







总共需要配置5个文件

1.配置 hadoop-env.sh
vi hadoop-env.sh,修改 JAVA_HOME 为之前那个参数(之前已经设置过)
2.配置core-site.xml
vi core-site.xml,在configuration中添加各配置项
配置默认采用的文件系统(由于存储层和运算层松耦合,要为它们指定使用hadoop原生的分布式文件系统hdfs。value填入的是URI,参数是 分布式集群中主节点的地址(主机名) : 指定端口号)

3.配置 hdfs-site.xml
vi hdfs-site.xml,在data目录下创建tmp文件夹
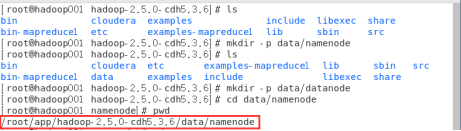
(1)配置hadoop的公共目录,在data目录创建namenode和datanode文件夹
(指定hadoop进程运行中产生的数据存放的工作目录,NameNode、DataNode等就在本地工作目录下建子目录存放数据。但事实上在生产系统里,NameNode、DataNode等进程都应单独配置目录,而且配置的应该是磁盘挂载点,以方便挂载更多的磁盘扩展容量)
(value的参数仍与之前一样可以进入解压目录输入pwd查看)
(2)配置hdfs的副本数
(客户端将文件存到hdfs的时候,会存放在多个副本。value一般指定3,但因为搭建的是伪分布式就只有一台机器,所以只能写1。)

4.配置 mapred-site.xml
mv mapred-site.xml.template mapred-site.xml,将mapred-site.xml.template重命名为mapred-site.xml(也可以使用rename命令)
vi mapred-site.xml,指定MapReduce程序应该放在哪个资源调度集群上运行。若不指定为yarn,那么MapReduce程序就只会在本地运行而非在整个集群中运行。

5.配置 yarn-site.xml
vi yarn-site.xml,要配置的参数有2个:
(1)指定yarn集群中的老大(就是本机)
配置yarn集群中的重节点,指定map产生的中间结果传递给reduce采用的机制是shuffle。

6.配置slaves
vi slaves,把localhost改为hadoop001(主机名)
7.配置环境变量PATH(在单例模式中已经配置过)
8.Namenode格式化
输入hdfs namenode -format

出现这个说明格式化成功,如果出现error信息说明格式化失败,把data目录下的三个临时文件删除重新格式化即可。
9.启动
start-dfs.sh
start-yarn.sh
然后输入jps 查看已成功启动的进程。

若出现这六个都没少则说明已全部成功启动了。
也可以通过访问http://192.168.127.128:50070/来监控伪分布式文件系统是否搭建成功。
















 209
209











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









