是,那这个摆法就是错误的摆法
现在的目标是:找出错误摆法的特征,用数表示出来,再用
C
2
n
n
C^n_{2n}
C2nn 减去即可 ( 很容易想到 找出正确摆法的特征,用数表示出来,不是更简单?我没想出来… )
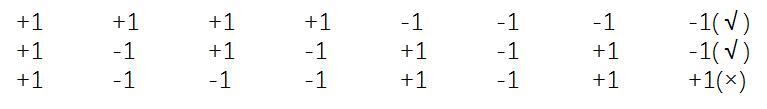
上图中,前 3 个顺序是错的
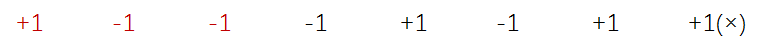
具体看,因为 前 3 个数中 +1 的个数是 1,-1 的个数是 2,1 ≤ 2,现在我把前 3 个数的正负号颠倒一下就变成
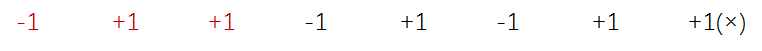
这对应这 错误的摆法 — 此时有 (n + 1) 个 +1 和 (n - 1)个 -1
很容易想到,所有错误的摆法,在经过刚刚的转换后都会变成 (n + 1) 个 +1 和 (n - 1)个 -1 的摆法,它们 一一对应!
( 刚刚的转换,一般的,就是从位置 1 向后面的位置依次检查 +1 和 -1 的数量,当 +1的数量 小于 -1 的数量时,就可以转换了 )
则错误的摆法数是
C
2
n
n
+
1
C^{n+1} _{2n}
C2nn+1
∴正确摆法数 =
C
2
n
n
C^n_{2n}
C2nn -
C
2
n
n
+
1
C^{n+1} _{2n}
C2nn+1
=
(
2
n
)
!
n
!
n
!
\frac{(2n)!}{n! n! }
n!n!(2n)! -
(
2
n
)
!
(
n
+
1
)
!
(
n
−
1
)
!
\frac{(2n)!}{(n+1)! (n-1)! }
(n+1)!(n−1)!(2n)!
=
(
2
n
)
!
(
n
+
1
)
(
n
+
1
)
!
n
!
\frac{(2n)!(n+1)}{(n+1)! n! }
(n+1)!n!(2n)!(n+1) -
(
2
n
)
!
n
(
n
+
1
)
!
(
n
−
1
)
!
n
\frac{(2n)!n}{(n+1)! (n-1)!n }
(n+1)!(n−1)!n(2n)!n
=
(
2
n
)
!
(
n
+
1
)
−
(
2
n
)
!
n
(
n
+
1
)
!
n
!
\frac{(2n)!(n+1)-(2n)!n}{(n+1)!n! }
(n+1)!n!(2n)!(n+1)−(2n)!n
=
(
2
n
)
!
(
n
+
1
)
!
n
!
\frac{(2n)!}{(n+1)!n! }
(n+1)!n!(2n)!=
(
2
n
)
!
(
n
+
1
)
n
!
n
!
\frac{(2n)!}{(n+1)n!n! }
(n+1)n!n!(2n)!=
1
(
n
+
1
)
\frac{1}{(n+1) }
(n+1)1
(
2
n
)
!
n
!
n
!
\frac{(2n)!}{n!n! }
n!n!(2n)!
=
C
2
n
n
n
+
1
\frac{C^n_{2n}}{n + 1}
n+1C2nn 即证
2.4 存储结构
1 顺序存储结构
2 链式存储结构
2.4.1 顺序存储结构
就是一维数组,略
2.4.2 链式存储
类似链表
typedef struct BNode
{
int data;
struct BNode *lchild, *rchild; // 分别是 左子树 和 右子树
}*BLink,BNode;
2.5 4 个遍历
1 先序、2 中序、3 后序 和 4 层次遍历
2.5.1 先序
结点→左子树→右子树
void preorder(BLink L)
{
if(L != NULL)
{
cout << L->data << " ";
preorder(L->lchild);
preorder(L->rchild);
}
}
2.5.2 中序
左子树→结点→右子树
void inorder(BLink L) // 中序遍历
{
if(L!=NULL)
{
inorder(L->lchild);
cout << L->data << " ";
inorder(L->rchild);
}
}
2.5.3 后序
左子树→右子树→结点
void postorder(BLink L)
{
if(L!=NULL)
{
postorder(L->lchild);
postorder(L->rchild);
cout << L->data << " ";
}
}
2.5.4 层次遍历
一层一层的遍历结点
用到了 循环队列!
根结点先入循环队列
循环队列出一个,输出其值,判断是否有左右子树,有的话就加入队列,一直循环到 循环队列为空 停止。
void level(BLink L)
{
int front,rear;
BLink p,que[num];
front = rear = 0;
if(L!=NULL)
{
rear = (rear+1)%num;
que[rear] = L;
while(front != rear)
{
front = (front + 1)%num;
p = que[front];
cout << p->data << " ";
if(p->lchild != NULL)
{
rear = (rear+1)%num;
que[rear] = p->lchild;
}
if(p->rchild != NULL)
{
rear = (rear+1)%num;
que[rear] = p->rchild;
}
}
}
}
注意
判断 结点是否为空
不是 if(L)
而是 if(L!=NULL)
因为结点没赋值前,其值一般是无意义的随机值
创建树
单独先说明:
先创建根结点,再创建左右子树
要随机生成 length 个结点,令 n 是已创建结点数,每次和 length 比较
左子树 创建 (length - 1)/2 个结点
右子树 创建 length - 1 - (length - 1)/2 个结点,不是 (length - 1)/2 个!
因为 (6-1)/2 = 2;6 - 1 - (6-1)/2 = 3!
注意:
在创建右子树 creatTree(L->rchild, t, length-1-(length-1)/2); 之前,t 要 t = 0!
若不这样做,此时 t ==(length - 1)/2!
这一点,在递归中的代码,就不用重新 t = 0!因为在递归中,系统会保留现场,当回到该现场时,数据会回复,这就用到了 栈 结构!
但现在这个代码是在递归之前用的,所以creatTree(L->rchild, t, length-1-(length-1)/2);前要手动 t = 0
void creatTree(BLink &L, int &n, int length)
{
if(n < length)
{
BLink p;
p = (BTNode *)calloc(1, sizeof(BTNode));
p->data = rand()%max;
L = p;
n++;
creatTree(L->lchild, n, length);
creatTree(L->rchild, n, length);
}
}
void creat(BLink &L)
{
int t,length = rand()%num;
cout << "随机生成 " << length << "个元素" << endl;
if(length > 0)
{
L = (BTNode *)calloc(1, sizeof(BTNode));
L->data = rand()%max;
t = 0;
creatTree(L->lchild, t, (length-1)/2);
t = 0;
creatTree(L->rchild, t, length-1-(length-1)/2);
cout << "创建成功!" << endl << endl;
}
else
{
L = NULL;
cout << "树为空!" << endl << endl;
}
}
2.5.5 测试代码
创建树 + 4 个遍历
#include<bits/stdc++.h>
#define num 100
#define max 1000
using namespace std;
typedef struct BNode
{
int data;
struct BNode *lchild, *rchild; // 分别是 左子树 和 右子树
}*BLink,BNode;
void creat(BLink &p);
void creatTree(BLink &L, int &n, int length);
void preorder(BLink L); // 前序遍历
void inorder(BLink L); // 中序遍历
void postorder(BLink L); // 后序遍历
void level(BLink L); // 层次遍历
int main()
{
srand(time(NULL));
BLink L;
creat(L);
cout << "先序遍历:" << endl;
preorder(L);
cout << endl << endl;
cout << "中序遍历:" << endl;
inorder(L);
cout << endl << endl;
cout << "后序遍历:" << endl;
postorder(L);
cout << endl << endl;
cout << "层次遍历:" << endl;
level(L);
cout << endl << endl;
system("pause");
return 0;
}
void creatTree(BLink &L, int &n, int length)
{
if(n < length)
{
BLink p;
p = (BNode *)calloc(1, sizeof(BNode));
p->data = rand()%max;
L = p;
n++;
creatTree(L->lchild, n, length);
creatTree(L->rchild, n, length);
}
}
void creat(BLink &L)
{
int t,length = rand()%num;
cout << "随机生成 " << length << "个元素" << endl;
if(length > 0)
{
L = (BNode *)calloc(1, sizeof(BNode));
L->data = rand()%max;
t = 0;
creatTree(L->lchild, t, (length-1)/2);
t = 0;
creatTree(L->rchild, t, length-1-(length-1)/2);
cout << "创建成功!" << endl << endl;
}
else
{
L = NULL;
cout << "树为空!" << endl << endl;
}
}
void preorder(BLink L) // 先序遍历
{
if(L != NULL)
{
cout << L->data << " ";
preorder(L->lchild);
preorder(L->rchild);
}
}
void inorder(BLink L) // 中序遍历
{
if(L!=NULL)
{
inorder(L->lchild);
cout << L->data << " ";
inorder(L->rchild);
}
}
void postorder(BLink L) // 后序遍历
{
if(L!=NULL)
{
postorder(L->lchild);
postorder(L->rchild);
cout << L->data << " ";
}
}
void level(BLink L)
{
int front,rear;
BLink p,que[num];
front = rear = 0;
if(L!=NULL)
{
rear = (rear+1)%num;
que[rear] = L;
while(front != rear)
{
front = (front + 1)%num;
p = que[front];
cout << p->data << " ";
if(p->lchild != NULL)
{
rear = (rear+1)%num;
que[rear] = p->lchild;
}
if(p->rchild != NULL)
{
rear = (rear+1)%num;
que[rear] = p->rchild;
}
}
}
}
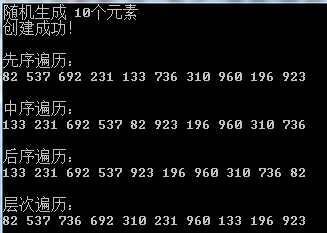
2.5.6 缺点
前、中、后序遍历,都是递归,很低效
递归 VS 循环,参见:https://blog.csdn.net/qq_40893824/article/details/106190466
低效原因
递归是系统给你做了个栈,每次递归要保护现场、恢复现场
2.6 前、中、后序遍历 - 非递归
主要用到了栈
2.6.1 前序
先访问结点值
若 右子树存在,进栈
若 左子树存在,进栈
void preorder(BLink L) // 先序遍历
{
if(L != NULL)
{
BLink p, stack[num];
int top = -1;
stack[++top] = L;
while(top != -1)
{
p = stack[top--];
cout << p->data << " " ;
if(p->rchild != NULL)
stack[++top] = p->rchild;
if(p->lchild != NULL)
stack[++top] = p->lchild;
}
}
}
2.6.2 中序
循环的条件:结点非空 或 栈非空
左子树进栈
输出左下角结点值,右子树若存在则进栈,否则再次循环输出结点的双亲
void inorder(BLink L) // 中序遍历
{
if(L != NULL)
{
BLink p, stack[num];
int top = -1;
p = L;
while(p != NULL || top != -1 ) // 结点非空 或 栈非空 都是循环的条件
{
while(p != NULL) //左子树进栈
{
stack[++top] = p;
p = p->lchild;
}
if(top != -1) // 输出左下角结点值,右子树若存在则进栈,否则再次循环输出结点的双亲
{
p = stack[top--];
cout << p->data << " ";
p = p->rchild;
}
}
}
}
2.6.3 后序
非递归先序的相反!
2 个栈:s1、s2
结点入栈 s1
栈 s1非空时,出栈 1 个结点,该结点进栈 s2
该结点若 左子树存在,进栈 s1
该结点若 右子树存在,进栈 s1,循环
生成栈 s2
顺序出栈就是后序遍历的顺序!
| 后序 | 先序 |
|---|---|
| 结点入栈 s1 栈 s1非空时,出栈 1 个结点,该结点进栈 s2 该结点若 左子树存在,进栈 s1 该结点若 右子树存在,进栈 s1,循环 | 先访问结点值 若 右子树存在,进栈 若 左子树存在,进栈 |
void postorder(BLink L) // 后序遍历
{
if(L != NULL)
{
BLink p, stack1[num], stack2[num];
int top1 = -1, top2 = -1;
stack1[++top1] = L;
while(top1 != -1)
{
p = stack1[top1--];
stack2[++top2] = p;
if(p->lchild != NULL)
stack1[++top1] = p->lchild;
if(p->rchild != NULL)
stack1[++top1] = p->rchild;
}
while(top2 != -1)
{
p = stack[top--];
cout << p->data << " ";
}
}
}
2.6.4 测试代码
#include<bits/stdc++.h>
#define num 100
#define max 1000
using namespace std;
typedef struct BNode
{
int data;
struct BNode *lchild, *rchild; // 分别是 左子树 和 右子树
}*BLink,BNode;
void creat(BLink &p);
void creatTree(BLink &L, int &n, int length);
void preorder2(BLink L); // 前序遍历 - 非递归
void inorder2(BLink L); // 中序遍历 - 非递归
void postorder2(BLink L); // 后序遍历 - 非递归
int main()
{
srand(time(NULL));
BLink L;
creat(L);
cout << "先序遍历 - 非递归:" << endl;
preorder2(L);
cout << endl << endl;
cout << "中序遍历 - 非递归:" << endl;
inorder2(L);
cout << endl << endl;
cout << "后序遍历 - 非递归:" << endl;
postorder2(L);
cout << endl << endl;
system("pause");
return 0;
}
void creatTree(BLink &L, int &n, int length)
{
if(n < length)
{
BLink p;
p = (BNode *)calloc(1, sizeof(BNode));
p->data = rand()%max;
L = p;
n++;
creatTree(L->lchild, n, length);
creatTree(L->rchild, n, length);
}
}
void creat(BLink &L)
{
int t,length = rand()%num;
cout << "随机生成 " << length << "个元素" << endl;
if(length > 0)
{
L = (BNode *)calloc(1, sizeof(BNode));
L->data = rand()%max;
t = 0;
creatTree(L->lchild, t, (length-1)/2);
t = 0;
creatTree(L->rchild, t, length-1-(length-1)/2);
cout << "创建成功!" << endl << endl;
}
else
{
L = NULL;
cout << "树为空!" << endl << endl;
}
}
void preorder2(BLink L) // 先序遍历
{
if(L != NULL)
{
BLink p, stack[num];
int top = -1;
stack[++top] = L;
while(top != -1)
{
p = stack[top--];
cout << p->data << " " ;
if(p->rchild != NULL)
stack[++top] = p->rchild;
if(p->lchild != NULL)
stack[++top] = p->lchild;
}
}
}
void inorder2(BLink L) // 中序遍历
{
if(L != NULL)
{
BLink p, stack[num];
int top = -1;
p = L;
while(p != NULL || top != -1 ) // 结点非空 或 栈非空 都是循环的条件
{
while(p != NULL) //左子树进栈
{
stack[++top] = p;
p = p->lchild;
}
if(top != -1) // 输出左下角结点值,右子树若存在则进栈,否则再次循环输出结点的双亲
{
p = stack[top--];
cout << p->data << " ";
p = p->rchild;
}
}
}
}
void postorder2(BLink L) // 后序遍历
{
if(L != NULL)
{
BLink p, stack1[num], stack2[num];
int top1 = -1, top2 = -1;
stack1[++top1] = L;
while(top1 != -1)
{
p = stack1[top1--];
stack2[++top2] = p;
if(p->lchild != NULL)
stack1[++top1] = p->lchild;
if(p->rchild != NULL)
stack1[++top1] = p->rchild;
}
while(top2 != -1)
{
p = stack2[top2--];
cout << p->data << " ";
}
}
}

2.7 线索二叉树
2.7.1 起源 + 好处
普通 n 个结点的二叉树,有 (n + 1)个空指针
为什么是 (n + 1)?
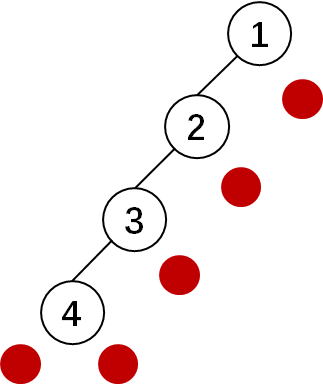
4个结点,5个红球就是 5个空子树指针
这么多空指针,不利用,多浪费!
二叉树的非递归,高效
线索二叉树,充分利用了空指针,非递归遍历时,连栈都不需要,更高效!
2.7.2 存储结构
仅链式
新加了 ltag、rtag

typedef struct TBNode
{
int data; //数据
int ltag, rtag;
// 0,1;
// ltag = 0, lchild指向孩子-左子树; ltag = 1, lchild指向前驱
// rtag = 0, rchild指向孩子-右子树; rtag = 1, rchild指向后继
struct TBNode *lchild, *rchild; // 左子树、右子树 指针
}TBLink, TBNode;
2.7.3 3个建树标准
原本的空指针指向的结点,按照不同顺序,是不一样的
按 先序顺序,是 先序线索二叉树
按 中序顺序,是 中序线索二叉树
按 后序顺序,是 后序线索二叉树
其中,中序线索二叉树用的最多!
2.7.3.0 三个递归遍历
前序
void preorder(TBLink L) // 前序遍历递归
{
if(L != NULL)
{
cout << L->data << " ";
if(L->ltag == 0)
preorder(L->lchild);
if(L->rtag == 0 )
preorder(L->rchild);
}
}
中序
void inorder(TBLink L) // 中序遍历递归
{
if(L != NULL)
{
if(L->ltag==0)
inorder(L->lchild);
cout << L->data << " " ;
if(L->rtag==0)
inorder(L->rchild);
}
}
后序
void postorder(TBLink L)
{
if(L != NULL)
{
if(L->ltag == 0)
postorder(L->lchild);
if(L->rtag == 0)
postorder(L->rchild);
cout << L->data << " ";
}
}
2.7.3.1 前序线索化
建树
先写好标记 ltag、rtag,再去访问左右节点要判断是否标记为 0!
void creat1(TBLink &L) // 前序线索化
{
cout << "尝试前序线索化..." << endl ;
if(L != NULL)
{
TBLink pre = NULL;
precreat(L, pre);
pre->rchild = NULL;
pre->rtag = 1;
cout << "成功!" << endl << endl;
}
else
cout << "树为空!" << endl << endl;
}
void precreat(TBLink &L, TBLink &pre) // 跟 creat1() 前序线索化
{
if(L != NULL)
{
if(L->lchild == NULL)
{
L->lchild = pre;
L->ltag = 1;
}
if(pre != NULL && pre->rchild == NULL)
{
pre->rchild = L;
pre->rtag = 1;
}
pre = L;
if(L->ltag == 0)
precreat(L->lchild, pre);
if(L->rtag == 0)
precreat(L->rchild, pre);
}
}
非递归遍历
void preorder3(TBLink L)
{
if(L != NULL)
{
TBLink p;
p = L;
while(p != NULL)
{
while(p->ltag == 0)
{
cout << p->data << " ";
p = p->lchild;
}
cout << p->data << " ";
p = p->rchild;
}
}
}
2.7.3.2 中序线索化
建树
最后一个结点的后继 记得为 NULL
void creat2(TBLink &L) // 中序线索化
{
cout << "尝试中序线索化..." << endl ;
if(L != NULL)
{
TBLink pre = NULL;
increat(L, pre);
pre->rchild = NULL;
pre->rtag = 1;
cout << "成功!" << endl << endl;
}
else
cout << "树为空!" << endl << endl;
}
void increat(TBLink &L, TBLink &pre)
{
if(L != NULL)
{
increat(L->lchild, pre); // 左子树 线索化
if(L->lchild == NULL) // 前驱线索
{
L->lchild = pre;
L->ltag = 1;
}
if(pre != NULL && pre->rchild == NULL) // 后继线索
{
pre->rchild = L;
pre->rtag = 1;
}
pre = L;
increat(L->rchild, pre); // 右子树 线索化
}
}
非递归遍历
TBLink first(TBLink L)
{
while(L->ltag == 0)
L = L->lchild;
return L;
}
TBLink next(TBLink L)
{
if(L->rtag == 1) // 后继
return L->rchild;
else
return first(L->rchild); // 右子树的 左下角
}
void inorder3(TBLink L) // 中序遍历
{
TBLink p;
for(p = first(L); p != NULL; p = next(p))
cout << p->data << " " ;
cout << endl << endl;
}
2.7.3.3 后序线索化
建树
void creat3(TBLink &L) // 后序化
{
cout << "尝试后序线索化..." << endl ;
if(L != NULL)
{
TBLink pre = NULL;
postcreat(L, pre); //最后一个结点是根结点,前驱后继均为 0!
if(L->rchild == NULL)
{
L->rtag = 1;
}
cout << "成功!" << endl << endl;
}
else
cout << "树为空!" << endl << endl;
}
void postcreat(TBLink &L, TBLink &pre)
{
if(L != NULL)
{
postcreat(L->lchild,pre);
postcreat(L->rchild,pre);
if(L->lchild == NULL) // 前驱
{
L->lchild = pre;
L->ltag = 1;
}
if(pre != NULL && pre->rchild == NULL)
{
pre->rchild = L;
pre->rtag = 1;
}
pre = L;
}
}
非递归遍历
想了很久,该部分代码 有没头绪
认为最方便的是 中序线索二叉树 和其遍历,后序复杂又不简洁,若遇到树的构造问题,直接 中序线索化就可以了,哎…
而且没有想到 后序线索二叉树有啥优点,以后若遇到 后序线索的好处,一定回来补齐这部分代码
2.7.4 测试代码
代码太长,参见:https://blog.csdn.net/qq_40893824/article/details/106209532
3 二叉树、树、森林 相互转化
树 ↔ 二叉树 ↔ 森林
3.1 树 ↔ 二叉树
3.1.1 树 → 二叉树
结点的孩子用线连起来
每个结点的分支,从左往右,除第 1 个外,把其它减掉
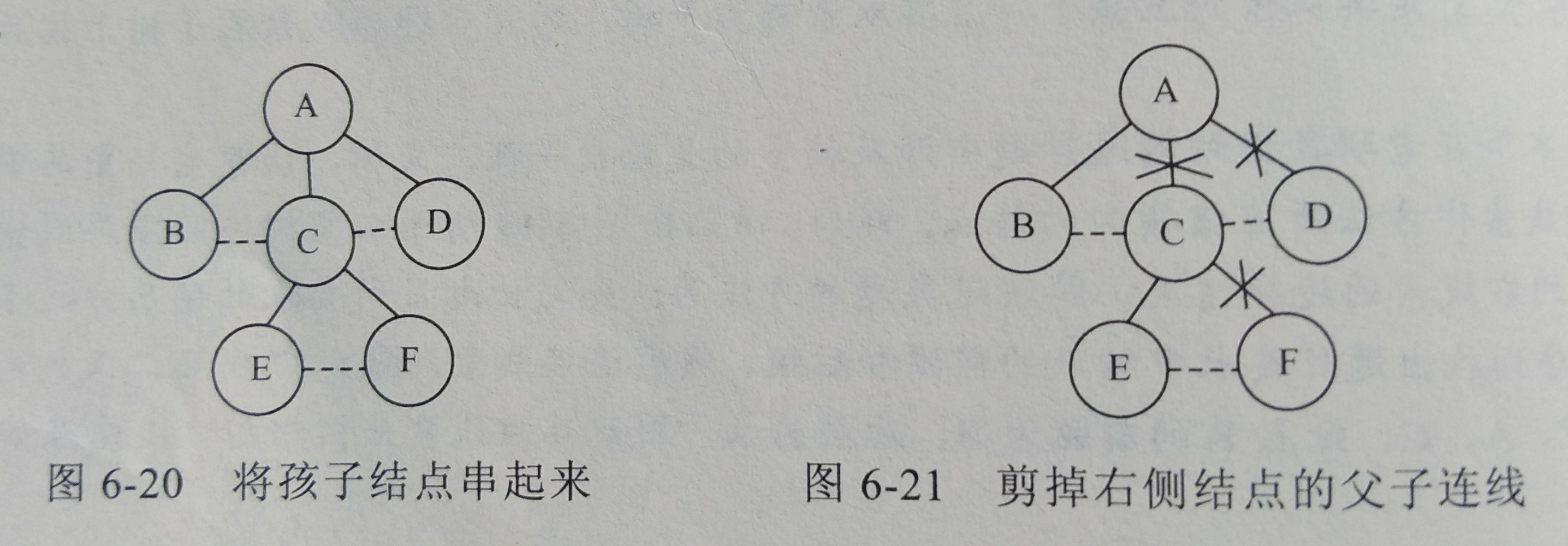
3.1.2 树 ← 二叉树
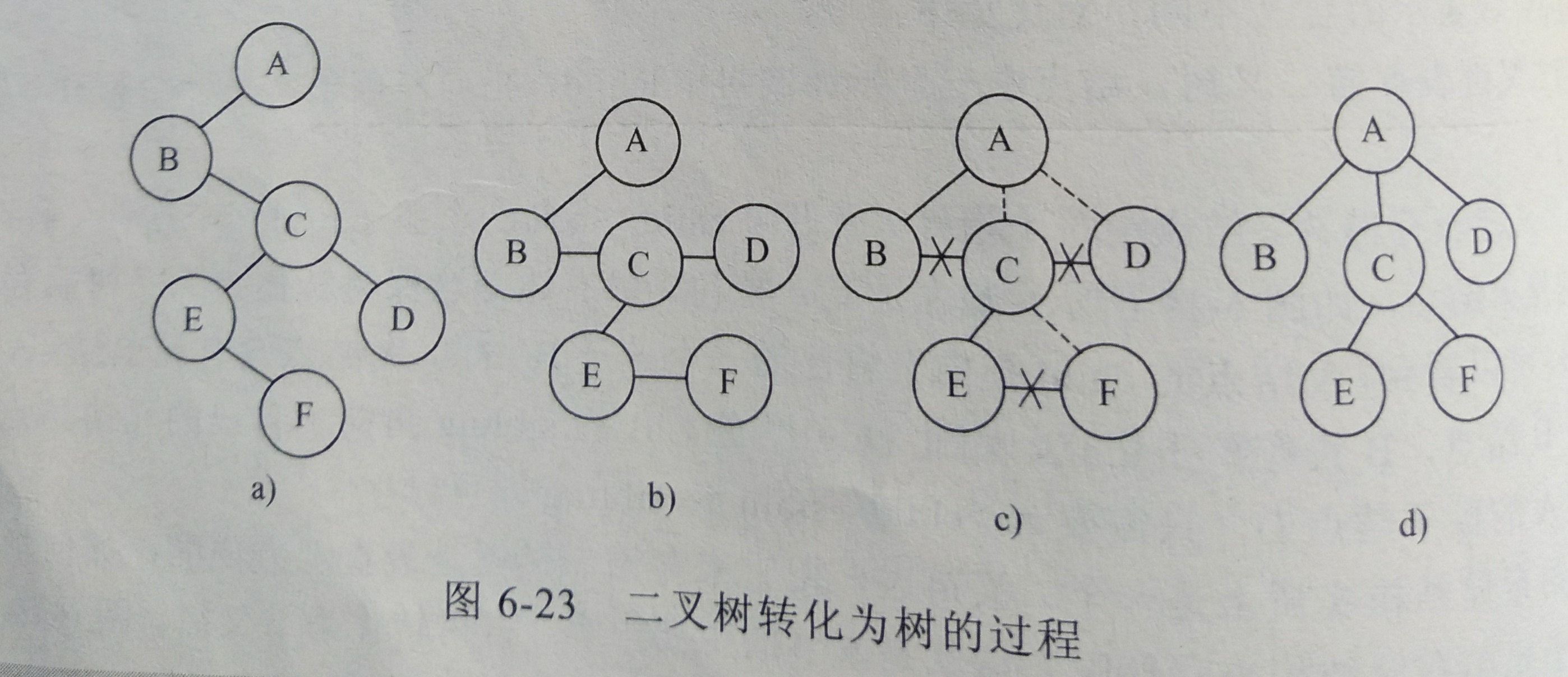
是 树 → 二叉树 过程的相反
结点和它右孩子放同 1 层
每 1 层 结点,和它的双亲连线
每 1 层 结点之间的连线,除第 1 个外,其它减掉
3.2 二叉树 ↔ 森林
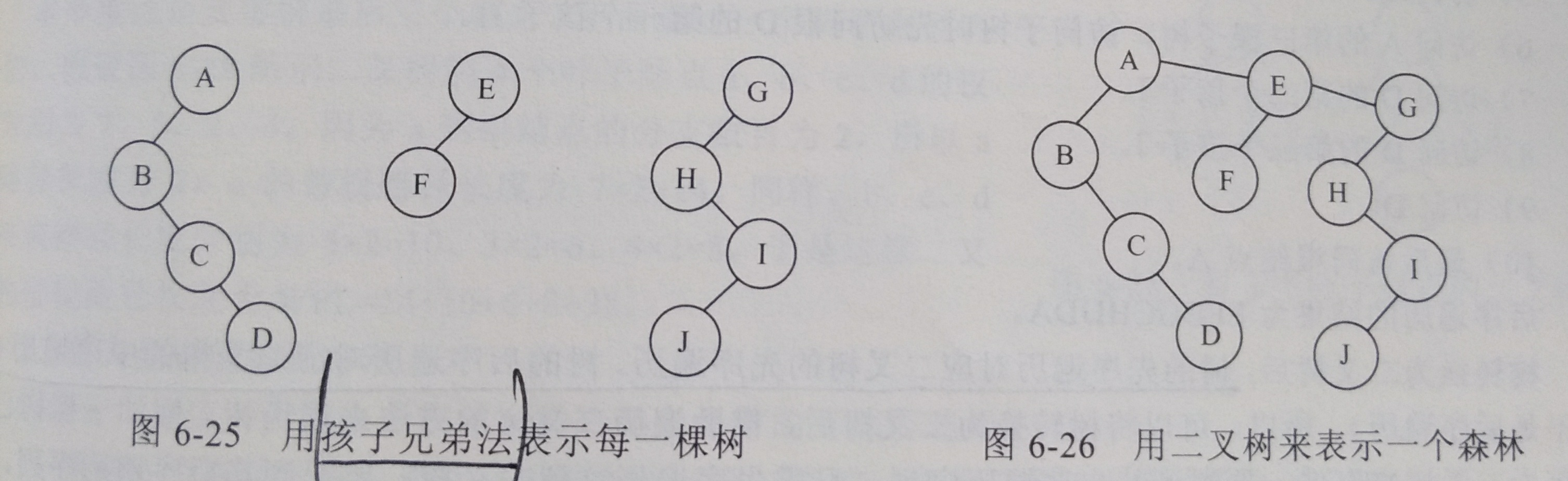
3.2.1 二叉树 ← 森林
森林的 n 个树 → n 个二叉树
第 i 个二叉树的根结点,作为第 (i - 1) 个二叉树的右孩子,i ≥ 2

3.2.2 二叉树 → 森林
二叉树 ← 森林 的相反,略
3.3 遍历
| 分类 | 树 | 森林 |
|---|---|---|
| 先序遍历 | = 二叉树的 先序遍历 根结点 → 左孩子 → 右孩子 | = 二叉树的 先序遍历 |
| 后序遍历 | = 二叉树的 后序遍历 左孩子 → 右孩子 → 根结点 | = 二叉树的 中序遍历 |
4 哈夫曼树 ( 赫夫曼树 / 最优二叉树 ) 及 哈夫曼编码
| 概念 | 解释 |
|---|---|
路径长度区别二叉树的路径长度见1.1 基本概念 | 结点 a 到 结点 b 的路径上线段个数a→b→c,2 个线段,故 a 到 c 的路径长度是 2 |
| 树 的路径长度 | 根结点 到 每个结点的 路径长度 的 和 |
| 带权路径长度 | 该点权值 乘以 到根结点的 路径长度 的 数值 |
| 树 的带权路径长度 ( WPL ) | 树的所有叶子结点的 带权路径长度 的 和 |
哈夫曼树的 带权路径长度WPL 最短!
4.1 特点
- 权值越大,离根结点越近
- 没有 度为 1 的结点
- 带权路径长度 最 短
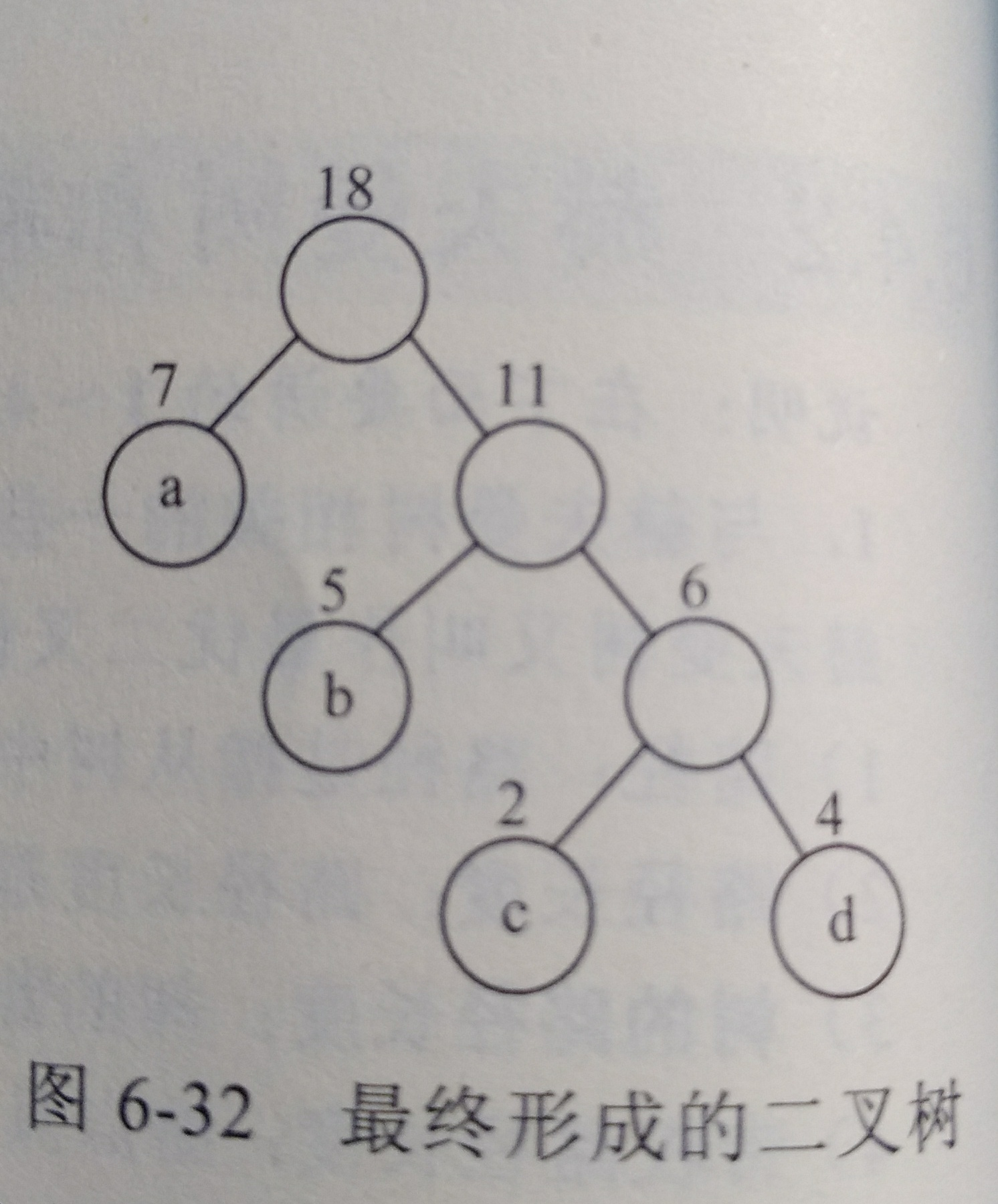
4.2 构造 哈夫曼树
哈夫曼二叉树 - 原则
选 2 个最小的数 是底层的叶子结点, 两数的和(1个数)代替这 2 个数 在剩下数 的位置
剩下数中 再选 2 个最小的数,重复
默认: 左子树的值 < 右子树的值
构造哈夫曼树 可能不唯一,因为开始可能有 3 个相同的最小值,看你先选哪两个了
4.3 哈夫曼编码
对于字符串,每个字符 变长 存储,这样比 定长存储字符要 节省空间!
用哈夫曼编码 表示 每 1 个字符!
做法
统计各字符 的出现次数
出现次数 作为一系列数字,构造哈夫曼树,树的路径,左0右1
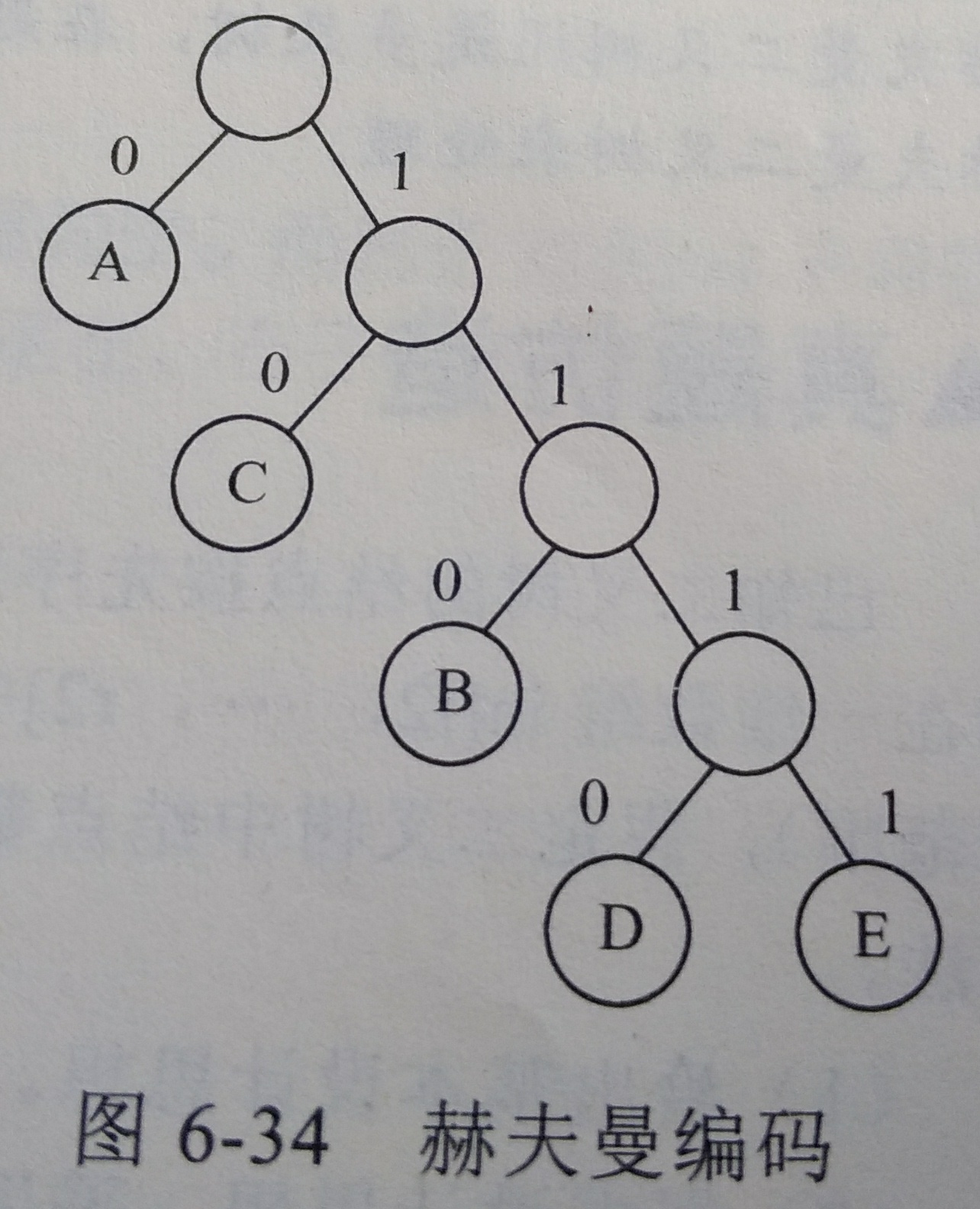
| 结点 | A | C | B | D | E |
|---|---|---|---|---|---|
| 哈夫曼编码 | 0 | 10 | 110 | 1110 | 1111 |
歧义问题 - 前缀码
对于变长存储,如何识别 它表示的字符呢?
出现前缀相同的编码,该判定表示哪一个字符呢?
例:
a 用 0 表示,b 用 01 表示,c 用 1 表示,当出现 01时,应该是 “ac” 还是单独的 “b” 呢?
用 前缀码 可以解决 前缀相同 引起的 歧义问题。
哈夫曼编码 是 前缀码,是最短前缀码
前缀码:任意编码串 不是 其他 编码串的 前缀!
哈夫曼树 构成的哈夫曼编码,组成的 表示串 s 的字符串,是 0、1 组成的,从头读,0 就是A,10 就是C,这就是路径,不会产生歧义的路径!
4.4 代码 - 构造哈夫曼树 + 哈夫曼编码
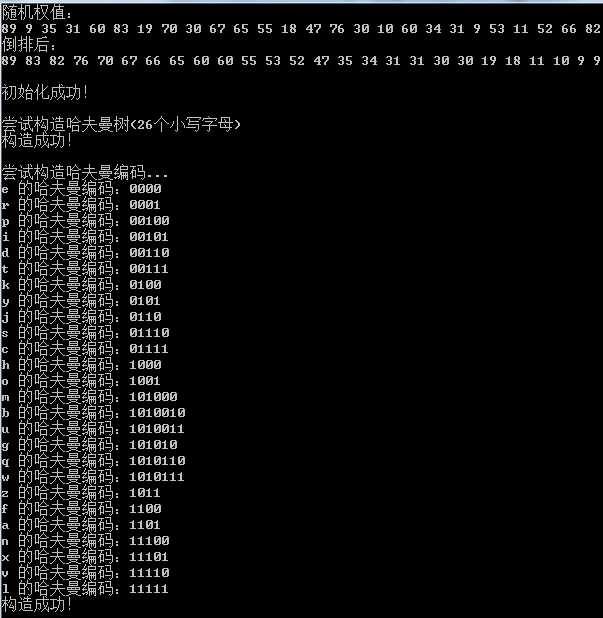
构造哈树 - 思路
26 个哈树结点,小写字母对应随机权值,给各结点
将结点 按权值 倒序排列
从后往前,两两生成 1 个父节点,并在前面一趟插入排序,保持倒序状态,
构造哈夫曼编码 - 思路
从头结点开始进行前序遍历,左子树编码在自己编码基础上加 “0”,右子树编码在自己编码基础上加 “1”(strcpy + strcat)
无左右子树,就输出其 编码
结点可以互相赋值,不用对其属性一个一个赋值!像单个变量一样,直接等号赋值即可
结构体不能进行加减操作!
网络其他可运行的代码:https://blog.csdn.net/XJTUbottom/article/details/103004000
我的思路更简洁点,蜜汁自信~~~
#include<bits/stdc++.h>
#define num 26
#define max 100
#define swap(a,b){a = a + b; b = a - b; a = a - b;} // 交换两数
using namespace std;
typedef struct HBNode
{
int data; // 权值
char c; // 代表字符
char code[max]; //编码
struct HBNode *lchild, *rchild; // 左子树 和 右子树
}*HBLink, HBNode;
void creat(HBLink &L) ; // 构造哈夫曼树
void init(HBLink a[]) ;
void print(HBLink a[]);
int com(HBLink a, HBLink b) ;
void sort1(HBLink a[], int high, HBLink data); //插入一趟排序
void HBCode(HBLink &L); // 哈夫曼编码
void connect(char *a, char *b, char c[]); // 字符串连接
int main()
{
srand(time(NULL));
HBLink L;
creat(L);
cout << "尝试构造哈夫曼编码..." << endl;
HBCode(L);
cout << "构造成功!" << endl << endl;
system("pause");
return 0;
}
void HBCode(HBLink &L)
{
if(L != NULL)
{
if(L->lchild == NULL && L->rchild == NULL)
{
cout << L->c << " 的哈夫曼编码:" << L->code << endl;
}
else
{
if(L->lchild!=NULL)
connect(L->lchild->code, L->code, "0");
if(L->rchild!=NULL)
connect(L->rchild->code, L->code, "1");
}
HBCode(L->lchild);
HBCode(L->rchild);
}
}
void connect(char a[], char b[], char c[])
{
strcpy(a, b);
strcat(a, c);
}
void creat(HBLink &L)
{
HBLink a[num]; //num个哈树结点
int t = num-1;
HBLink p;
init(a);
cout << "尝试构造哈夫曼树(26个小写字母)" << endl ;
while(t >= 1) // 开始构造哈夫曼树
{
p = (HBLink)calloc(1,sizeof(HBNode)); //父节点
p->lchild = a[t];
p->rchild = a[t - 1];
p->data = a[t]->data + a[t - 1]->data;
sort1(a, t-1, p); // 插入一趟排序
t--;
p = NULL;
}
L = a[0];
cout << "构造成功!" << endl << endl;
}
void sort1(HBLink a[], int high, HBLink p) //插入一趟排序
{
while(a[high]->data <= p->data && high >= 0)
{
a[high+1]=a[high]; // 树结点a[high]赋值给 树结点a[high+1]
high--;
}
a[high+1]=p;
}
int com(HBLink a, HBLink b)
{
return a->data > b->data;
}
void init(HBLink a[])
{
int i, t, t1, t2 ;
char c;
cout << "随机权值:" << endl;
for (i = 0; i < num ; i++)
{
a[i] = (HBLink)calloc(1,sizeof(HBNode));
a[i]->c = 'a' + i;
a[i]->data = rand()%max;
cout << a[i]->data << " ";
}
cout << endl;
t = rand()%num + 1; // 打乱顺序
for(i = 0; i < t ; i++)
{
t1 = rand()%num;
t2 = rand()%num;
if(t1 != t2) // 若相同,会导致是一个数在交换,自己减自己是0!
{
// swap(a[t1], a[t2]); // 这句话错误!结构体不能做加减操作
swap(a[t1]->c, a[t2]->c); // 交换两数
swap(a[t1]->data, a[t2]->data); // 交换两数
}
}
sort(a, a + num, com);//降序排列!
print(a);
cout << "初始化成功!" << endl <<endl;
}
void print(HBLink a[])
{
int i;
cout << "倒排后:" << endl;
for(i = 0; i < num; i++)
cout << a[i]->data << " ";
cout <<endl << endl;
}
4.5 哈夫曼 n 叉树 ( n > 2 )
4.4.1 构造
原则类似 哈夫曼二叉树
构造时,发现最后的数不足 n 个时,用数字 0 来补
















 192
192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











